概述
Dinky 是一个基于 Apache Flink 的实时计算平台,它提供了一站式的 Flink 任务开发、运维、监控等功能。
本教程一步一步的教你如何使用dinky运行CDC pipline任务实现整库同步Doris并自动建表功能。Starrocks同理
原文阅读:【巨人肩膀社区·专栏·分享】Dinky教程--Flink CDC pipline整库同步Doris
如果觉得项目不错欢迎前去点下 Star, 感谢您的支持!
前置条件
- 已部署好的Dinky
- 准备好Flink集群
如果还没有准备好dinky与flink集群,可以参考我以前的文章或官网进行部署
快速部署Doris与Mysql测试环境
Flink CDC为我们提供了可快速部署的docker-compose yaml文件,我们可以很方便的创建一个测试环境出来
如果你mysql与Doris环境都已经具备,那么可以跳过此章节
yaml 复制代码
version: '2.1'
services:
doris:
image: yagagagaga/doris-standalone
ports:
- "8030:8030"
- "8040:8040"
- "9030:9030"
mysql:
image: debezium/example-mysql:1.1
ports:
- "3306:3306"
environment:
- MYSQL_ROOT_PASSWORD=123456
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=mysqlpw在 docker-compose.yml 所在目录下执行下面的命令来启动本教程需要的组件:
bash 复制代码
docker-compose up -d该命令将以 detached 模式自动启动 Docker Compose 配置中定义的所有容器。你可以通过 docker ps 来观察上述的容器是否正常启动了,也可以通过访问http://localhost:8030/ 来查看 Doris 是否运行正常。
准备数据
进入 MySQL 容器
bash 复制代码
docker-compose exec mysql mysql -uroot -p123456创建数据库 app_db 和表 orders,products,shipments,并插入数据
sql 复制代码
Doris 暂时不支持自动创建数据库,需要先创建写入表对应的数据库。
进入 Doris Web UI。
http://localhost:8030/
默认的用户名为 root,默认密码为空。
通过 Web UI 创建 app_db 数据库
sql 复制代码
create database app_db;
image.png
下载CDC相关依赖
flink-cdc-3.1.0-bin.tar.gz
MySQL pipeline connector 3.1.0
Apache Doris pipeline connector 3.1.0
上述依赖下载完成后,把
flink-cdc-pipeline-connector-doris-3.1.0.jar与flink-cdc-pipeline-connector-mysql-3.1.0.jar放到dinky的依赖目录下(dinky/extends 或者 docker部署的customJar下面)
解决CDC依赖冲突问题
如果直接在dinky使用
flink-cdc-dist-3.1.0.jar会有java.lang.NoSuchMethodError: org.apache.calcite.tools.FrameworkConfig.getTraitDefs()Lorg/apache/flink/calcite/shaded/com/google/common/collect/ImmutableList;错误,所以我们需要先处理一下
sh 复制代码
# 解压 flink-cdc-3.1.0-bin.tar.gz
tar -zxvf flink-cdc-3.1.0-bin.tar.gz
cd flink-cdc-3.1.0/lib/
# 解压jar文件·
jar -xvf flink-cdc-dist-3.1.0.jar
# 删除冲突包
rm -rf org/apache/calcite
# 重新打包
jar -cvf flink-cdc-dist-3.1.0-new.jar * 把新打包的flink-cdc-dist-3.1.0-new.jar文件放到dinky依赖目录下,重启dinky
开始运行
打开dinky页面,新建Flink Sql任务,输入以下代码,注意把相关IP替换成你自己的
Flink集群需要自己提前注册好,选择对应集群
sql 复制代码
SET 'execution.checkpointing.interval' = '30s';
EXECUTE PIPELINE WITHYAML (
source:
type: mysql
hostname: localhost
port: 3306
username: root
password: '123456'
tables: app_db.\.*
server-id: 5400-5404
sink:
type: doris
fenodes: localhost:8030
username: root
password: ''
table.create.properties.light_schema_change: true
table.create.properties.replication_num: 1
pipeline:
name: Sync MySQL Database to Doris
parallelism: 1
)
image.png
运行并验证
点击运行提交到Flink集群运行

前往运维中心查询任务状态,可以看到正常起来了

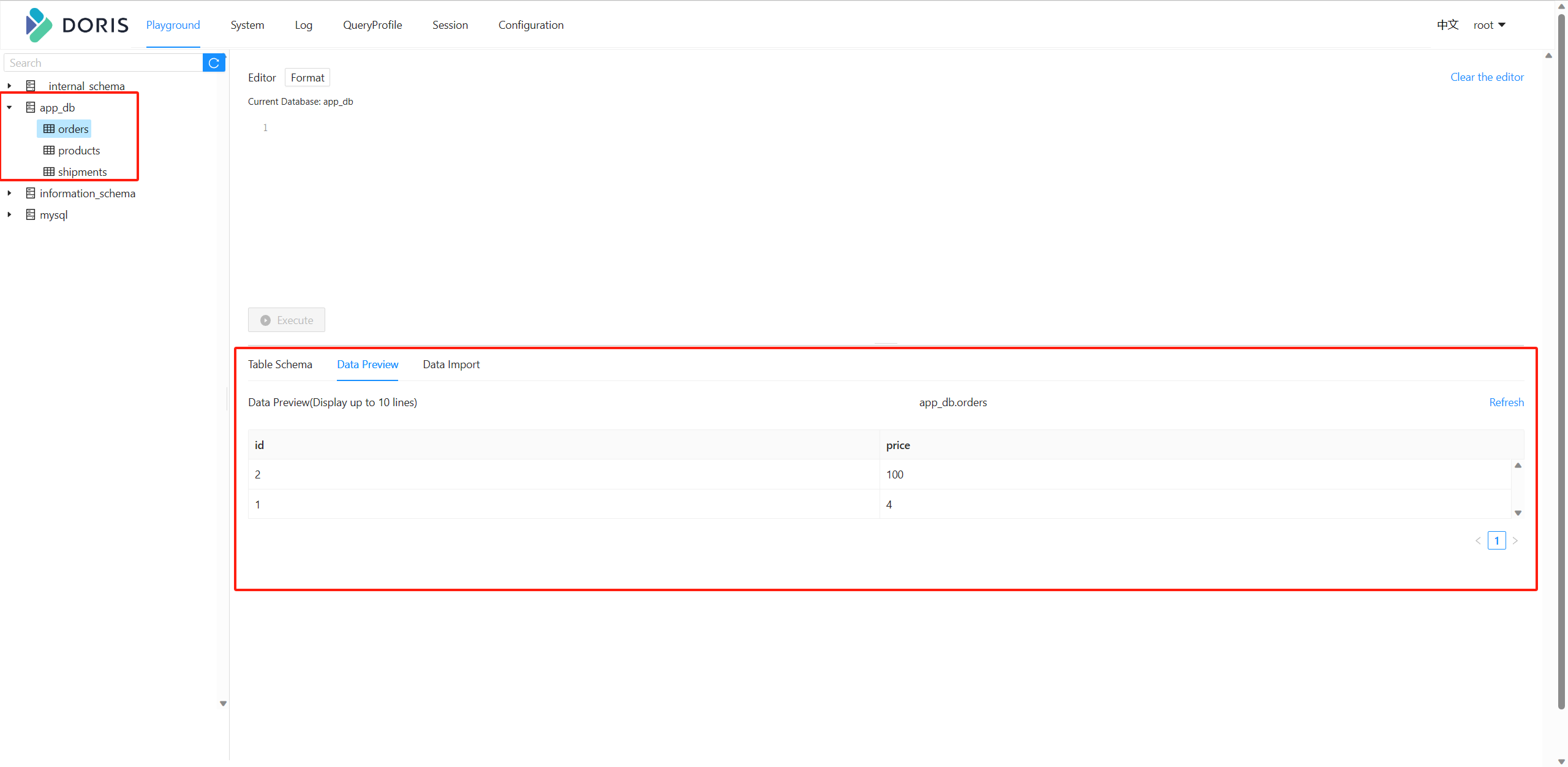
去Doris验证数据,可以看到表已经自动建好了,数据也同步过来了