文章目录
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎人工智能和前端开发。
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
1、简介
GRU:Gated Recurrent Unit
可以先复习一下之前的内容:
循环神经网络RNN:https://xzl-tech.blog.csdn.net/article/details/140940642
LSTM:https://xzl-tech.blog.csdn.net/article/details/140940759
概念:
GRU是另一种RNN变体,它简化了LSTM的结构,减少了计算复杂度,同时保持了处理长时依赖的能力。
结构:
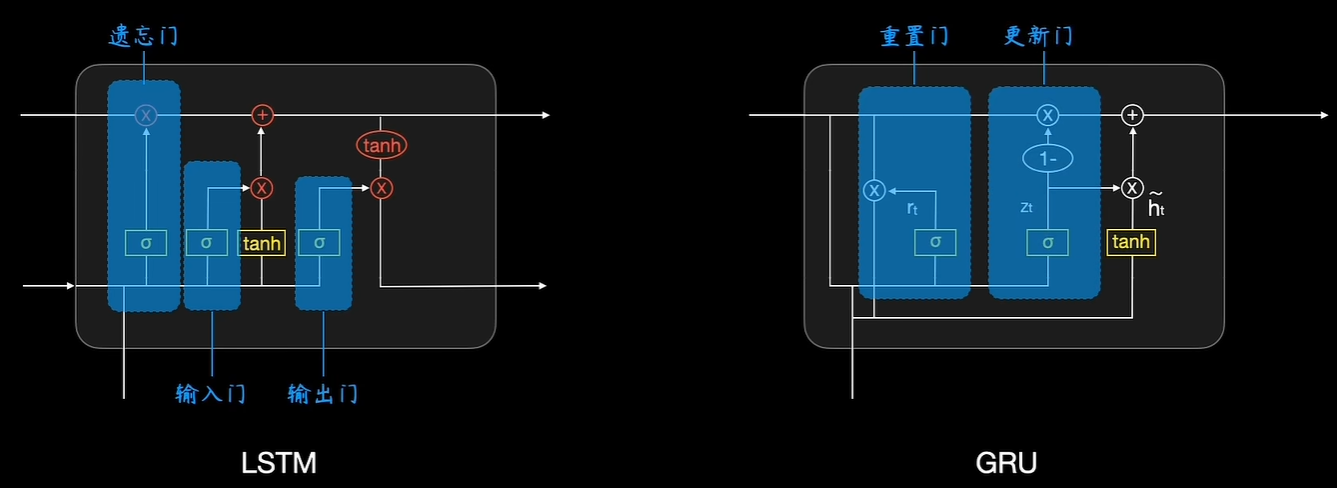
GRU将LSTM的输入门和遗忘门 合并为一个 更新门(Update Gate) ,并用一个 重置门(Reset Gate) 来决定隐藏状态如何结合新输入。
2、门控机制
- 门控机制的基本思想是使用"门"来控制信息在网络中的流动。
每个门都是通过神经网络层计算出来的权重向量,其值通常在0到1之间。- 不同的门在不同
时间步上控制信息的选择、遗忘和更新。 - 这些门是通过可学习的参数在训练过程中自动调整的。
3、公式
GRU在每个时间步的更新过程可以用以下公式描述:
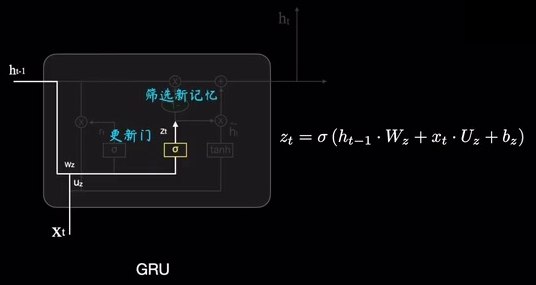
- 更新门 : z t = σ ( W z ⋅ h t − 1 , x t + b z ) z_t = \sigma(W_z \cdot h_{t-1}, x_t+b_z) zt=σ(Wz⋅ht−1,xt+bz)
- z t z_t zt 表示更新门的输出。
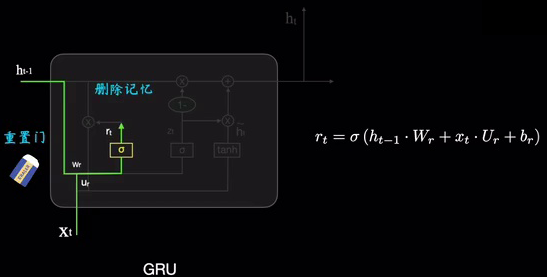
- 重置门 : r t = σ ( W r ⋅ h t − 1 , x t + b r ) r_t = \sigma(W_r \cdot h_{t-1}, x_t+b_r) rt=σ(Wr⋅ht−1,xt+br)
- r t r_t rt 表示重置门的输出。
- 候选隐藏状态 : h ~ t = tanh ( W h ⋅ r t ∗ h t − 1 , x t ) \tilde{h}_t = \tanh(W_h \cdot r_t \\ast h_{t-1}, x_t) h~t=tanh(Wh⋅rt∗ht−1,xt)
- h ~ t \tilde{h}_t h~t 表示候选的隐藏状态。
- 隐藏状态更新 : h t = ( 1 − z t ) ∗ h t − 1 + z t ∗ h ~ t h_t = (1 - z_t) \ast h_{t-1} + z_t \ast \tilde{h}_t ht=(1−zt)∗ht−1+zt∗h~t
- h t h_t ht 是当前时间步的隐藏状态。
回顾一下
tanh函数: f ( x ) = 1 − e − 2 x 1 + e − 2 x f(x) = \frac{1 - e^{-2x}}{1 + e^{-2x}} f(x)=1+e−2x1−e−2x
4、图解GRU
4.1、重置门和更新门
GRU实际上影藏了记忆链条 h t h_t ht:
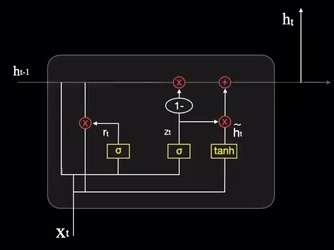
重置门的作用跟之前的遗忘门类似,都是充当橡皮擦的作用:
更新门则是筛选新的记忆:
4.2、候选隐藏状态和隐藏状态⭐
候选隐藏状态则是在前一时刻隐藏状态之上,擦除了一定记忆之后,融合进当前的输入 x t x_t xt,然后经过tanh函数临时记录下来:
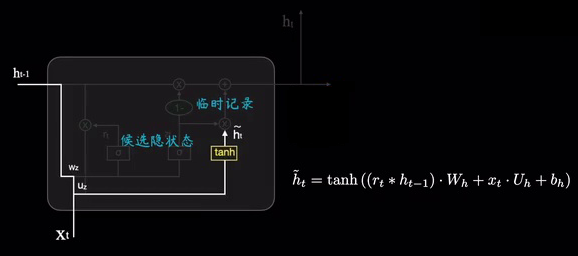
更新门在当前的候选隐状态 h ~ t \tilde{h}t h~t和前一时刻的候选隐状态 h ~ t − 1 \tilde{h}{t-1} h~t−1之间取舍,组合之后输出当前的隐藏状态 h t h_t ht,然后网络进行更新,即融入了原有的"记忆"中,相当于阅后即焚:
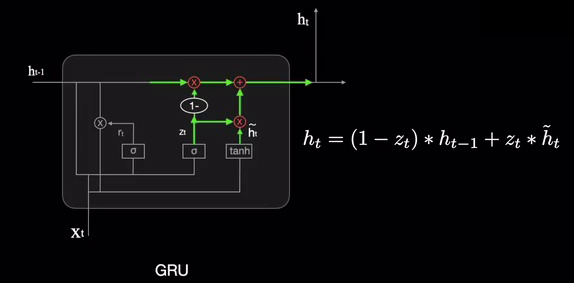
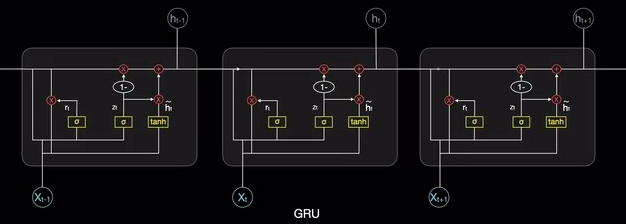
经过这样不断的模块迭代,就是一直在短期记忆和长期记忆之间融合更新,而且存储的信息不需要像LSTM那么多,更加简单高效:
5、LSTM与GRU的对比
- 复杂性 :
- LSTM更复杂,参数更多。
- GRU较为简洁,参数更少,训练速度更快。
- 性能 :
- 两者在处理长时依赖性任务时表现都很优异,具体选择往往取决于数据集和计算资源。
- 在一些特定任务和数据集上,GRU可能比LSTM表现更好,尤其是在计算资源有限的情况下。
- 使用场景 :
- 对于需要更强的长期记忆和复杂信息流动的任务,LSTM可能更合适。
- 对于实时性要求较高或者模型简单性要求较高的任务,GRU可能更具优势。
LSTM和GRU是两种非常成功的RNN变体,通过改进信息传递机制,有效解决了传统RNN在处理长序列数据时的局限性。
它们在自然语言处理、语音识别和时间序列预测等领域得到广泛应用。
6、应用
RNN及其变体广泛应用于以下领域:
- 自然语言处理:如语言模型、机器翻译和文本生成。
- 语音识别:将音频序列转换为文本。
- 时间序列预测:如股票价格预测和天气预报。
- 视频分析:从视频帧中提取时间信息。
7、训练技巧
- 梯度裁剪:限制梯度的大小以防止梯度爆炸。
- 正则化:使用Dropout等技术防止过拟合。
- 预训练和转移学习:利用大规模预训练模型微调特定任务。
RNN模型在序列数据处理中具有强大的表现力和适应能力,但也面临一些挑战。通过使用LSTM、GRU等改进模型,结合适当的训练技巧,能够有效地应用于各种实际问题。