本文将介绍如何在流量高峰之前使用KEDA和Cron scaler主动调整工作负载规模。
在设计Kubernetes集群时,我们可能经常需要回答以下问题:
- 集群伸缩需要多长时间?
- 在新Pod创建之前需要等待多长时间?
有四个主要因素会影响集群的伸缩:
- Horizontal Pod Autoscaler的反应时间;
- Cluster Autoscaler的反应时间;
- 节点预配时间;以及
- Pod创建时间。
下文将依次讨论这些因素。
默认情况下,kubelet每10秒从Pod中提取一次CPU使用情况数据,而Metrics Server每1分钟从kubelet获取一次这些数据。Horizontal Pod Autoscaler每30秒检查一次CPU和内存度量。
如果度量超过阈值,Autoscaler会增加Pod的副本数,并在采取进一步行动之前暂停3分钟。在最糟糕的情况下,可能要等待长达3分钟才能添加或删除Pod,但平均而言,用户应该期望等待1分钟后Horizontal Pod Autoscaler即可触发伸缩。

Horizontal Pod Autoscaler的反应时间
Cluster Autoscaler会检查是否有待处理的Pod,并增加集群的大小。检测到需要扩展集群可能需要:
- 在具有少于100个节点和3000个Pod的集群上最多需要30秒,平均延迟约为5秒;或
- 在具有100个以上节点的集群上最多需要60秒的延迟,平均延迟约为15秒。
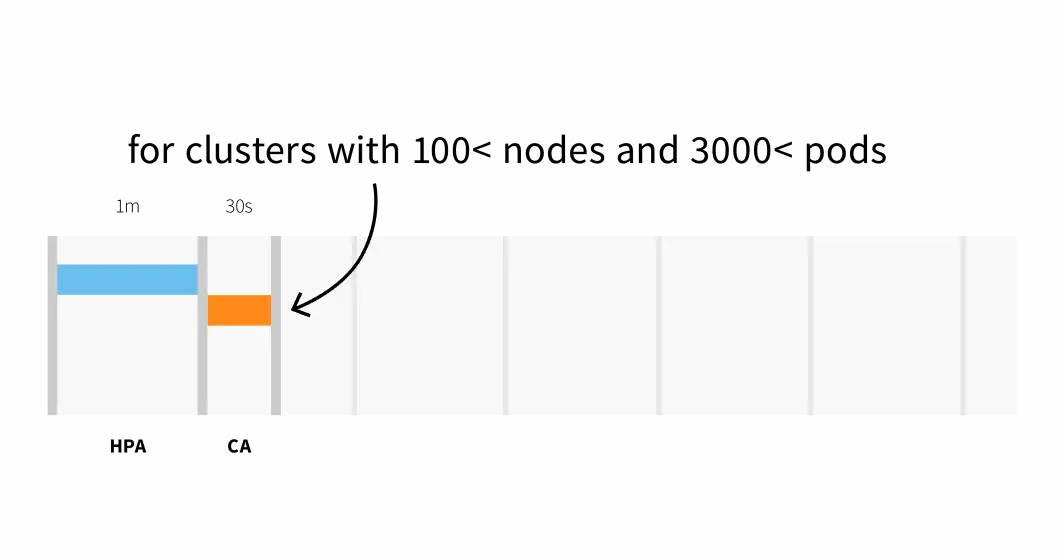
Cluster Autoscaler的反应时间
Linode上的节点预配,也就是从Cluster Autoscaler触发API到新创建节点上可以调度Pod,这一过程需要大约3-4分钟时间。
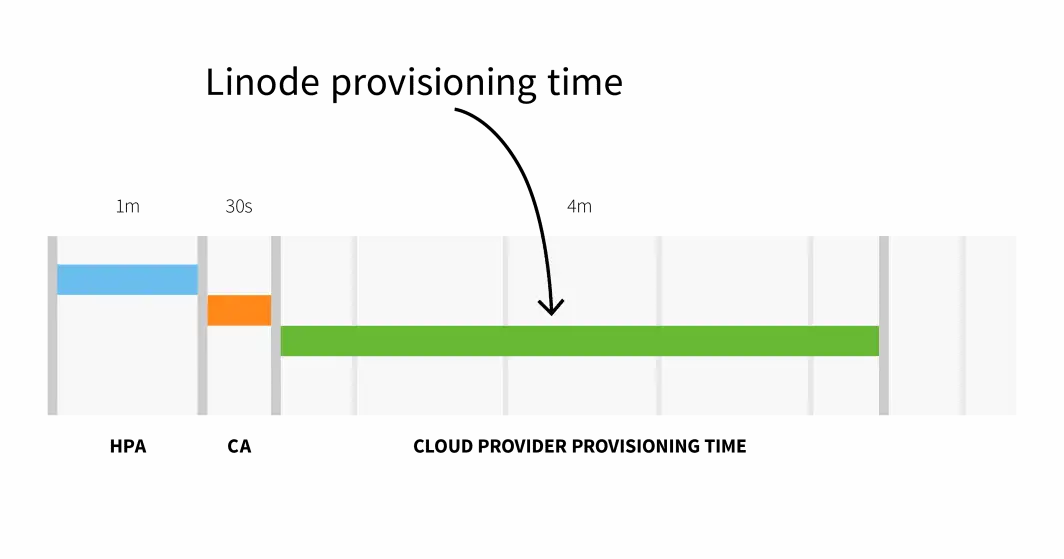
Linode的预配时间
简而言之,对于小规模集群,我们会面临:
HPA延迟: 1m +
CA延迟: 0m30s +
云提供商: 4m +
容器运行时: 0m30s +
=========================
总计 6m
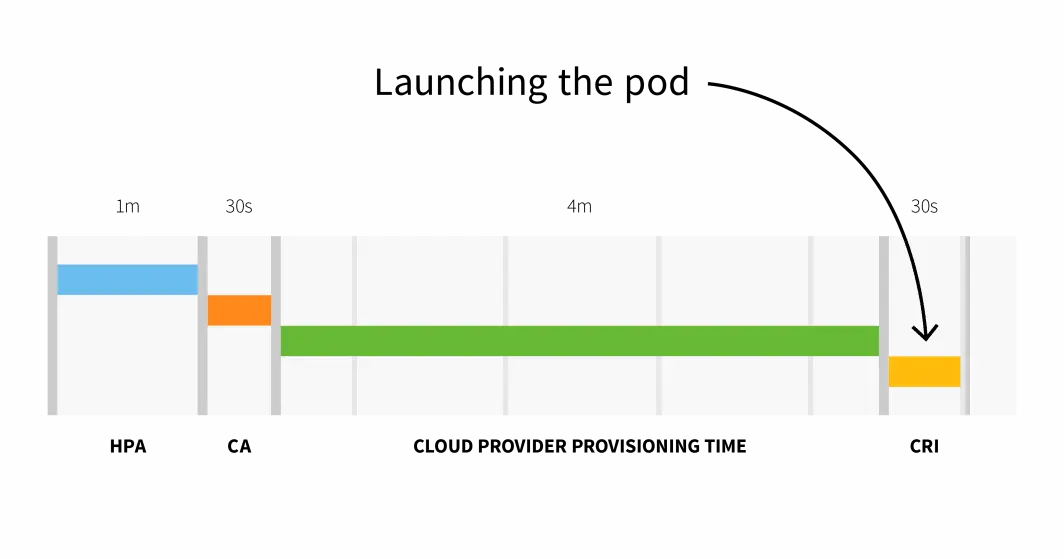
端到端Autoscaler反应时间
对于具有100个以上节点的集群,总延迟可能为6分30秒......这是一个相当长的时间,那么该如何解决这个问题?可以主动调整工作负载,或者如果非常了解流量模式,也可以提前伸缩。
使用KEDA进行预伸缩
如果流量的变化模式可预测,那么在高峰之前扩展工作负载(和节点)就是可行的。
Kubernetes没有提供根据日期或时间扩展工作负载的机制,因此我们将介绍如何使用KEDA(Kubernetes Event Driven Autoscaler)实现我们的目标。
KEDA由三个组件组成:
-
一个伸缩器;
-
一个指标适配器;以及
-
一个控制器。
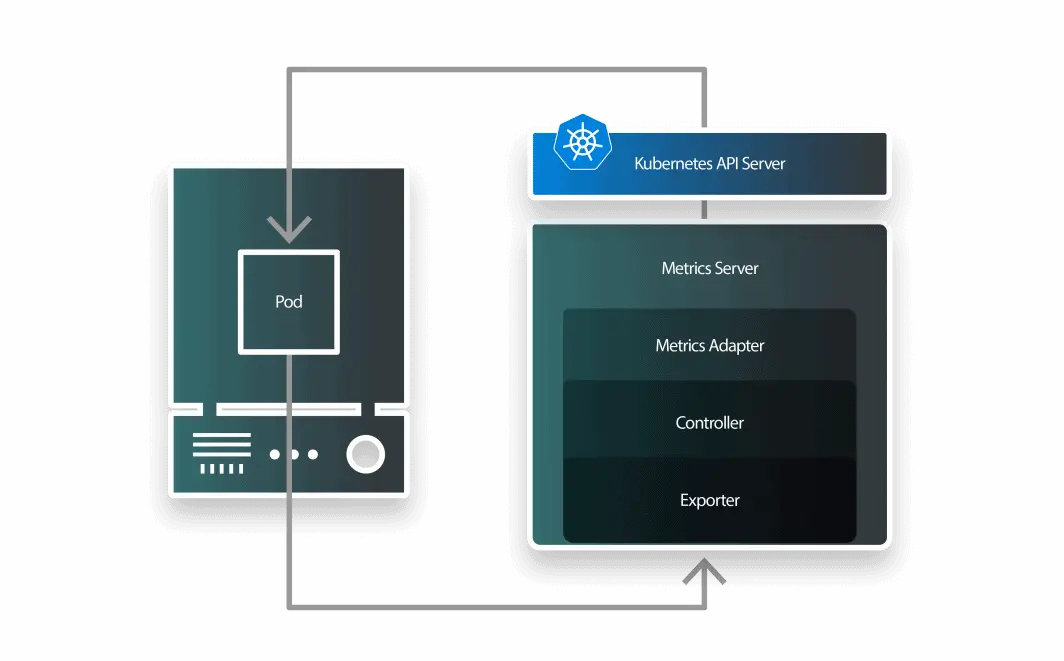
KEDA的架构
我们可以使用Helm安装KEDA:
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda安装好Prometheus和KEDA后,让我们创建一个部署。
apiVersion: apps/v1
kind: Deployment
metadata:
name: https://zhida.zhihu.com/search?q=podinfo&zhida_source=entity&is_preview=1
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo用下列命令将资源提交到集群:
$ kubectl apply -f deployment.yaml
KEDA在现有的Horizontal Pod Autoscaler之上工作,并使用名为ScaleObject的自定义资源定义(CRD)进行包装。下列ScaledObject使用Cron Scaler定义了更改副本数的时间窗口:
apiVersion: keda.sh/https://zhida.zhihu.com/search?q=v1alpha1&zhida_source=entity&is_preview=1
kind: ScaledObject
metadata:
name: https://zhida.zhihu.com/search?q=cron-scaledobject&zhida_source=entity&is_preview=1
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 1
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 23 * * * *
end: 28 * * * *
desiredReplicas: "5"用下列命令提交对象:
$ kubectl apply -f scaled-object.yaml接下来会发生什么?什么也不会发生。自动伸缩只会在23 * * * *到28 * * * *之间触发。在Cron Guru的帮助下,我们可以将这两个Cron表达式翻译成:
- 从第23分钟开始(例如2:23、3:23等)。
- 在第28分钟停止(例如2:28、3:28等)。
如果等到开始时间,我们将注意到副本数增加到5。
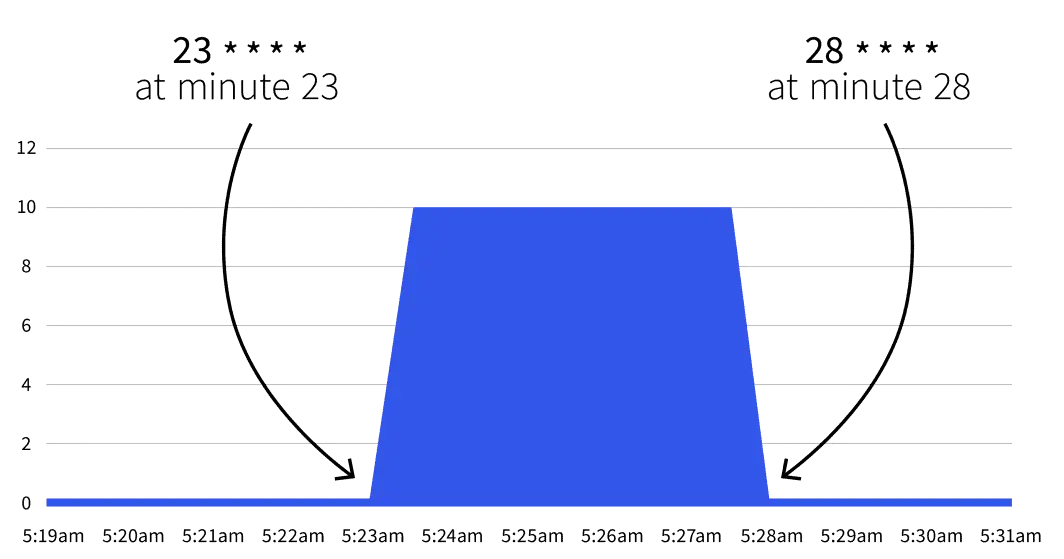
使用KEDA通过Cron表达式进行伸缩
在第28分钟后,副本数是否恢复到1?是的,自动伸缩器会恢复为minReplicaCount中指定的副本数。
如果在其中一个时间间隔内增加副本数会发生什么?如果在23和28分钟之间,我们将部署的副本数扩展到10,KEDA将覆盖我们的更改并设置计数。如果在第28分钟后重复相同实验,副本数将设置为10。
在了解了理论后,让我们看一些实际用例。
在工作时间内伸缩
假设我们在开发环境中部署了一个应该在工作时间段内处于活跃状态,并且在夜间应该关闭的工作负载。
我们可以使用以下ScaledObject:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * *
end: 0 17 * * *
desiredReplicas: "10"默认副本数为零,但在工作时间(上午9点到下午5点)期间,副本会扩展到10个。
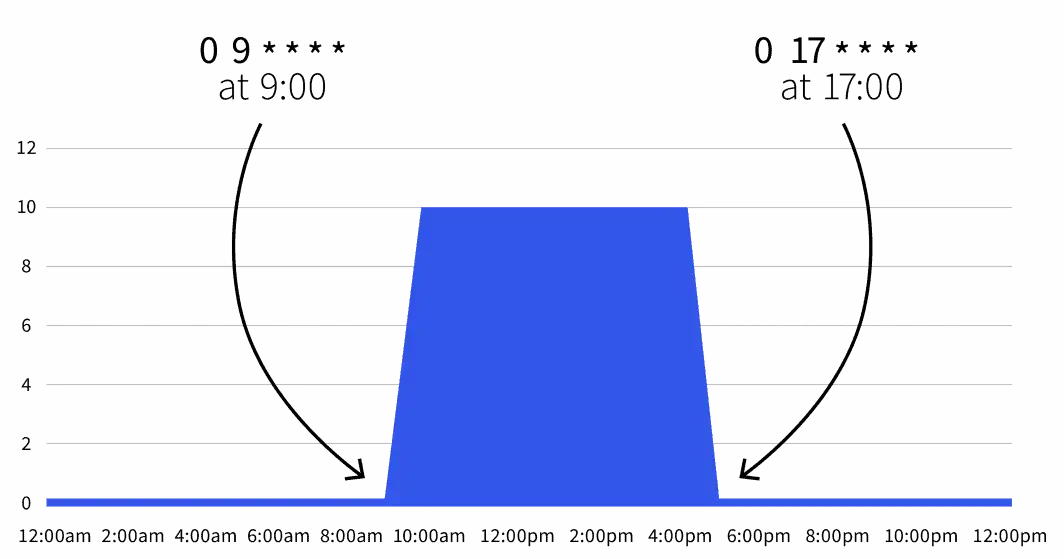
仅在工作时间内扩展工作负载
我们还可以扩展Scaled Object以排除周末:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"这样,我们的工作负载将仅在周一至周五的9点到17点活跃。由于可以组合多个触发器,因此还可以包括一些例外情况。
在周末伸缩
例如,我们可能计划在星期三让工作负载保持更长时间,为此可使用以下定义:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
- type: cron
metadata:
timezone: Europe/London
start: 0 17 * * 3
end: 0 21 * * 3
desiredReplicas: "10"在此定义中,工作负载会在周一至周五的9点到17点之间处于活动状态,但星期三会从9点持续到21点。
总结
KEDA cron自动伸缩器可以让我们定义一个时间范围,在此范围内缩放工作负载。这有助于在流量高峰之前扩展Pod,从而提前触发Cluster Autoscaler。
本文介绍了Cluster Autoscaler的工作原理、水平扩展和向集群添加节点需要的时间,以及如何使用KEDA根据Cron表达式扩展应用程序。