kafka的成神秘籍
kafka的简介
Kafka 最初是由Linkedin 即领英公司基于Scala和 Java语言开发的分布式消息发布-订阅系统,现已捐献给Apache软件基金会。Kafka 最被广为人知的是作为一个 消息队列(mq)系统存在,而事实上kafka已然成为一个流行的分布式流处理平台。其具有高吞吐、低延迟的特性,许多大数据处理系统比如storm、spark、flink等都能很好地与之集成。按照Wikipedia上的说法,kafka的核心数据结构本质上是一个"按照分布式事务日志架构的大规模发布/订阅消息队列"。总的来讲,kafka通常具有3重角色:
消息系统
Kafka和传统的消息队列比如RabbitMQ、RocketMQ、ActiveMQ类似,支持流量削锋、服务解耦、异步通信等核心功能。
流处理平台
Kafka 不仅能够与大多数流式计算框架完美整合,并且自身也提供了一个完整的流式处理库,即kafka Streaming。kafka Streaming提供了类似Flink中的窗口、聚合、变换、连接等功能。
存储系统
通常消息队列会把消息持久化到磁盘,防止消息丢失,保证消息可靠性。Kafka的消息持久化机制和多副本机制使其能够作为通用数据存储系统来使用
一句话概括:Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),在业界主要应用于大数据实时处理领域。
kafka体系结构
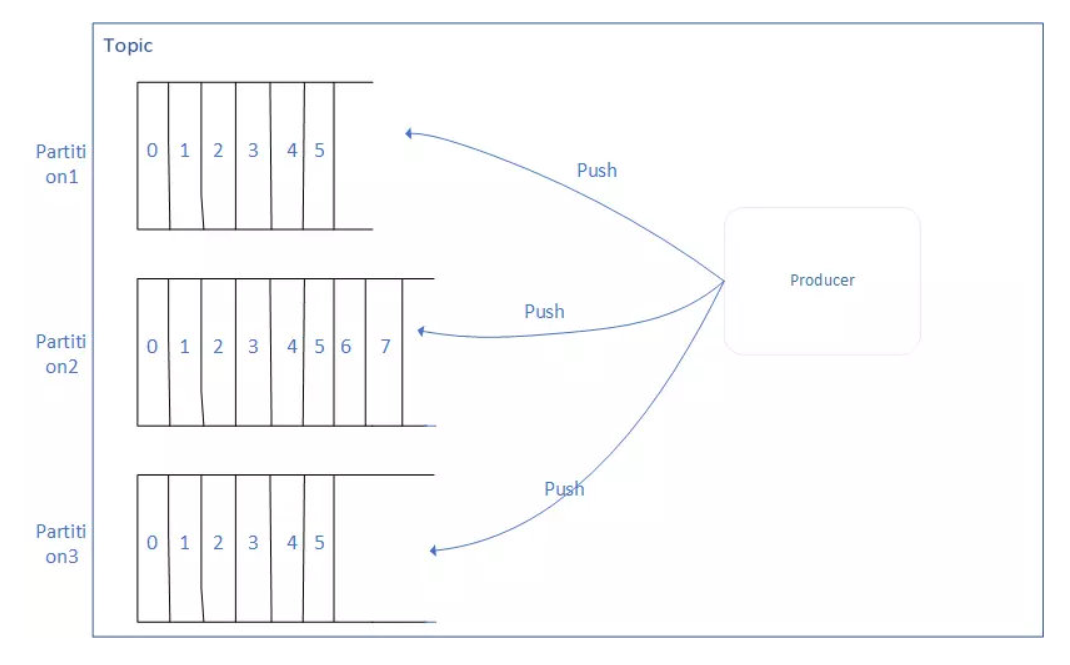
Topic(主题)
- 适用于存储消息的逻辑概念,1个Topic,可以看做是消息的集合。
- 这个消息的集合(Topic),可以接收多个生产者(Producer)推送(Push)过来的消息,也可以让多个消费者(Consumer)从中消费(Pull)消息。
分区(Partition)
-
分区的概念,可以理解为Topic的子集:1个Topic可能只有1个分区,也可能有多个分区。这里说的多个分区,一个分区就代表磁盘的一块连续的位置,不同的分区也就是磁盘上不同的区域块。
-
分区存在的意义:
通过不同的区域块,kafka存储在Topic里的消息就可以在多个地方存储,也就是对kafka进行了水平扩展,这样可以增加kafka的 并行处理能力。
- 对于不同分区的理解
同一个Topic下,多个区域块,这些不同的区域块,存储的消息是不同的,也就是说,A、B两个区域块,不会同时存储1类消 息。
-
对于同一个分区中的消息:
在区块A中接收到消息时,该消息会接收它在这块区域块A中的Offset(唯一编号),这个Offset使得kafka确定了消息在区域块中的顺序。(这样就保证了磁盘的顺序读写,减少磁盘IO)
Log
-
分区在逻辑上,对应一个Log,当生产者将消息写入分区的时候,实际上就是写入一个log。
-
Log:一个逻辑概念,对应着磁盘上的一个文件夹。
-
Log的组成:由多个Segment组成,每1个Segment对应1个日志文件和一个索引文件。
Broker
区域块A会给他接收的消息分配一个offset,并且x会保存到A所在的磁盘区域上。而这个功能,就是由Broker完成的。
-
Broker:1个Broker就是一个单独的kafka server。
-
Broker的主要工作:接收生产者发送来的消息,分配offset,然后将包装过的数据保存到磁盘上。
-
Broker的其他作用:接收消费者Consumer和其他Broker的请求,根据请求的类型进行相应的处理然后返回响应。
-
这里引出集群(Cluster)的概念,1个Cluster是由多个Broker构成的,也就是说,1个Broker不会对外提供服务,而是通过Cluster的形式对外提供服务:
因为,一个Cluster里,需要1个Broker担任Controller,这个Broker就是这个集群的指挥中心,负责:
- 管理各个分区(Partition)的状态;
- 管理每个分区(Partition)的副本的状态;
- 监听zookeeper的数据变化。
其他的Broker均是通过这个Controller进行指挥的,完成各自相应的功能。
关于Cluster的一主多从实现:
除了担任Controller的Broker会监听其他Broker的状态,其他Broker也会监听Controller的状态,当Controller出翔了故障,就会重新选取新的Broker担任Controller
消息
kafka中最基本的消息单元。有一串字节组成,主要由key和value构成(即key、value都是字节数组)
- key:主要作用是 根据一定策略,将这个消息路由到制定分区中 ==> 这样就保障了,包含同一个key的消息全部写入一个分区A,不会写入另外一个分区。(即实现了Partition分区中提到的"不同分区存储的消息是不一样的")
副本
kafka会对消息进行冗余备份,每一个分区Partition,都可以有多个副本(每一个副本包含的消息是相同的,但是不能保证同一时刻下完全相同)。
副本类型:Leader、Follower。
副本选举策略(即选举1个Leader,其余为Follower):
- 当分区只有1个副本,这个副本就是Leader,没有Follower。
- 在其他不同场景,会采取不同的选举策略。
- Leader:处理kafka中所有的读写请求
- Follower:仅仅把数据从Leader中拉取到本地,同步更新到自己的Log中。
生产者
产生消息的对象,产生消息之后,将消息按照一定的规则推送到Topic的分区中
消费者
从Topic中拉取消息,并对消息进行消费。
- Consumer:有一个作用,维护它消费到分区(Partition)上的什么位置(即offset的值)。
- Consumer Group: 在kafka中,多个Consumer可以组成1个Consumer Group,1个Consumer只属于1个Consumer Group.
Consumer Group的作用:保证了这个Consumer Group订阅的Topic(Partition的集合)中的每一个分区(Partition),只被Consumer Group中的一个Consumer处理。
当然,如果要实现消息的广播消费,则将同1条消息放在多个不同的Consumer Group中即可。
就上述这个Consumer和Partition的关系可以理解下面的说法:
通过向Consumer Group中动态添加适量的Consumer, 可以触发kafka的Rebalance操作(重新分配Partition和Consumer的一一对应关系,结合Topic部分的理解,这样就实现了kafka的水平扩展能力)。
kafka的安装与使用
安装
本文采用docker安装需要确定linux主机上是否有docker环境
docker -v

拉取zookeeper镜像与kafka镜像
#拉取zookeeper镜像
docker pull zookeeper
#拉取kafka镜像
docker pull wurstmeister/kafka
运行zookeeper
docker run --restart=always -d -p 2181:2181 --name zookeeper zookeeper
#-restart=always 停机不断重启
#-p 2181:2181 docker容器端口映射到主机的端口
运行kafka
docker run --restart=always -d --name kafka -p 19092:19092 -e KAFKA_ZOOKEEPER_CONNECT=localhost:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:19092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:19092 -e KAFKA_PORT=19092 wurstmeister/kafka
#KAFKA_ZOOKEEPER_CONNECT=localhost:2181 需要注册的 zookeeper的ip和端口
创建topic
- 进入容器目录
docker exec -it kafka bash - 执行创建topic命令
sh /opt/kafka_2.13-2.8.1/bin/kafka-topics.sh --create --bootstrap-server 127.0.0.1:19092 --replication-factor 1 --partitions 1 --topic data-transform

使用(java)
添加项目依赖
java
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>编写配置文件
yaml
spring:
kafka:
bootstrap-servers: localhost:9092
# 消费者
consumer:
#分组id
group-id: my-group
# 从一次消费过信息的下一条开始消费
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 配置kafka的信息的生产者
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
template:
# 默认的消费主题
default-topic: data-transform生产者
java
@Component
@Slf4j
public class DataProductService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public final static String TOPIC = "data-transform";
public void sendDataMessage(String message){
log.info("生产者生产数据开始:", DateUtils.format(new Date()),"yyyyMMdd HH:mm:ss");
kafkaTemplate.send(TOPIC, message).completable()
.whenComplete((result, ex) -> {
if (ex == null) {
RecordMetadata metadata = result.getRecordMetadata();
log.info("生产者生产数据成功:,数据为:{}",metadata);
} else {
log.error("生产者生产数据失败:", ex);
}
});
}
}消费者
/**
* @Description:
* @author:<a href="2358853434@qq.com"></a> zh
* @Create : 2024/10/2
**/
@Component
@Slf4j
public class DataConsumerService {
@KafkaListener(topics = DataProductService.TOPIC,groupId = "my-group")
public void ConsumerData(String message){
log.info("消费者消费数据,数据为:{}",message);
}
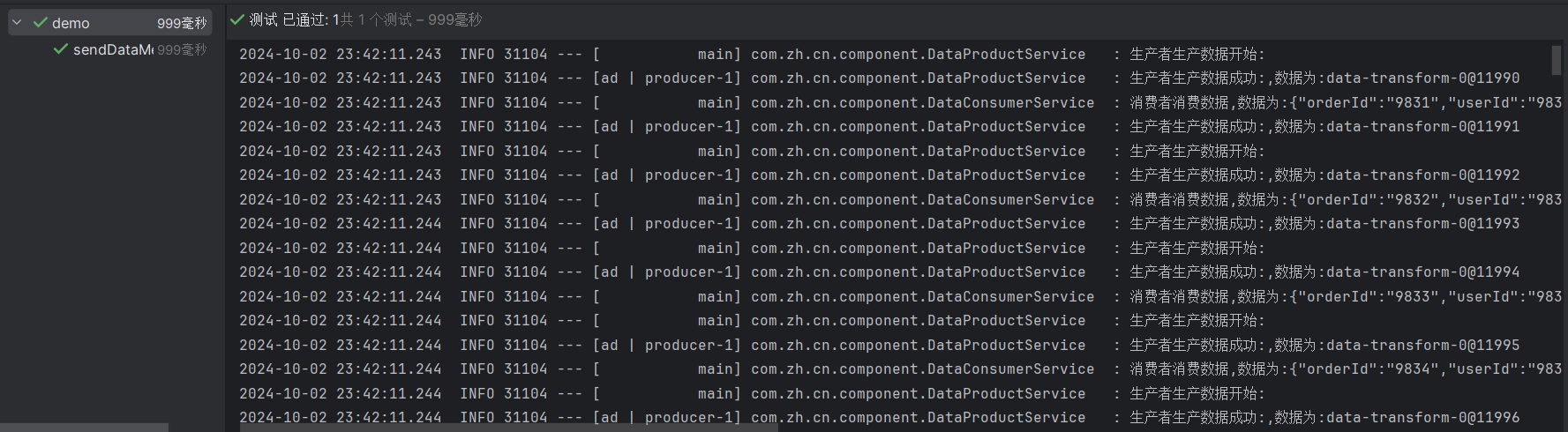
}测试用例
java
@SpringBootTest(classes = application.class)
public class demo {
@Resource
DataProductService dataProductService;
@Resource
DataConsumerService dataConsumerService;
@Test
public void sendDataMessage(){
long l = System.currentTimeMillis();
//模拟电商下单信息推送
for (int i = 1000; i < 10001; i++) {
String message = "{\"orderId\":\""+i+"\",\"userId\":\""+i+"\",\"productId\":\""+i+"\",\"productName\":\""+i+"\",\"productPrice\":\""+i+"\"}";
dataProductService.sendDataMessage(message);
dataConsumerService.ConsumerData(message);
}
System.out.println(System.currentTimeMillis()-l);
}
}结果