随着ChatGPT引领的大模型热潮,国内的公司开始相继投入研发自己的人工智能大模型,截止到2023年10月,国产公司的大模型有近百个,包括一些通用大模型,比如百度的文心一言,也有特定领域的专用大模型,比如蚂蚁金服的CodeFuse,京东的言犀等。
国内的大模型尚处于百花齐放的状态。
而随着GPT的一路爆火,国内大模型的开源生态也开始火热。各大商业机构和科研组织都在不断发布自己的大模型产品和成果。当然,国产的商业产品也很多,但因为缺少模型细节,实在不好细究。
今天来简单分析当前国产开源大模型的生态发展情况。数据来自DataLearnerAI,统计的开源模型主要包括机构自己训练开源的模型,并不包括所有种类和一些已经不更新的模型。
01
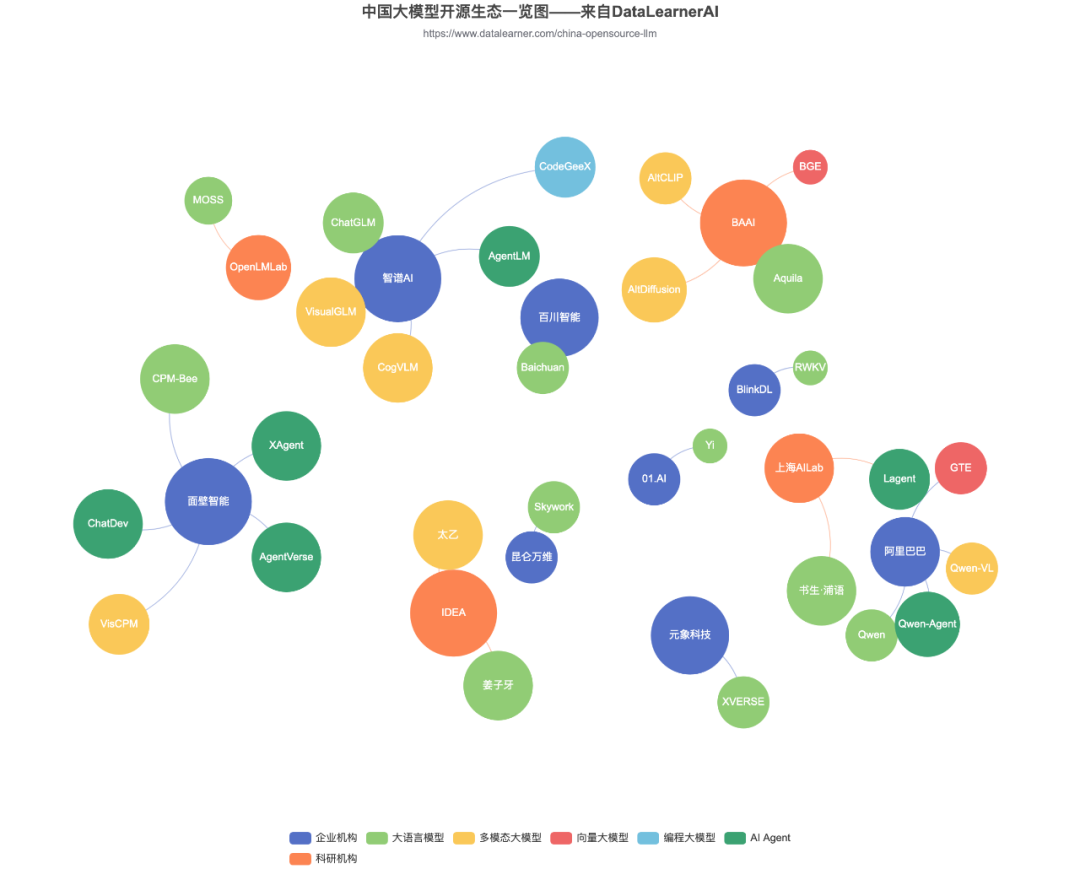
国产开源大模型的发布者
从国产开源大模型的发布者来看,主要包括二类:
-
企业机构:为了获得商业影响力而开源的模型,如智谱AI开源的ChatGLM系列。
-
科研机构:主要展示最新的科研成果,如北京智源人工智能研究院发布的Aquila系列大模型。
02
国产开源大模型的类型
国产开源大模型的数量很多,类型也很丰富,包括_大语言模型__、多模态大模型 、向量大模型、__编程大模型__和__AI Agent框架(模型)_几类。
不同机构的模型丰富程度不同。
智谱AI、阿里巴巴的开源大模型都较为丰富,都开源了四种大模型。
具体来看,智谱AI开源的大模型包括:
-
大语言模型ChatGLM系列
-
多模态大模型CogVLM
-
Agent大模型AgentLM
-
编程大模型CodeGeeX
具体来看,阿里巴巴的开源大模型包括:
-
大语言模型Qwen
-
多模态大模型Qwen-VL
-
向量大模型GTE
-
Agent大模型Qwen-Agent
其它大多数企业或者机构开源的模型都是1-3类左右。
特别地,
-
智谱AI是目前唯一开源了编程大模型的机构;
-
开源向量大模型的机构只有北京智源人工智能研究院(BGE)和阿里巴巴(GTE)两家;
-
面壁智能(ModelBest)开源了较多的AI Agent模型和框架,如AgentVerse、XAgent等。
03
国产开源大模型的参数规模
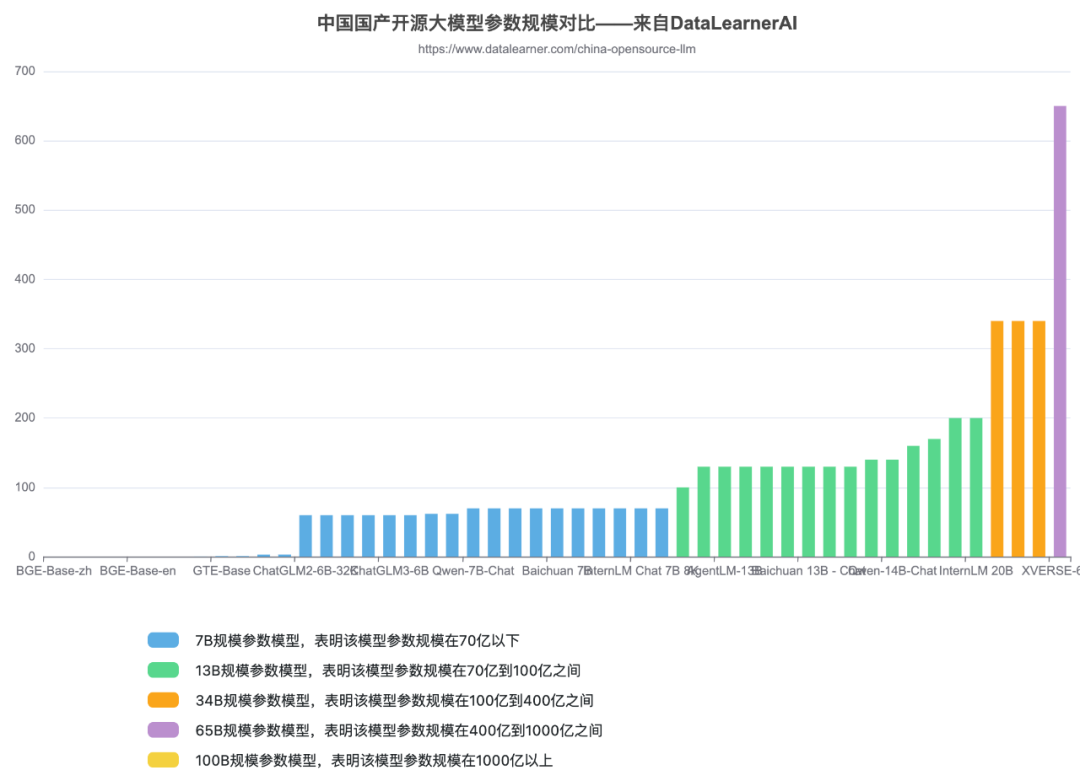
将模型开源的参数规模分为五类:
-
7B规模参数模型,表明该模型参数规模在70亿以下
-
13B规模参数模型,表明该模型参数规模在70亿到100亿之间
-
34B规模参数模型,表明该模型参数规模在100亿到400亿之间
-
65B规模参数模型,表明该模型参数规模在400亿到1000亿之间
-
100B规模参数模型,表明该模型参数规模在1000亿以上
智谱AI 最早开源的模型是ChatGLM系列,参数规模是60-70亿左右,之后大多数的开源大模型的参数量都在这个范围。
Meta 的开源大模型LLaMA1 的最大参数规模是650亿,LLaMA2是700亿。
经过一段时间的发展,国内340亿参数规模的模型分别有2个:北京智源的Aquila-34b 、李开复零一万物开源的Yi-34b(包括200K的版本)。
目前国产开源大模型的参数规模终于提高到了650亿规模,如元象科技发布的XVERSE-65B。
04
国产开源大模型的测评结果
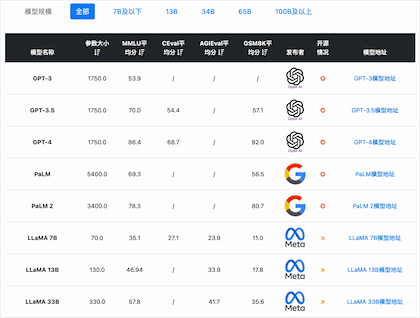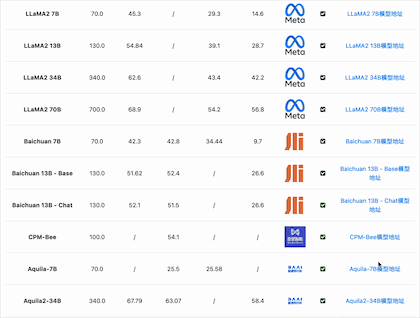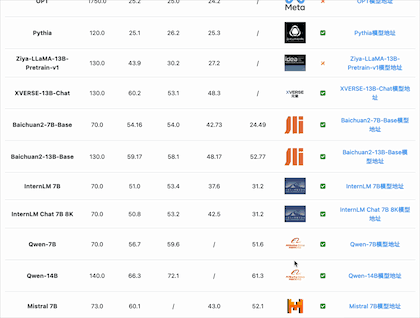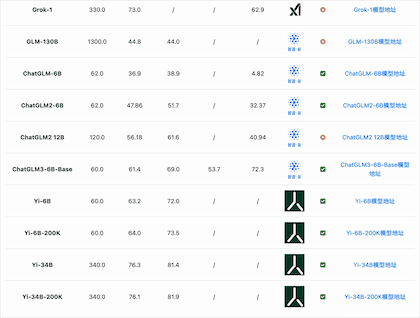
在综合能力评测上,选择4个评测基准来看看国产开源模型的能力如何。
-
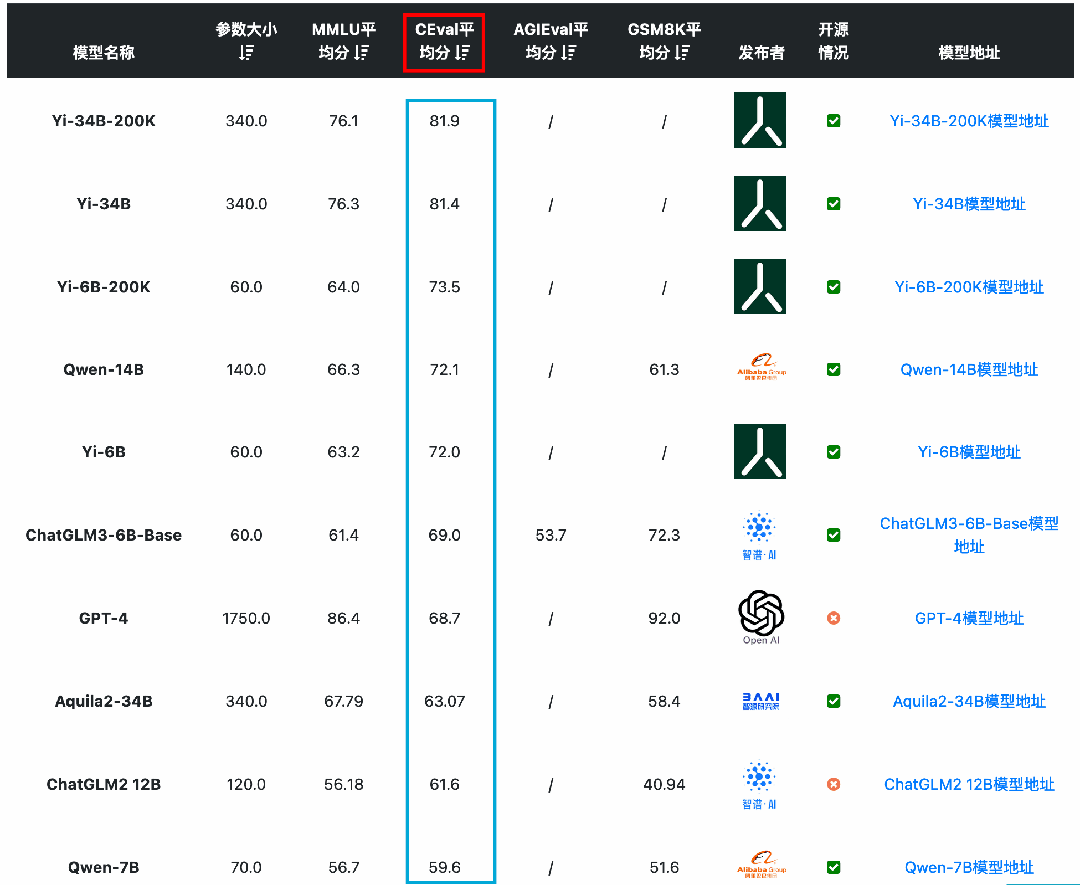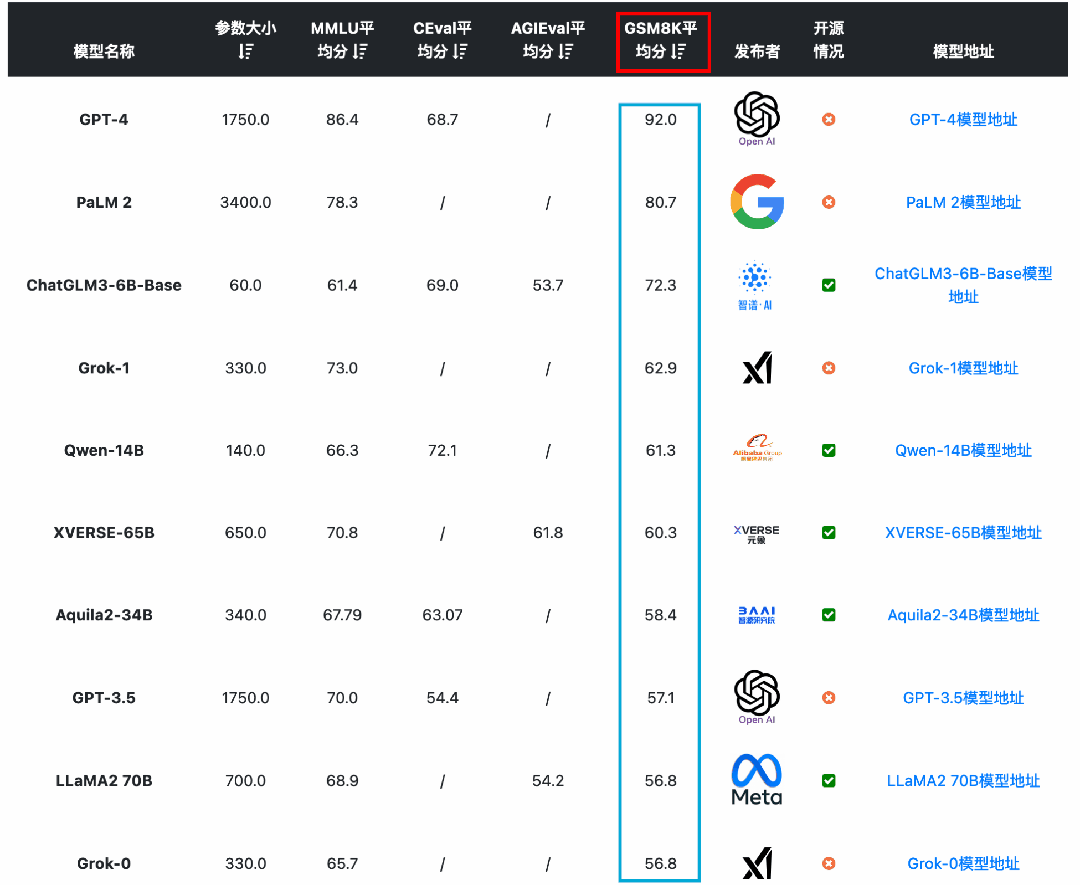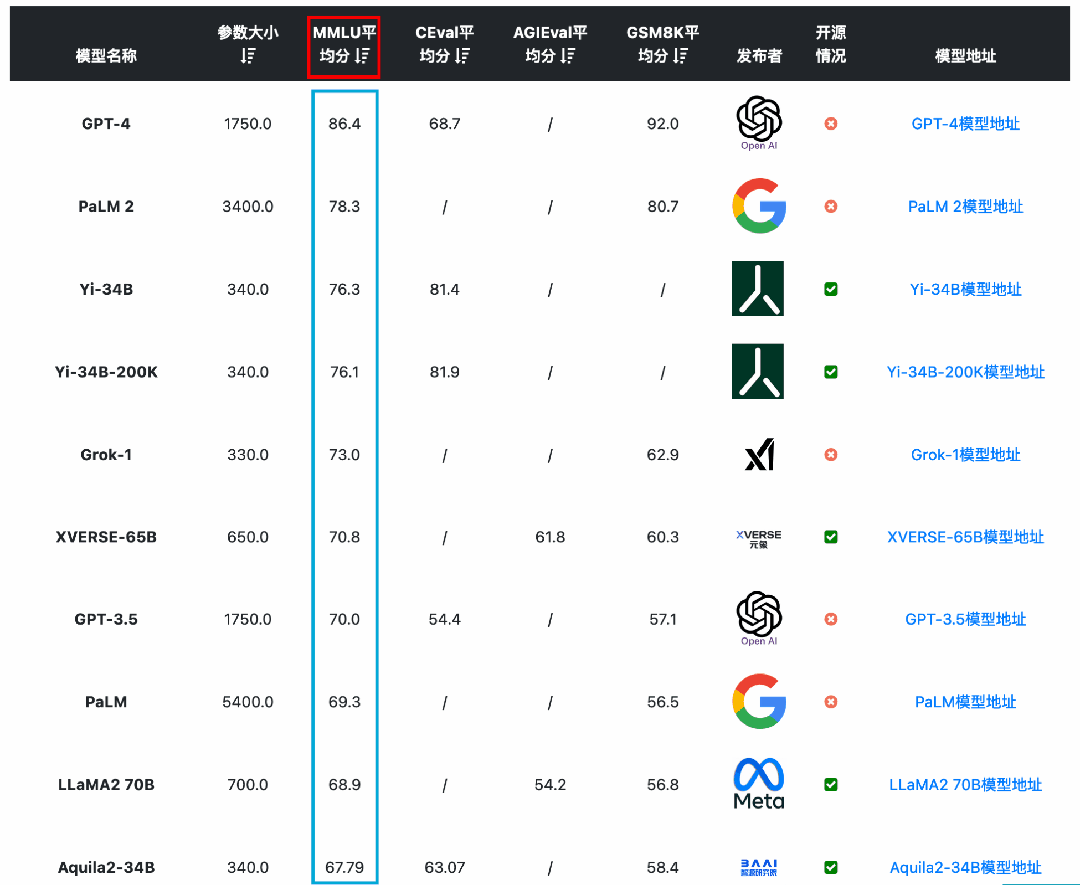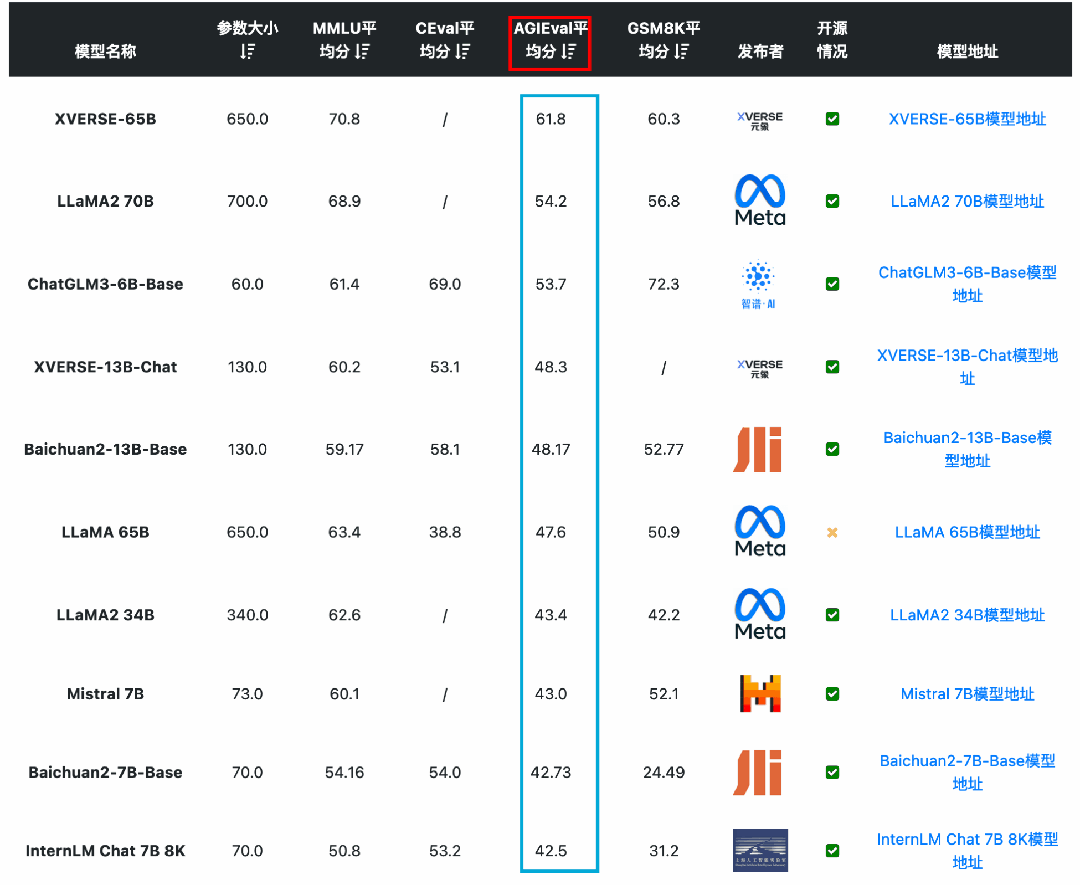
从MMLU(大模型语义理解能力)来看,国产开源模型的能力已经很优秀。李开复零一万物开源的Yi-34B模型的MMLU得分已经超过GPT-3.5,得分76.3,仅次于闭源的GPT-4和PaLM2模型。
-
从GSM8K(数学逻辑能力)来看,国产开源模型的能力也能很强悍。智谱AI的ChatGLM3-6B-Base模型以60多亿参数规模的结果超过了GPT-3.5、Qwen-14B等知名模型,排名仅次于GPT-4和PaLM2。
-
从C-Eval(大模型中文理解能力)来看,国产开源模型的能力优势更是明显。李开复零一万物开源的Yi-34B模型的C-Eval得分81.9,通义千问Qwen-14B得分72.1,ChatGLM3-6B得分69.0,优于GPT-4(68.7)。
-
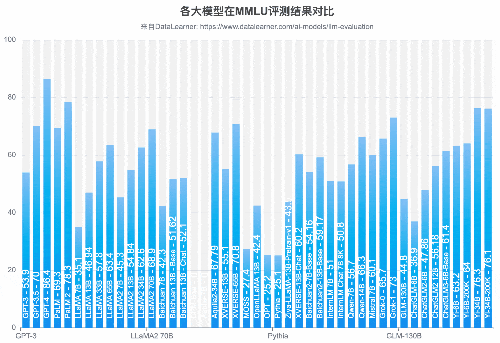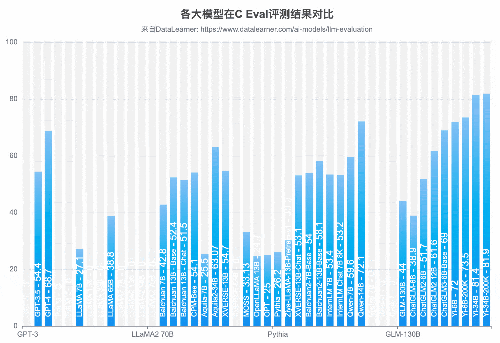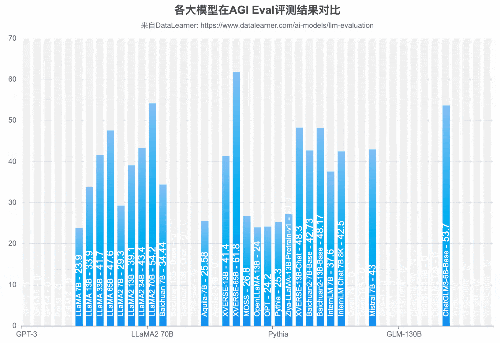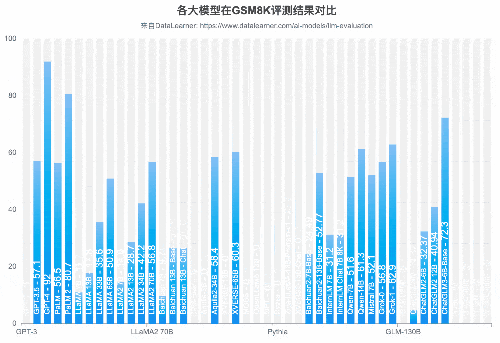
从AGI Eval(大模型在人类认知和解决问题的一般能力)来看,国产开源模型的能力也很强。元象科技发布的XVERSE-65B得分61.8位列第一,其次是LLaMA2-70B得分54.2,第三名是ChatGLM3-6B得分53.7。
MMLU
MMLU:全称Massive Multitask Language Understanding,是一种针对大模型的语言理解能力的测评,是目前最著名的大模型语义理解测评之一,由UC Berkeley大学的研究人员在2020年9月推出。该测试涵盖57项任务,包括初等数学、美国历史、计算机科学、法律等。任务涵盖的知识很广泛,语言是英文,用以评测大模型基本的知识覆盖范围和理解能力。论文地址:https://arxiv.org/abs/2009.03300
C-Eval
C-Eval:C-Eval 是一个全面的中文基础模型评估套件。由上海交通大学、清华大学和匹兹堡大学研究人员在2023年5月份联合推出,它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别。用以评测大模型中文理解能力。论文地址:https://arxiv.org/abs/2305.08322
AGI Eval
AGI Eval:微软发布的大模型基础能力评测基准,在2023年4月推出,主要评测大模型在人类认知和解决问题的一般能力,涵盖全球20种面向普通人类考生的官方、公共和高标准录取和资格考试,包含中英文数据。因此,该测试更加倾向于人类考试结果,涵盖了中英文,论文地址:https://arxiv.org/abs/2304.06364
GSM8K
GSM8K:OpenAI发布的大模型数学推理能力评测基准,涵盖了8500个中学水平的高质量数学题数据集。数据集比之前的数学文字题数据集规模更大,语言更具多样性,题目也更具挑战性。该项测试在2021年10月份发布,至今仍然是非常困难的一种测试基准。论文地址:https://arxiv.org/abs/2110.14168
在大模型编程能力评测上,选择的评测基准包括2个:
Human Eval
HumanEval是一个用于评估代码生成模型性能的数据集,由OpenAI在2021年推出。这个数据集包含164个手工编写的编程问题,每个问题都包括一个函数签名、文档字符串(docstring)、函数体以及几个单元测试。这些问题涵盖了语言理解、推理、算法和简单数学等方面。这个数据集的一个重要特点是,它不仅仅依赖于代码的语法正确性,还依赖于功能正确性。也就是说,生成的代码需要通过所有相关的单元测试才能被认为是正确的。这种方法更接近于实际编程任务,因为在实际编程中,代码不仅需要语法正确,还需要能够正确执行预定任务。结果通过pass@k表示,其中k表示模型一次性生成多少种不同的答案中,至少包含1个正确的结果。例如Pass@1就是只生成一个答案,准确的比例。如果是Pass@10表示一次性生成10个答案其中至少有一个准确的比例。目前,收集的包含Pass@1、Pass@10和Pass@100
MBPP
MBPP(Mostly Basic Programming Problems)是一个数据集,主要包含了974个短小的Python函数问题,由谷歌在2021年推出,这些问题主要是为初级程序员设计的。数据集还包含了这些程序的文本描述和用于检查功能正确性的测试用例。结果通过pass@k表示,其中k表示模型一次性生成多少种不同的答案中,至少包含1个正确的结果。例如Pass@1就是只生成一个答案,准确的比例。如果是Pass@10表示一次性生成10个答案其中至少有一个准确的比例。目前,收集的包含Pass@1、Pass@10和Pass@100
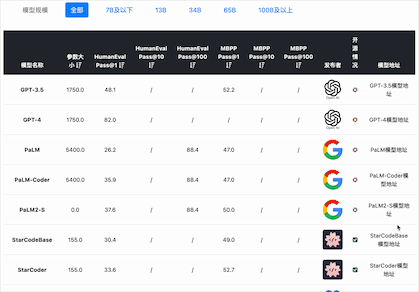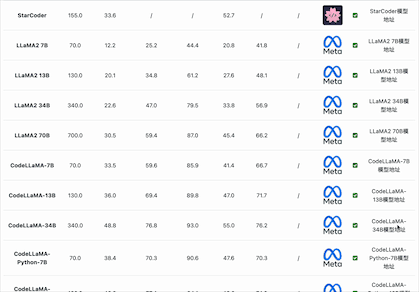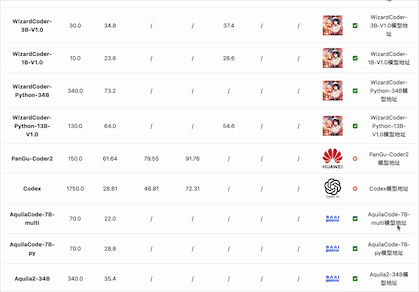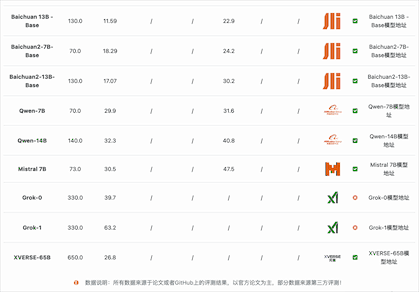
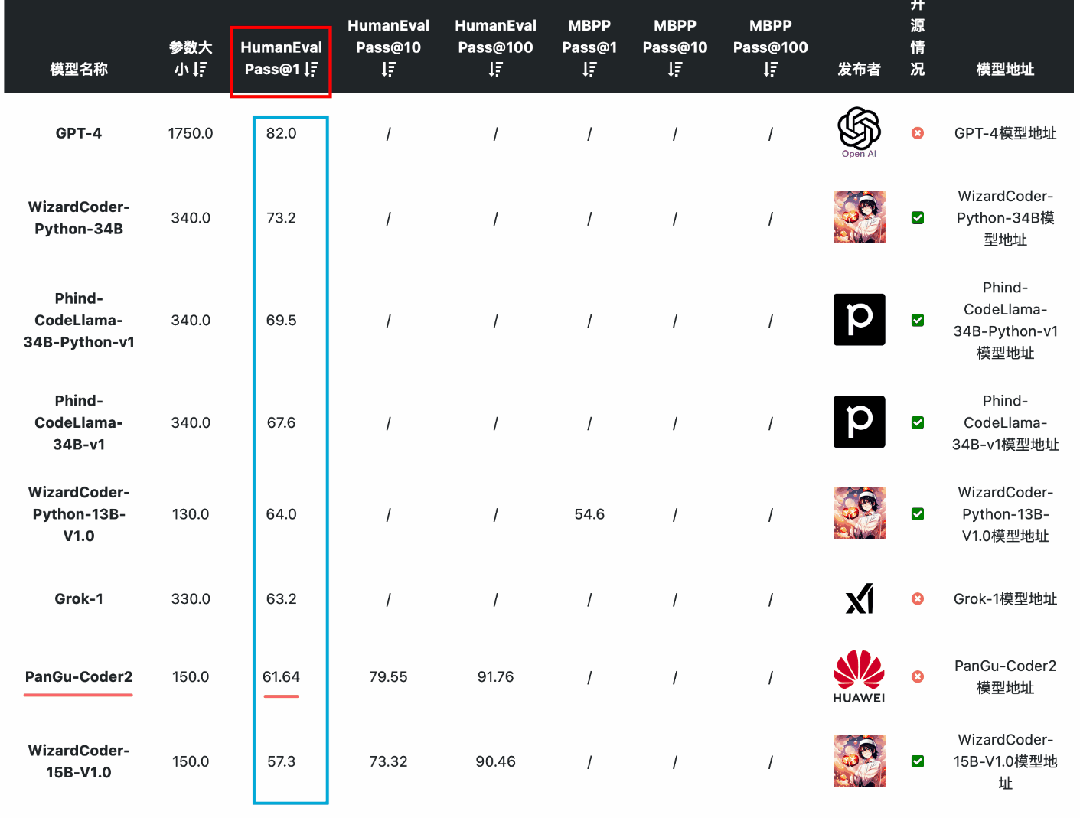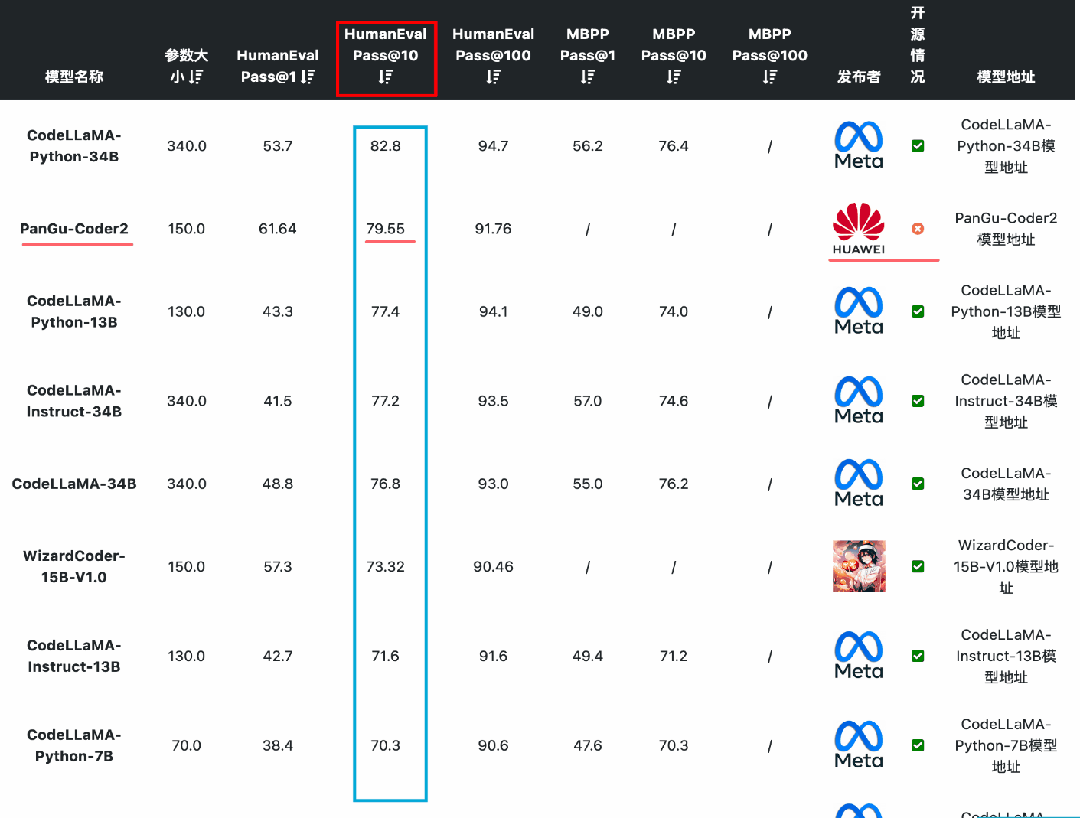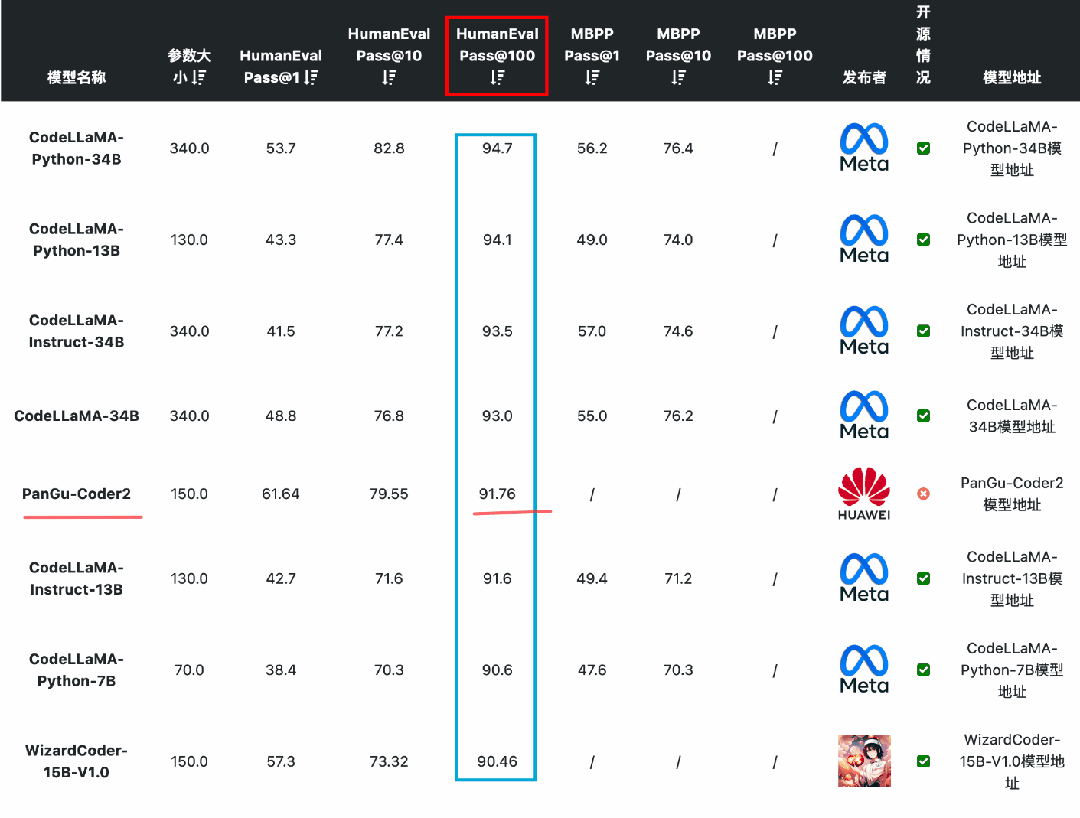
在编码能力上,国产开源模型的表现较差。按照HumanEval Pass@ 1的得分结果看,除了闭源的PanGu-Coder2的得分超过了60分(排名第7),其它国产开源模型都没怎么公布或者排名靠后。而在MBPP的得分上国内开源和闭源模型更是没能进入前十的榜单,排名均靠后。
05
国产开源大模型总结
从模型的发布数量、参数规模、模型种类来看,国产开源模型的生态已经比较不错。但是,我们也能清楚看到一些不足和未来值得改进的方向:
-
国产开源大模型的参数分布比较集中,其中超过200亿参数规模的数量较少;
-
国产开源大模型的类型多样性不足,比如编程大模型、向量大模型等很少发布开源;
-
国产开源大模型的编程能力普遍不足,还有待加强。