初始的探索
在NLP领域,早期的模型如 LSTM 和 GRU 在处理序列数据时取得了一定的成功。但随着数据量和复杂性的增加,这些模型开始显得力不从心。
Transformer的诞生
Transformer 模型的提出,它通过自注意力(Self-Attention)机制,显著提高了处理长距离依赖关系的能力,这一架构成为后续大语言模型的基石。
模型的革新和扩展
随后,BERT (Bidirectional Encoder Representations from Transformers) 的出现改变了游戏规则,它通过双向训练的方式,大大提升了上下文理解的深度。BERT 及其变种如 RoBERTa 和 ALBERT 推动了 NLP 在多个任务上的性能提升。
规模的扩张
GPT 系列(尤其是 GPT-3)的开发为LLM的规模设立了新的标杆。GPT-3 拥有1750 亿个参数,能够执行写作、翻译、摘要、问答等复杂任务,而无需特定任务的训练。
成就的显现
大语言模型的成就不仅是在学术领域,它们还成功商业化并广泛应用于各个行业。LLM开始在医疗诊断、法律文件分析、金融市场预测等领域中扮演重要角色。在教育领域,LLM被用于辅助写作和提供个性化学习建议,让教育资源更加个性化和可访问。
技术的普及
伴随着这些成就,LLM 的技术也不断普及,API 的开放使得即使非专业人士也能轻松地集成和利用强大的 NLP 功能,这种易于访问的转变,进一步推动了LLM在各种应用中的创新和实践。
影响的深远
大语言模型的影响力已经渗透到我们生活的方方面面,从简化的用户界面到智能化的客户服务,从内容创建到自动化的决策支持,LLM 已经逐步成为现代技术不可或缺的一部分。这些成就标志着LLM的一个时代的结束和新时代的开始。随着技术的不断进步,我们对LLM的期待也在升级。下一阶段的LLM将如何发展,将是一个充满挑战和机遇的话题。

挑战与机遇
复合性挑战
资源与伦理的双重压力
训练和运行大型语言模型所需的庞大计算资源引发了经济和环境伦理的考量。最先进的大语言模型需要大量的计算资源进行训练,这不仅涉及巨大的经济成本,还有能源消耗和随之而来的环境影响。这要求业界和学术界共同探索更高效的模型架构,同时在模型设计和训练过程中融入可持续性的原则。
数据问题的多维度处理
数据偏见、隐私保护和安全性构成了一系列相互关联的问题。数据集可能包含偏见,从而在模型的输出中再现这些偏见。同时如何确保这些数据不被滥用,并保护用户的隐私,是 LLM 发展中必须解决的问题这不仅涉及技术层面的改进,如开发新的数据匿名化技术,而且还涉及到政策和治理层面,即如何制定合理的数据使用规范。
技术透明度与责任
随着 LLMs 在敏感领域的应用日益增加,其决策逻辑的不透明性引起了公众的担忧。尽管LLM在多项任务上表现出色,但它们的决策过程往往是黑箱式的,缺乏可解释性。这在一些高风险领域(如医疗或司法)尤为重要,因为错误的决策可能会有严重的后果。这要求开发新的解释性工具和框架,以便用户和监管者能够理解并信任 AI 系统的决策。
综合性机遇
技术跨界和多领域合作
面对效率和伦理挑战,新的模型优化技术,如参数共享、模型剪枝等,以及跨界技术例如量子计算的融入,可能为 LLMs 的发展带来革命性的变革。LLMs 的进步为跨学科研究提供了肥沃的土壤。例如,与心理学家合作可以提升模型对人类语言的理解;与社会学家合作可以帮助模型更好地处理社会性偏见问题。
责任感与创造力的共存
随着隐私保护技术和可解释 AI 的发展,LLMs 有机会在保障用户隐私和提升透明度的同时,为各个行业提供创新的解决方案,从智能化的客户服务到个性化的教育体验。新兴的隐私保护技术,如差分隐私、联邦学习等,为训练更加安全的 LLM 提供了可能。这些技术的应用有助于保护训练数据中的敏感信息,同时仍能利用数据来训练高效的模型。通过整合强化学习,未来的 LLM 可能会更加灵活地适应新环境和任务,实现真正的连续学习。这种自适应能力将使模型在与人类互动时更加智能和个性化。
趋势与展望
企业级数据分析

在组织数据的动态世界中,我们正在见证一个革命性时代的来临,其标志就是将大型语言模型(LLM)整合到数据管理和分析工作流程中。这一跨越未来十年的变革之旅有望重新定义我们与业务数据的交互,将复杂性与以用户为中心的体验融为一体。
想象一下在这样一个环境中,在应用程序中提出的业务数据问题会被无缝转化为数据查询,在正确的数据上执行,并在同一界面中以可视化故事的形式呈现结果。这种先进的交互方式预示着一个数据可访问性和可用性的新时代的到来。
对于大多数组织来说,不太可能马上就能实现,主要原因有 2 个:
- 数据库和仓库中存储的业务数据大多缺少语义;
- 我们必须建立机制,以了解在正确的组织业务背景下提出的问题,并管理这些问题的执行。
在中短期内改变数据消费者与 LLM 的互动方式
语义人工智能(Semantic AI)是大型语言模型和关系模型的结合,通过组织元数据和特定语境的训练语料库激活,将能够实现以下功能:
- 让数据环境具有语义并与定义保持一致,从而为生成式人工智能的实施做好准备;
- 根据企业的业务背景来理解问题;
- 将问题映射到正确的内部或外部数据;
- 运行查询,并通过支持讲故事的决策智能叙述结果;
- 帮助用户在特定情况下进一步提出相关问题。
增强数据生产者的能力
LLM 对数据生产者的影响也将是变革性的。从近期到中期来看,预计数据工程师、分析师和数据运维人员将通过脚本编写、文档编制、测试、分步指南和管道创建等常规任务的自动化,大幅提高工作效率。这一演变还将通过重复数据删除和跨部门统一实践提高效率。
随着进一步发展,数据基础设施本身也将发生巨变,从僵化、预定义的模式转变为更加动态、自动化和灵活的实施,这与近年来商业智能的发展如出一辙。我们将不会看到重复或庞大的集成项目,而会看到智能结果缓存、工作流程自动化、自动实施重新调整和重复使用。
从 LLM 中获取价值
推动数据管理未来的 LLM 使用案例:
- 自动化文档:简化数据流程描述的创建。
- 增强的自动标记功能:提高数据分类的准确性,这是管理敏感信息的关键因素。
- 语义发现:使用户能够毫不费力地搜索数据元素,提高数据的可访问性和利用率。
在我们拥抱这些技术进步的同时,必须继续把重点放在挖掘有形价值上。将 LLM 纳入数据管理和分析是一种战略演变,而不仅仅是技术升级。它将彻底改变企业与数据的交互方式,让有洞察力的数据驱动决策更加直观,让所有人都能使用。这种模式的转变不仅仅是为了提高能力,而是要从根本上改变商业智能和分析的格局。
将 LLM 扩展到企业数据实践代表着一个战略拐点,预示着商业决策支持智能的新时代。这是一个从技术应用到战略转型的过程,重新定义了企业如何利用数据进行决策和创新。
RAG 的快速发展

RAG (Retrieval Augmented Generation) 是一个 AI 框架,用于从外部知识库检索事实,以基于最准确、最新的信息构建大语言模型 (LLM),并让用户深入了解 LLM 的生成过程。
像 ChatGPT 这样的 LLM 目前的发展已经相对成熟,跨越了生成式人工智能的门槛,可以与特定于业务的数据(如知识库和数据库)以及由此产生的用例相结合。不过 RAG 对企业和消费者的影响远远高于基础 LLM,将LLM 的能力与 RAG 的知识相结合,将为企业和消费者创造巨大的收入和生产效益。
0 代码系统
没有像 ChatGPT GPTs 这样的代码系统,适用于消费者和个人。随着对基于 RAG 的业务用例的需求激增,面向业务的"自定义 GPTs"将会处于领先位置。这些 0 代码系统允许日常非技术人员仅使用浏览器构建复杂而复杂的生成式 AI 功能,无需编码过程。
RAG API
随着 OpenAI Assistants API 的发布,该 API 具有一些非常有限的内置 RAG 和其他更复杂的 RAG API (如 CustomGPT API),企业可以毫不费力地使用自己的数据、网站内容和账户特定数据创建复杂的生成式 AI 聊天机器人功能和工作流程。
这些类型的项目曾经是复杂的、数月、数百万美元的项目,涉及大型软件开发团队。但现在,可以用极低的成本在一天内创建一个复杂的基于 RAG 的聊天机器人。
甚至还有一些 Streamlit 应用程序也能够以非常低的成本创建,周转时间很快。随着越来越多的开发人员开始了解这些 API 的强大功能,更多基于 RAG 的系统和工作流将开始出现。
工作流
现在一些云平台开始将基于 API 的工作流整合到他们的系统中。这些工作流让用户更容易地接触到账户级别的数据,并实现基于 RAG 的工作流程管理。
使用这些工作流,一些原本复杂的数据操作变得简单许多。例如,可以轻松捕获 HTML 表单的输入,并根据这些输入生成 PDF 文档。这项操作可以非常简单,但它在提高效率和减轻工作负担方面的潜力巨大。可以想象一下动态生成旅游行程单或发票 PDF 这样的任务,这通常需要某种生成型 AI 组件来实现。这种 AI 组件能够理解表单输入的内容,并根据预设的模板生成一个结构化的文档。不过生成 PDF 只是众多应用中的一个元素,任何一种工作流,其基本的数据流现在都可以通过生成型 AI 内容来增强。无论是生成定制报告、自动编写代码还是创建数据可视化,都有可能通过 API 工作流和 AI 结合实现。
私域 LLM (Self-Hosted LLM)

与 GPT-4 一样好的开源模型
阻碍很多企业一头扎进自托管 (Self-Hosted) 生态系统的最大因素之一是 API 模型比开源模型更好。这意味着更容易获得工作原型。然而,一旦我们得到一个与 GPT-4 一样好的开源模型,我们将看到向自托管的大规模转变。
有些人认为这不会发生,因为到这个时候我们将拥有 GPT-5,它会有更好的表现,然而在模型质量方面存在边际回报。企业只需要"足够好"的模型来解决他们的用例,而不是 AGI,目前的 GPT-4 就是这个阶段。
企业正在从 POC (Proof of Concept) 转向规模化
基于 API 的模型真正擅长的是快速创建演示,它们是了解 LLM 能够做什么并弄清楚它们是否能够解决业务问题的好方法,但是价格、速率限制和延迟差等原因是不可忽视的制约因素。很多企业的具体用例展示了巨大的商业价值
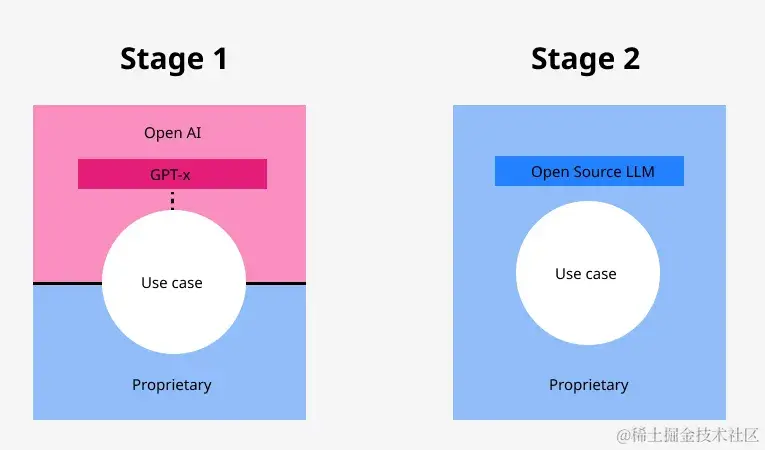
如果企业想要转型地采用 LLM,他们将需要大规模使用。在任何规模上,自托管 LLM 都比使用 API 服务便宜得多。此外,对于大多数用例,不需要像 GPT-4 这样的大型 LLM 来解决任务,通过使用更小的语言模型 (≤7B),可以节省大量成本。
部署模型的难度正在降低
企业被阻止自托管 LLM 的最大原因可能是因为它太难了。自托管时存在无数问题,从数百个模型选项中进行选择,获得足够的 GPU 访问权限,以及足够快地获得模型。这些问题之所以存在,很大程度上是由于该领域还不够成熟。自托管最佳实践会很快发布并验证,这将从根本上降低自托管语言模型所需的难度和技能,这也是企业采用自托管 LLM 的巨大加速器。
结语
随着我们对大语言模型(LLM)的理解越来越深刻,我们发现自己站在了人工智能发展的一个新的门槛上。这些模型不仅是技术上的壮举,也是人类知识与创造力的集大成者。从提升业务流程的效率到拓展教育的边界,从增强创新能力到改善人机交互,LLM 的潜力几乎无所不包。
然而,正如所有前沿技术一样,LLM的发展之路充满了挑战和责任。随着我们继续探索这些工具的可能性,有必要谨慎考虑它们对社会、伦理和人类价值的影响。我们必须聆听多样的声音,确保我们的技术进步不仅仅是一项科学的胜利,更是对公平、透明和包容原则的坚持。
在未来,我们期待着 LLM 能够解锁未知的潜力,推动人类进步到新的高度。但这一切都必须建立在对未来的深思熟虑和对过去的深刻理解之上。让我们共同努力,确保大型语言模型成为我们共同繁荣与智慧增长的工具,而不是另一个转瞬即逝的技术奇迹。在这个信息日益丰富、互联世界的新纪元,LLM不仅预示着技术的未来,更代表了我们对未来的希冀与承诺。