今天这篇文章将给大家介绍关于电商零售客户细分数据分析及可视化的案例分析。
01
数据整理
导入数据
import pandas as pdimport numpy as npfrom pyecharts.charts import *import pyecharts.options as opts
import warningswarnings.filterwarnings('ignore')数据读取及预处理
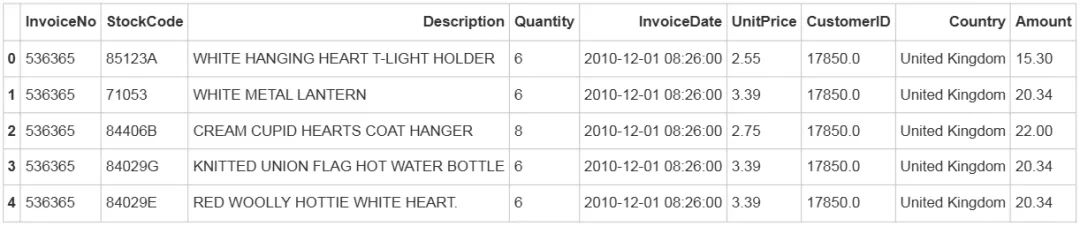
df = pd.read_excel('/home/mw/input/seg6541/Online Retail.xlsx')## 缺失值处理df.dropna(subset=['CustomerID'],inplace=True)## 时间处理df['InvoiceDate'] = df['InvoiceDate'].map(lambda x: str(x))## 国家名称统一化df.replace({'EIRE':'Ireland','USA':'United States','RSA':'South Africa','Czech Republic':'Czech','Channel Islands':'United Kingdom'}, inplace=True)## 计算每单的价格df['Amount'] = df['Quantity']*df['UnitPrice']预处理后的数据预览
df.head()输出结果:
02
数据分析及可视化
## 订单交易状态df['InvoiceNo'] = df['InvoiceNo'].astype(str)df['Transaction status'] = df['InvoiceNo'].map(lambda x:'0' if x.startswith('C') else '1')##可视化--订单交易状态label = ['交易成功','交易取消']value = df['Transaction status'].value_counts().values.tolist()pie=( Pie(init_opts=opts.InitOpts(theme='light',height='350px')) .add("",[list(z) for z in zip(label, value)],radius=["40%", "55%"],center=['32%','52%']) .set_series_opts( label_opts=opts.LabelOpts( formatter="{b}: {d}%" ) ) .set_global_opts( title_opts=opts.TitleOpts( title='订单交易情况', subtitle=' 2010-12-1 ~ 2011-12-9', pos_left='24%' ), legend_opts=opts.LegendOpts( is_show=False ) ))## 删除总消费金额<=0的用户df.drop(df.query('Amount <= 0').index.tolist(),inplace=True)df_country_amount = df.groupby('Country').agg({'Amount':'sum'}).reset_index()df_country_amount['Amount'] = df_country_amount.Amount.map(lambda x:round(x,2))df_country_amount = df_country_amount.sort_values('Amount',ascending=False)label = df_country_amount.head(7)['Country'].tolist()value = df_country_amount.head(7)['Amount'].tolist()bar = (Bar(init_opts=opts.InitOpts(theme='light')) .add_xaxis(label[::-1]) .add_yaxis('',value[::-1],itemstyle_opts={ 'barBorderRadius': [10, 10, 10, 10], }, ) .set_series_opts( label_opts = opts.LabelOpts( position='insideLeft', formatter='{b}:{c}£' ) ) .set_global_opts( title_opts = opts.TitleOpts( title='地区消费Top 7', subtitle = '2010-12-1 ~ 2011-12-9', pos_right = '18%' ), legend_opts = opts.LegendOpts( is_show=False ), xaxis_opts=opts.AxisOpts( is_show=False ), yaxis_opts=opts.AxisOpts( is_show=False ), ) )## 去除未确定的数据('Unspecified'、'European Community')data = df['Country'].value_counts().reset_index()data.drop([15,29],inplace=True)attr = data['index'].tolist()values = data['Country'].tolist()map_= ( Map(init_opts=opts.InitOpts(width='980px',height='400px')) .add("订单数量", [list(z) for z in zip(attr, values)], "world",is_map_symbol_show=False,is_roam=False,zoom='0.9') .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) .set_global_opts( title_opts=opts.TitleOpts( title='全球订单分布状态', subtitle=' 2010-12-1 ~ 2011-12-9', pos_left='center', pos_top='2%' ), visualmap_opts=opts.VisualMapOpts( max_=10000, is_show=False ), legend_opts=opts.LegendOpts( is_show=False ), ))df['InvoiceDate_year_month'] = df['InvoiceDate'].map(lambda x: str(x)[:-12])data = df['InvoiceDate_year_month'].value_counts().reset_index().sort_values('index')data.columns = ['time', 'counts']# LineStyleline_style = { 'normal': { 'width': 4, 'shadowColor': 'rgba(155, 18, 184, .3)', 'shadowBlur': 10, 'shadowOffsetY': 10, 'shadowOffsetX': 10, 'curve': 0.5 }}line = (Line(init_opts=opts.InitOpts(height='300px',width='500px')) .add_xaxis(data['time'].tolist()) .add_yaxis('',data['counts'].tolist(),is_symbol_show=False,is_smooth=True,linestyle_opts=line_style) .set_global_opts( title_opts=opts.TitleOpts( title='订单逐月变化趋势', subtitle='2010-12-1 ~ 2011-12-9', pos_left='28%', pos_top='2%' ), xaxis_opts=opts.AxisOpts( axislabel_opts={'rotate':'90'}, ), yaxis_opts=opts.AxisOpts( min_=10000, max_=70000, axisline_opts=opts.AxisLineOpts( is_show=False ), splitline_opts=opts.SplitLineOpts( is_show=True ) ), tooltip_opts=opts.TooltipOpts( is_show = True, trigger = 'axis', trigger_on = 'mousemove|click', axis_pointer_type = 'shadow' ) ))label = df['Description'].value_counts().head(7).index.tolist()value = df['Description'].value_counts().head(7).values.tolist()bar1 = (Bar(init_opts=opts.InitOpts(width='500px',height='300px',theme='light')) .add_xaxis(label[::-1]) .add_yaxis('',value[::-1],itemstyle_opts={ 'barBorderRadius': [10, 10, 10, 10], }, ) .set_series_opts( label_opts = opts.LabelOpts( position='insideLeft', formatter='{b}:{c}份' ) ) .set_global_opts( title_opts = opts.TitleOpts( title='热门商品Top 7', subtitle = '2010-12-1 ~ 2011-12-9', pos_right = '18%' ), legend_opts = opts.LegendOpts( is_show=False ), xaxis_opts=opts.AxisOpts( is_show=False ), yaxis_opts=opts.AxisOpts( is_show=False ), ) )grid = Grid(init_opts=opts.InitOpts(height='300px',theme='light'))grid.add(bar.reversal_axis(), grid_opts=opts.GridOpts(pos_left="60%"))grid.add(pie, grid_opts=opts.GridOpts(pos_left="60%"))
grid1 = Grid(init_opts=opts.InitOpts(height='300px',theme='light'))grid1.add(line, grid_opts=opts.GridOpts(pos_right="50%",pos_left='20%'))grid1.add(bar1.reversal_axis(), grid_opts=opts.GridOpts(pos_left="60%"))
page = Page()page.add(map_)page.add(grid)page.add(grid1)page.render_notebook()输出结果:
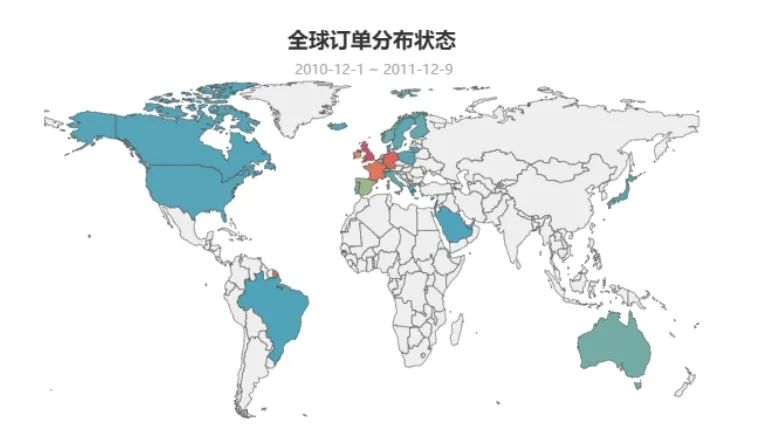
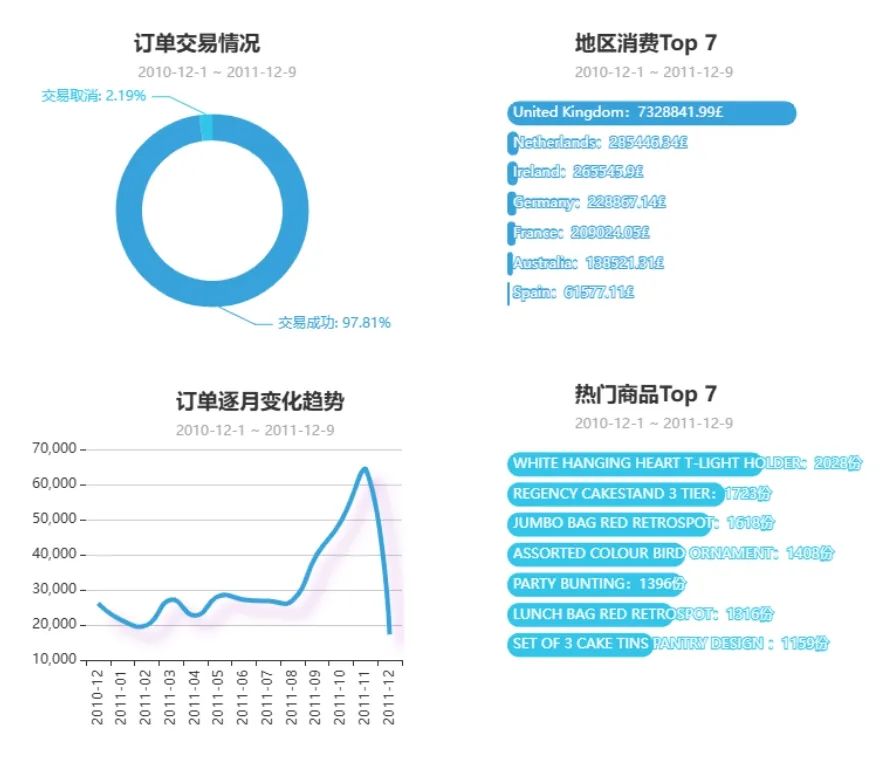
结论:
**1、英国为订单数量最多的多家:**在全球订单分布区域中,零售订单主要分布在以英国为中心辐射的欧洲地区,此外,北美、南美以及澳大利亚均有国家地区涉及订单下单。
**2、存在少量取消订单或退货:**在所有订单中,成功交易的订单占比达到97.81%,有2.19%的订单为取消订单或退货。
**3、2011年11月是订单高峰月:**2011年8月到2011年11月订单数量上升明显。
**4、热门商品:**WHITE HANGING HEART T-LIGHT HOLDER。
基于RFM模型的客户分群
## 计算每位顾客的消费总金额df_total=pd.DataFrame(df.groupby('CustomerID')['Amount'].sum()).reset_index()df_total.columns = ['CustomerID','Total_Amount']df_total['Total_Amount'] = df_total['Total_Amount'].map(lambda x:round(x,2))## 提取各订单消费年月日与时间df['InvoiceDate_ymd'] = df['InvoiceDate'].map(lambda x:x.split(' ')[0])df['InvoiceDate_hms'] = df['InvoiceDate'].map(lambda x:x.split(' ')[1])## 删除不需要的数据df.drop('InvoiceDate_year_month',axis=1,inplace=True)df.drop('Description',axis=1,inplace=True)## 计算每位用户的消费金额df1 = df.groupby('CustomerID').agg({'Amount':sum,'InvoiceDate':[pd.Series.nunique,'max']})df1.columns = df1.columns.droplevel()df1.columns = ['Amount','Frequency','Time']df1['Amount'] = df1['Amount'].map(lambda x:round(x,2))## 时间类型处理df1['Time'] = pd.to_datetime(df1['Time'],format='%Y-%m-%d %H:%M:%S')##from datetime import datetimet = datetime.strptime('2011-12-10',"%Y-%m-%d")df1['Last_purchase'] = df1['Time'].map(lambda x:(t - x).days)## 提取为RFM表df_rfm = df1[['Last_purchase','Frequency','Amount']]df_rfm.columns = ['R','F','M']## RFM级别划分Step1## 若数值越小,表示级别越高df_rfm['R_level'] = pd.cut(df_rfm['R'],bins=[0,65,130,195,260,325,390],labels=[1,2,3,4,5,6],right=False)df_rfm['F_level'] = pd.cut(df_rfm['F'],bins=[0,10,20,50,100,175,250],labels=[6,5,4,3,2,1],right=False)df_rfm['M_level'] = pd.cut(df_rfm['M'],bins=[0,28,280,2800,28000,145000,285000],labels=[6,5,4,3,2,1],right=False)## RFM级别划分Step2df_rfm['R_level'] = df_rfm['R_level'].map(lambda x:'高' if x < df_rfm['R_level'].astype(int).mean() else '低')df_rfm['F_level'] = df_rfm['F_level'].map(lambda x:'高' if x < df_rfm['F_level'].astype(int).mean() else '低')df_rfm['M_level'] = df_rfm['M_level'].map(lambda x:'高' if x < df_rfm['M_level'].astype(int).mean() else '低')## 客户类型映射def mapping(x): if x=='高高高': return '高价值客户' elif x=='高低高': return '重点深耕客户' elif x=='低高高': return '重点唤回客户' elif x=='低低高': return '重点挽留客户' elif x=='高高低': return '潜力客户' elif x=='高低低': return '新客户' elif x=='低高低': return '一般保持客户' else: return '流失客户'## RFM级别划分Step3df_rfm['Score'] = df_rfm['R_level']+df_rfm['F_level']+df_rfm['M_level']df_rfm['user_type'] = df_rfm['Score'].map(lambda x:mapping(x))label = df_rfm['user_type'].value_counts().index.tolist()value = df_rfm['user_type'].value_counts().values.tolist()pie=( Pie(init_opts=opts.InitOpts(theme='light',height='350px')) .add("",[list(z) for z in zip(label, value)],radius=['0%','55%']) .set_series_opts( label_opts=opts.LabelOpts( formatter="{b}: {c}位,占比为{d}%" ) ) .set_global_opts( title_opts=opts.TitleOpts( title='客户价值类型分布情况', subtitle=' 2010-12-1 ~ 2011-12-9', pos_left='center' ), legend_opts=opts.LegendOpts( is_show=False ) ))pie.render_notebook()输出结果:
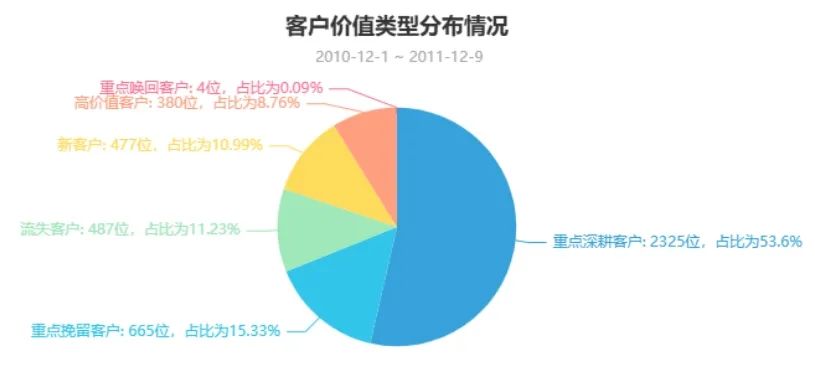
结论:
通过RFM 模型人工的对客户类型进行划分,占比最大的是重点深耕客户 ,其次是重点挽留客户 ,占比最少的是重点唤回客户。
def trans_data(type_): data_y = [] tmp = df_rfm[df_rfm['user_type'] == type_] data_y.append(tmp['R'].tolist()) data_y.append(tmp['F'].tolist()) data_y.append(tmp['M'].tolist()) return data_ytag = df_rfm['user_type'].unique().tolist()def trans_data(rfm): for item in df_rfm['user_type']: if item == tag[0]: s1 = df_rfm[df_rfm['user_type'] == item][rfm].tolist() elif item == tag[1]: s2 = df_rfm[df_rfm['user_type'] == item][rfm].tolist() elif item == tag[2]: s3 = df_rfm[df_rfm['user_type'] == item][rfm].tolist() elif item == tag[3]: s4 = df_rfm[df_rfm['user_type'] == item][rfm].tolist() elif item == tag[4]: s5 = df_rfm[df_rfm['user_type'] == item][rfm].tolist() else: s6 = df_rfm[df_rfm['user_type'] == item][rfm].tolist() datay = [] datay.append(s1) datay.append(s2) datay.append(s3) datay.append(s4) datay.append(s5) datay.append(s6) return dataydata_R = trans_data('R')data_F = trans_data('F')data_M = trans_data('M')def draw_boxplot(ydata,title_): boxplot = (Boxplot( init_opts=opts.InitOpts( width='980px',height='300px'))) boxplot.add_xaxis(tag) boxplot.add_yaxis('',boxplot.prepare_data(ydata)) boxplot.set_global_opts( title_opts=opts.TitleOpts( title='各类客户' + title_, subtitle='统计时间:2011-12-15', pos_left='center' ), yaxis_opts=opts.AxisOpts( axisline_opts=opts.AxisLineOpts( is_show=False ), axistick_opts=opts.AxisTickOpts( is_show=False ) ), )
boxplot.reversal_axis() return boxplotboxplot1 = draw_boxplot(data_R,'平均最近一次购物据今天数(R)')boxplot2 = draw_boxplot(data_F,'平均购物频率(F)')boxplot3 = draw_boxplot(data_M,'购物消费总金额(M)')page = Page()page.add(boxplot1)page.add(boxplot2)page.add(boxplot3)page.render_notebook()输出结果:
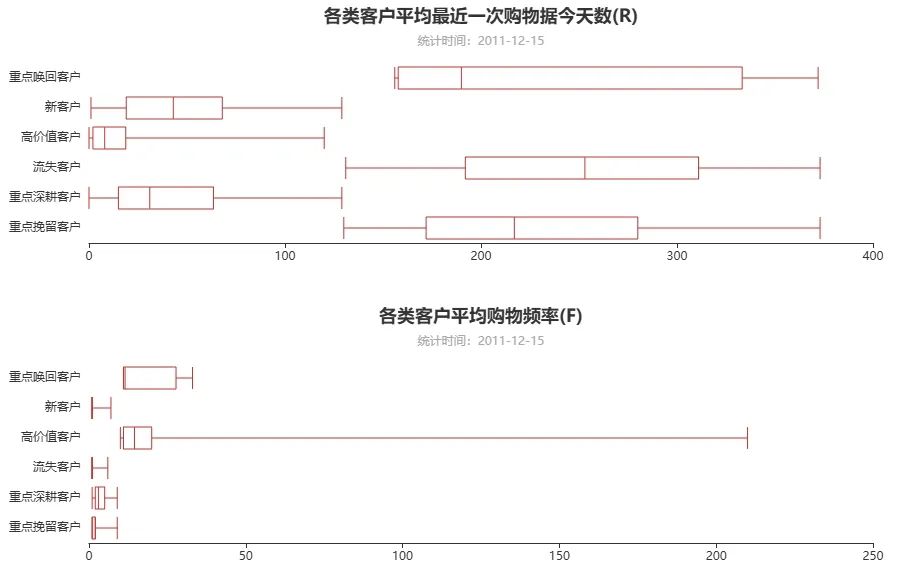
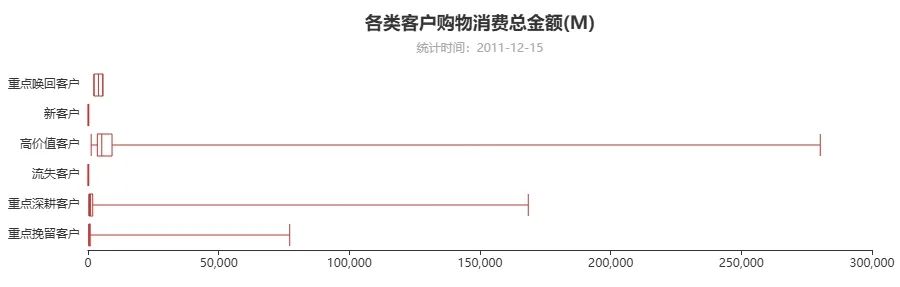
基于K-Means的聚类分析
from sklearn.preprocessing import MinMaxScalerfrom sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_score## 建模数据modle_data = df_rfm[['R','F','M']]## 数据标准化model_scaler = MinMaxScaler()data_scaled = model_scaler.fit_transform(modle_data)import matplotlib.pyplot as pltfrom scipy.spatial.distance import cdist
K = range(1, 10)meandistortions = []for k in K: kmeans = KMeans(n_clusters=k) kmeans.fit(data_scaled) meandistortions.append(sum(np.min(cdist(data_scaled, kmeans.cluster_centers_, 'euclidean'), axis=1))/data_scaled.shape[0])plt.plot(K, meandistortions, marker='o')plt.xlabel('K')plt.ylabel('Average distortion degree')plt.title('Use the Elbow Method to select the best K value')plt.show()输出结果:
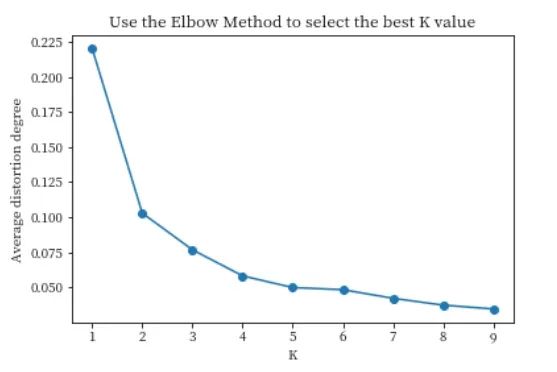
结论:
当K=4 时,平均畸变程度变化趋于平缓,此时改变K值对聚类效果影响不大,故确定聚类簇数为4。
聚类结果可视化
Kmeans = KMeans(n_clusters=4,max_iter=50)Kmeans.fit(data_scaled)cluster_labels_k = Kmeans.labels_df_rfm = df_rfm.reset_index()cluster_labels = pd.DataFrame(cluster_labels_k, columns=['clusters'])res = pd.concat((df_rfm, cluster_labels), axis=1)# 计算各个聚类类别内部最显著特征值cluster_features = []for line in range(4): label_data = res[res['clusters'] == line] part_data = label_data.iloc[:, 1:4] part_desc = part_data.describe().round(3) merge_data = part_desc.iloc[2, :] cluster_features.append(merge_data)df_clusters = pd.DataFrame(cluster_features)num_sets_max_min = model_scaler.fit_transform(df_clusters).tolist()c = ( Radar(init_opts=opts.InitOpts()) .add_schema( schema=[ opts.RadarIndicatorItem(name="R",max_=1.2), opts.RadarIndicatorItem(name="F", max_=1.2), opts.RadarIndicatorItem(name="M", max_=1.2), ], splitarea_opt=opts.SplitAreaOpts( is_show=True, areastyle_opts=opts.AreaStyleOpts(opacity=1) ), textstyle_opts=opts.TextStyleOpts(color="#000000"), ) .add( series_name="第1类客户", data=[num_sets_max_min[0]], areastyle_opts=opts.AreaStyleOpts(color="#FF0000",opacity=0.2), # 区域面积,透明度 ) .add( series_name="第2类客户", data=[num_sets_max_min[1]], areastyle_opts=opts.AreaStyleOpts(color="#00BFFF",opacity=0.2), # 区域面积,透明度 ) .add( series_name="第3类客户", data=[num_sets_max_min[2]], areastyle_opts=opts.AreaStyleOpts(color="#00FF7F",opacity=0.2), # 区域面积,透明度 ) .add( series_name="第4类客户", data=[num_sets_max_min[3]], areastyle_opts=opts.AreaStyleOpts(color="#007F7F",opacity=0.2), # 区域面积,透明度 ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) .set_global_opts( title_opts=opts.TitleOpts(title="各聚类类别显著特征对比"), ))c.render_notebook()输出结果:
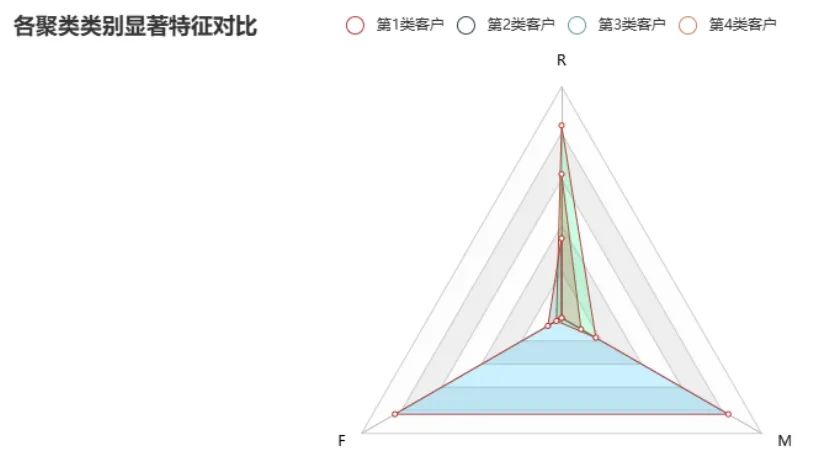
结论:
**1、第1类客户:**该类客户上一次购物距今间隔较长,购物频率为0,且购物总金额较少,为典型的流失客户。
**2、第2类客户:**该类客户上一次购物距今间隔为0,购物频率很高,且花费总金额很大,为典型的高价值客户。
**3、第3类客户:**该类客户与第1类客户有很多相似的地方,不同之处在于该类客户仍有购物次数,但不高,为典型的重要挽回客户。
**4、第4类客户:**该类客户上一次购物距今间隔较短,购物频率较低,且花费总金额为0,可能为新客户。