CatBoost 是一种基于梯度提升决策树的机器学习算法,它在处理类别特征方面有独特的优势,并且通常能够提供比其他梯度提升框架更好的性能。下面是一个我最近使用 SMOTE 和 CatBoost 库进行分类任务的基本示例。
需要安装的包
bash
pip install catboost
pip install imblearn示例代码
这里是一个简单的例子,展示如何使用 CatBoostClassifier 进行分类任务:
- 导入必要的库。
- 准备数据集。
- 划分训练集和测试集。
- 创建并训练模型。
- 评估模型性能。
步骤 1: 导入库
python
import pandas as pd
from sklearn.model_selection import train_test_split
from catboost import CatBoostClassifier, Pool
from sklearn.metrics import accuracy_score, classification_report, ConfusionMatrixDisplay
from imblearn.over_sampling import SMOTE
import numpy as np # 截至2024年8月15日,catboost不支持NumPy 2.0,建议使用NumPy 1.26步骤 2: 准备数据集
假设我们有一个 XLSX 文件 data.xlsx 包含特征和标签。
python
# 加载数据
data = pd.read_excel('data.xlsx')
# 分离特征和标签
X = data.drop('target', axis=1)
y = data['target']
# SMOTE采样
X_resampled, y_resampled = SMOTE().fit_resample(X, y)步骤 3: 划分训练集和测试集
python
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X_resampled, y_resampled, test_size=0.2, random_state=42)步骤 4: 创建并训练模型
python
# 定义分类器
model = CatBoostClassifier(iterations=1000, learning_rate=0.1, depth=8)
# 指定类别特征的索引(如果有的话)
categorical_features_indices = np.where(X.dtypes != np.float64)[0]
# 训练模型
model.fit(
X_train, y_train,
cat_features=categorical_features_indices,
eval_set=(X_test, y_test),
verbose=False
)步骤 5: 评估模型性能
python
# 预测
predictions = model.predict(X_test)
# 打印结果
print("Accuracy:", accuracy_score(y_test, predictions))
print(classification_report(y_test, predictions, digits=8))
_ = ConfusionMatrixDisplay.from_estimator(model, X_test, y_test)
bash
Accuracy: 0.9818376068376068
precision recall f1-score support
0 0.99433798 0.96942675 0.98172436 2355
1 0.96979866 0.99440860 0.98194946 2325
accuracy 0.98183761 4680
macro avg 0.98206832 0.98191768 0.98183691 4680
weighted avg 0.98214697 0.98183761 0.98183619 4680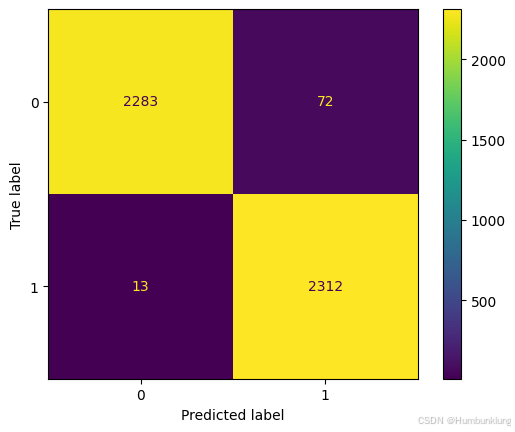
效果不错,但这种使用SMOTE制造数据的方式,可能存在过拟合的问题。