摘要
本文深入探讨了自动化网络爬虫技术如何彻底改变数据收集领域的游戏规则,揭示其作为提升工作效率的终极工具的奥秘。通过分析其工作原理、优势及实际应用案例,我们向读者展示了如何利用这一强大工具加速业务决策过程,同时保持数据收集的准确性和时效性。此外,本文还将简要介绍如何选择合适的网络爬虫服务,以及推荐一个可靠的选择------集蜂云平台。
一、引言:数据洪流中的精准捕捞者
在这个信息爆炸的时代,数据如同海洋,浩瀚而深邃。企业与开发者如同渔人,渴望在这片海洋中捕获有价值的数据珍珠。然而,传统的人工收集方式如同手工捕鱼,耗时费力且效率低下。自动化网络爬虫,这个智能的数据捕捞者,正是解决这一难题的关键。
1.1 什么是自动化网络爬虫?
自动化网络爬虫是一种程序,能够自动浏览互联网,按照预设规则抓取网页内容并结构化存储。它的工作原理类似于搜索引擎的爬虫,但更加专注于特定目标数据的收集。
1.2 数据收集的新篇章
随着技术的发展,自动化网络爬虫已经从简单的页面抓取进化到能处理复杂网站结构、动态加载内容甚至需要登录验证的高级数据挖掘工具。这不仅极大地提升了数据收集的效率,也为数据分析、市场研究、竞争情报等领域开辟了新的可能。
二、为何自动化网络爬虫是效率提升的终极武器?
2.1 节省时间和资源
自动化网络爬虫可以7x24小时不间断工作,相比人工收集,显著减少了人力成本和时间消耗。对于需要定期更新的大规模数据集,其优势更为明显。
2.2 提高数据准确性
通过精确的规则设定,网络爬虫能避免人为错误,确保所收集数据的准确性和一致性。这对于依赖高质量数据进行决策的业务至关重要。
2.3 动态适应,捕捉变化
互联网信息瞬息万变,自动化爬虫能够快速响应这些变化,及时调整策略,持续跟踪所需数据,让企业始终保持市场敏感度。
三、实战应用:自动化网络爬虫的行业实践
3.1 市场趋势分析
网络爬虫广泛应用于抓取电商、社交媒体等平台数据,帮助企业分析市场趋势、消费者行为,指导产品开发和营销策略。
3.2 竞争情报搜集
通过爬取竞争对手网站信息,企业可以了解对方的产品动态、价格策略,及时调整自己的市场定位,保持竞争力。
3.3 新闻监测与舆情管理
自动化爬虫能够实时监控新闻、论坛等平台,帮助企业快速响应社会舆论,有效管理品牌声誉。
四、选择网络爬虫服务的考量因素
在决定采用网络爬虫服务时,以下几点值得考虑:
-
合规性:确保所爬取数据的使用符合相关法律法规。
-
稳定性:选择具备高可用性和负载均衡能力的服务,保证数据采集的连续性。
-
技术支持:良好的客户服务和技术支持,能快速解决遇到的问题。
-
灵活性:支持自定义规则,满足多样化数据需求。
五、推荐方案:集蜂云平台
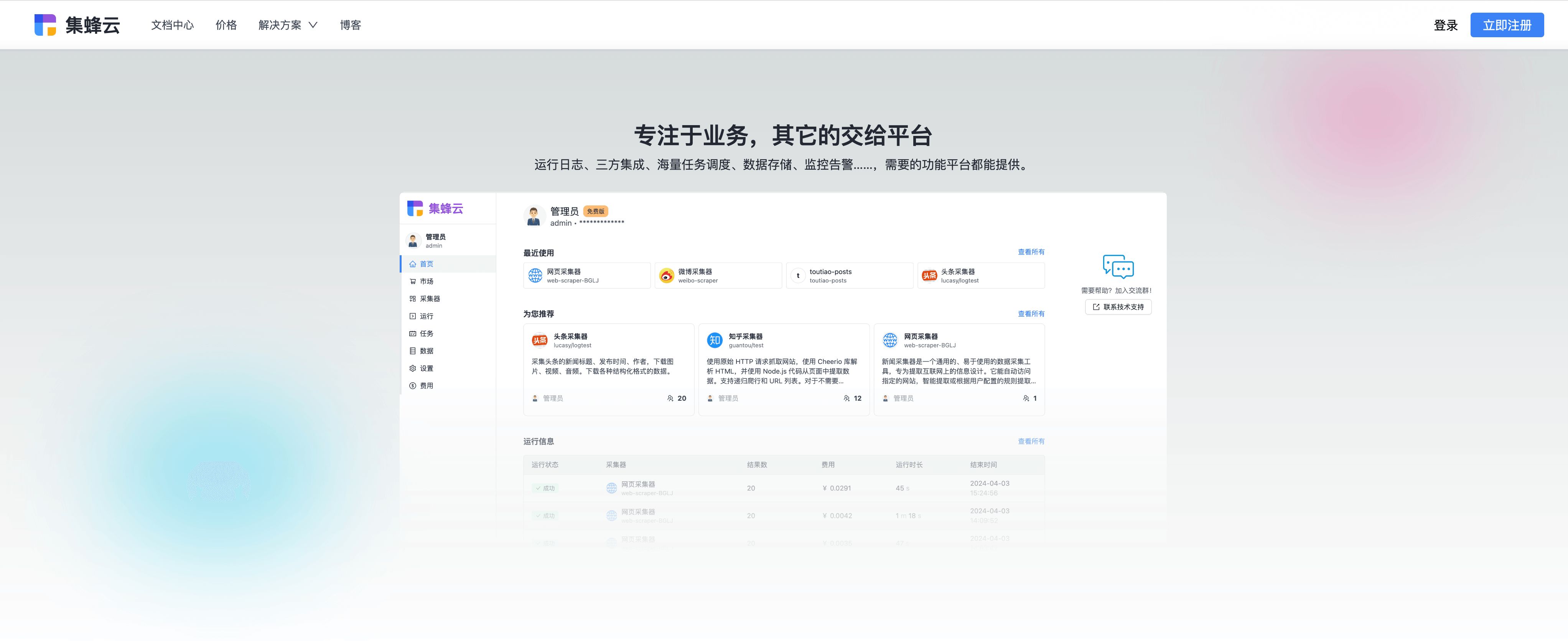
虽然本文未直接涉及集蜂云的具体功能,但基于其提供的海量任务调度 、三方应用集成 、数据存储等特性,集蜂云无疑是实现高效、稳定数据采集的一个优选平台。它不仅能满足上述所有考量因素,还能通过其强大的后台支持,助力企业轻松驾驭数据海洋,驱动业务增长。
常见问题与解答
-
Q: 网络爬虫是否合法?
- A: 合法,但需遵循目标网站的robots.txt协议及当地法律法规,不得侵犯版权或隐私。
-
Q: 如何避免被网站封禁?
- A: 设置合理的访问间隔,模拟正常用户行为,遵守网站规则,可使用代理IP池增加匿名性。
-
Q: 数据采集后的存储和分析怎么办?
- A: 可将数据存储于云数据库,利用数据分析工具(如Python的Pandas、SQL等)进行后续处理。
-
Q: 网络爬虫技术难度大吗?
- A: 初学者可使用Scrapy、BeautifulSoup等现成框架快速入门,复杂项目则需更多编程知识。
-
Q: 如何开始使用自动化网络爬虫?
- A: 了解基本概念后,可尝试编写简单爬虫脚本,或直接选用成熟的服务如集蜂云,快速部署数据采集任务。
本文通过对自动化网络爬虫的深入解析,展现了其在数据收集领域的强大效能。在正确使用下,它不仅是效率的提升者,更是商业智慧的加速器。希望每位读者都能从中找到解锁数据价值的钥匙,驱动自己的项目或企业迈向更高的台阶。