数据模型是什么?简单来说,数据模型是用来组织和管理数据的一种方式。它为构建高效且可靠的信息系统提供了基础,不仅决定了如何存储和管理数据,还直接影响系统的性能和可扩展性。
想要建立一个良好的数据模型,设计时需要优先考虑数据的关系和规范化,避免出现数据冗余和不一致的问题,减少数据维护的难度。
正是基于这样的需求,袋鼠云数据资产平台中的数据模型提供了一种标准化建表的能力,可以对表名、字段名等信息进行标准化约束,并且支持批量解析模式(根据中文名批量解析字段)与建表语句模式进行快速的模型搭建。
下面是其界面功能展示,针对不同的数据源类型,可配置的字段属性与交互方式也不尽相同。 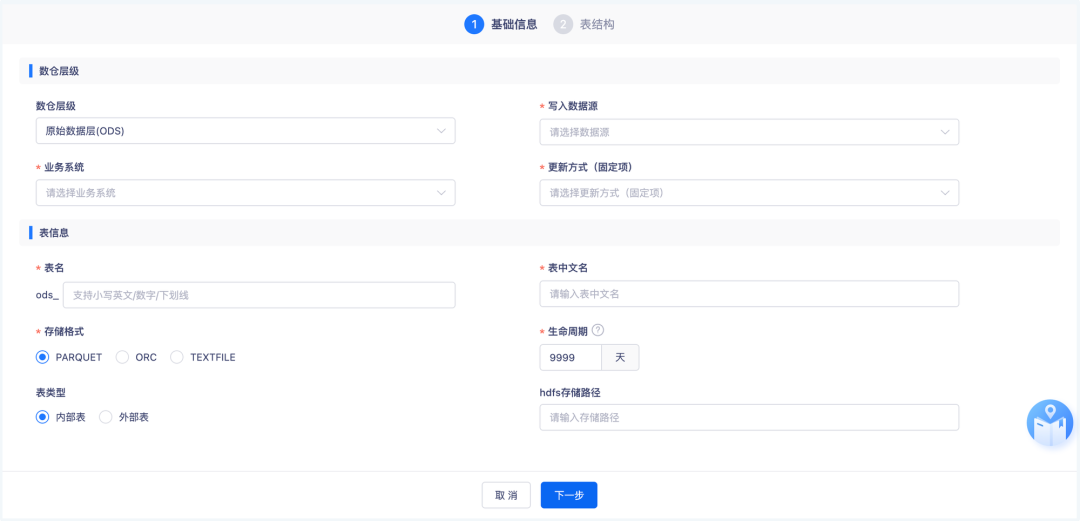
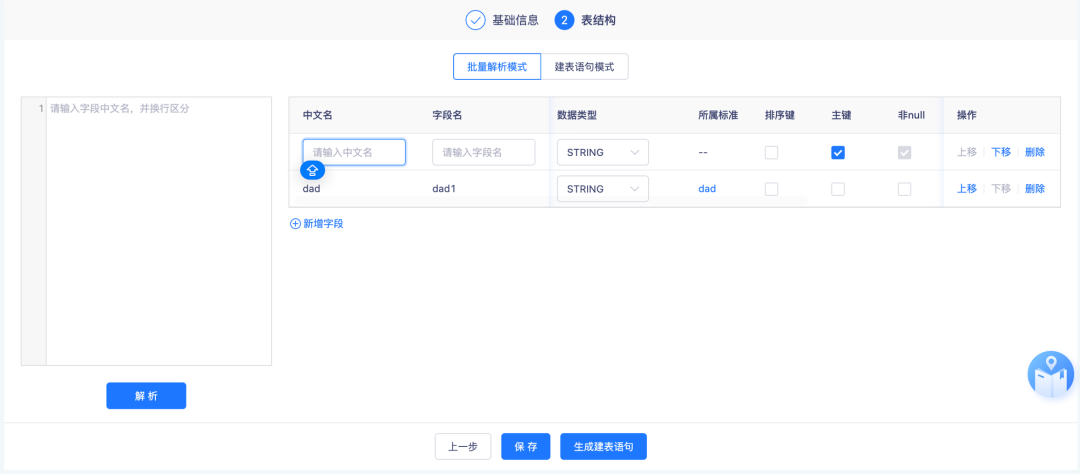
数据资产数据模型标准化建表一开始是只针对建Hive表的,但随着后续迭代改为数仓表后,会不断支持离线开发中的更多数据源类型。但由于历史代码书写原因,目前存在以下问题:
- 数据流管理混乱,未遵守单向数据流原则,导致常常出现页面展示与实际提交数据不一致的情况;
- 表单完全受控,性能问题显著,当字段数达到30+时,表单总数来到300+,输入型表单明显掉帧;
- 迭代中加入的字段间交互越来越多,没法解决表单间交互依赖问题;
- 代码维护成本过高,工时评估普遍偏长;
- 不同数据源类型交互、字段差异性管理,需要维护的枚举会越来越多,需要统一管理。
为了更好地满足客户需求,提升用户体验,袋鼠云数栈UED团队根据政策导向、市场环境、行业趋势和用户反馈,对数据资产平台的数据模型标准化建表资产源代码进行了重构升级。
架构设计
标准化建表主要分为两个部分,表基本信息配置与字段结构配置。针对以上痛点问题,本次数据模型标准化建表的主要重构点为字段结构配置的以下四个方面。
- 数据流 数据流管理是 React 前端开发流程中最重要的一环之一,良好的数据流管理,能使组件之间进行高效的状态共享,状态变化溯源与提高代码可维护性。 数据模型数据流目前的情况:
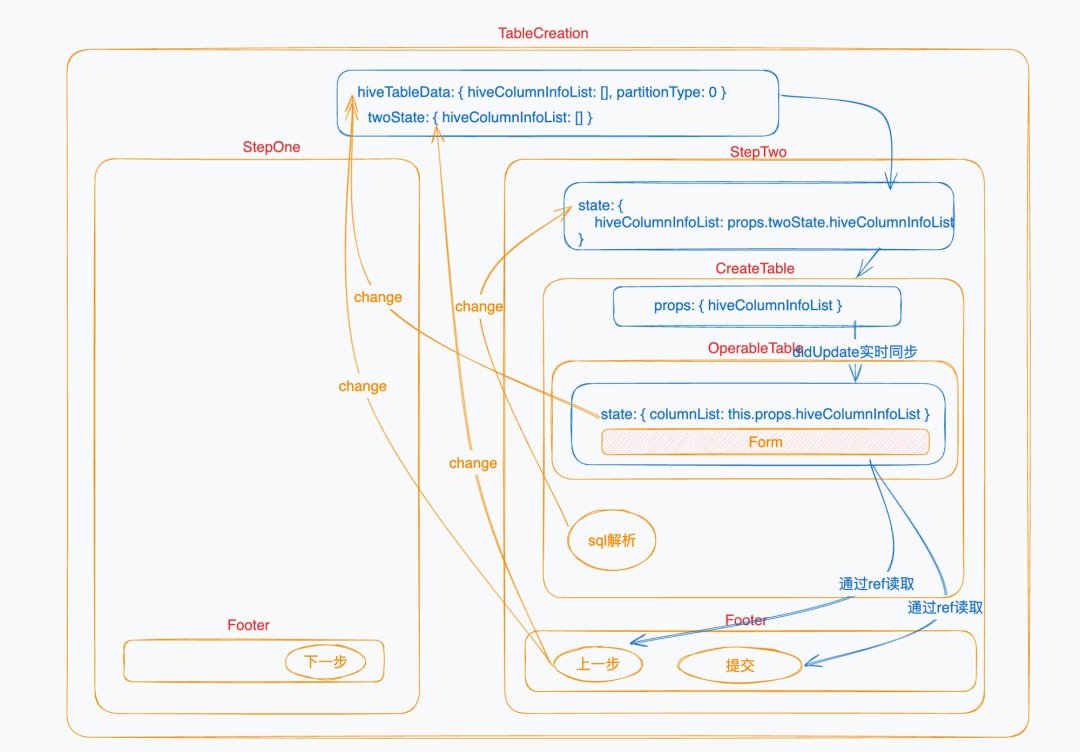
可以看出原始代码中的数据流管理是非常混乱的,组件间状态随意共享,ref 跨多个层级的访问,其中为了能在进行步骤条切换时仍能保留状态信息,还在最外层组件保留了每个步骤组件的状态信息。 我们重新设计组件的嵌套结构,与状态存储的方式,使其符合单一数据源与单向数据流基本原则。 重构后数据流图如下,引入了Context层来精简数据流。 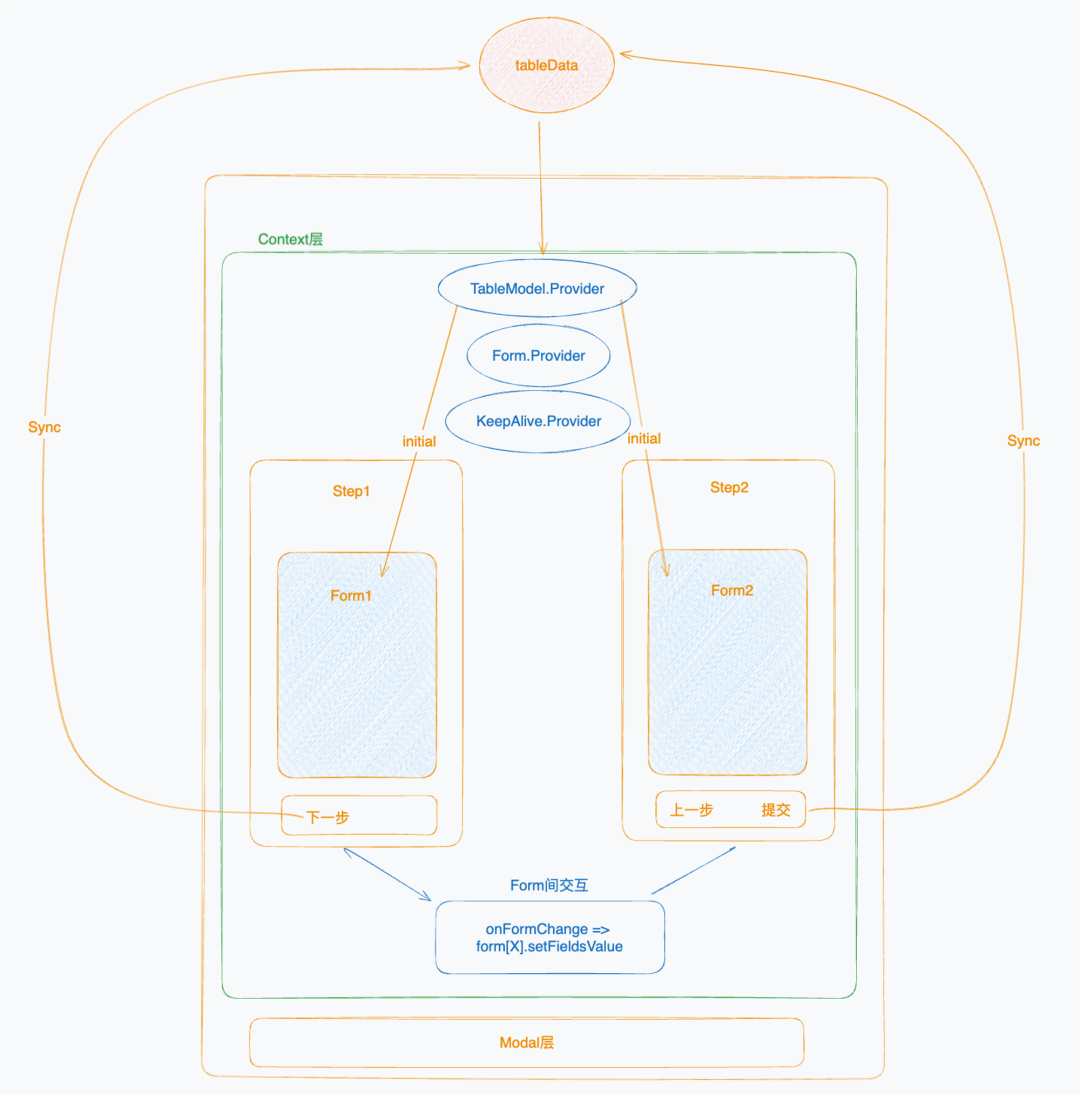
- Context层
最外层组件维护 tableData数据源来保存表单数据,通过 TableModel.ProviderContext来向所有子组件共享该数据源,避免 Props 传递过深。 Form.Provider为 antd提供的表单间交互方式,目前 Step1 与 Step2 之间的交互并不多,主要是切换数据源类型时将 Step2 的数据清空,我们所有表单间交互都在外层组件中 onFormChange中去定义。 KeepAlive.Provider是用来缓存每个步骤组件实例的,我们无需再在步骤切换时缓存每个组件内的状态信息至父组件。KeepAlive功能由于 React 不支持,我们自行通过 Suspense实现。
- Form层
原来的 Form组件的作用仅仅是用来做表单校验,实际又用了 state 去做数据收集,带来了严重的数据不一致问题,所以重构后完全采用 Form进行数据收集。 实现FormList FormList用于实现第二步的可编辑表格功能,其使用方式与 antd 的 Form.List基本相同,但我们采用自己实现的 FormList组件。 为何不直接使用 antd 的 Form.List ? Form.List会给其内部所有的表单项拼接上 List 字段名,如 "columnInfoList", 0, "columnType" ,但诸如分区字段类型,分区详细信息是与 columnInfoList字段同级的,没法在 Form.List中定义绑定在全局的字段。 FormList中自行实现增、删、移动等基本功能,比较 Array 来判断是否要重新渲染,每个 item 项可自行决定是否拼接 List 前缀 ...field.fieldName, "columnType", 并通过 Context的方式向子组件传递 List 字段名 使用方式: {(fields, operation) => ( <>
<Button
onClick={() =>
operation.add({
isPartition: true,
isAdd: true,
})
}
>
新增
</Button>
</>
)}Form视图依赖处理 由于 Form 的局部渲染机制,只对改变的字段进行渲染,所以为了简化表单项依赖代码,封装两个组件方便定义重新渲染时机。 数据模型中一个表单项是否需要重新渲染有三种情况: list 中当前行的依赖的字段值改变了才 rerender, 比如当前行勾选主键则禁用当前行的非null列。 list 所有行中某个依赖的字段值改变了都 rerender, 比如勾选了其中一个分区字段,其他所有行的分区字段列都禁用掉,都需要进行一次 rerender。
Form 层级中的表单项改变了需要进行 rerender。 针对第1、2种情况,封装 FormListDependency, 传入 index表示依赖的具体行,deps表示依赖的字段名。 deps如果是 "fieldA"的形式则是上述第一种情况 , 如果是 "$list", "fieldA"则是第二种情况。 一个例子:只允许一列为主键,勾选后其他所有主键列禁用, 且与当前列的分区字段互斥。 主键列的定义实现代码如下: <FormListDependency index={index} deps={'isPartition', \['$list', 'pk']}> {(record, columnInfoList) => { const pkIndex = columnInfoList.findIndex((item) => item.pk); const disabled = pkIndex !== -1 && pkIndex !== index || record.isPartition; return ( <FormItem name={...field.fieldName, 'pk'} initialValue={false} valuePropName="checked" > ); }}
针对第3种情况,封装 FormDependency 组件,使用方式同 FormListDependency,不需要额外传入下标参数。 注意:对于动态列,即可能展示或者隐藏的列,都需要在对应FormItem上加上preserve=false ,如选择了 VARCHAR 字段类型,会自动设置 dataLength ,但切换成其他类型,就应该清除 dataLength ,这也是完全采用 Form 管控的一个很大的好处,无需再关心动态列的脏数据问题。 至此,视图层的依赖我们已经解决,下面我们需要处理逻辑数据层的交互依赖。
- 交互依赖联动
选中某个字段后,自动设置关联的另外一个字段的值,这种交互在数据模型中会很多。依赖具有传递性,如依赖为A ⇒ B ⇒ C,如果使用以前的方法,我们通常会在A表单项 onChange时手动改变 B 和 C ,但其实 C 是与 B 才是直接关联的,我们可能会考虑不到还要同步设置 C 的值。 参考 Formily 的设计, 依赖可分为主动模式和被动模式 。 主动模式就是类似于 onChange时主动去处理其依赖项的数据变动,优点:更符合开发习惯且更加灵活。 被动模式就是监听某个字段,字段变化时处理自身数据变动,优点:字段依赖显式声明,更清楚的表示依赖关系。 由于我们是列表型表单,如果是使用被动模式,当出现 A 列变更后,所有行的 B 列同步修改这种1对N依赖情况,需要对所有行的 B 列添加 A 依赖,那么当 A 变化时,所有行的 B 列添加的监听回调会执行N次,如果采用主动模式,则只需要在一次监听回调中修改所有行即可。因此,我们采用主动模式。 实现 useFormListReactions 封装一个hooks useFormListReactions 来做依赖管理。 我们需要预先定义字段与该字段改变时的 effect, 当触发字段改变时,会传递当前字段改变后的值,字段在列表中的下标,该行的完整值,表单的完整值,set 方法等。 在进行依赖注册时,如果字段是全局字段,非 List 中的某一项,则可以添加 isExternalField=true,在 effect中只需要设置直接依赖项的值即可。 const { notify } = useFormListReactions( { fieldName: 'dataType', effect(field, { index, item, allFieldsValue }, { setColumnFieldsValue }) { field === 'VARCHAR' \&\& setColumnFieldsValue(index, { isPartition: 1 }); }, }, { fieldName: 'partitionType', isExternalField: true, effect(_field, _values, { setFieldValue }) { setFieldValue('xx', xx) }, }, , { form, formListName: 'columnInfoList' } ); 正常情况下,在 Form 的onValuesChange中能监听到用户手动交互时改变的字段,像 setFieldValue 等手动修改情况无法监听到,所以需要对 Form 原生的 set 方法进行一层包装,统一使用包装后的 set 方法我们才能完全监听表单变化。 我们侵入 onValuesChange 中,并使用 hooks 返回的 notify 方法进行消息通知。 <Form form={form} name="tableStructInfo" onValuesChange={(changedValue) => { // columnInfoList.3.dataType => 'columnInfoList', 4, 'xxx' const namePath = getObjectNamePath(changedValue); // 具体的值 const fieldValue = getChangedValueByNamePath(changedValue, namePath); notify(namePath, fieldValue); }}
hooks 中提供三种 set 方法, setFieldValue与 setFieldsValue与 Form 的完全一致,setColumnFieldsValue用于修改 List 中某行的值。 const setFieldValue = (name: NamePath, value: any) => { const oldValue = form.getFieldValue(name);
form.setFieldValue(name, value);
if (checkValueChanged(oldValue, value)) notify(name, value);};
const setFieldsValue = (values) => { const namePaths = Object.keys(values); const oldValues = form.getFieldsValue(namePaths);
form.setFieldsValue(values);
namePaths.forEach((namePath) => {
if (checkValueChanged(oldValues[namePath], values[namePath])) {
notify(namePath, values[namePath]);
}
});};
const setColumnFieldsValue = (columnIndex, fieldsValue) => { const updateFieldNames = Object.keys(fieldsValue); const notifyList = \[\]; // 批处理完所有setFieldValue后再进行notify, 否则在effect中拿到的其他字段值不是最新的 updateFieldNames.forEach((fieldName) => { const name = formListName, columnIndex, fieldName; const oldValue = form.getFieldValue(name);
const newValue = fieldsValuefieldName; form.setFieldValue(name, newValue); if (checkValueChanged(oldValue, newValue)) { notifyList.push(notify.bind(this, name, newValue)) } }); while(notifyList.length) { const cb = notifyList.pop(); cb(); } }; 所有交互产生的副作用我们都通过 useFormListReactions 进行管理,它能够自行处理依赖传递行为,且声明式管理使字段变更后可以很方便的进行溯源。 图片 性能优化
为了提升客户使用过程中的交互体验,优化产品性能表现,本次重构后我们完全采用 Form 做数据收集,能够做到足够精细化的局部渲染,相比重构前几十个字段输入框输入就卡顿严重,重构后在几百行字段数量级下表单输入不会造成非常明显的掉帧现象。
- 重写 inititalValue,减少初次渲染时 shouldUpdate 调用次数
antd 的按需渲染依赖于 shouldUpdate,假如我们有300行数据,每行有三列字段设置了依赖,那每次表单变化都会触发300 * 3 = 900次 shouldUpdate的执行,这点是没法避免的。 数据模型的动态表单会在该表单上设置 inititalValue, 当表单字段设置 inititalValue时会单独触发一次 storeChange, 导致执行900次 shouldUpdate。编辑时首次渲染,900个字段设置了 initialValue,那么shouldUpdate触发次数将达到 900 * 900 = 810000次,初次渲染会长时间的无反应。 
 且antd实现的Form.List也是不允许我们设置动态字段的initialValue的。 注意:Form.List 下的字段不应该配置initialValue ,你始终应该通过 Form.List 的initialValue或者 Form 的initialValue来配置。 在数据模型场景下 initialValue 尤为重要,所以我们需要自行实现 initialValue 逻辑,对 Form.Item 进行二次封装,代理掉默认的 initialValue 行为。 const FormItem = ({initialValue, ...restProps}) => { const form = Form.useFormInstance();
且antd实现的Form.List也是不允许我们设置动态字段的initialValue的。 注意:Form.List 下的字段不应该配置initialValue ,你始终应该通过 Form.List 的initialValue或者 Form 的initialValue来配置。 在数据模型场景下 initialValue 尤为重要,所以我们需要自行实现 initialValue 逻辑,对 Form.Item 进行二次封装,代理掉默认的 initialValue 行为。 const FormItem = ({initialValue, ...restProps}) => { const form = Form.useFormInstance();
useEffect(() => {
if (initialValue !== undefined) {
if (
restProps.name &&
form.getFieldValue(restProps.name) === undefined
) {
form.setFieldValue(restProps.name, initialValue);
}
}
}, []);
return <Form.Item {...restProps}/>} 替换所有 FormItem后,编辑时首次渲染 shouldUpdate调用次数降为1。
- 使用KeepAlive,减少切换步骤时的卡顿
以200行,每列11个字段的 StarRocks 为例: 未重构前切换步骤是直接销毁了整个组件,导致每次切换时都要重新生成新的节点,花费时间与首次挂载时一致非常长达到4s以上, FPS骤降至个位数。 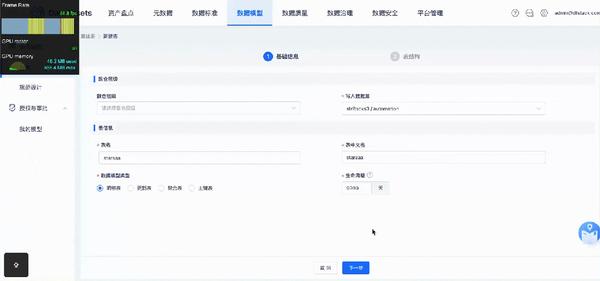
引入KeepAlive后,除首次渲染外,切换后FPS稳定在40以上,渲染完成时间基本在1s以内; 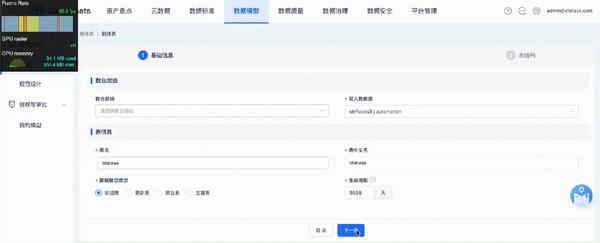
- 首次加载添加loading,保持正常FPS帧数
由于首次加载时需要渲染2000条 FormItem,其花费大量时间不可避免,当点击下一步时,会直接卡在当前步骤等待4s+直至表格渲染完成才会完成步骤切换, 给用户一种死机的感觉,用户体验非常不好。 首先为了能让点击下一步时立马响应用户操作,需要把表格数据初始化的操作设置为异步的,其次为避免长时间的表格空数据展示,添加 loading。 const initFormData = () => { setLoading(true); setTimeout(() => { const { partitionType, partitionVOList, columnInfoVOList, granularity } = tableData; form.setFieldsValue({ columnInfoVOList, partitionType, partitionVOList, granularity, }); setLoading(false); }, 0); }; 首次渲染会稍微慢些,但用户交互的及时响应对用户体验非常重要,几乎没有出现FPS掉帧现象。 
- 避免同时调用大量接口
当第一次挂载时,会直接请求当前列表中所有字段的匹配标准列表,如果200个字段,就直接发送200个请求。 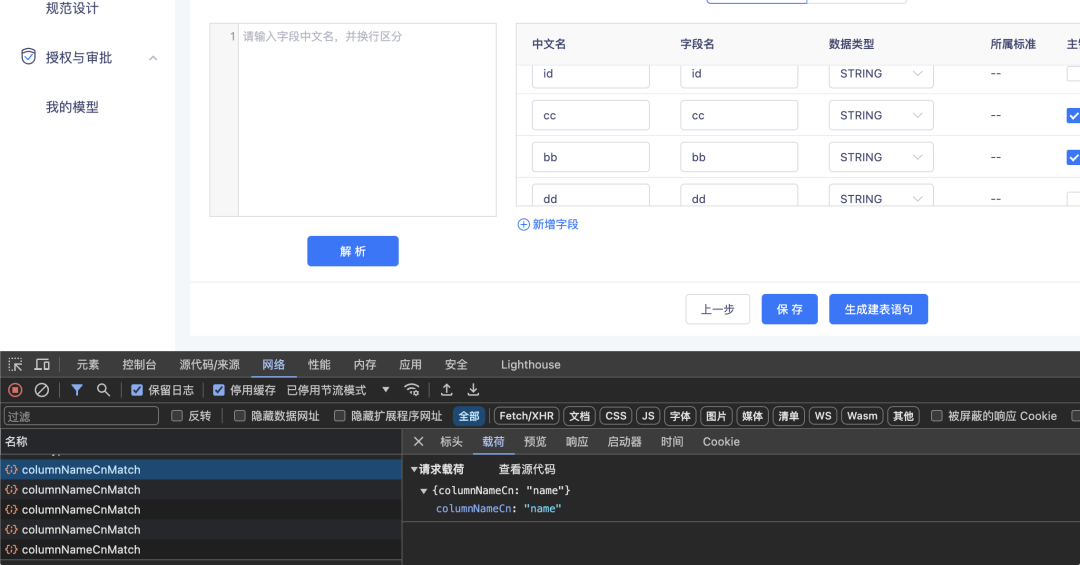 优化后: 仅在当前表单 Focus 且未缓存任何数据时才去请求接口, 忽略无用接口请求,加入防抖。 <AutoComplete value={value} onChange={onChange} onSelect={onSelect} onFocus={() => { if (!matchFieldData?.length) getMatchFieldData(value); }} /> const getMatchFieldData = (columnNameCn: string) => { if (!columnNameCn) { setMatchFieldData(\[\]) return } const requestId = Symbol('requestId'); lastRequestIdRef.current = requestId; API.columnNameCnMatch({ columnNameCn }).then((res: any) => { if (res.success) { requestId === lastRequestIdRef.current && setMatchFieldData(res.data || \[\]); } }); }; const debounceGetMatchFieldData = useDebounce(getMatchFieldData, 300); 5. Table复用Cell
优化后: 仅在当前表单 Focus 且未缓存任何数据时才去请求接口, 忽略无用接口请求,加入防抖。 <AutoComplete value={value} onChange={onChange} onSelect={onSelect} onFocus={() => { if (!matchFieldData?.length) getMatchFieldData(value); }} /> const getMatchFieldData = (columnNameCn: string) => { if (!columnNameCn) { setMatchFieldData(\[\]) return } const requestId = Symbol('requestId'); lastRequestIdRef.current = requestId; API.columnNameCnMatch({ columnNameCn }).then((res: any) => { if (res.success) { requestId === lastRequestIdRef.current && setMatchFieldData(res.data || \[\]); } }); }; const debounceGetMatchFieldData = useDebounce(getMatchFieldData, 300); 5. Table复用Cell
由于 table组件的 columns如果添加了 render 自定义渲染, 那么每次父组件的 render ,会造成所有 Cell 进行 rerender,我们需要添加 shouldCellUpdate属性进行 Cell 的缓存。 目前表格表单中依赖的外部状态只有 columnTypeList字段类型的下拉列表,那么 Cell 是否需要刷新仅在字段的顺序变更,删除时需要重新进行 FormItem的注册。 那么我们可以以当前字段的 key 和位置是否变化来决定是否要重新渲染。 <Table columns={getColumns() .map((item) => { return { ...item, shouldCellUpdate: (prev: any, curr: any) => prev.key !== curr.key || prev.index !== curr.index || item.shouldCellUpdate?.(prev, curr), }; })} /> 针对需要消费 columnTypeList 状态的列,自行实现 shouldCellUdpdate, 通过 usePreviousState来实现比较 columnTypeList 是否变化。 { title: '字段类型', key: 'columnType', shouldCellUpdate: () => columnTypeList !== prevColumnTypeListRef.current, }
总结
袋鼠云数栈UED团队以数据流重构为基本出发点,对组件进行重新设计与组装,使数据模型可维护性与可拓展性大大提升。通过统一依赖管理,使复杂的表单交互逻辑祛繁就简,可溯源、易管理。并且,通过大量的技术手段,优化了性能表现,提升了用户交互体验。 对数据资产平台感兴趣的朋友,可以点击文末的阅读原文进行免费产品试用。 《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057?src=szsm
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szcsdn