如果遇到使用 ajax 加载的网页,页面元素可能不是同时加载出来的,这个时候尝试在 get 方法执行完
成时获取网页源代码可能并非浏览器完全加载完成的页面。所以,这种情况下需要设置延时等待一定时间,确保全部节点都加载出来。
那么,有三种方式可以选择:强制等待、隐式等待和显式等待。
延时等待
1. 强制等待
这个实现就非常简单了,直接 time.sleep(n) 强制等待n秒,在执行 get 方法之后执行。
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
s = Service(r'D:\driver\chromedriver.exe')
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
# 打开百度
browser.get(r'https://www.baidu.com')
time.sleep(5)
# 关闭浏览器
browser.quit()2. 隐式等待
通过 implicitly_wait() 方法设置等待时间,如果到时间有元素节点没有加载出来,就会抛出异常。
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
s = Service(r'D:\driver\chromedriver.exe')
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
# 打开百度
browser.get(r'https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.quit()3. 显式等待
设置一个等待时间和一个条件,在规定时间内,每隔一段时间查看下条件是否成立,如果成立那么程序就继续执行,否则就抛出一个超时异常。
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.common.by import By
import time
s = Service(r'D:\driver\chromedriver.exe')
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
# 打开百度
browser.get(r'https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(ec.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(5)
browser.quit()
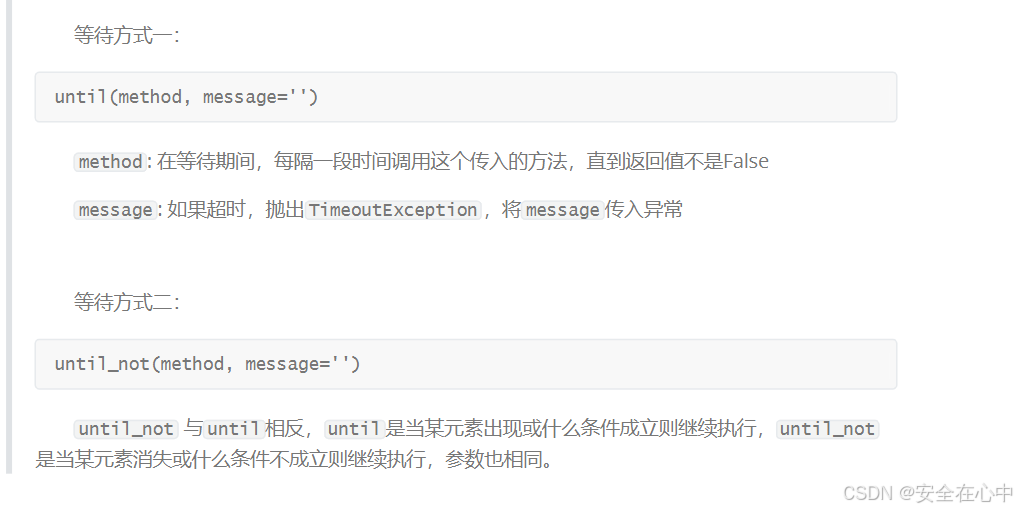
其它等待条件
以下只列出了对应函数名,参数请自行参考函数定义传入。
from selenium.webdriver.support import expected_conditions as ec
判断标题是否和预期的一致
ec.title_is()
判断标题中是否包含预期的字符串
ec.title_contains()
判断指定元素是否加载出来
ec.presence_of_element_located()
判断所有元素是否加载完成
ec.presence_of_all_elements_located()
判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的
locator
ec.visibility_of_element_located()
判断元素是否可见,传入参数是定位后的元素WebElement
ec.visibility_of()
判断某个元素是否不可见,或是否不存在于DOM树
ec.invisibility_of_element_located()
判断元素的 text 是否包含预期字符串
ec.text_to_be_present_in_element()
判断元素的 value 是否包含预期字符串
ec.text_to_be_present_in_element_value()
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
ec.frame_to_be_available_and_switch_to_it()
#判断是否有alert出现
ec.alert_is_present()
#判断元素是否可点击
ec.element_to_be_clickable()
判断元素是否被选中,一般用在下拉列表,传入WebElement对象
ec.element_to_be_selected()
判断元素是否被选中
ec.element_located_to_be_selected()
判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
ec.element_selection_state_to_be()
判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
ec.element_located_selection_state_to_be()
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
ec.staleness_of()
运行JavaScript
我们还需要模拟一些操作,比如下拉页面滚动条,模拟 javaScript ,那么可以使用
execute_script方法来实现。
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
s = Service(r'D:\driver\chromedriver.exe')
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
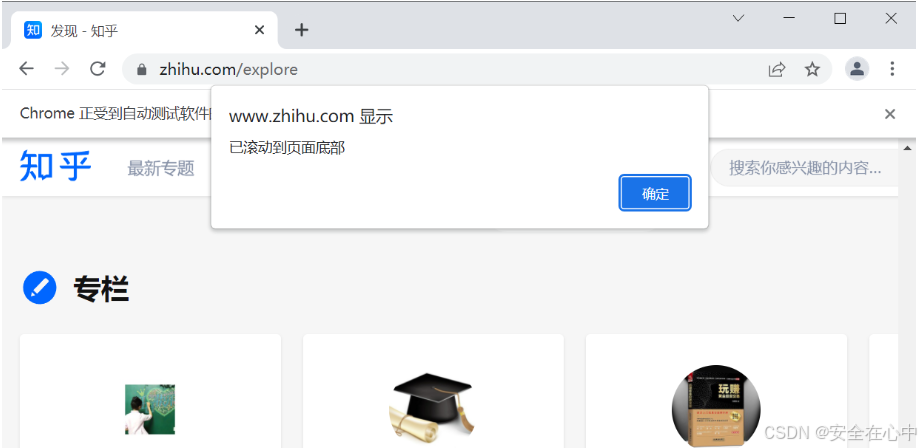
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("已滚动到页面底部")')
# 关闭浏览器
time.sleep(5)
browser.quit()这段代码的作用是使用浏览器的 JavaScript 引擎将网页滚动到页面的底部。具体来说:
`window.scrollTo(x, y)` 是一个 JavaScript 方法,用于滚动浏览器窗口到指定的坐标位置。
`0` 是水平坐标位置,表示滚动到页面的最左边。
`document.body.scrollHeight` 是文档的总高度,表示滚动到页面的最底部。
所以,`window.scrollTo(0, document.body.scrollHeight)` 这段代码会将网页的滚动条滚动到页面的最底部。
效果如下:
操作Cookie
在 selenium 使用过程中,还可以很方便对 Cookie 进行获取、添加与删除等操作。
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
s = Service(r'D:\driver\chromedriver.exe')
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome(service=s)
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'cookies的值:ibrowser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'有霸夫', 'value':'youbafu'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
# 关闭浏览器
time.sleep(5)
browser.quit()输出:
