原创文章第608篇,专注"AI量化投资、世界运行的规律、个人成长与财富自由"。
做因子挖掘这段时间,有一个观感。
传统的因子挖掘,尤其是手工构造因子,到遗传算法因子挖掘。------本身也是一种"拟合",或者说试图"解释"过往的收益率,有一种符号表达的方式。
传统机器学习,我们也是试图这么做的,有不少工程上的tricks。
但在深度学习时代,最大的一点进步就是不需要特征工程,因为特征工程本身是对现实数据的简化。深度卷积神经网络读图片,它是读入像素级数据,然后自己建模。
之前星球有同学提问说------为什么不能直接端到端建模?
这其实是一个好问题。
图像识别就是端到端,AlphaGo就是端到端,深度强化学习端到端构建投资组合------从逻辑上更符合金融投资的场景------它甚至不需要label。
通过深度强化学习构建、筛选因子,然后再用深度学习来组合因子,这里确实会损失很多信息。
IC筛选出来的因子,在机器学习里组合效果并不一定好。
一个原因可能是ic是线性信息,而机器学习可以拟合高维非线性的信息。
所以,现在手工构建的因子,多数用于加权合成,而非机器学习;那么反过来,机器学习所需的特征,通过IC值来筛选还靠谱吗?
import warnings
# from collections import defaultdict
from typing import Dict, List, Tuple
import pandas as pd
import torch
from torch.nn.utils import clip_grad_norm_
# from torch.utils.data import DataLoader
from tqdm import tqdm
from .data_processor import DataProcessor
from .general import corrcoef_loss, get_strategy_returns, share_loss
from .module import Multi_Task_Model # CustomDataset
from .utils import all_nan, plot_pred_nan_num
class MTL_TSMOM:
def __init__(
self,
dataset: DataProcessor,
input_size: int,
lstm_hidden_size: int,
mlp_hidden_size: int,
lstm_layers: int,
mlp_layers: int,
optimizer_name: str,
transcation_cost: float,
target_vol: float,
lstm_dropout: float,
mlp_dropout: float,
max_grad_norm: float,
# batch_size: int,
num_epochs: int,
opt_kwargs: Dict = None,
early_stopping: int = 50,
log_step: int = 100,
verbose: bool = False,
save_path: str = None,
) -> None:
self.epoch_loss = [] # 储存每一次的损失
# self.all_loss = defaultdict(list) # 储存每一次的损失 1-train 2-valid
self.dataset = dataset
self.transcation_cost = transcation_cost
self.target_vol = target_vol
self.max_grad_norm = max_grad_norm
# self.batch_size = batch_size
self.num_epochs = num_epochs
self.early_stopping = early_stopping
self.log_step = log_step
self.verbose = verbose
self.save_path = save_path
# 初始化模型
self.model = Multi_Task_Model(
input_size,
lstm_hidden_size,
mlp_hidden_size,
lstm_layers,
mlp_layers,
lstm_dropout,
mlp_dropout,
).cuda()
if opt_kwargs is None:
opt_kwargs = {}
self.optimizer = getattr(torch.optim, optimizer_name)(
self.model.parameters(), **opt_kwargs
)
def log(self, arg, verbose=True) -> None:
if verbose:
print(arg)
def train_model(self, train_datase: List, gloabal_step: int = None) -> float:
self.model.train()
# train_dataset = CustomDataset(train_datase)
# train_loader = DataLoader(
# train_dataset, batch_size=self.batch_size, shuffle=False
# )
features, next_returns, forward_vol = train_datase
total_loss = 0.0
# loss = 0.0
# for batch, (features, next_returns, forward_vol) in enumerate(train_loader):
pred_sigma, weight = self.model(features)
auxiliary_loss: float = corrcoef_loss(pred_sigma, forward_vol)
main_loss: float = share_loss(
weight, next_returns, self.target_vol, self.transcation_cost
)
total_loss = (auxiliary_loss + main_loss) * 0.5
self.optimizer.zero_grad()
total_loss.backward()
# 为了防止梯度爆炸,我们对梯度进行裁剪
if self.max_grad_norm is not None:
clip_grad_norm_(self.model.parameters(), self.max_grad_norm)
self.optimizer.step()
# if gloabal_step is not None:
# self.all_loss[gloabal_step].append(
# (1, batch, auxiliary_loss, main_loss, total_loss)
# )
# loss += total_loss
return total_loss # loss / len(train_loader)
def validation_model(
self, validation_dataset: List, gloabal_step: int = None
) -> float:
# valid_dataset = CustomDataset(validation_dataset)
# valid_loader = DataLoader(
# valid_dataset, batch_size=self.batch_size, shuffle=False
# )
total_loss = 0.0
# loss = 0.0
self.model.eval()
features, next_returns, forward_vol = validation_dataset
with torch.no_grad():
# for batch, (features, next_returns, forward_vol) in enumerate(valid_loader):
pred_sigma, weight = self.model(features)
auxiliary_loss = corrcoef_loss(pred_sigma, forward_vol)
main_loss = share_loss(
weight, next_returns, self.target_vol, self.transcation_cost
)
total_loss = (auxiliary_loss + main_loss) * 0.5
# loss += total_loss
# if gloabal_step is not None:
# self.all_loss[gloabal_step].append(
# (2, batch, auxiliary_loss, main_loss, total_loss)
# )
return total_loss # loss / len(valid_loader)
def predict_data(self, test_part: List) -> Tuple[torch.Tensor, torch.Tensor]:
features, next_returns, _ = test_part
with torch.no_grad():
_, weight = self.model(features)
return weight, next_returns
def loop(
self, train_part: List, valid_part: List, global_step: int = None
) -> float:
best_valid_loss: float = float("inf") # 用于记录最好的验证集损失
epochs_without_improvement: int = 0 # 用于记录连续验证集损失没有改善的轮数
for epoch in range(self.num_epochs):
train_loss: float = self.train_model(train_part)
valid_loss: float = self.validation_model(valid_part)
if (self.log_step is not None) and (epoch % self.log_step == 0):
self.log(
f"Epoch {epoch or epoch+1}, Train Loss: {train_loss:.4f}, Valid Loss: {valid_loss:.4f}",
self.verbose,
)
# 判断是否有性能提升,如果没有则计数器加 1
# NOTE:这样是最小化适用的,如果是最大化,需要改成 valid_loss > best_valid_loss
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
epochs_without_improvement: int = 0
else:
epochs_without_improvement += 1
# 保存每一次的损失
self.epoch_loss.append((global_step, train_loss, valid_loss))
# 判断是否满足 early stopping 条件
if (self.early_stopping is not None) and (
epochs_without_improvement >= self.early_stopping
):
self.log(f"Early stopping at epoch {epoch + 1}...", self.verbose)
break
return valid_loss
def fit(self):
ls: List = [] # 储存每一次的权重和收益
size: int = len(self.dataset.train_dataset)
for i, (train_part, valid_part, test_part) in enumerate(
tqdm(
zip(
self.dataset.train_dataset,
self.dataset.valid_dataset,
self.dataset.test_dataset,
),
total=size,
desc="train",
)
):
self.loop(train_part, valid_part, i)
weight, next_returns = self.predict_data(test_part)
ls.append((weight, next_returns))
if all_nan(weight):
warnings.warn(f"下标{i}次时:All nan in weight,已经跳过")
# raise ValueError(f"下标{i}次时:All nan in weight")
break
weights_tensor: torch.Tensor = torch.cat([t[0] for t in ls], dim=0)
returns_tensor: torch.Tensor = torch.cat([t[1] for t in ls], dim=0)
self.weight = weights_tensor
self.next_returns = returns_tensor
if self.save_path is not None:
torch.save(self.model.state_dict(), self.save_path)
# return weights_tensor, returns_tensor
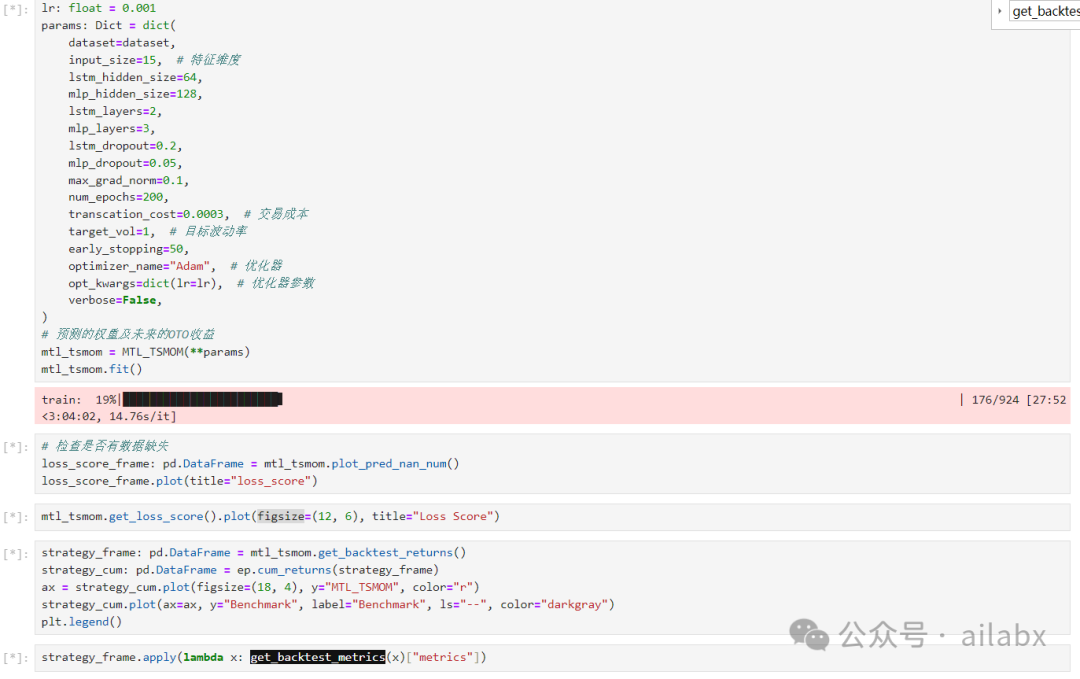
def get_backtest_returns(self) -> pd.DataFrame:
try:
self.weight
except NameError as e:
raise NameError("请先调用fit方法") from e
strategy_frame: pd.DataFrame = get_strategy_returns(
self.weight, self.next_returns, self.dataset.test_idx
)
return strategy_frame
def get_loss_score(self) -> pd.DataFrame:
if self.epoch_loss == []:
raise ValueError("请先调用fit方法")
return pd.DataFrame(
[(j.item(), k.item()) for _, j, k in self.epoch_loss],
columns=["train", "valid"],
)
def plot_pred_nan_num(self):
try:
self.weight
except NameError as e:
raise NameError("请先调用fit方法") from e
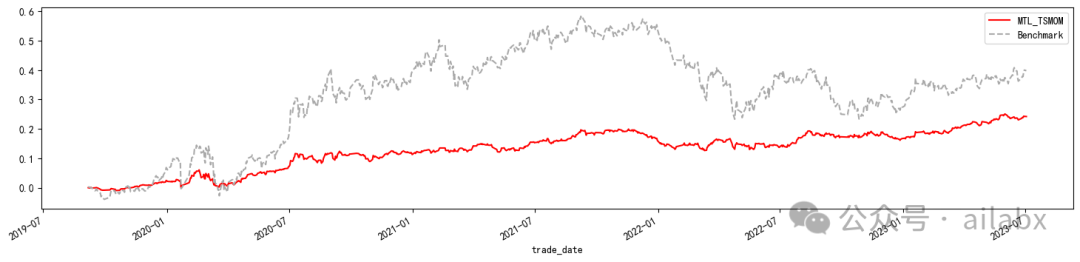
return plot_pred_nan_num(self.weight)昨天在星球里发布的论文,以上是核心代码。

通过时序动量和波动率对投资组合目标波动率建模。
代码下载:
吾日三省吾身
01
财富自由小目标------七年赚到500万实现财富自由,这是我的计划,也适合大多数普通人------这是我三年前写的文章了,这个时间点的认知,基本已经成型。财富自由的三个层次,三条路径吧。
第二层次相信并持续践行中。
努力开展第三层次。------做生产者,创造有价值的东西,走财富自由快车道。
更新了一下小目标: 按进度5年的阶段小目标,如果你有勇气把目标提升至10倍,那么5年内就可以实现大目标。
2000个W------普通人基本可以退休且无后顾之忧了。
怎么做呢?投资、创业、技能和知识付费。。
我问kimi怎么做,它的回答:
普通人在5年内赚取2000万是一个具有挑战性的目标,但并非不可能。以下是一些可能的途径和策略,但请注意,这些方法都涉及不同程度的风险,并且成功并不是保证的。
02
"对宏观保持耐心,对微观保持效率"。
今天读到这句话挺受启发。
多数人对宏观缺乏耐心,无论是投资还是经营自己的人生。
其实就是"但行好事,莫问前程",又同长期主义,延迟满足相关联。
好的事情发生,需要一点时间,有时候来得比你想象中要更久。我们可以努力的时间,只是一点一滴的当下。
"种一棵树最好的时间是十年前,其次是现在"。
03
吐槽两句------有一种讲量化的书,竟然只讲一堆理论、公式,数学推导。
然后竟然没有一行代码。
金融是一个偏实战的行业,它与物理、数学这种严格的科学不同。
好比马可维茨获得诺奖的MVO,并不能用于投资一样,因为参数敏感度太高,收益率无法预估且不稳定等因素。
理论当然重要,但金融的艺术性决定理论与实战会有出入。
所以,作为量化的书,不结合实战,连数据分析都不做,就光讲理论,洋洋洒洒这么厚的一本书,实在是。
之后我若是写书,一定会规避这种风格。要么不写,要么大家一定会拿到可以直接跑的代码。