为什么需要连接池?
假设现在没有连接池,每次建立一个新的连接,都需要消耗一定的时间开销(必要时会使用TCP三次握手)。因此,连接的创建和销毁是一件非常昂贵的操作。尤其是在高并发场景下,可能会成为系统的效率屏障。
为了解决连接的创建与销毁,由此诞生出了连接池。(可以简单的理解连接池是一种用于管理和重用连接资源的设计模式)。
连接池的基本思想是维护一定数量的连接,这些连接可以被多次重用,而不是每次需要连接时都新建一个连接。当一个连接不再使用时,它不会立即关闭,而是返回到连接池中,以便下次需要时可以快速获取。
连接池的工作原理
- 初始化:连接池在系统启动时预先创建一定数量的连接,并将这些连接存储在一个池中。
- 获取连接:当应用程序需要进行连接操作时,从连接池中获取一个空闲的连接。如果池中没有空闲连接,可能会等待一段时间,直到有连接被释放。
- 使用连接:应用程序使用获取到的连接进行操作,如数据库查询、网络通信等。
- 释放连接:操作完成后,将连接归还到连接池中,以便其他请求可以重用这个连接。
- 连接管理:连接池定期检查连接的健康状态,关闭不健康的连接,并创建新的连接以补充池中的连接数量。
连接池的优势
- 资源管理和效率
- 减少连接创建和销毁的开销:创建和销毁连接是昂贵的操作,尤其是在高并发环境下。通过使用连接池,可以重用现有的连接,从而减少连接创建和销毁的频率,提升系统的整体效率。
- 降低资源消耗:每个连接(例如数据库连接、网络连接)都会消耗系统资源。连接池可以限制同时打开的连接数量,防止系统资源被耗尽。
- 性能提升
- 提高响应速度:由于连接池中的连接是预先创建好的,使用连接池可以显著减少请求的响应时间。每当有新的请求时,可以直接从池中获取现有的连接,而不是重新建立连接。
- 提供并发支持:连接池可以有效地管理并发连接,确保系统能够高效地处理大量的并发请求,而不会因为频繁的连接创建和销毁而导致性能下降。
- 稳定性和可靠性
-
防止资源枯竭:通过限制连接池的大小,可以避免因过多的并发连接而导致的资源枯竭问题,从而提高系统的稳定性和可靠性。
-
管理连接生命周期:连接池可以定期检查和管理连接的健康状态,关闭不健康的连接,并创建新的连接,从而确保连接的可用性和可靠性。
连接池的适用场景
- 数据库连接池:最常见的连接池场景,通过管理数据库连接,提高数据库操作的效率和性能。
- 网络连接池:在需要频繁进行网络通信的应用中,通过重用网络连接来提高通信效率。
- WebSocket 连接池:在需要处理大量 WebSocket 连接的应用中,通过管理 WebSocket 连接,提升系统的并发处理能力。
连接池的常用参数
1. 最大连接数(Max Connections)
- 定义:连接池中允许存在的最大连接数量。
- 作用:限制连接池中的最大连接数,防止系统资源被耗尽。
- 示例:在数据库连接池中,这个参数设置的是数据库连接的最大数量。
go
db.SetMaxOpenConns(100) // 设置最大打开连接数为 100-
设置过大:
- 影响:系统资源(如内存、文件句柄等)可能会被大量连接占用,导致资源耗尽,影响系统的稳定性和其他进程的运行。
- 场景:在高并发环境下,如果最大连接数设置过大,可能会导致数据库服务器负载过高,响应速度变慢,甚至崩溃。
-
设置过小:
- 影响:连接池中的连接不够用,导致请求被阻塞或延迟,影响系统的响应时间和吞吐量。
- 场景:在负载较高的情况下,如果最大连接数设置过小,可能会导致大量请求被阻塞,用户体验变差。
2. 最大空闲连接数(Max Idle Connections)
- 定义:连接池中允许存在的最大空闲连接数量。
- 作用:保持一定数量的空闲连接,以便快速响应新的连接请求,同时避免过多的空闲连接占用资源。
- 示例:在数据库连接池中,这个参数设置的是数据库连接的最大空闲数量。
go
db.SetMaxIdleConns(10) // 设置最大空闲连接数为 10-
设置过大:
- 影响:空闲连接占用大量资源(如内存、数据库连接),导致资源浪费。
- 场景:如果有大量空闲连接长期存在,可能会导致系统资源被占用,其他进程无法获取足够的资源。
-
设置过小:
- 影响:频繁创建和销毁连接,增加了系统的开销,影响性能。
- 场景:在高并发场景下,如果空闲连接数设置过小,可能会导致频繁的连接创建和释放,增加系统负载,降低效率。
3. 连接最大生命周期(Max Connection Lifetime)
- 定义:连接在连接池中存在的最长时间。
- 作用:防止连接在池中存在过久,导致连接失效或资源泄漏。
- 示例:在数据库连接池中,这个参数设置的是连接的最大生命周期。
go
db.SetConnMaxLifetime(time.Hour) // 设置连接的最大生命周期为 1 小时-
设置过大:
- 影响:连接可能长时间存在,导致连接失效风险增加,可能会持有过期的连接。
- 场景:在长时间运行的系统中,如果连接长期不关闭,可能会导致连接失效,出现连接错误。
-
设置过小:
- 影响:连接频繁被关闭和重建,增加系统开销,降低性能。
- 场景:频繁的连接重建会增加系统负载,特别是在负载较高的情况下,可能会导致性能下降。
4. 空闲连接最大保留时间(Max Idle Time)
- 定义:空闲连接在连接池中保留的最长时间。
- 作用:防止空闲连接长时间不使用,导致资源浪费。
- 示例:在数据库连接池中,这个参数设置的是空闲连接的最大保留时间。
go
db.SetConnMaxIdleTime(30 * time.Minute) // 设置空闲连接的最大保留时间为 30 分钟-
设置过大:
- 影响:空闲连接长时间存在,导致资源浪费。
- 场景:长时间不使用的连接会占用资源,可能会影响系统的整体资源利用率。
-
设置过小:
- 影响:空闲连接过快被关闭,导致频繁创建和销毁连接,增加系统开销。
- 场景:在需要频繁使用连接的场景下,过短的空闲时间会导致频繁的连接重建,增加系统负载。
5. 连接获取超时时间(Connection Acquire Timeout)
- 定义:从连接池中获取连接的最长等待时间。
- 作用:防止客户端长时间等待连接,从而影响系统响应时间。
- 示例:在网络连接池中,这个参数设置的是连接获取的最大等待时间。
go
// 假设我们有一个自定义的连接池
type ConnectionPool struct {
connections chan *Connection
timeout time.Duration
}
// Get 方法中使用超时机制
func (pool *ConnectionPool) Get() (*Connection, error) {
select {
case conn := <-pool.connections:
return conn, nil
case <-time.After(pool.timeout):
return nil, fmt.Errorf("获取连接超时")
}
}-
设置过大:
- 影响:客户端等待时间过长,影响系统响应时间,用户体验变差。
- 场景:在高并发环境下,如果连接获取超时时间设置过长,可能会导致用户长时间等待,影响用户体验。
-
设置过小:
- 影响:频繁触发重试机制,请求的失败率增加。
- 场景:频繁的重试会消耗额外的资源(如CPU和内存),并且可能导致更严重的资源竞争问题。
连接池的通用方法
连接池的 Get 和 Put 操作是连接池管理的核心,它们负责从池中获取连接和将连接归还到池中。这两个操作需要保证线程安全,以防止并发访问导致的数据不一致问题。以下是如何在 Go 中实现连接池的 Get 和 Put 操作。
准备阶段
这里使用SQLDB模拟连接池的实现。
go
type Connection struct {
// 这里可以包含具体连接的信息,例如数据库连接
*sql.DB
}
type ConnectionPool struct {
mu sync.Mutex
connections chan *Connection
maxConnections int
}
// 初始化连接池
func NewConnectionPool(maxConnections int, dsn string) (*ConnectionPool, error) {
pool := &ConnectionPool{
connections: make(chan *Connection, maxConnections),
maxConnections: maxConnections,
}
// 预先创建连接
for i := 0; i < maxConnections; i++ {
conn, err := sql.Open("mysql", dsn)
if err != nil {
return nil, err
}
pool.connections <- &Connection{conn}
}
return pool, nil
}获取连接(Get)
从连接池中获取一个连接。如果池中没有可用连接,可能会等待,直到有连接被释放。
go
func (pool *ConnectionPool) Get() (*Connection, error) {
select {
case conn := <-pool.connections:
// 成功获取到连接
return conn, nil
default:
// 池中没有可用连接,视情况可能创建新连接或者等待
return nil, fmt.Errorf("没有可用的连接")
}
}释放连接(Put)
将连接归还到连接池中,以便其他请求可以重用。需要注意的是,释放连接时需要检查连接的健康状态,如果连接不可用,可能需要重新创建一个新的连接。
go
func (pool *ConnectionPool) Put(conn *Connection) {
select {
case pool.connections <- conn:
// 连接成功归还到池中
default:
// 池已满,关闭连接
conn.Close()
}
}以上是一个简单的 Get 和 Put 操作,没有非常复杂的操作,只是简单的获取和释放。
标准版连接池设计
这里,将带领大家实现一个支持常见连接池参数的 Simple 版的连接池。
首先,介绍一下连接池中两个重要的组件:空闲请求队列 (Idle Request Queue)和阻塞请求队列(Blocking Request Queue)。
基本概念
空闲请求队列用于存放当前空闲的连接。连接池中的连接在不被使用时会被放入该队列,以便其他线程能够迅速获取可用的连接。
特点:
- 快速响应:当线程需要连接时,优先从空闲队列中获取,而不是创建新连接,减少了创建连接的开销。
- 最大连接限制:空闲队列的长度受到连接池的最大连接数的限制。当有足够的空闲连接时,新的连接不再创建,避免了资源浪费。
- 自动复用:当线程释放连接时,会将该连接放入空闲队列供其他线程复用。
工作流程:
- Get 操作:线程从空闲请求队列中取出一个可用连接。如果队列为空,则需要查看是否可以创建新连接。
- Put 操作:线程将用完的连接放回空闲队列。如果空闲队列已满,可以选择销毁该连接或者等待一段时间后再尝试归还。
阻塞请求队列用于存放那些由于没有可用连接而被迫等待的请求。在连接池中,当所有连接都在使用,且无法创建更多连接时,新的连接请求就会被放入阻塞请求队列进行等待,直到有连接归还或被释放。
特点:
- 请求等待:当连接池中的所有连接都被占用时,新的请求不会立即被拒绝,而是进入阻塞请求队列等待空闲连接。
- 超时机制:在阻塞队列中的请求可以设置超时,超过指定时间仍无法获取连接的请求可以抛出超时异常。
- 公平调度:阻塞请求队列可以采用先进先出的(FIFO)方式管理,以确保连接的公平分配。
工作流程:
- 阻塞等待:当连接池中的连接已用完,新的请求进入阻塞队列等待。
- 连接归还时通知:当有连接被归还到空闲队列时,阻塞队列中的请求会被唤醒并获取到连接。
- 超时处理:如果某个请求在阻塞队列中等待时间超过指定阈值,可以选择抛出超时异常。
基本概念实现:
go
type Option func(p *SimplePool)
type conn struct {
c net.Conn
lastActive time.Time
}
type conReq struct {
con chan conn
}
type SimplePool struct {
idleChan chan conn // 空闲连接
waitChan chan *conReq // 阻塞的请求
factory func() (net.Conn, error) // 连接工厂
idleTimeOut time.Duration // 空闲时间
maxCnt int32 // 最大连接数
cnt int32 // 当前连接数
l sync.Mutex // 锁
}
func NewSimplePool(factory func() (net.Conn, error), opt ...Option) *SimplePool {
res := &SimplePool{
idleChan: make(chan conn, 100),
waitChan: make(chan *conReq, 100),
factory: factory,
maxCnt: 100,
}
for _, o := range opt {
o(res)
}
return res
}
// WithMaxIdleCnt 设置最大空闲连接数
func WithMaxIdleCnt(maxIdleCnt int32) Option {
return func(p *SimplePool) {
p.idleChan = make(chan conn, maxIdleCnt)
}
}
// WithMaxCnt 设置最大连接数量
func WithMaxCnt(maxCnt int32) Option {
return func(p *SimplePool) {
p.maxCnt = maxCnt
}
}接下来,我们详细的讲解一下,Get 和 Put 操作。
Get
Get 操作的目的是从连接池中获取一个可用的连接,如果没有可用连接且未达到最大连接数,则创建一个新的连接。
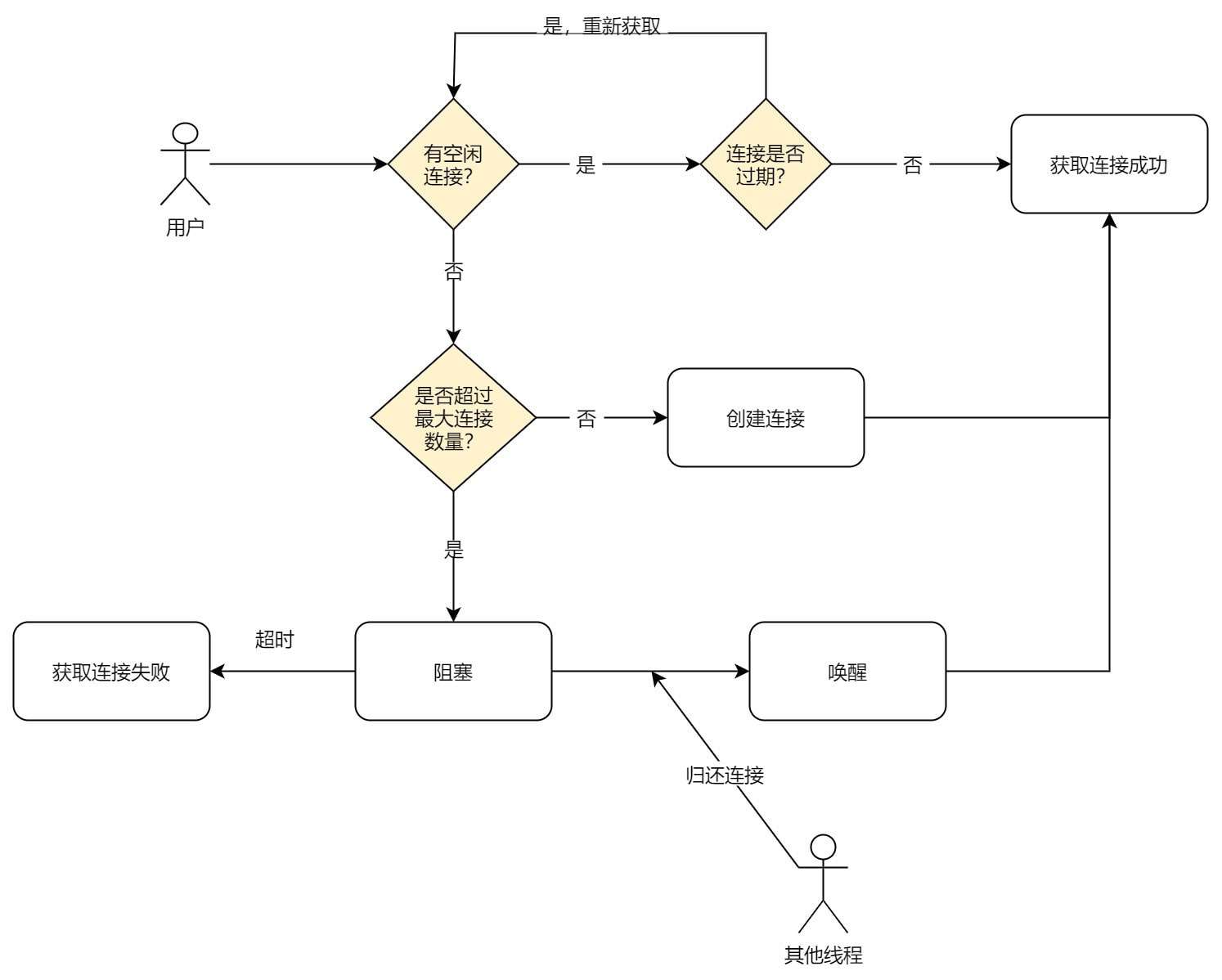
步骤:
- 获取锁:确保线程安全。
- 检查空闲请求队列 :
如果有空闲连接,直接从空闲队列中取出连接并返回。 - 检查当前连接数 :
如果当前连接数小于最大连接数,创建一个新连接,增加当前连接数,并返回该连接。 - 阻塞等待 :
- 如果没有空闲连接且当前连接数已达到最大值,将当前请求加入阻塞请求队列,并等待连接释放。
- 可以设置超时机制,若在指定时间内未获取到连接,则抛出异常或返回错误。
流程图大致如下所示:
go
func (p *SimplePool) Get() (net.Conn, error) {
for {
select {
// 当有空闲的时候,首先从空闲队列中取
case c := <-p.idleChan:
// 如果空闲时间超过了,则关闭连接
if c.lastActive.Add(p.idleTimeOut).Before(time.Now()) {
// 使用原子操作减少计数
atomic.AddInt32(&p.cnt, -1)
_ = c.c.Close()
continue
}
return c.c, nil
// 如果没有空闲的,则创建新的连接
default:
// 判断是否超过最大连接数
cnt := atomic.AddInt32(&p.cnt, 1)
// 如果没有超过,则创建新的连接
if cnt <= p.maxCnt {
return p.factory()
}
// 如果超过了,则等待
atomic.AddInt32(&p.cnt, -1)
req := &conReq{
con: make(chan conn, 1),
}
p.waitChan <- req
c := <-req.con
return c.c, nil
}
}
}Put
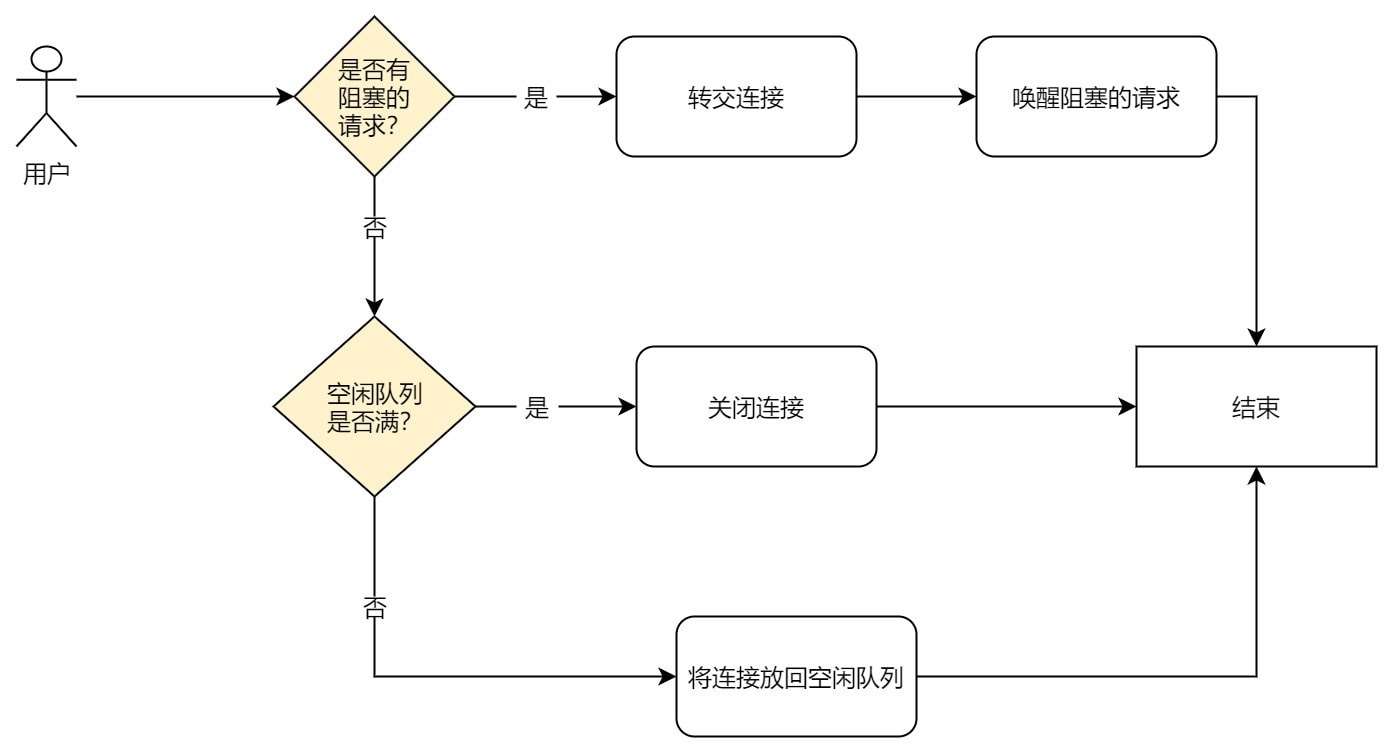
Put 操作的目的是将使用完的连接归还到连接池中,以便其他线程可以重用该连接。
步骤:
- 获取锁:确保线程安全。
- 验证连接有效性 :
- 如果连接有效,将其放回空闲请求队列。
- 如果连接无效,则销毁该连接并减少当前连接数。
- 通知阻塞请求队列 :
如果有线程在阻塞请求队列中等待获取连接,通知其中一个线程使其能够获取到刚归还的连接。 - 确保最小连接数 :
如果归还后空闲连接数低于最小连接数,可以预先创建新的连接以满足最小要求。
流程图大致如下所示:
go
func (p *SimplePool) Put(c net.Conn) {
// 如果有阻塞的,直接转交连接
p.l.Lock()
if len(p.waitChan) > 0 {
req := <-p.waitChan
p.l.Unlock()
req.con <- conn{
c: c,
lastActive: time.Now(),
}
return
}
p.l.Unlock()
// 没有阻塞时候
select {
// 如果空闲队列没有满,则放入空闲队列
case p.idleChan <- conn{c: c, lastActive: time.Now()}:
default:
// 如果满了,则关闭连接
defer func() {
atomic.AddInt32(&p.cnt, -1)
}()
_ = c.Close()
}
}额外考虑
- 连接的健康检查:可以在
Get操作时或定期对池中的连接进行健康检查,以确保连接可用性。 - 超时处理:
Get操作可以设置一个超时,当超过指定时间仍无法获取连接时抛出异常。 - 连接的生命周期管理:设置连接的最大空闲时间和生命周期,以避免长时间未使用的连接导致资源浪费或连接问题。
总结
在连接池的设计中,空闲请求队列 和阻塞请求队列共同作用,确保连接的高效利用和系统的稳定性。空闲请求队列负责管理可用的连接资源,而阻塞请求队列则处理并发请求的等待和调度。通过合理的同步机制和队列管理策略,可以实现一个高性能、可靠的连接池,满足多线程环境下的资源共享需求。
进一步优化
为了进一步优化连接池的性能和可靠性,可以考虑以下几点:
- 动态调整连接数:根据负载动态调整连接池中的连接数,例如在高并发时增加连接数,在低负载时减少连接数。
- 连接健康检查:定期检查连接的健康状态,提前回收无效连接,避免请求因获取无效连接而失败。
- 日志与监控:记录连接池的使用情况,如连接获取和释放的频率、等待时间等,便于监控和优化。
- 异常处理:完善异常处理机制,确保在连接获取或归还过程中发生错误时,能够正确处理连接状态,防止资源泄漏。
通过综合考虑这些因素,可以设计出一个功能完备、性能优越的连接池,满足各种应用场景的需求。