目录
在pandas中,Series.drop_duplicates(keep=, inplace=)方法用于删除Series对象中的重复值。
-
keep:-
决定保留哪些重复值。可以取以下三个值之一:
-
'first'(默认值):保留第一次出现的重复值。 -
'last':保留最后一次出现的重复值。 -
False:删除所有重复值。
-
-
-
inplace:- 这是一个布尔值参数。如果为
True,则直接在原始Series上进行修改,不会返回新的Series。如果为False(默认值),则会返回一个新的Series,原始的Series保持不变。
- 这是一个布尔值参数。如果为
准备数据
import pandas as pd
df = pd.read_csv("../data/b_LJdata.csv")
df.head()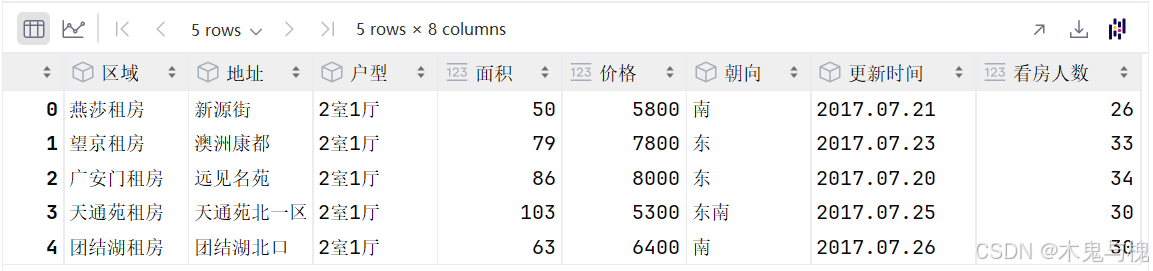
Series数据去重
-
对 朝向 构成的 Series对象 去重, 保留第一条, 不影响原始对象
1 对 朝向 构成的 Series对象 去重, 保留第一条, 不影响原始对象
1.1 准备数据
chaoxiang_series = df.head()['朝向']
print('------------ 去重前 ----------------')
print(chaoxiang_series)1.2 去重
new_series = chaoxiang_series.drop_duplicates(keep='first', inplace=False)
print('==================')
print(new_series)
print('==================')print('------------ 去重后 ----------------')
print(chaoxiang_series)

2) 对 朝向 构成的 Series对象 去重, 保留最后一条, 不影响原始对象
# 2 对 朝向 构成的 Series对象 去重, 保留最后一条, 不影响原始对象
# 2.1 准备数据
chaoxiang_series = df.head()['朝向']
print('------------ 去重前 ----------------')
print(chaoxiang_series)
# 2.2 去重
new_series = chaoxiang_series.drop_duplicates(keep='last', inplace=False)
print('==================')
print(new_series)
print('==================')
print('------------ 去重后 ----------------')
print(chaoxiang_series)
3) 对 朝向 构成的 Series对象 去重, 删除所有重复, 不影响原始对象
# 3 对 朝向 构成的 Series对象 去重, 删除所有重复, 不影响原始对象
# 3.1 准备数据
chaoxiang_series = df.head()['朝向']
print('------------ 去重前 ----------------')
print(chaoxiang_series)
# 3.2 去重
new_series = chaoxiang_series.drop_duplicates(keep=False, inplace=False)
print('==================')
print(new_series)
print('==================')
print('------------ 去重后 ----------------')
print(chaoxiang_series)
4) 对 朝向 构成的 Series对象 去重, 保留第一条, 影响原始对象
# 4 对 朝向 构成的 Series对象 去重, 保留第一条, 影响原始对象
# 4.1 准备数据
chaoxiang_series = df.head()['朝向']
print('------------ 去重前 ----------------')
print(chaoxiang_series)
# 4.2 去重
new_series = chaoxiang_series.drop_duplicates(keep='first', inplace=True)
print('==================')
print(new_series)
print('==================')
print('------------ 去重后 ----------------')
print(chaoxiang_series)
5) 对 朝向 构成的 Series对象 去重, 保留最后一条, 影响原始对象
# 5 对 朝向 构成的 Series对象 去重, 保留最后一条, 影响原始对象
# 5.1 准备数据
chaoxiang_series = df.head()['朝向']
print('------------ 去重前 ----------------')
print(chaoxiang_series)
# 5.2 去重
new_series = chaoxiang_series.drop_duplicates(keep='last', inplace=True)
print('==================')
print(new_series)
print('==================')
print('------------ 去重后 ----------------')
print(chaoxiang_series)
6) 对 朝向 构成的 Series对象 去重, 删除所有重复, 影响原始对象
# 6 对 朝向 构成的 Series对象 去重, 删除所有重复, 影响原始对象
# 6.1 准备数据
chaoxiang_series = df.head()['朝向']
print('------------ 去重前 ----------------')
print(chaoxiang_series)
# 6.2 去重
new_series = chaoxiang_series.drop_duplicates(keep=False, inplace=True)
print('==================')
print(new_series)
print('==================')
print('------------ 去重后 ----------------')
print(chaoxiang_series)
*7)*简化
# 7 简化
# 7.1 准备数据
chaoxiang_series = df.head()['朝向']
print('------------ 去重前 ----------------')
print(chaoxiang_series)
# 7.2 去重
new_series = chaoxiang_series.drop_duplicates()
print('==================')
print(new_series)
print('==================')
print('------------ 去重后 ----------------')
print(chaoxiang_series)
DataFrame数据和Series数据去重对比
DataFrame数据去重,最终呈现的是数据集合
temp_df = df.head().copy()
# 对df所有列去重, 当前df没有重复的行数据
print(temp_df.drop_duplicates())
print("=================================")
# 根据指定列对df去重, 默认保留第一条数据
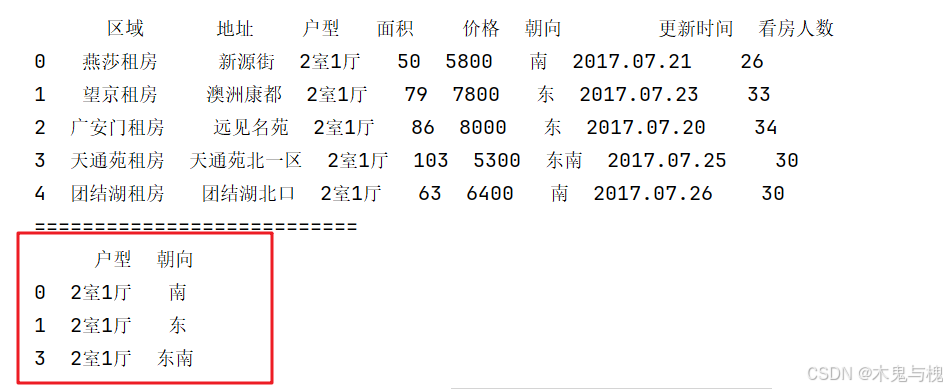
# 第1行和第5行、第2行和第3行重复
print(temp_df.drop_duplicates(subset=['户型', '朝向']))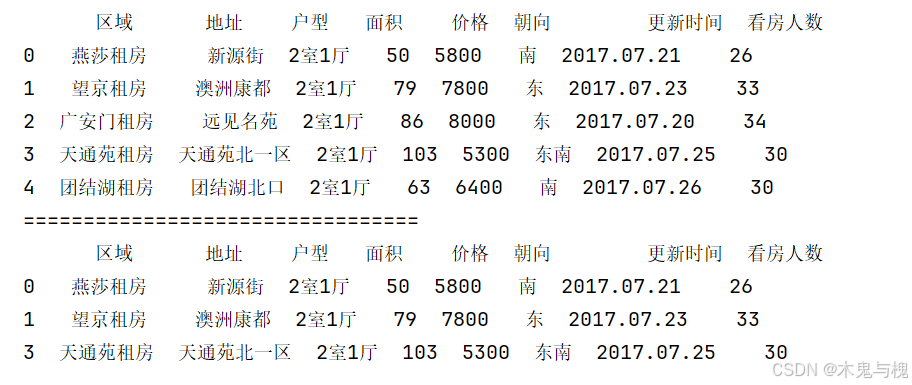
Series数据去重,最终呈现是一列数据
temp_df = df.head().copy()
# 默认保留第一条数据
print(temp_df.drop_duplicates())
print("===========================")
print(temp_df[['户型','朝向']].drop_duplicates())