当 SD 使用到了进阶阶段,经常需要添加多个 LoRA 来生成图片,因此,提示词中难免会出现一系列的 LoRA 和相关触发词。
但很多时候,我们直接复制网上别人分享的完整提示词,会发现生成出来的效果不一样,这是怎么回事?
原因就是,别人用了 Addition Networks 插件来单独加载 LoRA,这样 LoRA 就不在提示词中显示了,
所以,你复制过来的,实际上是缺少 LoRA 的提示词,出图自然就不一样了。
插件安装
下载地址:https://github.com/kohya-ss/sd-webui-additional-networks
解压后,放置在:SD安装目录\extensions
重载UI后,在「文生图」页面下方,就会发现「Addition Networks」模块:

如果是首次使用,需要在「设置---Addition Networks」中,顶部的输入框,填入 LoRA 的存放位置,保存设置后,重载UI:
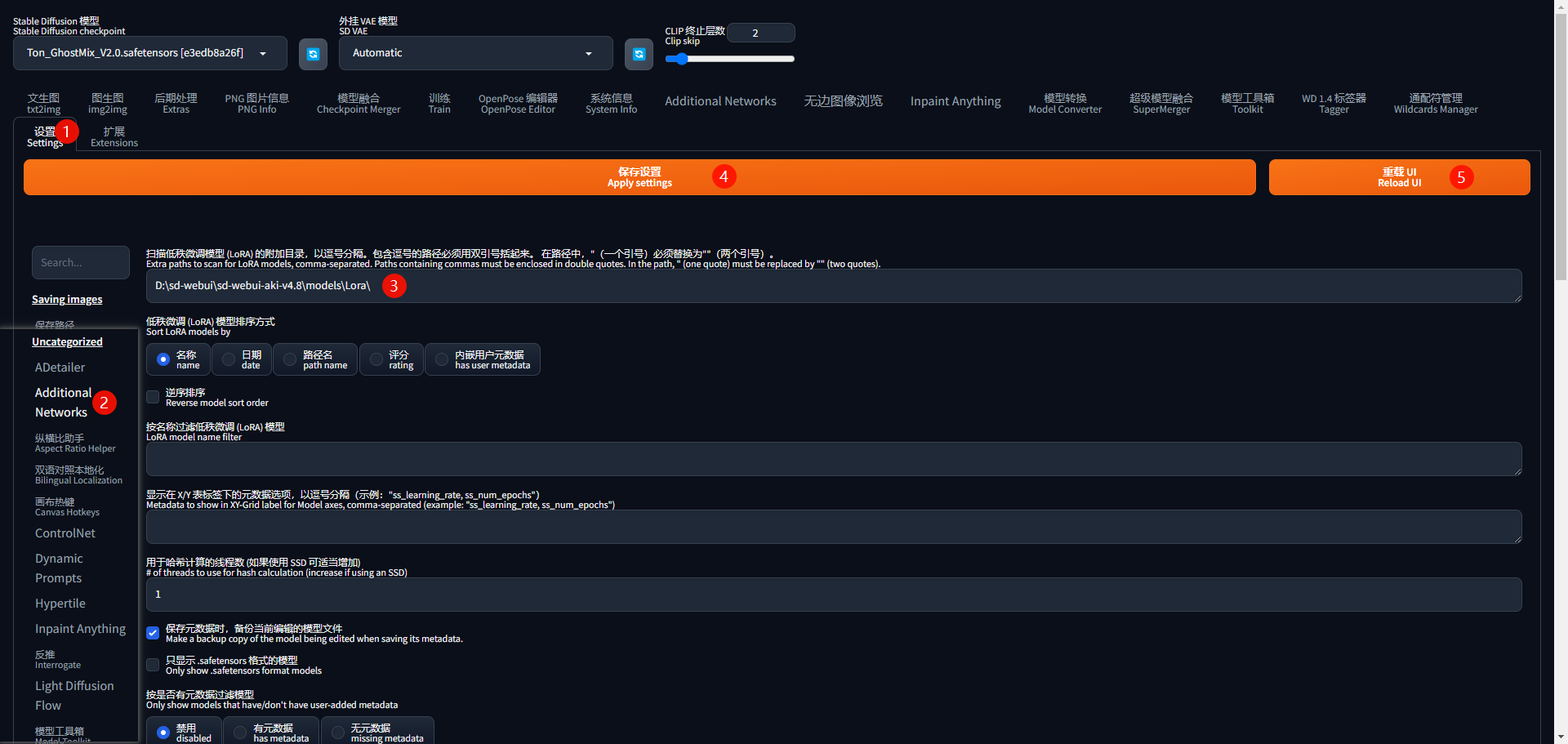
再返回「文生图---Addition Networks」模块,点击「刷新模型列表」,在 模型 下拉选项中,就会更新显示目录中存放的所有 LoRA:
实操应用
还是上一篇文章的国潮插画提示词,去除 LoRA 提示词,启用「Addition Networks」,选择相同的2个 LoRA,设置对应权重:

生成图片如下:
今天先分享到这里~
开启实践: SD绘画 | 为你所做的学习过滤