随着数据量的快速增长与用户需求的变化,数据库的管理与优化工作日益凸显其重要性。作为DBA及开发者,您是否曾面临以下挑战:
○ 分析场景下,在处理大规模数据的且耗时较长的查询是,常涉及海量数据的处理及复杂的计算,如何有效地实时监控其执行状态?
○ 面对线上多节点部署环境中的慢SQL问题时,如何判断是否存在分布式执行计划上的瓶颈?又如何精准定位是哪个长尾节点影响了整体执行效率?
○ 在分析SQL执行计划偏离预期的原因时,如何区分是由于查询时使用的SQL参数不具有代表性造成,还是统计信息不准确所导致?怎样判断?
相比于传统单机数据库,分布式数据库面对的场景更加复杂,涉及更多的链路,一条 SQL 的执行可能涉及到数十个节点的协同工作,如果慢 SQL 无法被及时解决,可能会导致正常请求被阻塞、CPU 负载飙升甚至影响整个集群的可用性。
作为原生分布式数据库,OceanBase 一直在努力提升数据库管理和运维效率、优化诊断和调优体验,本文将分享 OceanBase 对高效诊断数据库方面的实践和思考,包括:
○ 探讨在 AP 场景下面临的执行性能挑战,并介绍常用的诊断工具;
○ 通过案例分析展示如何利用 real-time plan monitor 进行分布式计划的诊断;
○ 思考如何简化和优化诊断调优过程,并介绍 OceanBase 实时 SQL 诊断的应用。
一、OceanBase AP 场景诊断实践
(一)AP 场景执行性能面临的挑战
在 AP(Analytical Processing,分析处理)场景下,每次执行通常涉及大量数据,需要复杂的多维数据建模,并依赖大规模并行能力来加速查询。
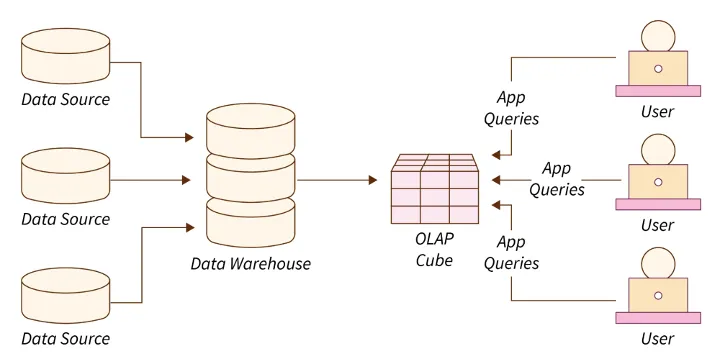
图 1:OLAP Process
在这种场景下,分布式数据库常见的性能问题主要包括以下几个方面:
1. 大规模数据扫描
许多分析查询需要处理大量数据,经常导致全表扫描或大范围数据扫描,进而造成高 I/O 和长响应时间。不合理的分区设计可能导致分区裁剪无效,使得查询范围扩大,导致扫描更多不必要的数据。在 OceanBase 数据库中,不同分区可能会分布在不同的节点上,因此跨分区查询要求系统能高效地跨节点甚至跨数据中心进行数据扫描。
2. 多表聚合和连接
○ 复杂聚合函数:在分析场景中频繁使用聚合函数(如 COUNT、SUM、AVG、MAX、MIN),在大数据集上执行会非常耗时。
○ GROUP BY 处理:高基数的 GROUP BY 操作会消耗大量内存和 CPU 资源,影响查询性能。
○ 大规模 JOIN 操作:分析查询通常涉及多个大表的关联, JOIN 操作会占用大量内存和 CPU 资源,特别是在关联条件选择不恰当时,可能会导致效率低下。
○ 不合理的 JOIN 顺序:优化器选择的 JOINS 顺序如果不合理,会导致中间结果集增大,从而降低查询性能。
3. 并行计算性能不达预期
由于数据分析需要处理大量数据,AP 业务通常依赖高度并行的计算能力来加速查询,当并行性能不达预期时,需要判断是系统配置不足还是 SQL 本身存在问题。此外,由于 AP 使用的 SQL 通常执行时间较长,而且其执行过程对用户不可见,如何在执行期间监控其实时信息和执行状态,也是 AP 场景使用过程中重要的一项功能。这些挑战需要系统化的诊断工具和优化策略来有效应对,以提升 OceanBase 在 AP 场景下的性能和可靠性。
(二) OceanBase 常用诊断工具
上述问题不可避免地会带来计划的复杂性。当 SQL 执行的性能不达预期,往往有可能是其中的某一个环节出现了卡点,而分布式计划多个数据库节点的处理使得这种问题环节的定位变得格外困难。
为了解决这些困难,OceanBase 提供了一系列用户诊断和调优工具,包括 SQL Audit、Full Link Trace、DBMS_XPLAN 工具包等。
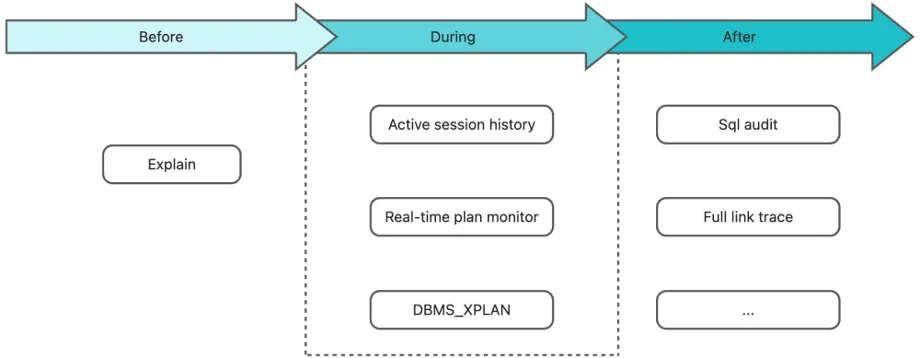
图 2:OceanBase Diagnostic Tools
例如,可以通过下面的步骤,初步通过 SQL Audit 视图进行 SQL 级别的诊断:
○ 查看 retry 次数:如果 retry 次数很多,则可以考虑是否存在锁冲突或切主等情况
○ 查看 queue time 是否很大:如果产生了抖动,那些 QUEUE_TIME 非常大但是 EXCUTE_TIME 并不长的 SQL ,往往是受抖动影响的 SQL ,而不是引起抖动的 SQL 。因为产生抖动的原因一般都是某条 SQL 执行的时间很长,导致其他 SQL 不能及时得到 CPU 来执行,只能一直在队列里排队
○ 查看获取执行计划时间(GET_PLAN_TIME)是否很长:如果是,往往说明此 SQL 没有命中计划而是重新去走了一次完整的生成计划流程,一般会伴随 IS_HIT_PLAN=0
○ 查看 EXCUTE_TIME 是否很长:如果很长,可以通过下面的 SQL 查看是否有很长耗时的等待事件。比如发现此 SQL 的等待事件耗费了很长时间在等 IO ,那么可以查看抖动时间点的磁盘状态是否正常
(三)SQL Plan Monitor 实时分析性能瓶颈
尽管我们提供了多种诊断工具,但在 AP 场景下,仍然比较缺乏 SQL 算子级别的执行监控支持。例如并行执行任务划分了多少个,是否有倾斜,HASH 冲突是否严重,执行 hang 住时卡在了哪个算子上等等问题,诊断问题依赖于日志。
如果遇到了 SQL 整体层面的信息汇总分析完成,慢 SQL 仍然未定位的场景,可能问题是出在 SQL 本身而非调度阶段。此时可以使用 SQL_PLAN_MONITOR 视图进行算子级别的详细分析。SQL_PLAN_MONITOR 视图是一个非常有用的工具,用于实时监控 SQL 语句的执行情况,通过该视图,可以详细了解 SQL 语句在执行过程中的资源消耗和执行状态,包括算子并发数、在每个线程上的吐行、扫描行数、实际执行时间等,用户可以通过这些信息进行进一步的诊断。
1. 查询性能瓶颈
SQL_PLAN_MONITOR 视图记录了执行过程中每一个算子的吐行以及执行时间等信息,这也是进行性能诊断的时候最先关注的数据项,一般可以通过每个算子使用了多少线程(并发度),共吐出了多少行数据,以及吐出第一行和最后一行数据的时间,查询最慢的算子。
我们以 TPC-H Q17 为例,一次执行的记录如下图:
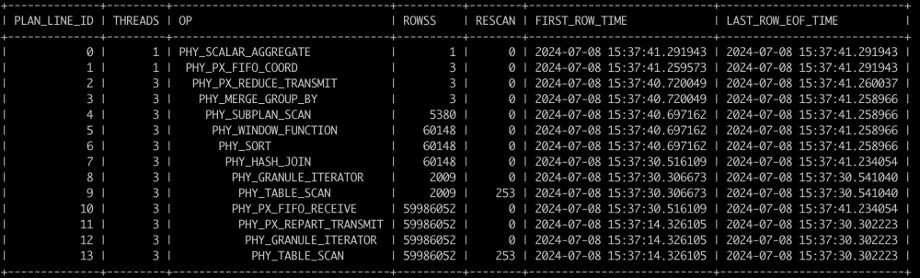
图 3:TPC-H Q17 (LINEITEM.L_PARTKEY 无索引)
结合图中数据与执行计划能够看出,对 LINEITEM 的扫描和 7 号算子 HASH JOIN 是本次执行的瓶颈,而左表 PART 的扫描很快就完成了,这种情况可以对右表的 join 列加索引。
添加索引后的记录如下,连接方法由 HASH JOIN 调整为 NLJ,避免了 LINEITEM 表的全表扫描,执行时间由 30s 降低至 4s。
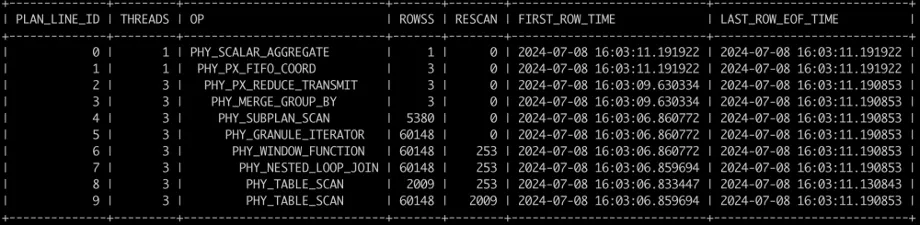
图 4:TPC-H Q17 (LINEITEM.L_PARTKEY 有索引)
2. 实时 I/O 数据
从 4.2.4 版本起,SQL_PLAN_MONITOR 支持实时查看每个算子在每个线程上的耗时、I/O 数据详情。可以通过 OTHERSTAT_x_KEY 与 OTHERSTAT_x_VALUE 获取 I/O 数据。KEY 与 VALUE 的对应关系可以在 V$SQL_MONITOR_STATNAME 视图中获取,其中与 I/O 相关的字段为:
33:total io bytes read from disk
34:total bytes processed by ssstore
35:total rows processed by ssstore
36:total rows processed by memstore
一个片段如下,可以看出,该算子所有数据都是由 sstable 中扫描得到,且吐行行数不足为扫描行数的 1%,说明当前查询需要针对该表进行优化,例如调整过滤条件或在当前过滤列上建索引。
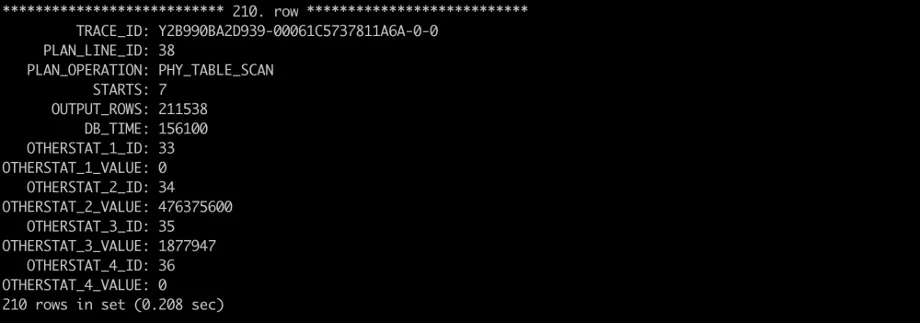
图 5:SQL_PLAN_MONITOR I/O 数据
3. 负载倾斜问题
当数据在分布节点之间不均匀时,部分节点可能承载了大量数据处理任务,而其他节点几乎没有工作负载,这会造成单点瓶颈并影响整体性能。
例如有一个大表,有数十个分区,某个分区上存在一天的峰值数据,它的数据达到了总体的 90%。那么如果并行统计每分区某个字段上不同值的个数,每个线程去计算部分分区的结果,计算后汇总起来。可以想象并行执行的效果:对于一些小分区,线程很早就做完并汇报上去,但负责大分区的线程要算很久,其它分区都在等着这个线程结束,导致整体性能上不去。这种场景加并行的收益很低,因为没有让每个线程的负载达到平衡。
在实际业务场景中,可以通过 SQL_PLAN_MONITOR 视图来进行负载倾斜问题的诊断。plan monitor 视图记录了每个节点上每个线程的详细数据,如果遇到并行性能不符合预期的表现,可以通过对比同个算子不同线程的记录,可以分析是否存在长尾节点拖慢整个执行过程的情况。
二、OceanBase 实时 SQL 诊断
(一)开发者分析慢 SQL 的痛点
尽管 OceanBase 目前提供了一些诊断和调优工具,但目前还存在一些挑战,特别是对开发人员:
○ 使用多步骤、多工具的复杂性,要求开发人员具备深入的数据库和 OceanBase 内核知识。
○ 诊断和调优过程复杂繁琐,需要管理和维护大量的 SQL 查询和脚本。
○ 学习成本较高,需要专业的培训和长期的经验积累才可以掌握 SQL 诊断方法。
(二)全新设计的实时 SQL 执行剖析
为了解决这些问题,进一步提升 SQL 诊断的实时性和准确性,我们在 ODC 4.3.1 推出了全新的 Query Profile(执行剖析)功能,Query Profile 通过可视化方式展示了 OceanBase 4.x 提供的 real-time SQL plan monitor 功能,能够在 SQL 执行过程中实时查询和展示实际计划的执行状态,并详细呈现计划中每个算子的耗时和资源使用情况。
通过执行剖析,结合 ODC 已有的执行计划可视化和全链路追踪可视化功能,用户可以直观地看到执行瓶颈,理解每一步操作的性能开销,从而自主分析和优化查询性能。执行剖析可以帮助回答以下关键问题:
○ 我们要处理多少数据?
○ 瓶颈出现在哪里?
○ 哪些列在过滤器和连接中使用最频繁?
○ 这些列是否过滤了大部分数据,或者它们总是提取大多数行?
TPC-H Q15 语句查询获得某段时间内为总收入贡献最多的供货商(排名第一)的信息。可用以决定对哪些头等供货商给予奖励、给予更多订单、给予特别认证、给予鼓舞等激励。Q15 语句的特点是:带有分组、排序、聚集、聚集子查询操作并存的普通表与视图的连接操作。我们以此条语句为例,说明执行剖析的功能及结构。通过 ODC 执行后,在执行结果处,点击执行画像按钮,
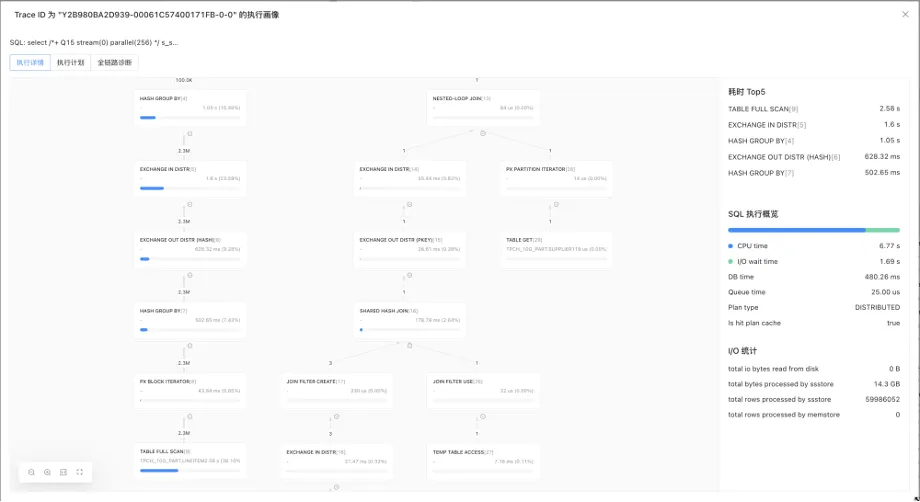
图 6:查看执行剖析
从执行概览可以看到一些 SQL 执行的基本信息,例如是否为分布式计划、是否命中计划缓存和总耗时信息,这可以作为诊断的背景信息。
图形视图向我们展示了执行计划被调度的顺序。我们通常自底向上阅读执行计划,但 ODC 的执行剖析以蓝色进度条突出显示每个算子实际所花费的 CPU cost,以及提供了耗时最高的 5 个节点排序,使识别性能瓶颈变得容易得多。通过上面的可视化视图,能够快速发现的结论:
第一,每个节点所花费的时间:耗时是识别性能问题的入手点。从每个算子的总耗时中,我们可以快速识别瓶颈,并分析原因。在上面的示例中,查询中运行时间最长的节点是表"LINEITEM"的扫描节点。且可以看出主要性能瓶颈在根节点的左子计划侧。
第二,每个节点的行输出:现在查看每个节点的行输出。LINEITEM 表输出约 230 万条记录,而右侧所有算子输出行数都为 1。
现在我们有了一些基本信息,且已经了解大体的性能瓶颈所在。接下来,我们可以深入了解执行剖析的第二部分:I/O 统计和算子属性。
如上图右侧所示,这是我们查询整体的概览部分。我们可以查看的一些关键简单指标包括总 CPU 耗时、总 I/O 耗时、实际执行耗时、读取的行/字节数(关键问题,我们要处理多少数据)等。这些是诊断的起点,通常可以帮助用户调整大多数查询。回到上面的例子,我们从图中注意到一个关键的事情:我们的瓶颈是计划的左子树。点击确定的瓶颈"TABLE FULL SCAN"节点,查询算子执行详情如下图:
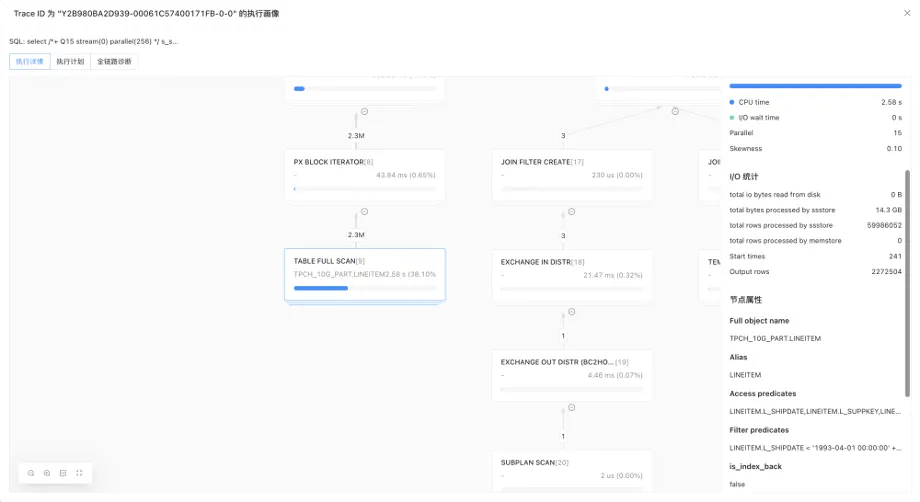
图 7:查看算子详情
通过右侧 I/O 统计中的 total rows processed by ssstore 字段,可以看到当前节点进行了完整的全表扫描,这说明是没有走索引的,即便在 L_SHAPEDATE 列上我们已经创建了索引,这可能是由于优化器评估得到。
从节点形状可以看出,当前算子为分布式算子,执行概况表明该算子的并行度为 15,倾斜度为 0.1,倾斜度较小,说明线程之间负载较为均衡,没有拖慢整体性能的长尾节点。
如果想查询每个线程执行详情,也可以在右侧切换到不同线程,查看每个线程的吐行、吐行耗时和 rescan 次数。ODC 提供了耗时、内存和吐行三个维度的排序,方便找到瓶颈线程。
此外,ODC 4.3.1 还对 SQL 诊断相关的功能做了全面重新设计,在一个交互页面中同时提供 执行剖析、执行计划和全链路诊断 信息,支持多种格式的视图,提高分布式场景下用户请求问题诊断效率。
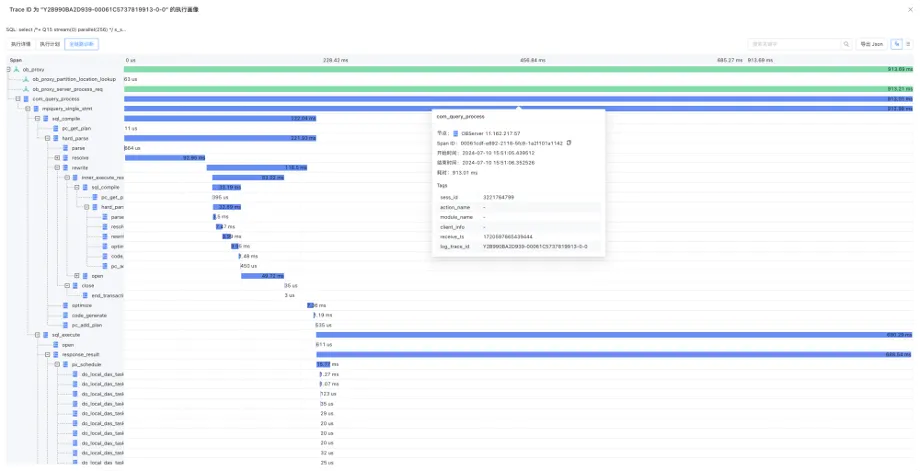
图 8:全链路诊断 Trace 视图
三、写在最后
ODC 执行剖析功能是深入了解 OceanBase 计划查询机制的强大工具,可以帮助用户更全面地了解每次查询的性能细节,从而发现 SQL 中潜在的性能瓶颈和优化空间。
SQL 实时诊断调优在 AP 开发具有重要意义,OceanBase 将持续增强这方面的能力,未来的计划包括:
○ 提供不同视角的并行计划时间线视图,如 DFO 汇总视图、线程优先详情视图和算子优先详情视图。这些视图相较于传统的树形视图,更容易识别和分析长尾算子,有助于提高诊断效率。
○ 支持将执行剖析、执行计划和全链路追踪导出为文件(例如 HTML),以保存 SQL 执行现场。这种导出功能便于与支持团队进行沟通和分享,促进问题的快速解决。
○ 进一步的发展方向包括自助诊断和自动调优能力的引入。未来用户将能够在一个页面上完成 SQL 性能问题的定位和解决,大大简化调优过程并提升了数据库操作的效率。
通过持续的功能增强和优化,OceanBase 将不断为用户提供更强大、更高效的 SQL 数据库管理和优化工具,以应对更复杂的 AP 场景挑战和数据处理需求。
ODC 是一款开源的企业级数据库协同开发工具,获取源码及更多详情,可访问 ODC GitHub 仓库。