本项目使用jupyter notebook开发,主要目的是分析成都二手房房价。
项目完成代码下载地址:成都二手房数据可视化分析项目
数据:爬取二手房交易网站近期数据,成都各个区域交易热度较高的房屋信息。
目标:分析成都各区域二手房市场走势,了解各区域交易情况,建立简单机器学习模型预测房价,及进行聚类分析各房源具体分布情况。
技术点:
- Pandas
- Numpy
- sklearn
- matplotlib
基本流程:
一. 数据采集
主要抓取房源的特征有:
| 字段名称 | 字段含义 |
|---|---|
| title | 房源名称 |
| price | 房源总价 |
| unit_price | 房源单价 |
| community_name | 所在小区名字 |
| region | 所在行政区划 |
| type | 户型 |
| construction_area | 建筑面积 |
| orientation | 房屋朝向 |
| decoration | 装修情况 |
| floor | 楼层 |
| elevator | 电梯情况 |
| purposes | 房屋用途 |
| release_date | 挂牌时间 |
| image_urls | 房源图片 |
| from_url | 房源来源 |
| house_structure | 建筑结构 |
爬取完成后导入Excel文件

另外,考虑到后边将进行地图展示,所以还需增加地理坐标信息:经纬度,这部分将在数据清洗后进行。
二. 数据清洗
1. 原始数据检视
基于我爬虫项目的存储策略,我将个区划的结果分别存储到了不同的文件,所以要进行文件合并操作。
首先读取文件列表,然后对循环文件列表,进行合并任务:
python
datas = []
for file in res:
filename = file.replace('.csv','')
try:
data = pd.read_csv(file)
datas.append(data)
except:
print('%s暂无数据'%filename)
# 得到所有合并数据
result = pd.concat(datas)这里我们就得到了总体数据集,使用result.info()及result.shape查看基本信息:
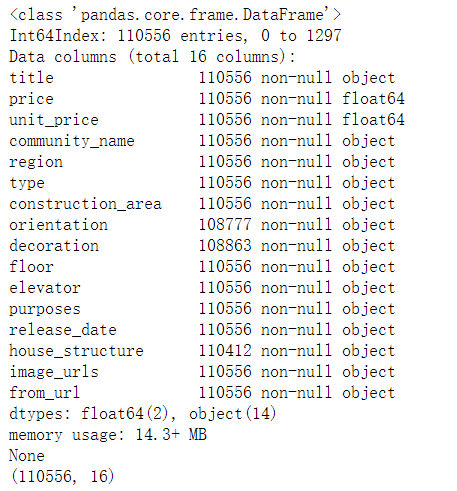
通过以上代码,可以看出训练集数据总共有110556条房屋记录,总共有16列数据,仔细检查数据,可以发现存在很多的缺失值。
2. 数据的探索性可视化分析
数据里面有的值大,有的值小,有的列还有缺失值等等,使用pandas_profiling模块工具一键生成探索性数据分析报告,快速查看这些数据的分布 。
python
ppf.ProfileReport(df_train)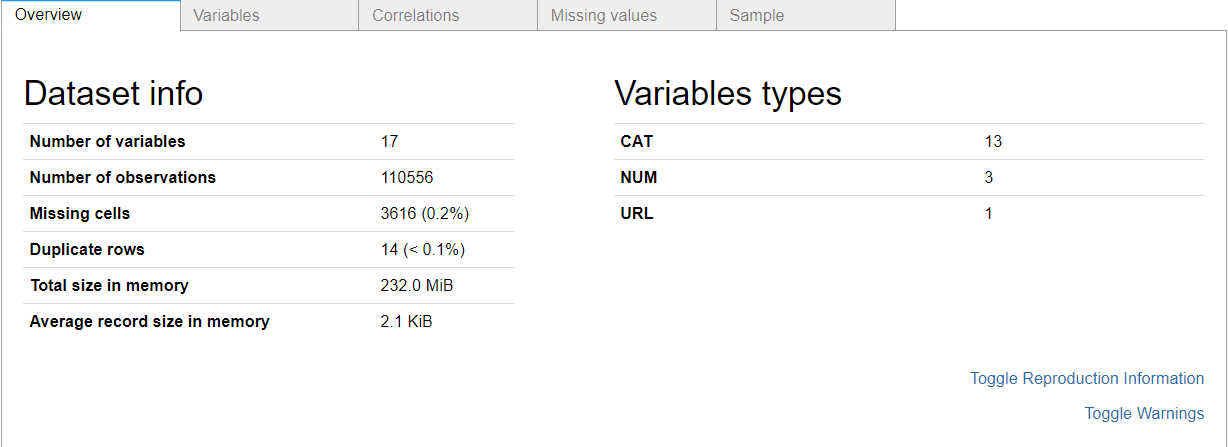
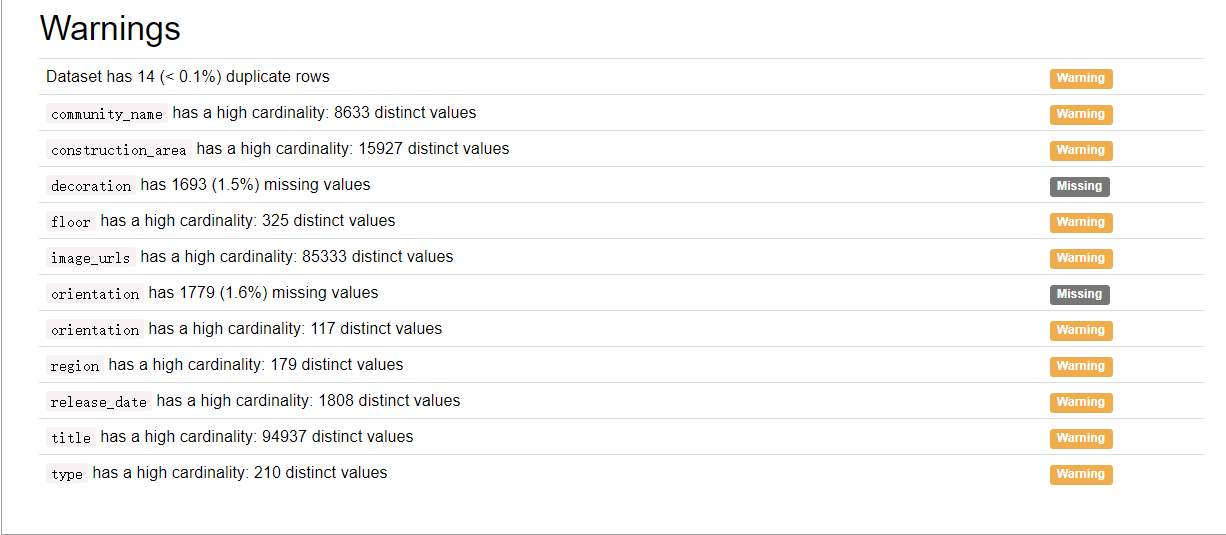
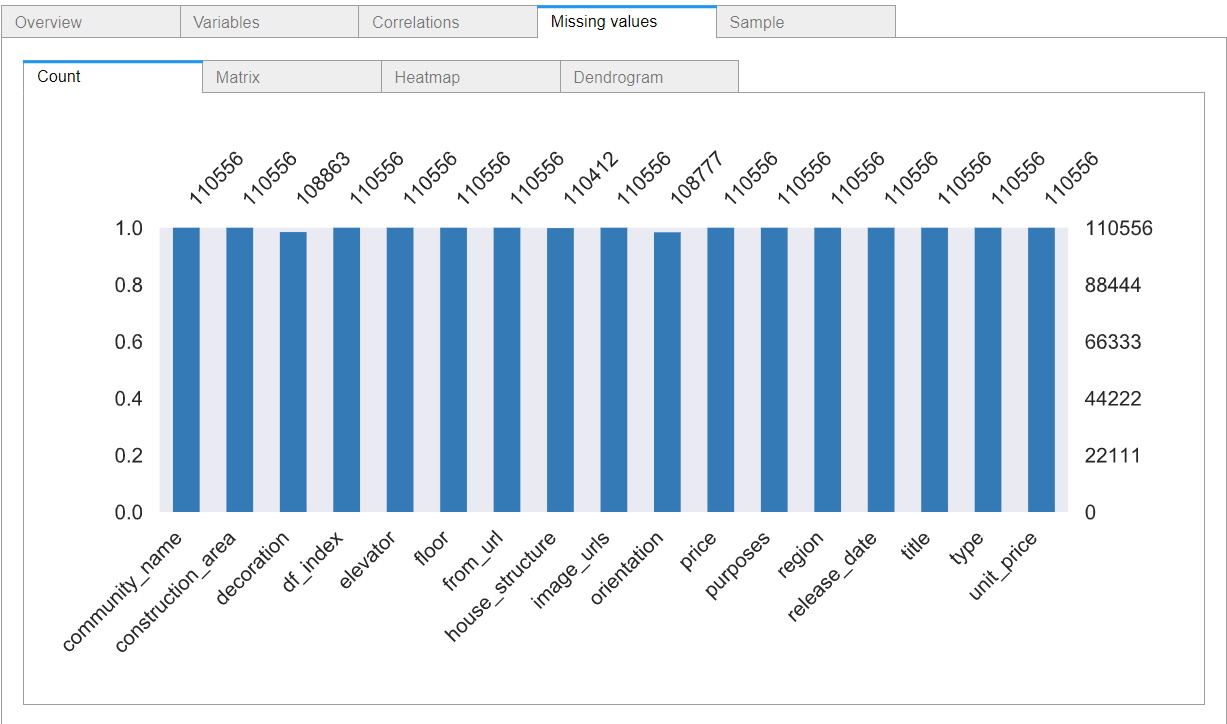
通过以上数据探索性分析报告可以看出数据集的基本信息、哪些特征属性的缺失值和0元素的占比情况、各特征变量的分布情况以及相关性等等。
3. 数据清洗
3.1 去重
查看重复值数量:
python
result.duplicated().value_counts()
False表示未重复的数目,True表示重复数目。通过drop_duplicates方法去除数据集中所有重复值:
python
res = result.drop_duplicates(subset=None,keep='first',inplace=False)
3.2 检测与处理缺失值
查看缺失值统计结果:
python
res.isnull().sum()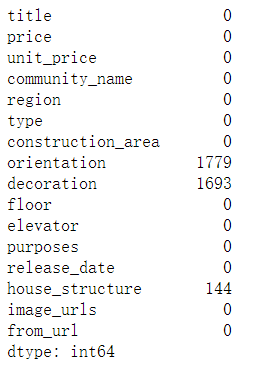
上面可以看出房屋朝向(orientation),装修情况(decoration),建筑结构(house_structure)存在大量缺失值。关于缺失值处理有很多处理方法,比如直接删除,使用随即森林法填充等,这里我们使用特定数据进行填充。定义房屋朝向列表['东','南','西','北','东南','西南','东北','西北'],装修情况列表['简装','精装','毛坯','其他'],建筑结构列表 ['钢混结构','钢结构','混合结构','框架结构','未知','砖混结构','砖木结构']。用这里的值进行随机填充。
python
res1 = res.copy()
orientations = ['东','南','西','北','东南','西南','东北','西北']
decorations = ['简装','精装','毛坯','其他']
house_structures = ['钢混结构','钢结构','混合结构','框架结构','未知','砖混结构','砖木结构']
res1['orientation'].fillna(random.choice(orientations),inplace=True)
res1['decoration'].fillna(random.choice(decorations),inplace=True)
res1['house_structure'].fillna(random.choice(house_structures),inplace=True)3.3 检测异常值
这之前先将面积特征转换为浮点数类型:res1['construction_area'] = res1['construction_area'].str.replace('㎡','').astype("float"),去掉'㎡'。此时查看数据集描述信息,包括最小值,下四分位数,均值,上四分位数,最大值,方差,数量信息。
python
res1.describe()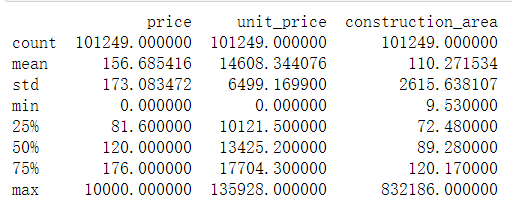
这里可以看到存在房价为0的数据,以及不合理的面积数值,稍后做相关处理。
接下来检查面积与价格之间的关系图:
python
plt.figure(figsize=(16,15))
plt.subplot(221)
plt.scatter(res1["construction_area"], res1["price"])
plt.xlabel('建筑面积',fontsize=15)
plt.ylabel('总价',fontsize=15)
plt.subplot(222)
plt.scatter(res1["construction_area"], res1["unit_price"])
plt.xlabel('建筑面积',fontsize=15)
plt.ylabel('单价',fontsize=15)
plt.show()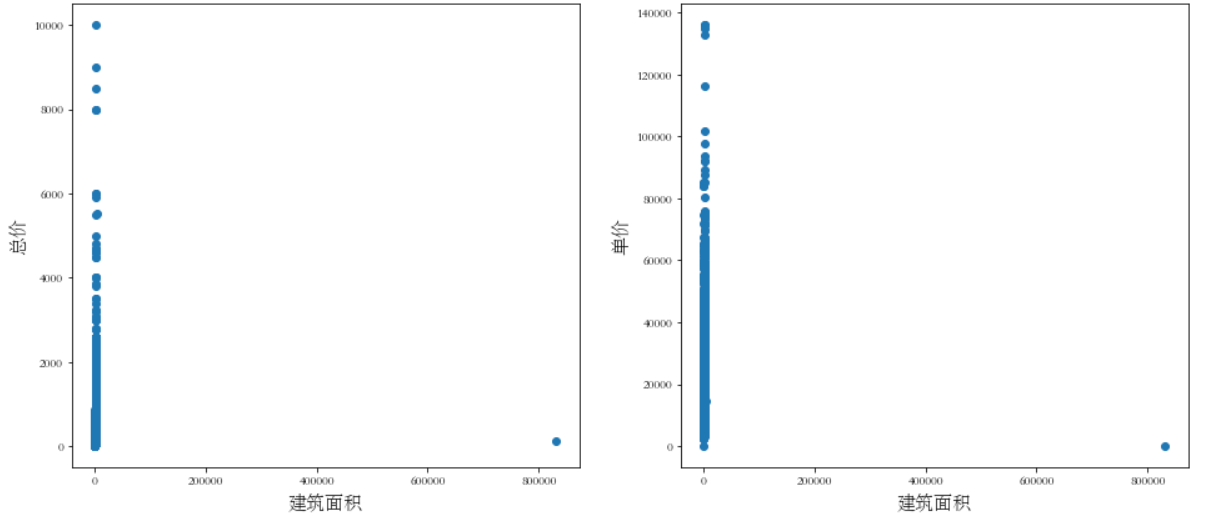
可以明显观察到存在异常情况。最后观察房价的箱线图:
python
plt.figure(figsize=(16,8))
plt.subplot(1,2,1)
plt.boxplot(res1["price"])
plt.ylabel('总价',fontsize=15)
plt.subplot(1,2,2)
plt.boxplot(res1["unit_price"])
plt.ylabel('单价',fontsize=15)
plt.show()
3.4 处理异常值
通过上面观察分析,房价个面积都存在异常情况,对其分别处理。
首先处理离群值和有失一般性值,比如上图中的面积:
python
res1.drop(res1[res1['construction_area']>1000].index,inplace=True)处理price和unit_price为 0 的数据
python
# 查看相关数据
print(res1[res1['unit_price']==0])
print(res1[res1['unit_price']==0]['community_name'])
由于数据量过小,所以直接删除res1.drop(res1[res1['price']==0].index,inplace=True),但是如果对于存在一定数量相关值时,不能直接删除,这样会影响数据。这里可以采用一种替换值法:获取到每条数据对应的小区的均价,用这个均价来填充房源单价,面积同样采用这个方法,最后房屋总价通过计算单价和面值积获得。当然也可用机器学习算法建模获取与待处理目标最相近的房源的数据来填充该处理目标。处理后的面积散点图:
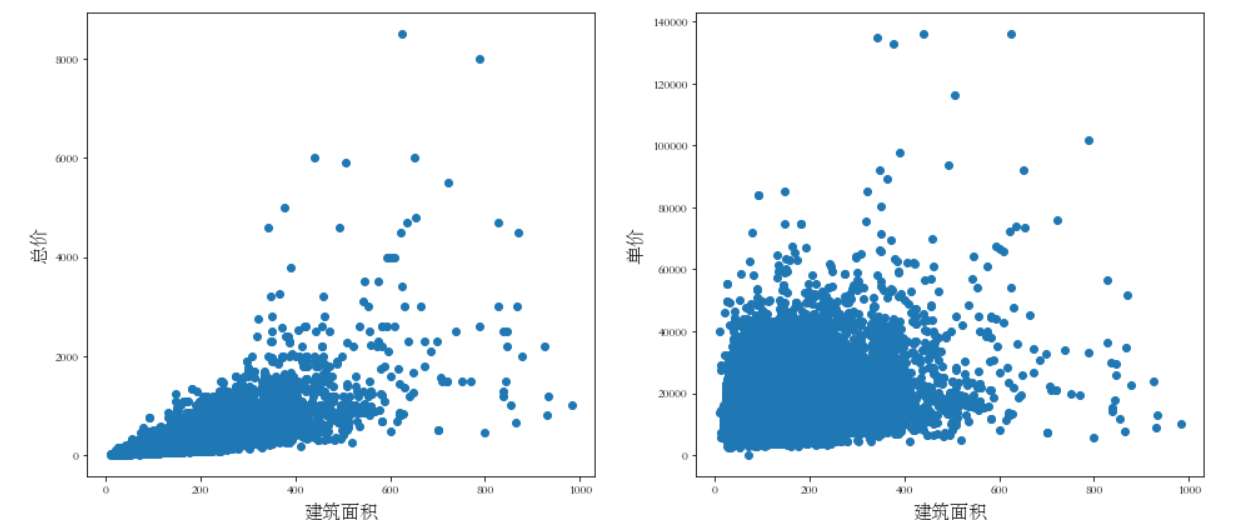
3.5 其他标准
绘制出装修情况,建筑结构,房屋用途,房屋面积与房价的散点图:
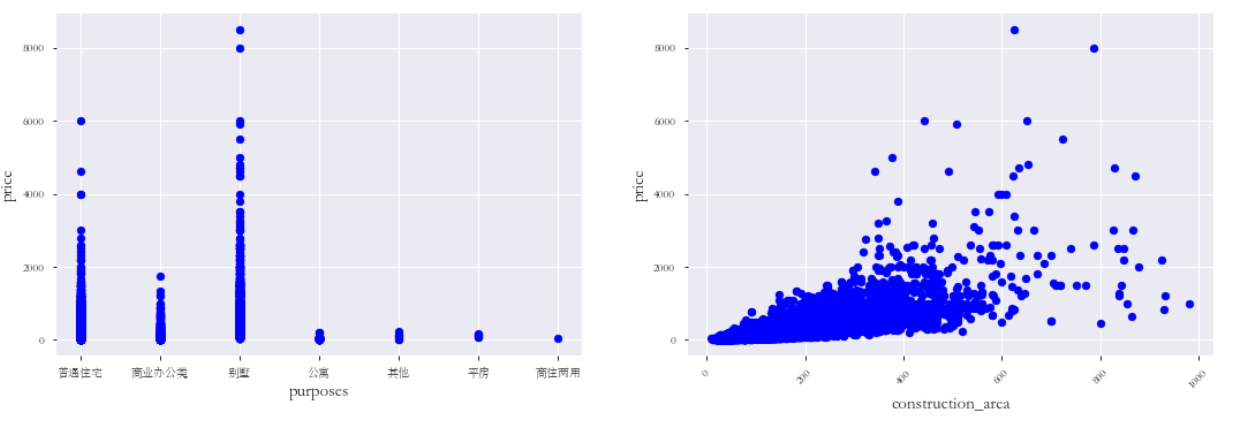
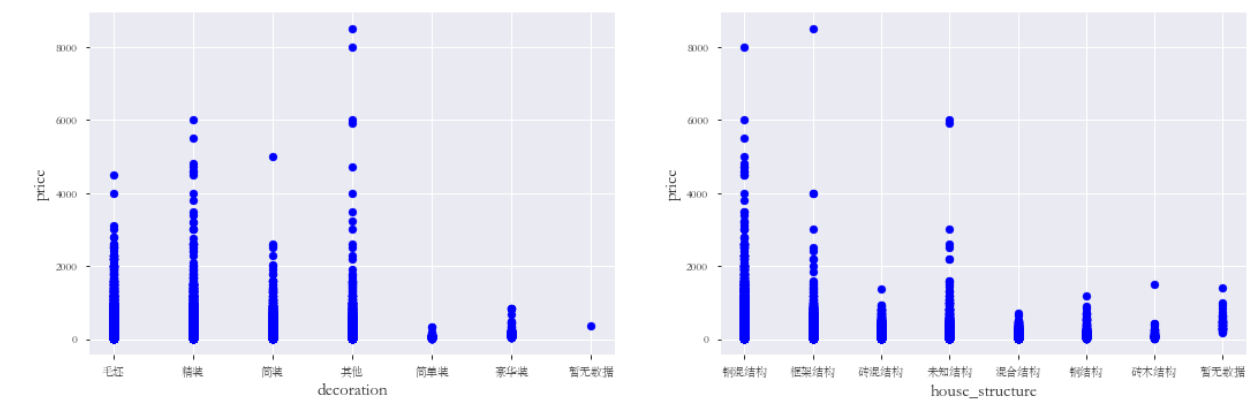
通过散点图可以观察到哪些是异常值点,例如:construction_area与price的关系图中,有几个离群的 construction_area值很高的数据,可以推测出现这种情况的原因。或许他们代表了相当高级地区,也就解释了高价。 这些点很明显不能代表典型样例,所以我们将它们定义为异常值并删除。
同理,对于其他特征存在的不合理的离群点,在这里也考虑将其删除。
python
res1.drop(res1[(res1['decoration']=='其他') & (res1['price']>6000)].index,inplace=True)
res1.drop(res1[(res1['house_structure']=='钢混结构') & (res1['price']>7000)].index,inplace=True)
res1.drop(res1[(res1['house_structure']=='框架结构') & (res1['price']>6000)].index,inplace=True)
res1.drop(res1[(res1['house_structure']=='未知结构') & (res1['price']>4000)].index,inplace=True)
res1.drop(res1[(res1['purposes']=='普通住宅') & (res1['price']>6000)].index,inplace=True)
res1.drop(res1[(res1['construction_area']>700) & (res1['price']<300)].index,inplace=True)
res1.drop(res1[(res1['construction_area']<600) & (res1['price']>4000)].index,inplace=True)
complete_data = res1.copy()至此,简单的数据清洗就完成了,接下俩要完成的是地理坐标转换功能,后续使用聚类进行地图应用展示的时候需要用到地理坐标,所以我们要将每房源的地理位置解析出来,合并到数据中。
三. 逆地址解析
为数据集添加索引# complete_data['id'] = range(len(complete_data))使得其连续。
这里我们使用高德地图解析进行具体地址转换为经纬度操作,使用高德地图webapi前,需要申请到高德地图的key(百度地图为ak),才能使用相关接口,百度地图同理。
注:
- 地理编码/逆地理编码 API 是通过 HTTP/HTTPS 协议访问远程服务的接口,提供结构化地址与经纬度之间的相互转化的能力。
- 此处选择高德地图是因为我在使用百度地图的webapi时频繁断开链接,导致解析失败,所以选择了高德地图。但是后面还要进行一次高德地图坐标转换百度地图坐标,之所以这样做是因为我的另一个项目使用的是百度地图做的地图可视化,所以如果这里使用百度地图服务的话,就能省去后面的坐标转换步骤。
使用:
-
申请Web服务API类型Key
-
参考接口参数文档发起HTTP/HTTPS请求,第一步申请的 Key 需作为必填参数一同发送
-
接收请求返回的数据(JSON或XML格式),参考返回参数文档解析数据。
地理编码 API 服务地址:https://restapi.amap.com/v3/geocode/geo?parameters
请求方式:GET
具体参数及说明见高德地图开发者文档。
1. 定义转换函数
python
def getlnglat_gaode(address):
address = quote(address)
# api
url_base = "http://restapi.amap.com/v3/geocode/geo"
# 返回数据格式
output = "json"
# key
key = "5d297ac38ce0db596ad9656b13fa9b08"
url = url_base + '?' + 'address=' + address + '&output=' + output + '&key=' + key
lat = 0.0
lng = 0.0
res = requests.get(url)
temp = json.loads(res.text)
location = temp['geocodes'][0]['location'].split(',')
if temp["info"] == 'OK':
lat = location[1]
lng = location[0]
# 返回解析好的坐标
return lat,lng测试:lat,lang = getlnglat_gaode('四川省成都市新津金秋乐园一期')
2. 处理全部数据
2.1 定义基本数据结构:
python
# 索引
idint = []
# 小区名
community_names = []
# 经纬度
lats = []
lngs = []
# 完整地址
address = ''
# 格式化数据
lat_lng_data = {"id":idint,"community_name":community_names,"lat":lats,"lng":lngs}2.2 生成经纬度信息,这里我们的数据保存策略是每两千条存储到一个CSV文件中,以免断开链接后数据丢失的问题:
python
for idi,community_name,region in zip(list(complete_data["id"]),list(complete_data["community_name"]),list(complete_data["region"])):
# 获取小区名并生成完整地址
community_name = str(community_name)
region = re.sub(r"\[|\]|'","",region).split(',')
if len(region)>=2:
if region[0] != region[1]:
address = "成都市"+region[0]+region[1]+community_name
else:
address = "成都市"+region[0]+community_name
else:
address = "成都市"+region[0]+community_name
# print(address)
# print('*'*20)
# 解析地址
lat,lng = getlnglat_gaode(address)
if lat != 0 or lng !=0:
idint.append(idi)
community_names.append(community_name)
lats.append(lat)
lngs.append(lng)
print(idi,lat,lng)
# 分段存储
if idi>0 and idi%2000==0:
df_latlng = pd.DataFrame(lat_lng_data)
df_latlng.to_csv("./cleandata/latlng"+str(idi)+".csv",encoding='gbk')
idint = []
community_names = []
lats = []
lngs = []
address = ''
lat_lng_data = {"id":idint,"community_name":community_names,"lat":lats,"lng":lngs}过程截取:
由于数据不能整数2000,所以还会遗留一部分数据,接下来将这部分数据存储:df_latlng = pd.DataFrame(lat_lng_data) df_latlng.to_csv("./cleandata/latlng100983.csv")
3. 合并所有坐标文件
将所有坐标文件合并在一起,方便合并到房源数据集中。
python
position_name = os.listdir('./cleandata/')
res = [position for position in position_name]
datas = []
for file in res:
filename = file.replace('.csv','')
file = './cleandata/'+file
try:
data = pd.read_csv(file,encoding='gbk')
datas.append(data)
except:
print('%s暂无数据'%filename)
# 得到所有合并数据
position_result = pd.concat(datas)
position_result.to_csv('./cleandata/lnglat.csv')4. 合并得到最终数据
将房源数据集和做坐标数据集按Id合并,保证数据对应的一致性,由于前边做坐标转换时是根据id来存数据的,所以不存在数据对应出错的问题。
python
del position_result["community_name"]
df_merge = pd.merge(complete_data,position_result,on="id")
df_merge.to_csv('./housedata/fin_house.csv')注:这里的最终数据fin_house.csv中的坐标是遵循高德地图坐标,如果是做高德地图应用的话,就可直接使用了,但我是采用的百度地图,所以我还要在进行高德地图和百度地图的坐标转换,以及坐标纠正,不需要这一步的同学可以跳过。
四. 高德坐标转百度坐标
1. 定义转换函数,实现坐标对接:
相关参数详情见百度地图开发者文档。
python
def parse2lnglat(lng,lat):
# 百度api
url_base = "http://api.map.baidu.com/geoconv/v1/?coords="
# 返回数据格式
output = "json"
ak = "Qmz0VMtKw3uAI2GWClu9Q6iCnP2j2uH2"
url = url_base + str(lng) +','+ str(lat) + '&output=' + output + '&ak=' + ak
res = requests.get(url)
temp = json.loads(res.text)
lng=0
lat=0
if temp['status']==0:
lng = temp['result'][0]['x']
lat = temp['result'][0]['y']
return lat,lng测试:lat,lng = parse2lnglat(104.006705,30.577101)
2. 生成经纬度信息
这一步和上面解析地址类似
python
# 生成经纬度信息
idint = []
community_names = []
lats = []
lngs = []
lat_lng_data = {"id":idint,"community_name":community_names,"lat":lats,"lng":lngs}
for idi,lat,lng,community_name in zip(list(pre_location["id"]),list(pre_location["lat"]),list(pre_location["lng"]),list(pre_location["community_name"])):
lat = str(lat)
lng = str(lng)
community_name = str(community_name)
lat,lng = parse2lnglat(lng,lat)
if lat != 0 or lng !=0:
idint.append(idi)
community_names.append(community_name)
lats.append(lat)
lngs.append(lng)
print(idi,lat,lng)
if idi>0 and idi%2000==0:
df_latlng = pd.DataFrame(lat_lng_data)
df_latlng.to_csv("./cleandata/updateposition/latlng"+str(idi)+".csv",encoding='gbk')
idint = []
community_names = []
lats = []
lngs = []
address = ''
lat_lng_data = {"id":idint,"community_name":community_names,"lat":lats,"lng":lngs}处理剩下的数据:
df_latlng = pd.DataFrame(lat_lng_data) df_latlng.to_csv("./cleandata/updateposition/latlng100983.csv",encoding='gbk')
3. 合并数据集
python
position_name = os.listdir('./cleandata/updateposition/')
res = [position for position in position_name]
datas = []
for file in res:
filename = file.replace('.csv','')
file = './cleandata/updateposition/'+file
try:
data = pd.read_csv(file,encoding='gbk')
datas.append(data)
except:
print('%s暂无数据'%filename)
# 得到所有合并数据
position_result = pd.concat(datas)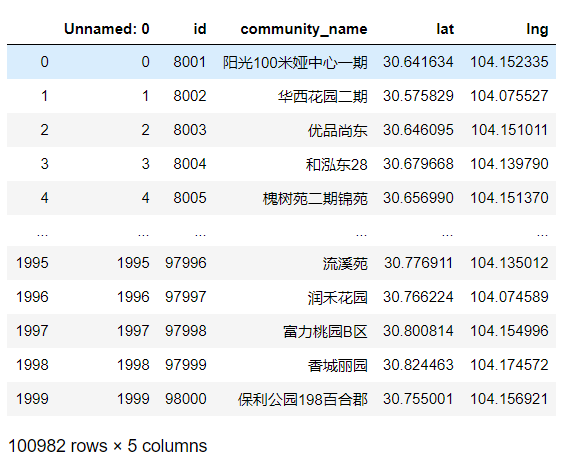
删除Unnaemd列,并保存为CSV文件:
del position_result['Unnamed: 0'] position_result.to_csv('./cleandata/updateposition/lnglat.csv')
这时的fin_house2.csv为百度坐标格式的文件,可使用到百度地图应用中去。
五. 特征工程
df = pd.read_csv('./housedata/fin_house2.csv',encoding='gbk')
1. 目标变量(price)处理
定义函数plt_distribution用于绘制特征变量的分布图像。
python
def plt_distribution(data, obj_col):
plt.figure(figsize=(10,6))
sns.distplot(data[obj_col] , fit=norm);
# 获取数据分布曲线的拟合均值和标准差
(mu, sigma) = norm.fit(data[obj_col])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
# 绘制分布曲线
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice distribution')
# 绘制图像查看数据的分布状态
fig = plt.figure()
plt.figure(figsize=(10,6))
tmp = stats.probplot(data[obj_col], plot=plt)
plt.show()
plt_distribution(df, 'price') # 目标变量变换前的分布情况对数变换前,目标变量的分布情况:
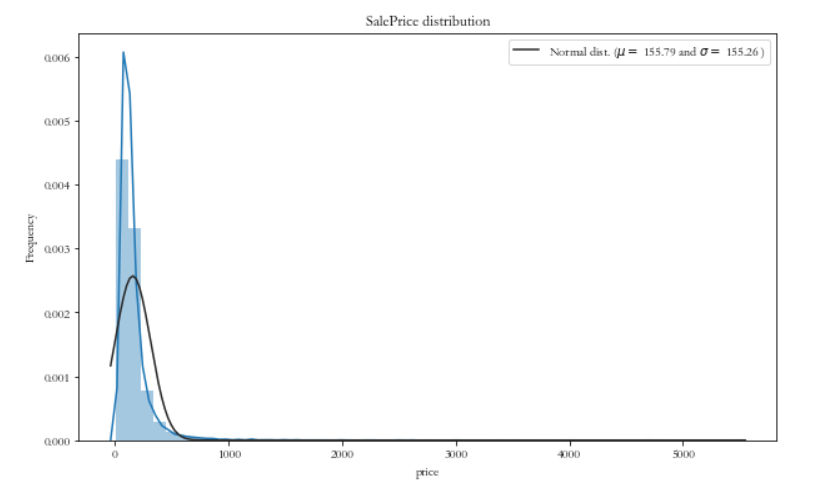

显然目标变量呈现明显的偏态分布,这里我们需要将它变换成无偏的正态分布,因为通常的线性模型所针对的数据都是正态分布的数据。
df["price"] = np.log1p(df["price"]) # 对数变换
plt_distribution(df, 'price') # 变换后的分布情况
对数变换后,目标变量的分布情况:
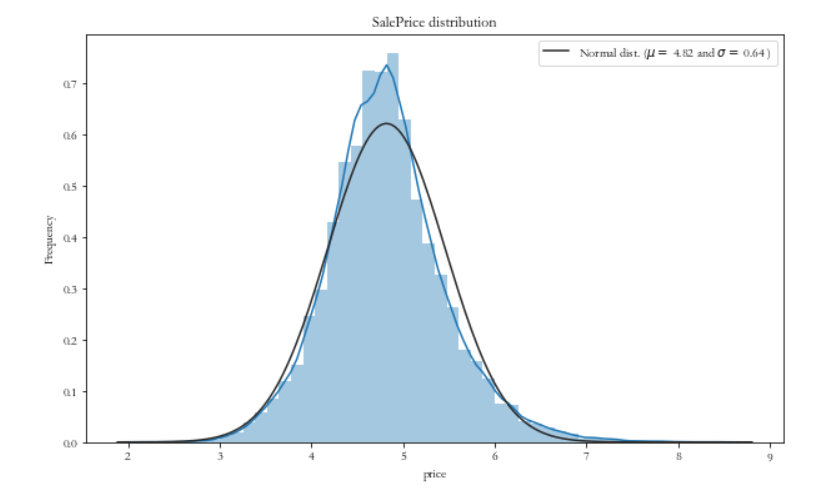
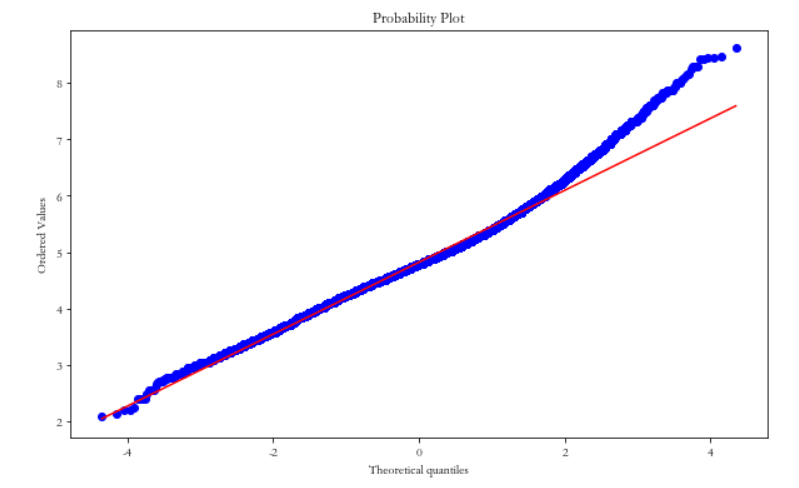
2. 特征编码
2.1 顺序特征编码-处理楼层信息
- 数据特征中存在一些顺序变量(ordinal variable),它们不同于一般的类型变量(categorical variable),顺序变量之间存在固有的顺序 比如 (低, 中, 高) 、病人疼痛指数 ( 1 到 10 - 但是他们之间的差是没有意义的, 因为1 到 10 仅仅表现了顺序)。
- 对于顺序变量,标签编码(LabelEncoder)的方式无法正确识别这种顺序关系。
查看楼层信息:np.unique(df['floor'])
截图不完整

定义函数process_floor对顺序变量进行编码,以10层为标准,将楼层分为6个等级:
- 低于10层且位于该楼的低层,即数据集中的低楼层:level=0
- 低于10层且位于该楼的中层,即数据集中的中楼层:level=1
- 低于10层且位于该楼的高层,即数据集中的高楼层:level=2
- 高于10层且位于该楼的低层,即数据集中的低楼层:level=3
- 高于10层且位于该楼的中层,即数据集中的中楼层:level=4
- 高于10层且位于该楼的高层,即数据集中的高楼层:level=5
- 其他:level=0
python
import re
level = 0
def process_floor(x):
floor_level = x[0:1]
floor_level_num = int(re.findall(r"\d+\.?\d*",x)[0]) if re.findall(r"\d+\.?\d*",x) else 1
if floor_level == '低' and floor_level_num < 10:
level = 0
elif floor_level == '中' and floor_level_num < 10:
level = 1
elif floor_level == '高' and floor_level_num < 10:
level = 2
if floor_level == '低' and floor_level_num >= 10:
level = 3
elif floor_level == '中' and floor_level_num >= 10:
level = 4
elif floor_level == '高' and floor_level_num >= 10:
level = 5
else:
level = 0
return level
## 顺序变量特征编码,替换元数据表示
cols = ['floor']
for col in cols:
df[col] = df[col].apply(process_floor)2.2 类别类编码
python
cols = ['region','type', 'construction_area', 'orientation', 'decoration','elevator','purposes','house_structure']
# 全部转换为string类型
for col in cols:
df[col] = df[col].astype(str)2.3 字符型特征标签编码(独热编码(OneHotEncoder)和标签编码(LabelEncoder)编码)
除了前面已经做了顺序特征编码的特征,这里需要对其他字符型特征进行数值型编码。对于字符型特征可以采用独热编码(OneHotEncoder)和标签编码(LabelEncoder)编码方式将字符型特征转换成数值型特征。
使用LabelEncoder和get_dummies来实现这些功能:
对orientation等数据等进行LabelEncoder编码,由于这类数据存在较多取值,直接进行独热编码会造成过于稀疏的数据,并且严重增加特征维度,因此在特征工程中会将其利用LabelEncoder进行数字化编码 )
python
df['construction_area']=df['construction_area'].astype(float)
## 年份特征的标签编码
# str_cols = ["year"]
# for col in str_cols:
# df[col] = LabelEncoder().fit_transform(df[col])
## 为了后续构建有意义的其他特征而进行标签编码
lab_cols = ['orientation','elevator', 'purposes', 'house_structure','decoration']
for col in lab_cols:
new_col = "lab_" + col
df[new_col] = LabelEncoder().fit_transform(df[col]) 2.4 处理户型特征
查看户型数值信息df['type'].value_counts():
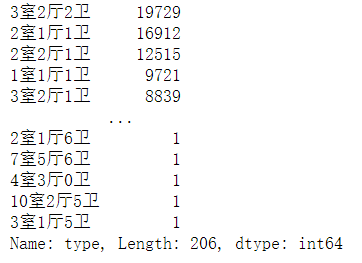
单独处理户型,用 str.extract() 方法,将"室","厅","卫"都提取出来,单独作为三个新特征:
python
# 室
df['type_room_num'] = df['type'].str.extract('(^\d).*', expand=False)
# 厅
df['type_hall_num'] = df['type'].str.extract('^\d.*?(\d).*', expand=False)
# 卫
df['type_wash_num'] = df['type'].str.extract('^\d.*?\d.*?(\d).*', expand=False)
# 转换类型
df['type_room_num'] = df['type_room_num'].fillna('1').astype('int64')
df['type_hall_num'] = df['type_hall_num'].fillna('1').astype('int64')
df['type_wash_num'] = df['type_wash_num'].fillna('1').astype('int64')2.5 处理行政区划特征
使用one-hot编码修改特征"region":
python
df['region'] = df['region'].apply(lambda x: re.sub(r"\[|\]|'", '', x).split(',')[0])
district = pd.get_dummies(df['region'], prefix='行政区划')
data = pd.concat([df, district], axis=1)查看处理结果
fin_data = data.copy()
data.drop(['unit_price','price','title','floor','construction_area','from_url','idi','image_urls','release_date','lat','lng','community_name','type','orientation','elevator', 'purposes', 'house_structure','decoration'], axis=1, inplace=True)
print(data)
3. 查看相关系数
python
# 删除旧特征
fin_data.drop(['title','from_url','idi','region','image_urls','release_date','lat','lng','community_name','type','orientation','elevator', 'purposes', 'house_structure','decoration'], axis=1, inplace=True)
corrmat = fin_data.corr()
f, ax = plt.subplots(figsize=(13, 10))
sns.heatmap(corrmat, vmax=.8, square=True)
plt.show()
4. 连续变量特征的数据变换:改变源特征数据的分布
通过函数变换来改变原始数值型特征的分布:
- 变换后可以更加便捷的发现数据之间的关系:从没有关系变成有关系,使得模型更好利用数据;
- 很多特征的数据呈现严重的偏态分布(例如:很多偏小的值聚在一起),变换后可以拉开差异;
- 让数据符合模型理论所需要的假设,然后对其进行分析,例如变换后的数据呈现正态分布;
常用数据转换方法的有:对数转换,box-cox转换等变换方式,其中对数转换的方式是最为常用的,取对数之后数据的性质和相关关系不会发生改变,但压缩了变量的尺度,大大方便了计算。
此处,绘制每个数值型特征与目标变量的分布情况:
python
num_features = fin_data.select_dtypes(include=['int64','float64','int32']).copy()
num_features.drop(['price','unit_price'],axis=1,inplace=True)
num_feature_names = list(num_features.columns)
num_features_data = pd.melt(fin_data, value_vars=num_feature_names)
g = sns.FacetGrid(num_features_data, col="variable", col_wrap=5, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")
plt.show()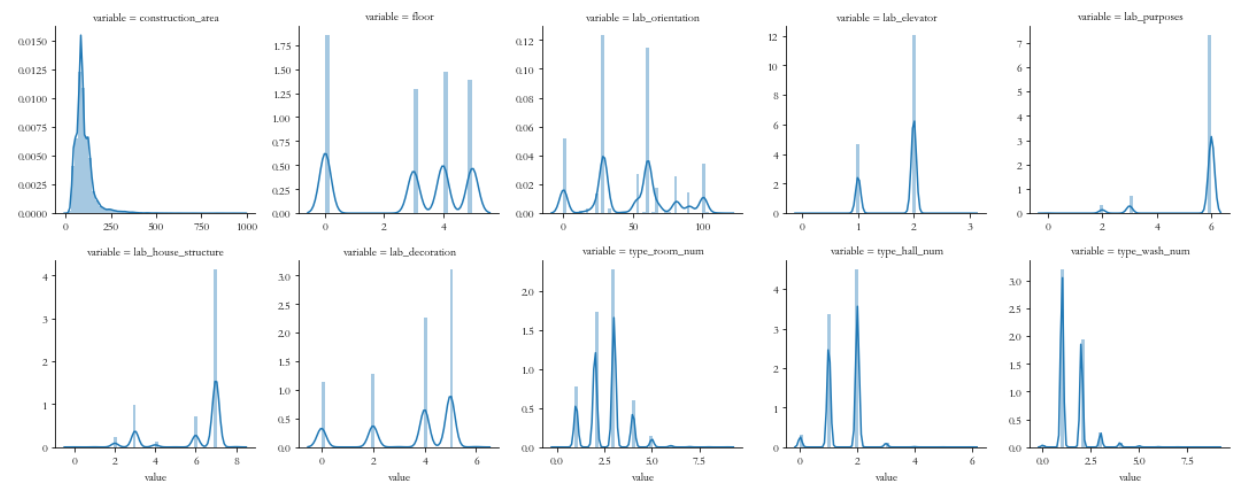
计算各数值型特征变量的偏度(skewness):
python
skewed_feats = fin_data[num_feature_names].apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
skewness = pd.DataFrame({'Skew' :skewed_feats})
skewness
# skewness[skewness["Skew"].abs()>0.75]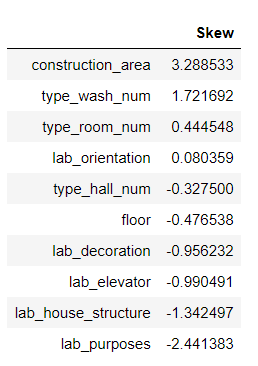
根据图像显示,可以看到数值型特征变量偏移程度,此处设置阈值为1,对偏度大于阈值的特征进行log函数变换操作以提升质量:
python
skew_cols = list(skewness[skewness["Skew"].abs()>1].index)
for col in skew_cols:
#fin_data[col] = boxcox1p(all_data[col], 0.15) # 偏度超过阈值的特征做box-cox变换
fin_data[col] = np.log1p(fin_data[col]) # 偏度超过阈值的特征对数变换fin_data最终信息:

5. 建立模型
注:在进行数据建模前,还需更具情况对数据进行特征降维-特征数过多的情况,然后进行特征选择,这里我并没有这部做法,毕竟特征数太少,感兴趣的同学可以尝试。
特征降维的方式也有很多种,例如主成分分析,这里根据特征的重要性图来进行选择出利于模型训练的关键特征,从而达到特征降维的目的。由于套索回归模型(Lasso)的系数可以表证特征的重要程度。
- 将数据拆分回训练数据和测试数据
- 特征归一化
- 特征的选择--基于特征重要性图来选择
当然,你也可以采用xgboost等模型获取特征的重要性程度。
5.1 数据划分
划分数据为训练集和测试集,并进行数据归一化:
python
#确定数据中的特征与标签
fin_data.drop(['unit_price'], axis=1, inplace=True)
x = fin_data.as_matrix()[:,1:]
y = fin_data.as_matrix()[:,0].reshape(-1,1)
#数据分割,随机采样25%作为测试样本,其余作为训练样本
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=40, test_size=0.25)
#数据标准化处理(归一化)
ss_x = StandardScaler()
ss_y = StandardScaler()
x_train = ss_x.fit_transform(x_train)
x_test = ss_x.transform(x_test)
y_train = ss_y.fit_transform(y_train)
y_test = ss_y.transform(y_test)5.2 建模准备
所谓建模也就是根据所研究的问题选择恰当的算法搭建学习模型,并且基于所设定的模型评价指标,在训练过程中调整模型参数以使得模型的整体性能达到最优。
模型评估方法:
MSE
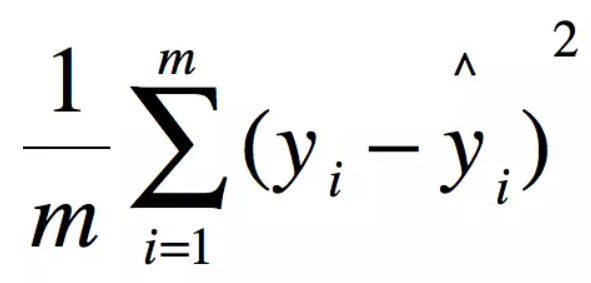
R2
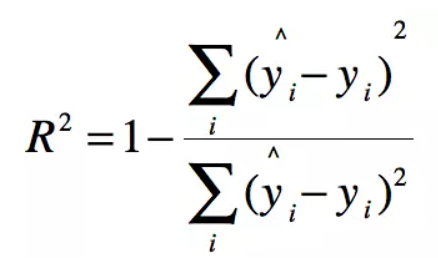
MAE
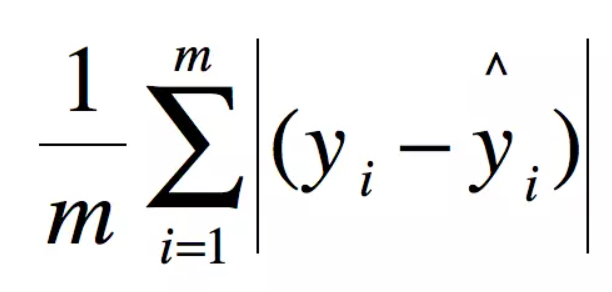
RMSE
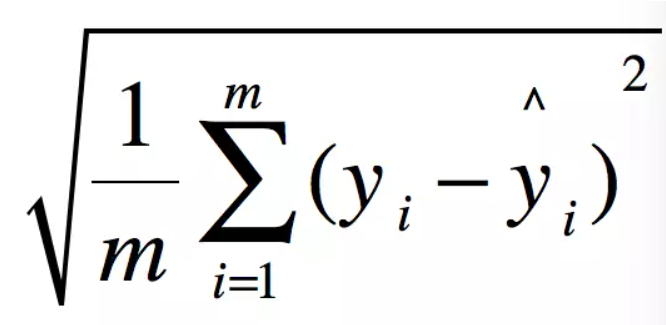
这里我们首先自定义获取均方误差,均方根误差,和交叉验证的函数:
python
def get_mse(records_real, records_predict):
# 均方误差 估计值与真值 偏差
if len(records_real) == len(records_predict):
return sum([(x - y) ** 2 for x, y in zip(records_real, records_predict)]) / len(records_real)
else:
return None
python
def get_rmse(records_real, records_predict):
# 均方根误差:是均方误差的算术平方根
mse = get_mse(records_real, records_predict)
if mse:
return math.sqrt(mse)
else:
return None
python
#定义交叉验证的策略,以及评估函数
def rmse_cv(model,X,y):
# 针对各折数据集的测试结果的均方根误差
rmse = np.sqrt(-cross_val_score(model, X, y, scoring="neg_mean_squared_error", cv=5)) # cv 代表数据划分的KFold折数
return rmse另外还需定义一个函数用于网格搜索,方便我们找到更好的参数-例如决策树的最大深度,剪枝策略等:
python
# 搜索各个算法的超参数
# 定义先验参数网格搜索验证方法
class grid():
def __init__(self,model):
self.model = model
def grid_get(self,X,y,param_grid):
grid_search = GridSearchCV(self.model,param_grid,cv=5, scoring="neg_mean_squared_error")
grid_search.fit(X,y)
# 打印最佳参数及对应的评估指标
print(grid_search.best_params_, np.sqrt(-grid_search.best_score_))
grid_search.cv_results_['mean_test_score'] = np.sqrt(-grid_search.cv_results_['mean_test_score'])
# 打印单独的各参数组合参数及对应的评估指标
print(pd.DataFrame(grid_search.cv_results_)[['params','mean_test_score','std_test_score']])其实,在开始训练模型前,最好再进行一次主成分分析,这样做的目的是为了去除相关性,有助于帮助提升模型训练的效果,不单单是为了特征降维。
经过尝试,主成分分分析对于最终分数的提升不是很大,因为我们数据集的特征很少,特征之间的相关性很弱,所以效果不是很显著。而对于特征数很大比如几百个特征,这时效果就提升很显著,因为可能处理数据时新建的特征和原始特征存在相关性,这可能导致较强的多重共线性 (Multicollinearity) ,而主成分分分析可以去除它们中的相关性。
n_components不能超过特征总数
pca_model = PCA(n_components=33)
x_train = pca_model.fit_transform(x_train)
y_train = pca_model.transform(y_train)
5.3 简单算法模型选择
这里采用K近邻,线性回归算法模型。
- K近邻回归模型不需要训练参数,只需要借助周围K个最近训练样本的目标值,对待测试样本的回归值进行决策。由此就衍生出衡量待测样本回归值的不同方式,即普通的算术平均算法和考虑距离差异的加权平均。
- 在线性回归中,数据使用线性预测函数来建模,并且未知的模型参数也是通过数据来估计。常用最小二乘逼近来拟合。
在sklearn中进行数据建模非常简单,它已经定义好了一些列模型,我们秩序调用即可。
python
from sklearn.neighbors import KNeighborsRegressor
# 初始化模型
knn = KNeighborsRegressor()
# 模型训练
knn.fit(x_train,y_train)
# 模型预测
y_pre_knn = knn.predict(x_test)
# 模型评估
knn_score = r2_score(y_test,y_pre_knn)
# 这里使用的r2决定系数
print(knn_score)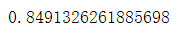
r2决定系数越趋近1越好,MSE,RMSE值越趋近0越好
使用均方误差:knn_score = get_mse(y_test,y_pre_knn):
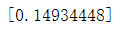
使用均方根误差:knn_score = get_rmse(y_test,y_pre_knn):

进行5此交叉验证rmse_cv(knn,x_train,y_train):
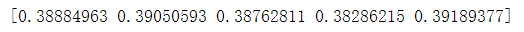
这里交叉验证使用的是均方根误差来评估模型,可以看到,每次结果相差不大,但总体结果不太好,一方面说明K近邻算法并不太适合此数据集,另一方面也可能数我们数据集不是太好。
同理线性回归:
python
linear = LinearRegression()
linear.fit(x_train,y_train)
y_pre_linear = linear.predict(x_test)
linear_score=r2_score(y_test,y_pre_linear)
print(linear_score)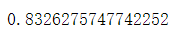
可以看到,结果还没有K近邻算法表现得好。
5.4 集成模型的算法选择
本次用于构建堆叠模型的回归算法有ElasticNet,SVR,BayesianRidge,Lasso,Ridge。
5.4.1 选定算法的先验参数预设,利用网格交叉验证的思想,选出各算法的最优先验参数:
- Lasso回归
python
param_grid = {'alpha': [0.0004,0.0005,0.0006,0.0007,0.0008,0.0009],'max_iter':[10000],'random_state':[1]}
grid(Lasso()).grid_get(x_train, y_train, param_grid)
- Ridge(岭回归)
python
param_grid = {'alpha':[35,40,45,50,55,60,65,70,80,90]}
grid(Ridge()).grid_get(x_train, y_train, param_grid)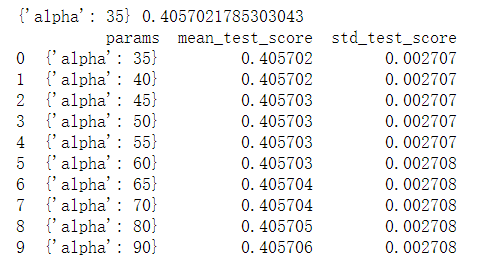
- SVR(支持向量回归)
python
param_grid = {'C':[11,12,13,14,15],'kernel':["rbf"],"gamma":[0.0003,0.0004],"epsilon":[0.008,0.009]}
grid(SVR()).grid_get(x_train, y_train, param_grid)- ElasticNet回归
python
param_grid = {'alpha':[0.0005,0.0008,0.004,0.005],'l1_ratio':[0.08,0.1,0.3,0.5,0.7],'max_iter':[10000],'random_state':[3]}
grid(ElasticNet()).grid_get(x_train, y_train, param_grid)其他算法类似,搜索出最佳超参数后,根据网格交叉验证结果指定各算法的超参数:
python
#指定每一个算法的参数
lasso = Lasso(alpha=0.0004,random_state=1,max_iter=10000)
ridge = Ridge(alpha=35)
svr = SVR(gamma= 0.0004,kernel='rbf',C=14,epsilon=0.009)
# ker = KernelRidge(alpha=0.4 ,kernel='polynomial',degree=3 , coef0=1.2)
ela = ElasticNet(alpha=0.004,l1_ratio=0.08,random_state=3,max_iter=10000)
bay = BayesianRidge()
xgb = XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,reg_alpha=0.4640,
reg_lambda=0.8571,subsample=0.5213, silent=1,random_state =7, nthread = -1)
lgbm = LGBMRegressor(objective='regression',num_leaves=5,learning_rate=0.05, n_estimators=700,max_bin = 55,
bagging_fraction = 0.8,bagging_freq = 5, feature_fraction = 0.25,feature_fraction_seed=9,
bagging_seed=9,min_data_in_leaf = 6, min_sum_hessian_in_leaf = 11)
GBR = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10, loss='huber', random_state =5)初步用每个算法训练数据,得到各模型的R2_score:
python
score = []
models = [ela,svr,bay,lasso,ridge,xgb,lgbm,GBR]
for regre in models:
regre.fit(x_train,y_train)
y_pre_regre = regre.predict(x_test)
regre_score=r2_score(y_test,y_pre_regre)
score.append(regre_score)
print('current model is {},rmse: {}'.format(regre,regre_score))
print('Optimal model is: {} , score is : {}'.format(models[score.index(max(score))],max(score)))

可以看到结果:梯度提升回归(Gradient boosting regression,GBR)得到的结果最优,为0.889922
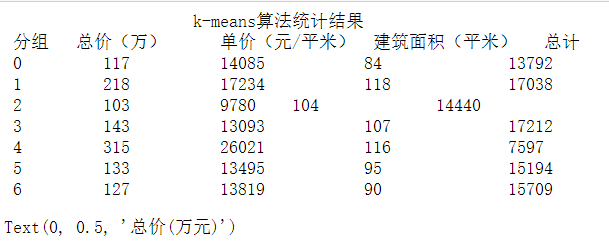
六. 聚类分析
该阶段采用聚类算法中的k-means算法对所有二手房数据进行聚类分析,根据聚类的结果和经验,将这些房源大致分类,已达到对数据概括总结的目的。在聚类过程中,选择面积、总价和单价这三个数值型变量作为样本点的聚类属性。
k-Means算法是一种使用最普遍的聚类算法,它是一种无监督学习算法,目的是将相似的对象归到同一个簇中。簇内的对象越相似,聚类的效果就越好。该算法不适合处理离散型属性,但对于连续型属性具有较好的聚类效果。
聚类效果判定标准:使各个样本点与所在簇的质心的误差平方和(SSE)达到最小,这是评价k-means算法最后聚类效果的评价标准。
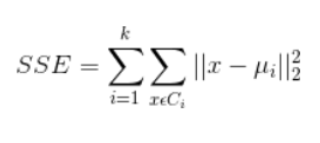
基本步骤:
- 选定k值
- 创建k个点作为k个簇的起始质心。
- 分别计算剩下的元素到k个簇的质心的距离,将这些元素分别划归到距离最小的簇。
- 根据聚类结果,重新计算k个簇各自的新的质心,即取簇中全部元素各自维度下的算术平均值。
- 将全部元素按照新的质心重新聚类。
- 重复第5步,直到聚类结果不再变化。
- 最后,输出聚类结果。
算法缺点
-
聚类的簇数k值需在聚类前给出,但在很多时候中k值的选定是十分难以估计的,很多情况我们聚类前并不清楚给出的数据集应当分成多少类才最恰当。
-
k-means需要人为地确定初始质心,不一样的初始质心可能会得出差别很大的聚类结果,无法保证k-means算法收敛于全局最优解。
-
对离群点敏感。
-
结果不稳定(受输入顺序影响)。
-
时间复杂度高O(nkt),其中n是对象总数,k是簇数,t是迭代次数。
聚类过程:
- 根据聚类原则:组内差距要小,组间差距要大。我们先算出不同k值下各个SSE值,然后绘制出折线图来比较,从中选定最优解。k值越大 SSE越小,我们就是要求出随着k值的变化SSE的变化规律,找到SSE减幅最小的k值,这时k应该是相对比较合理的值。从图中,我们可以看出k值到达5以后,SSE变化趋于平缓,所以我们选定5作为k值。
- 初始的k个质心选定是采用的随机法。从各列数值最大值和最小值中间按正太分布随机选取k个质心。
- 关于离群点,离群点就是远离整体的,非常异常、非常特殊的数据点。因为k-means算法对离群点十分敏感,所以在聚类之前应该将这些"极大"、"极小"之类的离群数据都去掉,否则会对于聚类的结果有影响。离群点的判定标准是根据数据可视化分析过程的散点图和箱线图进行判定。本数据集已经完成数据清洗工作,所以不存在离群值。
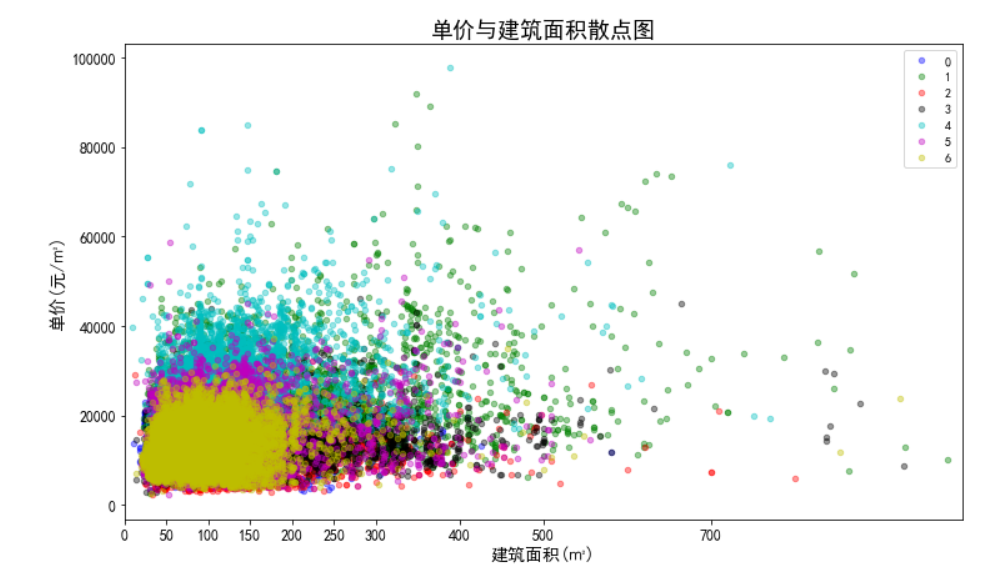
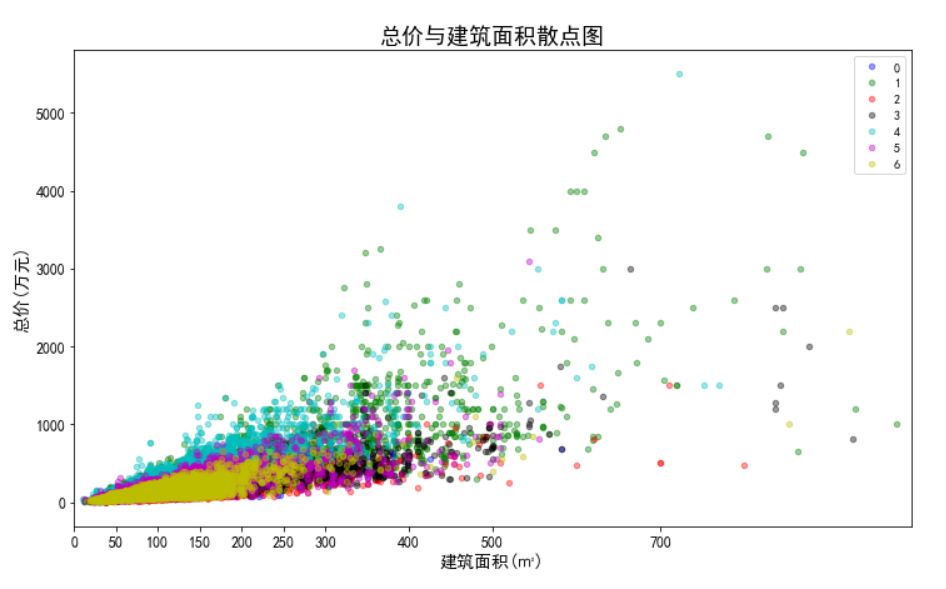
- 数据的标准化,因为总价的单位为万元,单价的单位为元/平米,建筑面积的单位为平米,所以数据点计算出欧几里德距离的单位是没有意义的。同时,总价都是5500以内的数,建筑面积都是1000以内的数,但单价都是100000以下的数,在计算距离时单价起到的作用就比总价大,总价和单价的作用都远大于建筑面积,这样聚类出来的结果是有问题的。这样的情况下,我们需要将数据标准化,即将数据按比例缩放,使之都落入一个特定区间内。去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行计算和比较。我们将单价、总价和面积都映射到1000,因为面积本身就都在1000以内,不要特别处理。单价在计算距离时,需要先乘以映射比例0.01,总价需要乘以映射比例0.18。进行数据标准化前和进行数据标准化后的聚类效果对比如下:
标准化前:
标准化后:
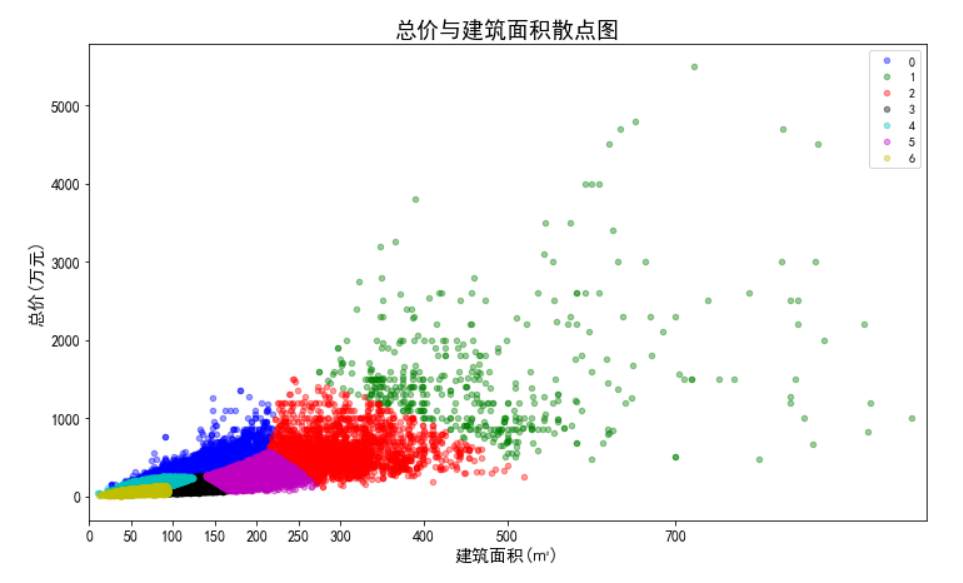
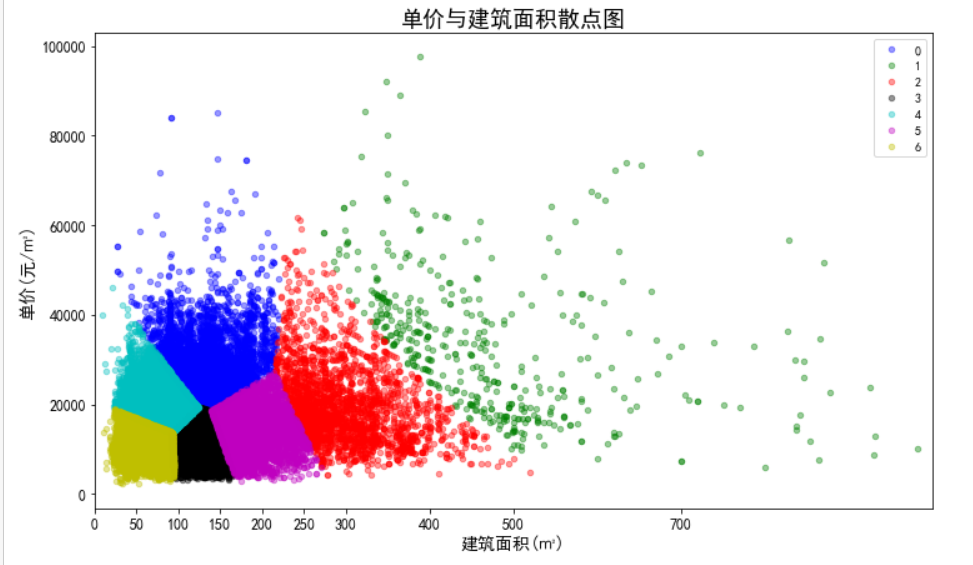
聚类结果: