按照往常我们的想法transformer,Bert等模型都只能用来做NLP的问题,很少有人能去想做CV的问题,但是Vit的出现,打破了常规的认识,让我们知道了其实NLP和CV是没有界限的,只是技术的落后,把我们的想法限制住了。
BERT模型的提出是用来做NLP的,通过BERT模型可以学习句子的语义,当然BERT的模型调用,输出有两个一个就是语义向量,另一个就是句子中所有token向量,那么语义向量是怎么表示的呢?BERT在进行句子编码时,会自动在句子头部添加CLS,注意这个是不用我们自己添加的,CLS所表示的向量是整个句子的语义向量,很神奇吧!
那么在使用transformer怎么处理图片呢?或者怎么做目标检测的任务呢?
我们可以把图片进行分割,那么每一个图片的像素点其实可以看做是像素矩阵,在通过encoder进行权重计算时可以形成该图像切片对应的向量(比如像素矩阵128*400乘以权重向量400*1,则变为了图像切片向量),当然该切片只表示原图片的一部分,我们可以使用position向量代表切片在原图片中的位置,将两个向量拼接(对应位置加运算)形成一个新等我向量作为切片向量。那么切片对应了token(单词),图片应该对应句子了吧!句子有语义向量,那应该不止切片有向量,图片也应该有吧,没错下图0号位置表示的就是图片向量,和CLS很相似。
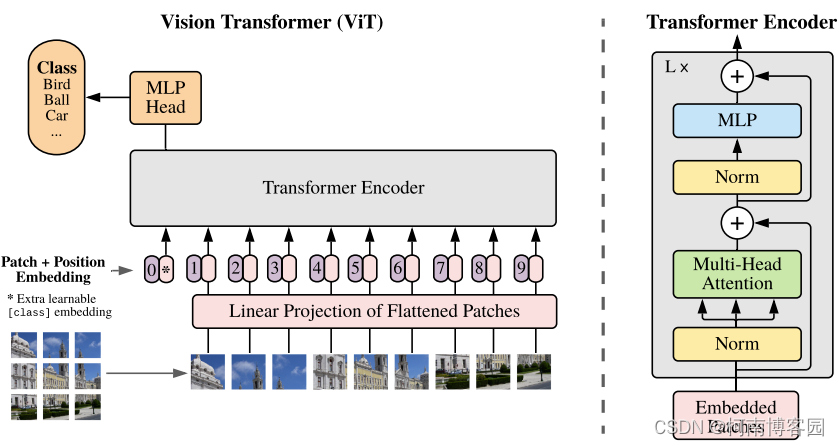
所以NLP的问题解决方案也可以推广到CV