
用于小样本分类的交叉注意力网络
引用:Hou, Ruibing, et al. "Cross attention network for few-shot classification." Advances in neural information processing systems 32 (2019).
论文地址:下载地址
论文代码:https://github.com/blue-blue272/fewshot-CAN
Abstract
少样本分类旨在仅给出少量标记样本的情况下,识别来自未见过类别的未标记样本。未见类别和数据不足的问题使得少样本分类极具挑战性。许多现有的方法分别从标记和未标记样本中提取特征,导致特征的区分性不足。在本工作中,我们提出了一种新颖的交叉注意力网络,以解决少样本分类中的挑战性问题。首先,提出了交叉注意力模块来应对未见类别的问题。该模块为每对类别特征和查询样本特征生成交叉注意力图,以突出目标对象区域,从而使提取的特征更具区分性。其次,我们提出了一种推理算法,以缓解数据不足的问题。该算法通过迭代地利用未标记的查询集来增强支持集,从而使类别特征更加具有代表性。在两个基准数据集上的大量实验表明,我们的方法是简单、高效且计算成本低的框架,并且优于当前最先进的方法。
1 Introduction
少样本分类旨在将未标记样本(查询集)分类到未见过的类别中,前提是只提供了极少量标记样本(支持集)。与传统分类相比,少样本分类面临两个主要挑战:一是未见过的类别,即训练和测试类别之间不重叠;二是数据不足的问题,即测试的未见类别只有极少量的标记样本。解决少样本分类问题需要模型在训练阶段的已知类别中进行训练,并能够在仅有少量标记样本的情况下对未见类别进行良好的泛化。
一种直接的方法是使用来自未见类别的少量标记样本对预训练模型进行微调,但这可能会导致严重的过拟合。正则化和数据增强能够缓解但不能完全解决过拟合问题。最近,元学习范式 [1](#1) [2](#2) [3](#3) 被广泛用于少样本学习。在元学习中,可迁移的元知识,例如一种优化策略 [4](#4) [5](#5),一种良好的初始条件 [6](#6) [7](#7) [8](#8),或一个度量空间 [9](#9) [10](#10) [11](#11),是从一组训练任务中提取的,并且能够泛化到新的测试任务。训练阶段的任务通常模拟测试阶段的设置,以缩小训练和测试设置之间的差距,并增强模型的泛化能力。
尽管已有一些很有前景的方法,但很少有方法充分关注提取特征的可区分性。它们通常独立地从支持类和未标记的查询样本中提取特征,导致这些特征的区分性不足。一方面,支持/查询集中的测试图像来自未见过的类别,因此它们的特征难以关注目标对象。具体来说,对于包含多个对象的测试图像,所提取的特征可能会关注训练集中具有大量标记样本的已见类别中的对象,而忽略来自未见类别的目标对象。如图1(c)和(d)所示,对于来自测试类别"窗帘"的两张图像,提取的特征仅捕获了与训练类别相关的对象信息,如图1(a)和(b)中的"人"或"椅子"。另一方面,数据不足的问题使得每个测试类别的特征不能代表真实的类别分布,因为它仅从少量标记的支持样本中获得。总而言之,独立的特征表示在少样本分类中可能会失效。

图1所示。现有方法[9](#图1所示。现有方法9和所提出方法的训练和测试图像的类激活图12的一个例子可以。颜色越暖值越高。)和所提出方法的训练和测试图像的类激活图[12](#图1所示。现有方法9和所提出方法的训练和测试图像的类激活图12的一个例子可以。颜色越暖值越高。)的一个例子可以。颜色越暖值越高。
在本工作中,我们提出了一种新颖的交叉注意力网络(Cross Attention Network, CAN)来增强少样本分类中特征的可区分性。首先,引入了交叉注意力模块(Cross Attention Module, CAM)来解决未见类别的问题。交叉注意力的思想来源于人类的少样本学习行为。给定少量标记样本来识别来自未见类别的样本时,人类倾向于首先定位标记和未标记样本对中最相关的区域。类似地,给定类别特征图和查询样本特征图,CAM 为每个特征生成一个交叉注意力图,以突出目标对象。相关性估计和元融合被用于实现这一目标。这样一来,测试样本中的目标对象可以得到关注,并且通过交叉注意力图加权的特征更具区分性。如图1(e)所示,带有 CAM 的提取特征能够大致定位目标对象"窗帘"的区域。
其次,我们提出了一种推理算法,利用整个未标记的查询集来缓解数据不足的问题。所提出的算法通过迭代地预测查询样本的标签,并选择伪标记的查询样本来增强支持集。每个类别中更多的支持样本能够使得获得的类别特征更加具有代表性,从而缓解数据不足的问题。
在多个基准数据集上进行了实验,将所提出的 CAN 与现有的少样本元学习方法进行了比较。我们的方法在所有数据集上都达到了新的最先进的结果,证明了 CAN 的有效性。
2 Related Work
2.1 少样本分类
根据整个未标记查询集的可用性,少样本分类可分为两类:归纳式少样本分类和传导式少样本分类。在本工作中,我们主要探讨基于元学习的少样本方法。
2.2 归纳式少样本学习
归纳式少样本学习在近年来得到了广泛的研究。一种有前途的方法是元学习 [1](#1) [2](#2) [3](#3) 范式。通常,它从一组任务中训练一个元学习器,以提取可迁移到新任务的元知识,使其能够应对稀缺数据的情况。用于少样本分类的元学习方法大致可以分为三类:基于优化的方法将元学习器设计为优化器,用于学习更新模型参数 [5](#5) [4](#4) [13](#13)。此外,研究 [6](#6) [14](#14) [15](#15) 学习了一个良好的初始条件,使学习器能够在少数优化步骤内快速适应新任务。基于参数生成的方法 [16](#16) [17](#17) [18](#18) [19](#19) 通常将元学习器设计为一个参数预测网络。基于度量学习的方法 [10](#10) [9](#9) [11](#11) [20](#20) [21](#21) 学习了一个通用特征空间,在该空间中基于距离度量可区分类别。
我们提出的框架属于基于度量学习的方法。与现有的度量学习方法独立提取支持样本和查询样本特征不同,我们的方法利用支持和查询特征之间的语义相关性来突出目标对象。尽管基于参数生成的方法也考虑了支持和查询样本之间的关系,但这些方法需要额外的复杂参数预测网络。我们的方法在较少的计算负担下,比这些方法取得了更大的提升。
2.3 传导式算法
传导式少样本分类首先由 [22](#22) 引入,该方法在支持集和整个查询集上构建了一个图,并在图中传播标签。然而,该方法需要一个特定的网络结构,通用性较差。受半监督学习中的自训练策略启发 [23](#23) [24](#24) [25](#25) [26](#26),我们提出了一种更简单且通用性更强的传导式少样本算法,该算法通过明确地使用未标记的查询样本来增强标记支持集,以获得更具代表性的类别特征。此外,所提出的传导式算法可以直接应用于现有的模型,例如 Prototypical Network [9](#9)、Matching Network [10](#10) 和 Relation Network [11](#11)。
2.4 注意力模型
注意力机制旨在突出重要的局部区域,以提取更具区分性的特征。在计算机视觉应用中取得了巨大的成功,如图像分类 [27](#27) [28](#28) [29](#29)、图像描述生成 [30](#30) [31](#31) [32](#32) 和视觉问答 [33](#33) [34](#34) [35](#35)。在图像分类中,SENet [27](#27) 提出了一种通道注意力模块,以增强网络的表示能力。Woo 等人 [28](#28) [29](#29) 进一步将通道和空间注意力模块集成到一个模块中。然而,这些模块对于少样本分类并不有效。我们认为它们仅基于训练类别的先验来定位测试图像中的重要区域,无法泛化到来自未见类别的测试图像。例如,如图1所示,由于"窗帘"不属于训练类别,上述模块将关注于已见类别的前景对象,如"人"或"椅子",而不是"窗帘"。
对于少样本图像分类,在本文中,我们设计了一个元学习器来计算支持(或类别)和查询特征图之间的交叉注意力,以帮助定位目标对象的关键区域,并增强特征的区分性。
3 Cross Attention Module
3.1 问题定义
少样本分类通常涉及训练集、支持集和查询集。训练集包含大量类别和标记样本。少样本的支持集和未标记样本的查询集共享相同的标签空间,并且与训练集的标签空间不重叠。少样本分类的目标是在给定训练集和支持集的情况下对未标记的查询样本进行分类。如果支持集包含 C C C 个类别且每个类别包含 K K K 个标记样本,那么该目标少样本问题称为 C C C-way K K K-shot。
参考文献 [10](#10) [9](#9) [36](#36) [37](#37) [38](#38) [39](#39) [6](#6),我们采用了"episode"训练机制,该机制被证明是少样本学习中的一种有效方法。训练过程中使用的每个"episode"模拟了测试时的设置。每个"episode"通过随机采样 C C C 个类别以及每个类别 K K K 个标记样本组成支持集 S = { ( x a s , y a s ) } a = 1 n s S = \{(x_{a}^s, y_{a}^s)\}{a=1}^{n_s} S={(xas,yas)}a=1ns(其中 n s = C × K n_s = C \times K ns=C×K),并从这 C C C 个类别中抽取一部分剩余样本组成查询集 Q = { ( x b q , y b q ) } b = 1 n q Q = \{(x{b}^q, y_{b}^q)\}{b=1}^{n_q} Q={(xbq,ybq)}b=1nq。我们将第 k k k 类的支持子集记作 S k S_k Sk。如何表示每个支持类别 S k S_k Sk 和查询样本 x b q x{b}^q xbq,以及测量它们之间的相似性,是少样本分类的关键问题。
3.2 CAM 概述
在本工作中,我们借助度量学习来获得支持类和查询样本对的合适特征表示。与现有独立提取类别和查询特征的方法不同,我们提出了交叉注意力模块(Cross Attention Module, CAM),它可以对类别特征和查询特征之间的语义相关性进行建模,从而突出目标对象,并有助于后续的匹配。
CAM 如图 2 所示。类别特征图 P k ∈ R c × h × w P_k \in \mathbb{R}^{c \times h \times w} Pk∈Rc×h×w 从支持集 S k S_k Sk 中提取( k ∈ { 1 , 2 , ... , C } k \in \{1, 2, \ldots, C\} k∈{1,2,...,C}),查询特征图 Q b ∈ R c × h × w Q_b \in \mathbb{R}^{c \times h \times w} Qb∈Rc×h×w 从查询样本 x b q x_b^q xbq 中提取( b ∈ { 1 , 2 , ... , n q } b \in \{1, 2, \ldots, n_q\} b∈{1,2,...,nq}),其中 c c c、 h h h 和 w w w 分别表示特征图的通道数、高度和宽度。CAM 为 P k P_k Pk( Q b Q_b Qb)生成交叉注意力图 A p A_p Ap( A q A_q Aq),并用其加权特征图以获得更具区分性的特征表示 P ˉ k b \bar{P}_k^b Pˉkb( Q ˉ b k \bar{Q}_b^k Qˉbk)。为了简化,我们省略上下标,将输入的类别和查询特征图分别记作 P P P 和 Q Q Q,输出的类别和查询特征图分别记作 P ˉ \bar{P} Pˉ 和 Q ˉ \bar{Q} Qˉ。

图2. (a) 交叉注意力模块(CAM)。(b) CAM 中的融合层。在图中, R p R_p Rp ( R q R_q Rq) ∈ R m × m \in \mathbb{R}^{m \times m} ∈Rm×m 被重塑为 R m × h × w \mathbb{R}^{m \times h \times w} Rm×h×w 以便于更好的可视化。如图所示,CAM 能够生成关注目标对象区域(图中的"被涂层的寻回犬")的特征图。
3.3 相关性层
如图 2 所示,我们首先设计了一个相关性层来计算 P P P 和 Q Q Q 之间的相关性图,该图用于指导生成交叉注意力图。为此,我们首先将 P P P 和 Q Q Q 重塑为 R c × m \mathbb{R}^{c \times m} Rc×m,即 P = p 1 , p 2 , ... , p m P = p_1, p_2, \\ldots, p_m P=p1,p2,...,pm, Q = q 1 , q 2 , ... , q m Q = q_1, q_2, \\ldots, q_m Q=q1,q2,...,qm,其中 m m m( m = h × w m = h \times w m=h×w)是每个特征图的空间位置数。 p i p_i pi、 q i ∈ R c q_i \in \mathbb{R}^c qi∈Rc 分别表示 P P P 和 Q Q Q 中第 i i i 个空间位置的特征向量。相关性层使用余弦距离计算 { p i } i = 1 m \{p_i\}{i=1}^m {pi}i=1m 和 { q i } i = 1 m \{q_i\}{i=1}^m {qi}i=1m 之间的语义相关性,以得到相关性图 R ∈ R m × m R \in \mathbb{R}^{m \times m} R∈Rm×m:
R i j = ( p i ∥ p i ∥ 2 ) T ( q j ∥ q j ∥ 2 ) , i , j = 1 , ... , m . . (1) R_{ij} = \left( \frac{p_i}{\|p_i\|_2} \right)^T \left( \frac{q_j}{\|q_j\|_2} \right), \quad i, j = 1, \ldots, m.. \tag{1} Rij=(∥pi∥2pi)T(∥qj∥2qj),i,j=1,...,m..(1)
此外,我们基于 R R R 定义了两个相关性图:类别相关性图 R p ≔ R T = r p 1 , r p 2 , ... , r p m R_p \coloneqq R^T = r_p\^1, r_p\^2, \\ldots, r_p\^m Rp:=RT=rp1,rp2,...,rpm 和查询相关性图 R q ≔ R = r q 1 , r q 2 , ... , r q m R_q \coloneqq R = r_q\^1, r_q\^2, \\ldots, r_q\^m Rq:=R=rq1,rq2,...,rqm,其中 r p i ∈ R m r_p^i \in \mathbb{R}^m rpi∈Rm 表示局部类别特征向量 p i p_i pi 与所有查询特征向量 { q i } i = 1 m \{q_i\}{i=1}^m {qi}i=1m 之间的相关性, r q i ∈ R m r_q^i \in \mathbb{R}^m rqi∈Rm 表示局部查询特征向量 q i q_i qi 与所有类别特征向量 { p i } i = 1 m \{p_i\}{i=1}^m {pi}i=1m 之间的相关性。通过这种方式, R p R_p Rp 和 R q R_q Rq 表征了类别和查询特征图之间的局部相关性。
3.4 元融合层
然后,元融合层根据相应的相关性图分别生成类别和查询的注意力图。我们以类别注意力图为例。如图2(b)所示,融合层以类别相关性图 R p R_p Rp 作为输入,并使用尺寸为 m × 1 m \times 1 m×1 的卷积核 w ∈ R m × 1 w \in \mathbb{R}^{m \times 1} w∈Rm×1 对 R p R_p Rp 的每个局部相关性向量 { r p i } \{r_p^i\} {rpi} 进行卷积操作,融合为注意力标量。然后使用 softmax 函数对注意力标量进行归一化,以获得位置 i i i 处的类别注意力:
A p i = exp ( w T r p i τ ) ∑ j = 1 h × w exp ( w T r p j τ ) , . (2) A_p^i = \frac{\exp \left( \frac{w^T r_p^i}{\tau} \right)}{\sum_{j=1}^{h \times w} \exp \left( \frac{w^T r_p^j}{\tau} \right)},. \tag{2} Api=∑j=1h×wexp(τwTrpj)exp(τwTrpi),.(2)
其中 τ \tau τ 是温度超参数。较低的温度会导致较低的熵,使得分布集中在少数高置信度的位置上。类别注意力图通过将 A p A_p Ap 重塑为 R h × w \mathbb{R}^{h \times w} Rh×w 中的矩阵获得。注意,卷积核 w w w 在融合中起到了关键作用。它将局部类别特征 p i p_i pi 与所有局部查询特征 { q j } j = 1 m \{q_j\}_{j=1}^m {qj}j=1m 之间的相关性聚合为位置 i i i 处的注意力标量。更重要的是,加权聚合应将注意力集中在目标对象上,而不仅仅是简单地突出支持类和查询样本中视觉上相似的区域。
基于上述分析,我们设计了一个元学习器,根据类别特征和查询特征之间的相关性自适应地生成卷积核。为此,我们对 R p R_p Rp 进行全局平均池化(GAP)操作(即按行平均),以获得一个平均查询相关性向量,然后将其输入到元学习器中以生成卷积核 w ∈ R m w \in \mathbb{R}^m w∈Rm:
w = W 2 ( σ ( W 1 ( GAP ( R p ) ) ) ) , . (3) w = W_2 \left( \sigma \left( W_1 (\text{GAP}(R_p)) \right) \right),. \tag{3} w=W2(σ(W1(GAP(Rp)))),.(3)
其中 W 1 ∈ R m r × m W_1 \in \mathbb{R}^{\frac{m}{r} \times m} W1∈Rrm×m 和 W 2 ∈ R m × m r W_2 \in \mathbb{R}^{m \times \frac{m}{r}} W2∈Rm×rm 是元学习器的参数, r r r 是缩减比率, σ \sigma σ 表示 ReLU 函数 [40](#40)。元学习模型中的非线性使得转换更加灵活。对于每一对类别和查询特征,元学习器应生成一个卷积核 w w w,以对目标对象产生交叉注意力。这通过最小化查询样本上的分类误差来实现元训练。
类似地,我们可以得到查询注意力图 A q ∈ R h × w A_q \in \mathbb{R}^{h \times w} Aq∈Rh×w。最后,我们使用残差注意力机制,其中初始特征图 P P P 和 Q Q Q 被分别用 1 + A p 1 + A_p 1+Ap 和 1 + A q 1 + A_q 1+Aq 进行逐元素加权,以形成更具区分性的特征图 P ˉ ∈ R c × h × w \bar{P} \in \mathbb{R}^{c \times h \times w} Pˉ∈Rc×h×w 和 Q ˉ ∈ R c × h × w \bar{Q} \in \mathbb{R}^{c \times h \times w} Qˉ∈Rc×h×w。
3.5 复杂度分析
CAM 的时间和空间成本主要在于相关性层。CAM 的时间复杂度为 O ( h 2 w 2 c ) O(h^2 w^2 c) O(h2w2c),空间复杂度为 O ( h w c ) O(hwc) O(hwc),这两者都随输入特征图的大小变化。因此,我们在最后一个卷积层之后插入 CAM,以避免过多的成本。
4 Cross Attention Network
如图3所示,整体交叉注意力网络(Cross Attention Network, CAN)由三个模块组成:嵌入模块、交叉注意力模块和分类模块。嵌入模块 E E E 由多个级联卷积层组成,将输入图像 x x x 映射到特征图 E ( x ) ∈ R c × h × w E(x) \in \mathbb{R}^{c \times h \times w} E(x)∈Rc×h×w。参考 Prototypical Network [9](#9),我们将类别特征定义为其支持集在嵌入空间中的平均值。如图3所示,嵌入模块 E E E 以支持集 S S S 和查询样本 x b q x_b^q xbq 作为输入,产生类别特征图 P k = 1 ∣ S k ∣ ∑ x a s ∈ S k E ( x a s ) P_k = \frac{1}{|S_k|} \sum_{x_a^s \in S_k} E(x_a^s) Pk=∣Sk∣1∑xas∈SkE(xas) 和查询特征图 Q b = E ( x b q ) Q_b = E(x_b^q) Qb=E(xbq)。每对特征图 ( P k , Q b ) (P_k, Q_b) (Pk,Qb) 然后通过交叉注意力模块进行处理,突出相关区域并输出更具区分性的特征对 ( P ˉ k b , Q ˉ b k ) (\bar{P}_k^b, \bar{Q}_b^k) (Pˉkb,Qˉbk) 以用于分类。

图3 所提出的 CAN 方法的框架。
4.1 通过优化进行模型训练
CAN 通过最小化训练集查询样本的分类损失进行训练。分类模块由最近邻分类器和全局分类器组成。最近邻分类器基于预定义的相似度度量,将查询样本分类到 C C C 个支持类中。为了获得精确的注意力图,我们约束查询特征图中每个位置的特征能够被正确分类。具体而言,对于位置 i i i 处的局部查询特征 q i b q_i^b qib,最近邻分类器会在 C C C 个支持类上生成类似 softmax 的标签分布。预测 q i b q_i^b qib 为第 k k k 类的概率为:
p ( y = k ∣ q i b ) = exp ( − d ( ( Q ˉ b k ) i , GAP ( P ˉ k b ) ) ) ∑ j = 1 C exp ( − d ( ( Q ˉ b j ) i , GAP ( P ˉ j b ) ) ) , p(y = k | q_i^b) = \frac{\exp \left( -d \left( (\bar{Q}_b^k)_i, \text{GAP}(\bar{P}k^b) \right) \right)}{\sum{j=1}^C \exp \left( -d \left( (\bar{Q}_b^j)_i, \text{GAP}(\bar{P}_j^b) \right) \right)}, p(y=k∣qib)=∑j=1Cexp(−d((Qˉbj)i,GAP(Pˉjb)))exp(−d((Qˉbk)i,GAP(Pˉkb))),
其中 ( Q ˉ b k ) i (\bar{Q}_b^k)i (Qˉbk)i 表示 Q ˉ b k \bar{Q}b^k Qˉbk 在第 i i i 个空间位置的特征向量, GAP \text{GAP} GAP 是全局平均池化操作,用于得到类别特征的平均值。在公式 (4) 中,余弦距离 d d d 是在由 CAM 生成的特征空间中计算的。最近邻分类损失定义为查询样本真实类别标签 y b q ∈ { 1 , 2 , ... , C } y_b^q \in \{1, 2, \ldots, C\} ybq∈{1,2,...,C} 对应的负对数概率:
L 1 = − ∑ b = 1 n q ∑ i = 1 m log p ( y = y b q ∣ q i b ) . L_1 = - \sum{b=1}^{n_q} \sum{i=1}^m \log p(y = y_b^q | q_i^b). L1=−b=1∑nqi=1∑mlogp(y=ybq∣qib).
全局分类器使用全连接层和 softmax 将每个查询样本分类到所有可用的训练类中。假设训练集中共有 l l l 个类。对于每个局部查询特征 q i b q_i^b qib,计算分类概率向量 z i b ∈ R l z_i^b \in \mathbb{R}^l zib∈Rl:
z i b = softmax ( W c ( Q ˉ b y b q ) i ) , z_i^b = \text{softmax}(W_c (\bar{Q}_b^{y_b^q})_i), zib=softmax(Wc(Qˉbybq)i),
其中 W c ∈ R l × c W_c \in \mathbb{R}^{l \times c} Wc∈Rl×c 是全连接层的权重, l b q ∈ { 1 , 2 , ... , l } l_b^q \in \{1, 2, \ldots, l\} lbq∈{1,2,...,l} 是 x b q x_b^q xbq 的真实全局类别。全局分类损失为:
L 2 = − ∑ b = 1 n q ∑ i = 1 m log ( ( z i b ) l b q ) , L_2 = - \sum_{b=1}^{n_q} \sum_{i=1}^m \log ((z_i^b)_{l_b^q}), L2=−b=1∑nqi=1∑mlog((zib)lbq),
其中 ( ( z i b ) l b q ) ((z_i^b)_{l_b^q}) ((zib)lbq) 表示概率向量 z i b z_i^b zib 在 l b q l_b^q lbq 位置的值。最终,整体分类损失定义为:
L = λ L 1 + L 2 , L = \lambda L_1 + L_2, L=λL1+L2,
其中 λ \lambda λ 是平衡不同损失效果的权重。网络可以通过最小化 L L L 使用梯度下降算法进行端到端训练。
4.2 归纳推理
在归纳推理阶段,嵌入模块直接用于新任务,以提取类别和查询特征图。然后,每对类别和查询特征图被输入到 CAM 中以获得注意力加权的特征。对 CAM 的输出进行全局平均池化,以得到类别和查询特征的平均值。最后,通过在余弦距离度量下找到最近的类别特征的均值,预测查询样本 x b q x_b^q xbq 的标签 y ^ b q \hat{y}_b^q y^bq:
y ^ b q = arg min k d ( GAP ( Q ˉ b k ) , GAP ( P ˉ k b ) ) . (7) \hat{y}_b^q = \arg \min_k d(\text{GAP}(\bar{Q}_b^k), \text{GAP}(\bar{P}_k^b)). \tag{7} y^bq=argkmind(GAP(Qˉbk),GAP(Pˉkb)).(7)
4.3 传导推理
在少样本分类任务中,每个类别只有很少的标记样本,因此类别特征很难代表真实的类别分布。为了解决这个问题,我们提出了一种简单且有效的传导推理算法,利用未标记的查询样本来丰富类别特征。
具体而言,我们首先利用初始类别特征图 P k P_k Pk 来预测未标记查询样本 { x b q } b = 1 n q \{x_b^q\}_{b=1}^{n_q} {xbq}b=1nq 的标签 { y ^ b q } b = 1 n q \{\hat{y}b^q\}{b=1}^{n_q} {y^bq}b=1nq,使用公式 (7)。然后,我们通过查询样本 x b q x_b^q xbq 与其最近类别邻居之间的余弦距离来定义一个标签置信度标准:
c b q = min k d ( GAP ( Q ˉ b k ) , GAP ( P ˉ k b ) ) . c_b^q = \min_k d(\text{GAP}(\bar{Q}_b^k), \text{GAP}(\bar{P}_k^b)). cbq=kmind(GAP(Qˉbk),GAP(Pˉkb)).
值 c b q c_b^q cbq 越低,预测标签 { y ^ b q } \{\hat{y}_b^q\} {y^bq} 的置信度越高。基于这个标准,我们可以得到候选集 D = { ( x b q , y ^ b q ) ∣ s b = 1 , x b q ∈ Q } D = \{(x_b^q, \hat{y}b^q) | s_b = 1, x_b^q \in Q\} D={(xbq,y^bq)∣sb=1,xbq∈Q},其中 s b ∈ { 0 , 1 } s_b \in \{0, 1\} sb∈{0,1} 表示查询样本 x b q x_b^q xbq 的选择指示器。选择指示器 s ∈ { 0 , 1 } n q s \in \{0, 1\}^{n_q} s∈{0,1}nq 由最有信心的 t t t 个查询样本确定:
s = arg min ∥ s ∥ 0 = t ∑ b = 1 n q s b c b q . s = \arg \min{\|s\|0 = t} \sum{b=1}^{n_q} s_b c_b^q. s=arg∥s∥0=tminb=1∑nqsbcbq.
最后,候选集 D D D 与支持集 S S S 一起用于生成更具代表性的类别特征图 ( P k ) ∗ (P_k)^* (Pk)∗:
( P k ) ∗ = 1 ∣ S k ∣ + ∣ D k ∣ ( ∑ x a s ∈ S k E ( x a s ) + ∑ x b q ∈ D k E ( x b q ) ) . (8) (P_k)^* = \frac{1}{|S_k| + |D_k|} \left( \sum_{x_a^s \in S_k} E(x_a^s) + \sum_{x_b^q \in D_k} E(x_b^q) \right). \tag{8} (Pk)∗=∣Sk∣+∣Dk∣1 xas∈Sk∑E(xas)+xbq∈Dk∑E(xbq) .(8)
其中 D k = { ( x b q , y ^ b q ) ∣ x b q ∈ D , y ^ b q = k } D_k = \{(x_b^q, \hat{y}_b^q) | x_b^q \in D, \hat{y}_b^q = k\} Dk={(xbq,y^bq)∣xbq∈D,y^bq=k}。然后, ( P k ) ∗ (P_k)^* (Pk)∗ 用于重新估计每个查询样本的伪标签。我们重复上述过程若干次,并在每次迭代中以固定比率逐渐增加候选集 D D D 中选定样本的数量。通过这种方式,我们可以逐渐丰富类别特征,使其更具代表性和鲁棒性。
5 Experiments
5.1 Experiment Setup
数据集
我们使用 miniImageNet [10](#10),这是 ILSVRC-12 [41](#41) 的一个子集,包含 100 个类别,每个类别有 600 张图像。我们遵循标准的划分方式 [4](#4) [11](#11) [20](#20) [42](#42) [14](#14):64 个类别用于训练,16 个类别用于验证,20 个类别用于测试。我们还使用了 tieredImageNet 数据集 [26](#26),它是 ILSVRC-12 [41](#41) 的一个更大子集。该数据集包含 34 个类别,共 608 个类。这些类别被划分为 20 个类别(351 个类)用于训练,6 个类别(97 个类)用于验证,8 个类别(160 个类)用于测试,参见 [26](#26) [6](#6) [9](#9) [11](#11)。
实验设置
我们在 5-way 1-shot 和 5-way 5-shot 设置下进行了实验。在 C C C-way K K K-shot 设置中,每个 episode 包含 C C C 个类别,每个类别包含 K K K 个支持样本,6 个查询样本用于训练,15 个查询样本用于推理。在推理过程中,从测试集中随机抽取 2000 个 episode。我们报告 2000 个 episode 上的平均准确率及相应的 95% 置信区间。
实现细节
我们使用 Pytorch [43](#43) 在一块 NVIDIA 1080Ti GPU 上实现了所有实验。参考 [20](#20) [22](#22) [15](#15) [18](#18),我们使用 ResNet-12 网络作为嵌入模块。输入图像的大小为 84 × 84 84 \times 84 84×84。在训练过程中,我们采用水平翻转、随机裁剪和随机擦除 [44](#44) 作为数据增强。优化器采用 SGD。每个 mini-batch 包含 8 个 episode。模型训练 80 个 epoch,每个 epoch 包含 1200 个 episode。对于 miniImageNet,初始学习率为 0.1,并在第 60 和 70 个 epoch 分别降低到 0.006 和 0.0012。对于 tieredImageNet,初始学习率设置为 0.1,每 20 个 epoch 以 0.1 的衰减因子衰减。温度超参数( τ \tau τ,在公式 (3) 中)设为 0.025,元学习器中的缩减比率设为 6,整体损失函数中的权重超参数( λ \lambda λ)设为 0.5。对于传导推理算法,在第一次迭代中选择的查询样本数 ( t t t) 设为 35,迭代次数和候选集的扩充因子均设为 2。所有超参数均在验证集上进行了交叉验证,并在所有实验中固定。
5.2 Comparison with State-of-the-arts
表1比较了我们的方法与现有的少样本方法在 miniImageNet 和 tieredImageNet 上的表现。比较的方法分为四组:基于优化的方法(O)、参数生成方法(P)、度量学习方法(M)和传导方法(T)。我们的方法优于基于优化的方法 [6](#6) [13](#13) [14](#14) [15](#15)。需要注意的是,基于优化的方法需要在目标任务上进行微调,使得分类过程耗时。相比之下,我们的方法不需要模型更新,以前馈的方式解决任务,比上述方法更快、更简单,并且表现更好。
表1 在 miniImageNet 和 tieredImageNet 数据集上的 5-way 分类中与最先进方法的比较,包含 95% 置信区间。IT:在 NVIDIA 1080Ti GPU 上每个查询数据在 5-way 1-shot 任务中的推理时间。CAN+T 表示带有传导推理的 CAN。比较方法分为四组:基于优化的方法(O )、参数生成方法(P )、度量学习方法(M )和传导方法(T)。
| model | Embedding | IT(s) | miniImageNet 1-shot | miniImageNet 5-shot | tieredImageNet 1-shot | tieredImageNet 5-shot | |
|---|---|---|---|---|---|---|---|
| O | MAML ^[6](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ MTL ^[15](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ LEO ^[14](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ MetaOpt ^[39](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ | ConvNet ResNet-12 WRN-28 ResNet-12 | 0.103 2.020 - 0.096 | 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 | 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 | 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 | 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 |
| P | MetaNet ^[17](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ MM-Net ^[19](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ adaNet ^[18](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ | ConvNet ConvNet ResNet-12 | - - 1.371 | 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 | - 66.97 ± 0.35 71.94 ± 0.57 | - - - | - - - |
| M | MN ^[10](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ PN ^[9](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ RN ^[11](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ DN4 ^[42](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ TADAM ^[20](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ Our CAN | ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 | 0.021 0.018 0.033 0.049 0.079 0.044 | 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 | 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 | - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 | - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 |
| T | TPN ^[22](#model Embedding IT(s) miniImageNet 1-shot miniImageNet 5-shot tieredImageNet 1-shot tieredImageNet 5-shot O MAML 6 MTL 15 LEO 14 MetaOpt 39 ConvNet ResNet-12 WRN-28 ResNet-12 0.103 2.020 - 0.096 48.70 ± 0.84 61.20 ± 1.80 61.76 ± 0.08 62.64 ± 0.62 55.31 ± 0.73 75.50 ± 0.80 77.59 ± 0.12 78.63 ± 0.46 51.67 ± 1.81 - 66.33 ± 0.05 65.99 ± 0.72 70.30 ± 1.75 - 81.44 ± 0.09 81.56 ± 0.53 P MetaNet 17 MM-Net 19 adaNet 18 ConvNet ConvNet ResNet-12 - - 1.371 49.21 ± 0.96 53.37 ± 0.48 56.88 ± 0.62 - 66.97 ± 0.35 71.94 ± 0.57 - - - - - - M MN 10 PN 9 RN 11 DN4 42 TADAM 20 Our CAN ConvNet ConvNet ConvNet ConvNet ResNet-12 ResNet-12 0.021 0.018 0.033 0.049 0.079 0.044 43.44 ± 0.77 49.42 ± 0.78 50.44 ± 0.82 51.24 ± 0.74 58.50 ± 0.30 63.85 ± 0.48 60.60 ± 0.71 68.20 ± 0.66 65.32 ± 0.70 71.02 ± 0.64 76.70 ± 0.30 79.44 ± 0.34 - 53.31 ± 0.89 54.48 ± 0.93 - - 69.89 ± 0.51 - 72.69 ± 0.74 71.32 ± 0.78 - - 84.23 ± 0.37 T TPN 22 Our CAN+T ResNet-12 ResNet-12 - - 59.46 67.19 ± 0.55 75.65 80.64 ± 0.35 - 73.21 ± 0.58 - 84.93 ± 0.38)^ Our CAN+T | ResNet-12 ResNet-12 | - - | 59.46 67.19 ± 0.55 | 75.65 80.64 ± 0.35 | - 73.21 ± 0.58 | - 84.93 ± 0.38 |
我们的方法比参数生成方法 [17](#17) [18](#18) [19](#19) 表现更好,提升幅度可达 7%。这些方法基于支持集生成特征提取器的参数,并自适应地提取查询特征。然而,这些方法受到参数空间高维度的影响。相反,我们的方法使用交叉注意力模块自适应地提取支持和查询特征,计算成本较低且性能更优。我们的方法属于度量学习方法。现有的度量学习方法 [10](#10) [9](#9) [11](#11) [20](#20) [42](#42) 独立提取支持和查询样本的特征,使得特征关注于非目标对象。相反,我们的 CAN 突出目标对象区域,并获得更具区分性的特征。与 TADAM [20](#20) 相比,CAN 在参数数量几乎相同的情况下,1-shot 上性能提升 5%,这证明了我们交叉注意力模块的优越性。
在传导式设置下,带有传导的 CAN(CAN+T)比先前的工作 TPN [22](#22) 有较大的优势,在 1-shot 和 5-shot 上分别提高了 8% 和 5%。TPN 使用图网络将支持集的标签传播到查询集。相比之下,我们的算法选择最有信心的查询样本来增强支持集,可以明确缓解数据不足问题。此外,我们的传导算法可以轻松应用于其他少样本学习模型,例如 Matching Network [10](#10)、Prototypical Network [9](#9) 和 Relation Network [11](#11)。
时间复杂度比较
表1 进一步比较了我们的方法与其他方法的时间成本。有些方法 [10](#10) [9](#9) [11](#11) [42](#42) [6](#6) 使用了 4 层 ConvNet 作为骨干网络,因此时间成本相对较低。尽管如此,我们的 CAN 在时间成本上仍然可与这些方法相媲美,甚至优于这些方法,性能提升可达 10%。其他方法使用与 CAN 相同的骨干网络,但需要后续模块,如每个任务的模型更新 [15](#15) [39](#39)、基于梯度的参数生成 [18](#18) 或昂贵的条件生成 [20](#20),这些都会比 CAM 引入更多的时间开销。总体而言,表1 显示了 CAN 在没有过多开销的情况下优于其他方法。
5.3 Ablation Study
5.3.1 实验组件分析
在本小节中,我们通过实验展示了 CAN 各个组件的有效性。我们首先引入两个用于对比的基线。在 R12-proto [9](#9) 中,嵌入模块提取的特征被直接送入最近邻分类器,并且模型用最近邻分类损失进行训练。在 R12-proto-ac 中,与 R12-proto 唯一不同的是 R12-proto-ac 具有一个额外的全局分类 logit head(在 miniImageNet 中是标准的 64-way 分类),并且模型使用全局和最近邻分类损失的联合训练。
5.3.2 全局分类的影响
对比结果见表 2。通过将 R12-proto-ac 与 R12-proto 进行比较,我们发现 1-shot(5.8%)和 5-shot(7.7%)均有显著提升。我们进一步尝试了另一种元学习器------Matching Network (MN) [10](#10),所提出的联合学习策略将 MN 在 1-shot 上的性能从 55.29% 提升到 59.14%,5-shot 上从 67.74% 提升到 73.81%。这些持续的提升证明了联合学习策略的有效性。我们认为,全局分类损失对嵌入模块起到了正则化的作用,并促使其在两个解耦的任务(最近邻分类和全局分类)上表现良好。
表2. 在 miniImageNet 上的消融实验和复杂度比较。PN:参数数量;GFLOPs:浮点运算次数;CIT:每个类别包含 15 个查询样本的任务在 CPU 上的推理时间。
| Description | PN | 5-way 1-shot GFLOPs | 5-way 1-shot CIT | 5-way 1-shot accuracy | 5-way 5-shot GFLOPs | 5-way 5-shot CIT | 5-way 5-shot accuracy |
|---|---|---|---|---|---|---|---|
| R12-proto R12-proto-ac | 8.04M 8.04M | 101.550 101.550 | 0.96s 0.97s | 55.46 61.30 | 126.938 126.938 | 1.25s 1.26s | 69.00 76.70 |
| CAN-NoML-1 CAN-NoML-2 | 8.04M 8.04M | 101.812 101.812 | 1.01s 1.01s | 63.55 63.38 | 127.201 127.201 | 1.29s 1.30s | 78.88 79.08 |
| CAN CAN+T | 8.04M 8.04M | 101.813 101.930 | 1.02s 1.11s | 63.85 67.19 | 127.203 127.320 | 1.31s 1.43s | 79.44 80.64 |
5.3.3 交叉注意力模块的影响
通过将我们的 CAN 与 R12-pro-ac 进行比较,我们在 1-shot 和 5-shot 场景中都观察到了持续的提升。其原因在于,当使用交叉注意力模块时,我们的模型能够突出相关区域并提取更具区分性的特征。性能差距也证明了:(1)传统独立提取的特征往往关注非目标区域,产生不准确的相似性;(2)交叉注意力模块可以帮助突出目标区域,并以较小的开销减少这种不准确性。
5.3.4 CAM 中元学习器的影响
为了验证 CAM 中元学习器的有效性,我们开发了两个不带元学习器的 CAM 变体。具体而言,其中一个变体(CAN-NoML-1)将卷积核 w w w(见图 2(b))设置为固定的均值卷积核,即在相关性图 R R R 上执行全局平均池化以获得注意力图 A A A。另一个变体(CAM-NoML-2)将卷积核 w w w 设置为一个通用的可学习卷积核,对于所有输入样本保持不变。如表 2 所示,这两个变体的性能均优于 R12-proto-ac,进一步证明了所提出的交叉注意力机制的有效性。CAN-NoML-1 的提升表明,相关性向量的均值可以大致估计相关的语义信息,这进一步验证了我们设计的元学习器的合理性。如所见,CAN 的性能优于两个变体。此提升可归因于元学习策略,它根据输入特征图对来自适应生成卷积核 w w w。
5.3.5 传导推理算法的影响
如表 2 所示,CAN+T 尤其在 1-shot 场景下显著提升了 CAN 的性能,1-shot 问题中的数据不足更为严重。为了进一步验证其有效性,我们将其应用于其他少样本模型,例如 Matching Network [10](#10)、Prototypical Network [9](#9) 和 Relation Network [11](#11)。我们使用 [45](#45) 提供的代码重新实现了这些模型,以确保公平比较。如表 3 所示,我们的算法持续提高了这些模型的性能,证明了其泛化能力。然而,相较于 CAN,这些模型的提升幅度较小。我们认为 CAN 能够为查询样本预测更精确的伪标签,并更有效地增强支持集,从而带来更好的性能。
| Models | Inductive 1-shot | Inductive 5-shot | Transductive 1-shot | Transductive 5-shot |
|---|---|---|---|---|
| Matching Network ^[10](#Models Inductive 1-shot Inductive 5-shot Transductive 1-shot Transductive 5-shot Matching Network 10 53.52* (43.77) 66.20* (60.60) 56.31 69.80 Prototypical Network 9 53.68* (49.42) 70.44* (68.20) 55.15 71.12 Relation Network 11 0.65* (50.44) 64.18* (65.32) 52.40 65.36)^ | 53.52* (43.77) | 66.20* (60.60) | 56.31 | 69.80 |
| Prototypical Network ^[9](#Models Inductive 1-shot Inductive 5-shot Transductive 1-shot Transductive 5-shot Matching Network 10 53.52* (43.77) 66.20* (60.60) 56.31 69.80 Prototypical Network 9 53.68* (49.42) 70.44* (68.20) 55.15 71.12 Relation Network 11 0.65* (50.44) 64.18* (65.32) 52.40 65.36)^ | 53.68* (49.42) | 70.44* (68.20) | 55.15 | 71.12 |
| Relation Network ^[11](#Models Inductive 1-shot Inductive 5-shot Transductive 1-shot Transductive 5-shot Matching Network 10 53.52* (43.77) 66.20* (60.60) 56.31 69.80 Prototypical Network 9 53.68* (49.42) 70.44* (68.20) 55.15 71.12 Relation Network 11 0.65* (50.44) 64.18* (65.32) 52.40 65.36)^ | 0.65* (50.44) | 64.18* (65.32) | 52.40 | 65.36 |
5.3.6 复杂度比较
为了说明 CAN 的成本,我们报告了 5-way 1-shot 和 5-way 5-shot 任务(每个类别包含 15 个查询样本)的参数数量(PN)、浮点运算次数(GFLOPs)和平均 CPU 推理时间(CIT)。如表 2 所示,CAN 引入了可以忽略的参数(CAM 中元学习器的参数 W 1 W_1 W1 和 W 2 W_2 W2)以及较小的计算开销。例如,CAN 在 5-way 1-shot 上需要 101.81 GFLOPs,相对于原始 R12-proto-ac 仅增加了 0.25%。值得注意的是,CAM 中的相关性图可以通过一次矩阵乘法计算出来,在 GPU 库中所占用的时间较少。传导推理算法也只引入了较小的计算开销(1-shot 上为 0.37%,5-shot 上为 0.31%),因为它直接利用提取的嵌入特征重新生成类别特征,并且仅需再次通过轻量级的 CAM。
5.4 Visualization Analysis
为了定性评估所提出的交叉注意力机制,我们将 CAN 的类激活图 [12](#12) 可视化结果与其他元学习器进行比较,包括 RN [11](#11)、MAML [6](#6) 和 TADAM [20](#20)。如图4(a)所示,RN 的特征通常包含非目标对象,因为它缺乏显式的特征自适应机制。MAML 执行基于梯度的自适应,这使得模型只能学习到支持图像中一些显著的区分性特征,而没有深入到目标对象的内在特性。如图4(b)所示,MAML 在 groenendael 支持图像中关注到船的部分,以更好地区分其与金毛犬类别,导致了对 groenendael 类别的混淆定位和错误分类。TADAM 执行任务相关的自适应,并将相同的自适应参数应用于一个任务中的所有查询图像,因此很难对不同类别的不同目标对象进行定位。如图4©所示,TADAM 在 worm fence 查询图像中错误地关注了狗的部分。相比之下,CAN 对查询样本使用不同的自适应参数,使其能够针对不同类别专注于不同的目标对象,如图4(d)所示。
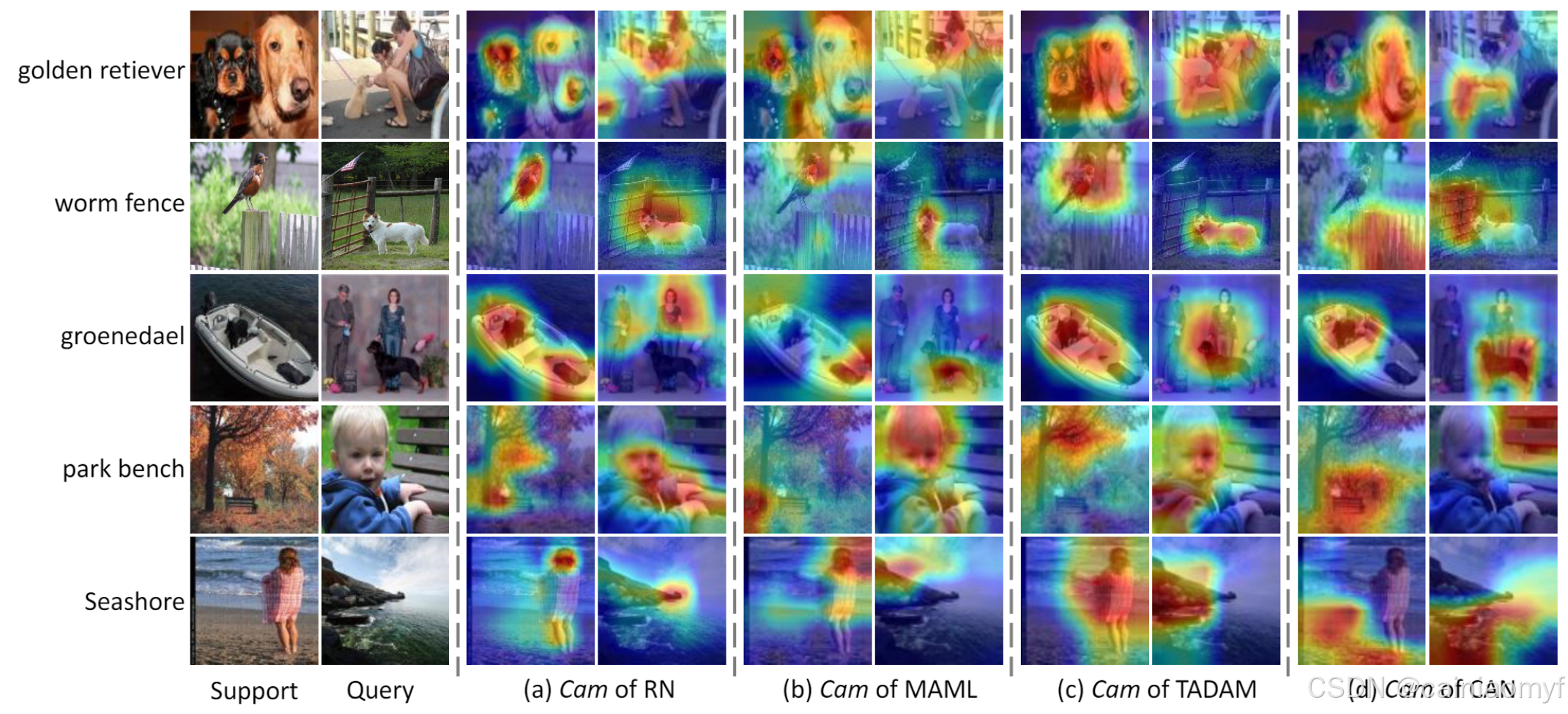 图4. 在 5-way 1-shot 任务中,每个类别包含 1 个查询样本的类激活映射(CAM)可视化。
图4. 在 5-way 1-shot 任务中,每个类别包含 1 个查询样本的类激活映射(CAM)可视化。
6 Conclusion
在本文中,我们提出了一种用于少样本分类的交叉注意力网络。首先,我们设计了一个交叉注意力模块来建模类别特征和查询特征之间的语义相关性。该模块能够自适应地定位相关区域并生成更具区分性的特征。其次,我们提出了一种传导推理算法来缓解数据不足的问题。它利用未标记的查询样本来丰富类别特征,使其更具代表性。大量实验表明,我们的方法比近期少样本元学习方法更简单、更高效,并且产生了最先进的结果
-
S. Thrun. Lifelong learning algorithms. In Learning to Learn, pages 181--209, 1998. ↩︎ ↩︎
-
S. Thrun and L. Pratt. Learning to learn: Introduction and overview. In Learning to Learn, pages 3--17, 1998. ↩︎ ↩︎
-
D. K. Naik and R. J. Mammone. Meta-neural networks that learn by learning. In IJCNN, pages 437--442, 1992. ↩︎ ↩︎
-
S. Ravi and H. Larochelle. Optimization as a model for few-shot learning. In ICLR, 2017. ↩︎ ↩︎ ↩︎
-
M. Andrychowicz, M. Denil, S. Gomez, M. W. Hoffman, D. P. T. Schaul, and N. d. Freitas. Learning to learn by gradient descent by gradient descent. In NeurIPS, 2018. ↩︎ ↩︎
-
C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In ICML, pages 1126--1135, 2017. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Z. Li, F. Zhou, F. Chen, and H. Li. Meta-sgd: Learning to learn quickly for few-shot learning. arXiv preprint arXiv:1707.09835, 2017. ↩︎
-
A. Nichol, J. Achiam, and J. Schulman. On first-order meta-learning algorithms. arXiv preprint arXiv:1803.02999, 2018. ↩︎
-
J. Snell, K. Swersky, and R. Zemel. Prototypical networks for few-shot learning. In NeurIPS, pages 4077--4087, 2017. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
O. Vinyals, C. Blundell, T. Lillicrap, and D. Wierstra. Matching networks for one shot learning. In NeurIPS, pages 3630--3638, 2016. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
F. Sung, Y. Yang, L. Zhang, T. Xiang, P. H. Torr, and T. M. Hospedales. Learning to compare: Relation network for few-shot learning. In CVPR, pages 1199--1208, 2018. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning deep features for discriminative localization. In CVPR, pages 2921--2929, 2016. ↩︎ ↩︎
-
Y. Liu, Q. Sun, A. A. Liu ad Y. Su, B. Schiele, and T. S. Chua. Lcc: Learning to customize and combine neural networks for few-shot learning. In CVPR, 2019. ↩︎ ↩︎
-
A. A. Rusu, D. Rao, J. Sygnowski, O. Vinyals, R. Pascanu, S. Osindero, and R. Hadsell. Meta-learning with latent embedding optimization. In ICLR, 2019. ↩︎ ↩︎ ↩︎ ↩︎
-
Q. Sun, Y. Liu, T. S. Chua, and B. Schiele. Meta-transfer learning for few-shot learning. In CVPR, 2019. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
L. Bertinetto, J. F. Henriques, J. Valmadre, P. Torr, and A. Vedaldi. Learning feed-forward one-shot learners. In NeurIPS, pages 523--531, 2016. ↩︎
-
T. Munkhdalai and H. Yu. Meta networks. In ICML, pages 2554--2563, 2017. ↩︎ ↩︎ ↩︎
-
T. Munkhdalai, X. Yuan, S. Mehri, and A. Trischler. Rapid adaptation with conditionally shifted neurons. In ICML, 2018. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Q. Cai, Y. Pan, T. Yao, C. Yan, and T. Mei. Memory matching networks for one-shot image recognition. In CVPR, pages 4080--4088, 2018. ↩︎ ↩︎ ↩︎
-
B. Oreshkin, P. R. Lopez, and A. Lacoste. Tadam: Task dependent adaptive metric for improved few-shot learning. In NeurIPS, pages 719--729, 2018. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
D. Zhou, O. Bousquet, T. N. Lal, J. Weston, and B. Schölkopf. Learning with local and global consistency. In NeurIPS, pages 321--328, 2004. ↩︎
-
Y. Liu, J. Lee, M. Park, S. Kim, E. Yang, S. J. Hwang, and Y. Yang. Learning to propagate labels: Transductive propagation network for few-shot learning. In ICLR, 2018. ↩︎ ↩︎ ↩︎ ↩︎
-
L. Dong-Hyun. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In ICML workshop, 2013. ↩︎
-
A. Oliver, A. Odena, C. A. Raffel, E. D. Cubuk, and I. J. Goodfellow. Realistic evaluation of deep semi-supervised learning algorithms. In NeurIPS, 2018. ↩︎
-
Y. Wu, Y. Lin, X. Dong, Y. Yan, W. Quyang, and Y. Yang. Exploit the unknown gradually: One-shot video-based person re-identification by stepwise learning. In CVPR, pages 5177--5186, 2018. ↩︎
-
M. Ren, E. Triantafillou, S. Ravi, J. Snell, K. Swersky, J. B. Tenenbaum, H. Larochelle, and R. S. Zemel. Meta-learning for semi-supervised few-shot classification. arXiv preprint arXiv:1803.00676, 2018. ↩︎ ↩︎ ↩︎
-
J. Hu, L. Shen, and G. Sun. Squeeze-and-excitation networks. arXiv preprint arXiv:1709.01507, 2017. ↩︎ ↩︎
-
S. Woo, J. Park, J. Y. Lee, and I. S. Kweon. Cbam: Convolutional block attention module. In ECCV, pages 3--19, 2018. ↩︎ ↩︎
-
J. Park, S. Woo, J. Y. Lee, and I. S. Kweon. Bam: Bottleneck attention module. In BMVC, 2018. ↩︎ ↩︎
-
M. Pedersoli, T. Lucas, C. Schmid, and J. Verbeek. Areas of attention for image captioning. In ICCV, pages 1251--1259, 2017. ↩︎
-
K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhutdinov, R. Zemel, and Y. Bengio. Show, attend and tell: Neural image caption generation with visual attention. 2015. ↩︎
-
L. Chen, H. Zhang, J. Xiao, L. Nie, J. Shao, W. Liu, and T. S. Chua. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In CVPR, pages 5659--5667, 2017. ↩︎
-
H. Xu and K. Saenko. Ask, attend and answer: Exploring question-guided spatial attention for visual question answering. In ECCV, pages 451--466, 2016. ↩︎
-
Z. Yang, X. He, J. Gao, L. Deng, and A. Smola. Stacked attention networks for image question answering. In CVPR, pages 21--29, 2016. ↩︎
-
D. Yu, J. Fu, T. Mei, and Y. Rui. Multi-level attention networks for visual question answering. In CVPR, pages 4709--4717, 2017. ↩︎
-
A. Santoro, S. Bartunov, M. Botvinick, D. Wierstra, and T. Lillicrap. Meta-learning with memory-augmented neural networks. In ICML, pages 1842--1850, 2016. ↩︎
-
N. Mishra, M. Rohaninejad, X. Chen, and P. Abbeel. A simple neural attentive meta-learner. In ICLR, 2018. ↩︎
-
S. Gidaris and N. Komodakis. Generating classification weights with gnn denoising autoencoders for few-shot learning. In CVPR, 2019. ↩︎
-
K. Lee, S. Maji, A. Ravichandran, and S. Soatto. Meta-learning with differentiable convex optimization. In CVPR, 2019. ↩︎ ↩︎ ↩︎
-
V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In ICML, 2010. ↩︎
-
A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NeurIPS, pages 1097--1105, 2012. ↩︎ ↩︎
-
W. Li, L. Wang, J. Xu, J. Huo, Y. Gao, and J. Luo. Revisiting local descriptor based image-to-class measure for few-shot learning. In CVPR, 2019. ↩︎ ↩︎ ↩︎ ↩︎
-
A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer. Automatic differentiation in pytorch. In NIPS workshop, 2017. ↩︎
-
Z. Zhun, Z. Liang, K. Guoliang, L. Shaozi, and Y. Yi. Random erasing data augmentation. arXiv preprint arXiv:1708.04896, 2017. ↩︎
-
S. Gidaris and N. Komodakis. Dynamic few-shot visual learning without forgetting. In CVPR, 2018. ↩︎