本篇简单拓展一下元素定位技巧,通过UI界面的文本去实现定位
目录
匹配XPath
比如我们要定位到下图的"百度一下"

先上代码
python
from playwright.sync_api import sync_playwright
def usage_1():
with sync_playwright() as p:
#启动谷歌浏览器实例
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.baidu.com")
# 在搜索框中输入关键词
page.locator('//input[@name="wd"]').fill("搜索")
# 点击"百度一下"按钮进行搜索
page.click("//input[@value='百度一下']")之前我们通过XPath 定位 ://input@value='百度一下',这个方法可行。
匹配文本元素
接下来我们使用get_by_text()方法匹配文本元素来实现定位,先断点调试一下
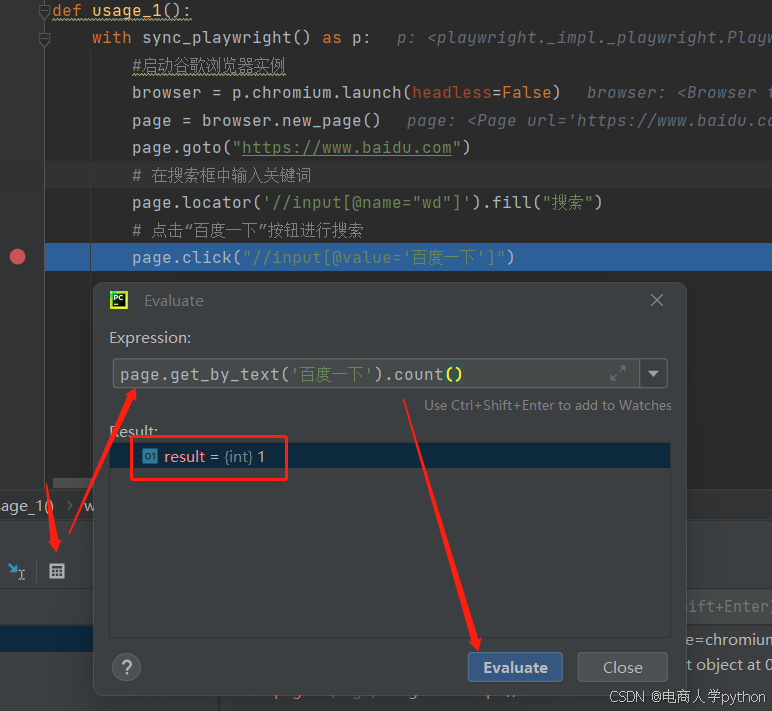
.count()统计匹配数量
get_by_text('需要查询的文本').count() 方法可以帮我们查询统计'百度一下' 文本在此时的UI页面有多少个,result={int}1 这个结果证明只有一个,是唯一的。继续调试
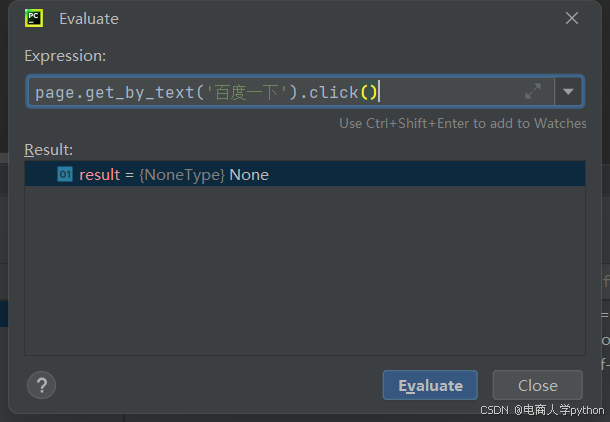
将count()方法换成click()方法,可以看到结果是成功了,现在切回UI检查是否点击'百度一下'成功,显而易见,使用get_by_text('百度一下')方法是可以成功实现元素定位操作的
处理匹配文本返回多个元素
1、使用.nth(index)选择特定元素:
如果你想要选择特定索引的元素,可以使用.nth(index)方法,其中index是从0开始的。
python
page.get_by_text('需要匹配的文本').nth(1) # 获取第二个匹配的元素2、获取所有匹配的元素并遍历:
如果需要处理所有匹配的元素,可以使用.all()方法来获取一个包含所有匹配元素的列表,然后遍历这个列表。
python
elements = page.get_by_text('需要匹配的文本').all()
for element in elements:
print(await element.inner_text())3、错误处理:
如果你期望只有一个匹配项,但是可能找到多个,可以检查返回的元素数量,并根据需要抛出异常或采取其他行动。
python
elements = page.get_by_text('需要匹配的文本').all()
if len(elements) > 1:
raise Exception("预期找到一个元素,但实际上找到了多个元素")
element = elements[0]希望通过以上内容能有效帮助到萌新友友理解使用playwright进行文本匹配操作实现元素定位!