大型语言模型(LLM)可是自然语言处理和人工智能的一大步。它们能做的事情可多了,比如生成听起来挺靠谱的文本,翻译语言,总结文档,甚至写诗。但你知道吗,这些模型有时候会出现 "幻觉(Hallucinations)"。

咱们这篇文章就是要说说LLM的幻觉现象,探讨一下背后的原因。我们会聊聊训练数据啊,模型的概率性质啊,还有怎么让模型更接地气,减少这种幻觉。
那么,啥是幻觉呢?就是说,这些大型语言模型有时候会生成一些听起来头头是道,但实际上包含错误或者自相矛盾的信息。比如说,模型可能会告诉你,"北京是法国的首都。"这明显是错的,但你要是不查查资料,可能还真信了。
再比如,如果有人问模型关于某种食物的健康好处,模型可能会上网搜一搜,然后把搜到的东西告诉你。但网上的信息也不都是真的,有时候模型就会找到不靠谱的来源,给出错误的建议。
还有一个问题,就是模型有时候会误解你给它的问题的上下文,给出一些不太合适的回答。
那么,为啥会这样呢?原因可能有好几个:
-
训练数据的质量参差不齐
-
数据可能过时了
-
模型生成文本的方式是概率性的,有时候就会出错
-
模型对现实世界的理解还不够
-
有时候问题太模糊或者太复杂,模型就懵了
-
模型有时候会过度拟合,也就是死记硬背训练数据,而不是真正理解
这些都是我们得解决的问题,好让这些聪明的大模型更靠谱一些。
下面就先具体来聊聊这些问题。
其一 可能我们喂给LLM的训练数据本身就有坑,想象一下,LLM就像个贪吃的小怪兽,它得吃很多文本数据才能长大。但问题是,这些数据的质量和准确性参差不齐。有的数据可能是靠谱的,但也有的可能是不准确、有偏见或者自相矛盾的。LLM不管三七二十一,把这些数据都吸收了,结果有时候就会生成一些错误的文本。
另外,数据其实也是有"保鲜期"的,就这就是数据的时效性问题。训练数据集就像是个时间胶囊,记录了它收集时的信息。但问题是,模型可能会用这些过时的信息来回答现在的问题。
比如,如果一个模型只训练到了2024年的数据,那它就不会知道2025年之后发生的事情。如果我们问它一些最新的情况,它可能就会"幻觉"出一些不存在的信息。
举个例子,如果有一个数字教育工具,它用LLM来帮助学生学习历史,这个模型可能是在很多不同来源的历史文档上训练的。但这些文档里有些内容可能在训练之后被证明是错误的。所以,这个模型可能会把这些错误的信息教给学生。
其二 ,LLM其实在生成文本方面,玩的就是一个"概率游戏",它们会根据每个词序列出现的可能性来生成文本。有时候,它们可能会生成一些在语法和上下文上看起来都没问题,但实际上不准确或者不连贯的文本。
比如,如果用一个"AI小助手"来帮助学生练习语法,它可能会生成一些语法上没问题,上下文也合适的句子。但这些句子里可能有一些细微的错误,导致意思变得模糊不清。
所以,为了让这些大型语言模型更靠谱,我们还得在训练数据和模型设计上下功夫。
其三,LLM有时候就像是现实世界的"小白",是个没出过门的孩子,对现实世界的知识了解不够。这可能会导致它们产生幻觉,给出一些不真实的答案。
比如,有些模型想帮助孩子们提高阅读能力,可能会用一些高级词汇来挑战他们,希望他们能学到更多复杂的单词。这个想法听起来不错,但问题是,AI可能没有考虑到孩子们的成长阶段。实际上,教育者需要根据每个孩子的阅读水平来选择合适的书籍和活动,这样才能帮助他们逐步提高。
其四,当LLM接到一些模糊不清的指令时,它可能会给出一些听起来合理,但实际上并没有抓住要点的回答。这样的回答可能既不充分也不准确。如果指令更清晰一些,模型给出误导性答案的可能性就会降低。
举个例子,如果有人问模型,"你能推荐一些精彩的书籍吗?"模型可能会列出一堆著名的文学作品,但它可能没有考虑到用户具体的兴趣或者适合的年龄。所以,这样的回答可能就不太靠谱。
其五,LLM也会死记硬背,就会出现一个问题是过度拟合。LLM可能会记住训练数据中的一些短语或事实,并在不适当的上下文中重复它们。
比如,如果一个模型是用旧的文本和测验来训练的,它可能会过度依赖这些数据,而不理解新问题的上下文。所以,当遇到需要根据上下文来解释的新问题时,模型的回答可能就不符合学生的实际需求。
比如,如果一个学生问,"我需要做些什么来提高我的论文?"模型可能会给出一些通用的建议,这些建议可能来自于历史数据,但并没有考虑到这个学生具体的挑战和技能水平。
所以,为了让LLM更靠谱,我们还得在训练数据和模型设计上下更多的功夫,让它们能更好地理解和适应现实世界的需求。
那怎么让大型语言模型(LLM)更靠谱,减少那些让人头疼的幻觉问题? 有几个招儿能帮咱们搞定LLM的幻觉问题。
法一:用高质量的数据来训练,这是控制幻觉最有希望的方法之一。咱们得精心挑选数据集,处理它们,找出并修正错误。
研究人员和开发者得挑那些靠谱的信息来源。虽然检查信息源的可信度可能挺费劲,但这能提高训练材料的可信度。
另外,咱们能用自然语言处理(NLP)工具来找出训练数据里的错误。这些工具能发现不一致、偏见和错误的地方,还能标出可能需要更多或不同数据的区域。
还能用机器学习算法,比如隔离森林、局部异常因子和单类SVM来识别数据点之间的差异。
咱们还能用数据增强和偏见检测算法来解决偏见问题。像IBM的AI Fairness 360和Google的What-If工具就能通过统计测试和指标来检测和量化偏见。
对抗性训练也可以用来最小化偏见。比如,鉴别器模型可以在训练过程中识别并惩罚有偏见的输出。
法二:改进模型架构,其中的一个方法是创建上下文感知模型。这些模型能保持更广泛的上下文,让它们能更好地理解提示的真实含义。
在教育领域,上下文感知模型能让自适应学习环境成为可能。这意味着它们能根据学生的学习和表现来调整教育材料的形式。了解学生困难的上下文后,模型能调整其响应,确保学生的问题能得到适合他们学习风格的解释。
咱们可以法三:引入额外的外部事实检查机制。让模型将其响应与高质量信息的外部来源进行核对,这样能显著减少幻觉。
比如,辅导系统可以将其答案与包含经过事实检查的数学问题解决方案或科学事实讨论的可信学术数据库进行核对。这样一来,发送给学生的回答就总是最新和最准确的。
让模型检查其响应的事实意味着实时事实检查。这可以通过集成到使用大型语言模型的应用程序中的事实检查API来实现。
法四:指令调整, 它的变体也能帮助缓解幻觉。这意味着给LLM提供清晰且与上下文相关的指令,并指定预期的响应格式。
LLM的设计应该包含在遇到模糊不清的情况时请求额外信息的功能。随后的用户输入可以扩展和纠正早期的响应。
比如,LLM导师可以在学生提出的问题不够清晰时请求更多细节。在收到详细上下文后,模型就能提供适合学生的好解释,考虑到学生当前的熟练程度和具体问题。
法五:用户反馈,如果很多用户都指出同一个问题,那咱们就知道模型哪里不足,需要改进了。
收集用户反馈的系统能让我们了解模型在现实世界中的表现。这涉及到在使用大型语言模型的应用程序中构建反馈机制。比如,"AI小助手"可能允许学生对每个答案的质量进行评分或标记不良响应。这样的反馈能帮助我们解决模型准确性中的常见错误。
利用用户的反馈来改进模型意味着要不断更新我们的模型,让它变得更好。
咱们来总结一下怎么搞定大型语言模型(LLM)的幻觉问题,大多数都能同时解决好几个造成幻觉的原因:
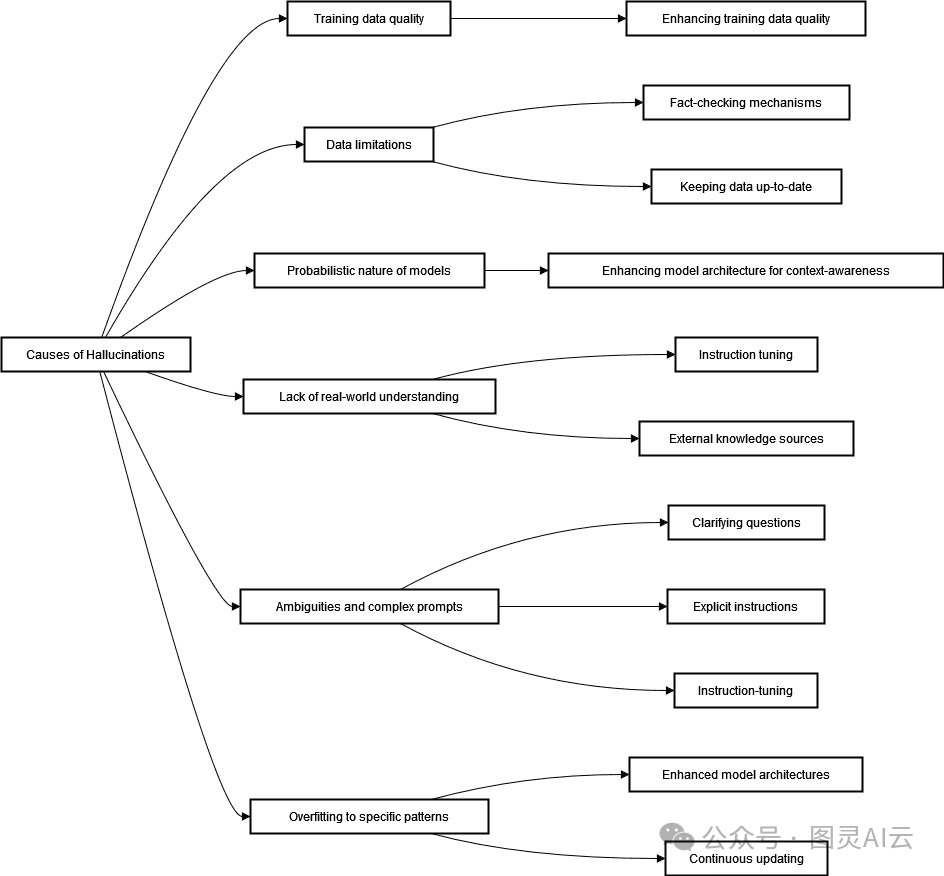
实际操作中,咱们得把这些策略结合起来,这样才能达到最好的效果。
总之,"幻觉"对大型语言模型来说是个不小的挑战。训练数据的质量和模型架构的限制都是造成这个问题的原因。而且,模型对现实世界的了解还不够。
要解决这些问题,咱们需要更高质量的训练数据,需要能处理模糊情况的模型架构,还需要实时的事实检查。另外,用户的反馈也能帮大忙,让模型不断进步,减少幻觉的发生。
