原文链接:超越JoyCaptain速度更快更准确显存更低的图像反推Florence2PromptGen,适配Flux打标 (chinaz.com)
我们之前介绍的图像反推工具Joy_caption,虽然可以带来最好的反推效果,但是以其7.7G的显存占用量劝退了大部分用户。MiaoshouAI带来了全新的Florence2-PromptGen,它在显存占用上最低仅有0.7G,却能提供与Joy_caption相媲美的精准度,无疑是性价比的一次飞跃。
MiaoshouAI主要功能(官网介绍)
- 高精度:基于精选的 Civitai 图像和清洗标签数据集进行微调,生成高度精确和上下文相关的标签。
- 基于节点的系统:利用 ComfyUI 的节点系统的强大功能,将标注节点连接起来,结合描述性打标和关键词标注以获得最佳效果。
- 多功能集成:可以与其他节点(如Prompt Text Encoder)结合,达到出色的自动图像处理效果。
- 增强的图像训练:通过使用先进的标注和描述方法,为图像训练打标提供最佳结果。
ComfyUI 安装 MiaoshouAI 插件
插件地址:https://github.com/miaoshouai/ComfyUI-Miaoshouai-Tagger
可以在Manager搜索:miaoshou 进行安装:

重启即可。
注意:至少需要 transformers 版本 4.38.0
怎么查看transformers版本,可以安装这个插件:https://aisc.chinaz.com/jiaocheng/10417.html
Florence-2-X-PromptGen 模型下载
Florence-2-X-PromptGen-v1.5 也和 Florence-2 一样有 Base 和 Large 版本之分,也就是基础版和升级版,大小分别是 1Gb 和 3Gb,显存占用分别是 0.7G 和 1.8G 左右
模型地址:
- https://huggingface.co/MiaoshouAI/Florence-2-large-PromptGen-v1.5
- https://huggingface.co/MiaoshouAI/Florence-2-base-PromptGen-v1.5
推荐用Large 版本。
下载后放到:ComfyUI\models\LLM 目录下。
当然,如果你网络好的话,可以直接运行工作流,会自动下载所需的模型
节点详解
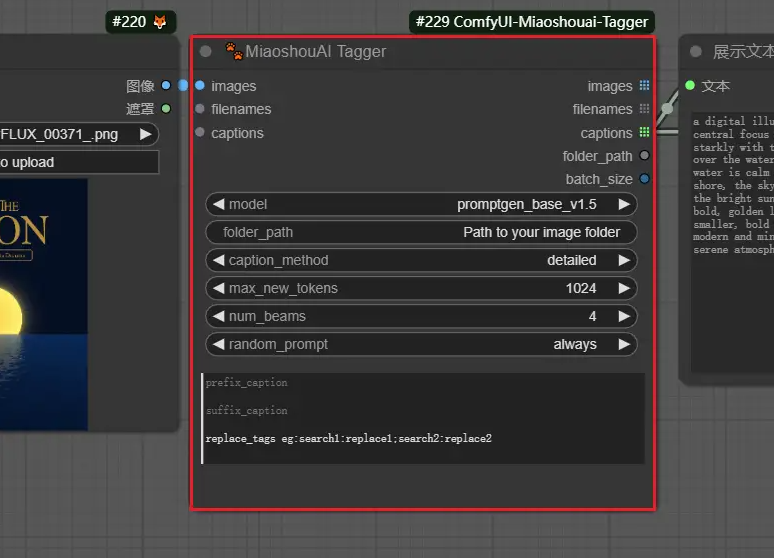
model支持:就是上面提到的base和large模型
caption_method:可以看下图的对比
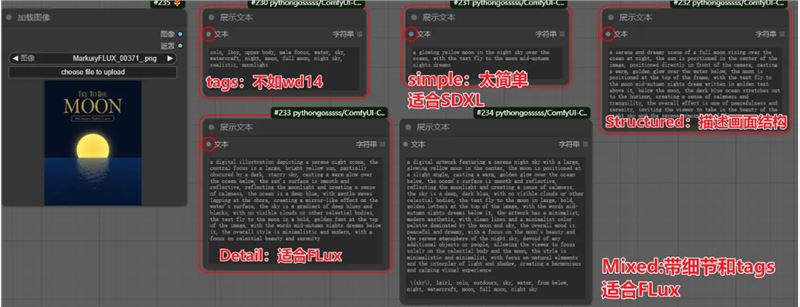
打标可以用Structured
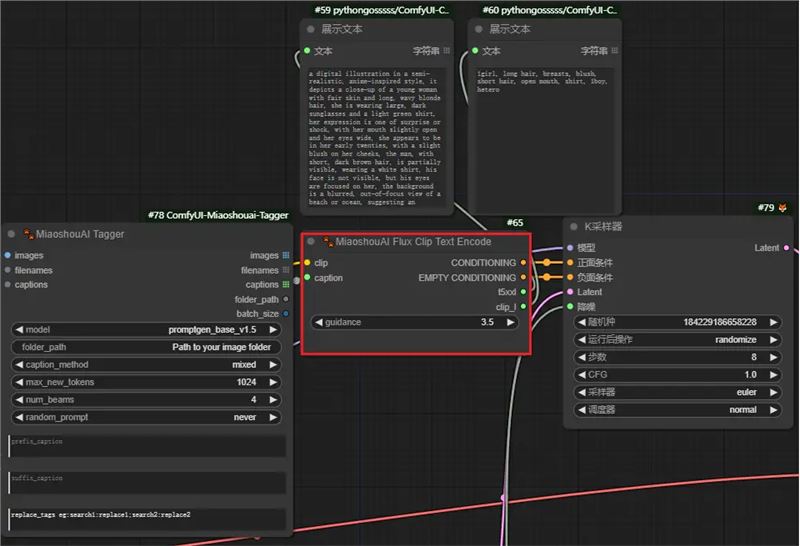
选择mixed时,可以生成混合的T5XXL和CLIP_L的clip数据流,这样就可以完美适配FLUX工作流,需要配合MiaoshouAI Flux CLIP Text Encode节点:
工作流示例
工作流插件作者都给了示例,大家可以自行下载
打标工作流说明
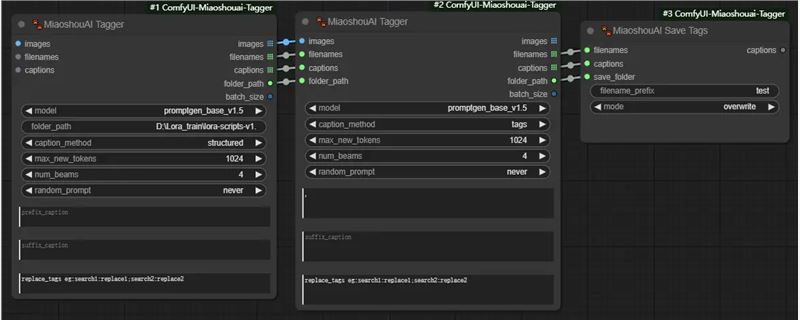
一般用于Lora 的训练,收集需要的图片,放到同一个目录下,一键打标。一般Flux的Lora训练都用这个来打标。
工作流
训练SDXL和SD15 的话第二个节点的metho可以选择tags,
训练Flux的话就选择Structured,mixed,detail都可以
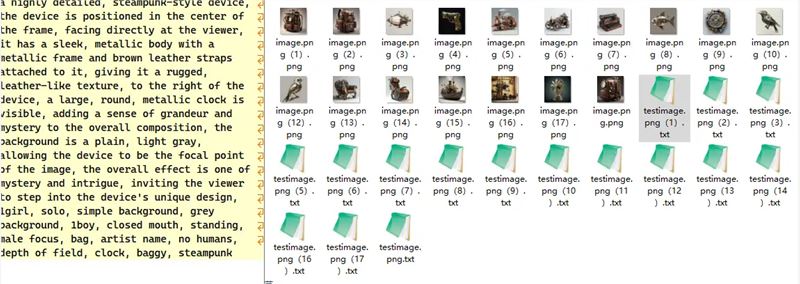
结果图
tags:
mixed:
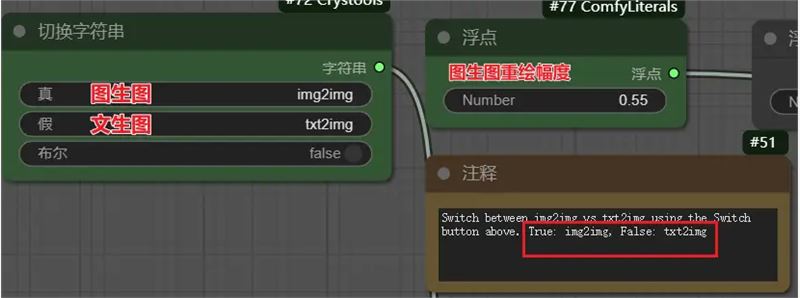
Flux工作流二说明
工作流中有个切换文生图和图生图的开关,大家注意一下即可
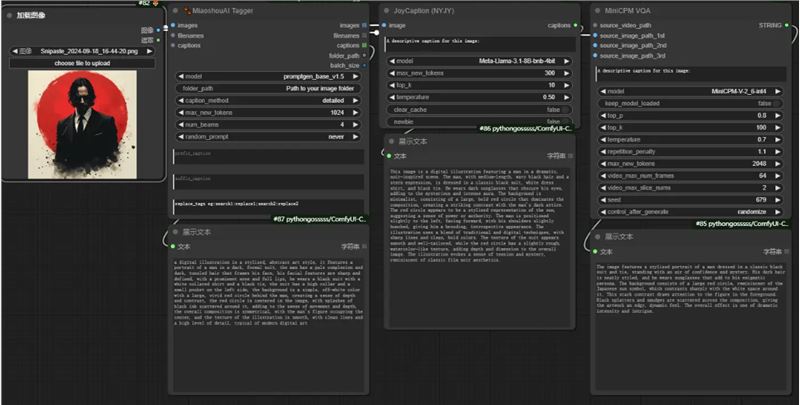
和其他反推模型的对比
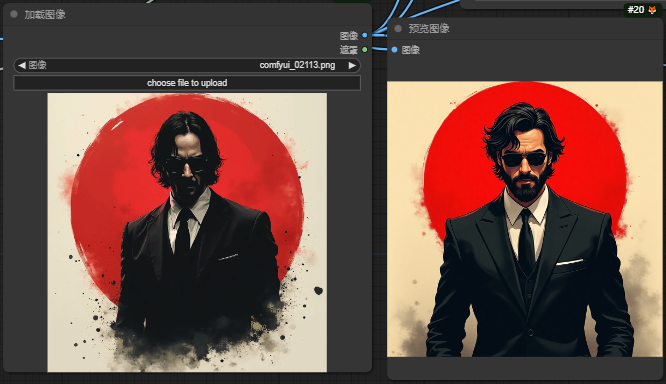
翻译及其生图效果:
Florence Gen:

Joy:

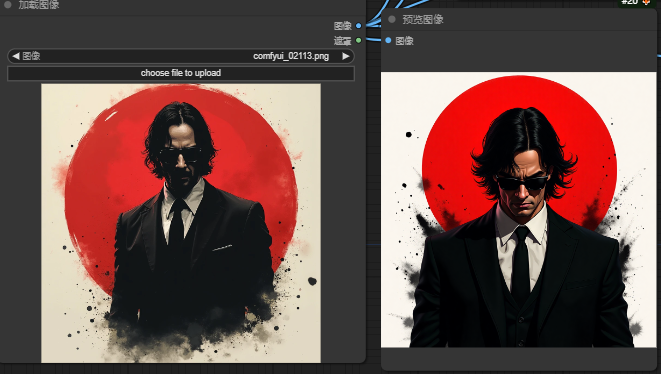
miniCPM:

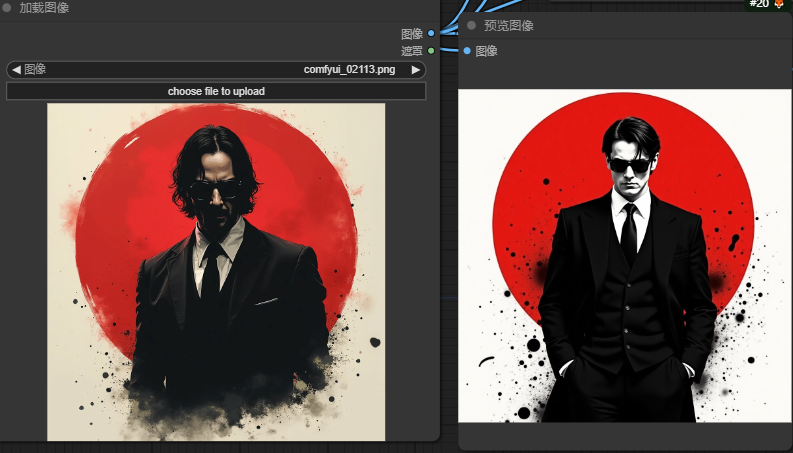
从这个对比可以看出Florencegen表现还是不错的,介于cpm和joy之间,cpm和joy对氛围的描写会更好,Florencegen更着重画面细节的描述。但是Florencegen仍然是最具性价比的,用极低的显存到达媲美joy的反推效果已经是成功了
不过这里也是简单测试,感兴趣的小伙伴可以多测试几个图片看看效果
我们的免费教程网站:AI教程_深度学习入门指南 - 站长素材 (chinaz.com)
