每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

Tx-LLM是一款专门优化,用于预测生物实体属性的大型语言模型(LLM),它覆盖了整个治疗药物开发管道,从早期靶点发现到晚期临床试验批准。
治疗药物的临床试验失败率高,即便成功,通常也需要10到15年、耗资10到20亿美元才能开发完成。原因在于开发过程繁琐,且治疗药物需要满足多种独立标准。比如,药物必须与特定靶点结合,避免与其他实体产生作用,从而实现所需功能而不引发副作用。此外,药物还需要有效抵达目标部位、在体内适时清除,并能够规模化生产。实验测量这些特性费时费钱,因而使用机器学习(ML)进行快速预测成为一种替代方案。
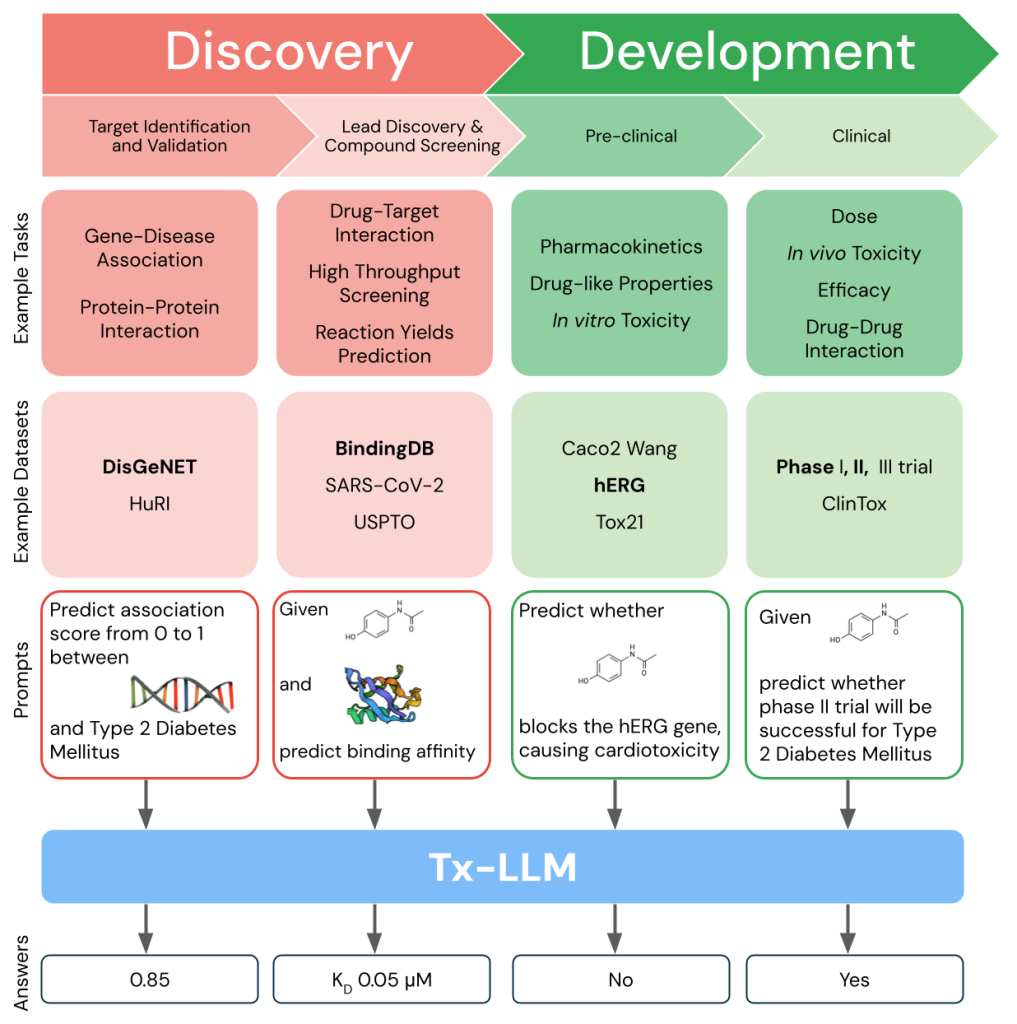
因此,Tx-LLM应运而生。该模型基于PaLM-2进行了微调,能够预测与药物开发相关的多个实体属性,如小分子、蛋白质、核酸、细胞系及疾病等。Tx-LLM在66个药物发现数据集上进行了训练,覆盖从早期靶基因识别到临床试验批准的多个环节。在43项任务上,Tx-LLM的表现达到了当前最先进模型的水平,并在22项任务上超越了它们。值得注意的是,Tx-LLM不仅可以结合分子信息与文本信息,还能在不同类型的治疗任务之间实现能力迁移,成为贯穿药物开发全流程的单一模型。

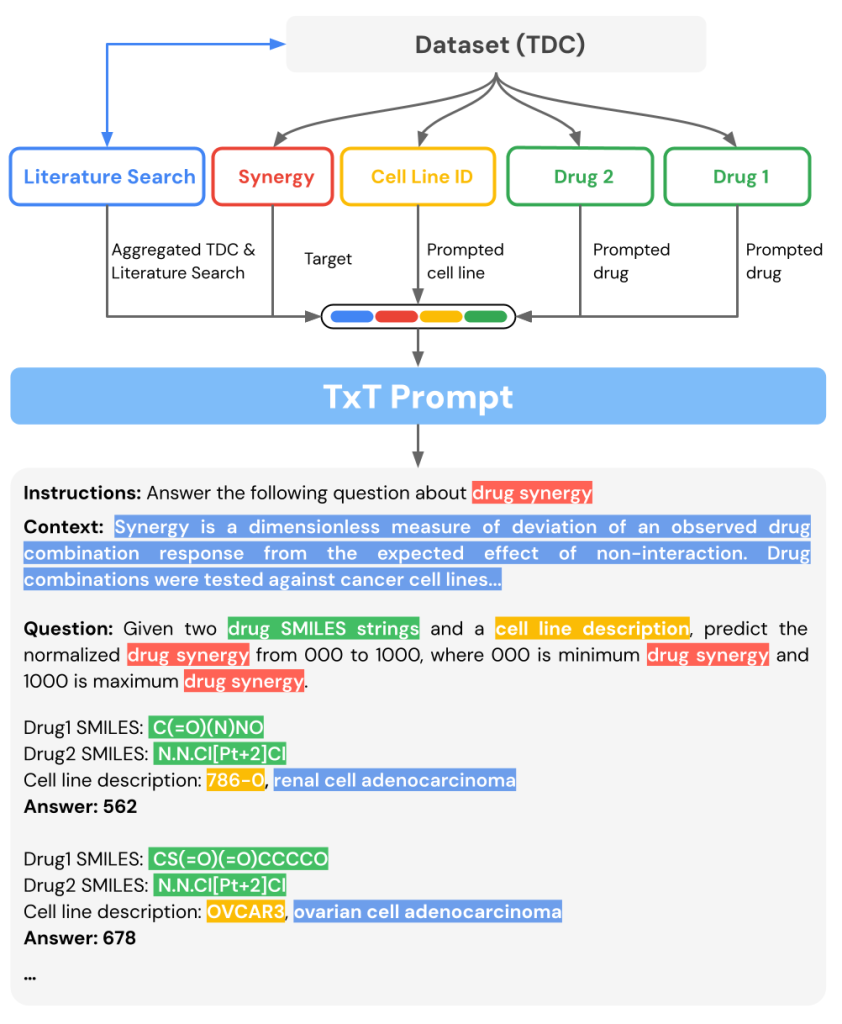
Tx-LLM的训练依赖精心整理的"治疗指令调优"(TxT)数据集,它涵盖709个与治疗药物开发相关的数据集。通过将Therapeutic Data Commons(TDC)中的66项任务数据转化为适合LLM训练的指令-回答格式,Tx-LLM得以提升其在多种任务上的表现。TxT数据集的构建不仅依赖TDC,还引入了文献中的额外信息,使得模型能够区分子任务。此外,部分特性直接以文本形式展示(如细胞系),这使得模型能更好地利用其自然语言预训练能力。
在性能测试中,Tx-LLM在许多任务上展现了强大的数值预测能力,这在以往的LLM中并不常见。特别是在处理小分子与文本结合的任务时,Tx-LLM表现尤其出色。例如,在给定药物和疾病名称的情况下预测药物是否会被批准,Tx-LLM的表现优于现有的顶尖模型。
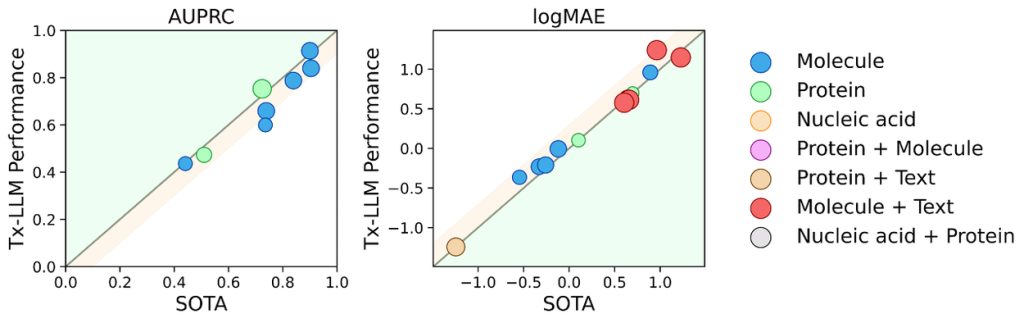
虽然Tx-LLM在多个任务中表现出色,但它仍有改进空间,特别是在解释其预测结果时。未来,随着模型继续发展,它可能会对整个治疗药物开发过程产生深远影响,大幅缩短开发时间、降低成本。
目前,团队正评估如何将Tx-LLM的能力开放给外部研究人员使用。如果有兴趣探索该模型的应用,欢迎与团队联系。了解外部的实际需求将有助于推动模型的进一步优化与发展。