中秋假期,又可以玩玩 AI 了。前面介绍了 ComfyUI 的 Lora 模型以及 ControlNet,本文介绍另一个非常重要且使用的节点,IP-Adapter。
一、 IP-Adapter 概念
1.1 IPAdapter 的介绍
IP-Adapter 的是腾讯 ailab 实验室发布的一个 Stable Diffusion 的适配器,我愿称之为 Stable Diffusion 最强插件,它的作用是输入一张或多张图像,作为生成图像的提示词,实现图片风格或者肖像风格的迁移。本质上类似 MJ 的垫图。
官网地址:https://github.com/tencent-ailab/IP-Adapter
IP-Adapter 的实际用途有很多,比如保留产品样式,替换背景生成海报,根据设计图纸,生成装修效果图,对图片进行人脸替换等等。看看下面的商业海报案例:

1.2 IPAdapter 与 img2img 的区别
IPAdapter 与 img2img 的底层原理完全不同,对于 IPAdapter 可以简单理解为,将输入的一张图像,作为图像提示词。而 img2img 是提取输入的图像的特征进行模仿生成。
举个不是十分准确的例子:
IPAdapter 在生成图像时,是在根据文本提示词进行作画,在绘图的过程中,始终记得输入图像的风格,把这些风格元素融入到画师的灵感中,进行创作。
img2img 在生成图像时,是拿着输入的参考图,然后先将其慢慢擦除,在擦除的过程中,保留了需要的部分,然后在这个基础上进行绘画。这样绘画出来的结果,总有一部分是复刻了输入的参考图像,保有了原图像的痕迹。
二、基本使用
2.1 节点安装及模型下载
在 ComfyUI 中使用需要安装节点 ComfyUI_IPAdapter_plus。
官方地址:https://github.com/cubiq/ComfyUI_IPAdapter_plus
- 节点安装方式有很多,之前的文章有讲过,推荐使用 ComfyUI 节点管理器安装
- Github 主页中对需要安装的模型有详细描述,下载后按要求安装到指定路径即可,需要注意的内容有:
安装在 /ComfyUI/models/clip_vision 的两个文件下载后需要重命名,再放到对应的文件夹内;
如果没有 /ComfyUI/models/ipadapter 这个文件夹,可以自己手动新建一个。
下载基础模型

下载 FaceID 模型
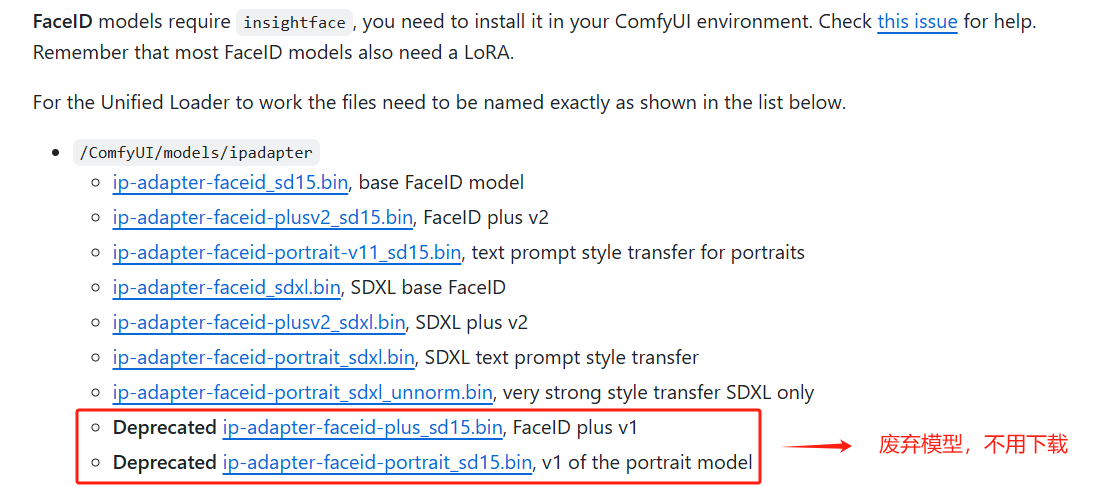
下载 Lora 模型
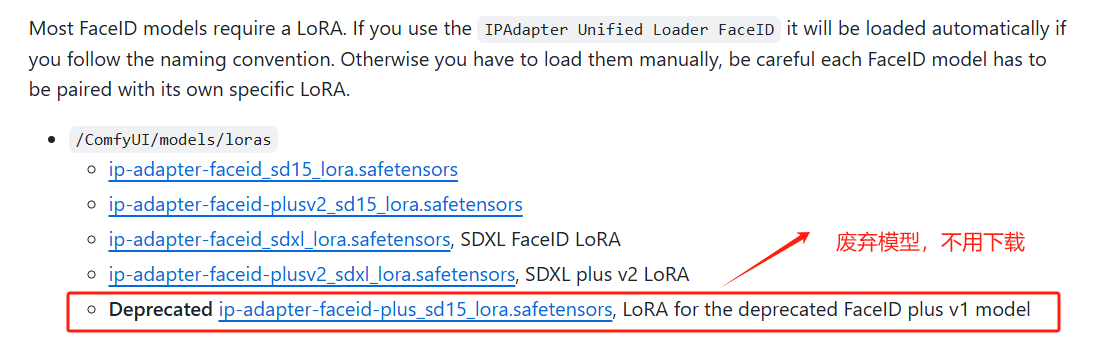
2.2 节点使用
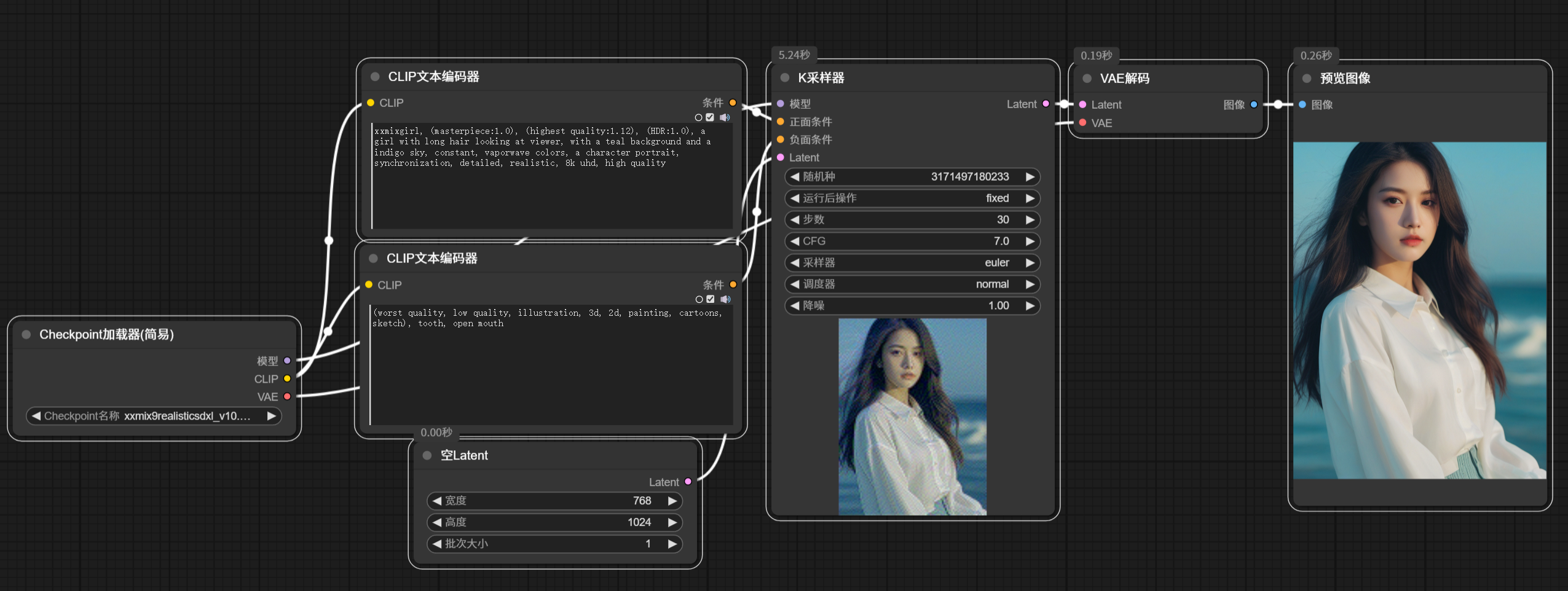
首先我们加载默认的工作流看看效果:
接下来我们接入 IP-Adapter 节点。
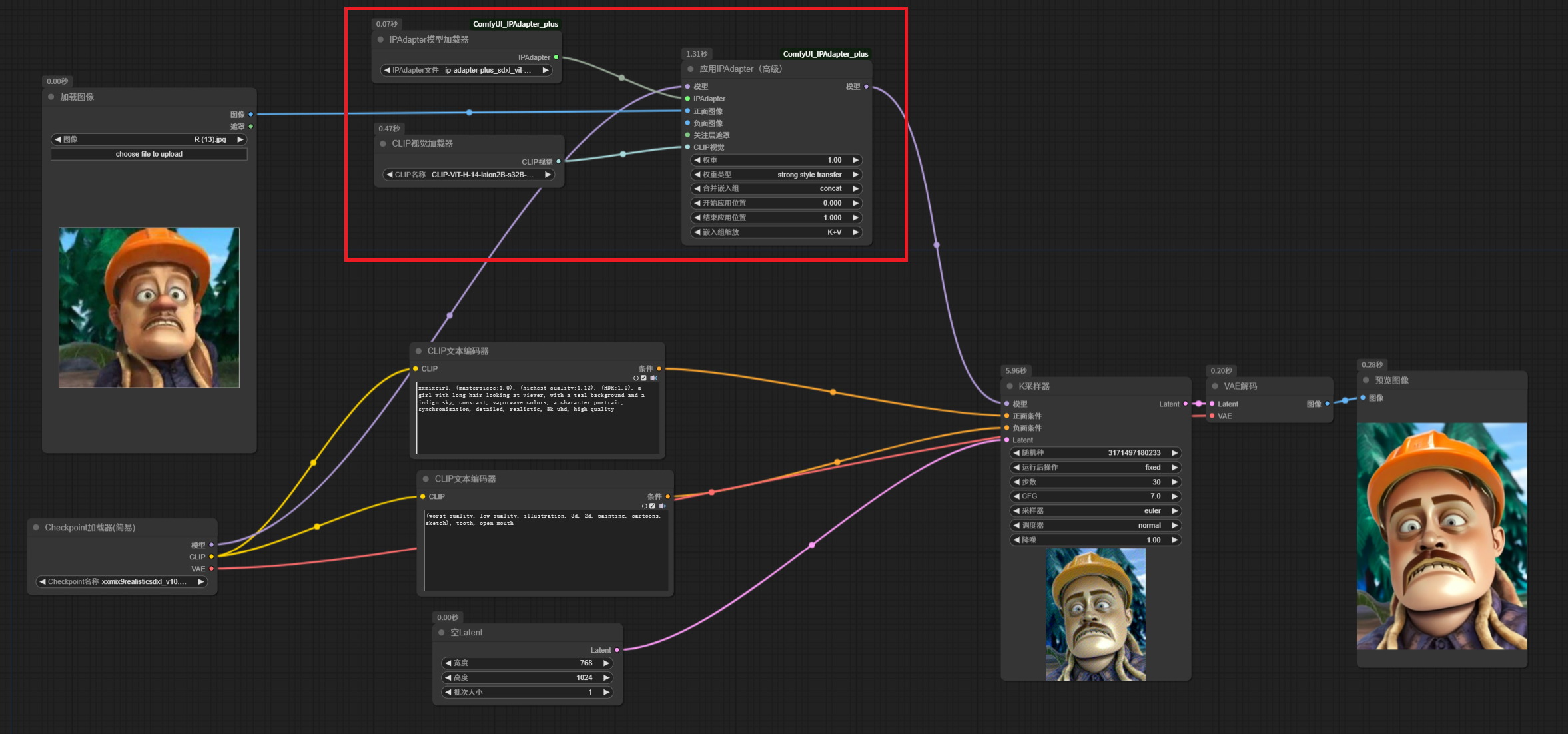
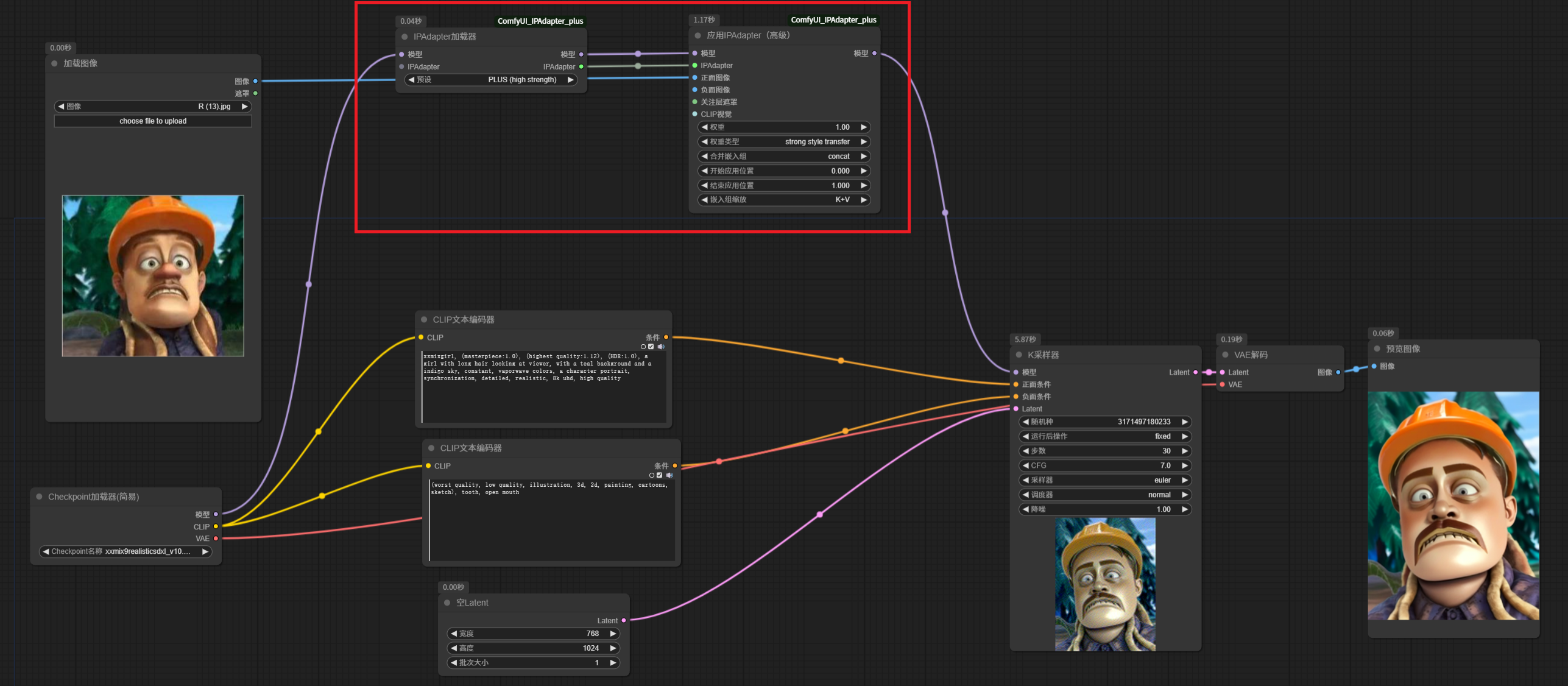
这里,我们输入了一张光头强的图片,核心节点主要是 应用 IPAdapter 节点,模型需要通过一个IPAdapter 模型加载器 加载一个 IP-Adapter 的模型输入。注意,这里的模型要和基础大模型版本匹配。同时还需要使用 CLIP 视觉加载器 加载一个视觉模型,这些模型都是刚才下载下来的。
我们固定了采样器的随机种子,其余参数也不变,IP-Adapater 模型权重设置为 1, 看看生成效果,此时生成的人物,已经变成了光头强风格,并且后面的背景也变成了森林。
基本流程就是,输入一张参考图,使用 CLIP 视觉模型对图像内容进行理解,在通过 IPAdapter 模型和基础大模型中和一下,作为条件输入到潜空间,以达到图像风格的魔法效果。
另外,ComfyUI_IPAdapter_plus 插件还提供了另一个节点,IPAdapter 加载器。它的作用是把 IPAdapter 模型和 Clip 视觉模型一起加载进来了。
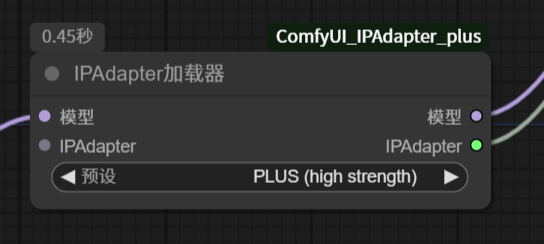
该节点需要将基础大模型连接到输入,输出的模型连接到应用 IPAdapter 节点。测试生成的图像和之前效果是一样的。
2.3 参数说明
2.3.1 IPAdater 模型
IPAdapter 的模型非常多,总共有十几二十个,在使用过程中,应该如何进行选择呢?
前面提到,IPAdapter 是将输入的参考图像,作为输入条件,与提示词共同作用,两者之间既有合作又有对抗,当输入的图像风格与提示词矛盾时,以哪个稳准呢,这里就跟选择的 IPAdapter 的模型相关了。
下面我做了一个简单的分类:

图中对 sd 1.5 模型进行了说明。除了框起来的部分,剩下的模型,根据名字,可以看到一些是 SDXL 版本的,还有一些则需要使用 bigG clip vision 模型进行视觉编码。
2.3.2 权重 Weight
权重可以通俗理解为 IPAdapter 的作用强度。
接下来,我们将 IPAdapter 的权重设置为 0 和 0.5, 看看生成效果:
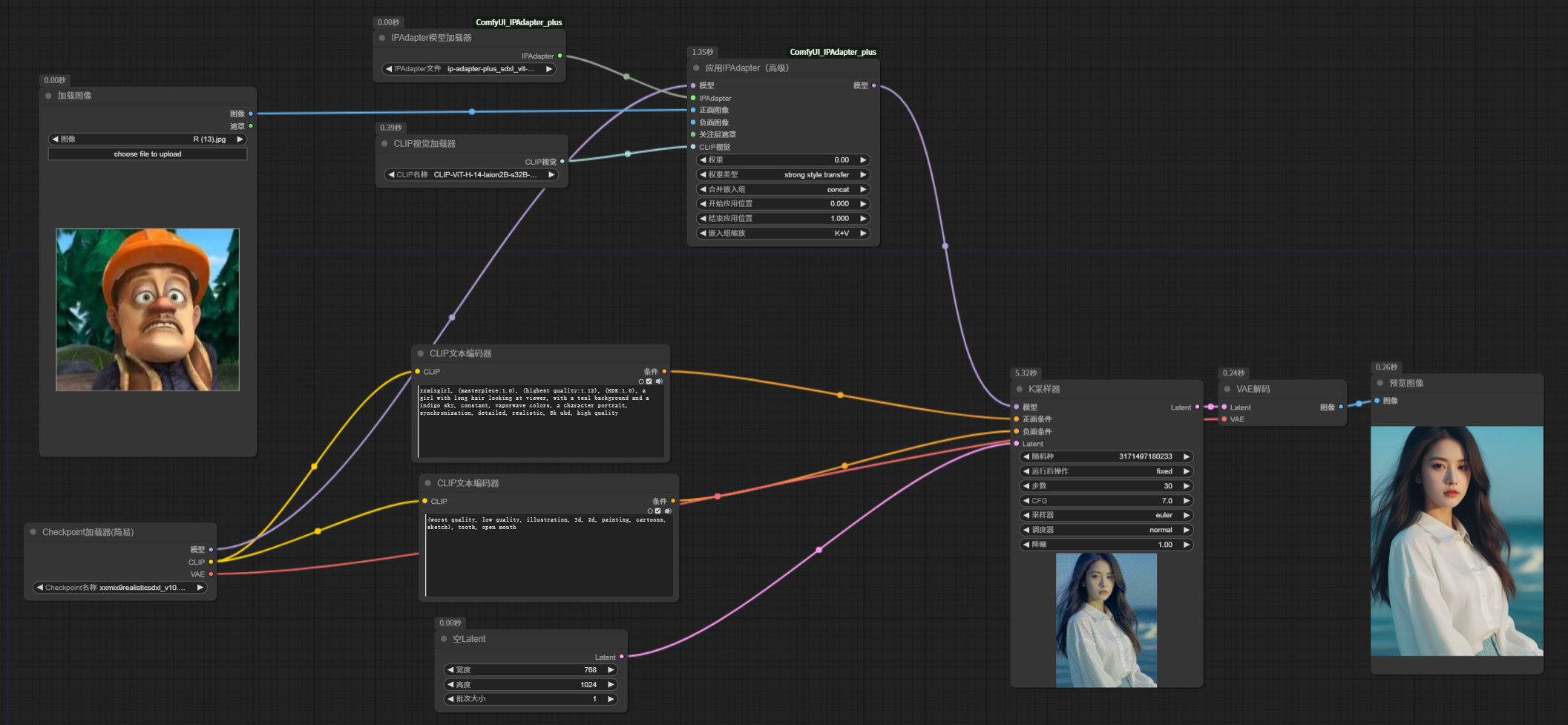
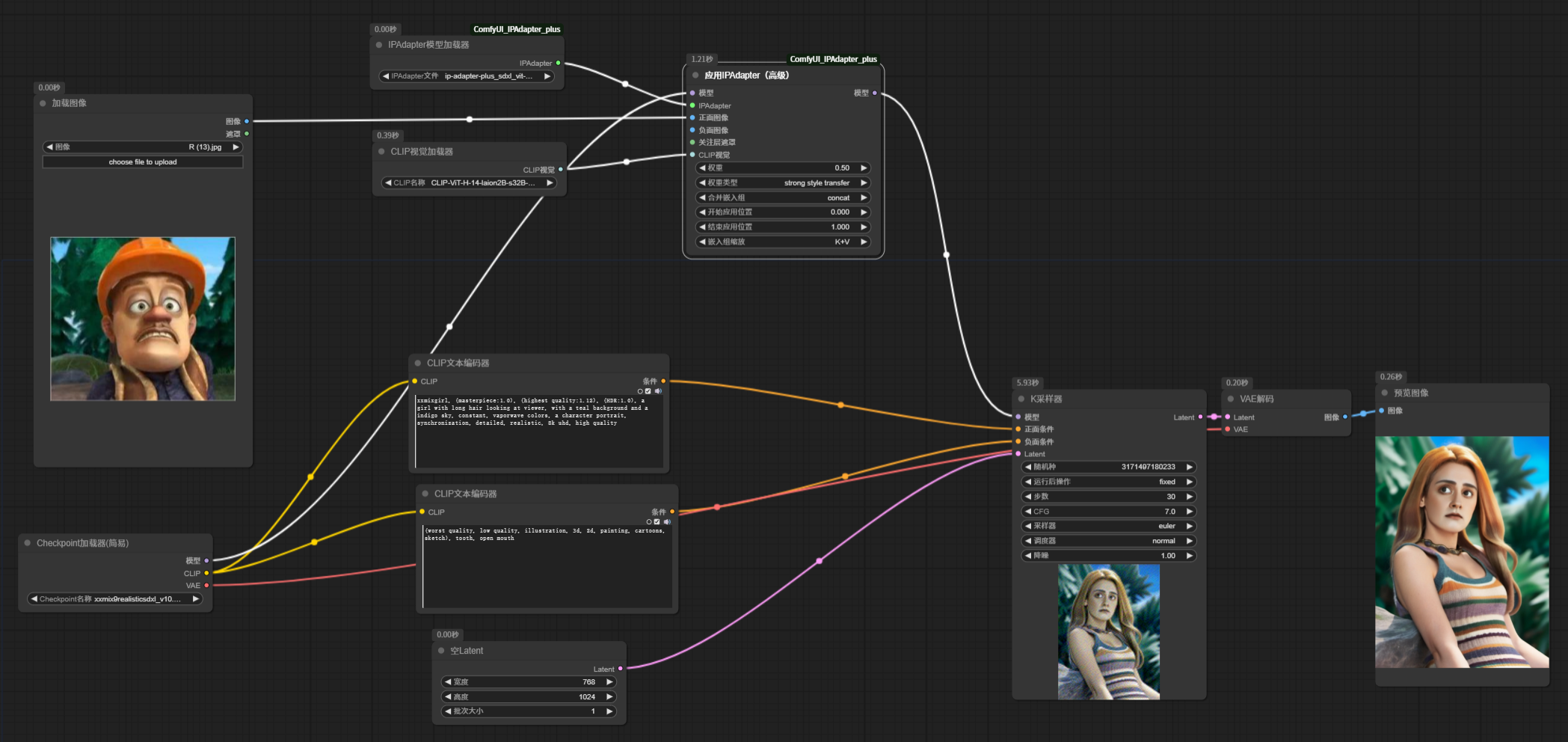
可以看到,权重为0,与没有加入 IPAdapter 生成的图像一样,说明,权重设置为 0 时,IPAdapter 完全没有介入,完全依靠提示词文本指导图像生成。权重设置为 0.5 时,提示词作用有所减弱,参考图的风格已经很明显了。
对于linear 类型(默认值,也是唯一老版本保留的类型),从 0.8开始一般效果比较好。如果使用其他类型,可以尝试更高的值。
2.3.3 权重类型 Weight_type
当 IPAdapter 权重设置为 1 时,会完全忽略提示词,无论提示词写什么,生成的图像都是按照参考图的风格绘制。为了解决这个问题,降低权重是一种方式,其实还有一种更好的方式,设置 IPAdapter 的权重类型。这里的类型有很多种:
权重类型,可以指导 IPAdapter 不同时机的作用强度,比如图像生成开始和结尾强,中间作用弱等,也可以指导风格参考或者构图参考。这样配合提示词也会生成不同的图片效果。
2.3.4 输入图像
IPAdater 可以输入正面图像和负面图像,这个很容易理解,就是希望模仿的风格和不希望掺杂的风格。负面图像非必须输入。
2.3.5 关注层遮罩
默认情况下,是参考输入图像的整张图像,如果只想参考输入图像的某个部分,就需要输入一个遮罩,这样可以避免图片不要的元素对图片造成影响。
2.3.6 开始应用位置和结束应用位置
这个也好理解,直接设定 IPAdapter 作用开始和结束的时机。
2.3.7 合并嵌入组 merge_embeds
当发送多个参考图像时,提示图像可以一个接一个地发送 ( concat最接近旧版本效果) 或以各种方式组合。average 类型可以减轻 GPU 压力。subtract 将第二张图像的条件减去第一张图像的条件;如果有 3 个或更多图像,则对它们进行平均再减去第一个图像。
2.3.8 嵌入组缩放 embeds_scaling
IPAdapter 模型应用于 K,V 的方式。该参数对模型对文本提示的反应影响不大。K+mean(V) w/ C penalty在高权重 (>1.0) 下提供良好的质量,而不会烧坏图像。
三、多 IP-Aadater 使用
看下面这个例子:

这里参考光头强图片的构图,参考川普同志的肖像,生成的图片,可以看到,背景是森林的,人物肖像是川普同志。融合了两者的风格。
或者使用另外一个节点:IPAdapterStylusComposition,汉化过来是 IPAdapter 风格合成

这里调整了一下权重,可以看到两张图片的风格元素完全融入进去了。
后记
关于 IPAdapter 的知识点其实不多,但是使用起来非常灵活,想要完全掌握 IPAdapter ,生成自己想要的图片,需要大量实践,不断累积经验,本文只是抛砖引玉,帮助没有理解 IPAdapter 的小白入门,后续还需要在练习中学习。