官方框架:
https://github.com/ultralytics/ultralytics
yolov8官方最近推出yolov11框架,标志着目标检测又多了一个检测利器,于是尝试在windows下部署yolov11的tensorrt模型,并最终成功。
重要说明:安装环境视为最基础操作,博文不做环境具体步骤,可以百度查询对应安装步骤即可。
测试通过环境:
vs2019
windows 10 RTX2070 8G显存
cmake==3.24.3
cuda11.7.1+cudnn8.8.0
Tensorrt==8.6.1.6
opencv==4.8.0
anaconda3+python3.8
torch==1.9.0+cu111
ultralytics==8.3.3
部署过程:
部署最费时间是安装环境。首先确保自己电脑是win10或者win11并确保电脑有一块nvidia显卡。查看自己显卡就是打开任务管理器(win10是ctrl+alt+delete,win11是ctrl+shift+ESC),在性能里面查看,如下图
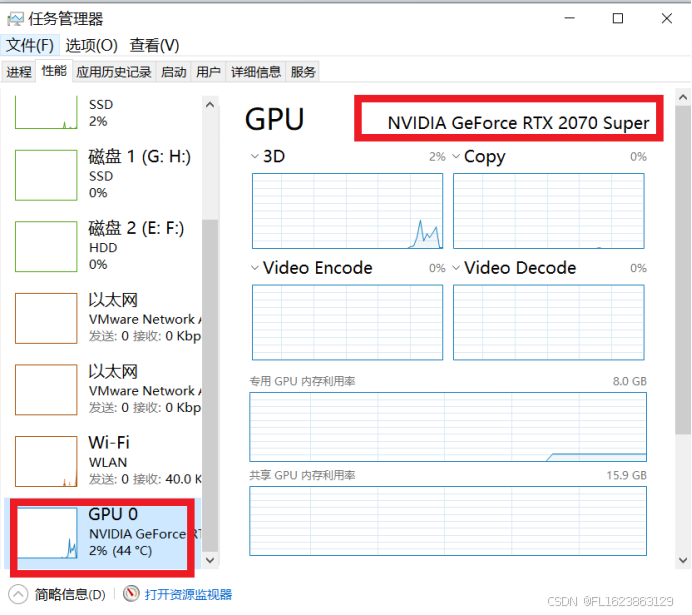
如果看到GPU0和GPU1等等表示有显卡,但是需要看到NVIDIA字样才能表示有独立显卡。其他是AMD显卡或者核心显卡,这些都是不能用于cuda的,也就是电脑不支持tensorrt加速和cuda使用的。
首先需要大家安装好VS2019或者VS2022,还有如下环境,由于安装包很多需要去官方搜索下载,需要自己安装,其中版本可以有区别,但是如果快速复现这个项目,最好安装位一致版本这样更快复现出项目。
cmake==3.24.3
cuda11.7.1+cudnn8.8.0
Tensorrt==8.6.1.6
opencv==4.8.0
anaconda3+python3.8
torch==1.9.0+cu111
假设大家安装好上面的环境。下面具体怎么部署,首先去yolov8官方仓库下载yolo11模型,这样下载yolo11n.pt
https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt
然后将pt模型放进项目里面,切换自己安装好的yolov8环境里面并切换到项目目录,执行python export.py即可转换得到onnx模型,当然你也可以使用下面命令直接转换
yolo export model=yolo11n.pt format=onnx dynamic=False opset=12
得到onnx模型以后我们开始编译源码。
首先我们修改CMakeLists.txt文件,将源码里面opencv路径和tensorrt路径修改成自己路径
Find and include OpenCV
set(OpenCV_DIR "D:\\lufiles\\opencv480\\build\\x64\\vc16\\lib")
Set TensorRT path if not set in environment variables
set(TENSORRT_DIR "D:\\lufiles\\TensorRT-8.6.1.6")
然后执行
mkdir build
cd build
cmake ..
之后去build文件夹找到sln文件用vs打开它
然后选择x64 release,并选中ALL_BUILD右键单击选择生成
之后build\Release文件夹下面有个yolov11-tensorrt.exe生成。之后我们开始转换onnx模型到tensorrt模型,执行命令
trtexec --onnx=yolo11n.onnx --saveEngine=yolov10n.engine --fp16
稍等20多分钟后会自动生成yolo11n.engine文件,我们将yolo11n.engine复制到build\Release文件夹
下面我们开始测试图片
yolov11-tensorrt.exe yolo11n.engine "test.jpg"
然后测试视频
yolov11-tensorrt.exe yolo11n.engine "car.mp4"
特别注意:
- tensorrt模型依赖于硬件,所以不是通用的需要在电脑重新转换,否则可能无法使用;
- 如需要二次开发,需要读懂main.cpp代码,需要有一定c++基础才行,否则无法进行二次开发。
完整源码下载: