
1、背景
在微服务拆分过程里,会对数据库模块重新进行建模拆分,导致部分表和数据,出现物理隔离,导致跨库JOIN的SQL不可行,并在数据检索上也有性能损耗的风险。下面我们来一起探讨一下,具体的解决方案。
1.1 方案比较
业界一般解决方案包括不限于下面几个
| 方案 | 实现手段 | 优点 | 缺点 |
|---|---|---|---|
| 应用程序层面改造 | 通过子查询、UNION ALL或进行JOIN操作来实现类似的效果 | 灵活性高、易于实现:可以根据具体需求定制查询逻辑 | * 性能问题:复杂的JOIN操作和子查询可能导致性能下降,尤其是在大数据量和高并发情况下。 * 维护成本高:随着业务逻辑的变化,SQL语句可能需要频繁修改和维护。 * 可读性差:复杂的SQL语句可能难以理解和维护。 |
| 使用mysql的FEDERATED引擎的表 | 自带的联邦存储引擎 | * 数据集中管理:可以将多个数据库的数据集中到一个数据库中进行查询和管理。 * 减少网络开销:通过本地代理表访问远程数据,减少了网络传输的开销。 | * 性能问题:FEDERATED引擎的性能通常不如本地表,尤其是在跨网络访问时。 * 可靠性问题:依赖于远程数据库的可用性,如果远程数据库不可用,本地代理表也无法访问数据。 * 安全性问题:需要确保远程数据库的安全性,防止数据泄露。 |
| 使用BI工具离线分析 | * 强大的分析功能:BI工具通常提供丰富的数据分析和可视化功能。 * 易于使用:用户友好的界面,便于非技术人员进行数据分析。 | * 延时性问题可能比较严重 * 机器配置要求也高 | |
| 使用Mysql跨库的平替方案实现 | 如ES文本搜索引擎等 | * 高性能:Elasticsearch等文本搜索引擎通常具有较高的查询性能,适合大数据量的查询。 * 分布式架构:支持分布式部署,具有良好的扩展性和容错性。 * 丰富的功能:提供全文搜索、聚合分析等多种功能。 | * 学习曲线:需要学习和掌握新的技术和工具。 * 数据同步问题:需要确保Elasticsearch中的数据与MySQL中的数据保持同步。 * 成本问题:部署和维护Elasticsearch集群可能需要较高的成本。 |
1.2 业务特点
-
确保数据的最终一致性
-
现实场景是读多写少,数据延迟性能容忍度较高,非金融业务场景
-
未来需要功能拓展,支持数据的灵活检索和模糊匹配
2、业务落地方案
2.1 核心组件选型
基于上述的业务特点,我们选择了通过Mysql + DTS + Kafka + ES来解决微服务拆分导致的跨库联表检索问题。
Mysql-数据库集群
Mysql有以下特点:
-
关系型数据库:MySQL作为关系型数据库,适用于存储结构化数据,并提供强大的事务支持和数据完整性保证。
-
微服务数据存储:在微服务架构中,每个服务可以拥有自己的MySQL数据库,实现数据的独立性和隔离性。
DTS-数据传输服务
DTS提供了多种数据传输的解决方案,我们是基于DTS消息订阅服务,本质是DTS内置了一个Kafka,并将binlog数据源,丢到kafka终端。
DTS有以下特点:
-
数据迁移与同步:DTS能够实现数据库和中间件之间的数据迁移和实时同步,确保数据在不同组件之间的准确性和一致性。
-
自动化操作:DTS提供自动化配置和管理工具,简化数据传输流程,减少人工干预。
ES-搜索引擎
Elasticsearch是一个强大的分布式搜索和分析引擎,它通过其灵活的数据模型和高级搜索功能,能够有效地解决跨表数据库查询的难题,ES具备以下的特点:
-
跨索引查询:Elasticsearch允许在一个查询中指定多个索引,实现跨表查询。这通过将不同表的数据映射到不同的索引中,使得查询能够跨越这些索引,类似于传统数据库中的JOIN操作
-
数据同步:Elasticsearch提供了多种数据同步方案,包括同步调用、异步通知和监听数据库的binlog。这些方案确保了数据在Elasticsearch和数据库之间的实时一致性
-
分布式排序:Elasticsearch支持分布式排序,能够在多个节点上并行处理排序任务,提高了排序性能
-
分片与副本:通过合理地设置分片和副本数量,Elasticsearch可以优化数据分布和查询性能,确保系统的高吞吐量和低延迟
2.2 架构整体方案
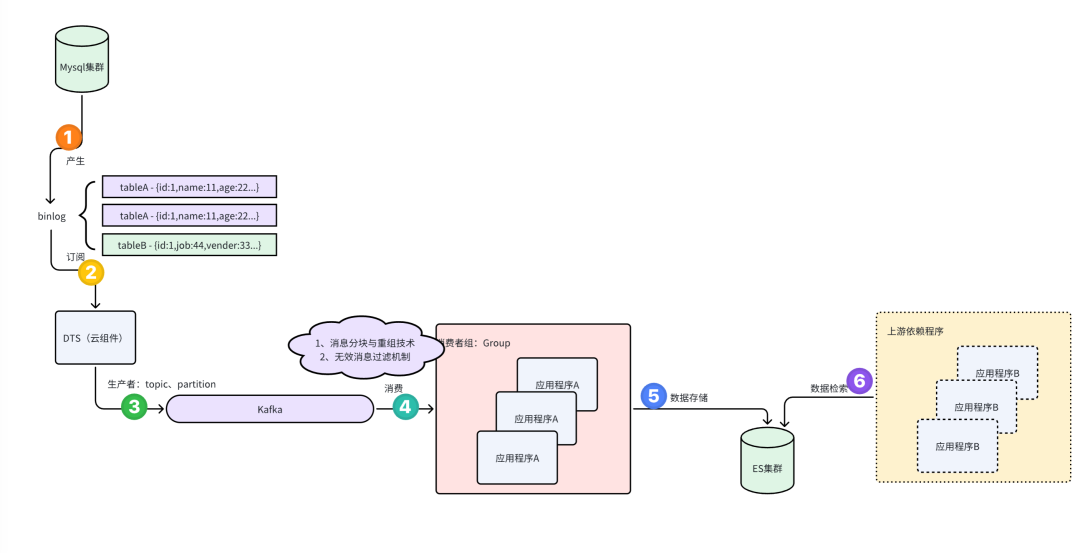
方案步骤如下:
-
MySQL集群产生Binlog
-
Binlog:MySQL的二进制日志,记录了数据库的所有更改操作(如插入、更新、删除)。
-
MySQL集群:通常指主从复制或多主复制的架构,确保数据的高可用性和冗余。
-
-
DTS采集Binlog
-
DTS(Data Transmission Service):腾讯云的数据传输服务,用于捕获和传输数据变更。
-
采集Binlog:DTS通过读取MySQL的Binlog,捕获数据的变更操作。
-
-
将Binlog数据发送到Kafka
-
Kafka集群:一个高吞吐量的分布式消息队列系统,用于处理实时数据流。
-
Topic和分区策略:DTS根据预定义的主题(Topic)和分区策略,将Binlog数据发送到Kafka集群的相应分区。分区策略可以基于表名等。
-
-
App轮训消费Kafka分区数据
-
轮训消费:应用程序(App)定期检查Kafka分区中的新数据,并进行消费。
-
数据处理:App对消费到的数据进行必要的处理,如过滤、转换等。
-
聚合和整合:App对处理后的数据进行聚合和整合,生成宽表数据。宽表通常包含多个相关表的数据,便于后续查询和分析。
-
-
将宽表数据落库ES
-
Elasticsearch(ES):一个分布式搜索和分析引擎,适用于全文搜索、结构化搜索和分析。
-
落库ES:将聚合后的宽表数据存储到Elasticsearch中,便于快速检索和分析。
-
-
上游服务检索ES数据
-
上游服务:其他依赖于这些数据的业务服务。
-
检索数据:上游服务可以通过Elasticsearch的API查询和检索已经存储的数据。
-
2.3 方案落地
2.3.1 Es宽表索引结构设计
我们用2张图对比,来说明ES宽表设计思路
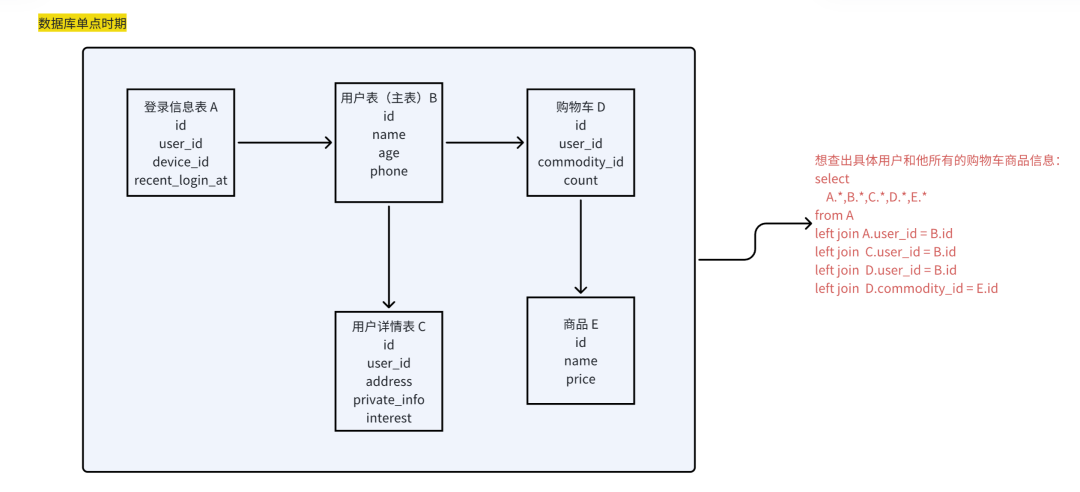
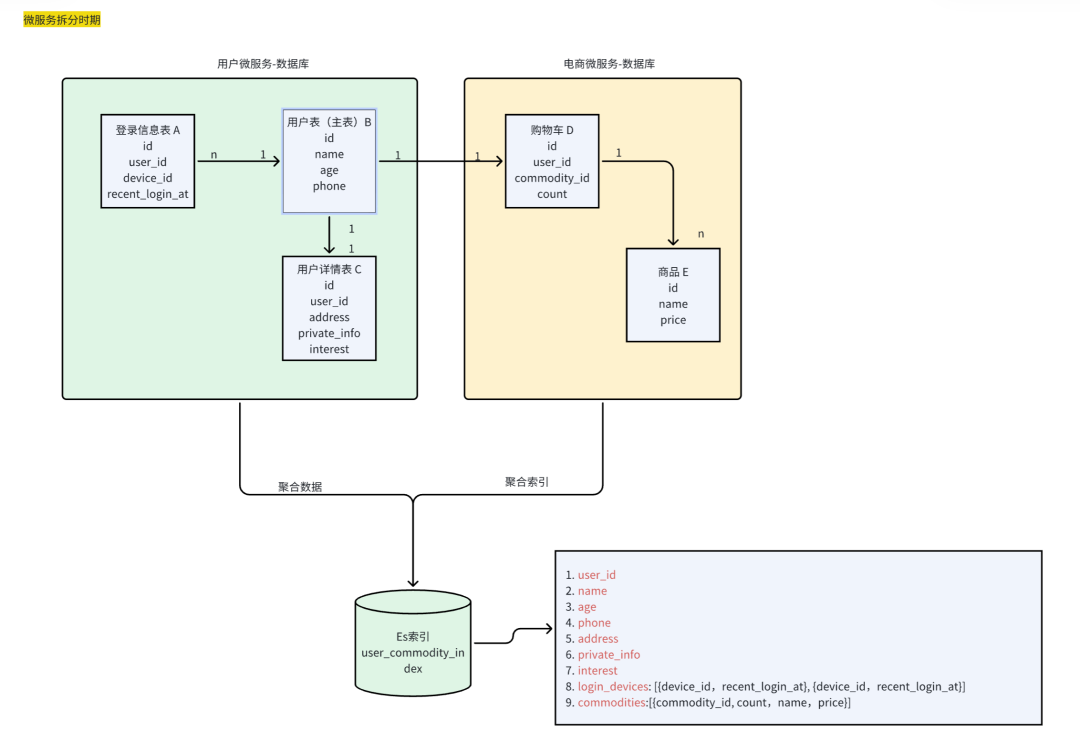
分析:
-
通过抽象表结构的ER关系图,我们用一个大的宽表,来存储诸多存在联表关系的表数据
-
例如字符串(text)、关键字(keyword)、整数(integer)、浮点数(float)、布尔值(boolean)等
-
1对1:使用平铺字段
-
1对N:使用json数组结构
-
2.3.2 DTS与Kafka的存储方案设计
DTS通过实时拉取源实例的Binlog增量日志,将增量数据解析成Kafka message,然后存储到内置Kafka Server。
(1)DTS支持的订阅事件
|------|--------------------------------------------------------------------------------|
| 操作类型 | 支持的 SQL 操作 |
| DML | INSERT、UPDATE、DELETE |
| DDL | CREATE DATABASE、DROP DATABASE、CREATE TABLE、ALTER TABLE、DROP TABLE、RENAME TABLE |
我们主要是监听相关业务表的DML事件。
精细到表维度
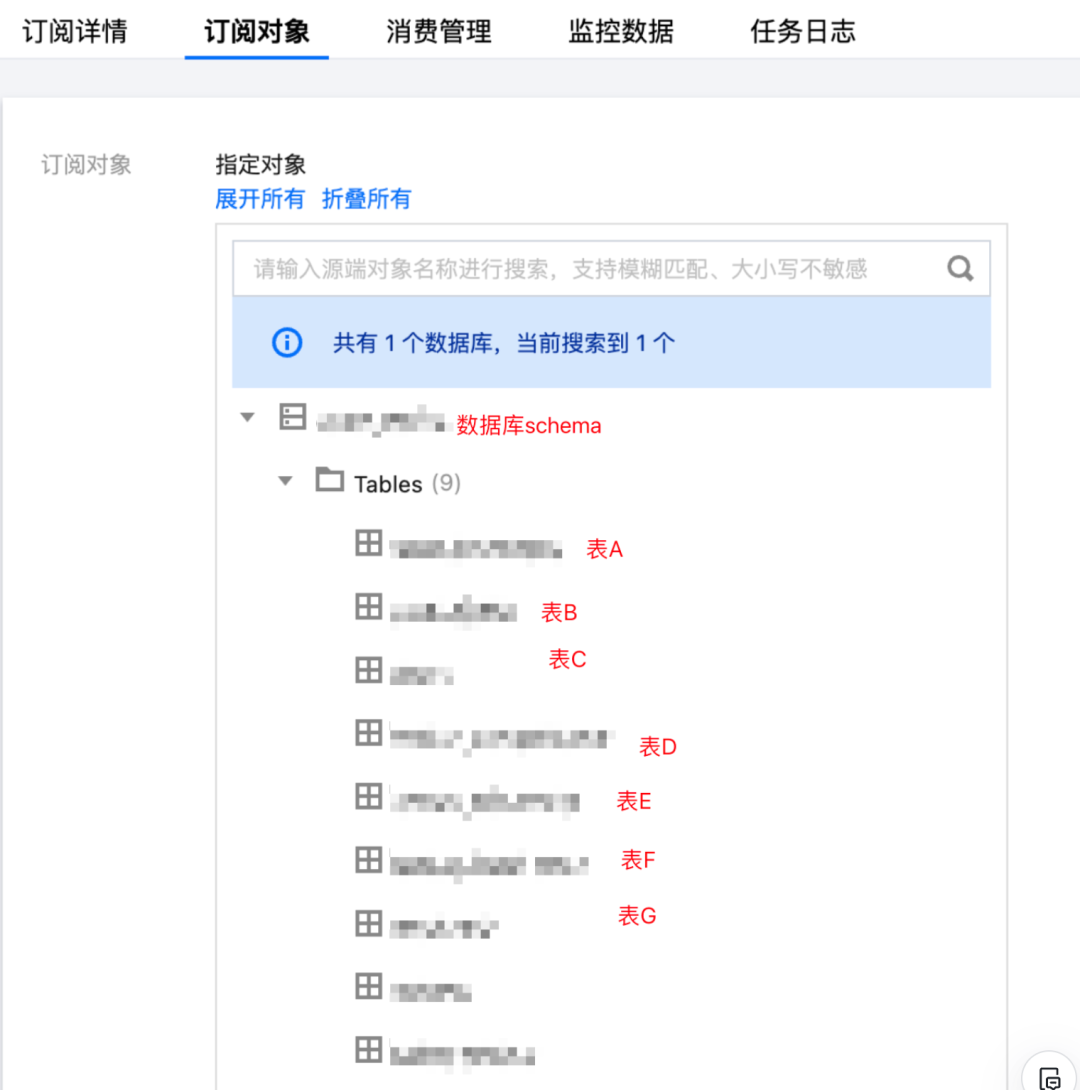
上面是DTS订阅了 某一数据库的某些表的binlog事件监听。这些被订阅表的以下变更,都会通过binlog,然后到DTS被暂存。
(2)DTS支持的消息格式
DTS内置支持 ProtoBuf、Avro 和 JSON 三种格式保存消息。
-
ProtoBuf 和 Avro 采用二进制格式,消费效率更高
-
JSON 采用轻量级的文本格式,更加简单易用
我们采用了ProtoBuf对消息进行序列化存储,使得消息存储更加灵活高效,空间占用更小,消费速度更快。
(3)内置Kafka支持的分区数量
设置数据投递到内置 kafka 中 Topic 的分区数量,增加分区数量可提高数据写入和消费的速度。单分区可以保障消息的顺序,多分区无法保障消息顺序,如果您对消费到消息的顺序有严格要求,请选择分区数量为1。
当用户选择 Kafka 多分区时,可以通过设置分区策略(见下面配置),将业务相互关联的数据路由到同一个分区中,这样方便用户处理消费数据。
(4)内置Kafka支持的分区策略
Topic 分区策略分为三种,将订阅数据生产到 Kafka 各分区:
-
按表名分区
-
表名+主键分区
-
使用自定义Topic分区策略
一、按表名分区
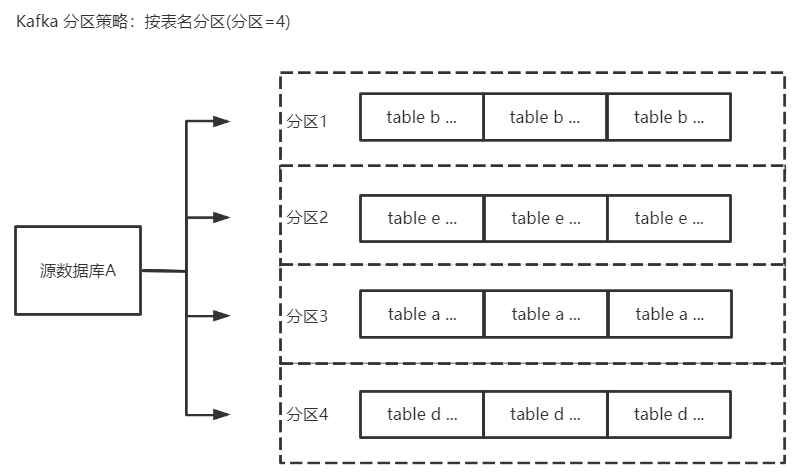
将源库的订阅数据按照表名进行分区,设置后相同表名的数据会写入同一个 Kafka 分区中。
好处
-
在数据消费时,同一个表内的数据变更总是顺序获得
-
适合表数据量均匀的场景,且各个表的数据量都十分独立解耦,没有太复杂的关联处理
缺点
-
仅指定按照表名分区时,如果一张表为热点数据(大表数据),可能导致某个分区的存储压力会非常大。
-
表之间存在1对1,或者1对n,所以必然导致不同表的数量级在后期会存在巨大差异,这会让分区的数据分布直接跟表数据量挂钩,不利于提高kafka的消费吞吐量,甚至造成消息堵塞
二、按表名+主键分区
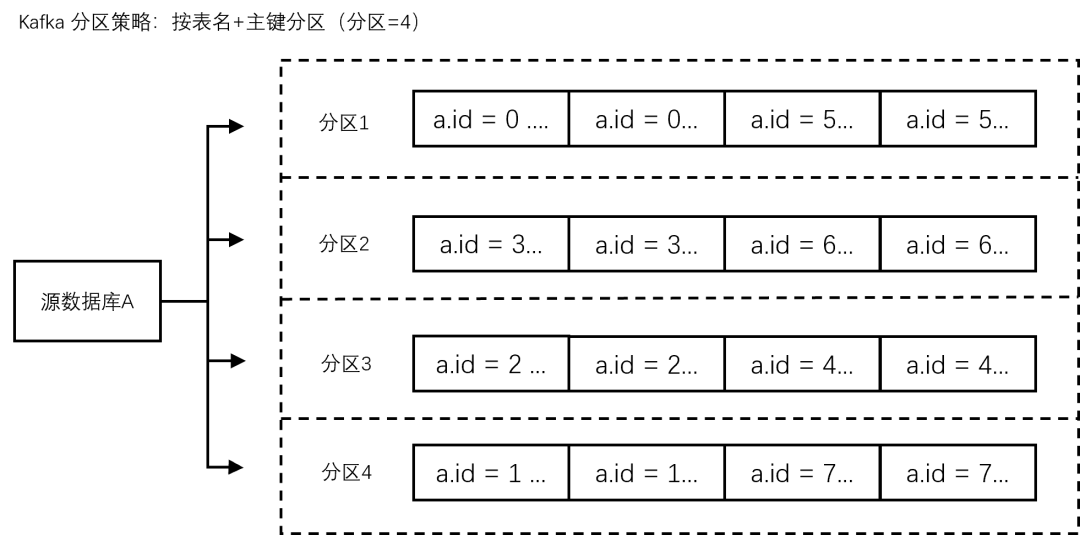
将源库的订阅数据按照表名+主键进行分区,设置后相同表名的同一个主键ID的数据,会写入同一个Kafka分区中。
好处
- 适用于热点数据(适用于热点数据的表),设置后热点数据的表,把相同主键的数据写入同一个分区,让同一个表的数据分散到不同分区中,提升并发消费效率。
三、自定义分区策略
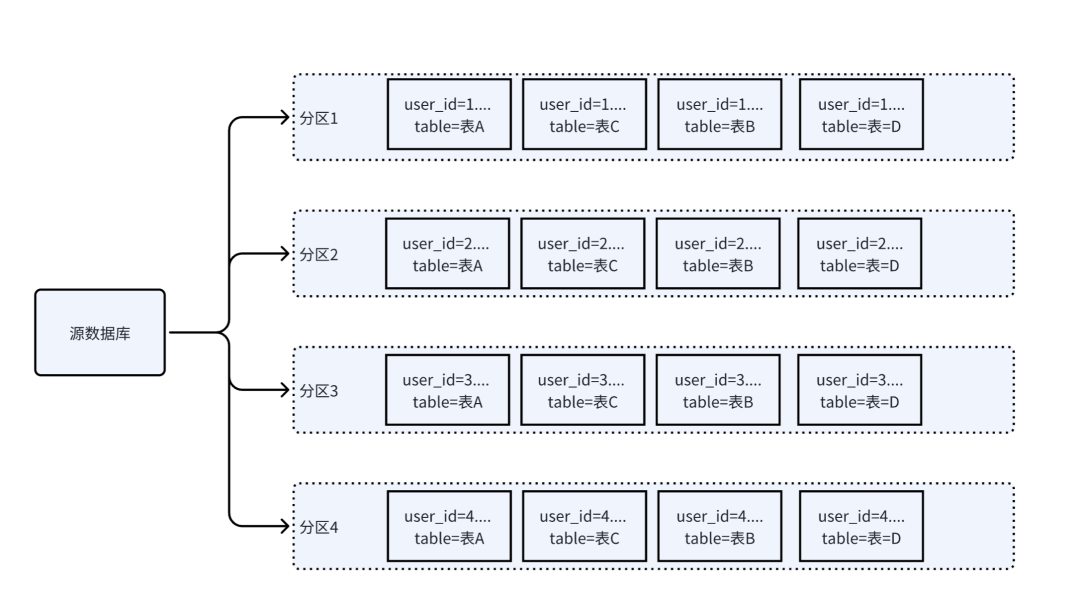
自定义分区策略:先通过正则表达式对订阅数据中的库名和表名进行匹配,将匹配到的数据按照表名+表列值进行分区投递。
好处
-
最终根据将不同表的不同列值,加入分区策略,并均匀写入到多个partition分区,让同一类的相关数据落到同一个分区
-
方便业务扩展聚合处理(本地缓存了用户信息,这样后续一定时间里,都可以复用了)
真实业务
虽然业务表都归属于独立模块,但都冗余了一个关联主表的字段user_id,因此我们可以通过对user_id设置列分区策略,使得某一位用户的所有关联表数据,落到同一个分区,便于后续做聚合处理:
-
正则表达式对库名和表名进行匹配
-
匹配后的数据再按照表的主键列进行分区
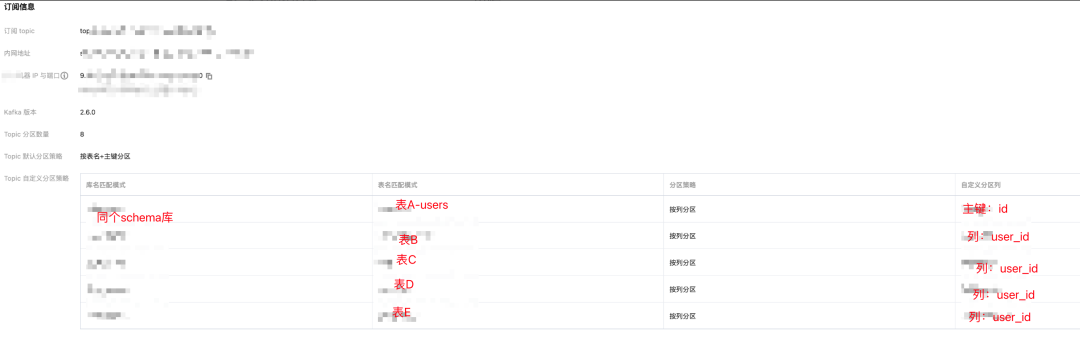
2.3.4 应用消费kafka消息
DTS通过实时拉取源实例的Binlog增量日志,将增量数据解析成Kafka message,然后存储到内置Kafka Server;因此我们可以通过Kafka Client来消费数据。
(1)DTS内置kafka特点
订阅的消息保存在内置Kafka中,默认保存时间为最近1天,单Topic的最大存储为500G。
(2)消息事件Record
过滤心跳事件
例如:checkPoint事件是用来检测心跳发送接受的,可以忽略这类事件(messageType = CHECKPOINT)
事件数据结构
|--------------------|------------------------------------------------------------------------------------------------------------------------------|
| Record 中的字段名称 | 说明 |
| id | 全局递增 ID。 |
| version | 协议版本,当前版本为1。 |
| messageType | 消息类型,枚举值:"INSERT","UPDATE","DELETE","DDL","BEGIN","COMMIT","HEARTBEAT","CHECKPOINT"。 |
| fileName | 当前 record 所在的 binlog 文件名。 |
| position | 当前 record 的在 binlog 中结束的偏移量,格式为 End_log_pos@binlog 文件编号。例如,当前 record 位于文件 mysql-bin.000004 中,结束偏移量为2196,则其值为"2196@4"。 |
| safePosition | 当前事务在 binlog 中开始的偏移量,格式同上。 |
| timestamp | 写入 binlog 的时间,unix 时间戳,秒级。binlog 记录的事务中对应 event header 里面的 timestamp,源端长事务操作可能会导致 timestamp 与 readerTimestamp 有时间差,这种属于正常情况。 |
| gtid | 当前的 gtid,如:c7c98333-6006-11ed-bfc9-b8cef6e1a231:9。 |
| transactionId | 事务 ID,只有 commit 事件才会生成事务 ID。 |
| serverId | 源库 serverId,查看源库 server_id 参考 SHOW VARIABLES LIKE 'server_id'。 |
| threadId | 提交当前事务的会话 ID,参考 SHOW processlist;。 |
| sourceType | 源库的数据库类型,当前版本只有 MySQL。 |
| sourceVersion | 源库版本,查看源库版本参考select version();。 |
| schemaName | 库名。 |
| tableName | 表名。 |
| objectName | 格式为:库名.表名。 |
| columns | 表中各列的定义。 |
| oldColumns | DML 执行前该行的数据,如果是 insert 消息,该数组为 null。 |
| newColumns | DML 执行后该行的数据,如果是 delete 消息,该数组为 null。 |
| sql | DDL 的 SQL 语句。 |
| executionTime | DDL 执行时长,单位为秒。 |
| heartbeatTimestamp | 心跳消息的时间戳,秒级。只有 heartbeat 消息才有该字段。 |
| syncedGtid | DTS 已解析 GTID 集合,格式形如:c7c98333-6006-11ed-bfc9-b8cef6e1a231:1-13。 |
| fakeGtid | 是否为构造的假 GTID,如未开启 gtid_mode,则 DTS 会构造一个 GTID。 |
| pkNames | 如果源库的表设有主键,则 DML 消息中会携带该参数,否则不会携带。 |
| readerTimestamp | DTS 处理这条数据的时间,unix 时间戳,单位为毫秒数。 |
| tags | QueryEvent 中的 status_vars,详细参考 QueryEvent。 |
| total | 如果消息分片,记录分片总数。当前版本 (version = 1) 无意义,预留扩展。 |
| index | 如果消息分片,记录当前分片的索引。当前版本 (version = 1) 无意义,预留扩展。 |
(3)正常业务流程和kafka消息拆包处理
根据2.3.2所述,kafka的消息是按user_id来定制分区策略的,通过消息过滤后,一次批量取消息会拿到多条Record(包括了update/delete/insert),即消费者将同时拿到一个用户关联的多个表数据变更记录;一个消息包含多个DML事件(不同的表、不同的log数据)。
异常情况:默认kafka最大的消息是8MB,但还是可能出现超限情况,即,一条binlog可能拆分为多条Record数据,因此在应用层只能在本地内存里,对多条消息进行合并操作。
下面对正常业务流程和kafka消息拆包处理分步描述:
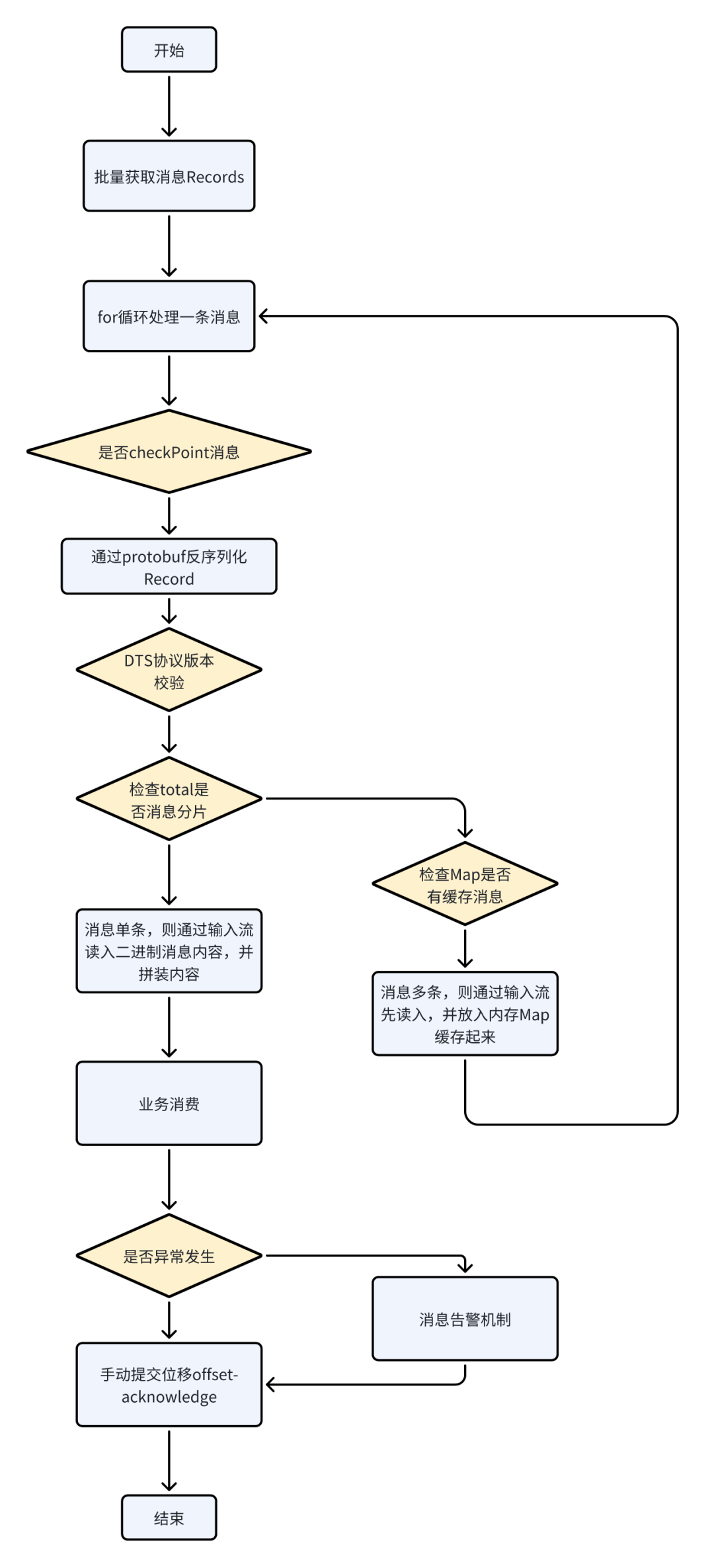
分析:
-
一个消费者,在一个分区里,消费是线程安全的。因此我们可以通过类似上图的逻辑,完成消息反序列化和业务处理。
-
kafka消息拆包是很常见的事情,如果我们想调整kafka消息拆包触发阈值,可以通过调整 Kafka 生产者的配置参数 max.request.size来实现
(4)策略模式处理不同数据结构的binlog
处理消息有以下需要注意的点:
-
DML事件类型:区分type是插入、更新、删除
-
表名:不同的表有不同的字段注入逻辑、模型构建方法
2.3.5 业务写入&读出ES
(1)业务写:应用客户端加锁
消费者组有以下几个建议:
-
应用的pod数量调整
- 这里search-app的数量设置为6,那么最终<partition分区数,可以确保所有实例都能消费到分区消息。
-
ES写操作:
-
-
更新:
-
信号量Semaphore加锁,并通过监听器成功&失败,都释放信号量,否则容易死锁
-
通过EsClient的异步执行api完成落库任务,提高消费能力
-
-
写入:
-
-
-
-
延迟500ms,提供一个空窗期给业务数据库的主从同步完成
-
检查doc是否存在
-
不存在则创建(es的version乐观锁)
-
内置重试机制
-
-
- 删除:
-
- 通过primaryKey直接删除doc
-
(2)业务读:应用客户端限流
参考之前写过客户端限流文章Guava客户端限流源码分析
(3)Es运维变更
需求会在重构期间不断调整,这不又来一个需求了吗。
我们要对已有的宽表增加字段,这就涉及到2个方面:
-
数据层面:有增量数据和存量数据
-
结构层面:有动态模板的mapping调整和字段运维变更
变更方案
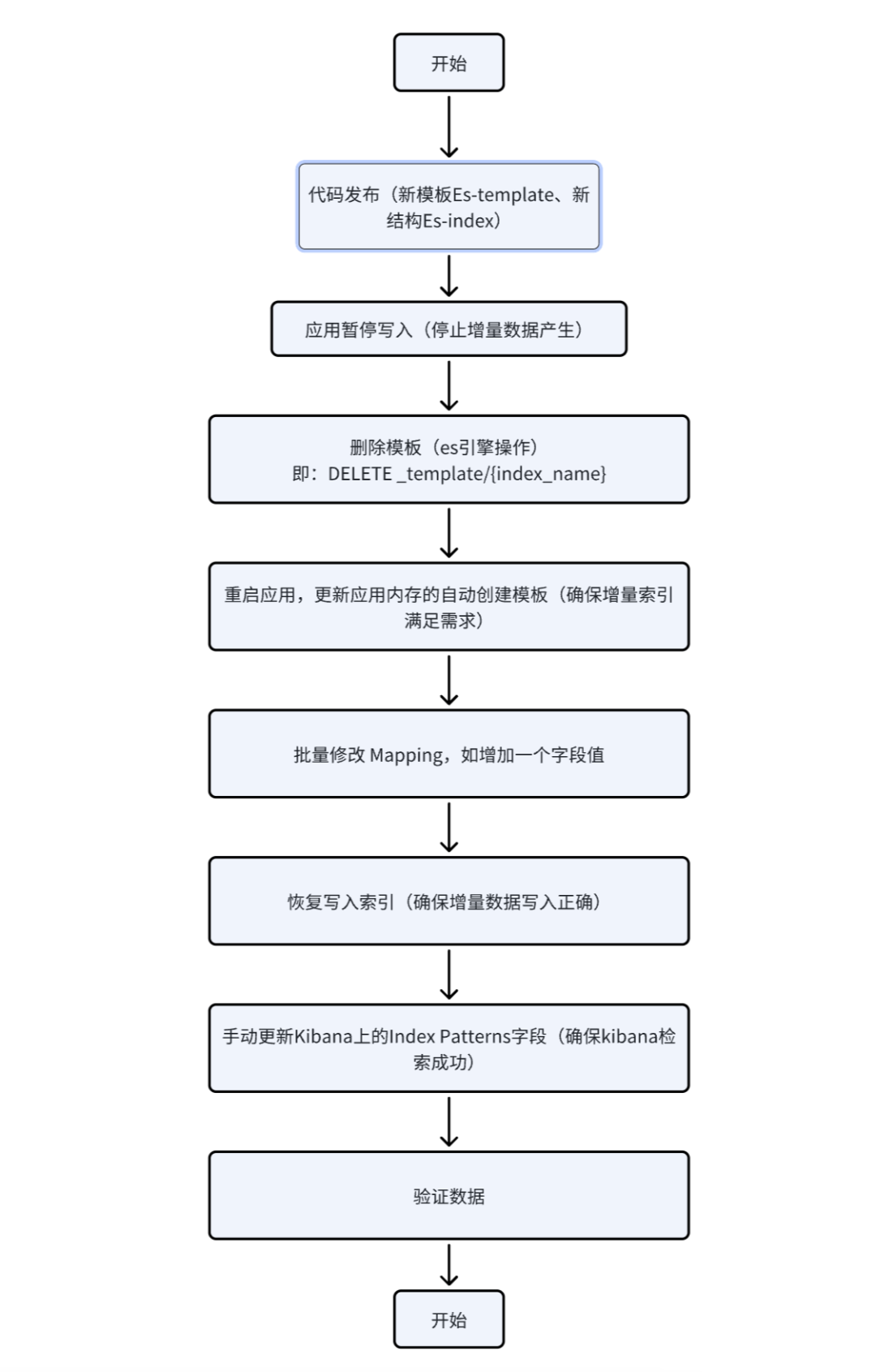
3、业务灰度
我们通过接口灰度策略,实现ES检索接口的逐步灰度。
可以参考我的上一篇文章:基于SpringMVC的API灰度方案
4、业务难点
难点1:消费者匹配kafka集群吞吐量
业务大表变更,可能导致的大量binlog生产,经过级联扩散,暴露应用程序的消费能力的不足,导致es写入效率降低。【埋个坑,后续补充问题的排查方向】
难点2:db与es的数据一致性维护
-
应用消费数据时,会进行异常捕获和重试,由于下游接口失败(超时、网络抖动、踩中了发布周期等原因),会重试2次,依旧失败则打日志和备份异常
-
运维接口批量同步数据
-
腾讯云,对kafka的堆积阈值设置告警
难点3:kafka消费延迟性问题
1~3s里,数据同步并消费完整。
-
产品层面做优化。增加用户的操作步骤,引导用户干点别事情
-
应用层面做优化。确保数据返回最新,并通过DB和redis缓存方案,提供最新数据
难点4:ES查询性能优化
es的深度分页问题
-
页面提供了最大2000条数据结果查询
-
openapi提供了快照分页+redis缓存的方案(通过redis缓存分页结果,提供查询性能)
过滤器优化
- 当进行精确值查找时, 我们会使用过滤器(filters)。过滤器很重要,因为它们执行速度非常快,不会计算相关度(直接跳过了整个评分阶段)而且很容易被缓存。我们会在本章后面的 过滤器缓存 中讨论过滤器的性能优势,不过现在只要记住:请尽可能多的使用过滤式查询。
分词器使用
- 默认使用了ES内置的standard分词器-BM25分析算法,将文本按照一定的规则进行切割,将其分成多个词项(Tokens),加速了数据检索。
难点5:es的并发读写问题
-
读请求:基于Guava的QPS客户端限流
-
写请求:乐观锁,version字段进行判断是否过期修改,考虑到es后续可能移除version字段,得改用seqNo或者primaryTerm。
参考:https://www.elastic.co/guide/cn/elasticsearch/guide/current/optimistic-concurrency-control.html
难点6:使用 DTS 进行数据迁移/同步,对目标数据库有啥影响?
全量导入阶段,DTS 写入目标库时,对目标库的主要影响在 CPU 和 IOPS。
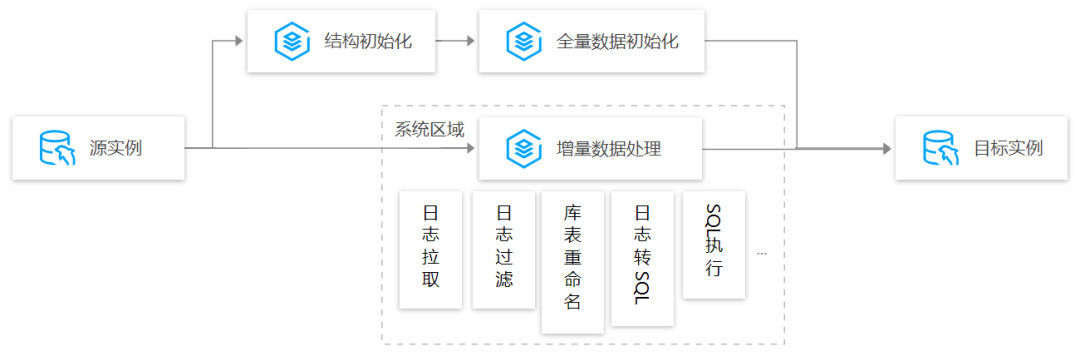
如下以 MySQL 同步为例进行介绍。整体流程为,数据从源实例中导出并导入到目标实例中,关键步骤包括结构初始化、全量数据初始化及增量数据处理。
(1)结构初始化
结构初始化即在目标实例中创建与源实例相同的库表结构信息。同步任务配置时,用户可以选择是否同步库表结构,如果目标实例中已经创建了与源实例相同的结构信息,则不需要同步库表结构信息,只需要同步数据即可,否则需要同步库表结构信息。
(2)全量数据初始化
结构初始化完成后,DTS 会进行存量数据初始化,即将源实例中的全部存量数据导出并导入到目标实例中。
(3)增量数据处理
增量数据处理通过源实例 Binlog 持续获取增量数据,进行一系列过滤转换操作后,将增量数据持久化到中间存储。在全量数据导入完成后,开始在目标实例上持续回放中间存储上的增量变更数据,从而实现目标实例与源实例数据保持一致。
5、总结
以上是我们的一次解决Es宽表解决跨库联表检索的设计方案总结,最后的业务难点和处理方法,后续有空我们继续聊!
6、参考:
7、其他文章