编者按:分享一个很硬核的免费人工智能学习网站,通俗易懂,风趣幽默, 可以当故事来看,轻松学习。
中文版本
****自然语言处理 (NLP)****已成为语言学、人工智能和计算机科学交叉领域的变革性领域。随着文本数据量的不断增加,NLP 提供了以有意义的方式处理、分析和理解人类语言的工具和技术。从参与智能对话的聊天机器人到衡量公众舆论的情绪分析算法,NLP 彻底改变了我们与机器的互动方式以及机器理解我们语言的方式。
此 NLP 面试问题适用于那些想要成为自然语言处理专家并为梦想的 NLP 开发人员职业做准备的人。许多求职者在面试中被拒绝,因为他们不了解这些 NLP 问题。此 GeeksforGeeks NLP 面试问题指南由专业人士设计,涵盖了 NLP 面试中会问到的所有常见问题。

NLP 面试问题
这篇NLP 面试问题文章是在 NLP 专业人士的指导下撰写的,并通过学生最近的 NLP 面试经验获得想法。我们准备了一份前 50 个自然语言处理面试问题和答案的列表,希望对您在面试中有所帮助。
目录
面向新人的 NLP 基本面试问题
1.什么是NLP?
NLP 代表自然语言处理。 人工智能和计算语言学的子领域涉及计算机与人类语言之间的交互。它涉及开发算法、模型和技术,使机器能够像人类一样理解、解释和生成自然语言。
NLP 涵盖广泛的任务,包括语言翻译、情感分析、文本分类、信息提取、语音识别和自然语言理解。NLP 通过处理和分析文本输入,使计算机能够提取含义、获得洞察力并以更自然、更智能的方式与人类交流。
2. NLP 中的主要挑战是什么?
人类语言的复杂性和多样性给自然语言处理(NLP)的研究带来了许多难题。NLP 面临的主要挑战如下:
- ****语义和意义:****准确捕捉单词、短语和句子的含义是一项艰巨的任务。语言的语义,包括词义消歧、隐喻语言、习语和其他语言现象,必须通过 NLP 模型准确地表示和理解。
- 歧义性:语言本质上具有歧义性,单词和短语有时会根据上下文具有多种含义。准确解决这种歧义是 NLP 系统的一大难题。
- ****语境理解:****语境经常用于解释语言。为了使 NLP 模型能够准确解释并产生有意义的回复,必须理解和使用语境。语境困难包括理解指称语句和将代词解析为其先行词等。
- 语言多样性: NLP 必须处理世界上种类繁多的语言和方言,每种语言和方言都有自己独特的语言特征、词汇和语法。缺乏资源和对低资源语言的了解使问题变得复杂。
- ****数据限制和偏差:****用于训练 NLP 模型的高质量标记数据可能有限,尤其是对于特定领域或语言。此外,训练数据中的偏差可能会损害模型性能和公平性,因此需要仔细考虑和缓解。
- 理解现实世界: NLP 模型通常无法理解人类与生俱来的现实世界知识和常识。捕捉这些知识并将其应用到 NLP 系统中是一个持续存在的问题。
3. NLP 中有哪些不同的任务?
自然语言处理 (NLP) 包括广泛的任务,涉及理解、处理和创建人类语言。NLP 中一些最重要的任务如下:
4. NLP 中的 Corpus 是什么意思?
在 NLP 中,语料库是大量文本或文档的集合。它是一个结构化的数据集,可作为特定语言、领域或问题的样本。语料库可以包含各种文本,包括书籍、论文、网页和社交媒体帖子。语料库通常是为了特定研究或 NLP 目标而开发和整理的。它们是开发语言模型、进行语言分析以及深入了解语言使用和模式的基础。
5. NLP 中的文本增强是什么意思,以及 NLP 中有哪些不同的文本增强技术?
NLP 中的文本增强是指从现有数据生成新的或修改后的文本数据的过程,以增加训练样本的多样性和数量。文本增强技术对原始文本进行大量修改,同时保留其基本含义。
NLP 中的不同文本增强技术包括:
- ****同义词替换:****用同义词替换文本中的单词以引入变化,同时保持语义相似性。
- ****随机插入/删除:****在文本中随机插入或删除单词,以模拟嘈杂或不完整的数据并增强模型鲁棒性。
- ****词语交换:****交换句子内单词的位置以生成替代的句子结构。
- ****回译:****将文本翻译成另一种语言,然后再翻译回原始语言,以引入不同的措辞和句子结构。
- ****随机掩蔽:****用特殊标记掩蔽或替换文本中的随机单词,类似于 BERT 等掩蔽语言模型中使用的方法。
- ****字符级增强:****修改文本中的单个字符,例如添加噪声、拼写错误或字符替换,以模拟现实世界的变化。
- ****文本释义:****使用不同的单词和句子结构重写句子或短语,同时保留原始含义。
- ****基于规则的生成:****应用语言规则来生成新的数据实例,例如使用语法模板或句法转换。
6. NLP 中使用了哪些常见的预处理技术?
自然语言处理 (NLP)预处理是指用于准备原始文本输入以进行分析、建模或任何其他 NLP 任务的一组流程和技术。预处理的目的是清理和更改文本数据,以便稍后对其进行处理或分析。
NLP 中的预处理通常涉及一系列步骤,其中可能包括:
- 标记化
- 停用词删除
- 文本规范化
- 小写
- 词形还原
- 词干提取
- 日期和时间规范化
- 删除特殊字符和标点符号
- 删除 HTML 标签或标记
- 拼写纠正
- 句子分割
7. NLP 中的文本规范化是什么?
文本规范化,也称为文本标准化,是将文本数据转换为标准化或规范化形式的过程,它涉及应用各种技术来确保一致性,减少变化并简化文本信息的表示。
文本规范化的目标是使文本更加统一,更易于在自然语言处理 (NLP) 任务中处理。文本规范化中使用的一些常用技术包括:
- 小写:将所有文本转换为小写,以将具有相同字符的单词视为相同并避免重复。
- 词形还原:将单词转换为其基本形式或词典形式,称为词干。例如,将"running"转换为"run",或将"better"转换为"good"。
- 词干提取:通过删除后缀或前缀将单词简化为词根形式。例如,将"playing"转换为"play",或将"cats"转换为"cat"。
- 缩写扩展:将缩写或首字母缩略词扩展为完整形式。例如,将"NLP"转换为"自然语言处理"。
- 数字规范化:将数字转换为其书写形式或规范化数字表示。例如,将"100"转换为"一百"或规范化日期。
- 日期和时间规范化:将日期和时间格式标准化为一致的表示。
8. NLP 中的标记化是什么?
标记化是将文本或字符串分解为更小的单元(称为标记)的过程。根据具体应用,这些标记可以是单词、字符或子词。它是许多自然语言处理任务(如情感分析、机器翻译和文本生成等)的基本步骤。
一些最常见的标记化方法如下:
- ****句子标记化:****在句子标记化中,文本被分解为单个句子。这是标记化的基本步骤之一。
- ****单词标记化:****在单词标记化中,文本被简单地分解成单词。这是最常见的标记化类型之一。它通常通过将文本拆分为空格或标点符号来完成。
- ****子词标记化:****在子词标记化中,文本被分解为子词,即单词的较小部分。有时单词由多个单词组成,例如 Subword 即 Sub+word,这里的 sub 和 words 有不同的含义。当这两个单词连接在一起时,它们形成新词"subword",意思是"单词的较小单位"。这通常用于需要理解文本形态的任务,例如词干提取或词形还原。
- ****字符标签标记化:****在字符标签标记化中,文本被分解为单个字符。这通常用于需要更细致地理解文本的任务,例如文本生成、机器翻译等。
9.什么是 NLTK 以及它在 NLP 中有何帮助?
NLTK代表自然语言处理工具包。它是一套用 Python 语言编写的库和程序,用于符号和统计自然语言处理。它提供标记化、词干提取、词形还原、词性标记、命名实体识别、解析、语义推理和分类。
NLTK 是 Python 的一个流行 NLP 库。它易于使用且功能广泛。它也是开源的,这意味着可以免费使用和修改。
10. NLP 中的词干提取是什么,它与词形还原有何不同?
词干提取和词形还原是 NLP 中两种常用的词语规范化技术,旨在将单词简化为其基本词或词根。两者的目标相似,但方法不同。
在词干提取中,无论词性的上下文如何,都会使用启发式或基于模式的规则删除单词后缀。生成的词干可能并不总是实际的词典单词。与词形还原相比,词干提取算法通常更简单、更快速,因此适用于具有时间或资源限制的某些应用程序。
在词形还原中,单词的词根形式(称为词干)是通过考虑单词的上下文和词性来确定的。它使用语言知识和数据库(例如 wordnet)将单词转换为其词根形式。在这种情况下,输出词干是词典中的有效单词。例如,对"running"和"runner"进行词形还原将得到"run"。词形还原提供了更好的可解释性,并且对于需要有意义的单词表示的任务来说可以更准确。
11. 词性标注在 NLP 中如何发挥作用?
词性标注是将词性标记分配给句子中每个单词的过程。词性标记表示单词的句法信息及其在句子中的作用。
词性标注主要有三种方法:
- ****基于规则的词性标注:****它使用一组手工制定的规则,根据句子中每个单词的形态、句法和上下文模式来确定其词性。例如,以"-ing"结尾的单词很可能是动词。
- ****统计词性标记:****隐马尔可夫模型 (HMM) 或条件随机场 (CRF) 等统计模型是在大量已标记文本上进行训练的。该模型学习单词序列与其对应的词性标记的概率,并可进一步用于根据单词出现的上下文为每个单词分配最可能的词性标记。
- ****神经网络 POS 标记:****基于神经网络的模型,如 RNN、LSTM、双向 RNN 和 Transformer,通过学习单词及其上下文的模式和表示,在 POS 标记方面取得了良好的效果。
12. NLP 中的命名实体识别是什么?
命名实体识别 (NER)是自然语言处理中的一项任务,用于识别和分类文本中的命名实体。命名实体是指现实世界中的对象或概念,例如人、组织、地点、日期等。NER 是 NLP 中的一项具有挑战性的任务,因为命名实体有很多种类型,而且可以用许多不同的方式来引用它们。NER 的目标是提取和分类这些命名实体,以便提供有关给定文本中引用的实体的结构化数据。
命名实体识别 (NER) 所采用的方法与 POS 标记相同。NER 训练中使用的数据带有人员、组织、地点和日期的标签。
13. NLP 中的解析是什么?
在 NLP 中,解析被定义为通过将句子分解为组成部分并根据正式语法规则确定它们之间的句法关系来确定句子底层结构的过程。解析的目的是理解句子的句法结构,从而可以更深入地学习其含义并促进不同的下游 NLP 任务,例如语义分析、信息提取、问答和机器翻译。它也被称为语法分析或句法解析。
解析中使用的正式语法规则通常基于乔姆斯基的层次结构。乔姆斯基层次结构中最简单的语法是常规语法,可用于描述简单句子的语法。更复杂的语法,例如上下文无关语法和上下文相关语法,可用于描述更复杂句子的语法。
14. NLP 中有哪些不同类型的解析?
在自然语言处理 (NLP) 中,有几种类型的解析算法用于分析句子的语法结构。以下是一些主要的解析算法类型:
- 成分解析:NLP 中的成分解析试图通过根据特定语法将句子分解为成分来找出句子的层次结构。它使用上下文无关语法生成有效的成分结构。生成的解析树表示句子的结构,根节点表示完整的句子,内部节点表示短语。成分解析技术(如 CKY、Earley 和图表解析)通常用于解析。这种方法适用于需要彻底理解句子结构的任务,例如语义分析和机器翻译。当需要完全理解句子结构时,会应用成分解析(一种经典的解析方法)。
- 依存关系解析****:****在 NLP 中,依存关系解析可识别句子中单词之间的语法关系。它将句子表示为有向图,其中的依存关系显示为带标记的弧。该图强调主语-谓语、名词-修饰语和宾语-介词关系。依存关系的头部控制另一个单词的句法属性。与成分解析相反,依存关系解析对具有灵活词序的语言很有帮助。它允许明确说明单词之间的关系,从而清晰地表示语法结构。
- 自上而下的解析:自上而下的解析从解析树的根开始,然后迭代地将句子分解成越来越小的部分,直到到达叶子。这是一种更自然的句子解析技术。但是,由于它需要更复杂的语言,因此可能更难实现。
- 自下而上的解析:自下而上的解析从解析树的叶子开始,然后从越来越小的组成部分开始递归地构建树,直到到达根。虽然这种解析方法需要更简单的语法,但它通常更易于实现,即使它不太容易理解。
15. NLP 中的向量空间是什么意思?
在自然语言处理 (NLP) 中,向量空间是一种数学向量,其中单词或文档由数值向量形式表示。单词或文档的特定特征或属性由向量的一个维度表示。向量空间模型用于将文本转换为机器学习算法可以理解的数字表示。
向量空间是使用诸如词嵌入、词袋和词频-逆文档频率 (TF-IDF) 等技术生成的。这些方法允许将文本数据转换为高维空间中的密集或稀疏向量。向量的每个维度可能表示不同的特征,例如单词的存在或不存在、词频、语义含义或上下文信息。
16.什么是词袋模型?
词袋模型是 NLP 中的一种经典文本表示技术,用于描述文档中单词的出现与否。它仅跟踪单词数,而忽略语法细节和词序。
每篇文档都被转换为一个数值向量,其中每个维度对应词汇表中一个唯一的单词。向量每个维度上的值表示该单词在文档中出现的频率、出现次数或其他重要性度量。
让我们考虑两个简单的文本文档:
文档 1:"我喜欢苹果。"
文档 2:"我也喜欢芒果。"
步骤 1:标记化
文档 1 标记:"我"、"爱"、"苹果"
文档 2 标记:"我"、"爱"、"芒果"、"也"
步骤 2:通过收集文档中所有唯一单词来创建词汇表
词汇表:"我"、"爱"、"苹果"、"芒果"、"也"
词汇表有五个唯一单词,因此每个文档向量将有五个维度。
步骤 3:向量化
根据词汇表为每个文档创建数值向量。
对于文档 1:
- 与"I"对应的维度的值为 1。
- 与"love"对应的维度的值为 1。
- 与"apples"对应的维度的值为 1。
- 与"mangoes"和"too"对应的维度的值为 0,因为它们未出现在文档 1 中。
文档 1 向量:1, 1, 1, 0, 0
对于文档 2:
- 与"I"对应的维度的值为 1。
- 与"love"对应的维度的值为 1。
- 与"mangoes"对应的维度的值为 1。
- 与"apples"对应的维度的值为 0,因为它未出现在文档 2 中。
- 与"too"对应的维度的值为 1。
文档 2 向量:1, 1, 0, 1, 1
每个维度的值表示相应单词在文档中的出现或频率。BoW 表示允许我们根据单词频率对文档进行比较和分析。
17. 定义NLP中的Bag of N-grams模型。
n-grams 包模型是 NLP 中标准词袋 (BoW) 模型的改进版。n-grams 包模型不将单个单词作为基本表示单位,而是将 n 个单词的连续序列(称为 n-gram)视为基本表示单位。
Bag of n-grams 模型将文本划分为 n-gram,这些 n-gram 可以根据 n 的值表示连续的单词或字符。这些 n-gram 随后被视为特征或标记,类似于 BoW 模型中的单个单词。
创建 bag-of-n-grams 模型的步骤如下:
- 文本被分割或标记为单个单词或字符。
- 标记化的文本用于构建大小为 n 的 N-gram(n 个连续单词或字符的序列)。如果 n 设置为 1,则称为 uni-gram,即与词袋相同;设置为 2,即为 bi-gram;设置为 3,即为 tri-gram。
- 词汇表是通过收集整个语料库中所有唯一的 n-gram 来构建的。
- 与 BoW 方法类似,每个文档都表示为一个数值向量。向量的维度对应于词汇表的唯一 n-gram,每个维度中的值表示该 n-gram 在文档中出现的频率或出现次数。
18.什么是词频-逆文档频率(TF-IDF)?
词频-逆文档频率 (TF-IDF)是 NLP 中的一种经典文本表示技术,它使用统计度量来评估文档中单词相对于文档语料库的重要性。它是两个术语的组合:词频 (TF) 和逆文档频率 (IDF)。
- ****词频 (TF):****词频衡量一个词在文档中出现的频率。它是给定文档 (d) 中某个词或词 (t) 出现的次数与给定文档中词的总数 (d) 的比率。较高的词频表示该词在特定文档中更重要。
- ****逆文档频率 (IDF):****逆文档频率衡量某个术语在整个语料库中的稀有性或独特性。计算方法是对语料库中的文档总数与包含该术语的文档数之比取对数。它降低了语料库中经常出现的术语的权重,并提高了罕见术语的权重。
TF-IDF 分数是通过将文档中每个术语的词频 (TF) 值与逆文档频率 (IDF) 值相乘来计算的。得出的分数表示该术语在文档和语料库中的重要性。在文档中频繁出现但在语料库中不常见的术语将具有较高的 TF-IDF 分数,这表明它们在该特定文档中的重要性。
19.解释余弦相似度的概念及其在 NLP 中的重要性。
使用余弦相似度度量来测量多维空间中两个向量之间的相似度。为了确定向量之间的相似度或不相似度,它会计算它们之间角度的余弦。
在自然语言处理 (NLP) 中,余弦相似度用于比较两个表示文本的向量。相似度是使用文档向量之间角度的余弦来计算的。为了计算两个文本文档向量之间的余弦相似度,我们经常使用以下步骤:
- 文本表示:使用词袋、TF-IDF(词频-逆文档频率)或 Word2Vec 或 GloVe 等词嵌入等方法将文本文档转换为数字向量。
- 向量归一化:将文档向量归一化为单位长度。此归一化步骤可确保向量的长度或幅度不会影响余弦相似度计算。
- 余弦相似度计算:取标准化向量的点积,然后除以向量幅度的乘积,即可获得余弦相似度。
从数学上讲,两个文档向量之间的余弦相似度, 一个⃗ 一个 和 b⃗ b ,可表示为:
余弦相似度 (一个⃗,b⃗)=一个⃗⋅b⃗∣一个⃗∣∣b⃗∣余弦相似度(一个 ,b )=∣一个 ∣ ∣b ∣一个 ⋅b
这里,
- 一个⃗⋅b⃗ 一个 ⋅b 是向量 a 和 b 的点积
- |a| 和 |b| 分别表示向量 a 和 b 的欧几里得范数(幅度)。
得到的余弦相似度得分范围是 -1 到 1,其中 1 表示相似度最高,0 表示不相似,-1 表示文档之间的差异最大。
20. NLP 中基于规则、基于统计和基于神经的方法有何区别?
自然语言处理 (NLP)使用三种不同的方法来解决语言理解和处理任务:基于规则、基于统计和基于神经。
- 基于规则的方法: 基于规则的系统依赖于预定义的语言规则和模式集来分析和处理语言。
- 语言规则是由人类专家手工制定的规则,用于定义模式或语法结构。
- 基于规则的系统中的知识被明确地编码在规则中,可能涵盖句法、语义或特定领域的信息。
- 基于规则的系统具有很高的可解释性,因为规则是明确定义的并且可以被人类专家理解。
- 这些系统通常需要人工干预和规则修改来处理新的语言变体或领域。
- 基于统计的方法: 基于统计的系统利用统计算法和模型从大型数据集中学习模式和结构。
- 通过检查数据的统计模式和关系,这些系统可以从训练数据中学习。
- 统计模型比基于规则的系统更加通用,因为它们可以对来自各种主题和语言的相关数据进行训练。
- 基于神经的方法: 基于神经的系统采用深度学习模型(例如神经网络)直接从原始文本数据中学习表示和模式。
- 神经网络学习输入文本的分层表示,这使它们能够捕捉复杂的语言特征和语义。
- 这些系统无需制定明确的规则或特征工程,而是直接从数据中学习。
- 通过对庞大而多样化的数据集进行训练,神经网络变得非常灵活并可以执行广泛的 NLP 任务。
- 在许多 NLP 任务中,基于神经的模型已经达到了最先进的性能,超越了经典的基于规则或基于统计的技术。
21. 在 NLP 语境中,序列是什么意思?
序列主要是指一起分析或处理的元素序列。在NLP中,序列可能是字符序列、单词序列或句子序列。
一般来说,句子通常被视为单词或标记的序列。句子中的每个单词都被视为序列中的一个元素。这种顺序表示允许以结构化的方式分析和处理句子,其中单词的顺序很重要。
通过将句子视为序列,NLP 模型可以捕获单词之间的上下文信息和依赖关系,从而实现词性标注、命名实体识别、情感分析、机器翻译等任务。
22. NLP 中使用的机器学习算法有哪些类型?
自然语言处理 (NLP) 任务中经常采用各种类型的机器学习算法。 其中一些如下:
- 朴素贝叶斯:朴素贝叶斯是一种概率技术,在 NLP 中广泛用于文本分类任务。它根据文档中单词或特征的存在来计算文档属于特定类别的可能性。
- 支持向量机 (SVM):SVM 是一种监督学习方法,可用于文本分类、情感分析和命名实体识别。根据给定的特征集,SVM 找到将数据点分成各种类别的超平面。
- 决策树:决策树通常用于情绪分析和信息提取等任务。这些算法根据决策顺序和特征条件构建树状模型,有助于进行预测或分类。
- 随机森林:随机森林是一种集成学习,它结合了多个决策树来提高准确性并减少过度拟合。它们可以应用于文本分类、命名实体识别和情感分析等任务。
- 循环神经网络 (RNN): RNN 是一种神经网络架构,常用于基于序列的 NLP 任务,如语言建模、机器翻译和情感分析。RNN 可以捕获单词序列中的时间依赖性和上下文。
- 长短期记忆 (LSTM):LSTM 是一种循环神经网络,旨在解决 RNN 的梯度消失问题。LSTM 可用于捕获序列中的长期依赖关系,并且已用于机器翻译、命名实体识别和情感分析等应用。
- Transformer:Transformer 是一种相对较新的架构,在 NLP 领域引起了广泛关注。通过利用自注意力过程来捕获文本中的上下文关系,诸如 BERT(Transformer 的双向编码器表示)模型之类的 Transformer 在各种 NLP 任务中都取得了最佳性能。
23. NLP 中的序列标记是什么?
序列标记是 NLP 的基本任务之一,其中将类别标签分配给序列中的每个单独元素。序列可以表示各种语言单位,例如单词、字符、句子或段落。
NLP 中的序列标记包括以下任务。
- 词性标注 (POS Tagging):为句子中的每个单词分配词性标注(例如名词、动词、形容词)。
- 命名实体识别 (NER):在句子中识别并标记人名、地点、组织或日期等命名实体。
- 分块:根据单词的语法角色,将单词组织成句法单位或"块"(例如,名词短语、动词短语)。
- 语义角色标注 (SRL):句子中的单词或短语根据其语义角色进行标注,如教师、医生、工程师、律师等
- 语音标记:在语音识别或音素分类等语音处理任务中,标签被分配给语音单元或声学片段。
条件随机场 (CRF)、隐马尔可夫模型 (HMM)、循环神经网络 (RNN) 或 Transformer 等机器学习模型可用于序列标记任务。这些模型从标记的训练数据中学习,以对未知数据进行预测。
24.NLP中的主题建模是什么?
主题建模是自然语言处理任务,用于从大型文本文档中发现隐藏的主题。它是一种无监督技术,将未标记的文本数据作为输入,并应用表示每个文档是混合主题的概率的概率模型。例如,一份文档有 60% 的可能性与神经网络有关,有 20% 的可能性与自然语言处理有关,有 20% 的可能性与其他内容有关。
每个主题将分布在单词上,这意味着每个主题都是一个单词列表,每个单词都有与之相关的概率。主题中概率最高的单词是最有可能用于描述该主题的单词。例如,"神经"、"RNN"和"架构"等词是神经网络的关键词,而"语言"和"情感"等词是自然语言处理的关键词。
主题建模算法有很多种,但最流行的两种主题建模算法如下:
- 潜在狄利克雷分配 (LDA): LDA 基于这样的理念:语料库中的每个文本都是各种主题的混合体,文档中的每个单词都来自其中一个主题。假设存在一组不可观察的(潜在)主题,每个文档都是通过主题选择或单词生成生成的。
- 非负矩阵分解 (NMF): NMF 是一种矩阵分解技术,它将术语文档矩阵(其中行代表文档,列代表单词)近似为两个非负矩阵:一个代表主题-单词关系,另一个代表文档-主题关系。NMF 旨在确定每个文档的代表性主题和权重。
主题建模对于庞大的文本集合尤其有效,因为手动检查和分类每个文档既不切实际又耗时。我们可以利用主题建模深入了解文本数据的主要主题和结构,从而更轻松地组织、搜索和分析大量非结构化文本。
25.什么是GPT?
GPT代表"生成式预训练 Transformer"。它是指 OpenAI 创建的大型语言模型集合。它基于大量文本和代码数据集进行训练,使其能够生成文本、生成代码、翻译语言、编写多种类型的创意内容,以及以信息丰富的方式回答问题。GPT 系列包括各种模型,其中最著名和最常用的是 GPT-2 和 GPT-3。
GPT 模型建立在 Transformer 架构之上,这使得它们能够高效地捕捉文本中的长期依赖关系和上下文信息。这些模型在来自互联网的大量文本数据上进行了预训练,这使它们能够学习语言的底层模式和结构。
面向经验丰富的高级 NLP 面试问题
26.NLP 中的词嵌入是什么?
NLP 中的词向量被定义为密集的低维词向量表示,用于捕获语言中单词的语义和上下文信息。它通过无监督或监督方法使用大型文本语料库进行训练,以机器学习模型可以处理的数字格式表示单词。
词向量的主要目标是通过将单词表示为连续向量空间中的密集向量来捕获单词之间的关系和相似性。这些向量表示是使用分布假设获得的,该假设指出具有相似含义的单词往往出现在相似的上下文中。一些流行的预训练词向量包括 Word2Vec、GloVe(用于单词表示的全局向量)或 FastText。与传统的文本向量化技术相比,词向量的优势如下:
- 它可以捕捉单词之间的语义相似性
- 它能够捕捉单词之间的句法联系。诸如"国王"-"男人"+"女人"之类的向量运算可能会产生类似于"女王"向量的向量,从而捕捉性别类比。
- 与一次性编码相比,它降低了单词表示的维数。与高维稀疏向量不同,词向量通常具有固定长度,并将单词表示为密集向量。
- 它可以推广到表示未经过训练的单词,即词汇表之外的单词。这是通过使用学习到的单词关联将新单词放置在向量空间中与其在语义或句法上相似的单词附近来实现的。
27.训练词嵌入的各种算法有哪些?
有多种方法通常用于训练词嵌入,即连续向量空间中单词的密集向量表示。一些流行的词嵌入算法如下:
- Word2Vec:Word2vec 是一种常用方法,用于生成反映单词含义和关系的向量表示。Word2vec 使用浅层神经网络学习嵌入,并遵循两种方法:CBOW 和 Skip-gram
- CBOW(连续词袋)根据上下文词预测目标词。
- Skip-gram 根据目标词预测上下文词。
- GloVe:GloVe(用于词表示的全局向量)是一种类似于 Word2vec 的词嵌入模型。另一方面,GloVe 使用目标函数,该函数基于大型语料库中词共现的统计数据构建共现矩阵。共现矩阵是一个方阵,其中每个条目表示两个词在一定大小的窗口中共现的次数。然后,GloVe 对共现矩阵执行矩阵分解。矩阵分解是一种寻找高维矩阵的低维表示的技术。在 GloVe 的情况下,低维表示是语料库中每个词的向量表示。通过最小化损失函数来学习词嵌入,该损失函数衡量预测的共现概率与实际的共现概率之间的差异。这使得 GloVe 对噪声更具鲁棒性,并且对句子中单词的顺序不太敏感。
- FastText:FastText 是包含子词信息的 Word2vec 扩展。它将单词表示为字符 n-gram 包,使其能够处理词汇表之外的术语并捕获形态信息。在训练期间,FastText 会考虑子词信息以及单词上下文。
- ELMo:ELMo 是一种深度语境化的词嵌入模型,可生成与语境相关的词表示。它使用双向语言模型根据单词的语境生成可捕获语义和句法信息的词嵌入。
- BERT:一种基于 Transformer 的模型,称为 BERT(来自 Transformer 的双向编码器表示),用于学习上下文化的词向量。BERT 在大型语料库上进行训练,通过预测句子中的掩码术语并获得有关双向上下文的知识。生成的向量在许多 NLP 任务中实现了最先进的性能,并捕获了大量上下文信息。
28. 如何处理 NLP 中的词汇表外(OOV)单词?
OOV 词是语言模型词汇表中或训练数据中缺失的词。以下是在 NLP 中处理 OOV 词的几种方法:
- ****字符级模型:****字符级模型可用于代替单词级表示。在这种方法中,单词被分解为单个字符,模型根据字符序列学习表示。因此,该模型可以处理 OOV 单词,因为它可以从已知的字符模式中进行推广。
- ****子词标记化:****字节对编码 (BPE) 和 WordPiece 是两种子词标记化算法,它们根据单词在训练数据中的频率将单词划分为较小的子词单元。此方法使模型能够处理 OOV 单词,方法是将它们表示为训练期间遇到的子词的组合。
- ****未知标记:****使用特殊标记(通常称为"未知"标记或"UNK")来表示推理过程中出现的任何 OOV 术语。每当模型遇到 OOV 术语时,它都会将其替换为未识别的标记并继续处理。即使此技术没有明确定义 OOV 词的含义,模型仍然能够生成相关输出。
- ****外部知识:****处理 OOV 术语时,使用外部知识资源(如知识图谱或外部词典)会很有帮助。遇到 OOV 词时,我们需要尝试在外部知识源中查找该词的定义或相关信息。
- ****微调:****我们可以使用包含 OOV 词的特定领域或特定任务数据对预训练语言模型进行微调。通过在微调过程中加入 OOV 词,我们让模型接触这些词,并提高其处理这些词的能力。
29. 词级和字符级语言模型有什么区别?
单词级语言模型和字符级语言模型之间的主要区别在于文本的表示方式。字符级语言模型将文本表示为字符序列,而单词级语言模型将文本表示为单词序列。
单词级语言模型通常更容易解释,训练起来也更高效。然而,它们不如字符级语言模型准确,因为它们无法捕捉以字符顺序存储的文本的复杂性。字符级语言模型比单词级语言模型更准确,但它们的训练和解释更复杂。它们对文本中的噪音也更敏感,因为字符的轻微改变会对文本的含义产生很大影响。
词级和字符级语言模型之间的主要区别是:
| | 字级 | 字符级 |
| 文本表示 | 单词序列 | 字符序列 |
| 可解释性 | 更容易解释 | 更难解释 |
| 对噪声的敏感性 | 不太敏感 | 更敏感 |
| 词汇 | 固定词汇量 | 没有预定义的词汇 |
| 词汇表外 (OOV) 处理 | 难以理解 OOV 单词 | 自然处理 OOV 词 |
| 概括 | 捕捉单词之间的语义关系 | 更好地处理形态细节 |
| 训练复杂度 | 输入/输出空间更小,计算强度更低 | 更大的输入/输出空间,计算更加密集 |
| 应用 | 非常适合需要单词级理解的任务 | 适用于需要细粒度细节或形态变化的任务 |
|---|
30. 什么是词义消歧?
在给定的上下文中确定单词的含义的任务称为词义消歧(WSD)。这是一项具有挑战性的任务,因为许多单词有多种含义,只有通过考虑单词使用的上下文才能确定。
例如,"银行"一词可用于指代各种事物,包括"金融机构"、"河岸"和"斜坡"。句子"我去银行存钱"中的"银行"一词应理解为"金融机构"。这是因为该句子的上下文暗示说话者正在前往可以存钱的地方的路上。
31. 什么是共指解析?
共指解析是一项自然语言处理 (NLP) 任务,涉及识别文本中指代同一实体的所有表达。换句话说,它试图确定文本中的单词或短语(通常是代词或名词短语)是否对应于同一个现实世界事物。例如,句子"Pawan Gunjan 编写了这篇文章,他对各种 NLP 面试问题进行了大量研究"中的代词"他"指的是 Pawan Gunjan 本人。共指解析会自动识别此类联系,并确定"他"在所有情况下都指代"Pawan Gunjan"。
共指解析用于信息提取、问答、摘要和对话系统,因为它有助于生成更准确、更具有上下文感知能力的文本数据表示。它是需要更深入地理解大型文本语料库中实体之间关系的系统的重要组成部分。
32.什么是信息提取?
信息提取是一种自然语言处理任务,用于从非结构化或半结构化文本中提取特定信息,如姓名、日期、位置和关系等。
自然语言通常具有歧义性,可以用多种方式进行解释,这使得信息提取成为一个困难的过程。用于信息提取的一些常见技术包括:
- ****命名实体识别 (NER):****在 NER 中,从文本文档中识别出人物、组织、地点、日期或其他特定类别等命名实体。对于 NER 问题,经常使用各种机器学习技术,包括条件随机场 (CRF)、支持向量机 (SVM) 和深度学习模型。
- ****关系提取:****在关系提取中,确定所述文本之间的联系。我找出各种事物之间的各种关系,例如"在...工作"、"住在..."等。
- ****共指解析:****共指解析是识别文本中代词和其他首语表达的指称的任务。例如,共指解析系统可能能够找出句子中的代词"他"与文本中前面提到的人"约翰"有关。
- ****基于深度学习的方法:****为了执行信息提取任务,人们使用了深度学习模型,例如循环神经网络 (RNN)、基于 Transformer 的架构(例如 BERT、GPT)和深度神经网络。这些模型可以自动从数据中学习模式和表示,从而使它们能够管理复杂多样的文本材料。
33. 什么是隐马尔可夫模型,它对 NLP 任务有何帮助?
隐马尔可夫模型是一种基于马尔可夫链规则的概率模型,通过计算序列的概率分布来对字符、单词和句子等序列数据进行建模。
马尔可夫链使用马尔可夫假设,该假设指出系统未来状态的概率仅取决于其当前状态,而不取决于系统的任何过去状态。该假设通过减少预测未来状态所需的信息量简化了建模过程。
HMM 中的底层过程由一组不可直接观察的隐藏状态表示。基于隐藏状态,生成可观察的数据,例如字符、单词或短语。
隐马尔可夫模型由两个关键部分组成:
- 转换概率:隐马尔可夫模型 (HMM) 中的转换概率表示从一个隐藏状态移动到另一个隐藏状态的可能性。它捕获序列中相邻状态之间的依赖关系或关系。例如,在词性标注中,HMM 的隐藏状态表示不同的词性标记,而转换概率表示从一个词性标记转换到另一个词性标记的可能性。
- 发射概率:在 HMM 中,发射概率定义在特定隐藏状态下观察到特定符号(字符、单词等)的可能性。隐藏状态和可观察符号之间的联系由这些概率编码。
- 发射概率通常用于 NLP 中,表示单词与语言特征(例如词性标记或其他语言变量)之间的关系。HMM 通过计算发射概率来捕获从特定隐藏状态(例如词性标记)生成可观察符号(例如单词)的可能性。
隐马尔可夫模型 (HMM) 使用 Baum-Welch 算法等方法估计标记数据的转移和发射概率。推理算法(如 Viterbi 和 Forward-Backward)用于确定给定观察到的符号的最可能隐藏状态序列。HMM 用于表示顺序数据,并已在 NLP 应用中实现,例如词性标记。然而,高级模型(例如 CRF 和神经网络)由于其灵活性和捕获更丰富依赖关系的能力而经常胜过 HMM。
34.NLP中的条件随机场(CRF)模型是什么?
条件随机场是一种概率图形模型,旨在预测给定观察序列的标签序列。它非常适合上下文信息或相邻元素之间的依赖关系至关重要的预测任务。
CRF 是隐马尔可夫模型 (HMM) 的扩展,可用于对序列中标签之间更复杂的关系进行建模。它专门用于捕获非连续标签之间的依赖关系,而 HMM 则假设马尔可夫属性,即当前状态仅依赖于过去状态。这使得 CRF 更具适应性,适合捕获长期依赖关系和复杂的标签交互。
在 CRF 模型中,标签和观测值以图形表示。图形中的节点表示标签,边表示标签之间的依赖关系。该模型为捕获与观测值和标签相关的信息的特征分配权重。
在训练过程中,CRF 模型通过最大化标记训练数据的条件对数似然来学习权重。此过程涉及梯度下降或迭代缩放算法等优化算法。
在推理过程中,给定一个输入序列,CRF模型会计算不同标签序列的条件概率。维特比算法等算法可以根据这些概率有效地找到最可能的标签序列。
CRF 在各种序列标记任务(如命名实体识别、词性标记等)中表现出了高性能。
35.什么是循环神经网络(RNN)?
循环神经网络是一种人工神经网络,专门用于处理顺序或时间序列数据。它用于自然语言处理活动,例如语言翻译、语音识别、情感分析、自然语言生成、摘要写作等。它与前馈神经网络的不同之处在于,RNN 中的输入数据不仅沿一个方向流动,而且在其设计中还有一个循环或周期,具有可随时间保存信息的"记忆"。因此,RNN 可以处理上下文至关重要的数据,例如自然语言。
RNN 的工作原理是一次分析一个输入序列元素,同时跟踪隐藏状态,该隐藏状态提供序列先前元素的摘要。在每个时间步骤中,隐藏状态都会根据当前输入和先前的隐藏状态进行更新。因此,RNN 可以捕获序列项之间的时间连接,并利用这些知识进行预测。
36. RNN 中的时间反向传播如何工作?
时间反向传播 (BPTT)通过输入数据序列在 RNN 的循环连接中传播梯度信息。让我们逐步了解 BPTT 的过程。
- 前向传递:输入序列从第一个元素开始,一次将一个元素输入到 RNN 中。每个输入元素都通过循环连接进行处理,并更新 RNN 的隐藏状态。
- 隐藏状态序列:RNN 的隐藏状态会保留下来,并从一个时间步骤延续到下一个时间步骤。它包含有关序列中先前输入和隐藏状态的信息。
- 输出计算:更新后的隐藏状态用于计算每个时间步骤的输出。
- 损失计算:在序列的末尾,将预测输出与目标输出进行比较,并使用合适的损失函数计算损失值,例如均方误差或交叉熵损失。
- 反向传播:然后,损失会随着时间反向传播,从最后一个时间步开始,并随时间向后移动。在每个时间步计算损失相对于 RNN 参数的梯度。
- 权重更新:在整个序列上累积梯度,并使用梯度下降或其变体等优化算法更新 RNN 的权重。
- 重复:该过程重复指定数量的时期或直到收敛,在此期间训练数据会被迭代几次。
在反向传播步骤中,获取每个时间步骤的梯度,并用于更新循环连接的权重。梯度在多个时间步骤上的积累使 RNN 能够学习和捕获序列数据中的依赖关系和模式。
37. 标准 RNN 的局限性是什么?
标准RNN(循环神经网络)有几个局限性,可能使其不适合某些应用:
- 消失梯度问题:标准 RNN 容易受到消失梯度问题的影响,即梯度在时间上向后传播时呈指数下降。由于此问题,网络很难在训练期间捕获和传输跨多个时间步骤的长期依赖关系。
- 梯度爆炸问题:另一方面,RNN 可能会遭受梯度膨胀问题,即梯度变得过大并导致训练不稳定。此问题可能导致网络收敛缓慢或根本无法收敛。
- 短期记忆:标准 RNN 的记忆有限,无法记住之前时间步骤的信息。由于这一限制,它们很难捕捉序列中的长期依赖关系,从而限制了它们对跨越大量时间步骤的复杂关系进行建模的能力。
38.什么是长短期记忆(LSTM)网络?
长短期记忆 (LSTM)网络是一种循环神经网络 (RNN) 架构,旨在解决梯度消失问题并捕获序列数据中的长期依赖关系。LSTM 网络在涉及处理和理解序列数据的任务(例如自然语言处理和语音识别)中特别有效。
LSTM 背后的关键思想是整合记忆单元,记忆单元充当能够长时间保留信息的记忆单元。记忆单元由三个门控制:输入门、遗忘门和输出门。
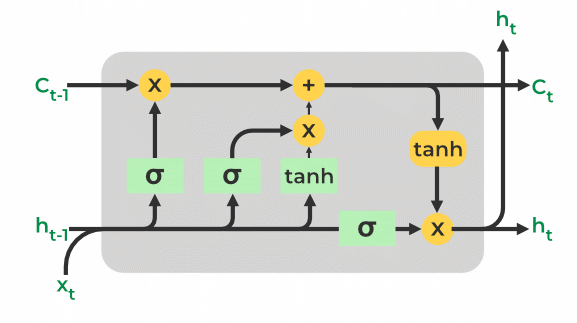
输入门控制应在记忆单元中存储多少新信息。遗忘门决定应销毁或遗忘记忆单元中的哪些信息。输出门控制从记忆单元输出到下一个时间步骤的信息量。这些门由激活函数控制,这些激活函数通常是 S 型函数和 Tanh 函数,允许 LSTM 有选择地更新、遗忘和输出来自记忆单元的数据。
39.NLP中的GRU模型是什么?
门控循环单元(GRU)模型是一种循环神经网络 (RNN) 架构,广泛应用于自然语言处理 (NLP) 任务。该模型旨在解决梯度消失问题并捕获序列数据中的长期依赖关系。
GRU 与 LSTM 类似,都采用了门控机制,但其架构更简化,门更少,因此计算效率更高,更易于训练。GRU 模型由以下组件组成:
- Hidden State: 隐藏状态 时长吨−1 时长 t− 1 GRU 中的表示截至当前时间步骤的输入序列的学习表示或记忆。它保留并将信息从过去传递到现在。
- 更新门: GRU 中的更新门控制从过去隐藏状态到当前时间步骤的信息流。它决定了应该保留多少先前的信息以及应该纳入多少新信息。
- 重置门: GRU 中的重置门决定应丢弃或遗忘多少过去信息。它有助于从先前的隐藏状态中删除不相关的信息。
- 候选激活: 候选激活表示要添加到隐藏状态的新信息 时长吨' 时长 吨' 。它是根据当前输入和先前隐藏状态的转换版本使用重置门进行计算的。
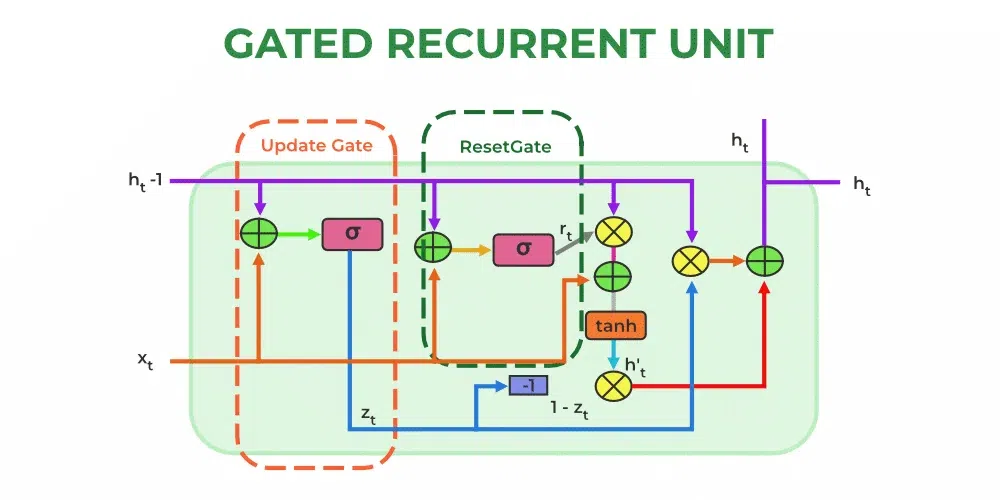
GRU 模型在语言建模、情感分析、机器翻译和文本生成等 NLP 应用中非常有效。它们在必须捕获长期依赖关系和理解上下文的情况下特别有用。由于其简单性和计算效率,GRU 使其成为 NLP 研究和应用中的热门选择。
40.NLP 中的序列到序列(Seq2Seq)模型是什么?
序列到序列 (Seq2Seq)是一种用于自然语言处理 (NLP) 任务的神经网络。它是一种可以学习长期单词关系的循环神经网络 (RNN)。这使其成为机器翻译、文本摘要和问答等任务的理想选择。
该模型由两大部分组成:编码器和解码器。Seq2Seq 模型的工作原理如下:
- 编码器:编码器将输入序列(例如源语言中的句子)转换为固定长度的向量表示,称为"上下文向量"或"思维向量"。为了从输入中捕获顺序信息,编码器通常采用循环神经网络 (RNN),例如长短期记忆 (LSTM) 或门控循环单元 (GRU)。
- ****上下文向量:****编码器的上下文向量充当输入序列的摘要或表示。它将输入序列中的含义和重要信息编码为固定大小的向量,而不管输入的长度如何。
- 解码器:解码器使用编码器的上下文向量来构建输出序列,输出序列可以是翻译或摘要版本。这是另一个基于 RNN 的网络,每次创建一个标记来创建输出序列。在每个步骤中,解码器都可以根据上下文向量进行调节,上下文向量作为初始隐藏状态。
在训练过程中,解码器在每一步都会从目标序列中获取真实标记。时间反向传播 (BPTT) 是一种常用于训练 Seq2Seq 模型的技术。该模型经过优化,可最大限度地减少预测输出序列与实际目标序列之间的差异。
Seq2Seq 模型用于预测或生成期间逐字构建输出序列,每个预测的单词都会返回到模型中作为后续步骤的输入。这个过程会重复进行,直到达到序列结束标记或预定的最大长度。
41.注意力机制对NLP有何帮助?
注意力机制是一种神经网络,它在编码器-解码器神经网络中使用额外的注意力层,使模型能够在执行任务时专注于输入的特定部分。它通过动态地为输入中的不同元素分配权重来实现这一点,表明它们的相对重要性或相关性。这种选择性注意力使模型能够专注于相关信息、捕获依赖关系并分析数据中的关系。
注意力机制在涉及顺序或结构化数据的任务中尤其有用,例如自然语言处理或计算机视觉,在这些任务中,长期依赖关系和上下文信息对于实现高性能至关重要。通过允许模型选择性地关注重要特征或上下文,它提高了模型处理数据中复杂关系和依赖关系的能力,从而提高了各种任务的整体性能。
42.什么是Transformer模型?
Transformer是基于注意力机制的 NLP 基本模型之一,与传统的循环神经网络 (RNN) 相比,Transformer 能够更有效地捕捉序列中的长距离依赖关系。Transformer 在词嵌入、机器翻译、文本摘要、问答等各种 NLP 任务中都取得了最佳成果。
使用 Transformer 的一些主要优点如下:
- 并行化:自注意力机制允许模型并行处理单词,与 RNN 等顺序模型相比,这使得训练速度明显更快。
- ****长距离依赖关系:****注意力机制使 Transformer 能够有效地捕获序列中的长距离依赖关系,这使其适合于长期上下文至关重要的任务。
- ****最先进的性能:****基于 Transformer 的模型在各种 NLP 任务中都取得了最先进的性能,例如机器翻译、语言建模、文本生成和情感分析。
Transformer模型的关键组件如下:
- 自注意力机制:
- 编码器-解码器网络:
- 多头注意力机制:
- 位置编码
- 前馈神经网络
- 层归一化和残差连接
43.Transformers中的自注意力机制起什么作用?
自注意力机制是一种强大的工具,它允许 Transformer 模型捕获序列中的长程依赖关系。它允许输入序列中的每个单词关注同一序列中的所有其他单词,并且模型会学习根据每个单词与其他单词的相关性为每个单词分配权重。这使模型能够捕获短期和长期依赖关系,这对于许多 NLP 应用程序至关重要。
44.Transformers 中的多头注意力机制有什么用途?
Transformers 中的多头注意力机制的目的是让模型能够识别输入序列中不同类型的相关性和模式。在编码器和解码器中,Transformer 模型都使用多个注意力头。这使模型能够识别输入序列中不同类型的相关性和模式。每个注意力头都会学习关注输入的不同部分,从而使模型能够捕捉各种特征和依赖关系。
多头注意力机制有助于模型学习更丰富、更具上下文相关的表示,从而提高各种自然语言处理 (NLP) 任务的性能。
45. Transformers 中的位置编码是什么?为什么需要它们?
Transformer模型并行处理输入序列,因此缺乏 LSTM 所具有的序列模型循环神经网络 (RNN) 所具有的对词序的固有理解。因此,它需要一种方法来明确表达位置信息。
位置编码应用于输入嵌入,以向模型提供此位置信息,例如序列中每个单词的相对或绝对位置。这些编码通常是学习的,可以采用多种形式,包括正弦和余弦函数或学习的嵌入。这使模型能够学习序列中单词的顺序,这对于许多 NLP 任务至关重要。
46.描述Transformer模型的架构。
Transformer 模型的架构基于自注意力和前馈神经网络概念。它由编码器和解码器组成,两者都由多个层组成,每个层包含自注意力和前馈子层。该模型的设计鼓励并行化,从而提高训练效率,并提高涉及顺序数据的任务(例如自然语言处理 (NLP) 任务)的性能。
该架构可以在下面进行深入描述:
- 编码器:
- 输入嵌入:编码器将输入的标记序列(例如单词)作为输入,并将每个标记转换为称为嵌入的向量表示。这些嵌入中使用位置编码来保留序列中单词的顺序。
- 自注意层:编码器由多个自注意层组成,每个自注意层用于捕获序列中单词之间的关系和依赖关系。
- 前馈层:在自注意力步骤之后,自注意力层的输出表征被馈送到前馈神经网络中。该网络将非线性变换独立应用于每个单词的上下文表征。
- 层归一化和残差连接:残差连接和层归一化用于支持自注意力层和前馈层。深度网络中的残差连接有助于缓解梯度消失问题,而层归一化则可稳定训练过程。
- 解码器:
- 输入嵌入:与编码器类似,解码器采用输入序列并将每个标记转换为具有位置编码的嵌入。
- 掩蔽自注意力:与编码器不同,解码器在自注意力层中使用掩蔽自注意力。这种掩蔽确保解码器在训练期间只能关注当前单词之前的位置,从而防止模型在生成期间看到未来的标记。
- 交叉注意层:解码器中的交叉注意层允许它关注编码器的输出,这使得模型能够在输出序列生成期间使用来自输入序列的信息。
- 前馈层:与编码器类似,解码器的自注意力输出经过前馈神经网络。
- 层归一化和残差连接:解码器还包括残差连接和层归一化,以帮助训练并提高模型稳定性。
- 最终输出层:
- Softmax 层:最终的输出层是 softmax 层,它将解码器的表示转换为词汇表上的概率分布。这使模型能够预测输出序列中每个位置最可能的标记。
总体而言,Transformer 的架构使其能够成功处理序列中的长距离依赖关系并执行并行计算,使其在各种序列到序列任务中非常高效且功能强大。该模型已成功用于机器翻译、语言建模、文本生成、问答和各种其他 NLP 任务,并取得了最先进的成果。
47. NLP 中的生成模型和判别模型有什么区别?
生成模型和判别模型都是在自然语言处理 (NLP) 领域用于不同目的的机器学习模型类型。
生成模型经过训练后,可以生成与用于训练它们的数据相似的新数据。例如,可以在文本和代码的数据集上训练生成模型,然后用于生成与数据集中的文本和代码相似的新文本或代码。生成模型通常用于文本生成、机器翻译和创意写作等任务。
判别模型经过训练可以识别不同类型的数据。判别模型。例如,判别模型可以在标记文本数据集上进行训练,然后用于将新文本分类为垃圾邮件或正常邮件。判别模型通常用于文本分类、情绪分析和问答等任务。
NLP 中的生成模型和判别模型之间的主要区别如下:
| | 生成模型 | 判别模型 |
| 目的 | 生成与训练数据相似的新数据。 | 区分不同类别或范畴的数据。 |
| 训练 | 学习输入和输出数据的联合概率分布以生成新的样本。 | 了解给定输入数据的输出标签的条件概率分布。 |
| 示例 | 文本生成、机器翻译、创意写作、聊天机器人、文本摘要和语言建模。 | 文本分类、情感分析和命名实体识别。 |
|---|
48. 什么是机器翻译?它是如何进行的?
机器翻译是使用计算机或机器学习模型自动将文本或语音从一种语言翻译成另一种语言的过程。
机器翻译有三种技术:
- 基于规则的机器翻译 (RBMT):RBMT 系统使用一组规则将文本从一种语言翻译成另一种语言。
- 统计机器翻译 (SMT):SMT 系统使用统计模型来计算给定翻译正确的概率。
- 神经机器翻译 (NMT):神经机器翻译 (NMT) 是一种最近的机器翻译技术,已被证明比 RBMT 和 SMT 系统更准确。近年来,由 Transformer 等深度学习模型驱动的神经机器翻译 (NMT) 越来越受欢迎。
49.BLEU 分数是多少?
BLEU代表"双语评估研究"。这是 IBM 于 2001 年发明的一种用于评估机器翻译质量的指标。它衡量机器生成的翻译与专业人工翻译之间的相似性。它是首批结果与人类判断高度相关的指标之一。
BLEU 分数是通过将机器翻译文本中的 n-gram(n 个单词的序列)与参考文本中的 n-gram 进行比较来衡量的。BLEU 分数越高,表示机器翻译文本与参考文本越相似。
BLEU(双语评估替补)分数是使用 n-gram 精度和简洁性惩罚来计算的。
- N 元语法准确率:N 元语法准确率是机器翻译中匹配的 N 元语法与参考翻译中 N 元语法总数的比率。与参考翻译中对应的 N 元语法重合的一元语法、二元语法、三元语法和四元语法(i=1,...,4)的数量通过 N 元语法重叠度来衡量。
精确我=匹配n -gram的计数 机器翻译中所有N语法的计数 精确我 =机器翻译中所有 n-gram 的数量匹配的 n-gram 计数
对于 BLEU 分数 精确我 精确我 针对 I 范围(1 到 N)进行计算。通常,N 值最大为 4。 - 简洁性惩罚:简洁性惩罚衡量机器生成的翻译与参考翻译之间的长度差异。在计算 BLEU 分数时,如果发现机器生成的翻译与参考翻译的长度相比太短,则会以指数衰减的方式对机器生成的翻译进行惩罚。
短暂刑罚=分钟(1,经验(1−參考長度 机器翻译长度) ))简洁惩罚=分钟( 1 ,经验值( 1−机器翻译长度)参考长度)) - BLEU 分数:BLEU 分数是通过取各个 n-gram 精度的几何平均值,然后根据简洁性惩罚进行调整来计算的。
蓝绿=短暂刑罚×经验∑我=1否日志(精确我)否=短暂刑罚×经验日志(∏我=1否精确我)否=短暂刑罚×(∏我=1否精确我)1否 布鲁=简洁惩罚×经验值*否* ∑*我* = 1*否* 对数(精度*我* )=简洁惩罚×经验值否 日志(∏我 = 1否 精确我 )=简洁惩罚×(我 = 1∏否 精确我 )否 1
这里,N 是最大 n-gram 大小(通常为 4)。
BLEU 分数从 0 到 1,值越高表示翻译质量越好,1 表示与参考翻译完美匹配
50. 列出流行的NLP任务及其相应的评估指标。
自然语言处理 (NLP) 涉及各种任务,每个任务都有自己的目标和评估标准。以下是常见 NLP 任务的列表以及用于评估其性能的一些典型评估指标:
| 自然语言处理(NLP)任务 | 评估指标 |
|---|---|
| 词性标注 (POS 标注) 或命名实体识别 (NER) | 准确率、F1 分数、精确率、召回率 |
| 依存关系解析 | UAS(未标记依恋评分)、LAS(标记依恋评分) |
| 共指消解 | B-CUBED、MUC、CEAF |
| 文本分类或情绪分析 | 准确率、F1 分数、精确率、召回率 |
| 机器翻译 | BLEU(双语评估替补)、METEOR(具有明确排序的翻译评估指标) |
| 文本摘要 | ROUGE(以回忆为导向的摘要评估替代研究)、BLEU |
| 问答 | F1 分数、准确率、召回率、MRR(平均倒数排名) |
| 文本生成 | 人工评估(主观评价)、困惑度(针对语言模型) |
| 信息检索 | 准确率、召回率、F1 分数、平均准确率 (MAP) |
| 自然语言推理 (NLI) | 准确率、精确率、召回率、F1 分数、马修斯相关系数 (MCC) |
| 主题建模 | 连贯性得分、困惑度 |
| 语音识别 | 单词错误率 (WER) |
| 语音合成(文本转语音) | 平均意见得分 (MOS) |
各个评估指标的简要解释如下:
- 准确度:准确度是正确预测的百分比。
- 精确度:精确度是所有预测中正确预测的百分比。
- 召回率:召回率是所有阳性案例中正确预测的百分比。
- F1 分数:F1 分数是精确度和召回率的调和平均值。
- MAP(平均精度):MAP 计算每个查询的平均精度,然后对所有查询求平均精度。
- MUC(基于提及的共指替代研究):MUC 是共指解析的一个指标,用于测量正确识别和链接的提及次数。
- B-CUBED:B-cubed 是共指解析的度量,用于测量正确识别、链接和排序的提及次数。
- CEAF:CEAF 是共指解析的度量,用于测量预测的共指链与黄金标准共指链之间的相似性。
- ROC AUC: ROC AUC 是二元分类的指标,用于测量接收者操作特征曲线下的面积。
- MRR:MRR 是问答系统的一个指标,它衡量排名前 k 位的文档的平均倒数排名。
- 困惑度:困惑度是一种语言模型评估指标。它评估语言模型对之前未见过的数据样本或测试集的预测能力。困惑度值越低,表明语言模型的预测能力越强。
- BLEU:BLEU 是机器翻译的一种指标,用于测量预测翻译和黄金标准翻译之间的 n-gram 重叠度。
- METEOR:METEOR 是机器翻译的一种衡量标准,它衡量预测翻译和黄金标准翻译之间的重叠度,同时考虑同义词和词干。
- WER(词错误率):WER 是机器翻译的一个指标,用于衡量预测翻译的词错误率。
- MCC:MCC 是自然语言推理的一种度量,它测量预测标签和黄金标准标签之间的马修斯相关系数。
- ROUGE:ROUGE 是一种文本摘要指标,它衡量预测摘要和黄金标准摘要之间的重叠度,同时考虑到 n-gram 和同义词。
- 人工评估(主观评估):该技术要求人类专家或众包工作者对 NLP 任务性能的许多要素提交他们的评论、评价或排名。
结论
总而言之,NLP 面试问题根据您的经验简要概述了面试官可能提出的问题类型。但是,为了增加面试成功的机会,您需要对公司特定问题进行深入研究,这些问题可以在不同平台(如志向框、gfg 体验等)中找到。这样做之后,您会感到自信,这有助于您通过下一次面试。
英文原版
Natural Language Processing (NLP) has emerged as a transformative field at the intersection of linguistics, artificial intelligence, and computer science. With the ever-increasing amount of textual data available, NLP provides the tools and techniques to process, analyze, and understand human language in a meaningful way. From chatbots that engage in intelligent conversations to sentiment analysis algorithms that gauge public opinion, NLP has revolutionized how we interact with machines and how machines comprehend our language.
This NLP Interview question is for those who want to become a professional in Natural Language processing and prepare for their dream job to become an NLP developer. Multiple job applicants are getting rejected in their Interviews because they are not aware of these NLP questions. This GeeksforGeeks NLP Interview Questions guide is designed by professionals and covers all the frequently asked questions that are going to be asked in your NLP interviews.
NLP Interview Questions
This NLP interview questions article is written under the guidance of NLP professionals and by getting ideas through the experience of students' recent NLP interviews. We prepared a list of the top 50 Natural Language Processing interview questions and answers that will help you during your interview.
Table of Content
Basic NLP Interview Questions for Fresher
1. What is NLP?
NLP stands for Natural Language Processing . The subfield of Artificial intelligence and computational linguistics deals with the interaction between computers and human languages. It involves developing algorithms, models, and techniques to enable machines to understand, interpret, and generate natural languages in the same way as a human does.
NLP encompasses a wide range of tasks, including language translation, sentiment analysis, text categorization, information extraction, speech recognition, and natural language understanding. NLP allows computers to extract meaning, develop insights, and communicate with humans in a more natural and intelligent manner by processing and analyzing textual input.
2. What are the main challenges in NLP?
The complexity and variety of human language create numerous difficult problems for the study of Natural Language Processing (NLP). The primary challenges in NLP are as follows:
- Semantics and Meaning: It is a difficult undertaking to accurately capture the meaning of words, phrases, and sentences. The semantics of the language, including word sense disambiguation, metaphorical language, idioms, and other linguistic phenomena, must be accurately represented and understood by NLP models.
- Ambiguity: Language is ambiguous by nature, with words and phrases sometimes having several meanings depending on context. Accurately resolving this ambiguity is a major difficulty for NLP systems.
- ****Contextual Understanding:****Context is frequently used to interpret language. For NLP models to accurately interpret and produce meaningful replies, the context must be understood and used. Contextual difficulties include, for instance, comprehending referential statements and resolving pronouns to their antecedents.
- Language Diversity: NLP must deal with the world's wide variety of languages and dialects, each with its own distinctive linguistic traits, lexicon, and grammar. The lack of resources and knowledge of low-resource languages complicates matters.
- ****Data Limitations and Bias:****The availability of high-quality labelled data for training NLP models can be limited, especially for specific areas or languages. Furthermore, biases in training data might impair model performance and fairness, necessitating careful consideration and mitigation.
- ****Real-world Understanding:****NLP models often fail to understand real-world knowledge and common sense, which humans are born with. Capturing and implementing this knowledge into NLP systems is a continuous problem.
3. What are the different tasks in NLP?
Natural Language Processing (NLP) includes a wide range of tasks involving understanding, processing, and creation of human language. Some of the most important tasks in NLP are as follows:
- Text Classification
- Named Entity Recognition (NER)
- Part-of-Speech Tagging (POS)
- Sentiment Analysis
- Language Modeling
- Machine Translation
- Chatbots
- Text Summarization
- Information Extraction
- Text Generation
- Speech Recognition
4. What do you mean by Corpus in NLP?
In NLP, a corpus is a huge collection of texts or documents. It is a structured dataset that acts as a sample of a specific language, domain, or issue. A corpus can include a variety of texts, including books, essays, web pages, and social media posts. Corpora are frequently developed and curated for specific research or NLP objectives. They serve as a foundation for developing language models, undertaking linguistic analysis, and gaining insights into language usage and patterns.
5. What do you mean by text augmentation in NLP and what are the different text augmentation techniques in NLP?
Text augmentation in NLP refers to the process that generates new or modified textual data from existing data in order to increase the diversity and quantity of training samples. Text augmentation techniques apply numerous alterations to the original text while keeping the underlying meaning.
Different text augmentation techniques in NLP include:
- Synonym Replacement: Replacing words in the text with their synonyms to introduce variation while maintaining semantic similarity.
- ****Random Insertion/Deletion:****Randomly inserting or deleting words in the text to simulate noisy or incomplete data and enhance model robustness.
- ****Word Swapping:****Exchanging the positions of words within a sentence to generate alternative sentence structures.
- Back translation: Translating the text into another language and then translating it back to the original language to introduce diverse phrasing and sentence constructions.
- Random Masking: Masking or replacing random words in the text with a special token, akin to the approach used in masked language models like BERT.
- Character-level Augmentation: Modifying individual characters in the text, such as adding noise, misspellings, or character substitutions, to simulate real-world variations.
- Text Paraphrasing: Rewriting sentences or phrases using different words and sentence structures while preserving the original meaning.
- Rule-based Generation: Applying linguistic rules to generate new data instances, such as using grammatical templates or syntactic transformations.
6. What are some common pre-processing techniques used in NLP?
Natural Language Processing (NLP)preprocessing refers to the set of processes and techniques used to prepare raw text input for analysis, modelling, or any other NLP tasks. The purpose of preprocessing is to clean and change text data so that it may be processed or analyzed later.
Preprocessing in NLP typically involves a series of steps, which may include:
- Tokenization
- Stop Word Removal
- Text Normalization
- Lowercasing
- Lemmatization
- Stemming
- Date and Time Normalization
- Removal of Special Characters and Punctuation
- Removing HTML Tags or Markup
- Spell Correction
- Sentence Segmentation
7. What is text normalization in NLP?
Text normalization, also known as text standardization, is the process of transforming text data into a standardized or normalized form It involves applying a variety of techniques to ensure consistency, reduce variations, and simplify the representation of textual information.
The goal of text normalization is to make text more uniform and easier to process in Natural Language Processing (NLP) tasks. Some common techniques used in text normalization include:
- Lowercasing: Converting all text to lowercase to treat words with the same characters as identical and avoid duplication.
- Lemmatization: Converting words to their base or dictionary form, known as lemmas. For example, converting "running" to "run" or "better" to "good."
- Stemming: Reducing words to their root form by removing suffixes or prefixes. For example, converting "playing" to "play" or "cats" to "cat."
- Abbreviation Expansion: Expanding abbreviations or acronyms to their full forms. For example, converting "NLP" to "Natural Language Processing."
- Numerical Normalization: Converting numerical digits to their written form or normalizing numerical representations. For example, converting "100" to "one hundred" or normalizing dates.
- Date and Time Normalization: Standardizing date and time formats to a consistent representation.
8. What is tokenization in NLP?
Tokenization is the process of breaking down text or string into smaller units called tokens. These tokens can be words, characters, or subwords depending on the specific applications. It is the fundamental step in many natural language processing tasks such as sentiment analysis, machine translation, and text generation. etc.
Some of the most common ways of tokenization are as follows:
- Sentence tokenization: In Sentence tokenizations, the text is broken down into individual sentences. This is one of the fundamental steps of tokenization.
- Word tokenization: In word tokenization, the text is simply broken down into words. This is one of the most common types of tokenization. It is typically done by splitting the text into spaces or punctuation marks.
- Subword tokenization: In subword tokenization, the text is broken down into subwords, which are the smaller part of words. Sometimes words are formed with more than one word, for example, Subword i.e Sub+ word, Here sub, and words have different meanings. When these two words are joined together, they form the new word "subword", which means "a smaller unit of a word". This is often done for tasks that require an understanding of the morphology of the text, such as stemming or lemmatization.
- Char-label tokenization: In Char-label tokenization, the text is broken down into individual characters. This is often used for tasks that require a more granular understanding of the text such as text generation, machine translations, etc.
9. What is NLTK and How it's helpful in NLP?
NLTK stands for Natural Language Processing Toolkit. It is a suite of libraries and programs written in Python Language for symbolic and statistical natural language processing. It offers tokenization, stemming, lemmatization, POS tagging, Named Entity Recognization, parsing, semantic reasoning, and classification.
NLTK is a popular NLP library for Python. It is easy to use and has a wide range of features. It is also open-source, which means that it is free to use and modify.
10. What is stemming in NLP, and how is it different from lemmatization?
Stemming and lemmatization are two commonly used word normalization techniques in NLP, which aim to reduce the words to their base or root word. Both have similar goals but have different approaches.
In stemming, the word suffixes are removed using the heuristic or pattern-based rules regardless of the context of the parts of speech. The resulting stems may not always be actual dictionary words. Stemming algorithms are generally simpler and faster compared to lemmatization, making them suitable for certain applications with time or resource constraints.
In lemmatization, The root form of the word known as lemma, is determined by considering the word's context and parts of speech. It uses linguistic knowledge and databases (e.g., wordnet) to transform words into their root form. In this case, the output lemma is a valid word as per the dictionary. For example, lemmatizing "running" and "runner" would result in "run." Lemmatization provides better interpretability and can be more accurate for tasks that require meaningful word representations.
11. How does part-of-speech tagging work in NLP?
Part-of-speech tagging is the process of assigning a part-of-speech tag to each word in a sentence. The POS tags represent the syntactic information about the words and their roles within the sentence.
There are three main approaches for POS tagging:
- Rule-based POS tagging: It uses a set of handcrafted rules to determine the part of speech based on morphological, syntactic, and contextual patterns for each word in a sentence. For example, words ending with '-ing' are likely to be a verb.
- ****Statistical POS tagging:****The statistical model like Hidden Markov Model (HMMs) or Conditional Random Fields (CRFs) are trained on a large corpus of already tagged text. The model learns the probability of word sequences with their corresponding POS tags, and it can be further used for assigning each word to a most likely POS tag based on the context in which the word appears.
- ****Neural network POS tagging:****The neural network-based model like RNN, LSTM, Bi-directional RNN, and transformer have given promising results in POS tagging by learning the patterns and representations of words and their context.
12. What is named entity recognition in NLP?
Named Entity Recognization (NER) is a task in natural language processing that is used to identify and classify the named entity in text. Named entity refers to real-world objects or concepts, such as persons, organizations, locations, dates, etc. NER is one of the challenging tasks in NLP because there are many different types of named entities, and they can be referred to in many different ways. The goal of NER is to extract and classify these named entities in order to offer structured data about the entities referenced in a given text.
The approach followed for Named Entity Recognization (NER) is the same as the POS tagging. The data used while training in NER is tagged with persons, organizations, locations, and dates.
13. What is parsing in NLP?
In NLP, parsing is defined as the process of determining the underlying structure of a sentence by breaking it down into constituent parts and determining the syntactic relationships between them according to formal grammar rules. The purpose of parsing is to understand the syntactic structure of a sentence, which allows for deeper learning of its meaning and encourages different downstream NLP tasks such as semantic analysis, information extraction, question answering, and machine translation. it is also known as syntax analysis or syntactic parsing.
The formal grammar rules used in parsing are typically based on Chomsky's hierarchy. The simplest grammar in the Chomsky hierarchy is regular grammar, which can be used to describe the syntax of simple sentences. More complex grammar, such as context-free grammar and context-sensitive grammar, can be used to describe the syntax of more complex sentences.
14. What are the different types of parsing in NLP?
In natural language processing (NLP), there are several types of parsing algorithms used to analyze the grammatical structure of sentences. Here are some of the main types of parsing algorithms:
- Constituency Parsing: Constituency parsing in NLP tries to figure out a sentence's hierarchical structure by breaking it into constituents based on a particular grammar. It generates valid constituent structures using context-free grammar. The parse tree that results represents the structure of the sentence, with the root node representing the complete sentence and internal nodes representing phrases. Constituency parsing techniques like as CKY, Earley, and chart parsing are often used for parsing. This approach is appropriate for tasks that need a thorough comprehension of sentence structure, such as semantic analysis and machine translation. When a complete understanding of sentence structure is required, constituency parsing, a classic parsing approach, is applied.
- Dependency Parsing: In NLP, dependency parsing identifies grammatical relationships between words in a sentence. It represents the sentence as a directed graph, with dependencies shown as labelled arcs. The graph emphasises subject-verb, noun-modifier, and object-preposition relationships. The head of a dependence governs the syntactic properties of another word. Dependency parsing, as opposed to constituency parsing, is helpful for languages with flexible word order. It allows for the explicit illustration of word-to-word relationships, resulting in a clear representation of grammatical structure.
- Top-down parsing: Top-down parsing starts at the root of the parse tree and iteratively breaks down the sentence into smaller and smaller parts until it reaches the leaves. This is a more natural technique for parsing sentences. However, because it requires a more complicated language, it may be more difficult to implement.
- Bottom-up parsing: Bottom-up parsing starts with the leaves of the parse tree and recursively builds up the tree from smaller and smaller constituents until it reaches the root. Although this method of parsing requires simpler grammar, it is frequently simpler to implement, even when it is less understandable.
15. What do you mean by vector space in NLP?
In natural language processing (NLP), A vector space is a mathematical vector where words or documents are represented by numerical vectors form. The word or document's specific features or attributes are represented by one of the dimensions of the vector. Vector space models are used to convert text into numerical representations that machine learning algorithms can understand.
Vector spaces are generated using techniques such as word embeddings, bag-of-words, and term frequency-inverse document frequency (TF-IDF). These methods allow for the conversion of textual data into dense or sparse vectors in a high-dimensional space. Each dimension of the vector may indicate a different feature, such as the presence or absence of a word, word frequency, semantic meaning, or contextual information.
16. What is the bag-of-words model?
Bag of Words is a classical text representation technique in NLP that describes the occurrence of words within a document or not. It just keeps track of word counts and ignores the grammatical details and the word order.
Each document is transformed as a numerical vector, where each dimension corresponds to a unique word in the vocabulary. The value in each dimension of the vector represents the frequency, occurrence, or other measure of importance of that word in the document.
Let's consider two simple text documents:
Document 1: "I love apples."
Document 2: "I love mangoes too."
Step 1: Tokenization
Document 1 tokens: "I", "love", "apples"
Document 2 tokens: "I", "love", "mangoes", "too"
Step 2: Vocabulary Creation by collecting all unique words across the documents
Vocabulary: "I", "love", "apples", "mangoes", "too"
The vocabulary has five unique words, so each document vector will have five dimensions.
Step 3: Vectorization
Create numerical vectors for each document based on the vocabulary.
For Document 1:
-
The dimension corresponding to "I" has a value of 1.
-
The dimension corresponding to "love" has a value of 1.
-
The dimension corresponding to "apples" has a value of 1.
-
The dimensions corresponding to "mangoes" and "too" have values of 0 since they do not appear in Document 1.
Document 1 vector: 1, 1, 1, 0, 0
For Document 2:
-
The dimension corresponding to "I" has a value of 1.
-
The dimension corresponding to "love" has a value of 1.
-
The dimension corresponding to "mangoes" has a value of 1.
-
The dimension corresponding to "apples" has a value of 0 since it does not appear in Document 2.
-
The dimension corresponding to "too" has a value of 1.
Document 2 vector: 1, 1, 0, 1, 1
The value in each dimension represents the occurrence or frequency of the corresponding word in the document. The BoW representation allows us to compare and analyze the documents based on their word frequencies.
17. Define the Bag of N-grams model in NLP.
The Bag of n-grams model is a modification of the standard bag-of-words (BoW) model in NLP. Instead of taking individual words to be the fundamental units of representation, the Bag of n-grams model considers contiguous sequences of n words, known as n-grams, to be the fundamental units of representation.
The Bag of n-grams model divides the text into n-grams, which can represent consecutive words or characters depending on the value of n. These n-grams are subsequently considered as features or tokens, similar to individual words in the BoW model.
The steps for creating a bag-of-n-grams model are as follows:
- The text is split or tokenized into individual words or characters.
- The tokenized text is used to construct N-grams of size n (sequences of n consecutive words or characters). If n is set to 1 known as uni-gram i.e. same as a bag of words, 2 i.e. bi-grams, and 3 i.e. tri-gram.
- A vocabulary is built by collecting all unique n-grams across the entire corpus.
- Similarly to the BoW approach, each document is represented as a numerical vector. The vector's dimensions correspond to the vocabulary's unique n-grams, and the value in each dimension denotes the frequency or occurrence of that n-gram in the document.
18. What is the term frequency-inverse document frequency (TF-IDF)?
Term frequency-inverse document frequency (TF-IDF)is a classical text representation technique in NLP that uses a statistical measure to evaluate the importance of a word in a document relative to a corpus of documents. It is a combination of two terms: term frequency (TF) and inverse document frequency (IDF).
- Term Frequency (TF): Term frequency measures how frequently a word appears in a document. it is the ratio of the number of occurrences of a term or word (t ) in a given document (d) to the total number of terms in a given document (d). A higher term frequency indicates that a word is more important within a specific document.
- Inverse Document Frequency (IDF): Inverse document frequency measures the rarity or uniqueness of a term across the entire corpus. It is calculated by taking the logarithm of the ratio of the total number of documents in the corpus to the number of documents containing the term. it down the weight of the terms, which frequently occur in the corpus, and up the weight of rare terms.
The TF-IDF score is calculated by multiplying the term frequency (TF) and inverse document frequency (IDF) values for each term in a document. The resulting score indicates the term's importance in the document and corpus. Terms that appear frequently in a document but are uncommon in the corpus will have high TF-IDF scores, suggesting their importance in that specific document.
19. Explain the concept of cosine similarity and its importance in NLP.
The similarity between two vectors in a multi-dimensional space is measured using the cosine similarity metric. To determine how similar or unlike the vectors are to one another, it calculates the cosine of the angle between them.
In natural language processing (NLP), Cosine similarity is used to compare two vectors that represent text. The degree of similarity is calculated using the cosine of the angle between the document vectors. To compute the cosine similarity between two text document vectors, we often used the following procedures:
- Text Representation: Convert text documents into numerical vectors using approaches like bag-of-words, TF-IDF (Term Frequency-Inverse Document Frequency), or word embeddings like Word2Vec or GloVe.
- Vector Normalization: Normalize the document vectors to unit length. This normalization step ensures that the length or magnitude of the vectors does not affect the cosine similarity calculation.
- Cosine Similarity Calculation: Take the dot product of the normalised vectors and divide it by the product of the magnitudes of the vectors to obtain the cosine similarity.
Mathematically, the cosine similarity between two document vectors, a⃗ a and b⃗ b , can be expressed as:
Cosine Similarity(a⃗,b⃗)=a⃗⋅b⃗∣a⃗∣∣b⃗∣Cosine Similarity(a,b)=∣a∣∣b∣a⋅b
Here,
- a⃗⋅b⃗ a⋅b is the dot product of vectors a and b
- |a| and |b| represent the Euclidean norms (magnitudes) of vectors a and b, respectively.
The resulting cosine similarity score ranges from -1 to 1, where 1 represents the highest similarity, 0 represents no similarity, and -1 represents the maximum dissimilarity between the documents.
20. What are the differences between rule-based, statistical-based and neural-based approaches in NLP?
Natural language processing (NLP) uses three distinct approaches to tackle language understanding and processing tasks: rule-based, statistical-based, and neural-based.
- Rule-based Approach: Rule-based systems rely on predefined sets of linguistic rules and patterns to analyze and process language.
- Linguistic Rules are manually crafted rules by human experts to define patterns or grammar structures.
- The knowledge in rule-based systems is explicitly encoded in the rules, which may cover syntactic, semantic, or domain-specific information.
- Rule-based systems offer high interpretability as the rules are explicitly defined and understandable by human experts.
- These systems often require manual intervention and rule modifications to handle new language variations or domains.
- Statistical-based Approach: Statistical-based systems utilize statistical algorithms and models to learn patterns and structures from large datasets.
- By examining the data's statistical patterns and relationships, these systems learn from training data.
- Statistical models are more versatile than rule-based systems because they can train on relevant data from various topics and languages.
- Neural-based Approach: Neural-based systems employ deep learning models, such as neural networks, to learn representations and patterns directly from raw text data.
- Neural networks learn hierarchical representations of the input text, which enable them to capture complex language features and semantics.
- Without explicit rule-making or feature engineering, these systems learn directly from data.
- By training on huge and diverse datasets, neural networks are very versatile and can perform a wide range of NLP tasks.
- In many NLP tasks, neural-based models have attained state-of-the-art performance, outperforming classic rule-based or statistical-based techniques.
21. What do you mean by Sequence in the Context of NLP?
A Sequence primarily refers to the sequence of elements that are analyzed or processed together. In NLP, a sequence may be a sequence of characters, a sequence of words or a sequence of sentences.
In general, sentences are often treated as sequences of words or tokens. Each word in the sentence is considered an element in the sequence. This sequential representation allows for the analysis and processing of sentences in a structured manner, where the order of words matters.
By considering sentences as sequences, NLP models can capture the contextual information and dependencies between words, enabling tasks such as part-of-speech tagging, named entity recognition, sentiment analysis, machine translation, and more.
22. What are the various types of machine learning algorithms used in NLP?
There are various types of machine learning algorithms that are often employed in natural language processing (NLP) tasks. Some of them are as follows:
- Naive Bayes: Naive Bayes is a probabilistic technique that is extensively used in NLP for text classification tasks. It computes the likelihood of a document belonging to a specific class based on the presence of words or features in the document.
- Support Vector Machines (SVM): SVM is a supervised learning method that can be used for text classification, sentiment analysis, and named entity recognition. Based on the given set of features, SVM finds a hyperplane that splits data points into various classes.
- Decision Trees: Decision trees are commonly used for tasks such as sentiment analysis, and information extraction. These algorithms build a tree-like model based on an order of decisions and feature conditions, which helps in making predictions or classifications.
- Random Forests: Random forests are a type of ensemble learning that combines multiple decision trees to improve accuracy and reduce overfitting. They can be applied to the tasks like text classification, named entity recognition, and sentiment analysis.
- Recurrent Neural Networks (RNN): RNNs are a type of neural network architecture that are often used in sequence-based NLP tasks like language modelling, machine translation, and sentiment analysis. RNNs can capture temporal dependencies and context within a word sequence.
- Long Short-Term Memory (LSTM): LSTMs are a type of recurrent neural network that was developed to deal with the vanishing gradient problem of RNN. LSTMs are useful for capturing long-term dependencies in sequences, and they have been used in applications such as machine translation, named entity identification, and sentiment analysis.
- Transformer: Transformers are a relatively recent architecture that has gained significant attention in NLP. By exploiting self-attention processes to capture contextual relationships in text, transformers such as the BERT (Bidirectional Encoder Representations from Transformers) model have achieved state-of-the-art performance in a wide range of NLP tasks.
23. What is Sequence Labelling in NLP?
Sequence labelling is one of the fundamental NLP tasks in which, categorical labels are assigned to each individual element in a sequence. The sequence can represent various linguistic units such as words, characters, sentences, or paragraphs.
Sequence labelling in NLP includes the following tasks.
- Part-of-Speech Tagging (POS Tagging): In which part-of-speech tags (e.g., noun, verb, adjective) are assigned to each word in a sentence.
- Named Entity Recognition (NER): In which named entities like person names, locations, organizations, or dates are recognized and tagged in the sentences.
- Chunking: Words are organized into syntactic units or "chunks" based on their grammatical roles (for example, noun phrase, verb phrase).
- Semantic Role Labeling (SRL): In which, words or phrases in a sentence are labelled based on their semantic roles like Teacher, Doctor, Engineer, Lawyer etc
- Speech Tagging: In speech processing tasks such as speech recognition or phoneme classification, labels are assigned to phonetic units or acoustic segments.
Machine learning models like Conditional Random Fields (CRFs), Hidden Markov Models (HMMs), recurrent neural networks (RNNs), or transformers are used for sequence labelling tasks. These models learn from the labelled training data to make predictions on unseen data.
24.What is topic modelling in NLP?
Topic modelling is Natural Language Processing task used to discover hidden topics from large text documents. It is an unsupervised technique, which takes unlabeled text data as inputs and applies the probabilistic models that represent the probability of each document being a mixture of topics. For example, A document could have a 60% chance of being about neural networks, a 20% chance of being about Natural Language processing, and a 20% chance of being about anything else.
Where each topic will be distributed over words means each topic is a list of words, and each word has a probability associated with it. and the words that have the highest probabilities in a topic are the words that are most likely to be used to describe that topic. For example, the words like "neural", "RNN", and "architecture" are the keywords for neural networks and the words like 'language", and "sentiment" are the keywords for Natural Language processing.
There are a number of topic modelling algorithms but two of the most popular topic modelling algorithms are as follows:
- Latent Dirichlet Allocation (LDA)****:****LDA is based on the idea that each text in the corpus is a mash-up of various topics and that each word in the document is derived from one of those topics. It is assumed that there is an unobservable (latent) set of topics and each document is generated by Topic Selection or Word Generation.
- Non-Negative Matrix Factorization (NMF): NMF is a matrix factorization technique that approximates the term-document matrix (where rows represent documents and columns represent words) into two non-negative matrices: one representing the topic-word relationships and the other the document-topic relationships. NMF aims to identify representative topics and weights for each document.
Topic modelling is especially effective for huge text collections when manually inspecting and categorising each document would be impracticable and time-consuming. We can acquire insights into the primary topics and structures of text data by using topic modelling, making it easier to organise, search, and analyse enormous amounts of unstructured text.
25. What is the GPT?
GPT stands for "Generative Pre-trained Transformer". It refers to a collection of large language models created by OpenAI. It is trained on a massive dataset of text and code, which allows it to generate text, generate code, translate languages, and write many types of creative content, as well as answer questions in an informative manner. The GPT series includes various models, the most well-known and commonly utilised of which are the GPT-2 and GPT-3.
GPT models are built on the Transformer architecture, which allows them to efficiently capture long-term dependencies and contextual information in text. These models are pre-trained on a large corpus of text data from the internet, which enables them to learn the underlying patterns and structures of language.
Advanced NLP Interview Questions for Experienced
26. What are word embeddings in NLP?
Word embeddings in NLP are defined as the dense, low-dimensional vector representations of words that capture semantic and contextual information about words in a language. It is trained using big text corpora through unsupervised or supervised methods to represent words in a numerical format that can be processed by machine learning models.
The main goal of Word embeddings is to capture relationships and similarities between words by representing them as dense vectors in a continuous vector space. These vector representations are acquired using the distributional hypothesis, which states that words with similar meanings tend to occur in similar contexts. Some of the popular pre-trained word embeddings are Word2Vec, GloVe (Global Vectors for Word Representation), or FastText. The advantages of word embedding over the traditional text vectorization technique are as follows:
- It can capture the Semantic Similarity between the words
- It is capable of capturing syntactic links between words. Vector operations such as "king" -- "man" + "woman" may produce a vector similar to the vector for "queen," capturing the gender analogy.
- Compared to one-shot encoding, it has reduced the dimensionality of word representations. Instead of high-dimensional sparse vectors, word embeddings typically have a fixed length and represent words as dense vectors.
- It can be generalized to represent words that they have not been trained on i.e. out-of-vocabulary words. This is done by using the learned word associations to place new words in the vector space near words that they are semantically or syntactically similar to.
27. What are the various algorithms used for training word embeddings?
There are various approaches that are typically used for training word embeddings, which are dense vector representations of words in a continuous vector space. Some of the popular word embedding algorithms are as follows:
- Word2Vec: Word2vec is a common approach for generating vector representations of words that reflect their meaning and relationships. Word2vec learns embeddings using a shallow neural network and follows two approaches: CBOW and Skip-gram
- CBOW (Continuous Bag-of-Words) predicts a target word based on its context words.
- Skip-gram predicts context words given a target word.
- GloVe: GloVe (Global Vectors for Word Representation) is a word embedding model that is similar to Word2vec. GloVe, on the other hand, uses objective function that constructs a co-occurrence matrix based on the statistics of word co-occurrences in a large corpus. The co-occurrence matrix is a square matrix where each entry represents the number of times two words co-occur in a window of a certain size. GloVe then performs matrix factorization on the co-occurrence matrix. Matrix factorization is a technique for finding a low-dimensional representation of a high-dimensional matrix. In the case of GloVe, the low-dimensional representation is a vector representation for each word in the corpus. The word embeddings are learned by minimizing a loss function that measures the difference between the predicted co-occurrence probabilities and the actual co-occurrence probabilities. This makes GloVe more robust to noise and less sensitive to the order of words in a sentence.
- FastText: FastText is a Word2vec extension that includes subword information. It represents words as bags of character n-grams, allowing it to handle out-of-vocabulary terms and capture morphological information. During training, FastText considers subword information as well as word context..
- ELMo: ELMo is a deeply contextualised word embedding model that generates context-dependent word representations. It generates word embeddings that capture both semantic and syntactic information based on the context of the word using bidirectional language models.
- BERT: A transformer-based model called BERT (Bidirectional Encoder Representations from Transformers) learns contextualised word embeddings. BERT is trained on a large corpus by anticipating masked terms inside a sentence and gaining knowledge about the bidirectional context. The generated embeddings achieve state-of-the-art performance in many NLP tasks and capture extensive contextual information.
28. How to handle out-of-vocabulary (OOV) words in NLP?
OOV words are words that are missing in a language model's vocabulary or the training data it was trained on. Here are a few approaches to handling OOV words in NLP:
- ****Character-level models:****Character-level models can be used in place of word-level representations. In this method, words are broken down into individual characters, and the model learns representations based on character sequences. As a result, the model can handle OOV words since it can generalize from known character patterns.
- Subword tokenization: Byte-Pair Encoding (BPE) and WordPiece are two subword tokenization algorithms that divide words into smaller subword units based on their frequency in the training data. This method enables the model to handle OOV words by representing them as a combination of subwords that it comes across during training.
- Unknown token: Use a special token, frequently referred to as an "unknown" token or "UNK," to represent any OOV term that appears during inference. Every time the model comes across an OOV term, it replaces it with the unidentified token and keeps processing. The model is still able to generate relevant output even though this technique doesn't explicitly define the meaning of the OOV word.
- ****External knowledge:****When dealing with OOV terms, using external knowledge resources, like a knowledge graph or an external dictionary, can be helpful. We need to try to look up a word's definition or relevant information in the external knowledge source when we come across an OOV word.
- ****Fine-tuning:****We can fine-tune using the pre-trained language model with domain-specific or task-specific data that includes OOV words. By incorporating OOV words in the fine-tuning process, we expose the model to these words and increase its capacity to handle them.
29. What is the difference between a word-level and character-level language model?
The main difference between a word-level and a character-level language model is how text is represented. A character-level language model represents text as a sequence of characters, whereas a word-level language model represents text as a sequence of words.
Word-level language models are often easier to interpret and more efficient to train. They are, however, less accurate than character-level language models because they cannot capture the intricacies of the text that are stored in the character order. Character-level language models are more accurate than word-level language models, but they are more complex to train and interpret. They are also more sensitive to noise in the text, as a slight alteration in a character can have a large impact on the meaning of the text.
The key differences between word-level and character-level language models are:
| | Word-level | Character-level |
| Text representation | Sequence of words | Sequence of characters |
| Interpretability | Easier to interpret | More difficult to interpret |
| Sensitivity to noise | Less sensitive | More sensitive |
| Vocabulary | Fixed vocabulary of words | No predefined vocabulary |
| Out-of-vocabulary (OOV) handling | Struggles with OOV words | Naturally handles OOV words |
| Generalization | Captures semantic relationships between words | Better at handling morphological details |
| Training complexity | Smaller input/output space, less computationally intensive | Larger input/output space, more computationally intensive |
| Applications | Well-suited for tasks requiring word-level understanding | Suitable for tasks requiring fine-grained details or morphological variations |
|---|
30. What is word sense disambiguation?
The task of determining which sense of a word is intended in a given context is known as word sense disambiguation (WSD). This is a challenging task because many words have several meanings that can only be determined by considering the context in which the word is used.
For example, the word "bank" can be used to refer to a variety of things, including "a financial institution," "a riverbank," and "a slope." The term "bank" in the sentence "I went to the bank to deposit my money" should be understood to mean "a financial institution." This is so because the sentence's context implies that the speaker is on their way to a location where they can deposit money.
31. What is co-reference resolution?
Co-reference resolution is a natural language processing (NLP) task that involves identifying all expressions in a text that refer to the same entity. In other words, it tries to determine whether words or phrases in a text, typically pronouns or noun phrases, correspond to the same real-world thing. For example, the pronoun "he" in the sentence "Pawan Gunjan has compiled this article, He had done lots of research on Various NLP interview questions" refers to Pawan Gunjan himself. Co-reference resolution automatically identifies such linkages and establishes that "He" refers to "Pawan Gunjan" in all instances.
Co-reference resolution is used in information extraction, question answering, summarization, and dialogue systems because it helps to generate more accurate and context-aware representations of text data. It is an important part of systems that require a more in-depth understanding of the relationships between entities in large text corpora.
32.What is information extraction?
Information extraction is a natural language processing task used to extract specific pieces of information like names, dates, locations, and relationships etc from unstructured or semi-structured texts.
Natural language is often ambiguous and can be interpreted in a variety of ways, which makes IE a difficult process. Some of the common techniques used for information extraction include:
- Named entity recognition (NER): In NER, named entities like people, organizations, locations, dates, or other specific categories are recognized from the text documents. For NER problems, a variety of machine learning techniques, including conditional random fields (CRF), support vector machines (SVM), and deep learning models, are frequently used.
- ****Relationship extraction:****In relationship extraction, the connections between the stated text are identified. I figure out the relations different kinds of relationships between various things like "is working at", "lives in" etc.
- Coreference resolution: Coreference resolution is the task of identifying the referents of pronouns and other anaphoric expressions in the text. A coreference resolution system, for example, might be able to figure out that the pronoun "he" in a sentence relates to the person "John" who was named earlier in the text.
- ****Deep Learning-based Approaches:****To perform information extraction tasks, deep learning models such as recurrent neural networks (RNNs), transformer-based architectures (e.g., BERT, GPT), and deep neural networks have been used. These models can learn patterns and representations from data automatically, allowing them to manage complicated and diverse textual material.
33. What is the Hidden Markov Model, and How it's helpful in NLP tasks?
Hidden Markov Model is a probabilistic model based on the Markov Chain Rule used for modelling sequential data like characters, words, and sentences by computing the probability distribution of sequences.
Markov chain uses the Markov assumptions which state that the probabilities future state of the system only depends on its present state, not on any past state of the system. This assumption simplifies the modelling process by reducing the amount of information needed to predict future states.
The underlying process in an HMM is represented by a set of hidden states that are not directly observable. Based on the hidden states, the observed data, such as characters, words, or phrases, are generated.
Hidden Markov Models consist of two key components:
- Transition Probabilities: The transition probabilities in Hidden Markov Models(HMMs) represents the likelihood of moving from one hidden state to another. It captures the dependencies or relationships between adjacent states in the sequence. In part-of-speech tagging, for example, the HMM's hidden states represent distinct part-of-speech tags, and the transition probabilities indicate the likelihood of transitioning from one part-of-speech tag to another.
- Emission Probabilities: In HMMs, emission probabilities define the likelihood of observing specific symbols (characters, words, etc.) given a particular hidden state. The link between the hidden states and the observable symbols is encoded by these probabilities.
- Emission probabilities are often used in NLP to represent the relationship between words and linguistic features such as part-of-speech tags or other linguistic variables. The HMM captures the likelihood of generating an observable symbol (e.g., word) from a specific hidden state (e.g., part-of-speech tag) by calculating the emission probabilities.
Hidden Markov Models (HMMs) estimate transition and emission probabilities from labelled data using approaches such as the Baum-Welch algorithm. Inference algorithms like Viterbi and Forward-Backward are used to determine the most likely sequence of hidden states given observed symbols. HMMs are used to represent sequential data and have been implemented in NLP applications such as part-of-speech tagging. However, advanced models, such as CRFs and neural networks, frequently beat HMMs due to their flexibility and ability to capture richer dependencies.
34. What is the conditional random field (CRF) model in NLP?
Conditional Random Fields are a probabilistic graphical model that is designed to predict the sequence of labels for a given sequence of observations. It is well-suited for prediction tasks in which contextual information or dependencies among neighbouring elements are crucial.
CRFs are an extension of Hidden Markov Models (HMMs) that allow for the modelling of more complex relationships between labels in a sequence. It is specifically designed to capture dependencies between non-consecutive labels, whereas HMMs presume a Markov property in which the current state is only dependent on the past state. This makes CRFs more adaptable and suitable for capturing long-term dependencies and complicated label interactions.
In a CRF model, the labels and observations are represented as a graph. The nodes in the graph represent the labels, and the edges represent the dependencies between the labels. The model assigns weights to features that capture relevant information about the observations and labels.
During training, the CRF model learns the weights by maximizing the conditional log-likelihood of the labelled training data. This process involves optimization algorithms such as gradient descent or the iterative scaling algorithm.
During inference, given an input sequence, the CRF model calculates the conditional probabilities of different label sequences. Algorithms like the Viterbi algorithm efficiently find the most likely label sequence based on these probabilities.
CRFs have demonstrated high performance in a variety of sequence labelling tasks like named entity identification, part-of-speech tagging, and others.
35. What is a recurrent neural network (RNN)?
Recurrent Neural Networks are the type of artificial neural network that is specifically built to work with sequential or time series data. It is utilised in natural language processing activities such as language translation, speech recognition, sentiment analysis, natural language production, summary writing, and so on. It differs from feedforward neural networks in that the input data in RNN does not only flow in a single direction but also has a loop or cycle inside its design that has "memory" that preserves information over time. As a result, the RNN can handle data where context is critical, such as natural languages.
RNNs work by analysing input sequences one element at a time while keeping track in a hidden state that provides a summary of the sequence's previous elements. At each time step, the hidden state is updated based on the current input and the prior hidden state. RNNs can thus capture the temporal connections between sequence items and use that knowledge to produce predictions.
36. How does the Backpropagation through time work in RNN?
Backpropagation through time(BPTT) propagates gradient information across the RNN's recurrent connections over a sequence of input data. Let's understand step by step process for BPTT.
- Forward Pass: The input sequence is fed into the RNN one element at a time, starting from the first element. Each input element is processed through the recurrent connections, and the hidden state of the RNN is updated.
- Hidden State Sequence: The hidden state of the RNN is maintained and carried over from one time step to the next. It contains information about the previous inputs and hidden states in the sequence.
- Output Calculation: The updated hidden state is used to compute the output at each time step.
- Loss Calculation: At the end of the sequence, the predicted output is compared to the target output, and a loss value is calculated using a suitable loss function, such as mean squared error or cross-entropy loss.
- Backpropagation: The loss is then backpropagated through time, starting from the last time step and moving backwards in time. The gradients of the loss with respect to the parameters of the RNN are calculated at each time step.
- Weight Update: The gradients are accumulated over the entire sequence, and the weights of the RNN are updated using an optimization algorithm such as gradient descent or its variants.
- Repeat: The process is repeated for a specified number of epochs or until convergence, during this the training data is iterated through several times.
During the backpropagation step, the gradients at each time step are obtained and used to update the weights of the recurrent connections. This accumulation of gradients over numerous time steps allows the RNN to learn and capture dependencies and patterns in sequential data.
37. What are the limitations of a standard RNN?
Standard RNNs (Recurrent Neural Networks) have several limitations that can make them unsuitable for certain applications:
- Vanishing Gradient Problem: Standard RNNs are vulnerable to the vanishing gradient problem, in which gradients decrease exponentially as they propagate backwards through time. Because of this issue, it is difficult for the network to capture and transmit long-term dependencies across multiple time steps during training.
- Exploding Gradient Problem: RNNs, on the other hand, can suffer from the expanding gradient problem, in which gradients get exceedingly big and cause unstable training. This issue can cause the network to converge slowly or fail to converge at all.
- Short-Term Memory: Standard RNNs have limited memory and fail to remember information from previous time steps. Because of this limitation, they have difficulty capturing long-term dependencies in sequences, limiting their ability to model complicated relationships that span a significant number of time steps.
38. What is a long short-term memory (LSTM) network?
A Long Short-Term Memory (LSTM) network is a type of recurrent neural network (RNN) architecture that is designed to solve the vanishing gradient problem and capture long-term dependencies in sequential data. LSTM networks are particularly effective in tasks that involve processing and understanding sequential data, such as natural language processing and speech recognition.
The key idea behind LSTMs is the integration of a memory cell, which acts as a memory unit capable of retaining information for an extended period. The memory cell is controlled by three gates: the input gate, the forget gate, and the output gate.
The input gate controls how much new information should be stored in the memory cell. The forget gate determines which information from the memory cell should be destroyed or forgotten. The output gate controls how much information is output from the memory cell to the next time step. These gates are controlled by activation functions, which are commonly sigmoid and tanh functions, and allow the LSTM to selectively update, forget, and output data from the memory cell.
39. What is the GRU model in NLP?
The Gated Recurrent Unit (GRU) model is a type of recurrent neural network (RNN) architecture that has been widely used in natural language processing (NLP) tasks. It is designed to address the vanishing gradient problem and capture long-term dependencies in sequential data.
GRU is similar to LSTM in that it incorporates gating mechanisms, but it has a simplified architecture with fewer gates, making it computationally more efficient and easier to train. The GRU model consists of the following components:
- Hidden State: The hidden state ht−1 ht−1 in GRU represents the learned representation or memory of the input sequence up to the current time step. It retains and passes information from the past to the present.
- Update Gate: The update gate in GRU controls the flow of information from the past hidden state to the current time step. It determines how much of the previous information should be retained and how much new information should be incorporated.
- Reset Gate: The reset gate in GRU determines how much of the past information should be discarded or forgotten. It helps in removing irrelevant information from the previous hidden state.
- ****Candidate Activation:****The candidate activation represents the new information to be added to the hidden state ht' ht' . It is computed based on the current input and a transformed version of the previous hidden state using the reset gate.
GRU models have been effective in NLP applications like language modelling, sentiment analysis, machine translation, and text generation. They are particularly useful in situations when it is essential to capture long-term dependencies and understand the context. Due to its simplicity and computational efficiency, GRU makes it a popular choice in NLP research and applications.
40. What is the sequence-to-sequence (Seq2Seq) model in NLP?
Sequence-to-sequence (Seq2Seq) is a type of neural network that is used for natural language processing (NLP) tasks. It is a type of recurrent neural network (RNN) that can learn long-term word relationships. This makes it ideal for tasks like machine translation, text summarization, and question answering.
The model is composed of two major parts: an encoder and a decoder. Here's how the Seq2Seq model works:
- Encoder: The encoder transforms the input sequence, such as a sentence in the source language, into a fixed-length vector representation known as the "context vector" or "thought vector". To capture sequential information from the input, the encoder commonly employs recurrent neural networks (RNNs) such as Long Short-Term Memory (LSTM) or Gated Recurrent Units (GRU).
- ****Context Vector:****The encoder's context vector acts as a summary or representation of the input sequence. It encodes the meaning and important information from the input sequence into a fixed-size vector, regardless of the length of the input.
- Decoder: The decoder uses the encoder's context vector to build the output sequence, which could be a translation or a summarised version. It is another RNN-based network that creates the output sequence one token at a time. At each step, the decoder can be conditioned on the context vector, which serves as an initial hidden state.
During training, the decoder is fed ground truth tokens from the target sequence at each step. Backpropagation through time (BPTT) is a technique commonly used to train Seq2Seq models. The model is optimized to minimize the difference between the predicted output sequence and the actual target sequence.
The Seq2Seq model is used during prediction or generation to construct the output sequence word by word, with each predicted word given back into the model as input for the subsequent step. The process is repeated until either an end-of-sequence token or a predetermined maximum length is achieved.
41. How does the attention mechanism helpful in NLP?
An attention mechanism is a kind of neural network that uses an additional attention layer within an Encoder-Decoder neural network that enables the model to focus on specific parts of the input while performing a task. It achieves this by dynamically assigning weights to different elements in the input, indicating their relative importance or relevance. This selective attention allows the model to focus on relevant information, capture dependencies, and analyze relationships within the data.
The attention mechanism is particularly valuable in tasks involving sequential or structured data, such as natural language processing or computer vision, where long-term dependencies and contextual information are crucial for achieving high performance. By allowing the model to selectively attend to important features or contexts, it improves the model's ability to handle complex relationships and dependencies in the data, leading to better overall performance in various tasks.
42. What is the Transformer model?
Transformer is one of the fundamental models in NLP based on the attention mechanism, which allows it to capture long-range dependencies in sequences more effectively than traditional recurrent neural networks (RNNs). It has given state-of-the-art results in various NLP tasks like word embedding, machine translation, text summarization, question answering etc.
Some of the key advantages of using a Transformer are as follows:
- Parallelization: The self-attention mechanism allows the model to process words in parallel, which makes it significantly faster to train compared to sequential models like RNNs.
- Long-Range Dependencies: The attention mechanism enables the Transformer to effectively capture long-range dependencies in sequences, which makes it suitable for tasks where long-term context is essential.
- ****State-of-the-Art Performance:****Transformer-based models have achieved state-of-the-art performance in various NLP tasks, such as machine translation, language modelling, text generation, and sentiment analysis.
The key components of the Transformer model are as follows:
- Self-Attention Mechanism:
- Encoder-Decoder Network:
- Multi-head Attention:
- Positional Encoding
- Feed-Forward Neural Networks
- Layer Normalization and Residual Connections
43. What is the role of the self-attention mechanism in Transformers?
The self-attention mechanism is a powerful tool that allows the Transformer model to capture long-range dependencies in sequences. It allows each word in the input sequence to attend to all other words in the same sequence, and the model learns to assign weights to each word based on its relevance to the others. This enables the model to capture both short-term and long-term dependencies, which is critical for many NLP applications.
44. What is the purpose of the multi-head attention mechanism in Transformers?
The purpose of the multi-head attention mechanism in Transformers is to allow the model to recognize different types of correlations and patterns in the input sequence. In both the encoder and decoder, the Transformer model uses multiple attention heads. This enables the model to recognise different types of correlations and patterns in the input sequence. Each attention head learns to pay attention to different parts of the input, allowing the model to capture a wide range of characteristics and dependencies.
The multi-head attention mechanism helps the model in learning richer and more contextually relevant representations, resulting in improved performance on a variety of natural language processing (NLP) tasks.
45. What are positional encodings in Transformers, and why are they necessary?
The transformer model processes the input sequence in parallel, so that lacks the inherent understanding of word order like the sequential model recurrent neural networks (RNNs), LSTM possess. So, that. it requires a method to express the positional information explicitly.
Positional encoding is applied to the input embeddings to offer this positional information like the relative or absolute position of each word in the sequence to the model. These encodings are typically learnt and can take several forms, including sine and cosine functions or learned embeddings. This enables the model to learn the order of the words in the sequence, which is critical for many NLP tasks.
46. Describe the architecture of the Transformer model.
The architecture of the Transformer model is based on self-attention and feed-forward neural network concepts. It is made up of an encoder and a decoder, both of which are composed of multiple layers, each containing self-attention and feed-forward sub-layers. The model's design encourages parallelization, resulting in more efficient training and improved performance on tasks involving sequential data, such as natural language processing (NLP) tasks.
The architecture can be described in depth below:
- Encoder:
- Input Embeddings: The encoder takes an input sequence of tokens (e.g., words) as input and transforms each token into a vector representation known as an embedding. Positional encoding is used in these embeddings to preserve the order of the words in the sequence.
- Self-Attention Layers: An encoder consists of multiple self-attention layers and each self-attention layer is used to capture relationships and dependencies between words in the sequence.
- Feed-Forward Layers: After the self-attention step, the output representations of the self-attention layer are fed into a feed-forward neural network. This network applies the non-linear transformations to each word's contextualised representation independently.
- Layer Normalization and Residual Connections: Residual connections and layer normalisation are used to back up the self-attention and feed-forward layers. The residual connections in deep networks help to mitigate the vanishing gradient problem, and layer normalisation stabilises the training process.
- Decoder:
- Input Embeddings: Similar to the encoder, the decoder takes an input sequence and transforms each token into embeddings with positional encoding.
- Masked Self-Attention: Unlike the encoder, the decoder uses masked self-attention in the self-attention layers. This masking ensures that the decoder can only attend to places before the current word during training, preventing the model from seeing future tokens during generation.
- Cross-Attention Layers: Cross-attention layers in the decoder allow it to attend to the encoder's output, which enables the model to use information from the input sequence during output sequence generation.
- Feed-Forward Layers: Similar to the encoder, the decoder's self-attention output passes through feed-forward neural networks.
- Layer Normalization and Residual Connections: The decoder also includes residual connections and layer normalization to help in training and improve model stability.
- Final Output Layer:
- Softmax Layer: The final output layer is a softmax layer that transforms the decoder's representations into probability distributions over the vocabulary. This enables the model to predict the most likely token for each position in the output sequence.
Overall, the Transformer's architecture enables it to successfully handle long-range dependencies in sequences and execute parallel computations, making it highly efficient and powerful for a variety of sequence-to-sequence tasks. The model has been successfully used for machine translation, language modelling, text generation, question answering, and a variety of other NLP tasks, with state-of-the-art results.
47. What is the difference between a generative and discriminative model in NLP?
Both generative and discriminative models are the types of machine learning models used for different purposes in the field of natural language processing (NLP).
Generative models are trained to generate new data that is similar to the data that was used to train them. For example, a generative model could be trained on a dataset of text and code and then used to generate new text or code that is similar to the text and code in the dataset. Generative models are often used for tasks such as text generation, machine translation, and creative writing.
Discriminative models are trained to recognise different types of data. A discriminative model. For example, a discriminative model could be trained on a dataset of labelled text and then used to classify new text as either spam or ham. Discriminative models are often used for tasks such as text classification, sentiment analysis, and question answering.
The key differences between generative and discriminative models in NLP are as follows:
| | Generative Models | Discriminative Models |
| Purpose | Generate new data that is similar to the training data. | Distinguish between different classes or categories of data. |
| Training | Learn the joint probability distribution of input and output data to generate new samples. | Learn the conditional probability distribution of the output labels given the input data. |
| Examples | Text generation, machine translation, creative writing, Chatbots, text summarization, and language modelling. | Text classification, sentiment analysis, and named entity recognition. |
|---|
48. What is machine translation, and how does it is performed?
Machine translation is the process of automatically translating text or speech from one language to another using a computer or machine learning model.
There are three techniques for machine translation:
- Rule-based machine translation (RBMT): RBMT systems use a set of rules to translate text from one language to another.
- Statistical machine translation (SMT): SMT systems use statistical models to calculate the probability of a given translation being correct.
- Neural machine translation (NMT): Neural machine translation (NMT) is a recent technique of machine translation have been proven to be more accurate than RBMT and SMT systems, In recent years, neural machine translation (NMT), powered by deep learning models such as the Transformer, are becoming increasingly popular.
49. What is the BLEU score?
BLEU stands for "Bilingual Evaluation Understudy". It is a metric invented by IBM in 2001 for evaluating the quality of a machine translation. It measures the similarity between machine-generated translations with the professional human translation. It was one of the first metrics whose results are very much correlated with human judgement.
The BLEU score is measured by comparing the n-grams (sequences of n words) in the machine-translated text to the n-grams in the reference text. The higher BLEU Score signifies, that the machine-translated text is more similar to the reference text.
The BLEU (Bilingual Evaluation Understudy) score is calculated using n-gram precision and a brevity penalty.
- N-gram Precision: The n-gram precision is the ratio of matching n-grams in the machine-generated translation to the total number of n-grams in the reference translation. The number of unigrams, bigrams, trigrams, and four-grams (i=1,...,4) that coincide with their n-gram counterpart in the reference translations is measured by the n-gram overlap.
precisioni=Count of matching n-gramscount of all n-grams in the machine translation precisioni=count of all n-grams in the machine translationCount of matching n-grams
For BLEU score precisioni precisioni is calculated for the I ranging (1 to N). Usually, the N value will be up to 4. - Brevity Penalty: Brevity Penalty measures the length difference between machine-generated translations and reference translations. While finding the BLEU score, It penalizes the machine-generated translations if that is found too short compared to the reference translation's length with exponential decay.
brevity-penalty=min(1,exp(1−Reference lengthMachine translation length)))brevity-penalty=min(1,exp(1−Machine translation length)Reference length)) - BLEU Score: The BLEU score is calculated by taking the geometric mean of the individual n-gram precisions and then adjusting it with the brevity penalty.
BLEU=brevity-penalty×exp∑i=1Nlog(precisioni)N=brevity-penalty×explog(∏i=1Nprecisioni)N=brevity-penalty×(∏i=1Nprecisioni)1N BLEU=brevity-penalty×expN∑i=1Nlog(precisioni)=brevity-penalty×expNlog(∏i=1Nprecisioni)=brevity-penalty×(i=1∏Nprecisioni)N1
Here, N is the maximum n-gram size, (usually 4).
The BLEU score goes from 0 to 1, with higher values indicating better translation quality and 1 signifying a perfect match to the reference translation
50. List out the popular NLP task and their corresponding evaluation metrics.
Natural Language Processing (NLP) involves a wide range of tasks, each with its own set of objectives and evaluation criteria. Below is a list of common NLP tasks along with some typical evaluation metrics used to assess their performance:
| Natural Language Processing(NLP) Tasks | Evaluation Metric |
|---|---|
| Part-of-Speech Tagging (POS Tagging) or Named Entity Recognition (NER) | Accuracy, F1-score, Precision, Recall |
| Dependency Parsing | UAS (Unlabeled Attachment Score), LAS (Labeled Attachment Score) |
| Coreference resolution | B-CUBED, MUC, CEAF |
| Text Classification or Sentiment Analysis | Accuracy, F1-score, Precision, Recall |
| Machine Translation | BLEU (Bilingual Evaluation Understudy), METEOR (Metric for Evaluation of Translation with Explicit Ordering) |
| Text Summarization | ROUGE (Recall-Oriented Understudy for Gisting Evaluation), BLEU |
| Question Answering | F1-score, Precision, Recall, MRR(Mean Reciprocal Rank) |
| Text Generation | Human evaluation (subjective assessment), perplexity (for language models) |
| Information Retrieval | Precision, Recall, F1-score, Mean Average Precision (MAP) |
| Natural language inference (NLI) | Accuracy, precision, recall, F1-score, Matthews correlation coefficient (MCC) |
| Topic Modeling | Coherence Score, Perplexity |
| Speech Recognition | Word Error Rate (WER) |
| Speech Synthesis (Text-to-Speech) | Mean Opinion Score (MOS) |
The brief explanations of each of the evaluation metrics are as follows:
- Accuracy: Accuracy is the percentage of predictions that are correct.
- Precision: Precision is the percentage of correct predictions out of all the predictions that were made.
- Recall: Recall is the percentage of correct predictions out of all the positive cases.
- F1-score: F1-score is the harmonic mean of precision and recall.
- MAP(Mean Average Precision): MAP computes the average precision for each query and then averages those precisions over all queries.
- MUC(Mention-based Understudy for Coreference): MUC is a metric for coreference resolution that measures the number of mentions that are correctly identified and linked.
- B-CUBED: B-cubed is a metric for coreference resolution that measures the number of mentions that are correctly identified, linked, and ordered.
- CEAF: CEAF is a metric for coreference resolution that measures the similarity between the predicted coreference chains and the gold standard coreference chains.
- ROC AUC: ROC AUC is a metric for binary classification that measures the area under the receiver operating characteristic curve.
- MRR: MRR is a metric for question answering that measures the mean reciprocal rank of the top-k-ranked documents.
- Perplexity: Perplexity is a language model evaluation metric. It assesses how well a linguistic model predicts a sample or test set of previously unseen data. Lower perplexity values suggest that the language model is more predictive.
- BLEU: BLEU is a metric for machine translation that measures the n-gram overlap between the predicted translation and the gold standard translation.
- METEOR: METEOR is a metric for machine translation that measures the overlap between the predicted translation and the gold standard translation, taking into account synonyms and stemming.
- WER(Word Error Rate): WER is a metric for machine translation that measures the word error rate of the predicted translation.
- MCC: MCC is a metric for natural language inference that measures the Matthews correlation coefficient between the predicted labels and the gold standard labels.
- ROUGE: ROUGE is a metric for text summarization that measures the overlap between the predicted summary and the gold standard summary, taking into account n-grams and synonyms.
- Human Evaluation (Subjective Assessment): Human experts or crowd-sourced workers are asked to submit their comments, evaluations, or rankings on many elements of the NLP task's performance in this technique.
Conclusion
To sum up, NLP interview questions provide a concise overview of the types of questions the interviewer is likely to pose, based on your experience. However, to increase your chance of succeeding in the interview you need to do deep research on company-specific questions that you can find in different platforms such as ambition box, gfg experiences etc. After doing this you feel confident and that helps you to crack your next interview.
You may also Explore:
- Advanced Audio Processing and Recognition with Transformer
- Artificial Intelligence Algorithms
- Deep Learning Tutorial
- TensorFlow Tutorial
Are you passionate about data and looking to make one giant leap into your career? Our Data Science Course will help you change your game and, most importantly, allow students, professionals, and working adults to tide over into the data science immersion. Master state-of-the-art methodologies, powerful tools, and industry best practices, hands-on projects, and real-world applications. Become the executive head of industries related toData Analysis , Machine Learning , and Data Visualization with these growing skills. Ready to Transform Your Future? Enroll Now to Be a Data Science Expert!
Top 50 NLP Interview Questions and Answers 2024 Updated