1. 创建相关配置目录
mkdir -P /data/clickhouse/data
mkdir -P /data/clickhouse/conf
mkdir -P /data/clickhouse/log
2. 拉取镜像
下载最新版本clickhouse
docker pull clickhouse/clickhouse-server
下载指定版本clickhouse
docker pull clickhouse/clickhouse-server:23.1.3.5-alpine
3. 查看 Network ports | ClickHouse Docs 中端口号配置 ,暂时只需要映射8123 9000 两个端口

4. 创建临时容器,用以生成配置文件
容器关闭后会自动删除掉
docker run -d --rm --name clickhouse-server --ulimit nofile=262144:262144 clickhouse/clickhouse-server
5. 将配置文件复制到 /data/clickhouse/conf 路径下
docker cp clickhouse-server:/etc/clickhouse-server/config.xml /data/clickhouse/conf/config.xml
docker cp clickhouse-server:/etc/clickhouse-server/users.xml /data/clickhouse/conf/users.xml
6. 关闭临时容器
docker stop clickhouse-server
7. 启动容器
docker run -d --name=clickhouse-server \
-p 8123:8123 -p 9090:9000 \
--ulimit nofile=262144:262144 \
-v /data/clickhouse/data:/var/lib/clickhouse:rw \
-v /data/clickhouse/conf/config.xml:/etc/clickhouse-server/config.xml \
-v /data/clickhouse/conf/users.xml:/etc/clickhouse-server/users.xml \
-v /data/clickhouse/log:/var/log/clickhouse-server:rw \
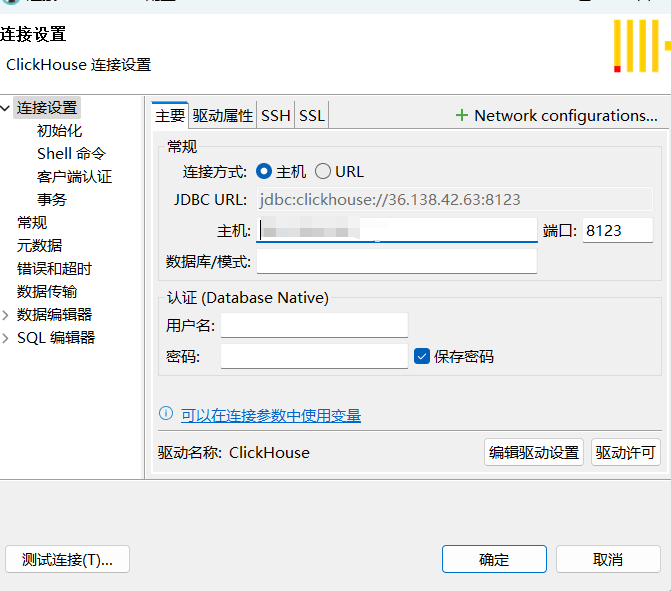
clickhouse/clickhouse-server8. 测试连接
9. 命令形式操作clickhouse
9.1. 查看clickhouse ip
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' d85c6bd07279
9.2. 进入容器
docker exec -it clickhouse-server bash
9.3. 进入客户端
clickhouse-client -m
-m :可以在命令窗口输入多行命令
9.4. 操作
9.4.1. 创建表
ClickHouse中最强大的表引擎当属MergeTree(合并树)引擎及该系列(MergeTree)中的其他引擎,支持索引和分区,地位可以相当于innodb之于Mysql。 而且基于MergeTree,还衍生除了很多小弟,也是非常有特色的引擎。
create table test(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
9.4.2. 插入数据
insert into test values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');
9.4.3. 查看
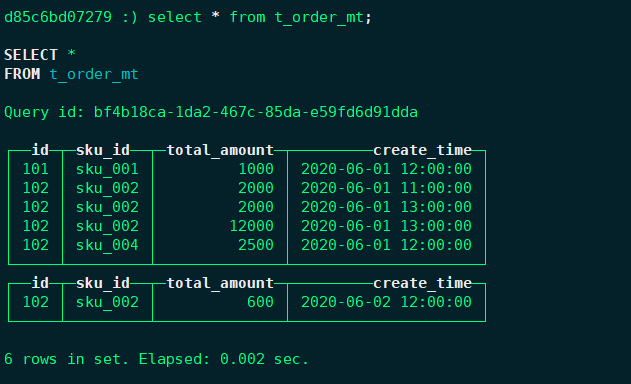
MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文件就会保存到不同的分区目录中。
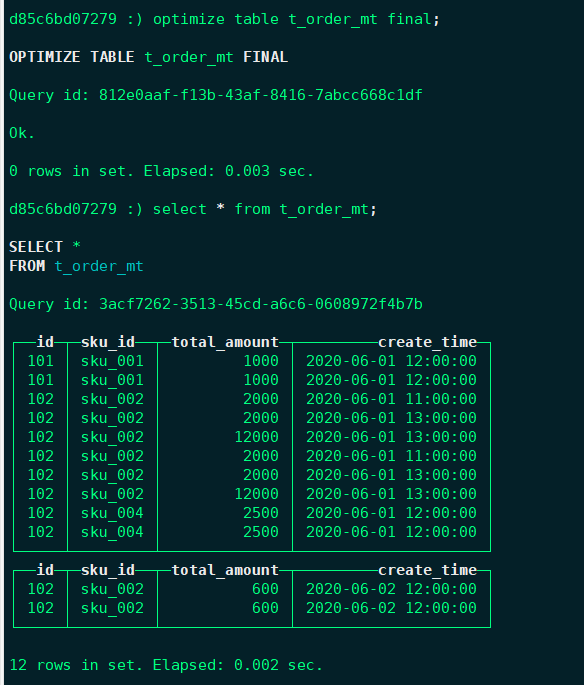
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入后的某个时刻(大概10-15分钟后),ClickHouse会自动执行合并操作(等不及也可以手动通过optimize执行),把临时分区的数据,合并到已有分区中。
再次执行上面的插入操作
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');

optimize table t_order_mt final;
9.5. 主键问题
ClickHouse中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束。这就意味着是可以存在相同primary key的数据的。
主键的设定主要依据是查询语句中的where 条件。
根据条件通过对主键进行某种形式的二分查找,能够定位到对应的index granularity,避免了全表扫描。
index granularity: 直接翻译的话就是索引粒度,指在稀疏索引中两个相邻索引对应数据的间隔。ClickHouse中的MergeTree默认是8192。官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据。