知乎:LLM迷思(已授权)
Zijie大佬的最新工作,拜读了一下,对于我之前一些工作很有启发。包括之前"介绍LLM迷思:【分布式训练技术分享十二】Skywork-MoE 技术报告细节分析"中的一些结论和我之前mark的LLAMA PRO和"weight-selection" 的一些思考在这篇文章中都有体现。LLM发展到现在一些共性的结论,业界是比较一致,期待NVIDIA能多来点基础实验性的工作,毕竟计算资源太宝贵了。喜欢这个系列的,记得一键三连。
1. 摘要
将预训练的稠密语言模型Upcycling为稀疏专家混合(MoE)模型是一种提高已训练模型容量的有效方法。然而,如何在大规模上进行最佳的Upcycling技术仍不明确。在这项工作中,作者对十亿参数规模语言模型的Upcycling方法和超参数进行了广泛研究。作者提出了一种新颖的"虚拟组"初始化方案和权重缩放方法,以支持Upcycling到更精细的MoE架构。通过消融实验,作者发现Upcycling模型优于继续训练稠密模型。此外,作者表明,先Softmax再TopK的专家路由方法优于先TopK再Softmax的方法(我的理解是需要配合虚拟组优化才是算法合理),并且更高Granularity的MoE有助于提高模型精度。最后,作者对Nemotron-4 15B模型在1万亿个tokens上进行了Upcycling,并与同样在1万亿个tokens上连续训练的模型进行了比较:连续训练的模型在MMLU上达到了65.3%,而Upcycling后(主要针对不scaling的模型)的模型达到了67.6%。作者的结果为有效利用Upcycling构建MoE语言模型提供了见解和最佳实践。
2. 介绍
稀疏专家混合(MoE)模型近年来越来越受欢迎,因为它们可以在不显著增加计算成本的情况下实现更好的精度。最先进的大型语言模型(LLM)如Grok-11、DBRX2、Phi-3.53、Mixtral 8x22B、DeepSeekV2和Qwen2都是MoE模型。将预训练的稠密语言模型Upcycling为稀疏专家混合模型(在本文中简称为"Upcycling")已经成为一种提高模型容量的有效方法,无需从头开始训练。通过利用现有密集模型的知识检查点,Upcycling使得在减少训练时间和计算成本的同时,能够构建大规模的MoE模型。
大多数关于模型Upcycling的先前研究要么未提供具体的Upcycling细节,要么只在小规模上进行了实验。作者还发现,有些建议会导致次优模型。为了改进对模型Upcycling方法的普遍认识,作者发布了这项关于十亿参数规模语言模型的Upcycling方法及最佳实践的研究。在这项工作中,作者对Upcycling技术和超参数进行了广泛的研究。作者的主要贡献如下:
-
作者提供了一套训练配方,能够一致地将十亿参数规模的LLM进行Upcycling。
-
作者对学习率、批量大小和平衡损失等超参数进行了全面的研究,以找到最优的Upcycling参数。
-
作者提出了一种新颖的"虚拟组"初始化方案,支持Upcycling到细Granularity的MoE架构,并提出了一种权重缩放方法,使得粗Granularity和细Granularity的MoE模型的损失减少了1.5%。
-
他们比较了先Softmax再TopK的专家路由方法与先TopK再Softmax的方法。
-
作者评估了更高Granularity的MoE模型和使用更高的TopK值的好处。
3. 方法
3.1 稀疏专家混合(MoE)
在本研究中,作者仅研究了MoE在Transformer的MLP层中的应用。MLP层占用了大部分计算资源,并且每个tokens(token)是单独处理的,从而避免了与kv-cache一致性相关的问题。一个路由层将tokens路由到多个可能的MLP层的子集。这种方法增加了参数数量,从而提升了模型的容量,但并不会必然增加所需的计算量(以总训练FLOPs衡量)。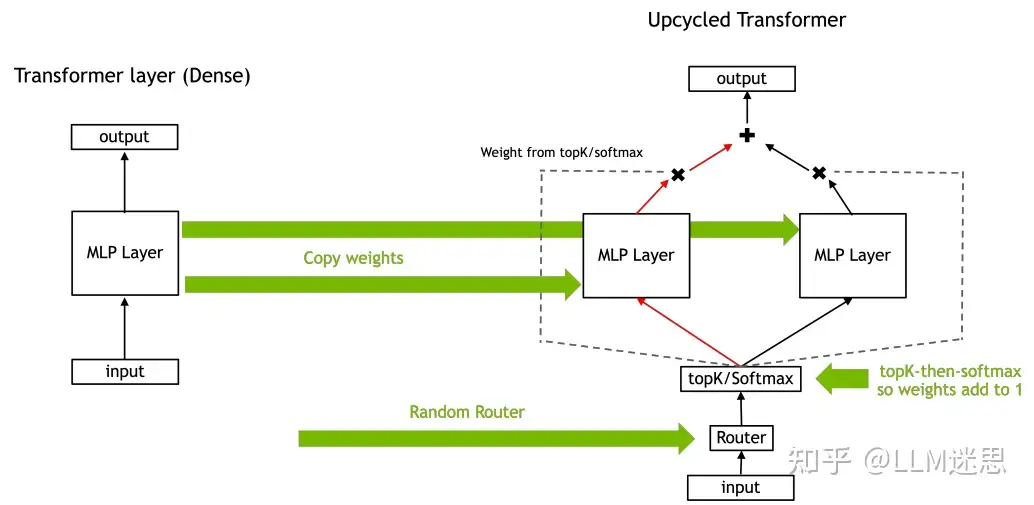
3.1.1 Upcycling
Upcycling是一种将训练好的稠密模型转换为MoE模型的方法。将稠密模型转换为MoE模型而不丧失准确性的一种最直接的方法是将MLP层的权重复制多次,并使用随机化的路由器,按照每个MLP层的概率加权其输出: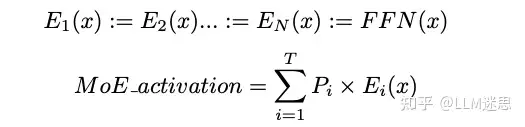 其中, 是具有路由器概率 的MLP专家,, 是从注意力机制的输出, 是MoE层中的专家总数, 是每个tokens被路由到的专家数量(即topK)。
其中, 是具有路由器概率 的MLP专家,, 是从注意力机制的输出, 是MoE层中的专家总数, 是每个tokens被路由到的专家数量(即topK)。
3.1.2 Softmax - TopK 顺序
标准的MoE路由器公式是在路由器的logits上先执行Softmax,然后再执行TopK操作(即Softmax-then-TopK)。随后,来自专家的激活值会乘以Softmax概率。在这种情况下,每个专家的权重通过以下公式确定: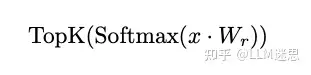 其中, 是输入到MoE模块的数据, 是路由器权重矩阵。
其中, 是输入到MoE模块的数据, 是路由器权重矩阵。
这种方法在模型Upcycling时会带来一个问题:在TopK < N的情况下,Upcycling后的模型的输出与稠密模型的输出并不等价。虽然在模型Upcycling后,MoE模型的输出与稠密模型的输出不相等,但通过训练几个步骤,模型可能能够适应这种变化。
另一种解决该问题的方法是直接在路由器的logits上使用TopK操作,然后仅使用这些TopK专家的logits来进行Softmax计算(即TopK-then-Softmax)。在这种情况下,每个专家的权重通过以下公式确定: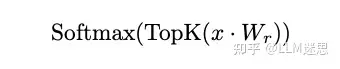 然而,这种方法的缺点是路由器输出的绝对幅度信息会丢失。此外,这种方法仅适用于TopK > 1的情况,因为单个元素的Softmax是常数1,对输入没有梯度。该技术曾用于Mixtral模型。
然而,这种方法的缺点是路由器输出的绝对幅度信息会丢失。此外,这种方法仅适用于TopK > 1的情况,因为单个元素的Softmax是常数1,对输入没有梯度。该技术曾用于Mixtral模型。
3.2 Granularity
早期关于MoE的研究将每个tokens路由到非常少数量的专家(topK = 1或2)。虽然MoE拥有更多的参数,但只路由到一个专家可以确保训练的FLOPs与稠密模型相似。然而,最近有建议提出,将tokens路由到更多的专家,同时缩小每个专家的维度,可能是一种更优的方式。这种方法被称为细Granularity的专家混合,如图2所示。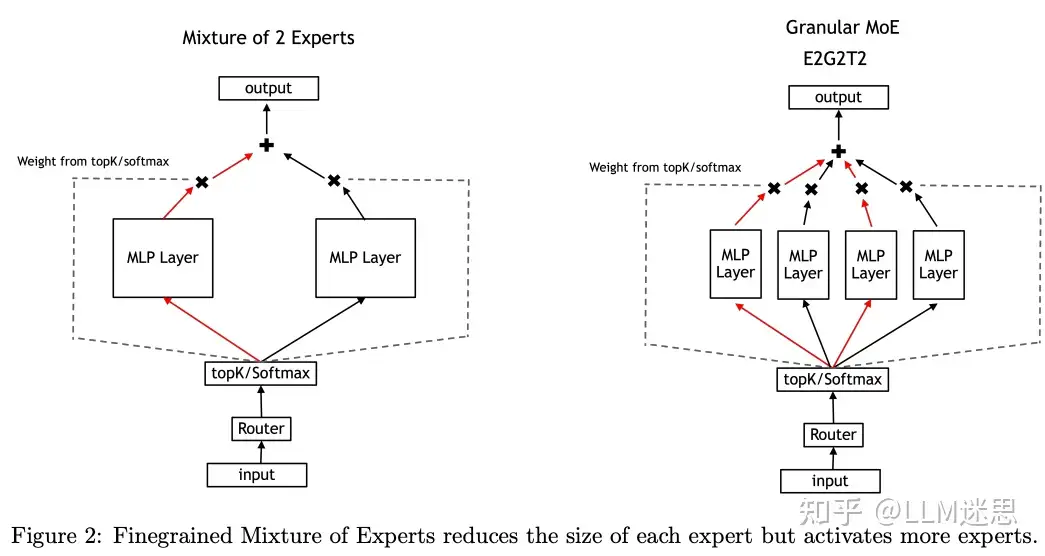 Granularity引入了一种新的自由度,因为每个专家的规模可以缩小。由于缩小专家的规模减少了每个专家的FLOPs,这种方法允许作者以相同比例增加topK的值,同时保持总体FLOPs数量不变。虽然FLOPs只是训练或部署模型所需实际计算量的一个近似指标,但它仍然是比较计算成本时的一个有用且易于使用的度量标准。
Granularity引入了一种新的自由度,因为每个专家的规模可以缩小。由于缩小专家的规模减少了每个专家的FLOPs,这种方法允许作者以相同比例增加topK的值,同时保持总体FLOPs数量不变。虽然FLOPs只是训练或部署模型所需实际计算量的一个近似指标,但它仍然是比较计算成本时的一个有用且易于使用的度量标准。
细GranularityMoE架构由三个超参数定义。作者使用提出的命名法,并添加了一个术语T来表示topK。这三个超参数的定义如下:
-
E: 扩展率。MoE层的总参数数量与对应的稠密MLP相比增大了多少倍。即
-
G: Granularity。专家隐藏层的大小与原始稠密层的FFN隐藏层大小相比缩小了多少倍。即
-
T: TopK。tokens被路由到多少个专家。
例如,在图2中,从左到右展示的是粗GranularityMoE(E2G1T1)和细GranularityMoE(E2G2T2)。
3.3. Granular Upcycling
与标准的MoEUpcycling不同,标准MoEUpcycling方法可以将稠密MLP的权重直接复制到MoE专家中,而细GranularityMoE则缩小了每个MoE专家的尺寸,这使得将稠密MLP的权重复制到MoE专家中变得不再简单。
将一个稠密模型Upcycling为细GranularityMoE的直观方法是:
-
在FFN维度上将稠密层分割成多个分片(G)。
-
将每个分片复制多次(E)。
-
在训练时将tokens路由到某些专家(T)。
例如,将稠密层分割为8个分片,然后复制8次,最终得到64个专家。然而,作者发现使用这种简单的方法会导致模型损失非常高,网络无法收敛到原始损失值。这种方法有两个问题:
-
专家输出被路由器缩减。对于具有8个专家和top-2设置的模型(E8G1T2),一种直接的Upcycling方法是使用topK-then-softmax路由器,确保topK的概率之和为1。然而,对于细Granularity的MoE,即使使用topK-then-softmax策略,输出仍然会被缩减。对于64个专家的MoE和top-8模型(E8G8T8),如果使用topK-then-softmax策略,输出会被缩减到原来的1/8。如果使用softmax-then-topK策略,由于随机初始化,路由器的概率大约为1/64,这意味着专家输出会被缩减到原来的1/64。
-
MoE在前向传递中不再与稠密模型功能相似。对于粗Granularity的MoE,使用topK-then-softmax策略时,Upcycling后的模型在训练初期在前向传递上与稠密模型功能上是相同的。然而,对于细Granularity的MoE,由于专家被分割成较小的分片,路由器必须从每个分片中精确选择一个副本,才能像稠密MLP层一样工作。
基于这两个观察结果,作者提出了用于细GranularityMoEUpcycling的权重缩放和虚拟分组方法。该方法如图3所示。作者使用虚拟分组初始化来初始化路由器。虚拟分组初始化确保在稠密模型转换为MoE后,路由器的topK中精确包含每个MLP分片的一个副本。虚拟分组初始化的专家和路由器权重确保:
-
每个路由器组拥有稠密MLP分片的精确副本。
-
所有路由器组具有相同的路由器权重。
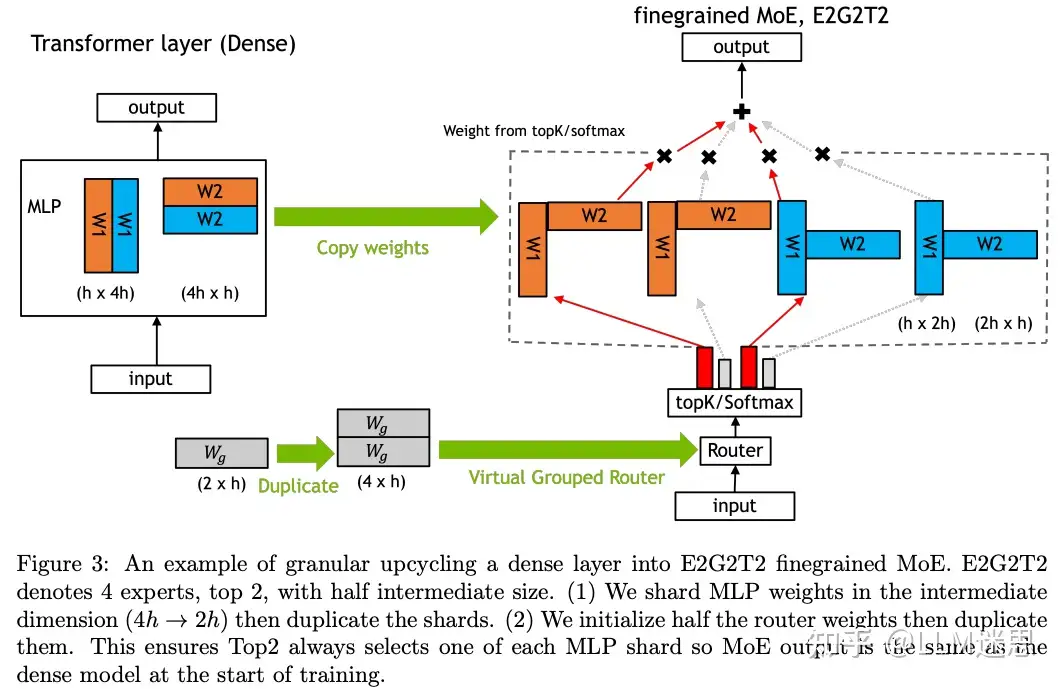 此部分理解可以参考伪代码:
此部分理解可以参考伪代码:

3.3.1 权重缩放
作者发现,对于细GranularityUpcycling,网络权重的缩放对细调后的MoE模型的准确性有着重大影响。虽然这种缩放可以完全在MLP的第二个线性投影(图3中的W2)上进行,但通过实验证明,同时缩放线性投影的权重(W1和W2)的效果更好。下述公式计算了作者用于15B稠密模型的基础模型中采用平方ReLU激活函数的情况下的缩放因子。
MoE激活值的计算公式如下: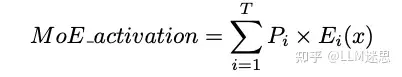 其中, 是第 个专家的概率, 是对应的专家层, T 是topK, x是来自注意力层的输出。
其中, 是第 个专家的概率, 是对应的专家层, T 是topK, x是来自注意力层的输出。
假设第0次迭代时概率近似均匀分布: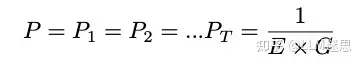 那么MoE激活值为:
那么MoE激活值为: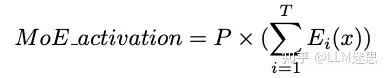 因此,对于虚拟分组,MoE激活值为:
因此,对于虚拟分组,MoE激活值为: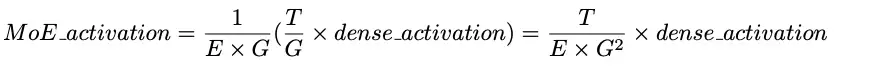 假设使用平方ReLU激活函数,作者对虚拟分组情况下的每个专家的MLP的W1和W2进行如下归一化:
假设使用平方ReLU激活函数,作者对虚拟分组情况下的每个专家的MLP的W1和W2进行如下归一化: 虽然对于不同的激活函数,搜索输入和输出权重的最佳缩放超参数可能会更好,但作者通过实验证明,对于使用swiglu激活的2B模型,上述均匀的权重分布效果良好。作者也将这种权重缩放方法应用于非细Granularity(即粗Granularity)的MoE模型,发现它有助于加快收敛。
虽然对于不同的激活函数,搜索输入和输出权重的最佳缩放超参数可能会更好,但作者通过实验证明,对于使用swiglu激活的2B模型,上述均匀的权重分布效果良好。作者也将这种权重缩放方法应用于非细Granularity(即粗Granularity)的MoE模型,发现它有助于加快收敛。
4. 结果
模型:作者在Nemotron 2B和Nemotron-4 15B模型上进行所有消融实验,最终使用更多的tokens在Nemotron-4 15B上得出最终结果。
数据:Upcycling可以在预训练的稠密模型已经见过的数据、新的未见过的数据,或者二者的组合上进行。
4.1 Upcycling的有效性
Upcycling vs 稠密模型的持续训练:遵循先前的工作,作者比较了在相同数量的tokens(0.1万亿)下,Upcycling和稠密Nemotron 2B模型的持续训练,采用了相似的学习调度策略。如图4a所示,持续训练的效果很快达到瓶颈,而Upcycling模型的性能则持续提升。从持续训练到Upcycling,语言模型的损失降低了1.1%。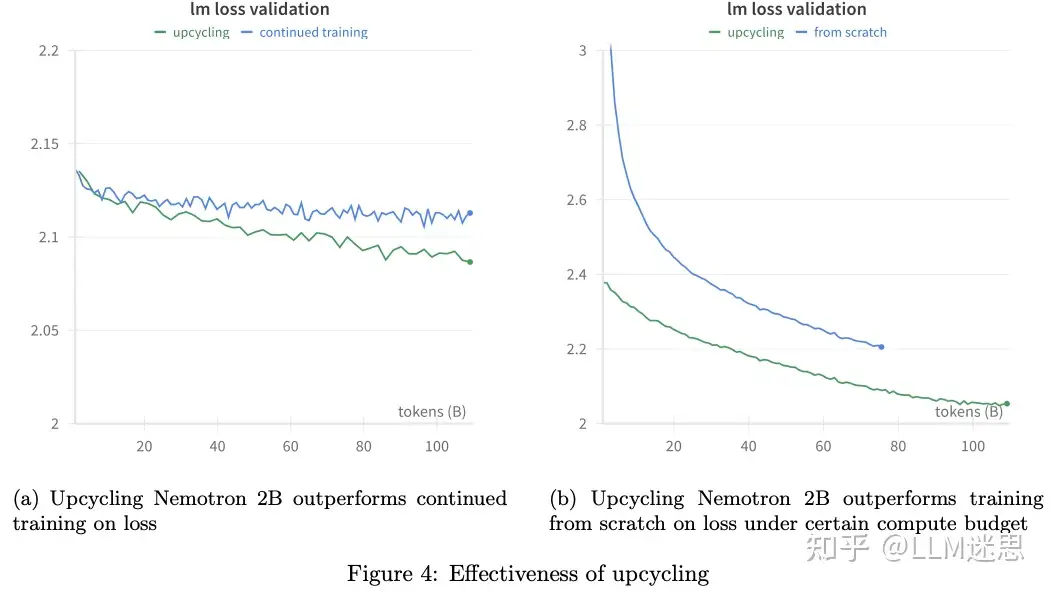 Upcycling vs 从头开始训练:图4b显示,在假定固定计算预算的情况下,Upcycling模型相对于从头开始训练有显著的提升。当计算预算远小于预训练计算预算时,Upcycling是利用预训练稠密模型权重的高效方法。一个有趣但未解答的问题是,假设有更大的计算预算,Upcycling稠密模型是否仍然比从头预训练更有价值。虽然一些近期工作如Skywork-MoE 尝试回答这个问题,但作者将这一方向留作未来的潜在研究课题。
Upcycling vs 从头开始训练:图4b显示,在假定固定计算预算的情况下,Upcycling模型相对于从头开始训练有显著的提升。当计算预算远小于预训练计算预算时,Upcycling是利用预训练稠密模型权重的高效方法。一个有趣但未解答的问题是,假设有更大的计算预算,Upcycling稠密模型是否仍然比从头预训练更有价值。虽然一些近期工作如Skywork-MoE 尝试回答这个问题,但作者将这一方向留作未来的潜在研究课题。
4.2 学习率和批大小
4.2.1 学习率调度
作者发现学习率调度在Upcycling过程中起着重要作用。通常在Upcycling稠密模型时,模型已经经过大量的训练步骤,且学习率通常在这个过程中已经逐渐衰减,使得模型进入了局部最小值。例如,作者的2B模型使用了余弦衰减学习率调度,其中学习率从2e-4的峰值逐渐衰减到在1.1万亿token训练结束时的2e-5。在Upcycling过程中,尚不清楚是否将学习率提高到预训练结束时的水平(作者称之为重置学习率)会改善或损害模型质量。
为找到合适的学习率调度,作者实验了三种不同的设置:
-
恒定学习率:作者使用了最小的预训练学习率2e-5,这是微调时的典型学习率调度。
-
峰值学习率2e-4,余弦衰减至2e-5:与预训练时相同的学习率调度,只是它在0.1万亿tokens的Upcycling训练结束时衰减到2e-5,因为作者只有预训练数据的10%。
-
峰值学习率1e-4,余弦衰减至2e-5:由于使用与预训练时同样高的学习率可能会导致灾难性遗忘,因此使用较低的峰值学习率可能是一个不错的选择。
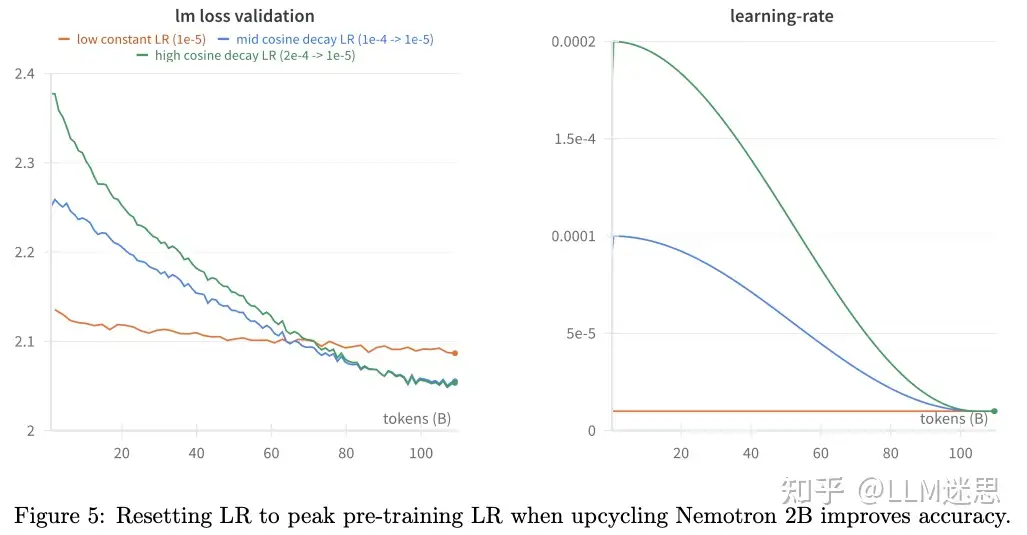 如图5所示,作者发现虽然恒定学习率调度在开始时的损失远低于重置学习率调度,但最终趋于平稳。重置学习率调度则逐渐赶上并最终超越了恒定学习率调度。在重置学习率的情况下,峰值学习率为1e-4和2e-4的表现相似。有趣的是,使用与预训练相同高的峰值学习率(2e-4)并没有导致灾难性遗忘。
如图5所示,作者发现虽然恒定学习率调度在开始时的损失远低于重置学习率调度,但最终趋于平稳。重置学习率调度则逐渐赶上并最终超越了恒定学习率调度。在重置学习率的情况下,峰值学习率为1e-4和2e-4的表现相似。有趣的是,使用与预训练相同高的峰值学习率(2e-4)并没有导致灾难性遗忘。
权重相似性:通常情况下,微调后的模型权重与基础模型权重有很高的余弦相似度。例如,Llama 2的聊天模型与Llama 2基础模型的余弦相似度接近1。作者计算了Upcycling后的模型与原始稠密模型逐层的余弦相似度。由于MoE层与MLP层不完全对应,作者计算了每个专家与原始MLP的余弦相似度,然后取平均值。最终,作者对所有层的余弦相似度取平均,得到一个单一的数值。
如图6所示,和大多数微调任务类似,使用最小学习率进行Upcycling时,权重几乎没有发生太大变化。MoE模型与基础模型的余弦相似度接近1。然而,应用重置学习率调度方法后,余弦相似度降低到了0.6-0.7。这可能意味着较高的学习率帮助模型跳出稠密模型的局部最小值,找到更优的最小值。此外,较高的学习率也有助于专家多样化。相比之下,较小的恒定学习率会导致专家彼此相似,使得模型与基础稠密模型相比差异不大。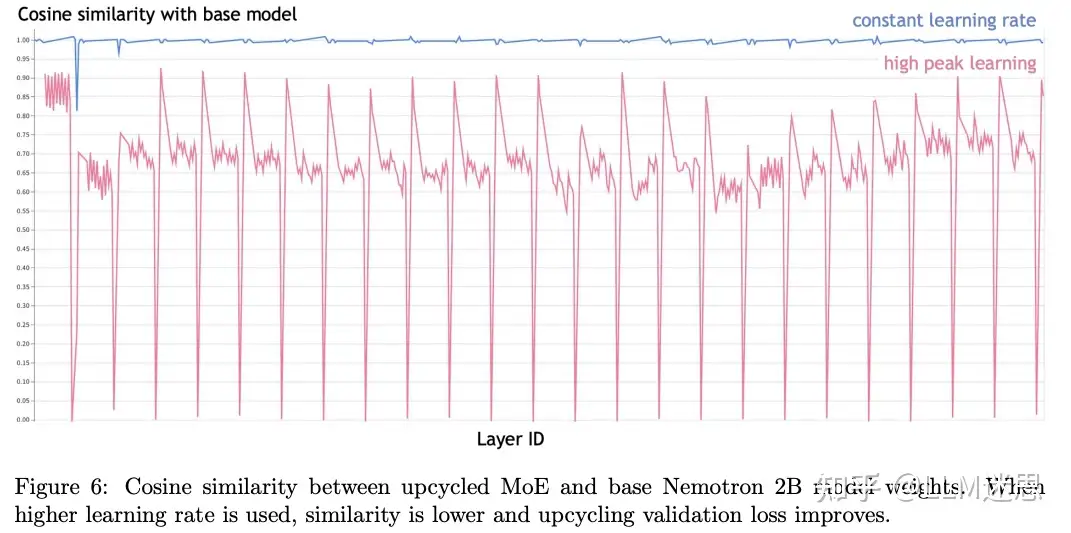
4.2.2 批大小
除了学习率之外,作者还观察到批大小对MoE模型的训练和Upcycling影响显著。作者推测MoE模型在以下两个原因下,比稠密模型更受益于较大的批大小:
-
每个专家只接收到一部分token,因此相对于稠密模型,梯度更加噪声化。
-
如果用于负载均衡的token较少,负载均衡损失的噪声也会更大。
如图7所示,作者比较了批大小为512、1024和8192(分别对应200万、400万和3200万个token)的情况,针对Nemotron 2B模型进行Upcycling训练。结果显示,批大小为3200万个token的情况下,表现最差;而批大小为400万个token时,收敛速度比200万个token更快。此外,较大的批大小在训练效率上(每个GPU的吞吐量)也明显更高。最近的Deepseek-V2 也采用了大批量大小9216(超过3700万个token)和学习率2.4e-4来预训练MoE模型。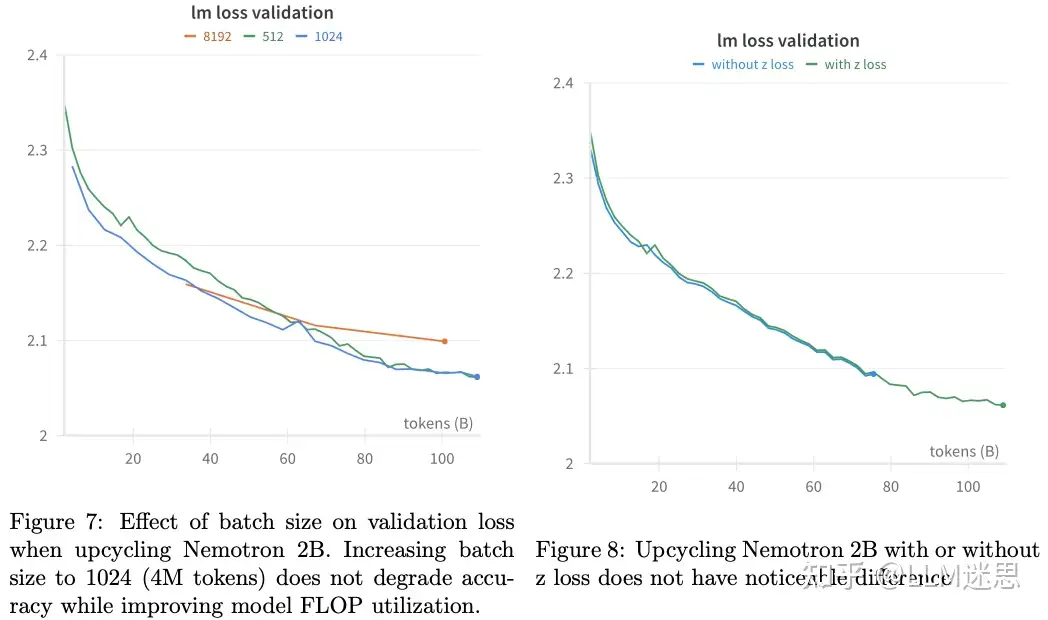
4.3 负载均衡和正则化损失
负载均衡辅助损失:作者采用了与ST-MoE 和Switch Transformer 中描述的相同的辅助损失(aux loss),并实验了不同的辅助损失系数。实验表明,完全不使用辅助损失会导致一些专家(expert)停止工作,且训练损失在早期就会停滞不前;而过高的辅助损失系数则会使辅助损失压过语言模型损失。作者发现,最佳的辅助损失系数在1e-2到1e-3之间。
Z损失:作者使用了与ST-MoE 中描述的相同的z损失。图8展示了带有和不带z损失的Upcycling训练对比(z损失系数为1e-3)。结果显示,z损失对最终模型质量没有影响。因此,作者在所有实验中使用了1e-2的辅助损失系数,并不使用z损失。
4.4 Softmax和TopK的顺序
作者始终发现,先softmax再topK的顺序比先topK再softmax在Upcycling过程中效果更好。作者推测,这是因为softmax-then-topK方法保留了路由器输出中绝对值的信息。然而,这种方法下,模型输出不再总和为1,因此很难使Upcycling后的模型输出与稠密模型的输出相似。作者通过权重缩放的方法解决了这一问题。
4.5 修正输出缩放
为了弥补专家输出缩小的问题,作者尝试了多种方法。除了权重缩放(如公式2中描述的),作者还尝试了以下几种方法:
-
缩放MoE输出:作者尝试对MoE层的输出进行常数因子或可学习标量的缩放,但实验表明,这些方法效果不佳。
-
专家层后添加Layernorm:一些关于细GranularityMoE缩放规律的研究 推荐在MoE层末尾添加一个layernorm。通常,稠密模型中没有这个layernorm。作者尝试在Upcycling训练时添加这个layernorm,虽然它可以阻止损失爆炸并达到相同效果,但适应时间较长。
作者比较了不同的方法,将Nemotron 2BUpcycling为具有64个专家、top-8的细GranularityMoE(E8G8T8)。每个专家的中间隐藏层大小为原始FFN中间层的1/8,以确保FLOP相同。作者提出的权重缩放方法表现最好,且易于实现,因为它不需要修改模型架构。
对于64个专家、top-8的细GranularityMoE,根据公式2,缩放因子应该是4。作者尝试了多个缩放因子(2x、2.5x、4x),结果发现,缩放因子为4的效果最好。因此,虽然作者的权重缩放函数并不完全准确,但它有助于模型收敛。
作者还发现,权重缩放也有助于标准的粗GranularityMoE的Upcycling训练。如图9所示,作者将Nemotron-4 15BUpcycling为具有8个专家、top-1的MoE模型。使用权重缩放后,训练损失比不使用权重缩放时提高了1.5%。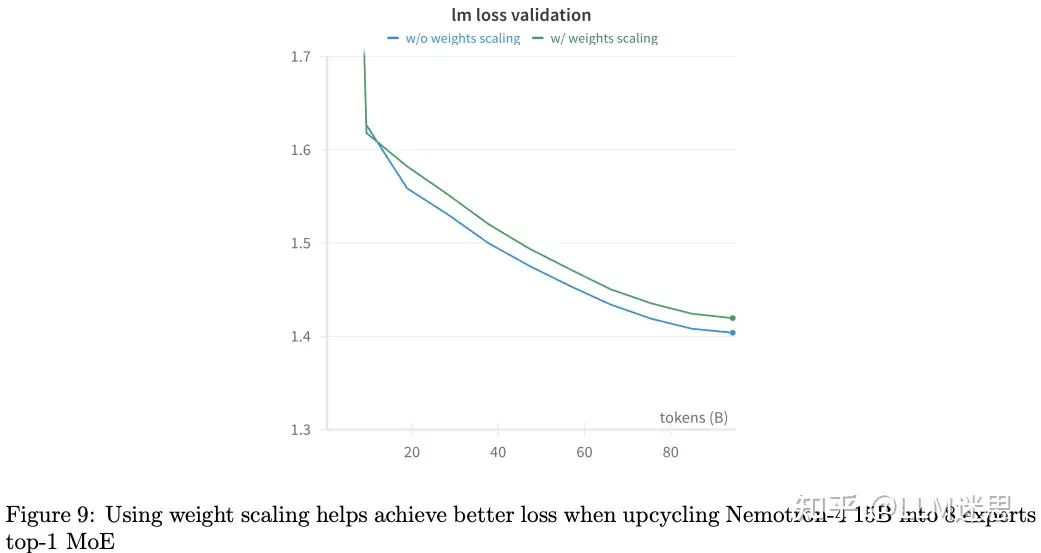
4.6 增加Granularity
作者发现,在较小的训练数据量(如15B模型使用的0.1T tokens)下,增加Granularity能够更快地降低损失,因为虚拟分组的细GranularityUpcycling比非细Granularity版本更能迅速优化损失。然而,当在更大数据量(≥1T tokens)的训练中,Granularity提升并未带来成比例的帮助,细Granularity和非细Granularity的模型最终收敛到了相似的损失值。由于这些大规模数据的训练需要消耗大量计算资源,作者没有对它们进行更多消融实验。
作者尝试在保持FLOP不变的前提下,将专家的数量从8个增加到256个。在对Nemotron 2B和Nemotron-4 15B的Upcycling过程中,作者分别比较了8个、64个、128个和256个专家。为了确保FLOP保持一致,作者按比例缩小了专家的隐藏层大小,以适应不同的topK值。
图10显示,在Nemotron 2B上,64个专家的效果优于8个专家。然而,进一步增加到128个或256个专家并未带来显著的收益。同样地,在Nemotron-4 15B上,性能的提升在64个专家时达到了最大。令人惊讶的是,Nemotron-4 15B的256个专家在Upcycling过程中表现略逊于64个或128个专家。过多的专家反而会降低模型的精度。作者推测这是因为专家都是拷贝,当专家数量增加时,网络很难找到新的、更优的最小值。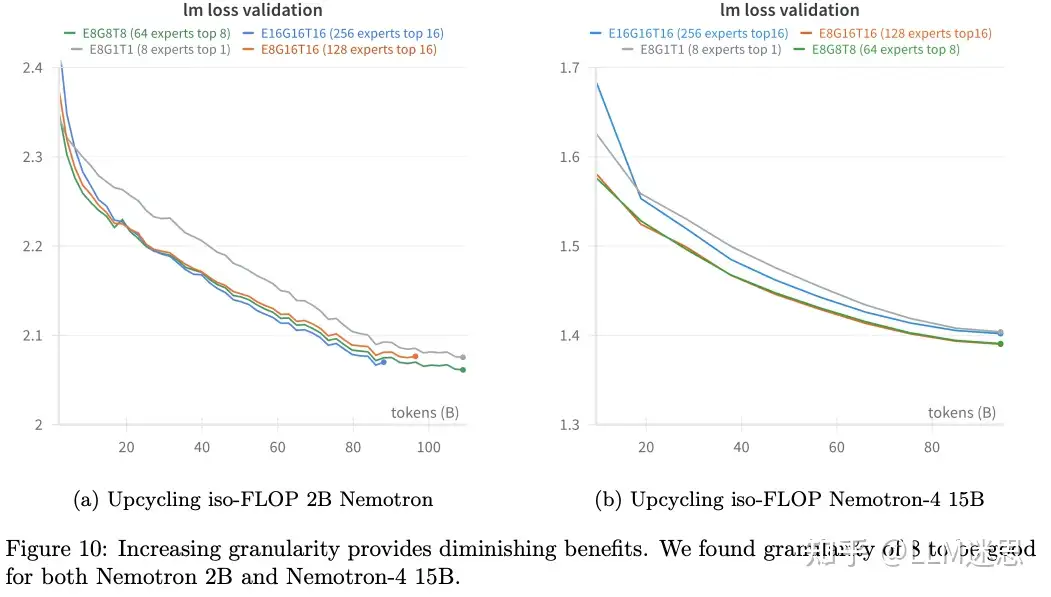 尽管增加Granularity具有潜力,但需要注意的是,它伴随着更高的MoE permute/unpermute成本和更小的GEMM矩阵运算规模。基于这些系统级的因素,作者在实验中同时使用了细Granularity和非细Granularity的方案。
尽管增加Granularity具有潜力,但需要注意的是,它伴随着更高的MoE permute/unpermute成本和更小的GEMM矩阵运算规模。基于这些系统级的因素,作者在实验中同时使用了细Granularity和非细Granularity的方案。
4.7 增加 TopK
在 MoE 模型中,Top-2 路由(即选择前两个专家)常被使用。尽管这会增加模型运行所需的计算量,但可以提升模型的准确性。作者比较了在粗Granularity和细Granularity的 MoE Upcycling中增加 topK 的效果。图11显示,在对 Nemotron 2B 和 Nemotron-4 15B 进行Upcycling时,**8 个专家的 top-2 模型(E8G1T2)**的表现优于 top-1 模型(E8G1T1)。在 15B 模型中,top-2 的训练损失比 top-1 更低(1.35757 vs 1.38031)。
先前的研究表明,使用实际时钟时间(wall clock time)而非计算量来衡量的权衡更合理,在这种情况下,topK 大于Granularity可能更有意义。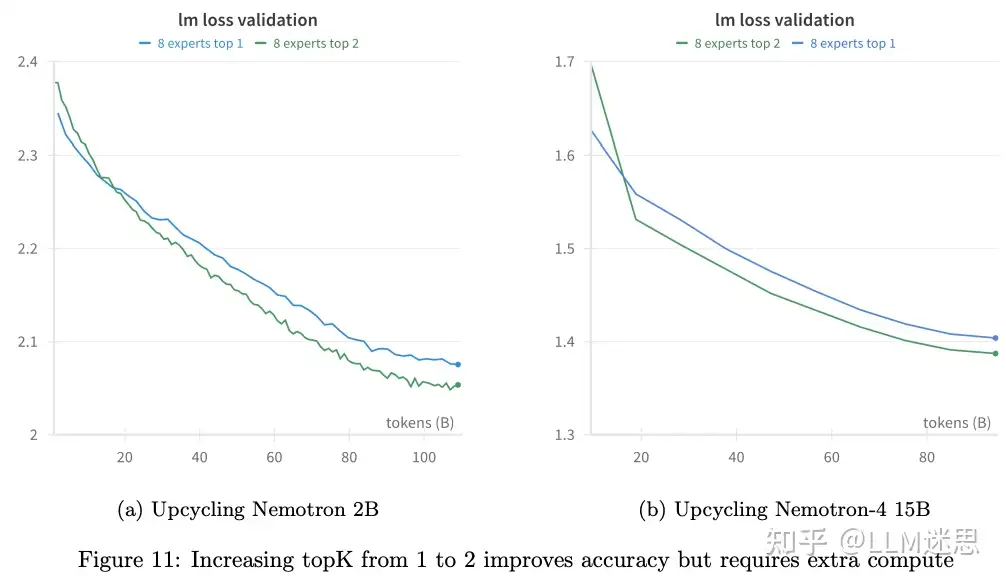
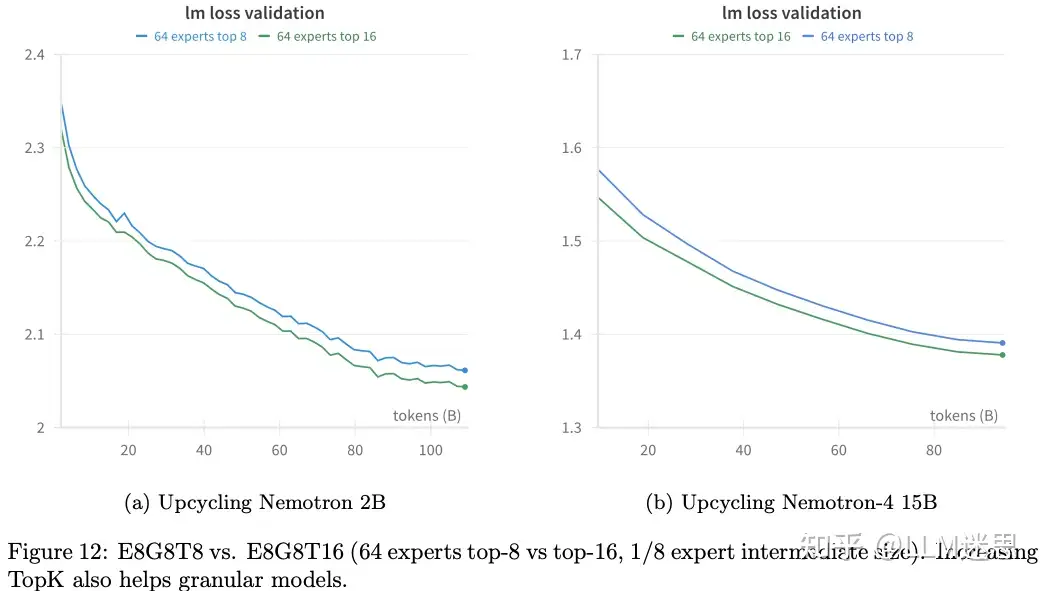
4.8 促进专家多样性:权重置换与重新初始化
作者尝试了在 Qwen 2中提出的权重置换与重新初始化方法。权重置换是在将 FFN 权重复制到每个专家之前,对其进行置换;而权重重新初始化则是随机重新初始化 50% 的专家权重。然而,在作者对 Nemotron 2B 的Upcycling实验中,这两种方法并未带来显著的性能提升。由于计算资源的限制,作者没有在更大规模的网络上进行这些技术的实验。
4.9 共享专家
作者尝试了 Deepseek-MoE中提出的共享专家方法。共享专家总是处于"开启"状态,即每个 token 都会被路由到共享专家。它们的作用类似于与 MoE 专家并行的稠密层。正如图13所示,作者在 Nemotron 2B 上比较了8 个共享专家 + 64 个专家的 top-8(与64个专家的 top-16 计算复杂度相同,iso-FLOP)。作者发现,使用共享专家的表现与不使用共享专家的同等计算复杂度模型相当。
由于使用共享专家并未带来准确率的提升,作者没有切换到使用共享专家的模型。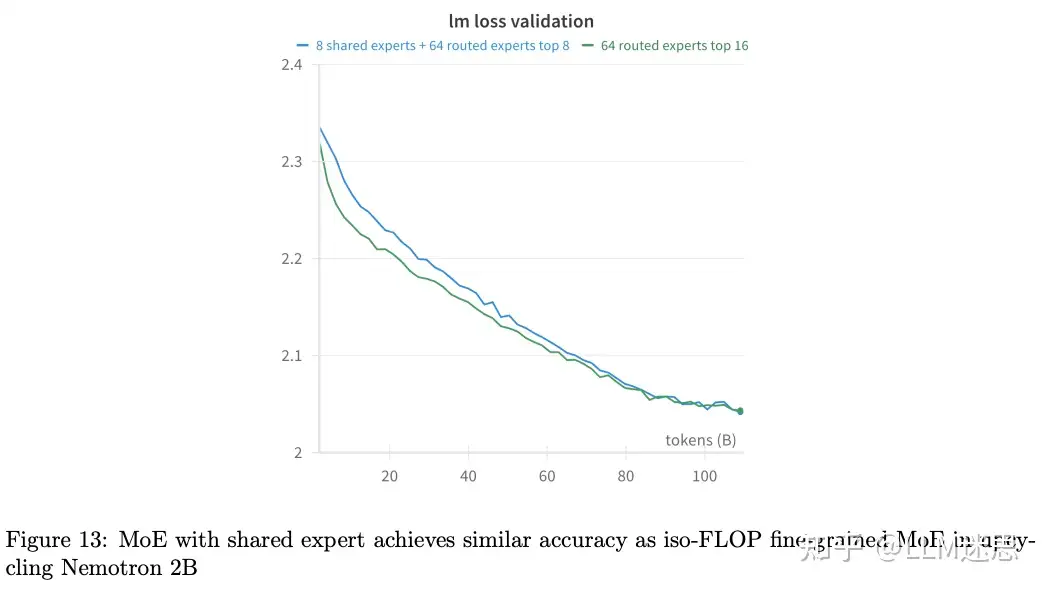
5. 大规模的 Upcycling
为了验证作者提出的方法在大规模(模型大小和训练 token 数量)场景下的有效性,作者对比了 Nemotron-4 15B 基础模型在 1T token 上的 upcycling 与持续训练效果。由于训练计算需求极高(0.3 yottaFLOPs),作者仅测试了两种变体:
-
E8G8T8
-
E8G1T2
作者选择 E8G8T8 使用虚拟组初始化,因为在之前的对比实验中它比 E8G1T1 表现更好。选择 E8G1T2 目的是展示计算量和 upcycling FLOPs 增加的效果。相比 E8G8T16,作者选择 E8G1T2 来验证作者提出的推荐方法(包括权重缩放和 softmax-then-topK 路由器)在非细Granularity场景中的效果。研究非细Granularity的用例很重要,因为它们在实际应用中比同等 FLOP 的细Granularity模型能更好地利用 GPU 的 FLOP。
在对 1T token 进行 upcycling 时,作者将学习率(lr)初始化为预训练的最小 lr(4.5e-4),峰值 lr 设为 3e-4,并采用余弦衰减将 lr 衰减至原预训练最小 lr 的 1/100。作者还使用了更大的batch大小用于 E8G8T8,因为 E8G1T2 平均每个专家接收的 tokens 更多。正如表 1 所示,upcycled 的 E8G8T8(64 个专家,top-8,1/8 专家隐藏层大小)在保持等 FLOP 的情况下,相比稠密持续训练模型的验证损失降低了 4.1%,并获得了更好的 MMLU 得分 66.2(相比稠密模型的 65.3)。作者还观察到,MMLU 的差异比例对持续训练数据很敏感,且随着 token 数量的增加差异逐渐扩大------因此更长的 token 训练有利于 MoE 模型。
随着训练 FLOP 的增加,作者还对 E8G1T2(8 个专家,top-2)进行了 upcycling,结果验证损失降低了 5.2%,MMLU 得分甚至达到了 67.6。
6. 相关工作
Upcycling 和模型扩展
在 MoE 模型的背景下,upcycling 概念指的是利用预训练的稠密模型初始化 MoE 架构的做法。该方法作为有效创建大规模 MoE 模型的方式逐渐受到重视,同时受益于现有预训练检查点中捕获的知识。此领域的一些重要研究包括:
-
稀疏 Upcycling:研究提出了一种从稠密检查点训练 MoE 模型的方法,证明了在保持或提高性能的同时扩展模型容量的能力。最近,Qwen 和 Deepseek 也采用了这种方法。然而,超越 10 亿参数的 upcycling 方法仍不够明确。
-
网络增长:对模型扩展技术的研究(如 Gopher 模型所探讨的)表明,可以显著增加模型规模,同时保持与从头训练的模型相当或更好的性能。
-
渐进式扩展:像 LLAMA PRO 这样的研究探讨了渐进式扩展技术,即在训练过程中逐步增加模型规模。
7. 结论
在这项工作中,作者对十亿参数规模语言模型的 upcycling 技术和最佳实践进行了深入研究。作者提出了一种"虚拟组"初始化方案和权重缩放方法,成功实现了大规模的粗Granularity和细Granularity的 MoE upcycling。研究表明,在相同计算量下,upcycling 在 2B 和 15B 参数模型中均优于持续的稠密模型训练。根据目标推理需求和可用的 upcycling FLOPs,使用更多 FLOPs 的架构(如 E8G1T2)能在精度上超过稠密等-FLOP MoE 模型。
在 2B 参数模型的实验中,作者发现 upcycling 需要与微调不同的超参数设置。在 upcycling 中,softmax-then-topK 的专家路由方式优于 topK-then-softmax。较高的细Granularity MoE 虽然提高了 upcycling 的准确性,但需要更精细的权重缩放和分片策略,同时会降低 GPU FLOP 的利用率。在纯 FLOP 限制的场景下,使用虚拟组初始化和细Granularity模型的 upcycling 是最佳策略。
作者希望这项工作能揭示十亿参数规模 MoE 模型 upcycling 的详细信息。未来的研究方向包括对更大规模模型的 upcycling 探讨、改进专家多样性和利用率,以及模型架构与系统设计的联合优化。(这篇文章可以看到作者做了大量实验对比dense模型向sparse模型转换的诸多细节,带来了很多启发。)
8.参考
备注:**昵称-学校/公司-方向/**会议(eg.ACL)****,进入技术/投稿群

id:DLNLPer,记得备注呦