今天给大家介绍阿里最近开源的个性化图像生成的新方法MIP-Adapter,将无需微调的预训练模型(IP-Adapter)推广到同时合并多个参考图像。MIP-Adapter会根据每个参考图像与目标对象的相关性来给这些图像分配不同的"重要性分数"。这样,在生成图像时,系统能更好地理解每个对象应该如何表现,从而生成更高质量的图像。
值得注意的是,该模型只需在 8 个 GPU 上进行5 小时的训练,就可以在多对象个性化图像生成方面实现最先进的性能。
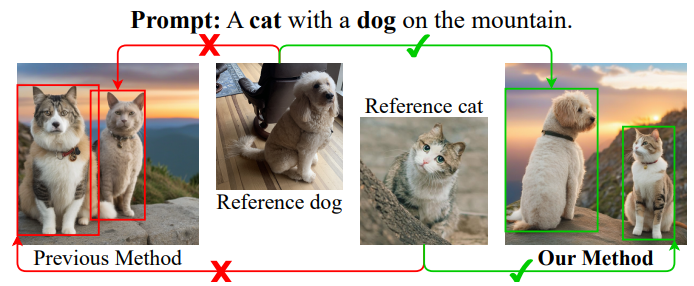
左图展示了解耦交叉注意机制下的目标混淆问题,右图展示了使用我们的方法正确生成的问题。
亮点直击
-
作者将无需微调的个性化图像生成方法的解耦交叉注意机制扩展到合并多种条件,并提出了一种加权合并方法来解决对象混淆问题。
-
文章从开源 SA-1B 数据集中构建了一个小而高质量的数据集用于模型训练,并提出了一个用于图像选择的对象质量分数。
-
加权合并训练框架在合并多种条件方面表现出色,MIP-Adapter在多对象个性化图像生成的 Concept101 数据集和 DreamBooth 数据集上均实现了最佳性能。
相关链接
论文地址:http://arxiv.org/abs/2409.17920v1
代码地址:https://github.com/hqhQAQ/MIP-Adapter
数据集地址:https://huggingface.co/datasets/hqhQAQ/subject_dataset_10k/tree/main
论文阅读

解决多条件混乱,实现免微调个性化图像生成
介绍
个性化文本到图像生成方法可以基于参考图像生成定制图像,这引起了广泛的研究兴趣。最近的方法提出了一种无需微调的方法,具有解耦的交叉注意机制,可以生成不需要测试时微调的个性化图像。然而,当提供多个参考图像时,当前解耦的交叉注意机制遇到对象混淆问题并且无法将每个参考图像映射到其对应的对象,从而严重限制了其应用范围。为了解决对象混淆问题,
在这项工作中,作者研究了扩散模型中潜在图像特征的不同位置与目标对象的相关性,并相应地提出了一种加权合并方法,将多个参考图像特征合并到相应的对象中。然后将这种加权合并方法集成到现有的预训练模型中,并继续在根据开源 SA-1B 数据集构建的多对象数据集上训练模型。为了减轻对象混乱并降低训练成本,在文章中提出了对象质量评分估计图像质量,以选择高质量的训练样本。
方法
方法的框架如下所示:
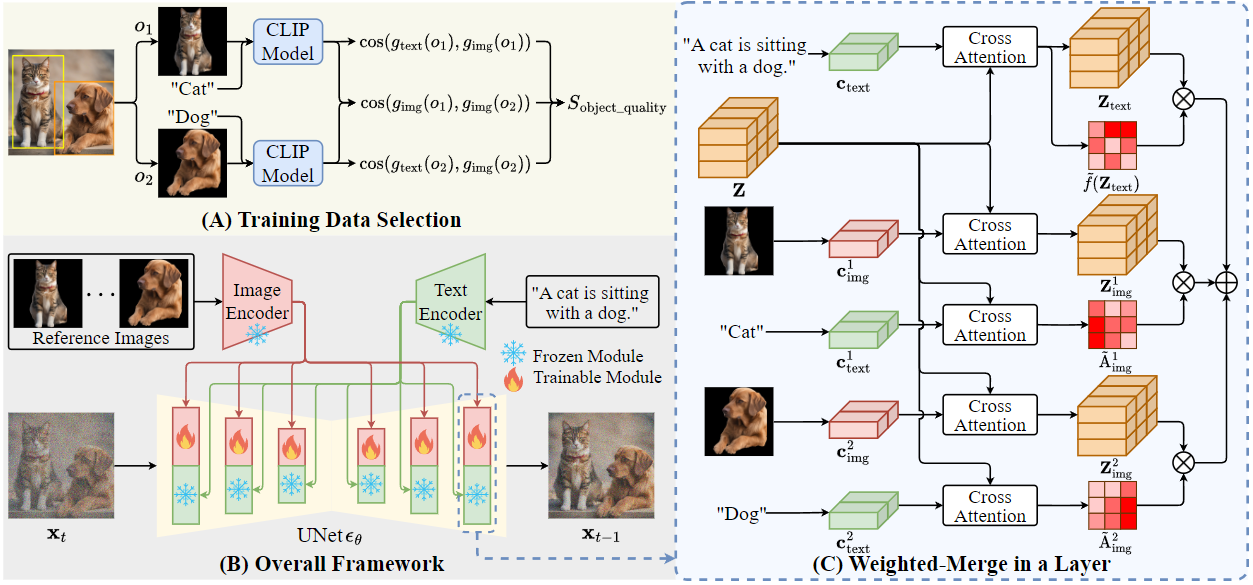
(A)演示了用于选择训练数据的 Sobject 相关性的计算。(B)中的整体框架包括一个以文本提示和多个参考图像为条件的 UNet 噪声预测模型。(C)展示了(B)中 UNet 中每个交叉注意层中提出的加权合并方法。
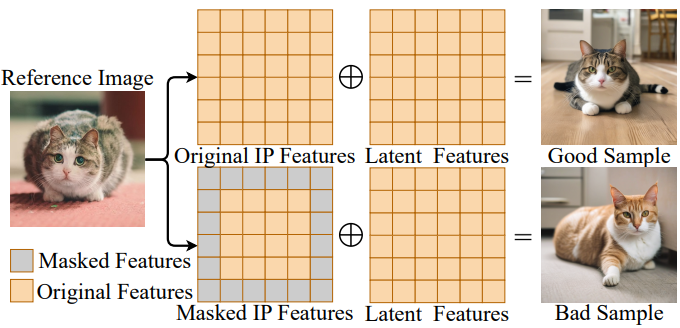
背景被遮挡的参考图像特征降低了IP- adapter的生成质量。
实验

多目标个性化图像生成方法的定性比较。

定性消融实验。

一个具有多个参考图像的单对象个性化图像生成的可视化示例。
结论
本文给大家介绍了阿里推出的个性化图像生成的新方法MIP-Adapter,特别是当我们有多个参考图像时。通常,当我们希望生成一个包含多个对象的图像时,比如一只猫和一只狗,现有的方法常常会出现混淆,导致猫和狗的特征被错误地匹配。为了避免这种情况,研究者们设计了一种"加权合并"技术。简单来说,他们会根据每个参考图像与目标对象的相关性来给这些图像分配不同的"重要性分数"。这样,在生成图像时,系统能更好地理解每个对象应该如何表现,从而生成更高质量的图像。此外,他们还通过选择高质量的训练样本来提升模型的表现,确保生成的图像既真实又符合用户的期望。