数据湖作为一种存储各种类型数据的集中式存储系统,以其灵活性、可扩展性和低成本的优势受到越来越多企业的青睐。然而,数据湖虽然降低了数据存储成本,但在数据分析尤其是实时数据分析场景下,其性能仍存在一定瓶颈。
本文将探讨如何利用开源项目 StarRocks 来提升 Iceberg 的查询效率,为企业提供更快速、更灵活的数据分析能力。 作为 StarRocks 社区的主要贡献者和商业化公司,镜舟科技深度参与 StarRocks 项目开发,也为企业着手构建湖仓架构提供更多参考。
一、Iceberg 数据湖查询所面临的性能挑战
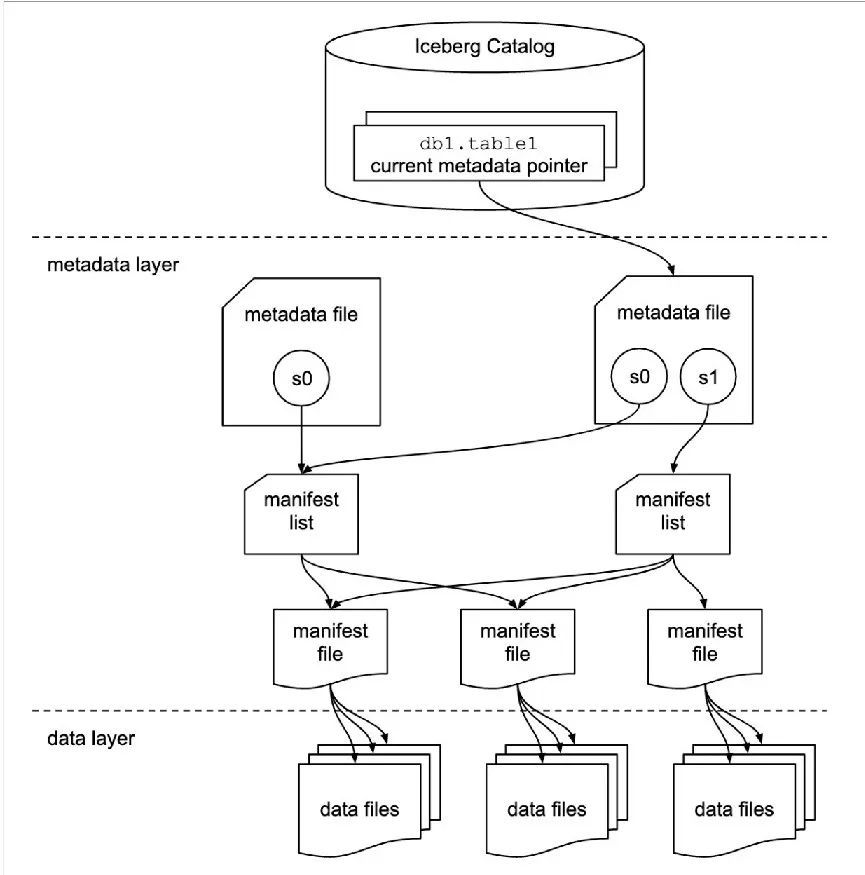
Iceberg 具备强大的功能和灵活性,不过在实际应用中,工程师在处理 Iceberg 表时经常会遇到查询性能瓶颈,对于持续增长的企业来说,这不仅是生产系统产生延迟的影响,更是对整体的业务交付和决策的影响,一旦出现问题,企业需要付出成倍的成本来解决。
1. 数据读取性能瓶颈
首先,由于 Iceberg 的数据存储在分布式文件系统中,数据读取性能受到文件系统性能的限制。
数据湖中的文件级别详细信息记录虽然强大,但扫描整个表进行数据查询需要较长时间。Iceberg 的清单文件(manifest files)通常被高度压缩以节省存储空间,但对于大型清单文件,解压缩过程需要更多时间。使用 C++ 等语言读取和解析这些大型文件时,即使在最佳情况下,也可能需要较长的解析时间。
2. 多维复杂查询性能不足
其次,Iceberg 在复杂多维查询上表现受限,尤其在处理大数据集时效率不足。其索引和分区策略虽能提升性能,但在特定场景下仍显不足。快照查询虽能及时反映数据最新状态,但在复杂查询场景下,数据扫描量大增,导致查询效率下降。
综上可以看出,Iceberg 提供了强大的功能和灵活性,但同时也要求企业投入相应的技术调优策略来实现最佳的系统管理和性能。因此,对于追求高效处理复杂查询的应用场景,需要考虑更简单高效的解决方案。
二、加速 Iceberg 查询的最佳方案------StarRocks
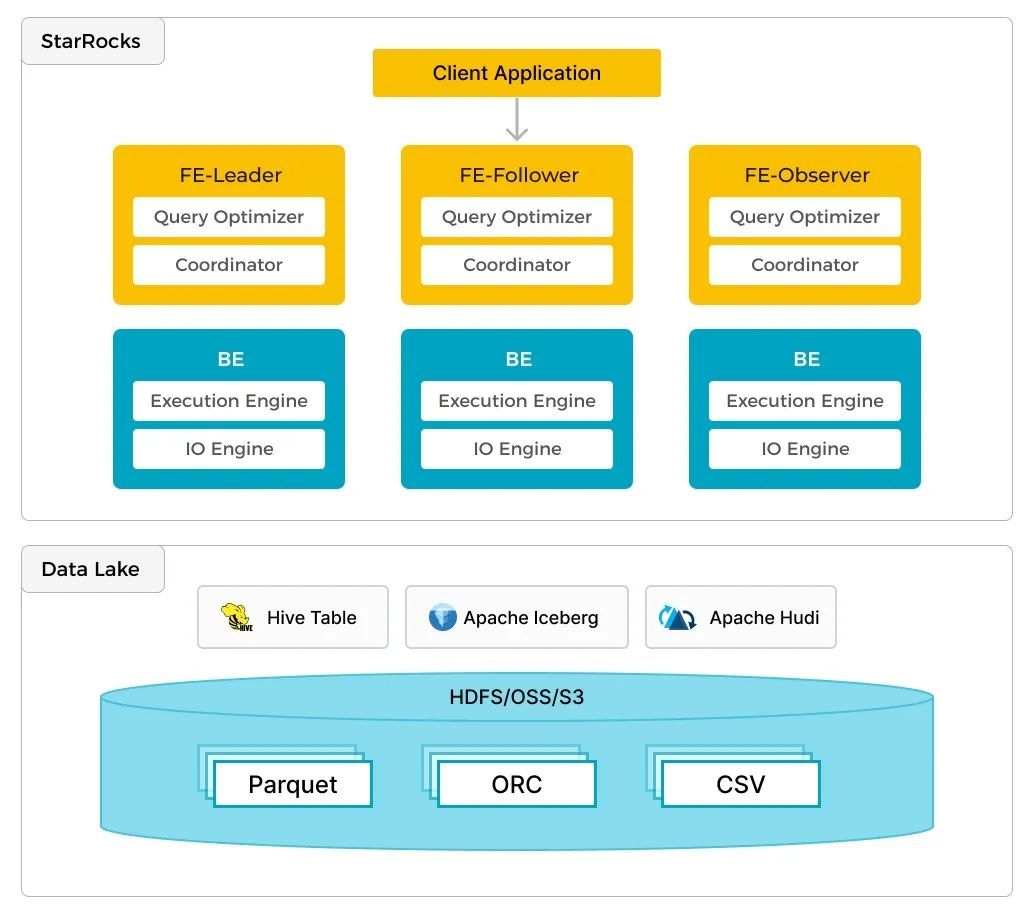
除了分析本地存储的数据,用户也可以通过 StarRocks 提供的 External Catalog,直接连接到 Iceberg 数据湖,实现无缝集成,无需进行数据迁移也能高效查询 Iceberg 上的数据。这一特性不仅简化了操作流程,还大大降低了数据访问的延迟。
1. 通过 StarRocks 优化查询执行,显著提升查询性能
StarRocks 采用了多种优化技术,如列式存储、索引加速、并行处理等,可以显著提升查询性能。
针对 Iceberg 元数据获取与解析存在的性能问题,可以利用 StarRocks 的 MPP 架构对元数据文件进行并行读取和过滤,这一特性不仅减少了 Master 节点的压力,还显著提升元数据处理的效率,从而加快查询计划的生成速度。
StarRocks 的 CBO 优化器能够收集外部表(包括 Iceberg 表)的统计信息,并利用这些信息生成高效的执行计划。特别是 3.2 版本开始,StarRocks 能够更精准地评估查询成本,选择最优的执行路径。
2. 缓存(Data Cache)与物化视图,提供不输数仓的查询体验
为了进一步提升查询效率,可以在 StarRocks 中部署缓存机制来存储热点数据。当查询请求到达时,如果缓存中有相关数据,则可以直接从缓存中读取数据而无需访问 Iceberg。
此外,在计算逻辑较为复杂、性能以及并发要求更高的场景下,可以利用预计算策略来生成物化视图,将复杂的查询结果预先计算并存储起来,以加快查询响应速度。目前,StarRocks 支持同步、异步、自动物化视图等多种能力。
三、最佳实践:小红书湖仓一体实践,性能提升 6-7 倍
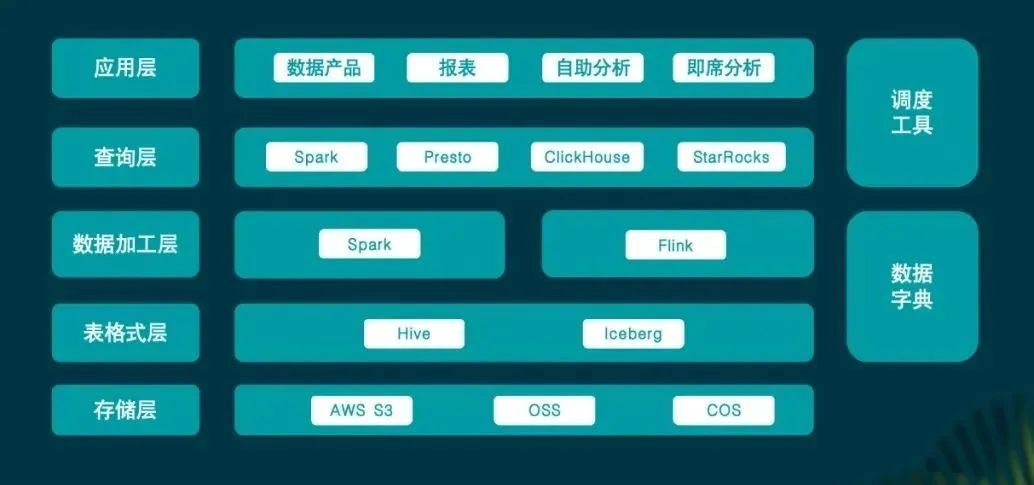
在小红书的数据平台架构中,Iceberg 作为数据湖的核心组件,负责存储海量数据。随着业务的发展和数据量的增长,Iceberg 数据湖的查询性能出现瓶颈。
StarRocks 3.0 的湖上分析能力帮助小红书在自助分析场景中,将查询引擎通过灰度迁移机制从 Presto 平滑迁移到 StarRocks,已迁移部分的平均查询性能提升 6-7 倍。同时,通过 StarRocks 自动化的数据同步流程,小红书能够对 Iceberg 数据进行直接分析,并确保 Iceberg 中的数据能够实时或定时同步到 StarRocks 中,来保持数据的一致性。
通过弹性伸缩等优化手段,小红书在保持查询性能的同时简化技术栈架构,降低了 IT 成本。特别是在低峰期通过归还 Spot 实例等方式,实现了成本的进一步节约。
更多与 Iceberg 集成的技术详情与用户实践点击此处了解。
写在最后
镜舟科技作为 StarRocks 的商业化公司,其湖仓分析引擎进一步解决了企业在实际应用中遇到的问题,镜舟湖仓分析引擎在开源产品 StarRocks 的基础上,增加诸多企业级产品特性,如更精细的数据权限控制、更便捷的可视化数据管理工具等,保障数据安全。
同时,镜舟湖仓分析引擎在易用性上提供更多支持,帮助企业轻松对接现有 IT 架构和业务系统,构建更加灵活数据分析平台,进一步提升企业的数据分析能力和用户体验。
