无论您的提示和模型有多好,一次性获得完美图像的情况很少见。
修复小缺陷的不可或缺的方法是图像修复(inpainting)。在这篇文章中,我将通过一些基本示例来介绍如何使用图像修复来修复缺陷。
需要的软件
我们将使用 AUTOMATIC1111 Stable Diffusion GUI 来创建图像。
基本的图像修复设置
在这一部分,我将逐步展示如何使用图像修复来修复小缺陷。
我们先使用下面的提示来创建一张图片:
正向提示词:
txt
masterpiece,best quality,masterpiece,best quality,official art,extremely detailed CG unity 8k wallpaper,a beautiful woman,full body,负向提示词:
txt
lowers,monochrome,grayscales,skin spots,acnes,skin blemishes,age spot,6 more fingers on one hand,deformity,bad legs,error legs,bad feet,malformed limbs,extra limbs,我们可以得到下面的图片:

虽然这张图片整体上看起来还不错,但是还是有一些问题。
比如脸部和手部。
那么接下来我们怎么修复呢?
选择对应的模型
如果你经常浏览C站的话,你可以看到对于有些模型会有一种专门给重绘使用的模型,这种模型是专门为图像修复而训练的Stable Diffusion模型。
如果您想获得最佳结果,可以使用它。但通常,使用生成图像的相同模型进行图像修复也是可以的。
我们把对应的模型下载下来,并将其放入文件夹中:
stable-diffusion-webui/models/Stable-diffusion
在AUTOMATIC1111中,点击左上角检查点选择下拉框旁边的刷新图标,就可以看到你刚刚下载的模型了。
创建图像修复遮罩
在AUTOMATIC1111 GUI中,选择img2img 标签并选择Inpaint子标签。将图像上传到图像修复画布。
或者在txt2img标签中选择send img to inpaint。
我们将同时修复手部和脸部。使用画笔工具创建一个遮罩。这是您希望Stable Diffusion重新生成图像的区域。
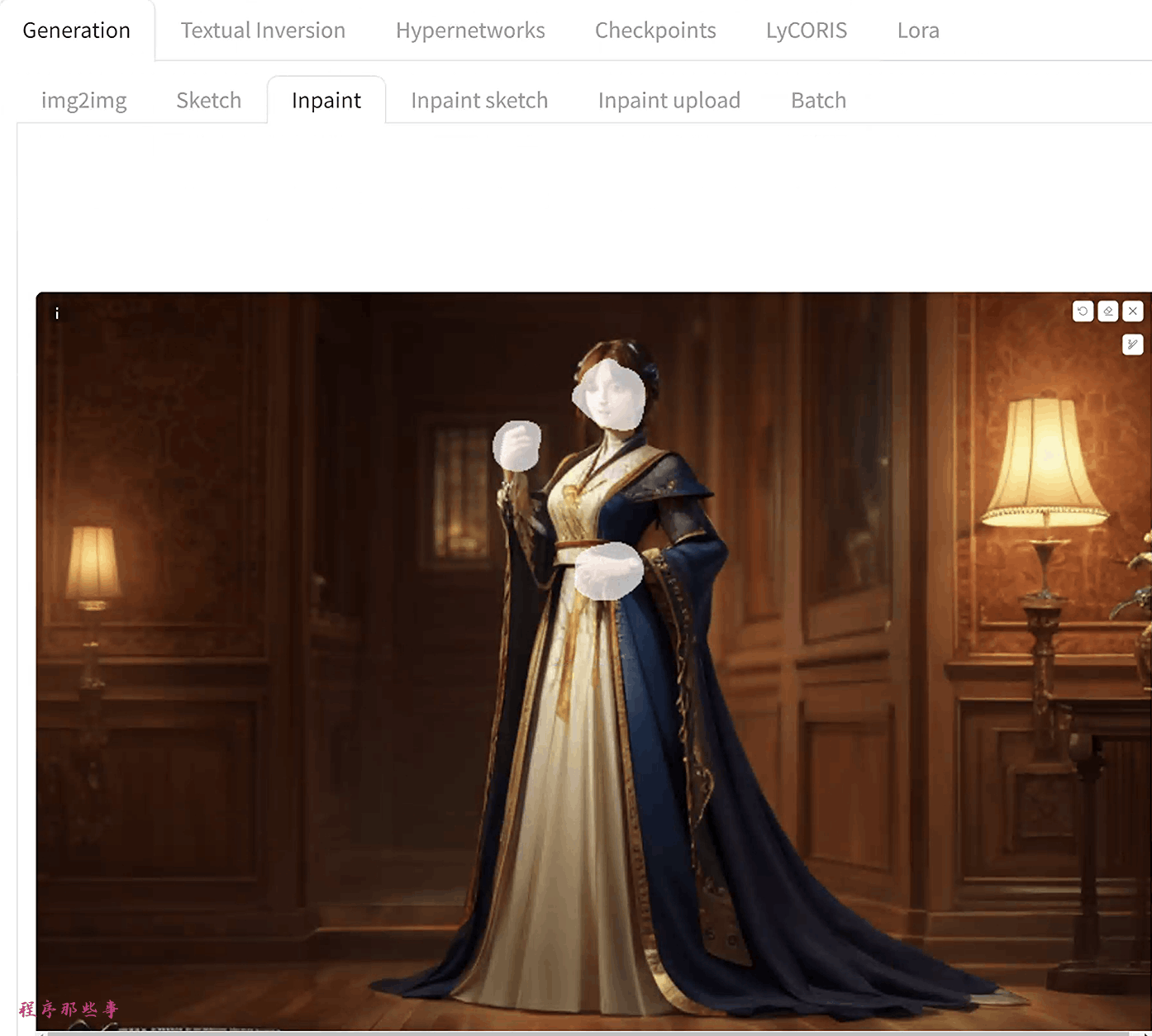
图像修复的设置
图像大小
需要调整图像大小以与原始图像相同。(在这种情况下为768 x 512)。

面部修复
如果您正在修复面部,可以打开restore faces。选择对应的face restoration model:CodeFormer。

有朋友会问了,为什么我的页面上面没有restore faces选项呢?
如果你没有这个选项的话,需要到setttings里面的user interface添加下面的两个设置:

请注意,此选项可能会生成不自然的外观。它也可能生成与模型风格不一致的内容。
遮罩内容
下一个重要设置是Masked Content。
如果您希望结果由原始内容的颜色和形状引导,请选择original。
original通常用于面部图像修复,因为一般形状和解剖结构是正确的。我们只是希望它看起来有点不同。
在大多数情况下,您将使用original 并更改去噪强度以实现不同的效果。
如果您想要从原始图像中完全重新生成某些内容,例如移除一个肢体或隐藏一只手,可以使用latent noise 或latent nothing。
这些选项使用与原始图像不同的内容初始化遮罩区域。它将产生完全不同的东西。
去噪强度
去噪强度控制与原始图像相比将进行多少变化。当您将其设置为0时,什么都不会改变。当您将其设置为1时,您将获得一个不相关的图像。0.75通常是一个很好的起点。如果您想要更少的变化,请降低它。
批量大小
确保一次生成一些图像,以便您可以选择最好的。将种子设置为-1,以便每个图像都不同。
图像修复结果
以下是一些修复后的图像。

可以看到第四张还是不错的,但是还不够完美。所以我们可以考虑再来一轮修复。
再进行一轮图像修复
把上面生成的最后一张图片再发到inpait中再次修复。
我们可以得到下面的结果:

图像修复是一个迭代过程。您可以根据需要多次应用它来细化图像。
如果一次不行的话,我们可以考虑多来几次。
添加新对象
有时,您可能希望在图像中添加一些新东西。
让我们尝试在图片中添加一把剑。
首先,将图像上传到图像修复画布并在手部的位置添加遮罩。
在原始提示的开头添加"holding a sword"。图像修复的提示是
txt
(holding a sword:1.5),masterpiece,best quality,masterpiece,best quality,official art,extremely detailed CG unity 8k wallpaper,a beautiful woman,full body,向原始提示中添加新对象确保风格一致。您可以调整关键词权重(上面的1.5)以使宝剑显示。
将遮罩内容 设置为潜在噪声。
调整去噪强度 和CFG比例以微调修复后的图像。
经过一些实验,我们的任务完成了:

图像修复参数的解释
去噪强度
去噪强度控制最终图像和原始内容的相似度。将其设置为0则什么都不会改变。将其设置为1,则您会得到一个不相关的图像。
如果您想要小的变化,请设置为低值;如果您想要大的变化,请设置为高值。
CFG scale
类似于在文本到图像中的使用,CFG scale是一个参数,用于控制模型和你的提示词的关联度。
1 -- 大致忽略您的提示。
3 -- 更有创造力。
7 -- 在遵循提示和自由之间取得良好的平衡。
15 -- 更多地遵循提示。
30 -- 严格遵循提示。
遮罩内容
遮罩内容控制遮罩区域是如何初始化的。
fill:用原始图像的高度模糊版本初始化。
Original:未修改。
latent noise :遮罩区域用填充初始化,并在潜在空间中添加随机噪声。
latent nothing:像潜在噪声,只是没有在潜在空间中添加噪声。
图像修复的技巧
成功的图像修复需要耐心和技巧。以下是使用图像修复的一些要点:
- 一次修复一个小区域。
- 尝试不同的遮罩内容以查看哪个最有效。
- 可以多次尝试修复。
- 如果在AUTOMATIC1111的设置中什么都不起作用,请使用像Photoshop或GIMP这样的图像编辑软件,用您想要的大致形状和颜色绘制感兴趣的区域。上传那张图像并用原始内容进行图像修复。