目标检测 YOLOv5-7.0 详细调试&自制数据集实战
- 一、项目介绍及环境配置
- 二、如何利用YOLOv5进行预测(detect.py)
-
- (一)main函数中参数的解读
- (二)小技巧
-
- [(1)网络模型 下载的太慢/直接下载失败 ,怎么办?](#(1)网络模型 下载的太慢/直接下载失败 ,怎么办?)
- (2)图例
- 三、如何训练YOLOv5神经网络(train.py)
- 四、如何训练与制作自己的数据集
-
- (一)常见的几种情况
- (二)实操演练
-
- (1)数据集的获取
- (2)人工/半人工标注
- (3)创建标准化目录
- [(4)创建 - - data 数据集参数](#(4)创建 - - data 数据集参数)
- (5)训练模型检验
- (三)注意事项
一、项目介绍及环境配置
(一)项目解读





(二)版本选择
- v1.0版本写的代码最为简单核心,后面越来越复杂,这是一个项目从想象到成熟必经的过程。高版本的看不懂,可优先去读低版本的


.pt(.pth)文件:Pytorch中常用的文件扩展名,用于保存和加载模型的权重或整个模型的状态
(三)环境配置
- 解压完压缩包,在Pycharm中打开项目后,进行Python解释器的配置
注:最好一个项目一个环境!!!不然之后很容易依赖冲突!!!别问我是怎么知道的 🤕

- 安装项目中需要用到的库

- 如果作者提供requirments.txt文件
可利用PyCharm自带的智能提示进行安装,或者利用pip install -r requirments.txt 指令输入终端进行安装- 如果作者没有提供requirments.txt文件
根据运行报错信息,百度,手动安装缺少的库
二、如何利用YOLOv5进行预测(detect.py)
(一)main函数中参数的解读
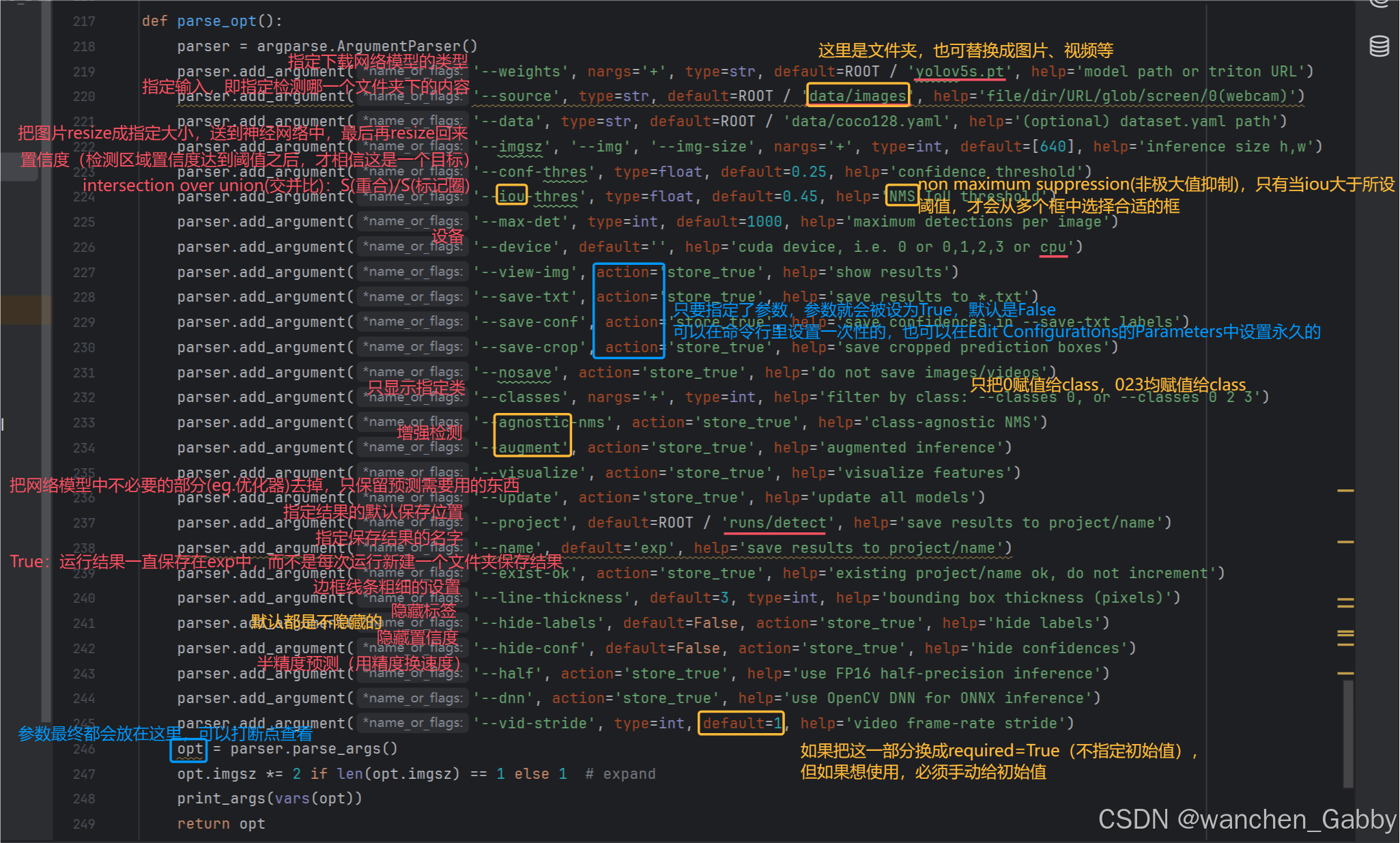
(二)小技巧
(1)网络模型 下载的太慢/直接下载失败 ,怎么办?
A:可以先在GitHub上下下来之后,再复制到当前文件夹(根目录)底下
Step1:Ctrl+C 暂停

Step2:找到项目的Release

Step3:往下翻,找到想要的模型,下载下来

Step4:粘贴到文件夹中


(2)图例
- resize的原理

- --iou-thres
iou达到某个阈值后,从下面多个框中选一个最适合的


-
参数解析

-
设置固定参数配置的位置

三、如何训练YOLOv5神经网络(train.py)
(一)本地上训练
(1)main函数中参数的解读

(2)可选参数



(3)训练生成文件的解读



(二)免费云端GPU上训练
(1)进入云端




(2)上传我们的项目


(3)解压缩

















(三)运行时的常见报错&解决方法
(1)attributeerror: 'FreeTypeFont' object has no attribute 'getsize'
这是因为安装了新版本的 Pillow10 删除了 getsize 功能
- 最容易想到的方法就是降级,降级到 Pillow 9.5 的确可以解决该问题,但有可能会造成其他库的依赖冲突。
- 我们这里讲另外一个方法:
因为 getsize 方法将在 Pillow10 中被 getbbox 或 getlength 代替
所以我们可以在 utils / plots.py 文件 的第 91 行,找到 w, h = self.font.getsize(label) ,把他替换成 x, y, w, h = self.font.getbbox(label) ,就可以解决问题。
(2)requests.exceptions.ConnectionError: HTTPSConnectionPool(host='drive.google.com', port=443): Max retries exceeded with url: /uc?id=1Kkx2zW89jq_NETu4u42CFZTMVD5Hwm6e (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x000001A5052AE640>: Failed to establish a new connection: WinError 10061 由于目标计算机积极拒绝,无法连接。'))
这个问题的原因是因为 DeepSORT 里面需要一些权重文件,没有权重文件的话会访问 Google Drive 进行下载,而国内没办法正常访问 Google Drive
- 那么需要我们手动下载权重文件放在 "C:\Users\31923.cache\torch\checkpoints" 里面,同时需要在DeepSORT源代码把联网下载部分注释掉,即可正常运行
- 最好的方法就是把需要下载的文件下载好之后,直接复制到当前文件夹底下
四、如何训练与制作自己的数据集
(一)常见的几种情况
(1)有数据集 --> 标注
(2)手动获得数据集 - 人工标注
(3)手动获得数据集 - 半人工标注
用已经训练好的网络对数据集进行简单的标注,再在此基础上进行微调
(4)仿真数据集(GAN,数字图像处理)
参考:https://github.com/Unity-Technologies/SynthDet

(二)实操演练
训练与制作自己的数据集教程参考:tutorials/train_custom_data
(1)数据集的获取



(2)人工/半人工标注


标注工具1:https://github.com/cvat-ai/cvat
标注工具2:https://www.makesense.ai/
标注工具3:labelme/labelimg/roboflow......










(3)创建标准化目录



(4)创建 - - data 数据集参数




(5)训练模型检验
- 权重参数

- 验证数据参数

- 结果

(三)注意事项


完