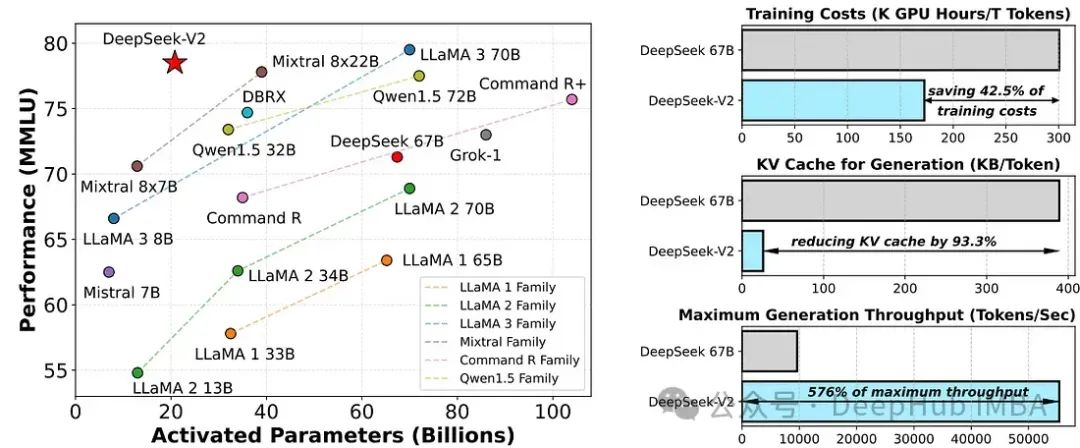
DeepSeek-V2是一个强大的开源混合专家(MoE)语言模型,通过创新的Transformer架构实现了经济高效的训练和推理。该模型总共拥有2360亿参数,其中每个令牌激活21亿参数,支持最大128K令牌的上下文长度。
在开源模型中,DeepSeek-V2实现了顶级性能,成为最强大的开源MoE语言模型。在MMLU(多模态机器学习)上,DeepSeek-V2以较少的激活参数实现了顶尖的性能。与DeepSeek 67B相比,DeepSeek-V2显著提升了性能,降低了42.5%的训练成本,减少了93.3%的KV缓存,并将最大生成吞吐量提高了5.76倍。
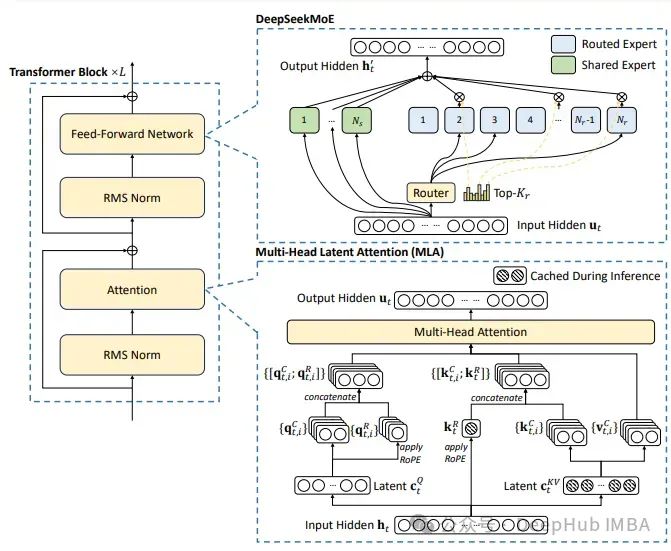
我们这里主要实现DeepSeek的主要改进:多头隐性注意力、细粒度专家分割和共享的专家隔离
架构细节
DeepSeek-V2整合了两种创新架构,我们将详细讨论:
- 用于前馈网络(FFNs)的DeepSeekMoE架构。
- 用于注意力机制的多头隐性注意力(MLA)。
DeepSeekMoE
在标准的MoE架构中,每个令牌被分配给一个(或两个)专家,每个MoE层都有多个在结构上与标准前馈网络(FFN)相同的专家。这种设置带来了两个问题:指定给令牌的专家将试图在其参数中聚集不同类型的知识,但这些知识很难同时利用;其次,被分配给不同专家的令牌可能需要共同的知识,导致多个专家在各自的参数中趋向于收敛,获取共享知识。
为了应对这两个问题,DeepSeekMoE引入了两种策略来增强专家的专业化:
- 细粒度专家分割:为了在每个专家中更有针对性地获取知识,通过切分FFN中的中间隐藏维度,将所有专家分割成更细的粒度。
- 共享专家隔离:隔离某些专家作为始终被激活的共享专家,旨在捕获不同上下文中的共同知识,并通过将共同知识压缩到这些共享专家中,减少其他路由专家之间的冗余。
让我们来定义DeepSeekMoE中第t个令牌的专家分配。如果u_t是该令牌的FFN输入,其输出h`_t将会是:
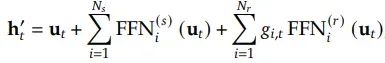
其中𝑁𝑠和𝑁𝑟分别是共享专家和路由专家的数量;FFN(𝑠)*𝑖和FFN(𝑟)*𝑖分别表示𝑖-th共享专家和𝑖-th路由专家。
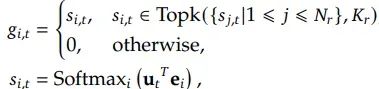
对于路由专家而言,g_i,t 是第i个路由专家的门控值,s_i,t 是令牌到专家的亲和分数,Topk(., Kr) 包含了Kr个最高的亲和分数,其中Kr是活跃的路由专家的数量。
有了以上的公式,我们就来使用代码实现
门控模型实现:
classMoEGate(torch.nn.Module):
def__init__(self, num_experts_per_tok: int, n_routed_experts: int, routed_scaling_factor: int, topk_method: str, n_group: int, topk_group: int, hidden_size: int):
super().__init__()
self.top_k=num_experts_per_tok
self.n_routed_experts=n_routed_experts
self.routed_scaling_factor=routed_scaling_factor
self.topk_method=topk_method
self.n_group=n_group
self.topk_group=topk_group
self.weight=torch.nn.Parameter(torch.empty((self.n_routed_experts, hidden_size)))
torch.nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
defforward(self, x: torch.Tensor):
batch, seq_len, h=x.shape
hidden_states=x.view(-1, h)
logits=torch.nn.functional.linear(hidden_states.type(torch.float32), self.weight.type(torch.float32), None)
scores=logits.softmax(dim=-1, dtype=torch.float32)
ifself.topk_method=="greedy":
topk_weight, topk_idx=torch.topk(scores, k=self.top_k, dim=-1, sorted=False)
elifself.topk_method=="group_limited_greedy":
group_scores= (scores.view(batch*seq_len, self.n_group, -1).max(dim=-1).values)
group_idx=torch.topk(group_scores, k=self.topk_group, dim=-1, sorted=False)[1] # [n, top_k_group]
group_mask=torch.zeros_like(group_scores) # [n, n_group]
group_mask.scatter_(1, group_idx, 1) # [n, n_group]
score_mask= (
group_mask.unsqueeze(-1)
.expand(
batch*seq_len, self.n_group, self.n_routed_experts//self.n_group
)
.reshape(batch*seq_len, -1)
) # [n, e]
tmp_scores=scores.masked_fill(~score_mask.bool(), 0.0) # [n, e]
topk_weight, topk_idx=torch.topk(
tmp_scores, k=self.top_k, dim=-1, sorted=False
)
returntopk_idx, topk_weightMoE
classMoE(torch.nn.Module):
def__init__(self, dim: int, routed_scaling_factor: int, topk_method: str, n_group: int, topk_group: int, hidden_dim: int|None=None, n_routed_experts: int=12, num_experts_per_tok: int=4, n_shared_experts: int=2, mlp: str="swiglu"):
super().__init__()
self.experts_per_rank=n_routed_experts
self.num_experts_per_tok=num_experts_per_tok
self.n_shared_experts=n_shared_experts
mlp_block=SwiGLU
self.experts=torch.nn.ModuleList([mlp_block(dim, hidden_dim) foriinrange(n_routed_experts)])
self.gate=MoEGate(num_experts_per_tok, n_routed_experts, routed_scaling_factor, topk_method, n_group, topk_group, dim)
self.shared_experts=mlp_block(dim, hidden_dim*n_shared_experts)
defforward(self, x: torch.Tensor):
identity=x
orig_shape=x.shape
topk_idx, topk_weight=self.gate(x)
x=x.view(-1, x.shape[-1])
flat_topk_idx=topk_idx.view(-1)
x=x.repeat_interleave(self.num_experts_per_tok, dim=0)
y=torch.empty_like(x)
y=y.type(x.dtype)
fori, expertinenumerate(self.experts):
y[flat_topk_idx==i] =expert(x[flat_topk_idx==i]).to(dtype=x.dtype)
y= (y.view(*topk_weight.shape, -1) *topk_weight.unsqueeze(-1)).sum(dim=1)
y=y.view(*orig_shape)
output=y+self.shared_experts(identity)
returnoutput多头隐性注意力(MLA)
多头隐性注意力(MLA)相较于标准的多头注意力(MHA)实现了更优的性能,并且显著减少了KV缓存,提高了推理效率。与多查询注意力(MQA)和分组查询注意力(GQA)中减少KV头的方法不同,MLA将键(Key)和值(Value)共同压缩成一个潜在向量。
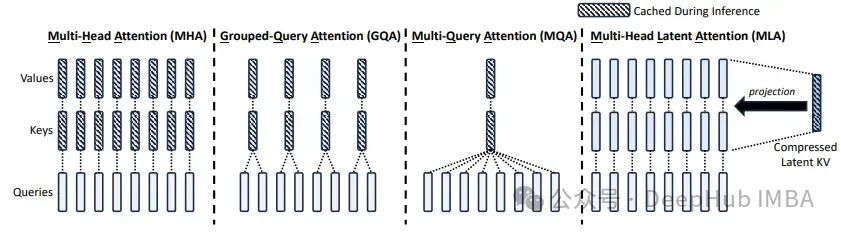
MLA不是缓存键(Key)和值(Value)矩阵,而是将它们联合压缩成一个低秩向量,这使得缓存的项目数量更少,因为压缩维度远小于多头注意力(MHA)中输出投影矩阵的维度。

标准的RoPE(旋转位置嵌入)与上述的低秩KV压缩不兼容。解耦RoPE策略使用额外的多头查询q_t和共享键k_t来实现RoPE。
下面总结了完整的MLA计算过程:
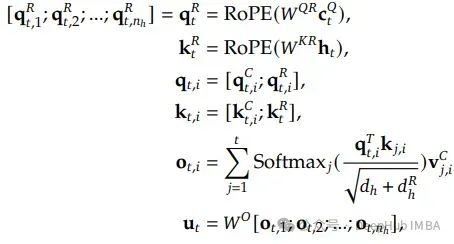
MLA实现
classMLA(torch.nn.Module):
def__init__(self, model_args: DeepseekConfig):
super().__init__()
d_model=model_args.d_model
self.num_heads=model_args.num_heads
self.head_dim=model_args.d_model//model_args.num_heads
self.attn_dropout=torch.nn.Dropout(model_args.dropout)
self.res_dropout=torch.nn.Dropout(model_args.dropout)
self.flash_attn=hasattr(torch.nn.functional, "scaled_dot_product_attention")
self.q_lora_rank=model_args.q_lora_rank
self.qk_rope_head_dim=model_args.qk_rope_head_dim
self.kv_lora_rank=model_args.kv_lora_rank
self.v_head_dim=model_args.v_head_dim
self.qk_nope_head_dim=model_args.qk_nope_head_dim
self.q_head_dim=model_args.qk_nope_head_dim+model_args.qk_rope_head_dim
self.q_a_proj=torch.nn.Linear(d_model, model_args.q_lora_rank, bias=False)
self.q_a_layernorm=RMSNorm(model_args.q_lora_rank)
self.q_b_proj=torch.nn.Linear(model_args.q_lora_rank, self.num_heads*self.q_head_dim, bias=False)
self.kv_a_proj_with_mqa=torch.nn.Linear(d_model,model_args.kv_lora_rank+model_args.qk_rope_head_dim,bias=False,)
self.kv_a_layernorm=RMSNorm(model_args.kv_lora_rank)
self.kv_b_proj=torch.nn.Linear(model_args.kv_lora_rank,self.num_heads* (self.q_head_dim-self.qk_rope_head_dim+
self.v_head_dim),bias=False,)
self.o_proj=torch.nn.Linear(self.num_heads*self.v_head_dim,d_model, bias=False,)
defforward(self, x: torch.Tensor, mask: torch.Tensor, freqs_cis) ->torch.Tensor:
batch, seq_len, d_model=x.shape
q=self.q_b_proj(self.q_a_layernorm(self.q_a_proj(x)))
q=q.view(batch, seq_len, self.num_heads, self.q_head_dim).transpose(1, 2)
q_nope, q_pe=torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
compressed_kv=self.kv_a_proj_with_mqa(x)
compressed_kv, k_pe=torch.split(compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
k_pe=k_pe.view(batch, seq_len, 1, self.qk_rope_head_dim).transpose(1, 2)
kv= (self.kv_b_proj(self.kv_a_layernorm(compressed_kv))
.view(batch, seq_len, self.num_heads, self.qk_nope_head_dim+self.v_head_dim)
.transpose(1, 2))
k_nope, value_states=torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
q_pe, k_pe=apply_rope(q_pe, k_pe, freqs_cis)
k_pe=k_pe.transpose(2, 1)
q_pe=q_pe.transpose(2, 1)
query_states=k_pe.new_empty(batch, self.num_heads, seq_len, self.q_head_dim)
query_states[:, :, :, : self.qk_nope_head_dim] =q_nope
query_states[:, :, :, self.qk_nope_head_dim :] =q_pe
key_states=k_pe.new_empty(batch, self.num_heads, seq_len, self.q_head_dim)
key_states[:, :, :, : self.qk_nope_head_dim] =k_nope
key_states[:, :, :, self.qk_nope_head_dim :] =k_pe
attn_mtx=torch.matmul(query_states, key_states.transpose(2, 3)) /math.sqrt(self.head_dim)
attn_mtx=attn_mtx+mask[:, :, :seq_len, :seq_len]
attn_mtx=torch.nn.functional.softmax(attn_mtx.float(), dim=-1).type_as(key_states)
attn_mtx=self.attn_dropout(attn_mtx)
output=torch.matmul(attn_mtx, value_states) # (batch, n_head, seq_len, head_dim)
output=output.transpose(1, 2).contiguous().view(batch, seq_len, self.num_heads*self.v_head_dim)
output=self.o_proj(output)
output=self.res_dropout(output)
returnoutput总结
本文详细介绍了DeepSeek-V2语言模型,这是一个强大的开源混合专家(MoE)语言模型,采用创新的架构来提高训练和推理的经济性和效率。DeepSeek-V2采用了两种核心技术:细粒度专家分割和共享专家隔离,这两种策略显著提高了专家的专业化水平。此外,文章还介绍了多头隐性注意力(MLA),这是一种改进的注意力机制,通过低秩键值联合压缩和解耦旋转位置嵌入,优化了模型的存储和计算效率。
除了理论探讨,我们通过编写代码实现DeepSeek-V2,可以更深入地理解其架构和工作原理。可以帮助你账务如何实现先进的混合专家(MoE)模型,还能深化对多头隐性注意力(MLA)和低秩键值压缩等关键技术的理解。通过实践,读者将能够验证理论的有效性,并对模型的性能和效率有直观的认识。
https://avoid.overfit.cn/post/317a967c8dac42ee98f96d8390851476
作者:Zain ul Abideen