一、添加依赖
我们使用spring本身支持的spring-kafka依赖,但是需要注意版本问题,不同的springboot版本支持不同的kafka版本,避免因版本不同带来困扰!参考下图:
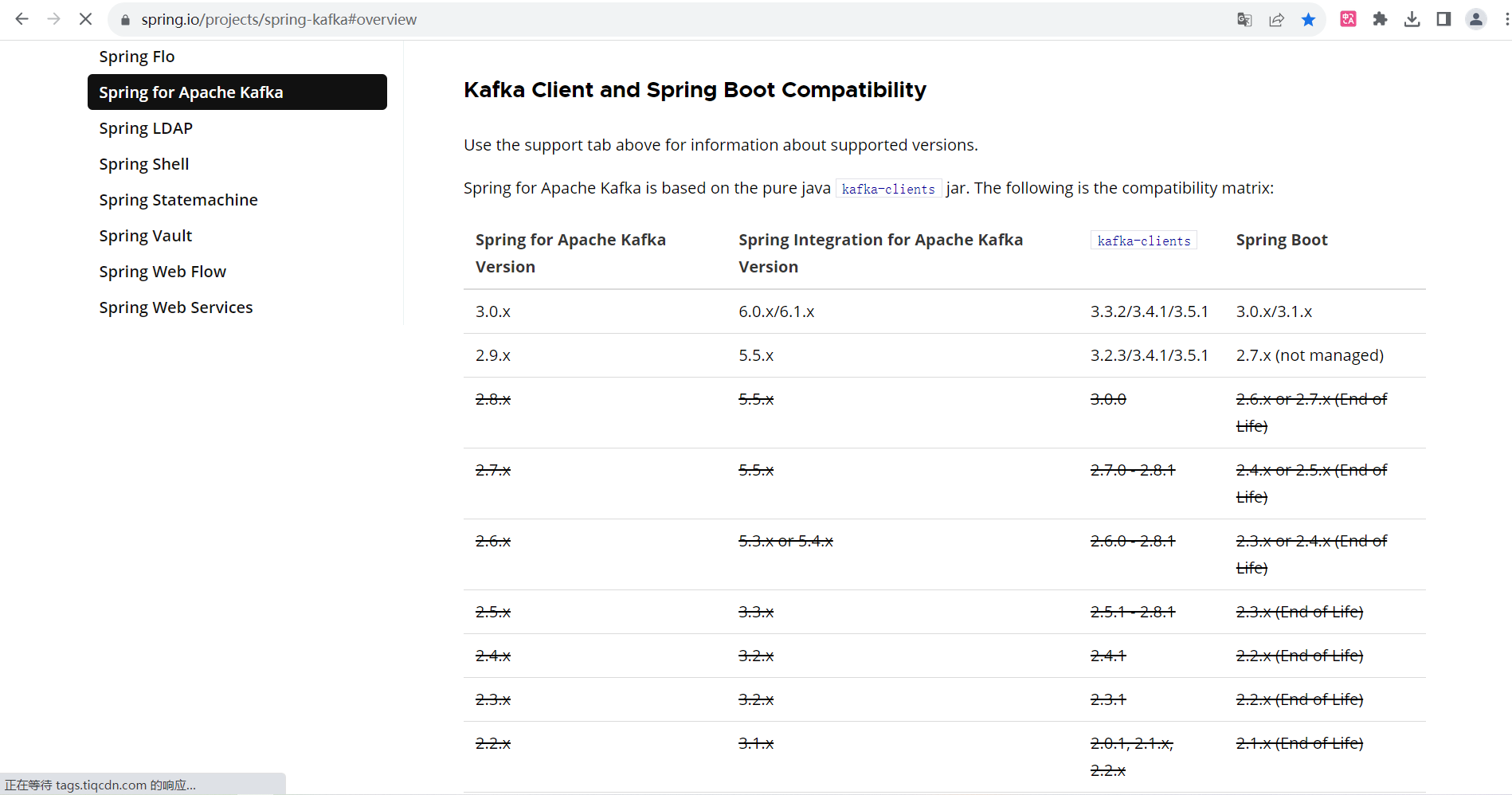
或者访问官网查看版本对应关系:Spring for Apache Kafka
本教程springboot版本使用的是2.6.13,对应kafka版本为2.8.x以上。
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.6.13</spring-boot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- kafka依赖 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.8.10</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>二、配置application.yml
application.yml文件添加kafka配置,kafka配置有很多,此教程只使用了部分,后续有时间会对其他配置再做研究。
# 应用服务web访问端口
server:
port: 8088
spring:
#kafka配置
kafka:
bootstrap-servers: 192.168.219.200:9092
producer:
# 发生错误后,消息重发的次数
retries: 0
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: test-consumer-group
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 当消费者监听的topic不存在时,保证项目能够启动。
missing-topics-fatal: false三、代码实现
生产者
package com.studykafka.springkafka.demos.kafka;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
/**
* Kafka生产者
*
* @author xiafan
* @Date 2023-09-01 13:48
*/
@Component
public class KafkaProducer {
private static final Logger log= LoggerFactory.getLogger(KafkaProducer.class);
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
/**
* 生产者简单发送消息
* @param topic
* @param msg
*/
public void send(String topic,String msg){
log.info("topic为:{},发送消息内容:{}", topic, msg);
kafkaTemplate.send(topic,msg);
}
}消费者
package com.studykafka.springkafka.demos.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* kafka消费者
*
* @author xiafan
* @Date 2023-09-01 13:48
*/
@Component
public class KafkaConsumer {
private static final Logger log= LoggerFactory.getLogger(KafkaConsumer.class);
/**
* 消费者监听消息
*
* @param record
*/
@KafkaListener(topics = {"demo"})
public void onMessage(ConsumerRecord<?, ?> record){
//消费的哪个topic、partition的消息,打印出消息内容
log.info("简单消费topic为:{},分区partition为:{},内容为:{}", record.topic(),
record.partition(), record.value());
}
}测试类
package com.studykafka.springkafka.demos.web;
import com.studykafka.springkafka.demos.kafka.KafkaProducer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
/**
* kafka测试类
*
* @author xiafan
* @Date 2023-09-01 14:12
*/
@RequestMapping("/kafka")
@RestController
public class KafkaController {
@Autowired
private KafkaProducer kafkaProducer;
@GetMapping("/sendMsg")
public void sendMsg(@RequestParam String message){
kafkaProducer.send("demo", message);
}
}输入http://ip:port/kafka/sendMsg,观察控制台打印信息,消费者输出的信息为:

从上结果可以看到 -》topic:demo,partition:8,已经消费了消息。
我们从kafka-ui界面也可以看到分区8增加了一条消息:
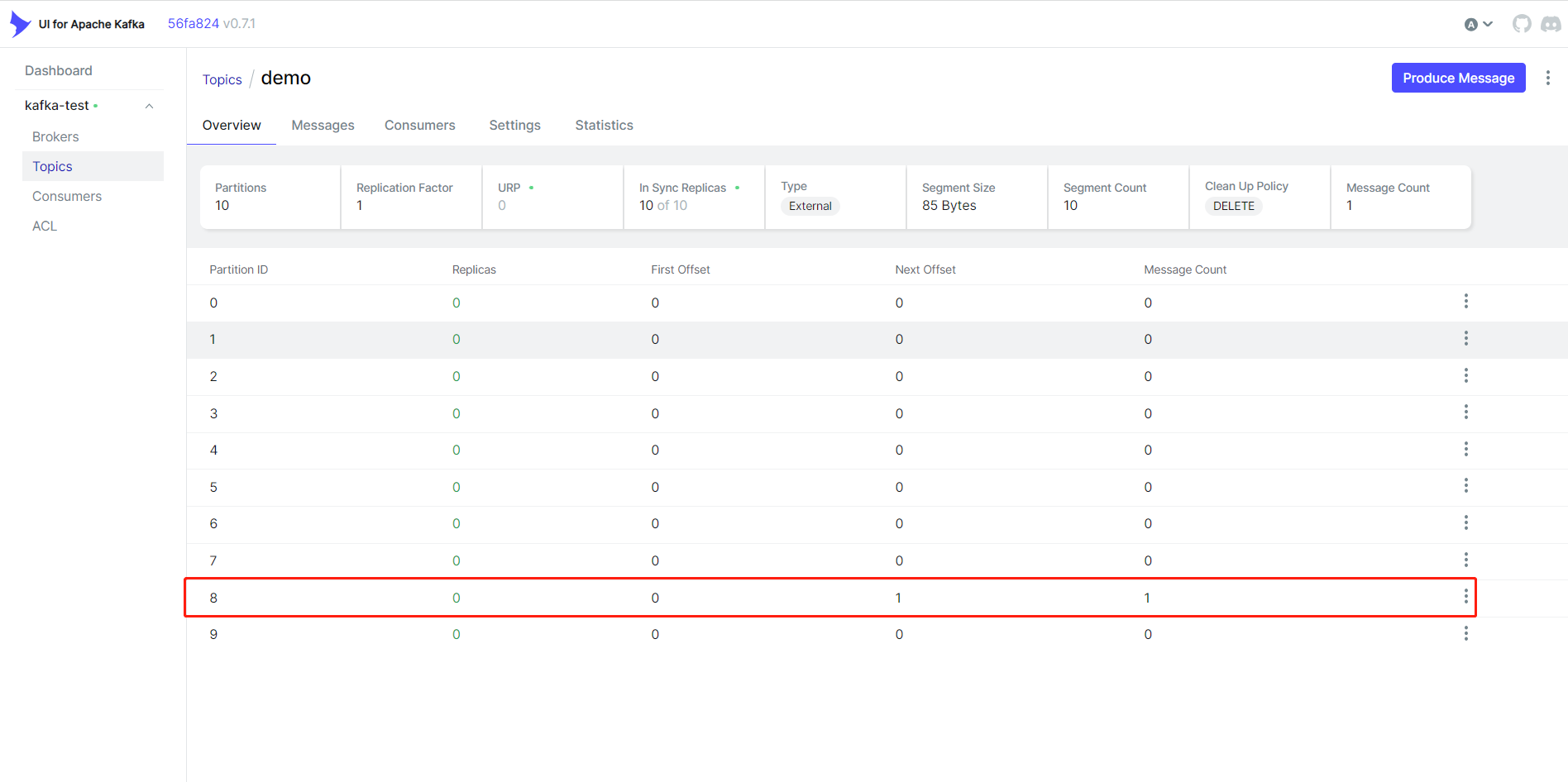

为什么会有10个分区呢?还记得在上一章节Linux安装kafka中,设置了num.partitions=10,所以在发送消息时,kafka会自动创建10个分区,并将消息负载均衡到分区8消费了。
而offset是当前partition中的数据个数的偏移量,从0开始,Next Offset是下一次消息的偏移量。
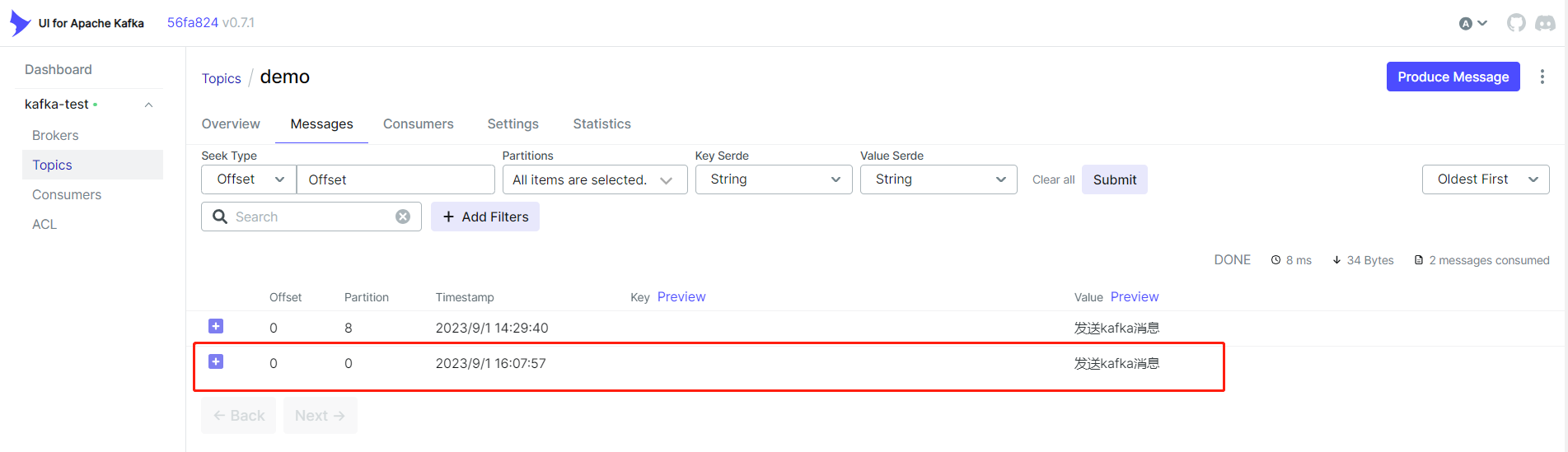
再次调用一次,发现消息被分区0消费了(负载均衡)。
到此为止,已经完成了springboot和kafka的集成!