掩码掩码,指的是掩盖住后面的词汇的词向量对我当前词汇造成影响。把PAD字符设置成负无穷大,概念上不叫掩码,只是计算方式和掩码一样。
怎么生成掩码,在非掩码注意力矩阵中,把PAD词向量每个维度设置成负无穷大,或者设置掩码矩阵为负无穷大,矩阵乘法的效果是一样的。
在实际计算的过程中,掩码不仅仅只是生成一半就可以了,我都知道GPT其实有限制token长度这一说法,假如限制50个token,我们最后生成的注意力矩阵就是长宽都是50个,但是当我们的句子不够50的时候,剩下的位置需要用指定字符去填充。
如下图:第一个矩阵的意思是一半做掩码防止后面词语对当前词汇的影响,第二个矩阵是对 填充字符 做掩码,因为填充字符的语义我们也是要求为对句子的影响为0,两个矩阵叠加得到第三个矩阵。(注:下图是叉为负无穷大)

举个例子,构造好掩码矩阵之后,跟右边的词向量句子做矩阵乘法,根据上一章节,可以看到 PAD填充符 对句子影响为负无穷大,达到我们的要求:无关字符对句子影响为0。(注:下图是叉为负无穷大)

预测阶段注意力矩阵的计算 encoder 阶段,没有掩码(注:下图是叉为负无穷大)

传递个decoder的词向量矩阵,最右侧的词向量矩阵当中,最底下的PAD词向量的每一个维度都是负无穷大

decoder 阶段,,有两个注意力矩阵,一个有掩码,一个没有掩码(注:下图是叉为负无穷大)
有掩码,

上面有个极其重点的内容,经过上面的一次矩阵运算,其实我已经进行了一个序列的不同长度的训练
就是下面这种计算方式,已经帮助我同时训练了
输入:START, 输出 g
输入:START g, 输出 f
输入:START g f, 输出 h
输入:START g f h, 输出 PAD
我不用像传统训练方式一样构造上面这种数据。
试验:当我进行预测输入START的时候,掩码矩阵是动态生成的,由于其他都是负无穷大,只有第一行有数字,其他的权重不会对START造成影响。我在训练的时候,第一行权重除了第一个是数字,其他都是负无穷大,矩阵乘法的到这这行的权重和词向量每一行相乘,虽然预测阶段和训练阶段计算方式有略微区别,但是这种恰当的巧合使得我不用特意去构造训练数据,这是一个计算巧合,这种掩码机制恰好帮我训练了这么多数据,巧合巧合巧合巧合巧合巧合巧合巧合巧合巧合巧合巧合,如下:
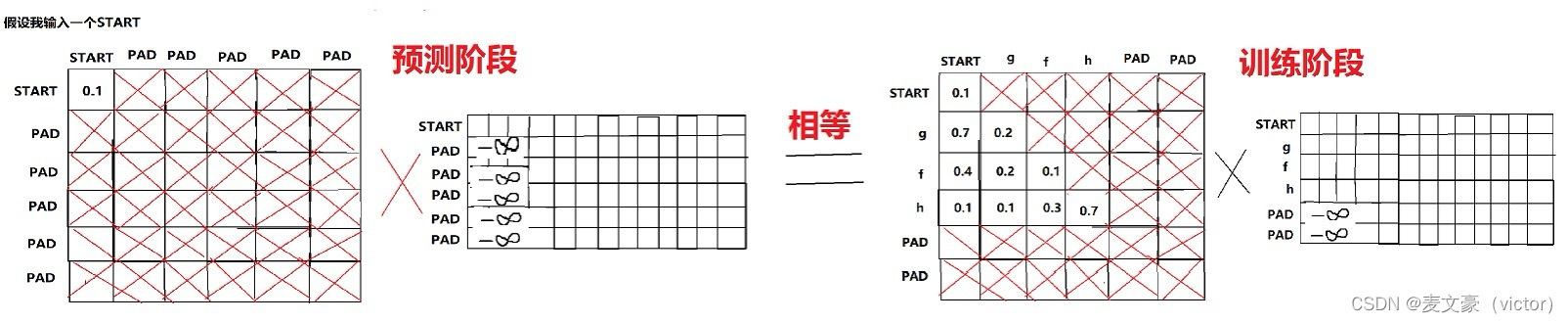
上面走完之后,就到了没有掩码的注意力矩阵阶段,就是decoder和encoder结合的自注意力矩阵,这个矩阵的意思是a,b,c词分对 START 的影响程度, 对 g 的影响程度,对 f 的影响程度,对 h 的影响程度,将这些影响程度叠加在原来的 START,g,f,h上。
