在使用 Elasticsearch 进行数据查询时,很多开发者、读者会遇到这样的问题:一次性检索大量数据,导致查询速度缓慢、网络延迟增加,甚至影响系统的整体性能。
单次获取过多数据不仅增加了网络传输的负担,还会使查询过程复杂化,降低响应速度。
本文将深入探讨该误区的常见场景、错误原因以及优化方案,帮助大家有效避免这个常见的性能陷阱。
1. 误区背景:单次获取大量数据
许多开发者在使用 Elasticsearch 进行数据查询时,往往试图一次性获取大量文档,认为可以减少查询次数并加速开发流程。
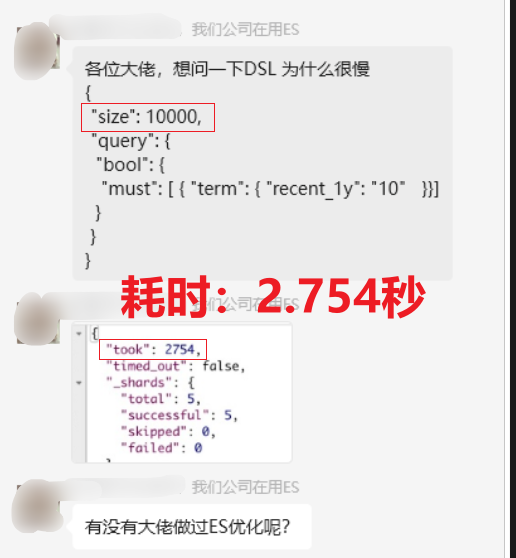
------来源:https://t.zsxq.com/cYUnx
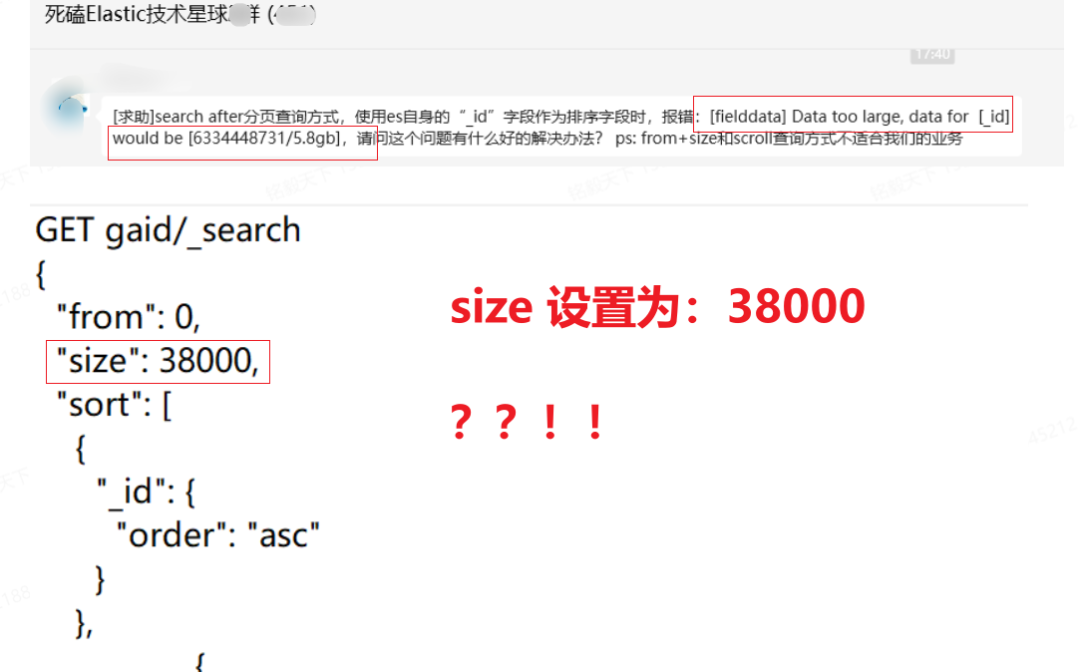
问题来源:https://articles.zsxq.com/id_qvaduu4ejgns.html
然而,Elasticsearch 是为分布式环境设计的,单次大规模的数据检索会对系统的性能造成负面影响,
具体表现为:
-
网络延迟增加。 大量数据的传输会占用带宽资源,导致网络延迟加大。
-
查询性能下降。系统需要消耗更多的内存和 CPU 来处理大规模结果集,进而拖慢查询速度。
-
系统负载增加。在负载高峰期,多个大查询可能导致节点资源过载。
2. 真实场景:电商平台用户查询
2.1 场景描述:
某电商平台的用户数据存储在一个包含数百万条用户记录的 Elasticsearch 索引中。
业务部门需要查询用户数据进行分析,但开发团队直接通过 match_all 查询所有用户,并设置 size 参数为 10000,试图一次性获取大量数据。
javascript
GET /users/_search
{
"query": {
"match_all": {}
},
"size": 10000
}2.2 问题描述:
该查询一次性返回 10000 条完整的用户数据,导致以下问题:
- 问题1:网络延迟
10,000 条数据中包含许多不必要的字段,增大了网络传输的数据量,导致响应时间延长。
大家知道, Elasticsearch 非 MySQL 等关系型数据库,字段不需要提前设定,如果 Mapping 不设置 strict 而是 默认值,意味着字段可以无限扩充,直到接近默认值 1000。
具体限制的设置项是:
css
index.mapping.total_fields.limit此参数决定一个索引中可以包含的字段的最大数量。默认值是 1000。
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-settings-limit.html
- 问题2:查询性能问题
处理如此多的数据占用了系统资源,使得查询速度减慢,影响了其他业务请求。
- 问题3:用户体验差
由于查询响应缓慢,业务人员在使用系统时感觉卡顿,影响日常工作效率。
3、错误原因分析
出现这种性能问题的主要原因是:
- 可能原因1:一次性获取过多数据
在大量数据场景中,单次获取 10000 条数据会显著增加负载。
- 可能原因2:未使用字段过滤
默认情况下,Elasticsearch 返回每个文档的所有字段,而业务部门往往只需要几个关键字段。
- 可能原因3:未分页处理
没有采用分页机制来分批获取数据,而是直接获取整个结果集。
4、改进方案
要优化这种场景下的查询,以下几种策略可以显著提升性能:
4.1 限制返回的文档数量
通过分页机制限制每次查询返回的文档数量,避免一次性获取过多数据。
分页不仅能减小单次查询的负载,还能提升整体查询的稳定性。
go
GET /users/_search
{
"query": {
"match_all": {}
},
"size": 10,
"from": 0
}这个查询一次性只返回 10条文档,并且可以通过 from 参数进行分页查询,避免单次查询获取过多数据。
这里深度分页的弊端关注一下,如下两幅图(建议放大查看)所示:Elasticsearch 中的深分页问题是一个常见的性能陷阱,因为越深的分页需要对越多的数据进行处理,这可能导致大量的资源消耗。
假设不断在这个边缘试探,会导致内存耗尽甚至有宕机风险。


4.2 使用源过滤(_source filtering)
在业务场景中,并非所有字段都是必要的,因此通过源过滤功能只返回特定字段可以减少数据传输量,进而提升查询效率。
go
GET /users/_search
{
"query": {
"match_all": {}
},
"_source": ["name", "email"],
"size": 10,
"from": 0
}这个查询只返回用户的 name 和 email 字段,减少了不必要的字段传输,降低了网络延迟和系统资源的消耗。
4.3 利用部分更新
如果需要更新用户文档,你可以只提供更新的字段,Elasticsearch 会重新索引整个文档,但不需要在请求中提交完整文档。部分更新减少了请求体的大小,但重新索引整个文档的操作仍会发生。
go
POST /users/_update/1
{
"doc": {
"email": "new_email@example.com"
}
}4.4 使用 Scroll API 或 search_after 处理大量数据
对于确实需要处理大量数据的场景,Scroll API 是更好的解决方案。Scroll API 允许你分批检索大量文档而不会影响集群性能。
go
GET /users/_search?scroll=1m
{
"query": {
"match_all": {}
},
"size": 100
}
POST /_search/scroll
{
"scroll": "1m",
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAPnMWSU5tbk5Za1NsVEd..."
}初始查询的时候,设置 scroll 参数并指定时间窗口,初次检索 100 条数据。
滚动查询需要使用 scroll_id 获取接下来的批次,直到所有数据被检索完。
Scroll API 保持了上下文信息,允许高效地分批处理数据,适用于一次性处理大量数据的批处理任务。
更多推荐:干货 | 全方位深度解读 Elasticsearch 分页查询
5. 进一步优化建议
5.1 合理设置查询条件
避免使用过于宽泛的查询条件,如 match_all,可以通过精确条件限定查询结果集的大小。
5.2 使用聚合功能
如果你只关心统计数据而不是具体文档,利用 Elasticsearch 的聚合功能可以直接返回统计结果,避免大量数据传输。
5.3 索引优化
定期优化索引,确保分片和副本的设置合理,避免查询时的热点问题。
6. 小结
在使用 Elasticsearch 时,合理设计查询是提升系统性能的关键。
通过限制返回文档数量、使用源过滤和部分更新等技术,可以有效减少数据传输量,提高查询效率。
对于需要检索大量数据的情况,利用 Scroll API 和分页机制,可以进一步优化查询性能,避免一次性获取大量数据带来的性能问题。
Elasticsearch 的强大功能需要合理使用,开发者应根据实际业务需求设计高效的查询方案,以充分发挥其优势。
更多推荐

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn------ElasticStack进阶助手

抢先一步学习进阶干货!