import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime
plt.rcParams['figure.figsize'] = (15, 7)
image1 = plt.imread("river basin.jpg")
plt.imshow(image1)
image2 = plt.imread("/besos.jpg")
plt.imshow(image2)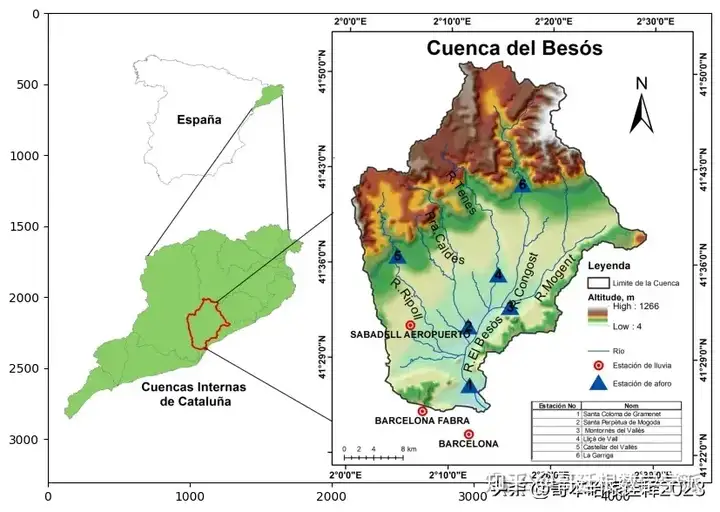
df=pd.read_excel("Copy of rainfall data edited(1).xlsx", index_col= 'Date')
df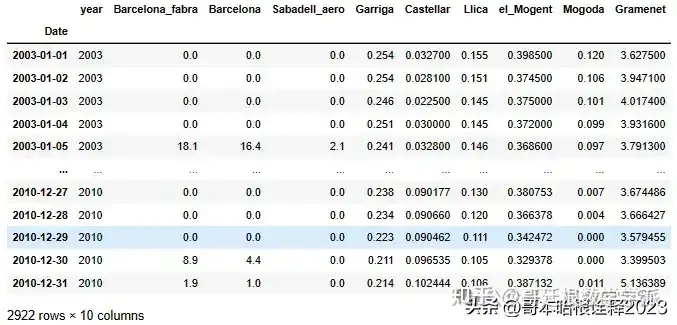
df.shape
(2922, 10)
df.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 2922 entries, 2003-01-01 to 2010-12-31
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 2922 non-null int64
1 Barcelona_fabra 2922 non-null float64
2 Barcelona 2922 non-null float64
3 Sabadell_aero 2922 non-null float64
4 Garriga 2922 non-null float64
5 Castellar 2922 non-null float64
6 Llica 2922 non-null float64
7 el_Mogent 2922 non-null float64
8 Mogoda 2922 non-null float64
9 Gramenet 2922 non-null float64
dtypes: float64(9), int64(1)
memory usage: 251.1 KB
df.drop("year", axis=1, inplace= True)
df.head()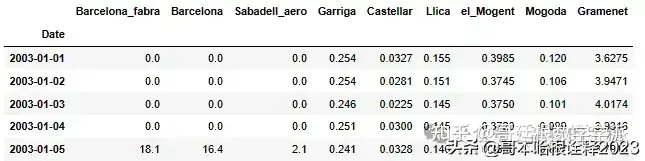
columns = [0, 1, 2]
i = 1
values = df.values
# define figure object and size
plt.figure(figsize=(15,12))
# plot each column with a for loop
for variable in columns:
plt.subplot(len(columns), 1, i)
plt.plot(values[:, variable])
plt.xlabel('day',fontsize=15)
plt.ylabel('Rainfall (mm)',fontsize=15)
plt.title(df.columns[variable], y=0.5, loc='right')
plt.tick_params(labelsize=15)
plt.grid()
plt.ioff()
i += 1
plt.show()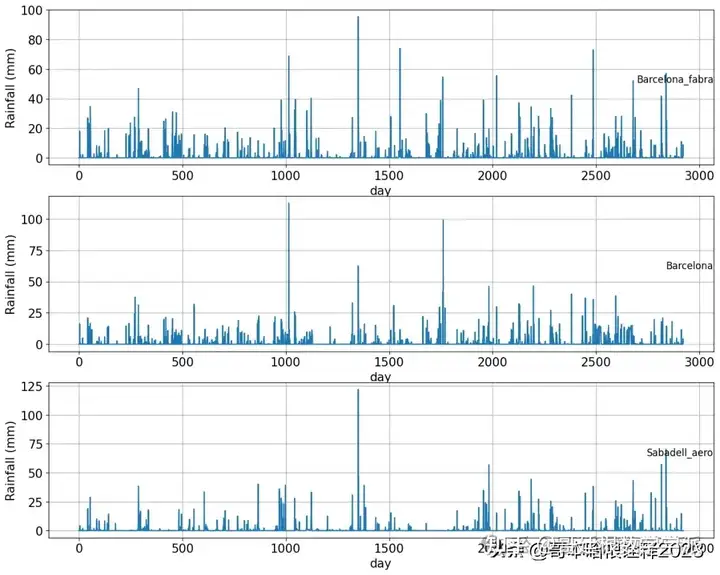
columns = [3,4,5,6,7,8]
i = 1
values = df.values
# define figure object and size
plt.figure(figsize=(15,20))
# plot each column with a for loop
for variable in columns:
plt.subplot(len(columns), 1, i)
plt.plot(values[:, variable])
plt.xlabel('day',fontsize=15)
plt.ylabel('Streamflow (m3/s)',fontsize=15)
plt.title(df.columns[variable], y=0.5, loc='right')
plt.tick_params(labelsize=15)
plt.grid()
plt.ioff()
i += 1
plt.show()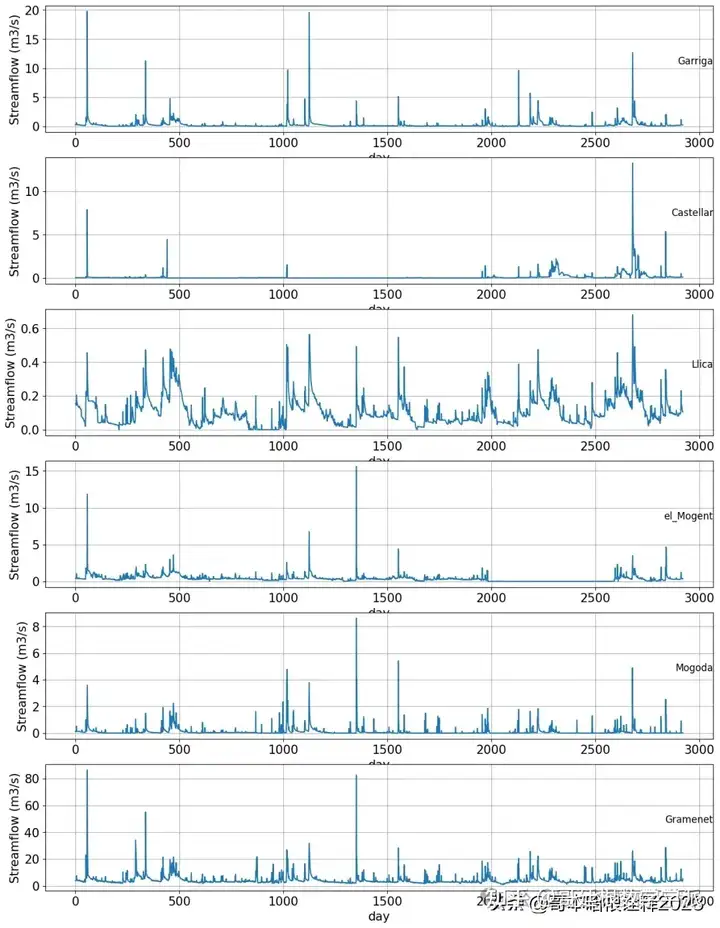
#Lag creation
def lag_creation(df, lag_start, lag_end, columns, inplace=False, freq=1):
if not inplace:
df = df.copy()
for col in columns:
for i in range(lag_start, lag_end, freq):
df["lag_"+str(i)+"_"+col] = df[col].shift(i)
if not inplace:
return df
#Encoding the cyclical properties of time
def date_features(df, inplace=False):
if not inplace:
df = df.copy()
df.index = pd.to_datetime(df.index)
df['day_sin'] = np.sin(df.index.dayofweek*(2.*np.pi/7))
df['day_cos'] = np.cos(df.index.dayofweek*(2.*np.pi/7))
df['month_sin'] = np.sin(df.index.dayofweek*(2.*np.pi/12))
df['month_cos'] = np.cos(df.index.dayofweek*(2.*np.pi/12))
if not inplace:
return df
#Data normalization
from sklearn.preprocessing import MinMaxScaler
def Normalize_columns(df, columns, inplace=False):
if not inplace:
df = df.copy()
sc = MinMaxScaler()
df[columns] = sc.fit_transform(df[columns])
if not inplace:
return df
#Cross-correlation
def crosscorr(datax, datay, lag=0, wrap=False):
if wrap:
shiftedy = datay.shift(lag)
shiftedy.iloc[:lag] = datay.iloc[-lag:].values
return datax.corr(shiftedy)
else:
return datax.corr(datay.shift(lag))
df.head(200)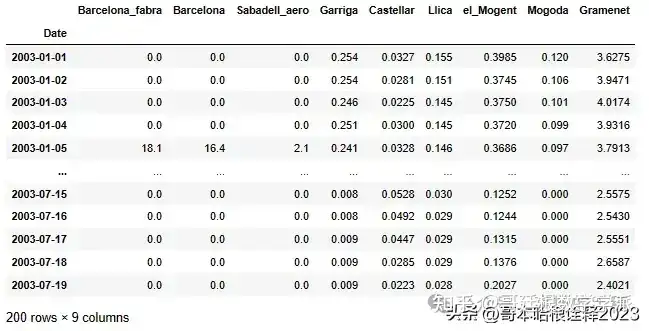
plt.plot(np.arange(0, 6), [crosscorr(df['Gramenet'], df['Barcelona'], lag) for lag in range(0, 6)])
plt.title('Q_Gramenet - P_Barcelona cross-correlation', fontsize=15)
plt.xlabel('Lags',fontsize=15)
plt.ylabel('Correlation coefficient',fontsize=15)
plt.tick_params(labelsize=15)
plt.grid()
plt.ioff()
plt.show();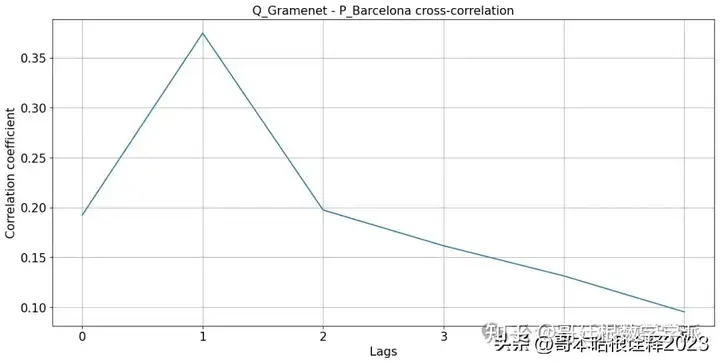
freq=1
Normalize_columns(df, ['Barcelona', 'Barcelona_fabra', 'Sabadell_aero', 'Garriga', 'Llica', 'el_Mogent', 'Mogoda', 'Gramenet'], inplace=True)
lag_creation(df, 1, 2, ['Barcelona'], inplace=True, freq=freq)
lag_creation(df, 1, 2, ['Barcelona_fabra'], inplace=True, freq=freq)
lag_creation(df, 1, 2, ['Sabadell_aero'], inplace=True, freq=freq)
lag_creation(df, 1, 2, ['Garriga'], inplace=True, freq=freq)
lag_creation(df, 1, 2, ['Llica'], inplace=True, freq=freq)
lag_creation(df, 1, 2, ['el_Mogent'], inplace=True, freq=freq)
lag_creation(df, 1, 2, ['Mogoda'], inplace=True, freq=freq)
lag_creation(df, 1, 3, ['Gramenet'], inplace=True, freq=freq)
date_features(df, inplace=True)
df.dropna(inplace=True)
df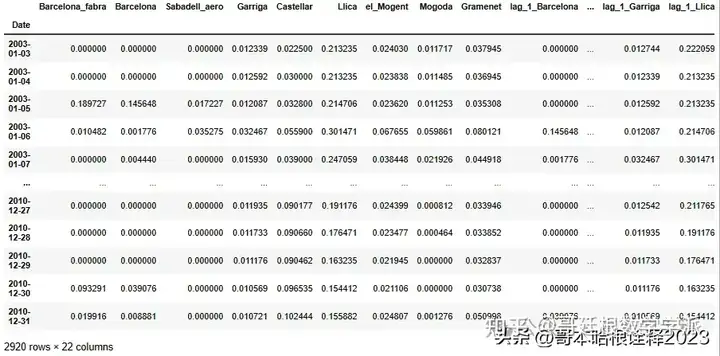
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
df.index = pd.to_datetime(df.index)
df.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 2920 entries, 2003-01-03 to 2010-12-31
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Barcelona_fabra 2920 non-null float64
1 Barcelona 2920 non-null float64
2 Sabadell_aero 2920 non-null float64
3 Garriga 2920 non-null float64
4 Castellar 2920 non-null float64
5 Llica 2920 non-null float64
6 el_Mogent 2920 non-null float64
7 Mogoda 2920 non-null float64
8 Gramenet 2920 non-null float64
9 lag_1_Barcelona 2920 non-null float64
10 lag_1_Barcelona_fabra 2920 non-null float64
11 lag_1_Sabadell_aero 2920 non-null float64
12 lag_1_Garriga 2920 non-null float64
13 lag_1_Llica 2920 non-null float64
14 lag_1_el_Mogent 2920 non-null float64
15 lag_1_Mogoda 2920 non-null float64
16 lag_1_Gramenet 2920 non-null float64
17 lag_2_Gramenet 2920 non-null float64
18 day_sin 2920 non-null float64
19 day_cos 2920 non-null float64
20 month_sin 2920 non-null float64
21 month_cos 2920 non-null float64
dtypes: float64(22)
memory usage: 524.7 KB
X = df.drop('Gramenet', axis=1)
y = df['Gramenet']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
from sklearn.linear_model import LinearRegression
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
param_grid = {
'C': [0.1, 1, 10, 100,1000],
'gamma': [0.001, 0.01, 0.1, 1]
}
svr = SVR(kernel='rbf')
from sklearn.model_selection import KFold, cross_val_score
kfold = KFold(n_splits=10, shuffle=True, random_state=42)
best_score = -np.inf
best_params = None
for C in param_grid['C']:
for gamma in param_grid['gamma']:
svr = SVR( C=C, gamma=gamma)
scores = cross_val_score(svr, X_train, y_train, cv=kfold, scoring='neg_mean_squared_error')
average_score = np.mean(scores)
if average_score > best_score:
best_score = average_score
best_params = { 'C': C, 'gamma': gamma}
print(f'Best parameters: {best_params}')
print(f'Best score: {-best_score}')
Best parameters: {'C': 1000, 'gamma': 0.01}
Best score: 0.0023295391574644246
svr_model = SVR(kernel='rbf', C=100, epsilon=0.0001, gamma=0.1)
svr_model.fit(X_train, y_train)
SVR(C=100, epsilon=0.0001, gamma=0.1)
y_pred = svr_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(round(mse,4))
0.0004
r2 = r2_score(y_test, y_pred)
print(round(r2,4))
0.8517
pip install hydroeval
import hydroeval as he
# Hydrograph plot for both training and test periods
plt.scatter(df.iloc[int(len(df)*0.80):].index, df.iloc[int(len(df)*0.80):].Gramenet, color ='b', label= "observed")
plt.scatter(df.iloc[:int(len(df)*0.80)].index, df.iloc[:int(len(df)*0.80)].Gramenet, color ='b')
plt.plot(df.iloc[int(len(df)*0.80):].index, y_pred, 'orange', label="simulated")
plt.plot(df.iloc[:int(len(df)*0.80)].index, y_train, 'orange')
plt.axvline(13596, 0, 80, linestyle='--')
plt.figtext(0.75, 0.7, "Testing period", fontsize = 20)
plt.figtext(0.35, 0.7, "Training period", fontsize = 20)
plt.title("Observed and simulated streamflow discharge", fontsize=15)
plt.xlabel('Year',fontsize=15)
plt.ylabel('Streamflow discharge (m3/s)',fontsize=15)
plt.tick_params(labelsize=15)
plt.grid()
plt.legend(fontsize="x-large")
plt.figure(figsize=(7,15))
plt.show()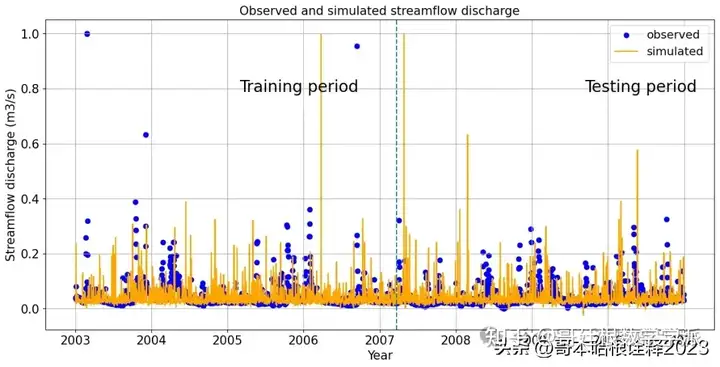
Linear Regression
plt.scatter(df.iloc[int(len(df)*0.80):].index, df.iloc[int(len(df)*0.80):].Gramenet, color ='b', label= "observed")
plt.scatter(df.iloc[:int(len(df)*0.80)].index, df.iloc[:int(len(df)*0.80)].Gramenet, color ='b')
plt.plot(df.iloc[int(len(df)*0.80):].index, y_pred1, 'orange', label="simulated")
plt.plot(df.iloc[:int(len(df)*0.80)].index, y_train, 'orange')
plt.axvline(13596, 0, 80, linestyle='--')
plt.figtext(0.75, 0.7, "Testing period", fontsize = 20)
plt.figtext(0.35, 0.7, "Training period", fontsize = 20)
plt.title("Observed and simulated streamflow discharge", fontsize=15)
plt.xlabel('Year',fontsize=15)
plt.ylabel('Streamflow discharge (m3/s)',fontsize=15)
plt.tick_params(labelsize=15)
plt.grid()
plt.legend(fontsize="x-large")
plt.show()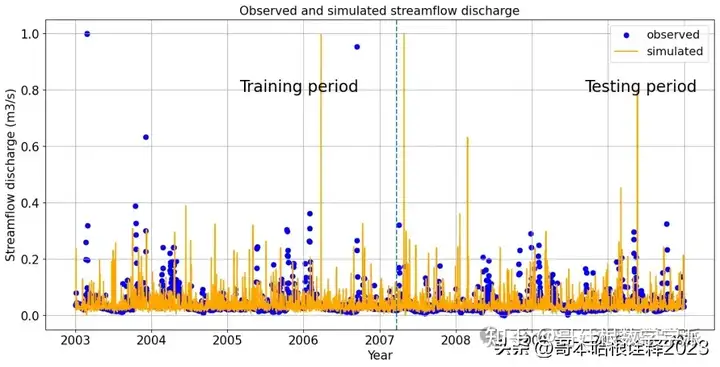
Random forest regressor
# Hydrograph plot for both training and test periods
plt.scatter(df.iloc[int(len(df)*0.80):].index, df.iloc[int(len(df)*0.80):].Gramenet, color ='b', label= "observed")
plt.scatter(df.iloc[:int(len(df)*0.80)].index, df.iloc[:int(len(df)*0.80)].Gramenet, color ='b')
plt.plot(df.iloc[int(len(df)*0.80):].index, y_pred2, 'orange', label="simulated")
plt.plot(df.iloc[:int(len(df)*0.80)].index, y_train, 'orange')
plt.axvline(13596, 0, 80, linestyle='--')
plt.figtext(0.75, 0.7, "Testing period", fontsize = 20)
plt.figtext(0.35, 0.7, "Training period", fontsize = 20)
plt.title("Observed and simulated streamflow discharge", fontsize=15)
plt.xlabel('Year',fontsize=15)
plt.ylabel('Streamflow discharge (m3/s)',fontsize=15)
plt.tick_params(labelsize=15)
plt.grid()
plt.legend(fontsize="x-large")
plt.show()
知乎学术咨询:https://www.zhihu.com/consult/people/792359672131756032?isMe=1担任《Mechanical System and Signal Processing》等审稿专家,擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。