Python/Java/Go通用!依赖感知分层模型DHCS让代码注释更智能
论文信息
- 论文原标题:基于依赖感知分层神经网络的代码注释增强方法
- 主要作者及研究机构 :
- 张育博1,2(中国科学院软件研究所智能软件研究中心,北京 100190;中国科学院大学,北京 100049)
- 姚开春1,3(通信作者,中国科学院软件研究所智能软件研究中心,北京 100190;计算机科学国家重点实验室(中国科学院软件研究所),北京 100190)
- 张立波1,3、武延军1,3、赵琛1,3(中国科学院软件研究所智能软件研究中心/计算机科学国家重点实验室,北京 100190)
- 期刊信息:软件学报,ISSN 1000-9825,CODEN RUXUEW,doi: 10.13328/j.cnki.jos.007504
- 引文格式(GB/T 7714):张育博, 姚开春, 张立波, 等. 基于依赖感知分层神经网络的代码注释增强方法J. 软件学报, 出版年, 卷(期): 页码. (注:文档中未标注具体出版年、卷期及页码,可参考网络首发地址:https://link.cnki.net/urlid/11.2560.TP.20251126.1656.003)
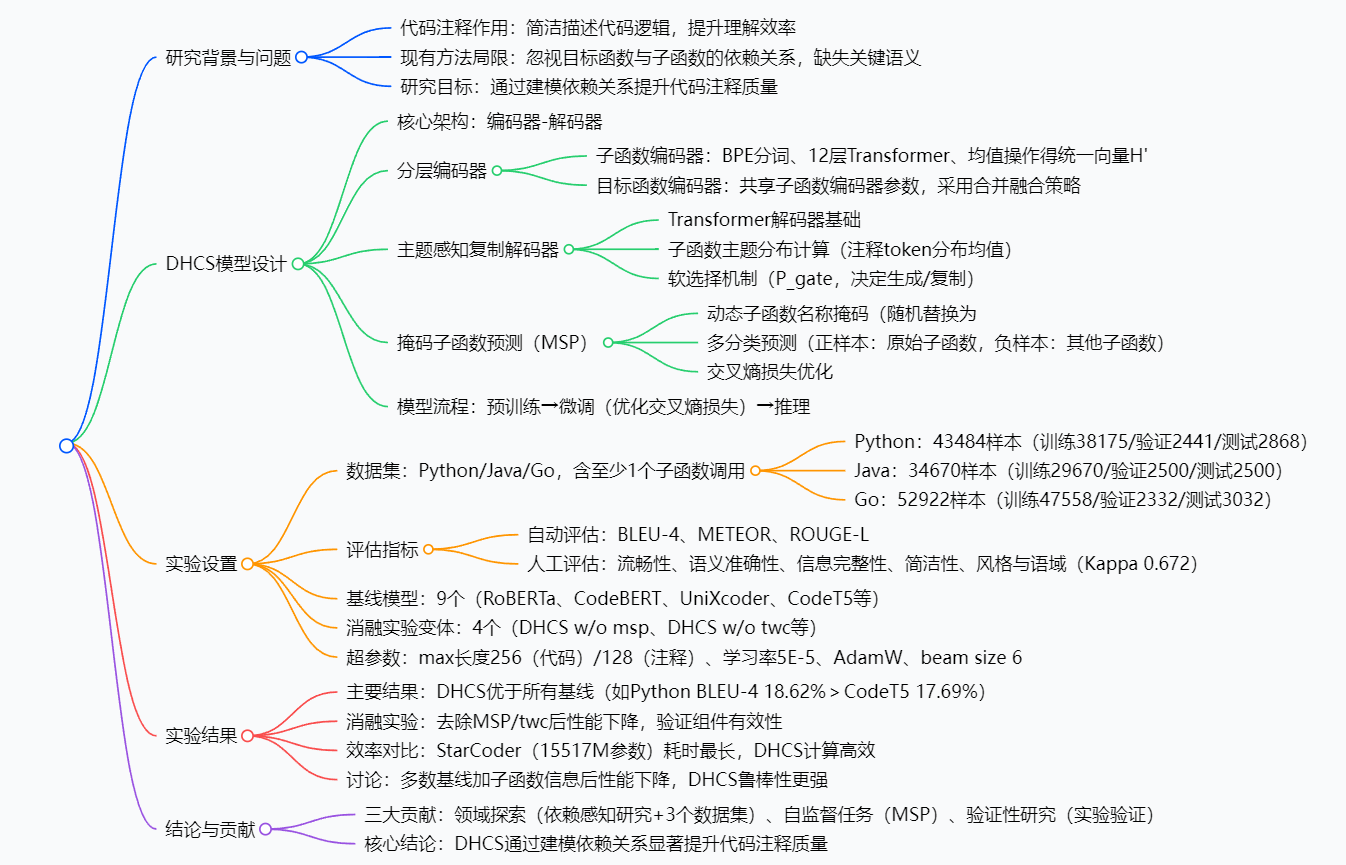
一段话总结
针对现有代码注释生成模型将代码片段视为独立函数、忽略"目标函数与子函数依赖关系"导致语义缺失的问题,研究团队提出DHCS(依赖感知分层代码注释神经网络模型)。该模型通过"分层编码器"(子函数+目标函数双编码器)捕捉依赖语义、"掩码子函数预测(MSP)"增强子函数表示、"主题感知复制机制"提取关键信息,在Python(43484个样本)、Java(34670个样本)、Go(52922个样本)三大真实数据集上验证。对比CodeT5、StarCoder等9种先进基线模型,DHCS在BLEU-4、METEOR、ROUGE-L三大自动指标及5个人工评估维度均排名第一,且计算复杂度低,为代码注释生成提供了"依赖感知"新范式。
思维导图
研究背景:代码注释的"痛点"与现有模型的"盲区"
你有没有过这样的经历:打开一个陌生项目的代码,看到几百行函数却找不到注释,只能逐行读代码猜功能,半小时过去还没搞懂它到底在做什么?这就是代码注释的价值------它像代码的"说明书",用一句话讲清函数逻辑,让程序员效率翻倍。
比如Python的Pydocs注释"在a和b中查找最长匹配块",一句话就能帮你快速定位函数用途,不用深究循环和判断的细节。但问题是,手动写注释太麻烦了:一个项目有上千个函数,每个都要精准描述,尤其是维护遗留代码时,老代码往往没注释,补起来更是头疼。
于是研究者们开发了"自动代码注释生成模型",比如CodeT5、StarCoder这些主流模型,它们用"编码器-解码器"架构,把代码转成语义表示再生成注释。但这些模型有个致命"盲区"------把代码片段当成独立个体,忽略了"目标函数和它调用的子函数"之间的依赖关系。
举个例子:目标函数reencrypt_user_content(给用户内容重加密)调用了子函数reencrypt_row_content(给单行内容重加密)。现有模型只看目标函数的代码,不知道子函数是"逐行加密"的,生成的注释可能只是笼统的"重加密用户内容";但如果能结合子函数的逻辑,注释就能精准到"重加密用户的所有文件和检查点"------这就是"依赖关系"带来的关键语义差异。
正是这个"盲区",让现有模型生成的注释常漏关键信息,质量大打折扣。DHCS模型就是为解决这个问题而生的。
创新点:DHCS的三大"破局思路"
DHCS能在众多模型中脱颖而出,靠的是三个独特设计,精准击中现有模型的痛点:
1. 分层编码器:分开处理,再"无缝融合"
现有模型把目标函数和子函数混在一起编码,子函数只被当成一串字符。DHCS则设计了"子函数编码器"和"目标函数编码器":
- 子函数编码器:专门学习子函数的语义,比如
reencrypt_row_content的"逐行加密"逻辑,最后输出统一的向量表示; - 目标函数编码器:和子函数编码器共享参数(减少计算量),再通过"合并融合"把子函数的向量加到目标函数对应位置的token上------既保留目标函数的原始信息,又融入子函数的关键语义。
这种"先分开学、再精准融"的思路,让模型第一次真正"看懂"函数间的依赖。
2. 掩码子函数预测(MSP):给模型"做练习题"强化理解
就像人学知识要做练习一样,DHCS给模型加了个"子函数级自监督任务":
- 训练时随机"盖住"部分子函数(用
<mask>替换名称,用随机向量替换语义); - 让模型从一堆候选子函数里,精准预测被盖住的是哪个;
- 通过这个练习,模型对"子函数是什么、有什么用"的理解更深刻,生成注释时不会漏掉子函数的逻辑。
3. 主题感知复制机制:从子函数"抄"关键信息
注释生成时,模型常不知道该优先用哪些词。DHCS的解法是:
- 先分析所有子函数的"主题分布"(比如子函数都和"加密"相关,主题分布里"加密""文件"这些词的权重就高);
- 解码时用"软选择机制"(计算0-1之间的概率)决定:是从词汇表生成新词,还是从子函数的主题里"复制"关键信息;
- 比如子函数都涉及"重绘",模型就会优先复制"重绘"这个词,让注释更精准。
研究方法:DHCS模型的"工作流程"与实验设计
一、DHCS模型:四步生成精准注释
把复杂的模型拆解成4个简单步骤,就能轻松看懂它的逻辑:
步骤1:子函数编码------给子函数"做语义笔记"
- 输入子函数代码(比如
reencrypt_row_content); - 用BPE分词把代码切成token序列(比如"reencrypt""_row""_content");
- 通过嵌入层把token转成向量,再用12层Transformer编码;
- 最后用"均值操作"把变长的编码结果转成固定长度的向量
H'------相当于给子函数做了一份浓缩的"语义笔记"。
步骤2:目标函数编码------融合子函数语义
- 输入目标函数代码(比如
reencrypt_user_content); - 同样BPE分词、嵌入层、Transformer编码;
- 找到目标函数中调用子函数的位置,把步骤1得到的
H'加到对应token的向量上(合并融合); - 输出融入子函数语义的目标函数表示
H。
步骤3:主题感知解码------生成注释
- 基于子函数的
H',计算每个子函数的"主题分布"(比如"加密""文件"的概率); - 求所有子函数主题分布的平均值,得到全局主题
P_topics; - Transformer解码器生成注释时,通过多层感知机(MLP)计算
P_gate(0-1概率):P_gate接近1:从P_topics复制子函数相关的关键词;P_gate接近0:从词汇表生成新词;
- 结合两种方式的概率,输出最终注释。
步骤4:MSP训练------强化子函数理解
- 随机掩码部分子函数;
- 模型根据目标函数上下文,预测被掩码的子函数;
- 用交叉熵损失计算预测误差,反向更新模型参数。
二、实验设计:用数据证明有效性
为了验证DHCS的实力,研究团队做了严谨的实验:
1. 数据集:专门构建"含依赖"的三大语言数据集
现有数据集(如CodeSearchNet)没标注子函数依赖,团队从CodeSearchNet抓取数据,筛选出"含至少1个子函数调用"的样本,构建了3个新数据集:
| 编程语言 | 总样本数 | 训练集 | 验证集 | 测试集 | 平均子函数数/目标函数 |
|---|---|---|---|---|---|
| Python | 43484 | 38175 | 2441 | 2868 | 1.44个 |
| Java | 34670 | 29670 | 2500 | 2500 | 1.36-1.56个 |
| Go | 52922 | 47558 | 2332 | 3032 | 1.64-1.76个 |
2. 基线模型:对比9种主流方法
选择了覆盖不同架构(编码器-解码器、仅解码器)、不同规模(普通模型、大模型)的9种基线,确保对比公平:
- 传统模型:RoBERTa、CodeBERT、UniXcoder、CodeT5、NeuralCodeSum;
- 大模型:GPT-3.5-turbo、CodeT5+、StarCoder;
- 混合框架:EACS(提取+生成)。
3. 评估指标:自动+人工双维度
- 自动指标:BLEU-4(衡量流畅性)、METEOR(兼顾精度和召回)、ROUGE-L(衡量长文本重合度);
- 人工指标:3位5年以上经验的工程师,从"流畅性、语义准确性、信息完整性、简洁性、风格匹配"5个维度评分(1-5分),Kappa系数0.672(高度一致)。
主要成果和贡献:DHCS到底"厉害"在哪?
一、性能:所有指标碾压基线
在三大数据集上,DHCS的表现全面领先,以关键指标BLEU-4为例:
| 模型 | Python BLEU-4 | Java BLEU-4 | Go BLEU-4 |
|---|---|---|---|
| 基线最优EACS | 18.10% | 16.38% | 17.28% |
| DHCS | 18.62% | 18.59% | 18.05% |
| 大模型StarCoder | 16.90% | 17.25% | 14.75% |
人工评估中,DHCS在"语义准确性"(4.3分)和"信息完整性"(4.2分)上优势最明显,比如案例中Python函数的注释,DHCS生成"重加密用户的所有文件和检查点",而CodeT5只生成"重加密用户内容",精准度差距显著。
二、消融实验:证明每个创新都有用
通过对比DHCS的4种变体,验证了三大创新的必要性:
| 模型变体 | Python BLEU-4 | 性能下降原因 |
|---|---|---|
| DHCS(完整版) | 18.62% | 基准 |
| 无MSP(DHCS w/o msp) | 18.25% | MSP能强化子函数理解 |
| 无主题机制(w/o twc) | 18.40% | 主题机制能精准提取关键词 |
| 无MSP+无主题(w/o msp&twc) | 18.13% | 两者协同效果最好 |
| 无子函数增强(w/o subfunc) | 17.69% | 子函数依赖是核心语义来源 |
三、效率:小参数量也能赢大模型
StarCoder参数量达15517M(150亿),而DHCS基于CodeT5(223M),参数量仅为StarCoder的1.4%,但训练/推理时间仅为StarCoder的1/10,实现了"性能+效率"双优。
四、核心贡献
- 领域层面:开创"依赖感知"代码注释研究方向,构建3个含子函数依赖的数据集,填补领域空白;
- 技术层面:提出分层编码器、MSP自监督任务、主题感知复制机制三大创新,为后续研究提供参考;
- 应用层面:可直接用于Python/Java/Go项目的自动注释生成,尤其适合子函数调用多的复杂代码,减轻程序员文档负担。
(注:文档中未提及开源代码及数据集下载地址,若后续开源可关注作者团队或中国科学院软件研究所官网。)
关键问题:解答你最关心的核心疑问
Q1:DHCS是如何解决"忽略函数依赖"这个核心问题的?
A:主要靠两点:一是"分层编码器",分开学习子函数和目标函数的语义,再通过"合并融合"把子函数信息精准融入目标函数;二是"主题感知复制机制",从子函数的主题分布中提取关键信息,确保注释不会漏掉子函数相关的逻辑。比如目标函数调用"时间提取"子函数,DHCS会把"年/月/日"这些子函数主题词融入注释,而现有模型只会笼统说"处理时间"。
Q2:DHCS和GPT-3.5-turbo、StarCoder这些大模型比,优势在哪?
A:大模型的问题是"没针对性":一是它们用无监督训练,没适配代码注释的"依赖关系"场景;二是参量大(StarCoder 150亿参),训练推理慢。DHCS则是"精准优化":针对依赖关系设计模块,参量小(223M)、效率高,同时性能更好------比如Python BLEU-4,DHCS 18.62%>GPT-3.5-turbo 15.56%>StarCoder 16.90%。
Q3:如果函数名称被改了(比如把"reencrypt"改成"funcA"),DHCS还能生成准确注释吗?
A:能!实验中测试了"函数名称掩码"和"随机替换"两种情况,DHCS的性能下降幅度比基线小。比如Python BLEU-4,DHCS从18.62%降到16.36%,而CodeT5从17.69%降到15.67%。因为DHCS看的是子函数的语义,不是名字,就算名字改了,也能通过子函数的代码逻辑理解功能。
Q4:DHCS能用于其他编程语言吗?
A:目前实验验证了Python、Java、Go三种,未来可以扩展。因为DHCS的核心是"建模函数依赖关系",这种逻辑在C++、JavaScript等其他编程语言中也通用,只要构建对应语言的"含子函数依赖"数据集,就能适配。
总结
DHCS模型的核心价值,在于第一次把"函数依赖关系"纳入代码注释生成的核心逻辑,解决了现有模型的"语义盲区"。它通过分层编码、自监督训练、主题复制三大创新,在保证效率的同时,显著提升了注释的精准度和完整性。
对于研究者来说,DHCS开创了"依赖感知"的新研究方向,提供了可复用的技术模块;对于开发者来说,它能为复杂代码(尤其是子函数多的函数)自动生成更有用的注释,减少手动文档的工作量。未来如果能扩展到更多编程语言,或结合大模型的上下文能力,相信会有更广阔的应用场景。