一、简介
TDengine 核心是一款高性能、集群开源、云原生的时序数据库(Time Series Database,TSDB),专为物联网IoT平台、工业互联网、电力、IT 运维等场景设计并优化,具有极强的弹性伸缩能力。同时它还带有内建的缓存、流式计算、数据订阅等系统功能,能大幅减少系统设计的复杂度,降低研发和运营成本,是一个高性能、分布式的物联网IoT、工业大数据平台。
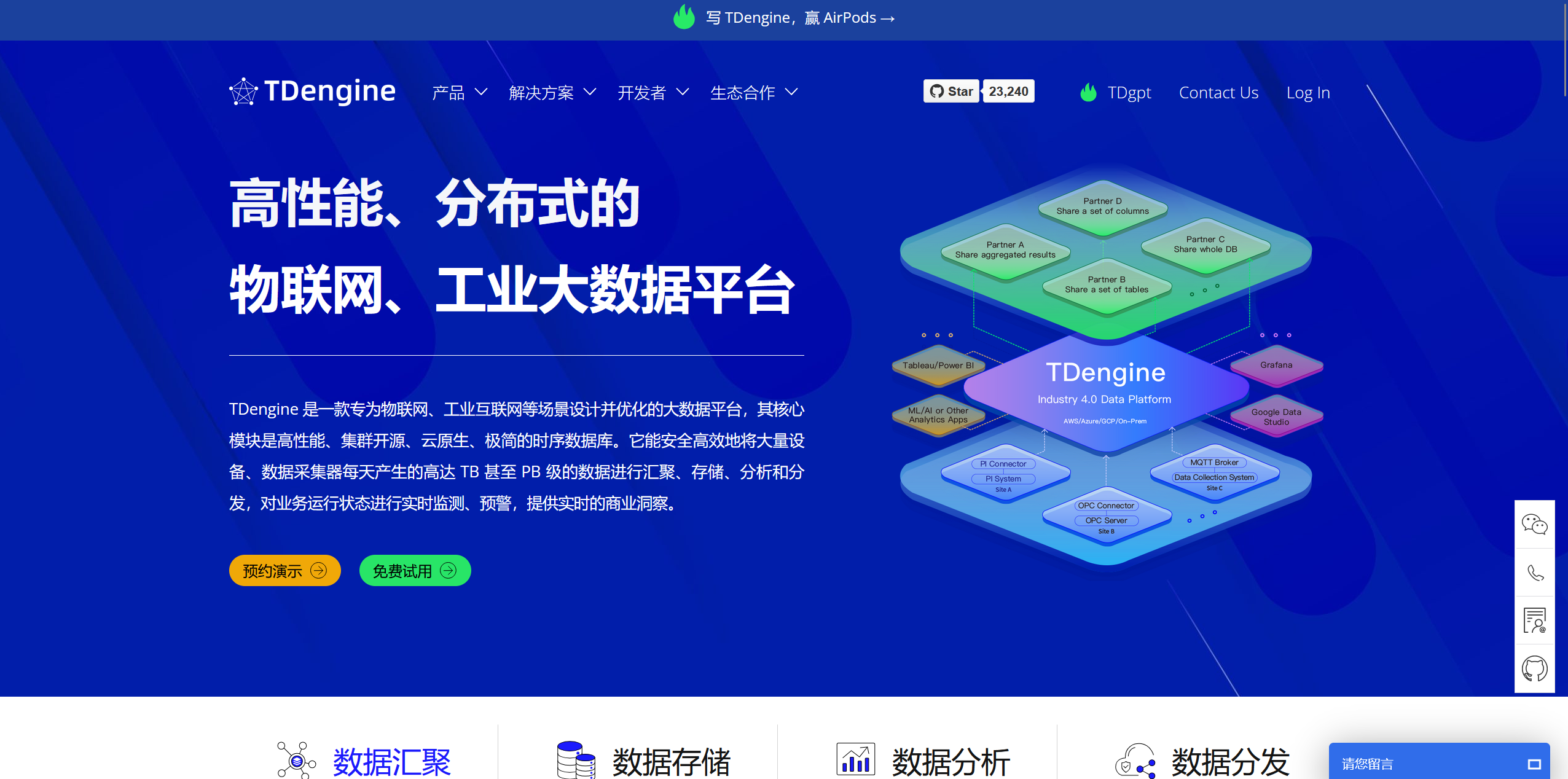
二、TDengine 功能与组件
TDengine 社区版是一开源版本,采用的是 AGPL 许可证,它具备高效处理时序数据所需要的所有功能,包括:
-
SQL 写入、无模式写入和通过第三方工具写入
S标准 SQL 查询、时序数据特色查询以及自定义函数(UDF)
S缓存每个时间序列的最新数据
S连续查询以及事件驱动流计算
S类 Kafka 数据订阅,加以过滤功能
S与 Grafana、Google Data Studio 可视化工具的无缝集成
S集群、高可用、高可靠
S主流编程语言的连接器
S命令行以及监控、数据导出、数据导入等多种工具
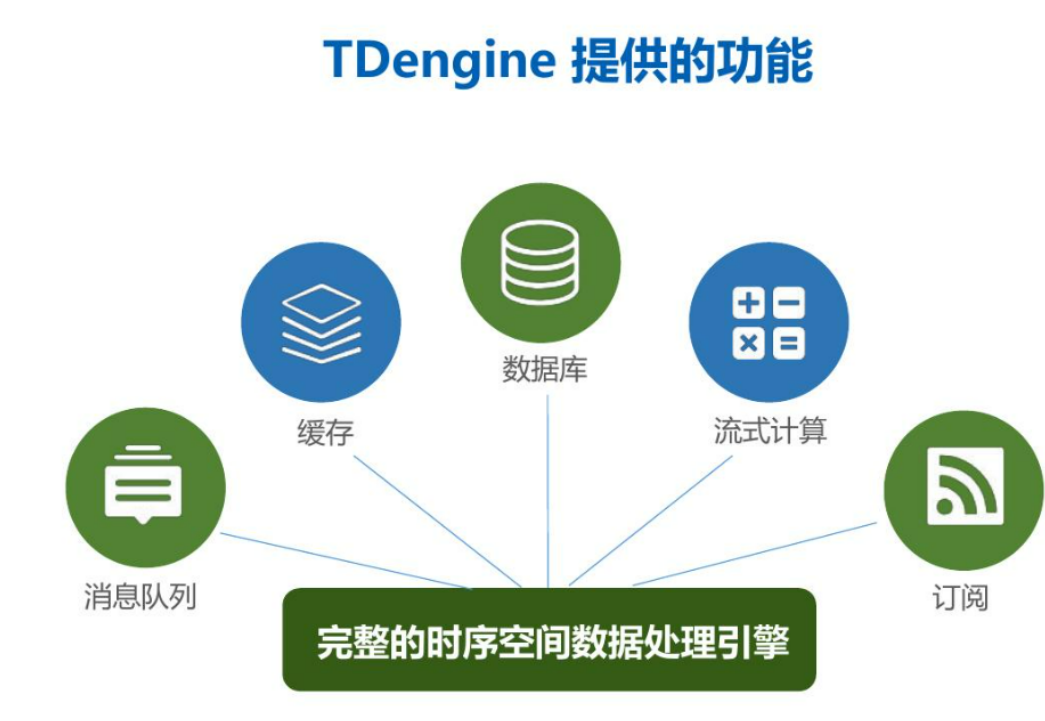
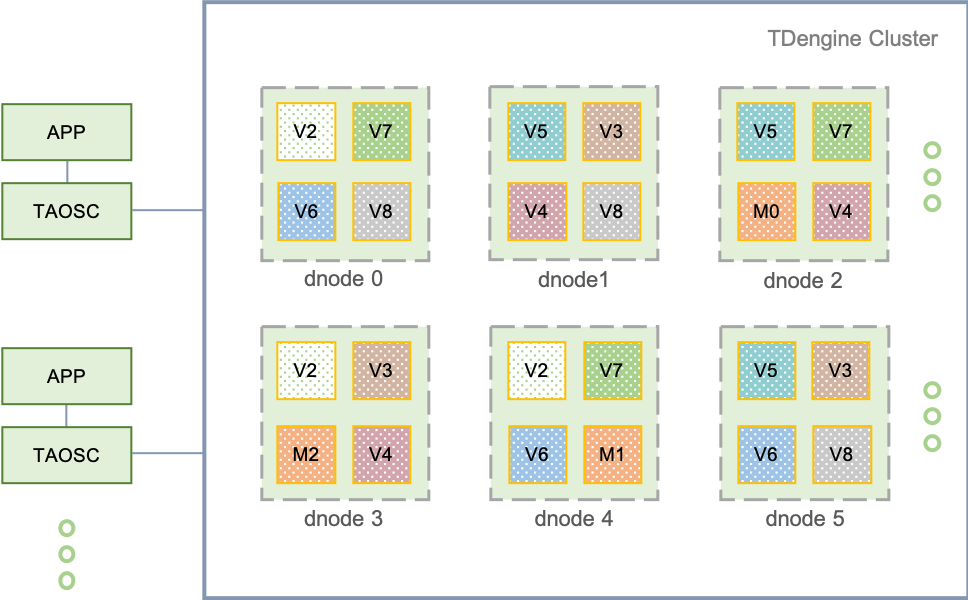
TDengine 分布式架构的逻辑结构图如下:
三、TDengine安装与应用
安装TDengine服务

下载地址:使用安装包快速体验 TDengine | TDengine 文档 | 涛思数据
目前 TDengine 在 Windows 平台上只支持 Windows Server 2016/2019 和 Windows 10/11。
这里我们先下载和安装TDengine-server-3.0.1.7-Windows-x64.exe。
安装之后的文件夹如下:
运行TDengine服务(taosd)
安装后,可以在拥有管理员权限的 cmd 窗口执行 sc start taosd 或在 C:\TDengine 目录下,运行 taosd.exe 来启动 TDengine 服务进程。
taosd.exe
执行TDengine命令行(taos)
为便于检查 TDengine 的状态,执行数据库(Database)的各种即席(Ad Hoc)查询,TDengine 提供一命令行应用程序(以下简称为 TDengine CLI)taos。要进入 TDengine 命令行,您只要在终端执行 taos 即可。
taos
新建数据库(脚本文件)
在 TDengine CLI 里可以通过 source 命令来运行脚本文件中的多条 SQL 命令。
# taos> source <filename>;
taos> source test.txt;test.txt内容如下:
CREATE DATABASE demo2;
USE demo2;
CREATE TABLE t (ts TIMESTAMP, speed INT);
INSERT INTO t VALUES ('2019-07-15 00:00:00', 10);
INSERT INTO t VALUES ('2019-07-15 01:00:00', 20);
SELECT * FROM t;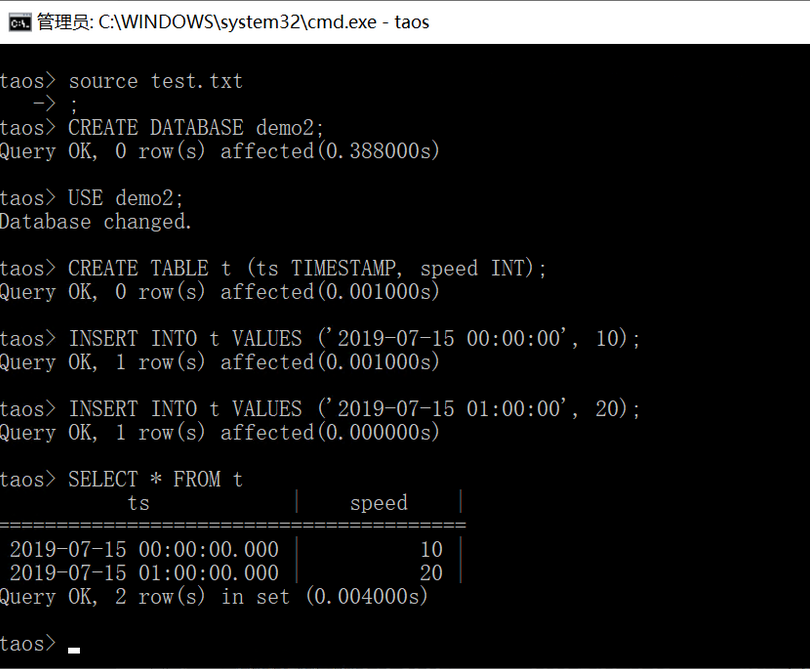
taosBenchmark命令(体验写入速度)
可以使用 TDengine 的自带工具 taosBenchmark 快速体验 TDengine 的写入速度。启动 TDengine 服务,然后在终端执行 taosBenchmark(曾命名为 taosdemo):
# taosBenchmark --help
taosBenchmark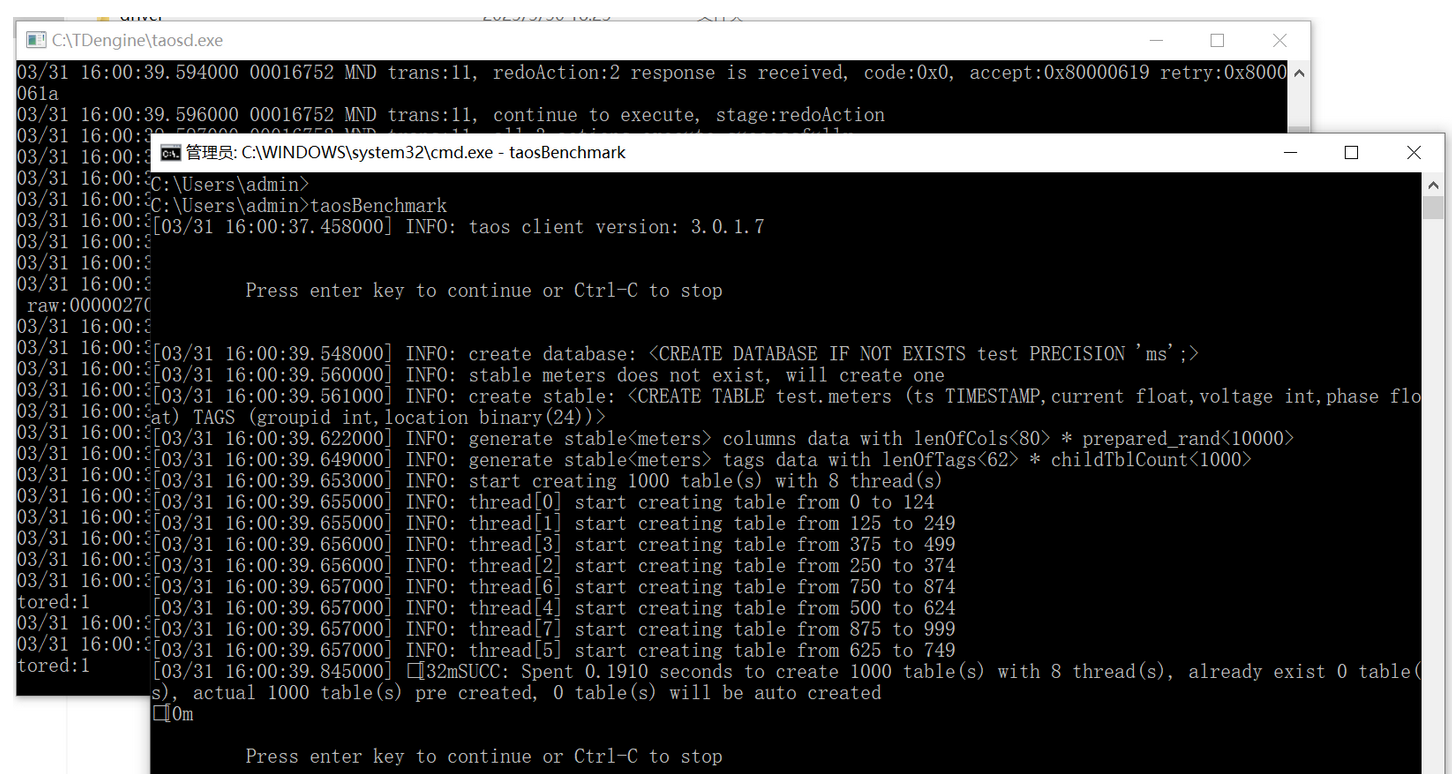
该命令将在数据库 test 下面自动创建一张超级表 meters,该超级表下有 1 万张表,表名为 d0 到 d9999,每张表有 1 万条记录,每条记录有 ts、current、voltage、phase 四个字段,时间戳从 2017-07-14 10:40:00 000 到 2017-07-14 10:40:09 999,每张表带有标签 location 和 groupId,groupId 被设置为 1 到 10,location 被设置为 California.Campbell、California.Cupertino、California.LosAngeles、California.MountainView、California.PaloAlto、California.SanDiego、California.SanFrancisco、California.SanJose、California.SantaClara 或者 California.Sunnyvale。
表管理
# 创建表
use testdb;
create table t1 (ts TIMESTAMP,name1 BINARY(100)) ;
# 查看表结构
describe t1;
# 插入数据
insert into t1 values('2021-03-10 22:37:36.100','test');
# 查询表
select * from t1;
# 查看当前所有表
show tables;
# 创建超级表
use testdb;
create table st1 (ts TIMESTAMP,name1 BINARY(100)) tags (tgs binary(20));
# 查看超级表结构
describe st1;
# 插入数据
insert into t2 using st1 tags('tt') values('2021-03-10 22:37:36.100','test');
# 查询超级表
select * from t1;
# 查看当前所有超级表
show stables;TDengine 提供了丰富的应用程序开发接口,为了便于用户快速开发自己的应用,TDengine 支持了多种编程语言的连接器,其中官方连接器包括支持 C/C++、Java、Python、Go、Node.js、C# 和 Rust 的连接器。这些连接器支持使用原生接口(taosc)和 REST 接口(部分语言暂不支持)连接 TDengine 集群。社区开发者也贡献了多个非官方连接器,例如 ADO.NET 连接器、Lua 连接器和 PHP 连接器。
taospy 是 TDengine 的官方 Python 连接器。taospy 提供了丰富的 API, 使得 Python 应用可以很方便地使用 TDengine。taospy 对 TDengine 的原生接口和 REST 接口都进行了封装, 分别对应 taospy 包的 taos 模块 和 taosrest 模块。 除了对原生接口和 REST 接口的封装,taospy 还提供了符合 Python 数据访问规范(PEP 249) 的编程接口。这使得 taospy 和很多第三方工具集成变得简单,比如 SQLAlchemy 和 pandas。
taos-ws-py 是使用 WebSocket 方式连接 TDengine 的 Python 连接器包。可以选装。
使用客户端驱动提供的原生接口直接与服务端建立的连接的方式下文中称为"原生连接";使用 taosAdapter 提供的 REST 接口或 WebSocket 接口与服务端建立的连接的方式下文中称为"REST 连接"或"WebSocket 连接"。
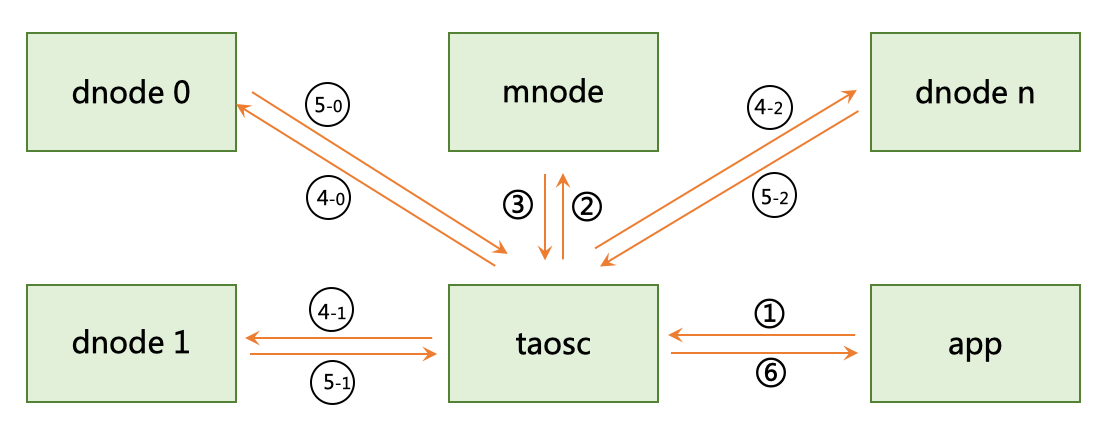
TDengine 典型的操作流程
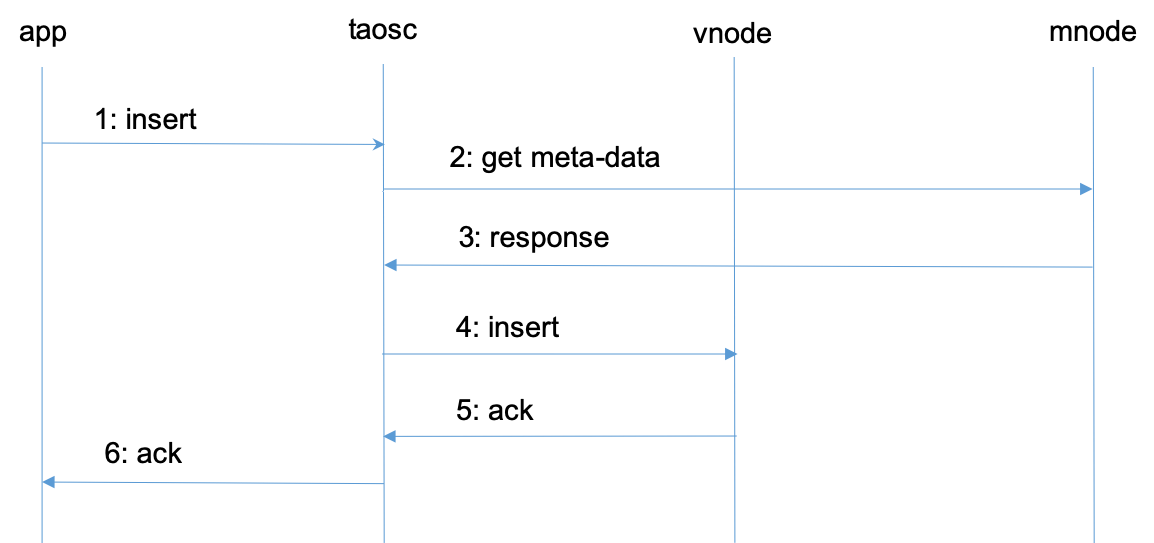
对于第二和第三步,taosc 启动时,并不知道 mnode 的 End Point,因此会直接向配置的集群对外服务的 End Point 发起请求。如果接收到该请求的 dnode 并没有配置 mnode,该 dnode 会在回复的消息中告知mnode EP 列表,这样 taosc 会重新向新的 mnode 的 EP 发出获取 meta-data 的请求。
对于第四和第五步,没有缓存的情况下,taosc 无法知道虚拟节点组里谁是 master,就假设第一个 vnodeID 就是 master,向它发出请求。如果接收到请求的 vnode 并不是 master,它会在回复中告知谁是 master,这样 taosc 就向建议的 master vnode 发出请求。一旦得到插入成功的回复,taosc 会缓存 master 节点的信息。
上述是插入数据的流程,查询、计算的流程也完全一致。taosc 把这些复杂的流程全部封装屏蔽了,对于应用来说无感知也无需任何特别处理。
通过 taosc 缓存机制,只有在第一次对一张表操作时,才需要访问 mnode,因此 mnode 不会成为系统瓶颈。但因为 schema 有可能变化,而且 vgroup 有可能发生改变(比如负载均衡发生),因此 taosc 会定时和mnode 交互,自动更新缓存。
多表聚合查询
TDengine 对每个数据采集点单独建表,但在实际应用中经常需要对不同的采集点数据进行聚合。为高效的进行聚合操作,TDengine 引入超级表(STable)的概念。超级表用来代表一特定类型的数据采集点,它是包含多张表的表集合,集合里每张表的模式(schema)完全一致,但每张表都带有自己的静态标签,标签可以有多个,可以随时增加、删除和修改。应用可通过指定标签的过滤条件,对一个 STable 下的全部或部分表进行聚合或统计操作,这样大大简化应用的开发。其具体流程如下图所示:
四、相关问题分析
为什么选择TDengine?
在装备行业物联网场景下实时数据量巨大,包括温度、压力、振动、位移等众多参数,针对这些参数如何进行分析和预警都是难点。这些需求概况如下:
-
高并发数据写入,每条记录都需要带时间戳;
-
不同传感器设备需要记录的数据字段不同,希望能够针对不同设备单独建表;
-
原始数据存储要求在5年以上,需要支持数据压缩,以降低数据存储成本;
-
支持国产化,支持数据库厂商服务快速响应。
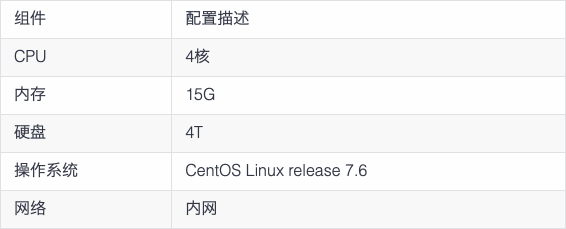
选用TDengine社区版2.2.1.1进行分布式模拟试验,用到了3台配置如下的服务器:
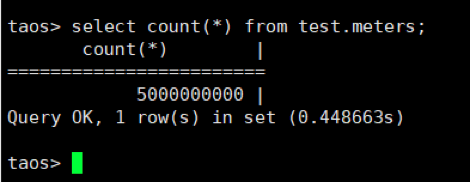
测试一:验证时序数据库产品3台数据库节点时序数据写入性能
模拟2个厂区共10个车间的数据、每个车间1000个监测点,每个监测点从2017-07-14 10:40:00.000开始写入模拟数据,记录时间戳间隔0.001秒,每个测点写入500000条记录。
8线程写入,在写入超过50亿条记录后停止了写入程序。本次测试对50亿条数据记录的写入,平均写入速度达到191万条/秒。

测试二:验证时序数据库产品3台数据库节点时序数据压缩能力
在测试一的基础上,查看3台数据库节点实际文件大小,如下:
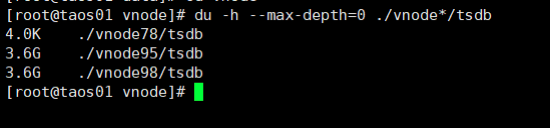
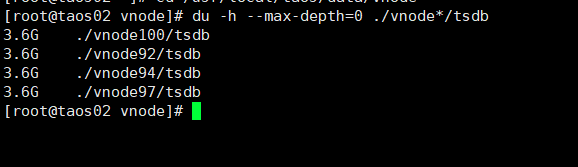
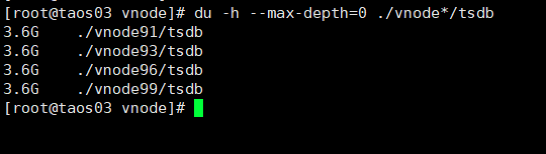
落盘后所有文件大小为36GB,
原始数据大小为5000000000*20/1024/1024/1024=93.13GB,
压缩比为36/93.13=38.65%。
测试三:时序数据库产品3台数据库节点对历史时序数据按时间回溯查询的性能
随机选择任一个测点,查询该测点在某个时间段内的历史数据,比如从2017-07-14 10:40:00.000 到 2017-07-14 10:40:10.000 10s内的共10001条数据记录(数据输出到文件)。数据库中对应查询语句为:
select * from d0 where ts >= '2017-07-14 10:40:00.000' and ts <= '2017-07-14 10:40:10.000' >> /dev/null;
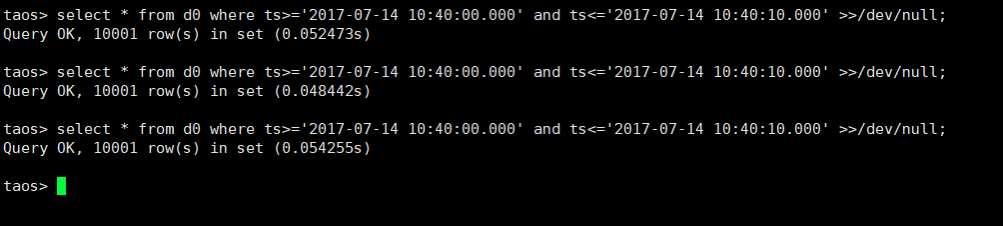
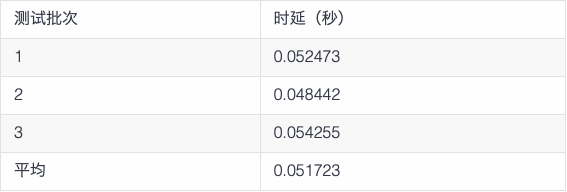
通过试验证,TDengine的写入性能高、并发高、查询时延极短;整体集群采用分布式架构,可靠性、稳定性、数据完整性满足项目需求。在选型结果确定之后,我们便立刻对原有业务系统进行了升级改造,正式引入 TDengine。
TDengine在3H1上的落地实践
3H1高端装备运维服务平台重点解决高端成形装备企业由制造化向服务化转型的关键问题,为企业提供工业互联网与智能运维的整体解决方案。
TDengine与高端成形装备的智能数据采集终端模块相连,助力采集终端完成对设备运行数据的采集,为系统提供设备数据基础;工业云计算服务平台提供系统数据的存储、转换、分析等,为系统提供业务数据支持;智能运维服务系统由装备智能运维服务平台和智能运维服务APP组成,分别为企业人员提供系统和移动端的服务支持。
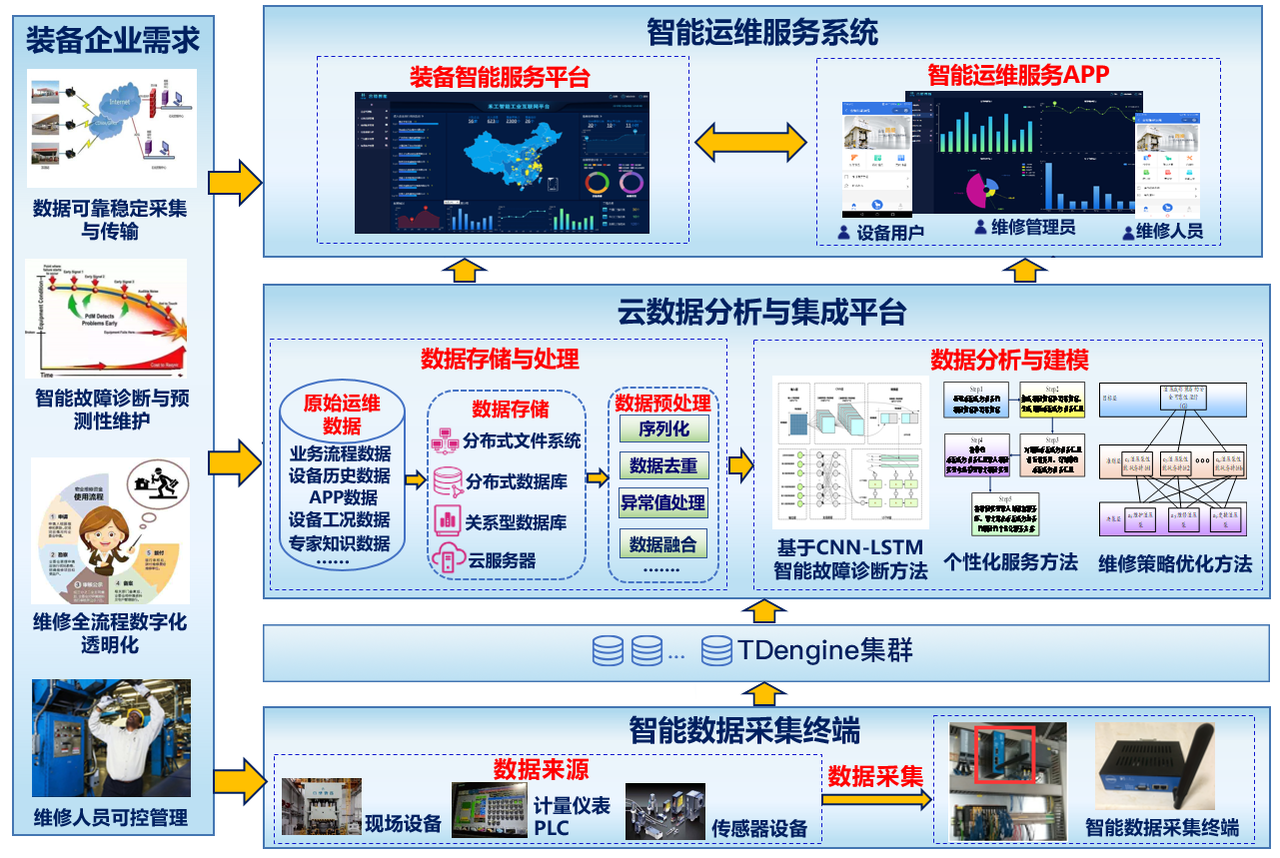
针对企业多种应用场景,系统应用服务共分为六大功能模块。
(1)企业驾驶舱:主要是服务于设备制造企业的管理者,方便了解平台数据情况与关键业务流程的指标,从整体界面上可以很方便的了解到设备的售卖情况,企业接入的信息,平台数据的采集情况。同时还可以对一些关键的业务流程,包括企业设备的监控、报警信息的展示、维修效率的管理、设备的故障情况和三包任务的信息进行追踪与管理。

(2)设备资源管理:主要的目的是为了给每一个高端成形装备建立电子档案,以便了解设备历史、当前情况,优化设备运行,预测设备未来状况,查看具体的设备信息时主要展示设备的四个维度------当前工况、健康分析、维修情况和历史工况。
当前工况方便用户了解设备的基本信息、关键指标和报警情况,还能够提供设备当前情况的总览。
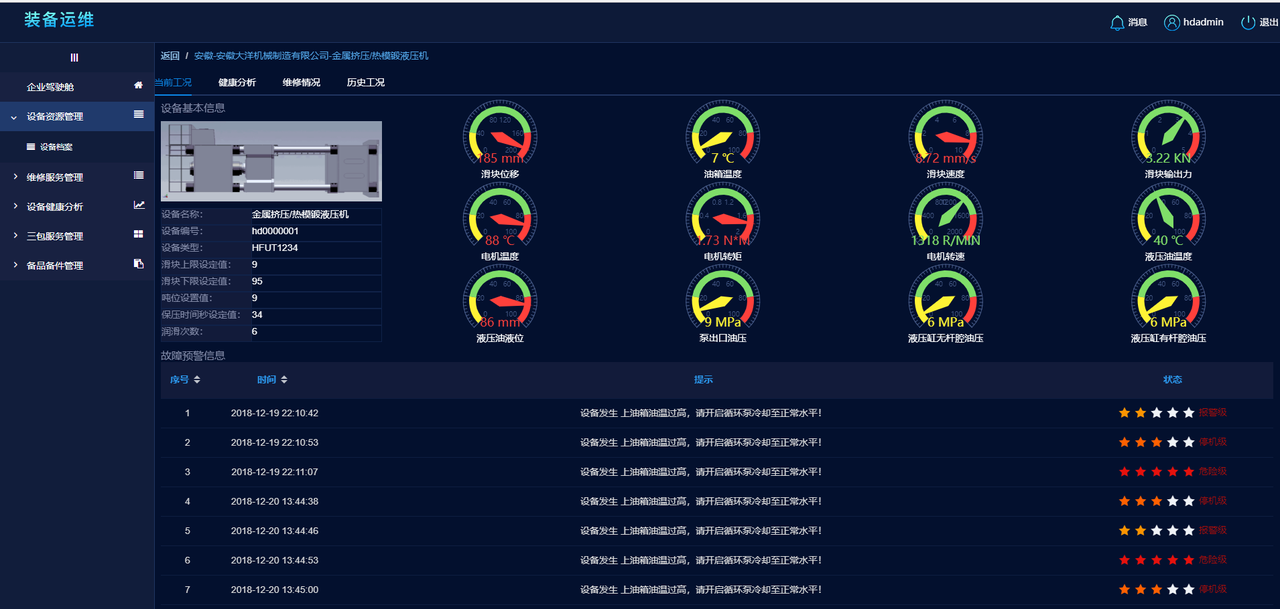
健康分析,其目的则是让设备用户更加深入地了解设备的当前状况、设备的健康状况随着时间的变化情况,如果设备当前面临故障风险,也能快速查找到引起风险的故障原因以及故障模块。
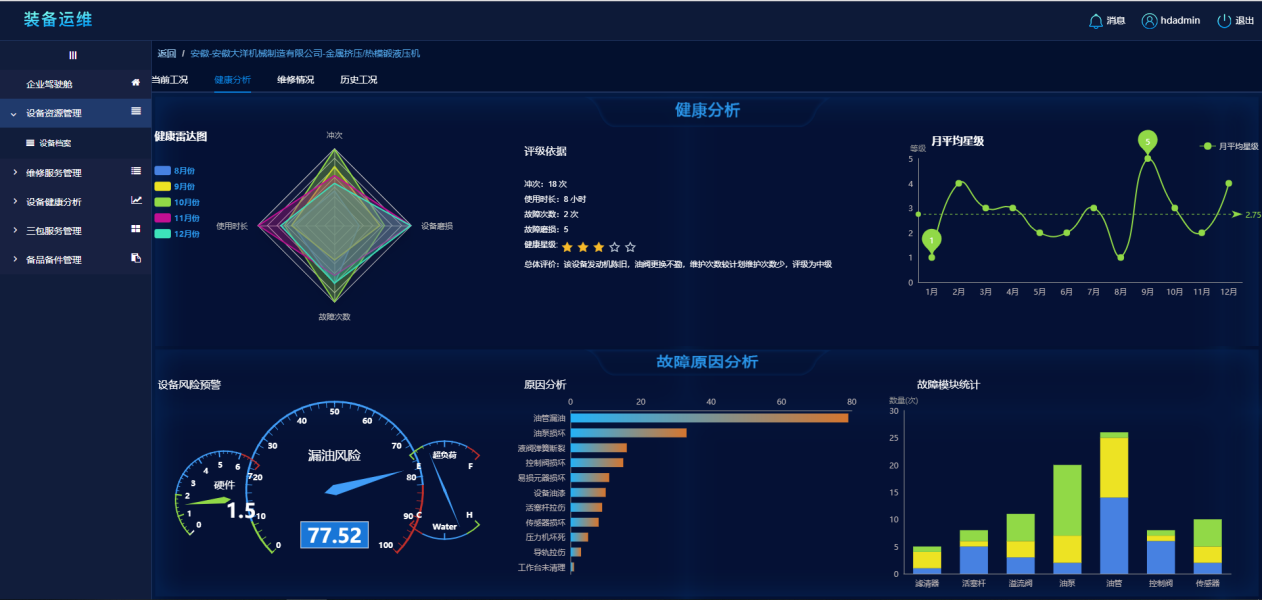
维修情况则是给了用户设备维修信息的总览和当前维修任务的流程跟踪。
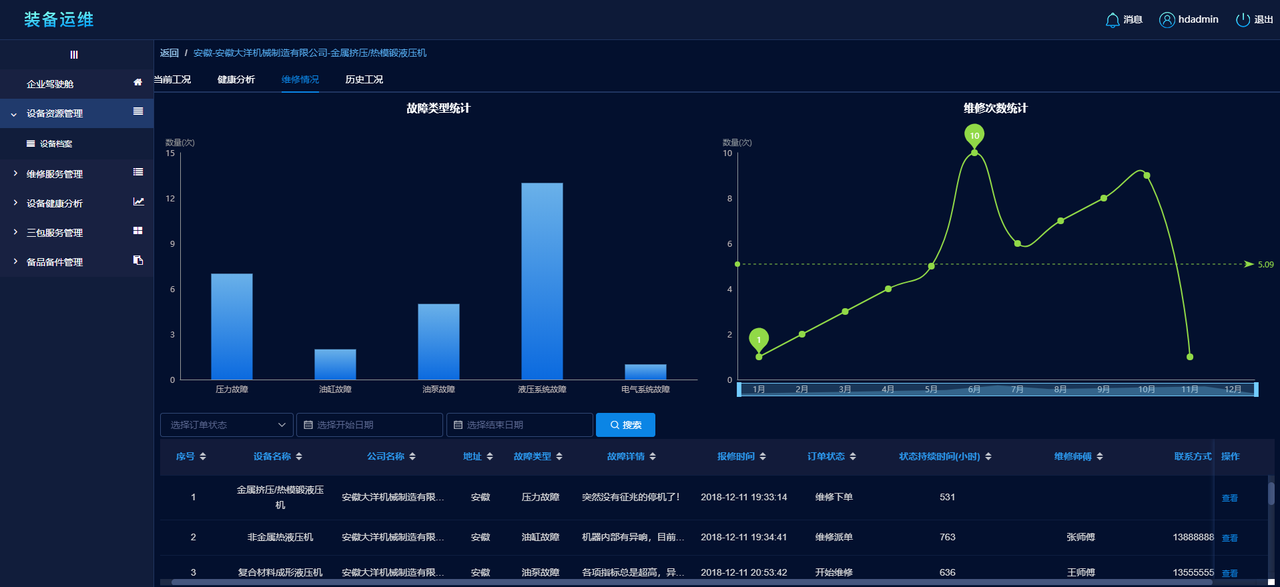
历史工况则是为了进行故障模块预排查。
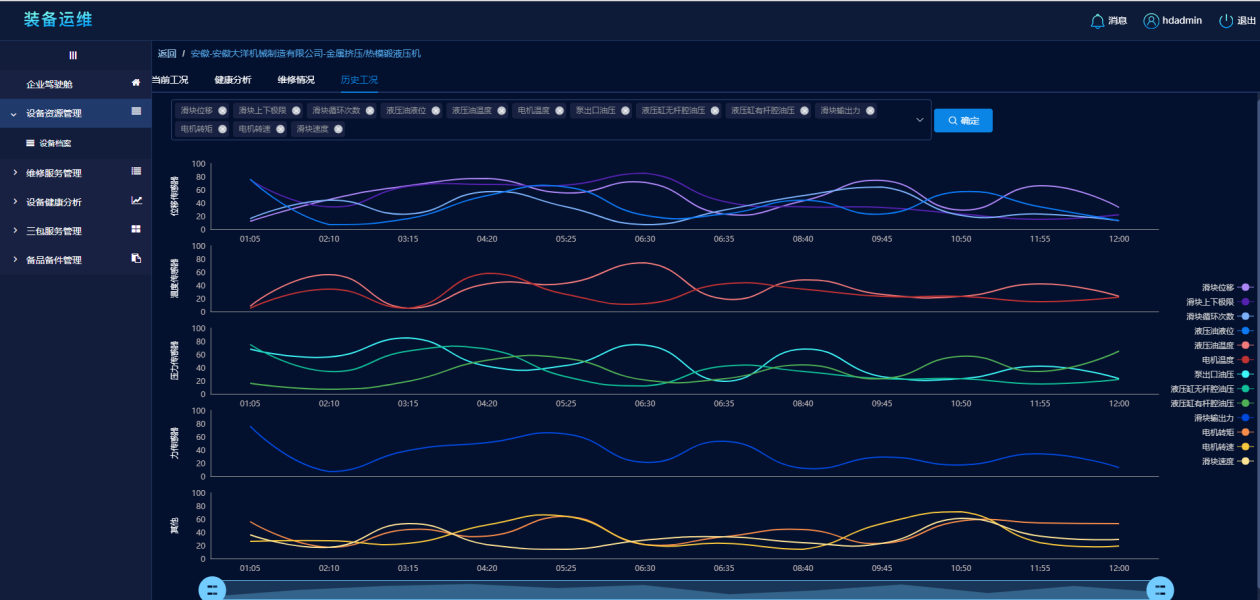
(3)维修服务管理:主要提供给维修服务部门人员所维修任务当前和历史的效率分析。维修任务展示当前待处理的任务数量,比如待接单、待派单和待回访,同时还可以对每个维修任务进行查看和操作,查看的内容具体到维修流程的每一个环节。
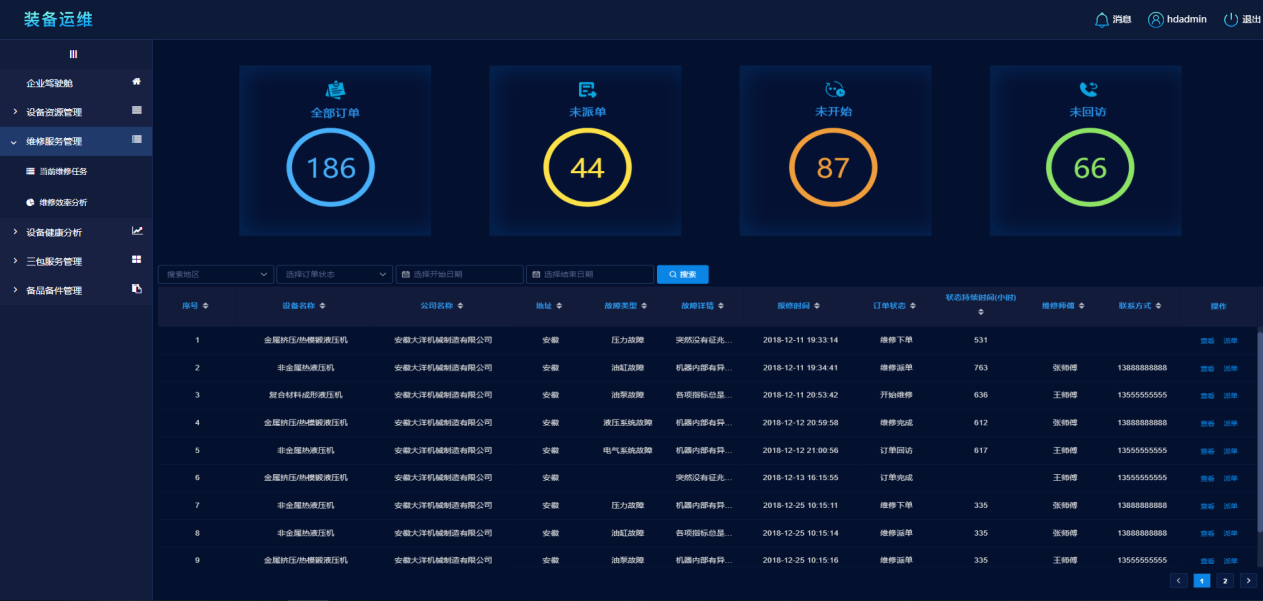
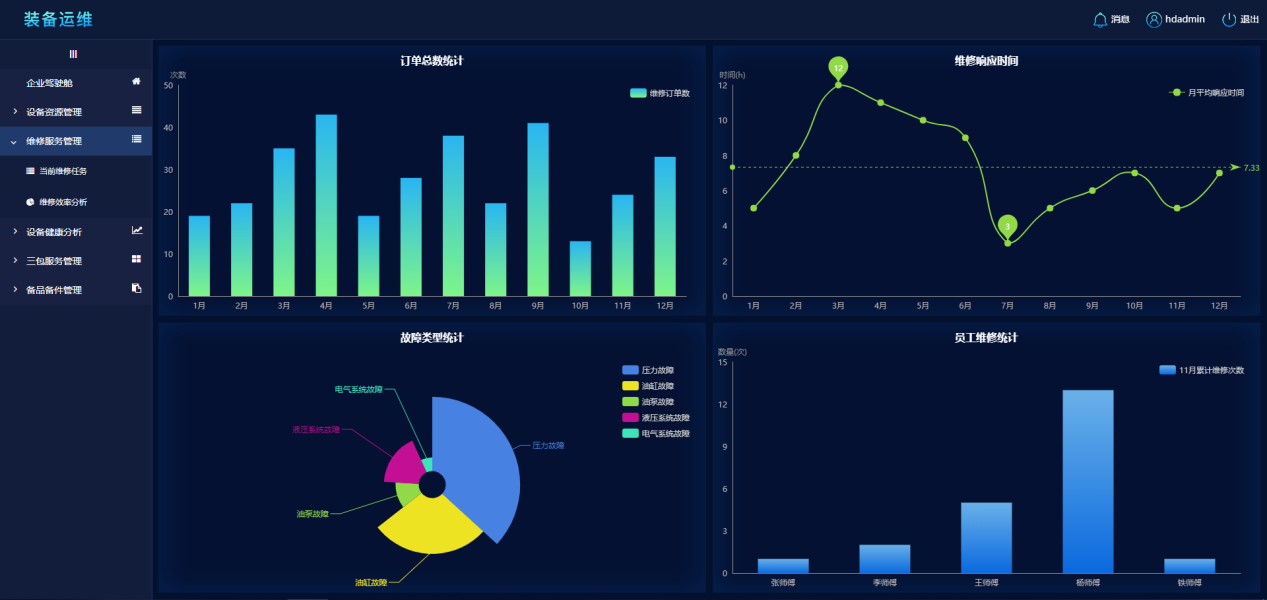
维修效率分析则是对维修中的关键效率指标进行统计分析、近一年来的订单量的变化情况、维修响应时间变化情况、故障类型分布、维修人员任务统计,方便维修管理人员对维修服务和效率进行管理。
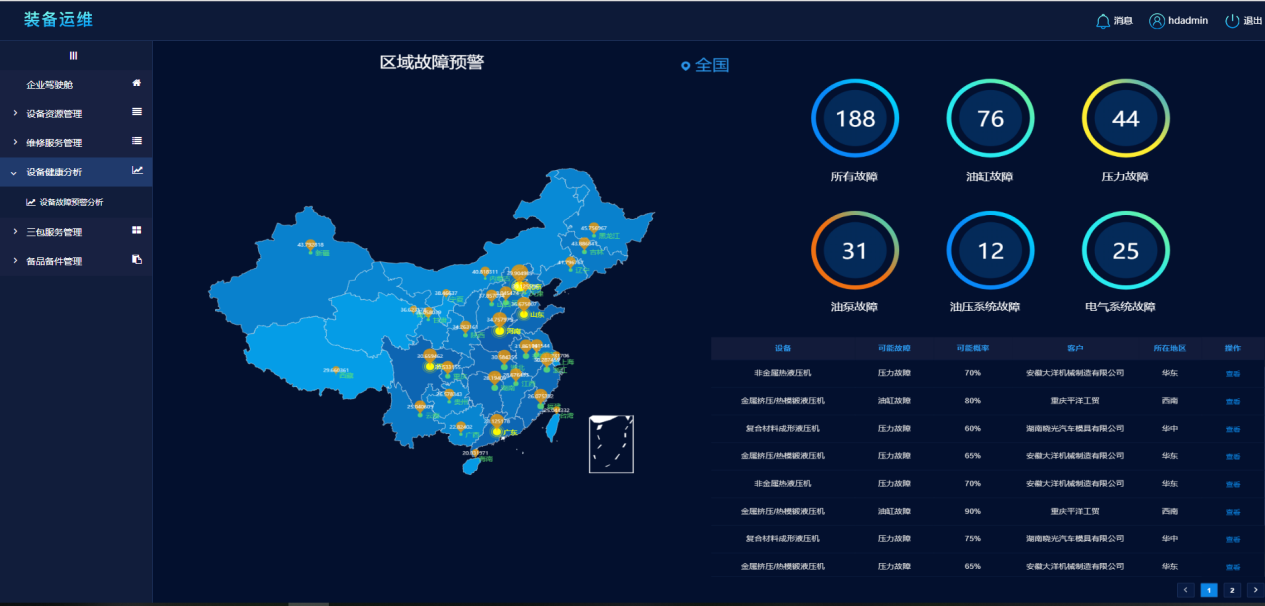
(4)设备健康分析:通过分析设备的历史和当前设备信息来预测设备未来可能发生的故障,并且给出故障的可能性和类型,方便维修部门为用户指定维保策略,主动联系用户。
(5)三包服务管理:服务于三包部门,提供当前维保活动提醒、设备维保活动记录、设备维保到期预警等功能。
(6)备品备件管理:备品备件管理通过将与维修保养相关的备品备件也都建档立案。用户和各相关部门人员可以在移动端和系统端进行备品备件查询申请审批等操作,减少不必要的工作流程,提高维修保养效率。同时通过数据分析来预测备品备件需求量,保证需求的同时减少企业的库存成本。在应用TDengine后,这六大功能模块在使用效果上也获得了显著提升,不光体现在数据的写入、查询性能上,同时也体现在高效的压缩效率上,真正实现了性能和成本平衡的最优化。
五、分析思路环节
架构改造升级TDengine后,效果非常明显,硬件资源减少到原来的1/5,效率有了明显的提升。随着存储规模的不断变大,这种改善和提升效果会越来越明显。此外,在运维管理、费用支出、开发测试等方面也有了很大的改善。
-
开发人员现在可以自己电脑上搭建一套环境,随便折腾,不用担心跑不起来,也不用担心影响别人;
-
性能测试的时候,用配置低一些的机器也没问题,照样能做出压测效果;
-
遇到技术难题,原来通过Google、百度、StackOverflow寻找答案,现在可以直接在官方渠道GitHub - taosdata/TDengine: High-performance, scalable time-series database designed for Industrial IoT (IIoT) scenarios提issue,也可以在TDengine的技术社区提问,TDengine的技术专家亲自答复,响应非常快;
-
TDengine的体积小,只有几M,上传起来非常快,有些私有化部署项目,不允许访问外网,只能手动上传,体积小的优势就非常明显;
-
安装部署简单,配合Docker容器,可以在几分钟内完成安装部署;
-
运营监控工作变简单了,只需要对TDengine的几个进程进行监控;
-
占用的磁盘空间明显变小了,减少到原来的1/5;
-
使用的主机减少到原来的1/5,相应的费用支出也减少了。
六、总结思考
此次升级改造总体进行得比较顺利,但过程中也有一些波折,尤其是在数据建模的时候遇到了一些困难。办法总比困难多,通过一些方法和技巧,我们把TDengine改造成了schema-free的数据库,满足了物联网平台的要求,最终完成了升级改造。
目前,已经支撑起了所有物联网设备上报的数据,同时支撑起了应用层的各种应用场景。
我们使用到的功能还比较简单,主要是插入、连续查询以及降采样查询,对于物联网平台来说基本够用。UNION、GROUP BY、JOIN、聚合查询等功能暂时还未使用到,这些功能对于大数据分析的场景非常有用,将来在一些大数据项目里可以尝试使用,用来代替Hadoop全家桶。
此外,使用过程中遇到一些问题,希望改进:
-
JDBC-JNI不是纯Java的,依赖一个动态库,给安装部署带来不少麻烦;后来通过JDBC-RESTful解决了这个问题,但是中间多了一层RESTful Connector,性能会低一些;最理想的做法,还是用纯Java写一个直连后端服务的JDBC Driver;
-
客户端是命令行方式,对于开发者不是很友好,尤其是一些初级开发者,或者是用惯了图形界面的开发者;图形界面,语法高亮,语法检查,这些功能还是很香;虽然目前有两个社区开发者提供的GUI,当然官方能提供支持的话是最好不过了。
七、未来规划
目前,在搭载TDengine后,3H1原有业务系统在升级改造后获得了极大的提升,不仅降低了研发和维护的成本,同时实现了横向扩展。TDengine优异的查询性能给我们带来了很大的惊喜,极高的压缩效率,也给我们节省了大量的存储资源。未来,我们也会尝试在更多场景应用TDengine,加强与TDengine的深度合作。