目录
[Radix Tree](#Radix Tree)
[使用Docker部署Go Web应用](#使用Docker部署Go Web应用)
[Docker Compose模式](#Docker Compose模式)
Gin框架简介
Gin是一个用Go语言编写的web框架。它是一个类似于martini但拥有更好性能的API框架, 由于使用了httprouter,速度提高了近40倍。 如果你是性能和高效的追求者, 你会爱上Gin。
Gin的安装非常简单,在go终端运行:
Go
go get -u github.com/gin-gonic/gin简单示例
gin.Default创建了一个默认的路由引擎r,然后可以根据r.GET,r.ROST,r.DELETE等内置函数处理客户端发来的http请求。
使用匿名函数func(c *gin.Context)来进行响应,其中c类型的gin.Context指针就是返回的内容,一般可以用c.HTML定义返回html文件,或者c.JSON返回JSON类型文件。JSON传参的格式是状态码code和空接口object;HTML是状态码code,模板名称name和空接口object
最后用r.RUN在指定端口监听并运行。
Go
package main
import (
"github.com/gin-gonic/gin"
)
func main() {
// 创建一个默认的路由引擎
r := gin.Default()
// GET:请求方式;/hello:请求的路径
// 当客户端以GET方法请求/hello路径时,会执行后面的匿名函数
r.GET("/hello", func(c *gin.Context) {
// c.JSON:返回JSON格式的数据 gin.H 是map[string]interface{}的缩写
c.JSON(200, gin.H{
"message": "Hello world!",
})
})
// 启动HTTP服务,默认在0.0.0.0:8080启动服务
r.Run()
}Gin渲染
HTML渲染
我们首先定义一个存放模板文件的templates文件夹,然后在其内部按照业务分别定义一个posts文件夹和一个users文件夹。 两个文件夹中分别有posts/index.html文件和users/index.html文件。
Gin框架中使用 LoadHTMLGlob() 或者 **LoadHTMLFiles()**方法进行HTML模板渲染
LoadHTMLGlob(pattern string):
- 这个方法接受一个模式(pattern),通常是一个通配符(如
"*.html"),用于匹配目录中的所有HTML模板文件。- 它会加载指定目录下所有匹配该模式的文件作为模板。
- 这种方式适合于项目中模板文件较多,且都存放在同一个目录下的情况。
LoadHTMLFiles(files ...string):
- 这个方法接受一个文件名列表,你可以显式地指定要加载的HTML模板文件。
- 它允许你加载项目中分散在不同目录的模板文件,或者只加载特定的几个模板文件。
- 这种方式提供了更细粒度的控制,你可以精确选择哪些模板文件被加载。
Go
func main() {
r := gin.Default()
r.LoadHTMLGlob("templates/**/*")
//r.LoadHTMLFiles("templates/posts/index.html", "templates/users/index.html")
r.GET("/posts/index", func(c *gin.Context) {
c.HTML(http.StatusOK, "posts/index.html", gin.H{
"title": "posts/index",
})
})
r.GET("users/index", func(c *gin.Context) {
c.HTML(http.StatusOK, "users/index.html", gin.H{
"title": "users/index",
})
})
r.Run(":8080")
}自定义模板函数
在Gin框架中,SetFuncMap 方法用于为模板渲染设置自定义的函数映射。这允许你在模板中使用自定义的函数,这些函数可以执行复杂的逻辑或操作,从而增强模板的灵活性和功能。
css
router.SetFuncMap(template.FuncMap)template.FuncMap:这是一个映射,键是字符串(函数名),值是可调用的函数func。这些函数可以在模板中被调用。
定义一个不转义相应内容的safe模板函数如下:
Go
func main() {
router := gin.Default()
router.SetFuncMap(template.FuncMap{
"safe": func(str string) template.HTML{
return template.HTML(str)
},
})
router.LoadHTMLFiles("./index.tmpl")
router.GET("/index", func(c *gin.Context) {
c.HTML(http.StatusOK, "index.tmpl", "<a href='https://liwenzhou.com'>李文周的博客</a>")
})
router.Run(":8080")
}静态文件处理
当我们渲染的HTML文件中引用了静态文件时,我们只需要按照以下方式在渲染页面前调用**gin.Static**方法即可。
css
r.Static(url string, path string)url:URL前缀,客户端通过这个前缀来访问静态文件。path:静态文件所在的目录路径。Gin 会将这个目录下的文件映射到指定的URL前缀下。
Go
func main() {
r := gin.Default()
r.Static("/static", "./public")
r.LoadHTMLGlob("templates/**/*")
// ...
r.Run(":8080")
}在这个例子中,所有 前端文件html 以 /static 开头的请求都会被Gin处理,并从 ./public 目录下查找相应的文件。例如,如果客户端请求 /static/css/style.css,Gin会尝试从 ./public/css/style.css 文件中提供内容。
关于模板文件和静态文件的路径,我们需要根据公司/项目的要求进行设置。可以使用下面的函数获取当前执行程序的路径:
Go
func getCurrentPath() string {
// 使用 os.Executable() 函数尝试获取当前可执行文件的完整路径。
// 该函数返回两个值:可执行文件的路径和可能发生的错误。
if ex, err := os.Executable(); err == nil {
// 如果没有错误,使用 filepath.Dir() 函数获取可执行文件所在的目录路径。
return filepath.Dir(ex)
}
// 如果获取可执行文件路径的过程中出现错误,返回当前目录的相对路径"./"。
return "./"
}使用模板继承
Gin框架默认都是使用单模板,如果需要使用block template功能,可以通过"github.com/gin-contrib/multitemplate"库实现,具体示例如下:
首先,假设我们项目目录下的templates文件夹下有以下模板文件,其中home.tmpl和index.tmpl继承了base.tmpl:
templates
├── includes
│ ├── home.tmpl
│ └── index.tmpl
├── layouts
│ └── base.tmpl
└── scripts.tmpl然后我们定义一个loadTemplates函数如下:
Go
// loadTemplates 函数负责初始化并加载模板文件,返回一个 multitemplate.Renderer 对象。
func loadTemplates(templatesDir string) multitemplate.Renderer {
// 创建一个新的 multitemplate.Renderer 实例。
r := multitemplate.NewRenderer()
// 使用 filepath.Glob 函数查找 templatesDir 目录下 "layouts" 子目录中的所有 ".tmpl" 文件。
// 这些文件将作为模板布局文件。
layouts, err := filepath.Glob(templatesDir + "/layouts/*.tmpl")
if err != nil {
// 如果在获取布局文件时出现错误,使用 panic 来中断程序并输出错误信息。
panic(err.Error())
}
// 使用 filepath.Glob 函数查找 templatesDir 目录下 "includes" 子目录中的所有 ".tmpl" 文件。
// 这些文件将作为模板包含文件。
includes, err := filepath.Glob(templatesDir + "/includes/*.tmpl")
if err != nil {
// 如果在获取包含文件时出现错误,使用 panic 来中断程序并输出错误信息。
panic(err.Error())
}
// 遍历所有包含文件(includes)。
for _, include := range includes {
// 创建一个布局文件的副本,以便在遍历过程中修改。
layoutCopy := make([]string, len(layouts))
copy(layoutCopy, layouts)
// 将当前包含文件(include)添加到布局文件列表的副本中。
files := append(layoutCopy, include)
// 使用 multitemplate.Renderer 的 AddFromFiles 方法添加模板。
// 这里使用 include 文件的基本名称(不包含路径)作为模板的名称。
r.AddFromFiles(filepath.Base(include), files...)
}
// 返回初始化并加载了模板文件的 multitemplate.Renderer 对象。
return r
}我们在main函数中
Go
func indexFunc(c *gin.Context){
c.HTML(http.StatusOK, "index.tmpl", nil)
}
func homeFunc(c *gin.Context){
c.HTML(http.StatusOK, "home.tmpl", nil)
}
func main(){
r := gin.Default()
r.HTMLRender = loadTemplates("./templates")
r.GET("/index", indexFunc)
r.GET("/home", homeFunc)
r.Run()
}JSON渲染和XML渲染
Go
func main() {
r := gin.Default()
r.GET("/someJSON", func(c *gin.Context) {
// 方式一:自己拼接JSON
c.JSON(http.StatusOK, gin.H{"message": "Hello world!"})
})
r.GET("/moreJSON", func(c *gin.Context) {
// 方法二:使用结构体
var msg struct {
Name string `json:"user"`
Message string
Age int
}
msg.Name = "奶牛"
msg.Message = "Hello world!"
msg.Age = 5
c.JSON(http.StatusOK, msg)
})
r.Run(":8080")
}
Go
func main() {
r := gin.Default()
r.GET("/someXML", func(c *gin.Context) {
// 方式一:自己拼接JSON
c.XML(http.StatusOK, gin.H{"message": "Hello world!"})
})
r.GET("/moreXML", func(c *gin.Context) {
// 方法二:使用结构体
type MessageRecord struct {
Name string
Message string
Age int
}
var msg MessageRecord
msg.Name = "奶牛"
msg.Message = "Hello world!"
msg.Age = 5
c.XML(http.StatusOK, msg)
})
r.Run(":8080")
}获取参数
获取querystring参数
- 定义 :查询字符串参数是通过HTTP GET请求发送的数据,附加在URL的末尾,以
?开始,参数之间用&分隔。 - 使用场景:当你需要传递非敏感信息或者进行数据过滤、排序等操作时,可以使用查询字符串参数。
- 安全性:由于数据直接显示在URL中,不适合传递敏感信息。
- 数据类型:通常只发送ASCII字符,对于非ASCII字符需要进行URL编码。
- 编码:查询字符串参数使用URL编码。
querystring 指的是URL中?后面携带的参数,例如:/user/search?username=奶牛&address=广东。 获取请求的querystring参数的方法如下,其中DefualtQuery就是没有传入Query值时拥有默认值:
Go
func main() {
//Default返回一个默认的路由引擎
r := gin.Default()
r.GET("/user/search", func(c *gin.Context) {
username := c.DefaultQuery("username", "奶牛")
//username := c.Query("username")
address := c.Query("address")
//输出json结果给调用方
c.JSON(http.StatusOK, gin.H{
"message": "ok",
"username": username,
"address": address,
})
})
r.Run()
}获取form参数
- 定义:表单参数是通过HTTP POST请求发送的数据,通常包含在请求的正文(body)中。
- 使用场景:当你需要提交敏感信息(如密码)、文件上传或者大量数据时,应该使用表单参数。
- 安全性:由于数据包含在请求正文中,不会被URL中直接显示,因此表单参数比查询字符串参数更安全。
- 数据类型:可以发送包括文本、文件、二进制数据等在内的各种类型的数据。
- 编码 :表单参数通常使用
application/x-www-form-urlencoded或multipart/form-data编码类型。
当前端请求的数据通过form表单提交时,例如向/user/search发送一个POST请求,获取请求数据的方式如下:
Go
func main() {
//Default返回一个默认的路由引擎
r := gin.Default()
r.POST("/user/search", func(c *gin.Context) {
// DefaultPostForm取不到值时会返回指定的默认值
//username := c.DefaultPostForm("username", "奶牛")
username := c.PostForm("username")
address := c.PostForm("address")
//输出json结果给调用方
c.JSON(http.StatusOK, gin.H{
"message": "ok",
"username": username,
"address": address,
})
})
r.Run(":8080")
}获取Path参数
请求的参数通过URL路径传递,例如:/user/search/奶牛/广东。 获取请求URL路径中的参数的方式如下。
Go
func main() {
//Default返回一个默认的路由引擎
r := gin.Default()
r.GET("/user/search/:username/:address", func(c *gin.Context) {
username := c.Param("username")
address := c.Param("address")
//输出json结果给调用方
c.JSON(http.StatusOK, gin.H{
"message": "ok",
"username": username,
"address": address,
})
})
r.Run(":8080")
}参数绑定
为了能够更方便的获取请求相关参数,提高开发效率,我们可以基于请求的Content-Type识别请求数据类型并利用反射机制自动提取请求中QueryString、form表单、JSON、XML等参数到结构体中。 下面的示例代码演示了.ShouldBind()强大的功能,它能够基于请求自动提取JSON、form表单和QueryString类型的数据,并把值绑定到指定的结构体对象。
Go
// 绑定的类型,注意要打上tag
type Login struct {
User string `form:"user" json:"user" binding:"required"`
Password string `form:"password" json:"password" binding:"required"`
}
func main() {
router := gin.Default()
// 绑定JSON的示例 ({"user": "knoci", "password": "123"})
router.POST("/loginJSON", func(c *gin.Context) {
var login Login
if err := c.ShouldBind(&login); err == nil {
fmt.Printf("login info:%#v\n", login)
c.JSON(http.StatusOK, gin.H{
"user": login.User,
"password": login.Password,
})
} else {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
}
})
// 绑定form表单示例 (user=knoci&password=123)
router.POST("/loginForm", func(c *gin.Context) {
var login Login
// ShouldBind()会根据请求的Content-Type自行选择绑定器
if err := c.ShouldBind(&login); err == nil {
c.JSON(http.StatusOK, gin.H{
"user": login.User,
"password": login.Password,
})
} else {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
}
})
// 绑定QueryString示例 (/loginQuery?user=knoci&password=123)
router.GET("/loginForm", func(c *gin.Context) {
var login Login
// ShouldBind()会根据请求的Content-Type自行选择绑定器
if err := c.ShouldBind(&login); err == nil {
c.JSON(http.StatusOK, gin.H{
"user": login.User,
"password": login.Password,
})
} else {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
}
})
// Listen and serve on 0.0.0.0:8080
router.Run(":8080")
}文件上传
单个文件上传
在Gin框架中,c.FormFile方法用于从HTTP请求中获取上传的文件。当你的Web应用需要处理文件上传时,这个方法非常有用。它允许你访问上传的文件信息,如文件名、大小等,并可以将文件保存到服务器。
Go
c.FormFile(name string) (*multipart.FileHeader, error)参数
name:表单字段的名称,即用户在表单中上传文件时使用的字段名。- 返回一个指向
multipart.FileHeader的指针,它包含了文件的元数据,如文件名Filename、文件大小、内容类型等。 - 返回一个错误对象,如果获取文件过程中出现错误,则该错误对象会被填充。
在Gin框架中,c.SaveUploadedFile 是一个用于处理文件上传的方法。当你的Web应用需要接收用户上传的文件时,这个方法非常有用。它允许你将上传的文件保存到服务器的指定位置。
Go
c.SaveUploadedFile(*file *multipart.FileHeader, dst string) error*file *multipart.FileHeader:这是一个指向上传文件的文件头的指针,通常通过解析请求中的文件来获得。dst string:这是文件保存的目标路径,包括文件名。- 返回值是一个错误对象,如果文件保存成功则为
nil,否则会返回一个错误描述。
Go
func main() {
router := gin.Default()
// 处理multipart forms提交文件时默认的内存限制是32 MiB
// 可以通过下面的方式修改
// router.MaxMultipartMemory = 8 << 20 // 8 MiB
router.POST("/upload", func(c *gin.Context) {
// 单个文件
file, err := c.FormFile("f1")
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{
"message": err.Error(),
})
return
}
log.Println(file.Filename)
dst := fmt.Sprintf("C:/tmp/%s", file.Filename)
// 上传文件到指定的目录
c.SaveUploadedFile(file, dst)
c.JSON(http.StatusOK, gin.H{
"message": fmt.Sprintf("'%s' uploaded!", file.Filename),
})
})
router.Run()
}多个文件上传
在Gin框架中,c.MultipartForm 方法用于解析HTTP请求中的多部分(multipart)表单数据。多部分表单数据通常用于文件上传,但也可以用于发送混合类型的数据,如文件和文本字段。
Go
c.MultipartForm() (*multipart.Form, error)- 返回一个指向
multipart.Form的指针,它包含了解析后的多部分表单数据。 - 返回一个错误对象,如果解析过程中出现错误,则该错误对象会被填充。
multipart.Form
cpptype Form struct { Value map[string]string File map[string][]*FileHeader }
Value:一个字符串到字符串的映射,包含了表单中的文本字段和它们的值。这个映射不包含文件字段。File:一个字符串到FileHeader指针数组的映射,包含了表单中的文件字段和对应的文件元数据。键是表单字段的名称,值是一个或多个*FileHeader指针,每个指针指向一个文件的元数据。
Go
func main() {
router := gin.Default()
// 处理multipart forms提交文件时默认的内存限制是32 MiB
// 可以通过下面的方式修改
// router.MaxMultipartMemory = 8 << 20 // 8 MiB
router.POST("/upload", func(c *gin.Context) {
// Multipart form
form, _ := c.MultipartForm()
files := form.File["file"] // 前端input的name是"file"的元数据
for index, file := range files {
log.Println(file.Filename)
dst := fmt.Sprintf("C:/tmp/%s_%d", file.Filename, index)
// 上传文件到指定的目录
c.SaveUploadedFile(file, dst)
}
c.JSON(http.StatusOK, gin.H{
"message": fmt.Sprintf("%d files uploaded!", len(files)),
})
})
router.Run()
}重定向
HTTP重定向
HTTP 重定向很容易。 内部、外部重定向均支持,使用c.Redirect跳转到别的url。
Go
r.GET("/test", func(c *gin.Context) {
c.Redirect(http.StatusMovedPermanently, "https://www.bilibili.com/")
})路由重定向
在Gin框架中,r.HandleContext 方法用于注册一个中间件函数,该函数可以处理请求的上下文。中间件是Gin框架中一个非常重要的概念,它允许你在请求处理流程的不同阶段执行代码,例如日志记录、权限验证、请求限流等。
Go
r.HandleContext(f func(*Context))f:一个函数,它接收一个*gin.Context指针作为参数。gin.Context包含了请求和响应的详细信息,以及处理请求的方法。
修改c.Request.URL.Path的参数,实现路由(web处理)上的重定向:
Go
r.GET("/test", func(c *gin.Context) {
// 指定重定向的URL
c.Request.URL.Path = "/test2"
r.HandleContext(c)
})
r.GET("/test2", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{"hello": "world"})
})Gin路由
Gin路由指的是在使用Gin框架开发Web应用时,定义URL路径与处理函数之间映射关系的机制。
- 路由(Route) :一个路由由一个URL模式(如
/user/profile)和一个HTTP方法(如GET、POST)组成。它定义了当特定URL和HTTP方法被请求时,应该执行哪个处理函数。 - 处理函数(Handler Function):当路由匹配到一个请求时,Gin会调用相应的处理函数来处理请求并返回响应。
- 参数 :在路由中,你可以定义参数,这些参数在请求URL中是动态的。例如,
/user/:id中的:id就是一个参数,它可以匹配任何值,并且可以在处理函数中作为变量使用。
普通路由
Go
r.GET("/index", func(c *gin.Context) {...})
r.GET("/login", func(c *gin.Context) {...})
r.POST("/login", func(c *gin.Context) {...})此外,还有一个可以匹配所有请求方法的Any方法如下:
Go
r.Any("/test", func(c *gin.Context) {...})NoRoute为没有配置处理函数的路由添加处理程序,默认情况下它返回404代码,下面的代码为没有匹配到路由的请求都返回views/404.html页面。
Go
r.NoRoute(func(c *gin.Context) {
c.HTML(http.StatusNotFound, "views/404.html", nil)
})路由组
我们可以将拥有共同URL前缀的路由划分为一个路由组。习惯性一对{}包裹同组的路由,这只是为了看着清晰,你用不用{}包裹功能上没什么区别。
Go
func main() {
r := gin.Default()
userGroup := r.Group("/user")
{
userGroup.GET("/index", func(c *gin.Context) {...})
userGroup.GET("/login", func(c *gin.Context) {...})
userGroup.POST("/login", func(c *gin.Context) {...})
}
shopGroup := r.Group("/shop")
{
shopGroup.GET("/index", func(c *gin.Context) {...})
shopGroup.GET("/cart", func(c *gin.Context) {...})
shopGroup.POST("/checkout", func(c *gin.Context) {...})
}
r.Run()
}路由组也是支持嵌套的,例如:
Go
shopGroup := r.Group("/shop")
{
shopGroup.GET("/index", func(c *gin.Context) {...})
shopGroup.GET("/cart", func(c *gin.Context) {...})
shopGroup.POST("/checkout", func(c *gin.Context) {...})
// 嵌套路由组
xx := shopGroup.Group("xx") {
xx.GET("/oo", func(c *gin.Context) {...})
}
}路由原理
gin框架使用的是定制版本的httprouter,其路由的原理是大量使用公共前缀的树结构,它基本上是一个紧凑的Trie tree(或者只是Radix Tree)。具有公共前缀的节点也共享一个公共父节点。
Radix Tree
基数树(Radix Tree)又称为PAT位树(Patricia Trie or crit bit tree),是一种更节省空间的前缀树(Trie Tree)。对于基数树的每个节点,如果该节点是唯一的子树的话,就和父节点合并。下图为一个基数树示例:
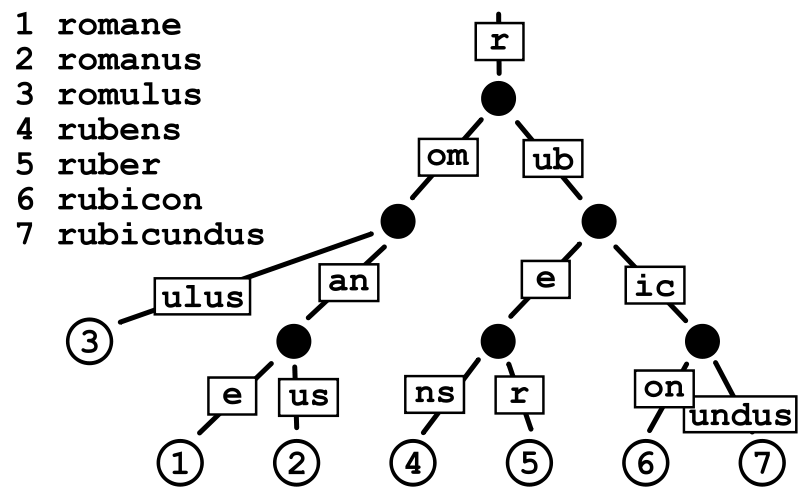
Radix Tree可以被认为是一棵简洁版的前缀树。我们注册路由的过程就是构造前缀树的过程,具有公共前缀的节点也共享一个公共父节点。假设我们现在注册有以下路由信息:
Go
r := gin.Default()
r.GET("/", func1)
r.GET("/search/", func2)
r.GET("/support/", func3)
r.GET("/blog/", func4)
r.GET("/blog/:post/", func5)
r.GET("/about-us/", func6)
r.GET("/about-us/team/", func7)
r.GET("/contact/", func8)那么我们会得到一个GET方法对应的路由树,具体结构如下:
bash
Priority Path Handle
9 \ *<1>
3 ├s nil
2 |├earch\ *<2>
1 |└upport\ *<3>
2 ├blog\ *<4>
1 | └:post nil
1 | └\ *<5>
2 ├about-us\ *<6>
1 | └team\ *<7>
1 └contact\ *<8>上面最右边那一列每个*<数字>表示Handle处理函数的内存地址(一个指针)。从根节点遍历到叶子节点我们就能得到完整的路由表。
例如:blog/:post其中:post只是实际文章名称的占位符(参数)。与hash-maps不同,这种树结构还允许我们使用像:post参数这种动态部分,因为我们实际上是根据路由模式进行匹配,而不仅仅是比较哈希值。
由于URL路径具有层次结构,并且只使用有限的一组字符(字节值),所以很可能有许多常见的前缀。这使我们可以很容易地将路由简化为更小的问题。此外,路由器为每种请求方法管理一棵单独的树。一方面,它比在每个节点中都保存一个method-> handle map更加节省空间,它还使我们甚至可以在开始在前缀树中查找之前大大减少路由问题。
为了获得更好的可伸缩性,每个树级别上的子节点都按Priority(优先级)排序,其中优先级(最左列)就是在子节点(子节点、子子节点等等)中注册的句柄的数量。这样做有两个好处:
-
首先优先匹配被大多数路由路径包含的节点。这样可以让尽可能多的路由快速被定位。
-
类似于成本补偿。最长的路径可以被优先匹配,补偿体现在最长的路径需要花费更长的时间来定位,如果最长路径的节点能被优先匹配(即每次拿子节点都命中),那么路由匹配所花的时间不一定比短路径的路由长。下面展示了节点(每个
-可以看做一个节点)匹配的路径:从左到右,从上到下。├------------ ├--------- ├----- ├---- ├-- ├-- └-
路由树节点
路由树是由一个个节点构成的,gin框架路由树的节点由node结构体表示,它有以下字段:
Go
// tree.go
type node struct {
// 节点路径,比如上面的s,earch,和upport
path string
// 和children字段对应, 保存的是分裂的分支的第一个字符
// 例如search和support, 那么s节点的indices对应的"eu"
// 代表有两个分支, 分支的首字母分别是e和u
indices string
// 儿子节点
children []*node
// 处理函数链条(切片)
handlers HandlersChain
// 优先级,子节点、子子节点等注册的handler数量
priority uint32
// 节点类型,包括static, root, param, catchAll
// static: 静态节点(默认),比如上面的s,earch等节点
// root: 树的根节点
// catchAll: 有*匹配的节点
// param: 参数节点
nType nodeType
// 路径上最大参数个数
maxParams uint8
// 节点是否是参数节点,比如上面的:post
wildChild bool
// 完整路径
fullPath string
}请求方法树
在gin的路由中,每一个HTTP Method(GET、POST、PUT、DELETE...)都对应了一棵 radix tree,我们注册路由的时候会调用下面的addRoute函数:
Go
// gin.go
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {
// liwenzhou.com...
// 获取请求方法对应的树
root := engine.trees.get(method)
if root == nil {
// 如果没有就创建一个
root = new(node)
root.fullPath = "/"
engine.trees = append(engine.trees, methodTree{method: method, root: root})
}
root.addRoute(path, handlers)
}从上面的代码中我们可以看到在注册路由的时候都是先根据请求方法获取对应的树,也就是gin框架会为每一个请求方法创建一棵对应的树。只不过需要注意到一个细节是gin框架中保存请求方法对应树关系并不是使用的map而是使用的切片,engine.trees的类型是methodTrees,其定义如下:
Go
type methodTree struct {
method string
root *node
}
type methodTrees []methodTree // slice而获取请求方法对应树的get方法定义如下:
Go
func (trees methodTrees) get(method string) *node {
for _, tree := range trees {
if tree.method == method {
return tree.root
}
}
return nil
}为什么使用切片而不是map来存储请求方法->树的结构呢?我猜是出于节省内存的考虑吧,毕竟HTTP请求方法的数量是固定的,而且常用的就那几种,所以即使使用切片存储查询起来效率也足够了。顺着这个思路,我们可以看一下gin框架中engine的初始化方法中,确实对tress字段做了一次内存申请:
Go
func New() *Engine {
debugPrintWARNINGNew()
engine := &Engine{
RouterGroup: RouterGroup{
Handlers: nil,
basePath: "/",
root: true,
},
// liwenzhou.com ...
// 初始化容量为9的切片(HTTP1.1请求方法共9种)
trees: make(methodTrees, 0, 9),
// liwenzhou.com...
}
engine.RouterGroup.engine = engine
engine.pool.New = func() interface{} {
return engine.allocateContext()
}
return engine
}注册路由
注册路由的逻辑主要有addRoute函数和insertChild方法。
addRoute
Go
// tree.go
// addRoute 将具有给定句柄的节点添加到路径中。
// 不是并发安全的
func (n *node) addRoute(path string, handlers HandlersChain) {
fullPath := path
n.priority++
numParams := countParams(path) // 数一下参数个数
// 空树就直接插入当前节点
if len(n.path) == 0 && len(n.children) == 0 {
n.insertChild(numParams, path, fullPath, handlers)
n.nType = root
return
}
parentFullPathIndex := 0
walk:
for {
// 更新当前节点的最大参数个数
if numParams > n.maxParams {
n.maxParams = numParams
}
// 找到最长的通用前缀
// 这也意味着公共前缀不包含":""或"*" /
// 因为现有键不能包含这些字符。
i := longestCommonPrefix(path, n.path)
// 分裂边缘(此处分裂的是当前树节点)
// 例如一开始path是search,新加入support,s是他们通用的最长前缀部分
// 那么会将s拿出来作为parent节点,增加earch和upport作为child节点
if i < len(n.path) {
child := node{
path: n.path[i:], // 公共前缀后的部分作为子节点
wildChild: n.wildChild,
indices: n.indices,
children: n.children,
handlers: n.handlers,
priority: n.priority - 1, //子节点优先级-1
fullPath: n.fullPath,
}
// Update maxParams (max of all children)
for _, v := range child.children {
if v.maxParams > child.maxParams {
child.maxParams = v.maxParams
}
}
n.children = []*node{&child}
// []byte for proper unicode char conversion, see #65
n.indices = string([]byte{n.path[i]})
n.path = path[:i]
n.handlers = nil
n.wildChild = false
n.fullPath = fullPath[:parentFullPathIndex+i]
}
// 将新来的节点插入新的parent节点作为子节点
if i < len(path) {
path = path[i:]
if n.wildChild { // 如果是参数节点
parentFullPathIndex += len(n.path)
n = n.children[0]
n.priority++
// Update maxParams of the child node
if numParams > n.maxParams {
n.maxParams = numParams
}
numParams--
// 检查通配符是否匹配
if len(path) >= len(n.path) && n.path == path[:len(n.path)] {
// 检查更长的通配符, 例如 :name and :names
if len(n.path) >= len(path) || path[len(n.path)] == '/' {
continue walk
}
}
pathSeg := path
if n.nType != catchAll {
pathSeg = strings.SplitN(path, "/", 2)[0]
}
prefix := fullPath[:strings.Index(fullPath, pathSeg)] + n.path
panic("'" + pathSeg +
"' in new path '" + fullPath +
"' conflicts with existing wildcard '" + n.path +
"' in existing prefix '" + prefix +
"'")
}
// 取path首字母,用来与indices做比较
c := path[0]
// 处理参数后加斜线情况
if n.nType == param && c == '/' && len(n.children) == 1 {
parentFullPathIndex += len(n.path)
n = n.children[0]
n.priority++
continue walk
}
// 检查路path下一个字节的子节点是否存在
// 比如s的子节点现在是earch和upport,indices为eu
// 如果新加一个路由为super,那么就是和upport有匹配的部分u,将继续分列现在的upport节点
for i, max := 0, len(n.indices); i < max; i++ {
if c == n.indices[i] {
parentFullPathIndex += len(n.path)
i = n.incrementChildPrio(i)
n = n.children[i]
continue walk
}
}
// 否则就插入
if c != ':' && c != '*' {
// []byte for proper unicode char conversion, see #65
// 注意这里是直接拼接第一个字符到n.indices
n.indices += string([]byte{c})
child := &node{
maxParams: numParams,
fullPath: fullPath,
}
// 追加子节点
n.children = append(n.children, child)
n.incrementChildPrio(len(n.indices) - 1)
n = child
}
n.insertChild(numParams, path, fullPath, handlers)
return
}
// 已经注册过的节点
if n.handlers != nil {
panic("handlers are already registered for path '" + fullPath + "'")
}
n.handlers = handlers
return
}
}其实上面的代码很好理解,大家可以参照动画尝试将以下情形代入上面的代码逻辑,体味整个路由树构造的详细过程:
- 第一次注册路由,例如注册search
- 继续注册一条没有公共前缀的路由,例如blog
- 注册一条与先前注册的路由有公共前缀的路由,例如support

insertChild
Go
// tree.go
func (n *node) insertChild(numParams uint8, path string, fullPath string, handlers HandlersChain) {
// 找到所有的参数
for numParams > 0 {
// 查找前缀直到第一个通配符
wildcard, i, valid := findWildcard(path)
if i < 0 { // 没有发现通配符
break
}
// 通配符的名称必须包含':' 和 '*'
if !valid {
panic("only one wildcard per path segment is allowed, has: '" +
wildcard + "' in path '" + fullPath + "'")
}
// 检查通配符是否有名称
if len(wildcard) < 2 {
panic("wildcards must be named with a non-empty name in path '" + fullPath + "'")
}
// 检查这个节点是否有已经存在的子节点
// 如果我们在这里插入通配符,这些子节点将无法访问
if len(n.children) > 0 {
panic("wildcard segment '" + wildcard +
"' conflicts with existing children in path '" + fullPath + "'")
}
if wildcard[0] == ':' { // param
if i > 0 {
// 在当前通配符之前插入前缀
n.path = path[:i]
path = path[i:]
}
n.wildChild = true
child := &node{
nType: param,
path: wildcard,
maxParams: numParams,
fullPath: fullPath,
}
n.children = []*node{child}
n = child
n.priority++
numParams--
// 如果路径没有以通配符结束
// 那么将有另一个以'/'开始的非通配符子路径。
if len(wildcard) < len(path) {
path = path[len(wildcard):]
child := &node{
maxParams: numParams,
priority: 1,
fullPath: fullPath,
}
n.children = []*node{child}
n = child // 继续下一轮循环
continue
}
// 否则我们就完成了。将处理函数插入新叶子中
n.handlers = handlers
return
}
// catchAll
if i+len(wildcard) != len(path) || numParams > 1 {
panic("catch-all routes are only allowed at the end of the path in path '" + fullPath + "'")
}
if len(n.path) > 0 && n.path[len(n.path)-1] == '/' {
panic("catch-all conflicts with existing handle for the path segment root in path '" + fullPath + "'")
}
// currently fixed width 1 for '/'
i--
if path[i] != '/' {
panic("no / before catch-all in path '" + fullPath + "'")
}
n.path = path[:i]
// 第一个节点:路径为空的catchAll节点
child := &node{
wildChild: true,
nType: catchAll,
maxParams: 1,
fullPath: fullPath,
}
// 更新父节点的maxParams
if n.maxParams < 1 {
n.maxParams = 1
}
n.children = []*node{child}
n.indices = string('/')
n = child
n.priority++
// 第二个节点:保存变量的节点
child = &node{
path: path[i:],
nType: catchAll,
maxParams: 1,
handlers: handlers,
priority: 1,
fullPath: fullPath,
}
n.children = []*node{child}
return
}
// 如果没有找到通配符,只需插入路径和句柄
n.path = path
n.handlers = handlers
n.fullPath = fullPath
} insertChild函数是根据path本身进行分割,将/分开的部分分别作为节点保存,形成一棵树结构。参数匹配中的:和*的区别是,前者是匹配一个字段而后者是匹配后面所有的路径。
路由匹配
我们先来看gin框架处理请求的入口函数ServeHTTP:
Go
// gin.go
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
// 这里使用了对象池
c := engine.pool.Get().(*Context)
// 这里有一个细节就是Get对象后做初始化
c.writermem.reset(w)
c.Request = req
c.reset()
engine.handleHTTPRequest(c) // 我们要找的处理HTTP请求的函数
engine.pool.Put(c) // 处理完请求后将对象放回池子
}函数很长,这里省略了部分代码,只保留相关逻辑代码:
Go
// gin.go
func (engine *Engine) handleHTTPRequest(c *Context) {
// liwenzhou.com...
// 根据请求方法找到对应的路由树
t := engine.trees
for i, tl := 0, len(t); i < tl; i++ {
if t[i].method != httpMethod {
continue
}
root := t[i].root
// 在路由树中根据path查找
value := root.getValue(rPath, c.Params, unescape)
if value.handlers != nil {
c.handlers = value.handlers
c.Params = value.params
c.fullPath = value.fullPath
c.Next() // 执行函数链条
c.writermem.WriteHeaderNow()
return
}
// liwenzhou.com...
c.handlers = engine.allNoRoute
serveError(c, http.StatusNotFound, default404Body)
}路由匹配是由节点的 getValue方法实现的。getValue根据给定的路径(键)返回nodeValue值,保存注册的处理函数和匹配到的路径参数数据。
如果找不到任何处理函数,则会尝试TSR(尾随斜杠重定向)。
Go
// tree.go
type nodeValue struct {
handlers HandlersChain
params Params // []Param
tsr bool
fullPath string
}
// liwenzhou.com...
func (n *node) getValue(path string, po Params, unescape bool) (value nodeValue) {
value.params = po
walk: // Outer loop for walking the tree
for {
prefix := n.path
if path == prefix {
// 我们应该已经到达包含处理函数的节点。
// 检查该节点是否注册有处理函数
if value.handlers = n.handlers; value.handlers != nil {
value.fullPath = n.fullPath
return
}
if path == "/" && n.wildChild && n.nType != root {
value.tsr = true
return
}
// 没有找到处理函数 检查这个路径末尾+/ 是否存在注册函数
indices := n.indices
for i, max := 0, len(indices); i < max; i++ {
if indices[i] == '/' {
n = n.children[i]
value.tsr = (len(n.path) == 1 && n.handlers != nil) ||
(n.nType == catchAll && n.children[0].handlers != nil)
return
}
}
return
}
if len(path) > len(prefix) && path[:len(prefix)] == prefix {
path = path[len(prefix):]
// 如果该节点没有通配符(param或catchAll)子节点
// 我们可以继续查找下一个子节点
if !n.wildChild {
c := path[0]
indices := n.indices
for i, max := 0, len(indices); i < max; i++ {
if c == indices[i] {
n = n.children[i] // 遍历树
continue walk
}
}
// 没找到
// 如果存在一个相同的URL但没有末尾/的叶子节点
// 我们可以建议重定向到那里
value.tsr = path == "/" && n.handlers != nil
return
}
// 根据节点类型处理通配符子节点
n = n.children[0]
switch n.nType {
case param:
// find param end (either '/' or path end)
end := 0
for end < len(path) && path[end] != '/' {
end++
}
// 保存通配符的值
if cap(value.params) < int(n.maxParams) {
value.params = make(Params, 0, n.maxParams)
}
i := len(value.params)
value.params = value.params[:i+1] // 在预先分配的容量内扩展slice
value.params[i].Key = n.path[1:]
val := path[:end]
if unescape {
var err error
if value.params[i].Value, err = url.QueryUnescape(val); err != nil {
value.params[i].Value = val // fallback, in case of error
}
} else {
value.params[i].Value = val
}
// 继续向下查询
if end < len(path) {
if len(n.children) > 0 {
path = path[end:]
n = n.children[0]
continue walk
}
// ... but we can't
value.tsr = len(path) == end+1
return
}
if value.handlers = n.handlers; value.handlers != nil {
value.fullPath = n.fullPath
return
}
if len(n.children) == 1 {
// 没有找到处理函数. 检查此路径末尾加/的路由是否存在注册函数
// 用于 TSR 推荐
n = n.children[0]
value.tsr = n.path == "/" && n.handlers != nil
}
return
case catchAll:
// 保存通配符的值
if cap(value.params) < int(n.maxParams) {
value.params = make(Params, 0, n.maxParams)
}
i := len(value.params)
value.params = value.params[:i+1] // 在预先分配的容量内扩展slice
value.params[i].Key = n.path[2:]
if unescape {
var err error
if value.params[i].Value, err = url.QueryUnescape(path); err != nil {
value.params[i].Value = path // fallback, in case of error
}
} else {
value.params[i].Value = path
}
value.handlers = n.handlers
value.fullPath = n.fullPath
return
default:
panic("invalid node type")
}
}
// 找不到,如果存在一个在当前路径最后添加/的路由
// 我们会建议重定向到那里
value.tsr = (path == "/") ||
(len(prefix) == len(path)+1 && prefix[len(path)] == '/' &&
path == prefix[:len(prefix)-1] && n.handlers != nil)
return
}
}路由拆分与注册
基本的路由注册
下面最基础的gin路由注册方式,适用于路由条目比较少的简单项目或者项目demo。
Go
package main
import (
"net/http"
"github.com/gin-gonic/gin"
)
func helloHandler(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"message": "Hello q1mi!",
})
}
func main() {
r := gin.Default()
r.GET("/hello", helloHandler)
if err := r.Run(); err != nil {
fmt.Println("startup service failed, err:%v\n", err)
}
}路由拆分成单独文件或包
当项目的规模增大后就不太适合继续在项目的main.go文件中去实现路由注册相关逻辑了,我们会倾向于把路由部分的代码都拆分出来,形成一个单独的文件或包:
我们在routers.go文件中定义并注册路由信息:
Go
package main
import (
"net/http"
"github.com/gin-gonic/gin"
)
func helloHandler(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"message": "Hello q1mi!",
})
}
func setupRouter() *gin.Engine {
r := gin.Default()
r.GET("/hello", helloHandler)
return r
}此时main.go中调用上面定义好的setupRouter函数:
Go
func main() {
r := setupRouter()
if err := r.Run(); err != nil {
fmt.Println("startup service failed, err:%v\n", err)
}
}此时的目录结构:
gin_demo
├── go.mod
├── go.sum
├── main.go
└── routers.go把路由部分的代码单独拆分成包的话也是可以的,拆分后的目录结构如下:
gin_demo
├── go.mod
├── go.sum
├── main.go
└── routers
└── routers.go routers/routers.go需要注意此时setupRouter需要改成首字母大写:
Go
package routers
import (
"net/http"
"github.com/gin-gonic/gin"
)
func helloHandler(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"message": "Hello q1mi!",
})
}
// SetupRouter 配置路由信息
func SetupRouter() *gin.Engine {
r := gin.Default()
r.GET("/hello", helloHandler)
return r
} main.go文件内容如下:
Go
package main
import (
"fmt"
"gin_demo/routers"
)
func main() {
r := routers.SetupRouter()
if err := r.Run(); err != nil {
fmt.Println("startup service failed, err:%v\n", err)
}
}路由拆分成多个文件
当我们的业务规模继续膨胀,单独的一个routers文件或包已经满足不了我们的需求了,
Go
func SetupRouter() *gin.Engine {
r := gin.Default()
r.GET("/hello", helloHandler)
r.GET("/xx1", xxHandler1)
...
r.GET("/xx30", xxHandler30)
return r
}因为我们把所有的路由注册都写在一个SetupRouter函数中的话就会太复杂了。我们可以分开定义多个路由文件,例如:
gin_demo
├── go.mod
├── go.sum
├── main.go
└── routers
├── blog.go
└── shop.go routers/shop.go中添加一个LoadShop的函数,将shop相关的路由注册到指定的路由器:
Go
func LoadShop(e *gin.Engine) {
e.GET("/hello", helloHandler)
e.GET("/goods", goodsHandler)
e.GET("/checkout", checkoutHandler)
...
} routers/blog.go中添加一个`LoadBlog的函数,将blog相关的路由注册到指定的路由器:
Go
func LoadBlog(e *gin.Engine) {
e.GET("/post", postHandler)
e.GET("/comment", commentHandler)
...
}在main函数中实现最终的注册逻辑如下:
Go
func main() {
r := gin.Default()
routers.LoadBlog(r)
routers.LoadShop(r)
if err := r.Run(); err != nil {
fmt.Println("startup service failed, err:%v\n", err)
}
}路由拆分到不同的APP
有时候项目规模实在太大,那么我们就更倾向于把业务拆分的更详细一些,例如把不同的业务代码拆分成不同的APP。
因此我们在项目目录下单独定义一个app目录,用来存放我们不同业务线的代码文件,这样就很容易进行横向扩展。大致目录结构如下:
gin_demo
├── app
│ ├── blog
│ │ ├── handler.go
│ │ └── router.go
│ └── shop
│ ├── handler.go
│ └── router.go
├── go.mod
├── go.sum
├── main.go
└── routers
└── routers.go其中app/blog/router.go用来定义blog相关的路由信息,具体内容如下:
func Routers(e *gin.Engine) {
e.GET("/post", postHandler)
e.GET("/comment", commentHandler)
} app/shop/router.go用来定义shop相关路由信息,具体内容如下:
Go
func Routers(e *gin.Engine) {
e.GET("/goods", goodsHandler)
e.GET("/checkout", checkoutHandler)
} routers/routers.go中根据需要定义Include函数用来注册子app中定义的路由,Init函数用来进行路由的初始化操作:
Go
type Option func(*gin.Engine)
var options = []Option{}
// 注册app的路由配置
func Include(opts ...Option) {
options = append(options, opts...)
}
// 初始化
func Init() *gin.Engine {
r := gin.Default()
for _, opt := range options {
opt(r)
}
return r
} main.go中按如下方式先注册子app中的路由,然后再进行路由的初始化:
Go
func main() {
// 加载多个APP的路由配置
routers.Include(shop.Routers, blog.Routers)
// 初始化路由
r := routers.Init()
if err := r.Run(); err != nil {
fmt.Println("startup service failed, err:%v\n", err)
}
}Gin中间件
Gin框架允许开发者在处理请求的过程中,加入用户自己的钩子(Hook)函数。这个钩子函数就叫中间件,中间件适合处理一些公共的业务逻辑,比如登录认证、权限校验、数据分页、记录日志、耗时统计等。
定义中间件
Gin中的中间件必须是一个gin.HandlerFunc类型。
记录接口耗时的中间件
例如我们像下面的代码一样定义一个统计请求耗时的中间件。
Go
// StatCost 是一个统计耗时请求耗时的中间件
func StatCost() gin.HandlerFunc {
return func(c *gin.Context) {
start := time.Now()
c.Set("name", "牛") // 可以通过c.Set在请求上下文中设置值,后续的处理函数能够取到该值
// 调用该请求的剩余处理程序
c.Next()
// 不调用该请求的剩余处理程序
// c.Abort()
// 计算耗时
cost := time.Since(start)
log.Println(cost)
}
}记录响应体的中间件
我们有时候可能会想要记录下某些情况下返回给客户端的响应数据,这个时候就可以编写一个中间件来搞定。
Go
type bodyLogWriter struct {
gin.ResponseWriter // 嵌入gin框架ResponseWriter
body *bytes.Buffer // 我们记录用的response
}
// Write 写入响应体数据
func (w bodyLogWriter) Write(b []byte) (int, error) {
w.body.Write(b) // 我们记录一份
return w.ResponseWriter.Write(b) // 真正写入响应
}
// ginBodyLogMiddleware 一个记录返回给客户端响应体的中间件
// https://stackoverflow.com/questions/38501325/how-to-log-response-body-in-gin
func ginBodyLogMiddleware(c *gin.Context) {
blw := &bodyLogWriter{body: bytes.NewBuffer([]byte{}), ResponseWriter: c.Writer}
c.Writer = blw // 使用我们自定义的类型替换默认的
c.Next() // 执行业务逻辑
fmt.Println("Response body: " + blw.body.String()) // 事后按需记录返回的响应
}跨域中间件cors
推荐使用社区的GitHub - gin-contrib/cors: Official CORS gin's middleware 库,一行代码解决前后端分离架构下的跨域问题。
注意: 该中间件需要注册在业务处理函数前面。
这个库支持各种常用的配置项,具体使用方法如下。
Go
package main
import (
"time"
"github.com/gin-contrib/cors"
"github.com/gin-gonic/gin"
)
func main() {
router := gin.Default()
// CORS for https://foo.com and https://github.com origins, allowing:
// - PUT and PATCH methods
// - Origin header
// - Credentials share
// - Preflight requests cached for 12 hours
router.Use(cors.New(cors.Config{
AllowOrigins: []string{"https://foo.com"}, // 允许跨域发来请求的网站
AllowMethods: []string{"GET", "POST", "PUT", "DELETE", "OPTIONS"}, // 允许的请求方法
AllowHeaders: []string{"Origin", "Authorization", "Content-Type"},
ExposeHeaders: []string{"Content-Length"},
AllowCredentials: true,
AllowOriginFunc: func(origin string) bool { // 自定义过滤源站的方法
return origin == "https://github.com"
},
MaxAge: 12 * time.Hour,
}))
router.Run()
}当然你可以简单的像下面的示例代码那样使用默认配置,允许所有的跨域请求。
Go
func main() {
router := gin.Default()
// same as
// config := cors.DefaultConfig()
// config.AllowAllOrigins = true
// router.Use(cors.New(config))
router.Use(cors.Default())
router.Run()
}注册中间件
在gin框架中,我们可以为每个路由添加任意数量的中间件。
为全局路由注册
Go
func main() {
// 新建一个没有任何默认中间件的路由
r := gin.New()
// 注册一个全局中间件
r.Use(StatCost())
r.GET("/test", func(c *gin.Context) {
name := c.MustGet("name").(string) // 从上下文取值
log.Println(name)
c.JSON(http.StatusOK, gin.H{
"message": "Hello world!",
})
})
r.Run()
}为某个路由单独注册
Go
// 给/test2路由单独注册中间件(可注册多个)
r.GET("/test2", StatCost(), func(c *gin.Context) {
name := c.MustGet("name").(string) // 从上下文取值
log.Println(name)
c.JSON(http.StatusOK, gin.H{
"message": "Hello world!",
})
})为路由组注册中间件
为路由组注册中间件有以下两种写法。
写法1:
Go
shopGroup := r.Group("/shop", StatCost())
{
shopGroup.GET("/index", func(c *gin.Context) {...})
...
}写法2:
Go
shopGroup := r.Group("/shop")
shopGroup.Use(StatCost())
{
shopGroup.GET("/index", func(c *gin.Context) {...})
...
}中间件注意事项
gin默认中间件
gin.Default()默认使用了Logger和Recovery中间件,其中:
Logger中间件将日志写入gin.DefaultWriter,即使配置了GIN_MODE=release。Recovery中间件会recover任何panic。如果有panic的话,会写入500响应码。
如果不想使用上面两个默认的中间件,可以使用gin.New()新建一个没有任何默认中间件的路由。
gin中间件中使用goroutine
当在中间件或handler中启动新的goroutine时,不能使用 原始的上下文(c *gin.Context),必须使用其只读副本(c.Copy())。
中间件详解
gin框架涉及中间件相关有4个常用的方法,它们分别是c.Next()、c.Abort()、c.Set()、c.Get()。
中间件的注册
gin框架中的中间件设计很巧妙,我们可以首先从我们最常用的r := gin.Default()的Default函数开始看,它内部构造一个新的engine之后就通过Use()函数注册了Logger中间件和Recovery中间件:
Go
func Default() *Engine {
debugPrintWARNINGDefault()
engine := New()
engine.Use(Logger(), Recovery()) // 默认注册的两个中间件
return engine
}继续往下查看一下Use()函数的代码:
Go
func (engine *Engine) Use(middleware ...HandlerFunc) IRoutes {
engine.RouterGroup.Use(middleware...) // 实际上还是调用的RouterGroup的Use函数
engine.rebuild404Handlers()
engine.rebuild405Handlers()
return engine
}从下方的代码可以看出,注册中间件其实就是将中间件函数追加到group.Handlers中:
Go
func (group *RouterGroup) Use(middleware ...HandlerFunc) IRoutes {
group.Handlers = append(group.Handlers, middleware...)
return group.returnObj()
}而我们注册路由时会将对应路由的函数和之前的中间件函数结合到一起:
Go
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes {
absolutePath := group.calculateAbsolutePath(relativePath)
handlers = group.combineHandlers(handlers) // 将处理请求的函数与中间件函数结合
group.engine.addRoute(httpMethod, absolutePath, handlers)
return group.returnObj()
}其中结合操作的函数内容如下,注意观察这里是如何实现拼接两个切片得到一个新切片的。
Go
const abortIndex int8 = math.MaxInt8 / 2
func (group *RouterGroup) combineHandlers(handlers HandlersChain) HandlersChain {
finalSize := len(group.Handlers) + len(handlers)
if finalSize >= int(abortIndex) { // 这里有一个最大限制
panic("too many handlers")
}
mergedHandlers := make(HandlersChain, finalSize)
copy(mergedHandlers, group.Handlers)
copy(mergedHandlers[len(group.Handlers):], handlers)
return mergedHandlers
}也就是说,我们会将一个路由的中间件函数和处理函数结合到一起组成一条处理函数链条HandlersChain,而它本质上就是一个由HandlerFunc组成的切片:
Go
type HandlersChain []HandlerFunc中间件的执行
我们在上面路由匹配的时候见过如下逻辑:
Go
value := root.getValue(rPath, c.Params, unescape)
if value.handlers != nil {
c.handlers = value.handlers
c.Params = value.params
c.fullPath = value.fullPath
c.Next() // 执行函数链条
c.writermem.WriteHeaderNow()
return
}其中c.Next()就是很关键的一步,它的代码很简单:
Go
func (c *Context) Next() {
c.index++
for c.index < int8(len(c.handlers)) {
c.handlers[c.index](c)
c.index++
}
}从上面的代码可以看到,这里通过索引遍历HandlersChain链条,从而实现依次调用该路由的每一个函数(中间件或处理请求的函数)。

我们可以在中间件函数中通过再次调用c.Next()实现嵌套调用(func1中调用func2;func2中调用func3),
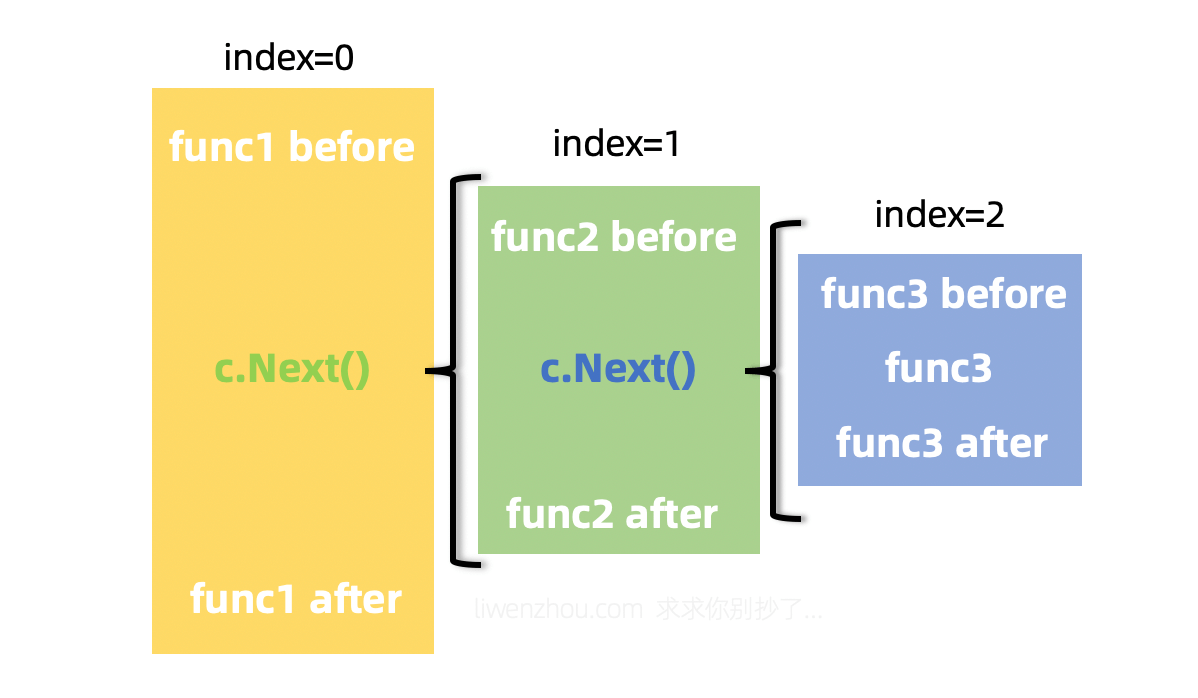
或者通过调用c.Abort()中断整个调用链条,从当前函数返回。
Go
func (c *Context) Abort() {
c.index = abortIndex // 直接将索引置为最大限制值,从而退出循环
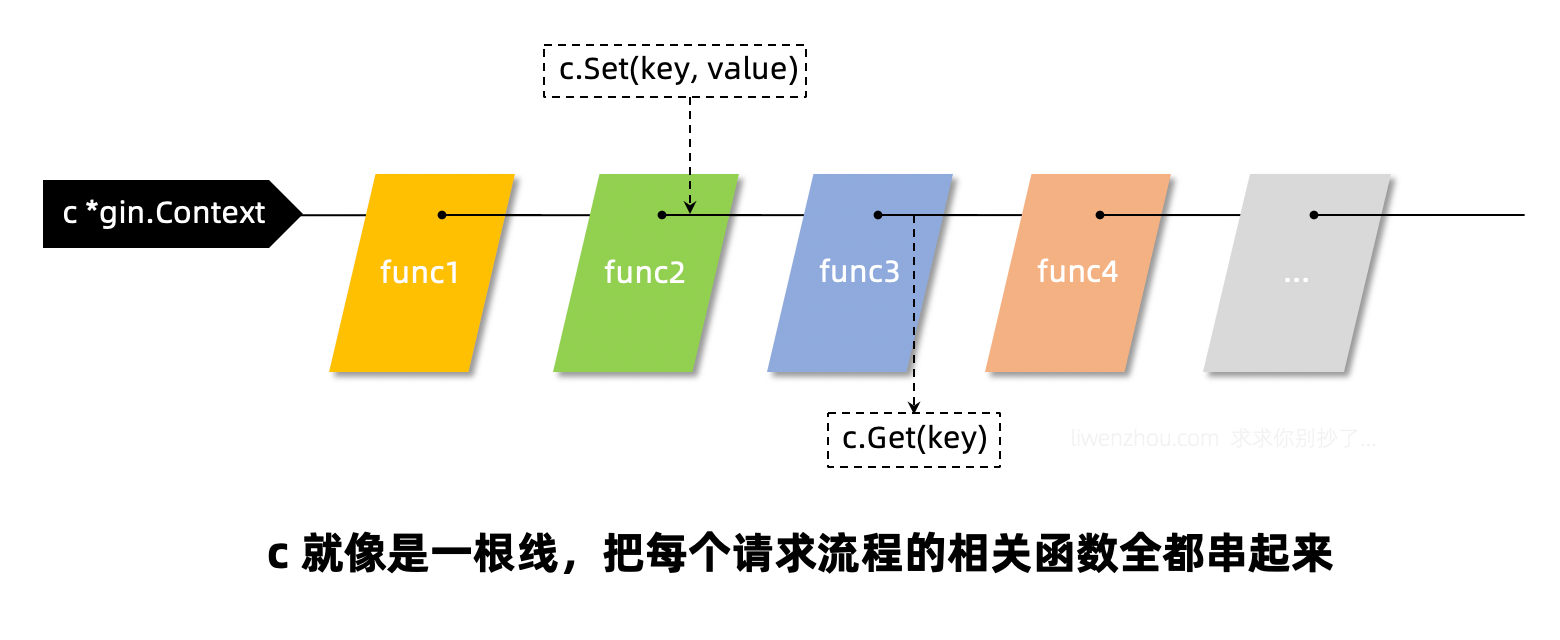
}c.Set()/c.Get()
c.Set()和c.Get()这两个方法多用于在多个函数之间通过c传递数据的,比如我们可以在认证中间件中获取当前请求的相关信息(userID等)通过c.Set()存入c,然后在后续处理业务逻辑的函数中通过c.Get()来获取当前请求的用户。c就像是一根绳子,将该次请求相关的所有的函数都串起来了。
Gin使用JWT
什么是JWT?
JWT全称JSON Web Token是一种跨域认证解决方案,属于一个开放的标准,它规定了一种Token 实现方式,目前多用于前后端分离项目和 OAuth2.0 业务场景下。
为什么需要JWT?
在之前的一些web项目中,我们通常使用的是Cookie-Session模式实现用户认证。相关流程大致如下:
- 用户在浏览器端填写用户名和密码,并发送给服务端
- 服务端对用户名和密码校验通过后会生成一份保存当前用户相关信息的session数据和一个与之对应的标识(通常称为session_id)
- 服务端返回响应时将上一步的session_id写入用户浏览器的Cookie
- 后续用户来自该浏览器的每次请求都会自动携带包含session_id的Cookie
- 服务端通过请求中的session_id就能找到之前保存的该用户那份session数据,从而获取该用户的相关信息。
这种方案依赖于客户端(浏览器)保存 Cookie,并且需要在服务端存储用户的session数据。
在移动互联网时代,我们的用户可能使用浏览器也可能使用APP来访问我们的服务,我们的web应用可能是前后端分开部署在不同的端口,有时候我们还需要支持第三方登录,这下Cookie-Session的模式就有些力不从心了。
JWT就是一种基于Token的轻量级认证模式,服务端认证通过后,会生成一个JSON对象,经过签名后得到一个Token(令牌)再发回给用户,用户后续请求只需要带上这个Token,服务端解密之后就能获取该用户的相关信息了。
想要了解JWT的原理,推荐大家阅读:阮一峰的JWT入门教程![]() https://www.ruanyifeng.com/blog/2018/07/json_web_token-tutorial.html
https://www.ruanyifeng.com/blog/2018/07/json_web_token-tutorial.html
安装
我们使用 Go 语言社区中的 jwt 相关库来构建我们的应用,例如:GitHub - golang-jwt/jwt: Go implementation of JSON Web Tokens (JWT).。
Go
go get github.com/golang-jwt/jwt/v4使用
默认Claim
如果我们直接使用JWT中默认的字段,没有其他定制化的需求则可以直接使用这个包中的和方法快速生成和解析token。
Go
// 用于签名的字符串
var mySigningKey = []byte("liwenzhou.com")
// GenRegisteredClaims 使用默认声明创建jwt
func GenRegisteredClaims() (string, error) {
// 创建 Claims
claims := &jwt.RegisteredClaims{
ExpiresAt: jwt.NewNumericDate(time.Now().Add(time.Hour * 24)), // 过期时间
Issuer: "qimi", // 签发人
}
// 生成token对象
token := jwt.NewWithClaims(jwt.SigningMethodHS256, claims)
// 生成签名字符串
return token.SignedString(mySigningKey)
}
// ParseRegisteredClaims 解析jwt
func ValidateRegisteredClaims(tokenString string) bool {
// 解析token
token, err := jwt.Parse(tokenString, func(token *jwt.Token) (interface{}, error) {
return mySigningKey, nil
})
if err != nil { // 解析token失败
return false
}
return token.Valid
}自定义Claims
我们需要定制自己的需求来决定JWT中保存哪些数据,比如我们规定在JWT中要存储username信息,那么我们就定义一个MyClaims结构体如下:
Go
// CustomClaims 自定义声明类型 并内嵌jwt.RegisteredClaims
// jwt包自带的jwt.RegisteredClaims只包含了官方字段
// 假设我们这里需要额外记录一个username字段,所以要自定义结构体
// 如果想要保存更多信息,都可以添加到这个结构体中
type CustomClaims struct {
// 可根据需要自行添加字段
Username string `json:"username"`
jwt.RegisteredClaims // 内嵌标准的声明
}然后我们定义JWT的过期时间,这里以24小时为例:
Go
const TokenExpireDuration = time.Hour * 24接下来还需要定义一个用于签名的字符串:
Go
// CustomSecret 用于加盐的字符串
var CustomSecret = []byte("夏天夏天悄悄过去")生成JWT
我们可以根据自己的业务需要封装一个生成 token 的函数。
Go
// GenToken 生成JWT
func GenToken(username string) (string, error) {
// 创建一个我们自己的声明
claims := CustomClaims{
username, // 自定义字段
jwt.RegisteredClaims{
ExpiresAt: jwt.NewNumericDate(time.Now().Add(TokenExpireDuration)),
Issuer: "my-project", // 签发人
},
}
// 使用指定的签名方法创建签名对象
token := jwt.NewWithClaims(jwt.SigningMethodHS256, claims)
// 使用指定的secret签名并获得完整的编码后的字符串token
return token.SignedString(CustomSecret)
}解析JWT
根据给定的 JWT 字符串,解析出数据。
Go
// ParseToken 解析JWT
func ParseToken(tokenString string) (*CustomClaims, error) {
// 解析token
// 如果是自定义Claim结构体则需要使用 ParseWithClaims 方法
token, err := jwt.ParseWithClaims(tokenString, &CustomClaims{}, func(token *jwt.Token) (i interface{}, err error) {
// 直接使用标准的Claim则可以直接使用Parse方法
//token, err := jwt.Parse(tokenString, func(token *jwt.Token) (i interface{}, err error) {
return CustomSecret, nil
})
if err != nil {
return nil, err
}
// 对token对象中的Claim进行类型断言
if claims, ok := token.Claims.(*CustomClaims); ok && token.Valid { // 校验token
return claims, nil
}
return nil, errors.New("invalid token")
}在gin框架中使用JWT
首先我们注册一条路由/auth,对外提供获取Token的渠道:
Go
r.POST("/auth", authHandler)我们的authHandler定义如下:
Go
func authHandler(c *gin.Context) {
// 用户发送用户名和密码过来
var user UserInfo
err := c.ShouldBind(&user)
if err != nil {
c.JSON(http.StatusOK, gin.H{
"code": 2001,
"msg": "无效的参数",
})
return
}
// 校验用户名和密码是否正确
if user.Username == "q1mi" && user.Password == "q1mi123" {
// 生成Token
tokenString, _ := GenToken(user.Username)
c.JSON(http.StatusOK, gin.H{
"code": 2000,
"msg": "success",
"data": gin.H{"token": tokenString},
})
return
}
c.JSON(http.StatusOK, gin.H{
"code": 2002,
"msg": "鉴权失败",
})
return
}用户通过上面的接口获取Token之后,后续就会携带着Token再来请求我们的其他接口,这个时候就需要对这些请求的Token进行校验操作了,很显然我们应该实现一个检验Token的中间件,具体实现如下:
Go
// JWTAuthMiddleware 基于JWT的认证中间件
func JWTAuthMiddleware() func(c *gin.Context) {
return func(c *gin.Context) {
// 客户端携带Token有三种方式 1.放在请求头 2.放在请求体 3.放在URI
// 这里假设Token放在Header的Authorization中,并使用Bearer开头
// 这里的具体实现方式要依据你的实际业务情况决定
authHeader := c.Request.Header.Get("Authorization")
if authHeader == "" {
c.JSON(http.StatusOK, gin.H{
"code": 2003,
"msg": "请求头中auth为空",
})
c.Abort()
return
}
// 按空格分割
parts := strings.SplitN(authHeader, " ", 2)
if !(len(parts) == 2 && parts[0] == "Bearer") {
c.JSON(http.StatusOK, gin.H{
"code": 2004,
"msg": "请求头中auth格式有误",
})
c.Abort()
return
}
// parts[1]是获取到的tokenString,我们使用之前定义好的解析JWT的函数来解析它
mc, err := ParseToken(parts[1])
if err != nil {
c.JSON(http.StatusOK, gin.H{
"code": 2005,
"msg": "无效的Token",
})
c.Abort()
return
}
// 将当前请求的username信息保存到请求的上下文c上
c.Set("username", mc.Username)
c.Next() // 后续的处理函数可以用过c.Get("username")来获取当前请求的用户信息
}
}注册一个/home路由,发个请求验证一下吧。
Go
r.GET("/home", JWTAuthMiddleware(), homeHandler)
func homeHandler(c *gin.Context) {
username := c.MustGet("username").(string)
c.JSON(http.StatusOK, gin.H{
"code": 2000,
"msg": "success",
"data": gin.H{"username": username},
})
}使用Docker部署Go Web应用
为什么需要Docker?
使用docker的主要目标是容器化。也就是为你的应用程序提供一致的环境,而不依赖于它运行的主机。
想象一下你是否也会遇到下面这个场景,你在本地开发了你的应用程序,它很可能有很多的依赖环境或包,甚至对依赖的具体版本都有严格的要求,当开发过程完成后,你希望将应用程序部署到web服务器。这个时候你必须确保所有依赖项都安装正确并且版本也完全相同,否则应用程序可能会崩溃并无法运行。如果你想在另一个web服务器上也部署该应用程序,那么你必须从头开始重复这个过程。这种场景就是Docker发挥作用的地方。
对于运行我们应用程序的主机,不管是笔记本电脑还是web服务器,我们唯一需要做的就是运行一个docker容器平台。从以后,你就不需要担心你使用的是MacOS,Ubuntu,Arch还是其他。你只需定义一次应用,即可随时随地运行。
Docker部署示例
准备代码
这里我先用一段使用net/http库编写的简单代码为例讲解如何使用Docker进行部署,后面再讲解稍微复杂一点的项目部署案例。
Go
package main
import (
"fmt"
"net/http"
)
func main() {
http.HandleFunc("/", hello)
server := &http.Server{
Addr: ":8888",
}
fmt.Println("server startup...")
if err := server.ListenAndServe(); err != nil {
fmt.Printf("server startup failed, err:%v\n", err)
}
}
func hello(w http.ResponseWriter, _ *http.Request) {
w.Write([]byte("hello bilibili.com!"))
}上面的代码通过8888端口对外提供服务,返回一个字符串响应:hello bilibili.com!。
创建Docker镜像
镜像(image)包含运行应用程序所需的所有东西------代码或二进制文件、运行时、依赖项以及所需的任何其他文件系统对象。
或者简单地说,镜像(image)是定义应用程序及其运行所需的一切。
编写Dockerfile
要创建Docker镜像(image)必须在配置文件中指定步骤。这个文件默认我们通常称之为Dockerfile。(虽然这个文件名可以随意命名它,但最好还是使用默认的Dockerfile。)
现在我们开始编写Dockerfile,具体内容如下:
注意:某些步骤不是唯一的,可以根据自己的需要修改诸如文件路径、最终可执行文件的名称等
bash
FROM golang:alpine
# 为我们的镜像设置必要的环境变量
ENV GO111MODULE=on \
GOPROXY=https://goproxy.cn,direct \
CGO_ENABLED=0 \
GOOS=linux \
GOARCH=amd64
# 移动到工作目录:/build
WORKDIR /build
# 将代码复制到容器中
COPY . .
# 将我们的代码编译成二进制可执行文件app
RUN go build -o app .
# 移动到用于存放生成的二进制文件的 /dist 目录
WORKDIR /dist
# 将二进制文件从 /build 目录复制到这里
RUN cp /build/app .
# 声明服务端口
EXPOSE 8888
# 启动容器时运行的命令
CMD ["/dist/app"]Dockerfile解析
From
我们正在使用基础镜像
golang:alpine来创建我们的镜像。这和我们要创建的镜像一样是一个我们能够访问的存储在Docker仓库的基础镜像。这个镜像运行的是alpine Linux发行版,该发行版的大小很小并且内置了Go,非常适合我们的用例。有大量公开可用的Docker镜像,请查看https://hub.docker.com/_/golang
Env
用来设置我们编译阶段需要用的环境变量。
WORKDIR,COPY,RUN
这几个命令做的事都写在注释里了,很好理解。
EXPORT,CMD
最后,我们声明服务端口,因为我们的应用程序监听的是这个端口并通过这个端口对外提供服务。并且我们还定义了在我们运行镜像的时候默认执行的命令
CMD ["/dist/app"]。
构建镜像
在项目目录下,执行下面的命令创建镜像,并指定镜像名称为goweb_app:
bash
docker build . -t goweb_app等待构建过程结束,输出如下提示:
...
Successfully built 90d9283286b7
Successfully tagged goweb_app:latest现在我们已经准备好了镜像,但是目前它什么也没做。我们接下来要做的是运行我们的镜像,以便它能够处理我们的请求。运行中的镜像称为容器。
执行下面的命令来运行镜像:
docker run -p 8888:8888 goweb_app标志位-p用来定义端口绑定。由于容器中的应用程序在端口8888上运行,我们将其绑定到主机端口也是8888。如果要绑定到另一个端口,则可以使用-p $HOST_PORT:8888。例如-p 5000:8888。
现在就可以测试下我们的web程序是否工作正常,打开浏览器输入http://127.0.0.1:8888就能看到我们事先定义的响应内容如下:
bash
hello bilibili.com!分阶段构建示例
我们的Go程序编译之后会得到一个可执行的二进制文件,其实在最终的镜像中是不需要go编译器的,也就是说我们只需要一个运行最终二进制文件的容器即可。
Docker的最佳实践之一是通过仅保留二进制文件来减小镜像大小,为此,我们将使用一种称为多阶段构建的技术,这意味着我们将通过多个步骤构建镜像。
bash
FROM golang:alpine AS builder
# 为我们的镜像设置必要的环境变量
ENV GO111MODULE=on \
GOPROXY=https://goproxy.cn,direct \
CGO_ENABLED=0 \
GOOS=linux \
GOARCH=amd64
# 移动到工作目录:/build
WORKDIR /build
# 将代码复制到容器中
COPY . .
# 将我们的代码编译成二进制可执行文件 app
RUN go build -o app .
###################
# 接下来创建一个小镜像
###################
FROM scratch
# 从builder镜像中把/dist/app 拷贝到当前目录
COPY --from=builder /build/app /
# 需要运行的命令
ENTRYPOINT ["/app"]使用这种技术,我们剥离了使用golang:alpine作为编译镜像来编译得到二进制可执行文件的过程,并基于scratch生成一个简单的、非常小的新镜像。我们将二进制文件从命名为builder的第一个镜像中复制到新创建的scratch镜像中。有关scratch镜像的更多信息,请查看https://hub.docker.com/_/scratch
附带其他文件的部署示例
这里以小清单项目为例,项目的Github仓库地址为https://github.com/knoci/list。
如果项目中带有静态文件或配置文件,需要将其拷贝到最终的镜像文件中。
我们的bubble项目用到了静态文件和配置文件,具体目录结构如下:
bash
list
├── README.md
├── conf
│ └── config.ini
├── controller
│ └── controller.go
├── dao
│ └── mysql.go
├── example.png
├── go.mod
├── go.sum
├── main.go
├── models
│ └── todo.go
├── routers
│ └── routers.go
├── setting
│ └── setting.go
├── static
│ ├── css
│ │ ├── app.8eeeaf31.css
│ │ └── chunk-vendors.57db8905.css
│ ├── fonts
│ │ ├── element-icons.535877f5.woff
│ │ └── element-icons.732389de.ttf
│ └── js
│ ├── app.007f9690.js
│ └── chunk-vendors.ddcb6f91.js
└── templates
├── favicon.ico
└── index.html我们需要将templates、static、conf三个文件夹中的内容拷贝到最终的镜像文件中。更新后的Dockerfile如下
bash
FROM golang:alpine AS builder
# 为我们的镜像设置必要的环境变量
ENV GO111MODULE=on \
GOPROXY=https://goproxy.cn,direct \
CGO_ENABLED=0 \
GOOS=linux \
GOARCH=amd64
# 移动到工作目录:/build
WORKDIR /build
# 将代码复制到容器中
COPY . .
# 下载依赖信息
RUN go mod download
# 将我们的代码编译成二进制可执行文件 bubble
RUN go build -o bubble .
###################
# 接下来创建一个小镜像
###################
FROM scratch
# 从builder镜像中把静态文件拷贝到当前目录
COPY ./templates /templates
COPY ./static /static
# 从builder镜像中把配置文件拷贝到当前目录
COPY ./conf /conf
# 从builder镜像中把/dist/app 拷贝到当前目录
COPY --from=builder /build/bubble /
# 需要运行的命令
ENTRYPOINT ["/bubble", "conf/config.ini"]简单来说就是多了几步COPY的步骤,大家看一下Dockerfile中的注释即可。
Tips: 这里把COPY静态文件的步骤放在上层,把COPY二进制可执行文件放在下层,争取多使用缓存。
关联其他容器
如果我们的项目中使用了MySQL,我们可以选择使用如下命令启动一个MySQL容器,它的别名为mysql8019;root用户的密码为root1234;挂载容器中的/var/lib/mysql到本地的/Users/q1mi/docker/mysql目录;内部服务端口为3306,映射到外部的13306端口。
docker run --name mysql8019 -p 13306:3306 -e MYSQL_ROOT_PASSWORD=root1234 -v /Users/q1mi/docker/mysql:/var/lib/mysql -d mysql:8.0.19这里需要修改一下我们程序中配置的MySQL的host地址为容器别名,使它们在内部通过别名(此处为mysql8019)联通。
[mysql]
user = root
password = root1234
host = mysql8019
port = 3306
db = bubble修改后记得重新构建bubble_app镜像:
docker build . -t bubble_app我们这里运行bubble_app容器的时候需要使用--link的方式与上面的mysql8019容器关联起来,具体命令如下:
docker run --link=mysql8019:mysql8019 -p 8888:8888 bubble_appDocker Compose模式
除了像上面一样使用--link的方式来关联两个容器之外,我们还可以使用Docker Compose来定义和运行多个容器。
Compose是用于定义和运行多容器 Docker 应用程序的工具。通过 Compose,你可以使用 YML 文件来配置应用程序需要的所有服务。然后,使用一个命令,就可以从 YML 文件配置中创建并启动所有服务。
使用Compose基本上是一个三步过程:
- 使用
Dockerfile定义你的应用环境以便可以在任何地方复制。 - 定义组成应用程序的服务,
docker-compose.yml以便它们可以在隔离的环境中一起运行。 - 执行
docker-compose up命令来启动并运行整个应用程序。
我们的项目需要两个容器分别运行mysql和bubble_app,我们编写的docker-compose.yml文件内容如下:
# yaml 配置
version: "3.7"
services:
mysql8019:
image: "mysql:8.0.19"
ports:
- "33061:3306"
command: "--default-authentication-plugin=mysql_native_password --init-file /data/application/init.sql"
environment:
MYSQL_ROOT_PASSWORD: "root1234"
MYSQL_DATABASE: "bubble"
MYSQL_PASSWORD: "root1234"
volumes:
- ./init.sql:/data/application/init.sql
bubble_app:
build: .
command: sh -c "./wait-for.sh mysql8019:3306 -- ./bubble ./conf/config.ini"
depends_on:
- mysql8019
ports:
- "8888:8888"这个 Compose 文件定义了两个服务:bubble_app 和 mysql8019。其中:
bubble_app
使用当前目录下的
Dockerfile文件构建镜像,并通过depends_on指定依赖mysql8019服务,声明服务端口8888并绑定对外8888端口。
mysql8019
mysql8019 服务使用 Docker Hub 的公共 mysql:8.0.19 镜像,内部端口3306,外部端口33061。
注意:
这里有一个问题需要注意,我们的bubble_app容器需要等待mysql8019容器正常启动之后再尝试启动,因为我们的web程序在启动的时候会初始化MySQL连接。这里共有两个地方要更改,第一个就是我们Dockerfile中要把最后一句注释掉:
# Dockerfile
...
# 需要运行的命令(注释掉这一句,因为需要等MySQL启动之后再启动我们的Web程序)
# ENTRYPOINT ["/bubble", "conf/config.ini"]第二个地方是在bubble_app下面添加如下命令,使用提前编写的wait-for.sh脚本检测mysql8019:3306正常后再执行后续启动Web应用程序的命令:
command: sh -c "./wait-for.sh mysql8019:3306 -- ./bubble ./conf/config.ini"当然,因为我们现在要在bubble_app镜像中执行sh命令,所以不能在使用scratch镜像构建了,这里改为使用debian:stretch-slim,同时还要安装wait-for.sh脚本用到的netcat,最后不要忘了把wait-for.sh脚本文件COPY到最终的镜像中,并赋予可执行权限哦。更新后的Dockerfile内容如下:
bash
FROM golang:alpine AS builder
# 为我们的镜像设置必要的环境变量
ENV GO111MODULE=on \
GOPROXY=https://goproxy.cn,direct \
CGO_ENABLED=0 \
GOOS=linux \
GOARCH=amd64
# 移动到工作目录:/build
WORKDIR /build
# 将代码复制到容器中
COPY . .
# 下载依赖信息
RUN go mod download
# 将我们的代码编译成二进制可执行文件 bubble
RUN go build -o bubble .
###################
# 接下来创建一个小镜像
###################
FROM debian:stretch-slim
# 从builder镜像中把脚本拷贝到当前目录
COPY ./wait-for.sh /
# 从builder镜像中把静态文件拷贝到当前目录
COPY ./templates /templates
COPY ./static /static
# 从builder镜像中把配置文件拷贝到当前目录
COPY ./conf /conf
# 从builder镜像中把/dist/app 拷贝到当前目录
COPY --from=builder /build/bubble /
RUN set -eux; \
apt-get update; \
apt-get install -y \
--no-install-recommends \
netcat; \
chmod 755 wait-for.sh
# 需要运行的命令
# ENTRYPOINT ["/bubble", "conf/config.ini"]所有的条件都准备就绪后,就可以执行下面的命令跑起来了:
docker-compose upCookie和Session
Cookie的由来
HTTP协议是无状态的,这就存在一个问题。
无状态的意思是每次请求都是独立的,它的执行情况和结果与前面的请求和之后的请求都无直接关系,它不会受前面的请求响应情况直接影响,也不会直接影响后面的请求响应情况。
一句有意思的话来描述就是人生只如初见,对服务器来说,每次的请求都是全新的。
状态可以理解为客户端和服务器在某次会话中产生的数据,那无状态的就以为这些数据不会被保留。会话中产生的数据又是我们需要保存的,也就是说要"保持状态"。因此Cookie就是在这样一个场景下诞生。
Cookie是什么
在 Internet 中,Cookie 实际上是指小量信息,是由 Web 服务器创建的,将信息存储在用户计算机上(客户端)的数据文件。一般网络用户习惯用其复数形式 Cookies,指某些网站为了辨别用户身份、进行 Session 跟踪而存储在用户本地终端上的数据,而这些数据通常会经过加密处理。
Cookie的机制
Cookie是由服务器端生成 ,发送给User-Agent(一般是浏览器),浏览器会将Cookie的key/value保存到某个目录下的文本文件内,下次请求同一网站时就发送该Cookie给服务器 (前提是浏览器设置为启用cookie)。Cookie名称和值可以由服务器端开发自己定义,这样服务器可以知道该用户是否是合法用户以及是否需要重新登录等,服务器可以设置或读取Cookies中包含信息,借此维护用户跟服务器会话中的状态。
总结一下Cookie的特点:
- 浏览器发送请求的时候,自动把携带该站点之前存储的Cookie信息。
- 服务端可以设置Cookie数据。
- Cookie是针对单个域名的,不同域名之间的Cookie是独立的。
- Cookie数据可以配置过期时间,过期的Cookie数据会被系统清除。
Gin框架操作Cookie
Go
import (
"fmt"
"github.com/gin-gonic/gin"
)
func main() {
router := gin.Default()
router.GET("/cookie", func(c *gin.Context) {
cookie, err := c.Cookie("gin_cookie") // 获取Cookie
if err != nil {
cookie = "NotSet"
// 设置Cookie
c.SetCookie("gin_cookie", "test", 3600, "/", "localhost", false, true)
}
fmt.Printf("Cookie value: %s \n", cookie)
})
router.Run()
}Session的由来
Cookie虽然在一定程度上解决了"保持状态"的需求,但是由于Cookie本身最大支持4096字节,以及Cookie本身保存在客户端,可能被拦截或窃取,因此就需要有一种新的东西,它能支持更多的字节,并且他保存在服务器,有较高的安全性。这就是Session。
问题来了,基于HTTP协议的无状态特征,服务器根本就不知道访问者是"谁"。那么上述的Cookie就起到桥接的作用。
用户登陆成功之后,我们在服务端为每个用户创建一个特定的session和一个唯一的标识,它们一一对应。其中:
- Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
- 唯一标识通常称为
Session ID会写入用户的Cookie中。
这样该用户后续再次访问时,请求会自动携带Cookie数据(其中包含了Session ID),服务器通过该Session ID就能找到与之对应的Session数据,也就知道来的人是"谁"。
总结而言:Cookie弥补了HTTP无状态的不足,让服务器知道来的人是"谁";但是Cookie以文本的形式保存在本地,自身安全性较差;所以我们就通过Cookie识别不同的用户,对应的在服务端为每个用户保存一个Session数据,该Session数据中能够保存具体的用户数据信息。