目录
[1. 引入cpp-httplib到项目中](#1. 引入cpp-httplib到项目中)
[2. cpp-httplib的使用介绍](#2. cpp-httplib的使用介绍)
[3. 正式编写http_server](#3. 正式编写http_server)
[十一. 详解传 gitee](#十一. 详解传 gitee)
写在前面
项目 gitee 已经上传啦
(还是决定将学校和个人的 gitee 区分开来,所以之后写博客的代码就用这个 gitee 号了(。・∀・)
接着上一篇文章,下面继续讲解网络库的使用~
编写http_server模块
1. 引入cpp-httplib到项目中
安装cpp-httplib 安装的是v0.7.15版本:
下载链接:cpp-httplib 下载地址
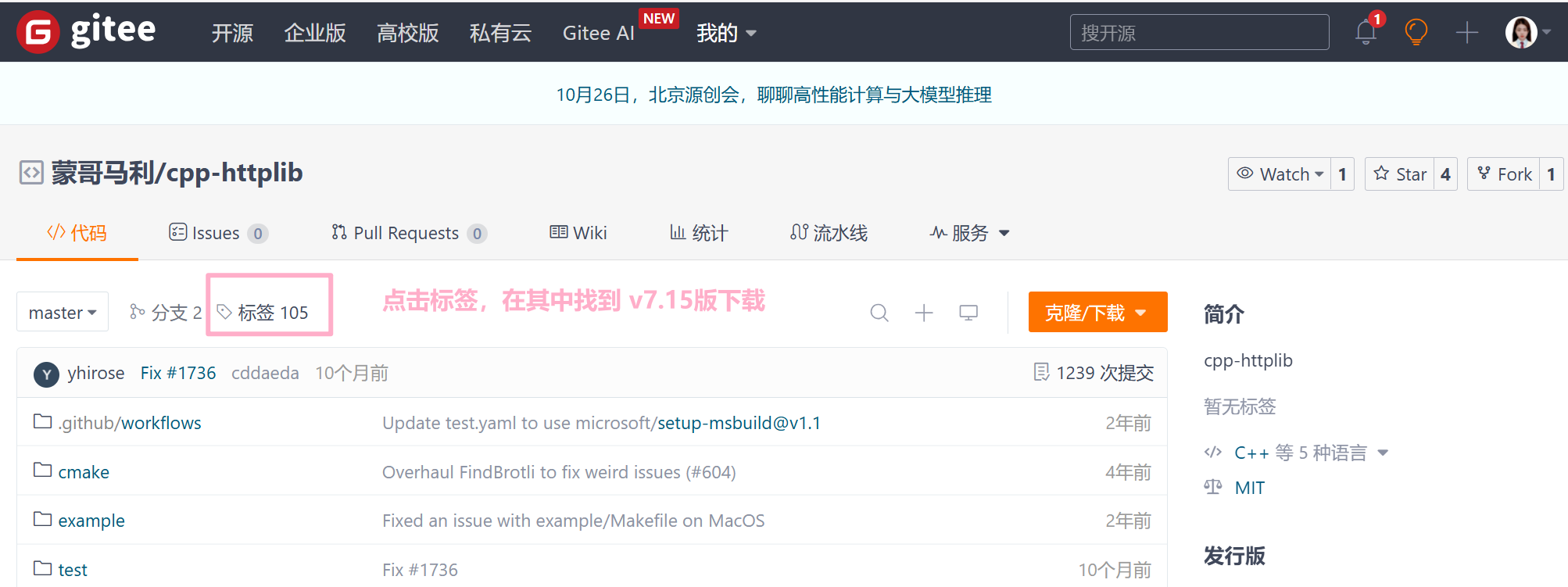
我们将cpp-httplib放到项目中的test目录下,并解压 unzip 好

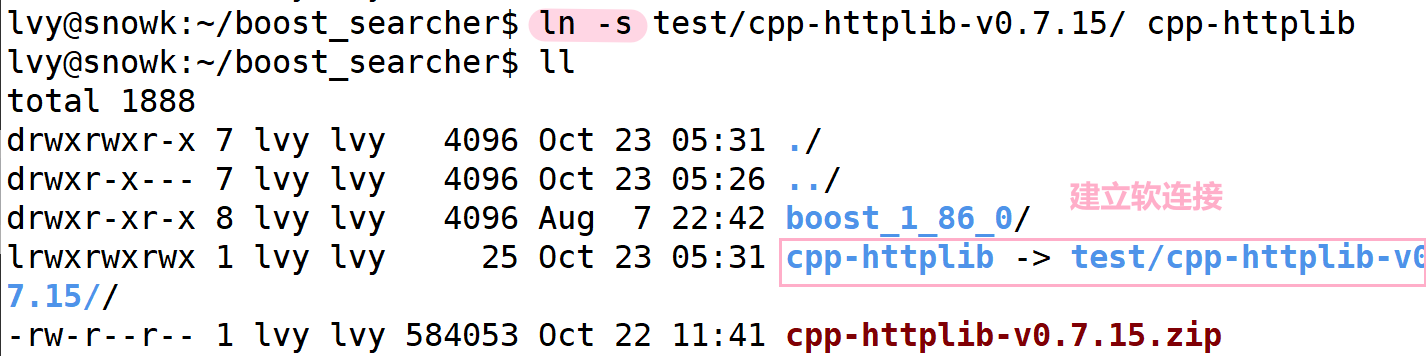
建立软连接到我们的项目路径下:
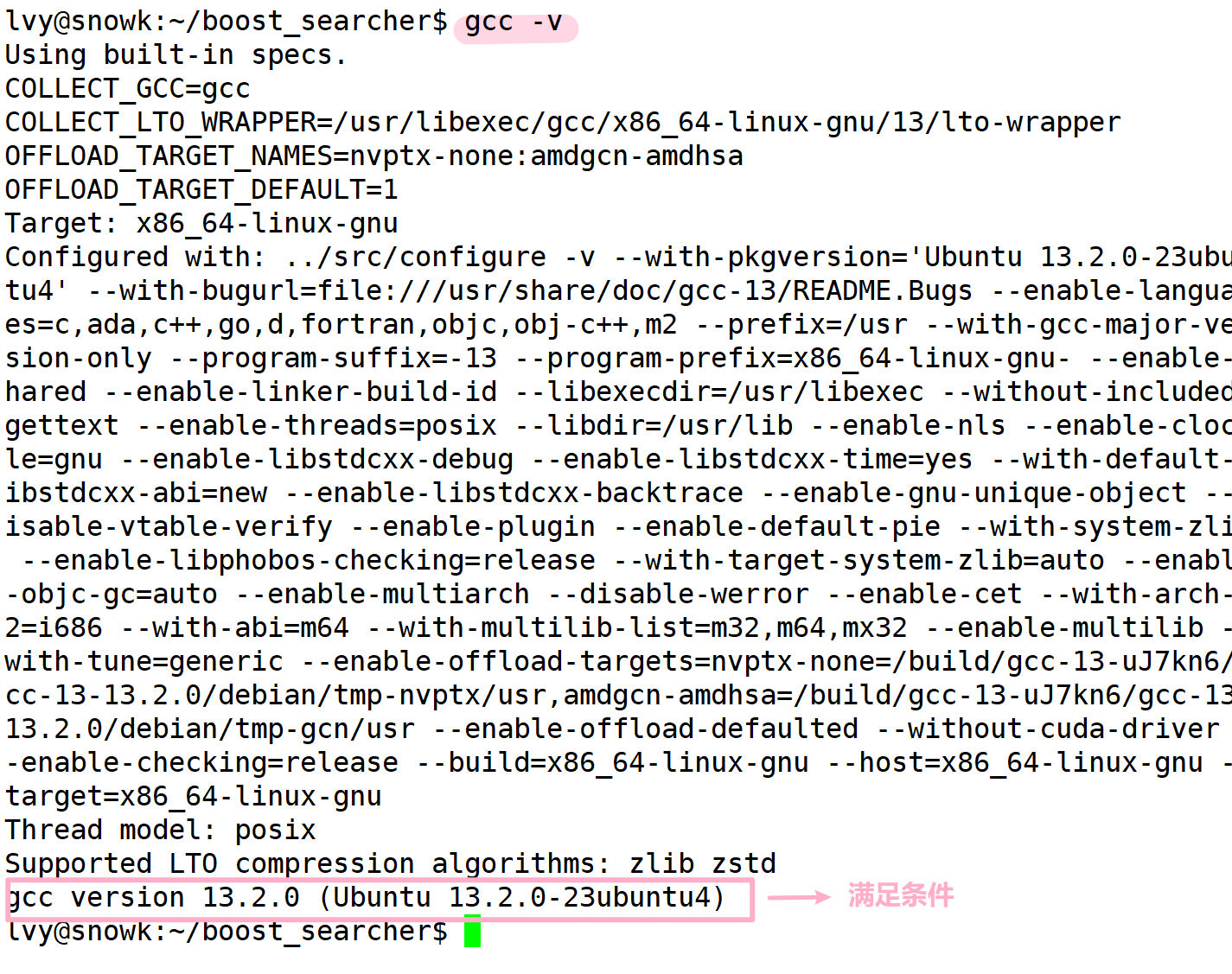
注意:要使用 cpp-httplib ,我们的 gcc 的版本必须时7 以上哦
至此,我们就可以在我们的项目中使用了。
2. cpp-httplib的使用介绍
创建一个http_server.cpp的文件,编写测试代码:
#include "cpp-httplib/httplib.h"
int main()
{
//创建一个Server对象,本质就是搭建服务端
httplib::Server svr;
// 这里注册用于处理 get 请求的函数,当收到对应的get请求时(请求hi时),程序会执行对应的函数(也就是lambda表达式)
svr.Get("/hi", [](const httplib::Request& req, httplib::Response& rsp){
//设置 get "hi" 请求返回的内容
rsp.set_content("hello world!", "text/plain; charset=utf-8");
});
// 绑定端口(8080),启动监听(0.0.0.0表示监听任意端口)
svr.listen("0.0.0.0", 8080);
return 0;
}对应的Makefile:
PARSER=parser
DUG=debug
HTTP_SERVER=http_server
cpp=g++
.PHONY:all
all:$(PARSER) $(DUG) $(HTTP_SERVER)
$(PARSER):parser.cpp
$(cpp) -o $@ $^ -lboost_system -lboost_filesystem -std=c++11
$(DUG):debug.cpp
$(cpp) -o $@ $^ -std=c++11 -ljsoncpp
$(HTTP_SERVER):http_server.cpp
$(cpp) -o $@ $^ -std=c++11 -ljsoncpp -lpthread
.PHONY:clean
clean:
rm -f $(DUG) $(PARSER) $(HTTP_SERVER)我们直接编译运行 http_server

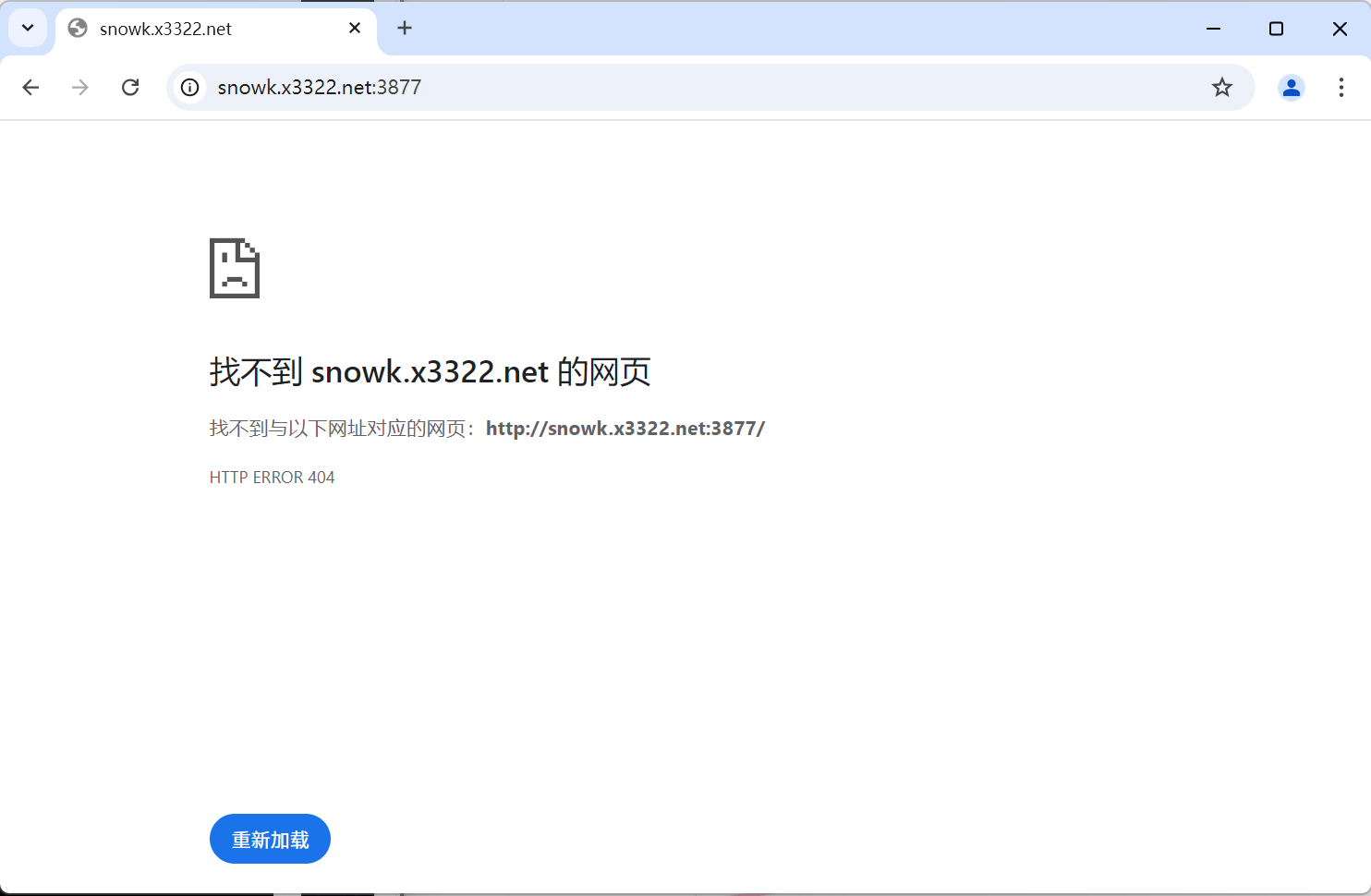
打开浏览器,访问我们这个端口(如服务器IP:3877/hi),结果如下:

但是当我们访问服务器IP:3877时,却找不到对应的网页,
像我们访问百度时,www.baidu.com,百度会给一个首页,所以在我们的项目目录下呢,也需要一个首页。 (在项目路径下创建一个wwwroot目录,目录中包含一个index.html文件)

编写我们的首页,并修改我们的 http_server.cpp:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>boost搜索引擎</title>
</head>
<body>
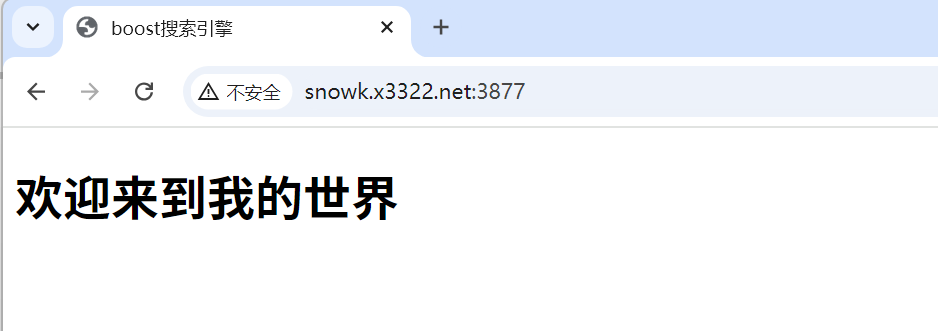
<h1>欢迎来到我的世界</h1>
</body>
</html>
#include "cpp-httplib/httplib.h"
const std::string root_path = "./wwwroot";
int main()
{
//创建一个Server对象,本质就是搭建服务端
httplib::Server svr;
//访问首页
svr.set_base_dir(root_path.c_str());
// 这里注册用于处理 get 请求的函数,当收到对应的get请求时(请求hi时),程序会执行对应的函数(也就是lambda表达式)
svr.Get("/hi", [](const httplib::Request& req, httplib::Response& rsp){
//设置 get "hi" 请求返回的内容
rsp.set_content("hello world!", "text/plain; charset=utf-8");
});
// 绑定端口(8080),启动监听(0.0.0.0表示监听任意端口)
svr.listen("0.0.0.0", 8080);
return 0;
}再次通过浏览器进行访问:
3. 正式编写http_server
#include "cpp-httplib/httplib.h"
#include "searcher.hpp"
const std::string input = "data/raw_html/raw.txt";
const std::string root_path = "./wwwroot";
int main()
{
ns_searcher::Searcher search;
search.InitSearcher(input);
//创建一个Server对象,本质就是搭建服务端
httplib::Server svr;
//访问首页
svr.set_base_dir(root_path.c_str());
// 这里注册用于处理 get 请求的函数,当收到对应的get请求时(请求s时),程序会执行对应的函数(也就是lambda表达式)
svr.Get("/s", [&search](const httplib::Request &req, httplib::Response &rsp){
//has_param:这个函数用来检测用户的请求中是否有搜索关键字,参数中的word就是给用户关键字取的名字(类似word=split)
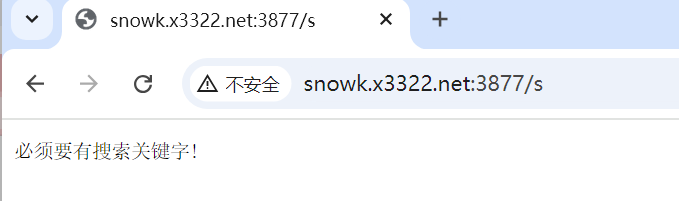
if(!req.has_param("word")){
rsp.set_content("必须要有搜索关键字!", "text/plain; charset=utf-8");
return;
}
//获取用户输入的关键字
std::string word = req.get_param_value("word");
std::cout << "用户在搜索:" << word << std::endl;
//根据关键字,构建json串
std::string json_string;
search.Search(word, &json_string);
//设置 get "s" 请求返回的内容,返回的是根据关键字,构建json串内容
rsp.set_content(json_string, "application/json");
});
std::cout << "服务器启动成功......" << std::endl;
// 绑定端口(8080),启动监听(0.0.0.0表示监听任意端口)
svr.listen("0.0.0.0", 3877);
return 0;
}
此时我们编译运行我们的代码,先执行parser进行数据清洗,然后执行http_server,搭建服务,创建单例,构建索引,发生请求(根据用户输入的关键字,进行查找索引,构建json串),最后响应给用户
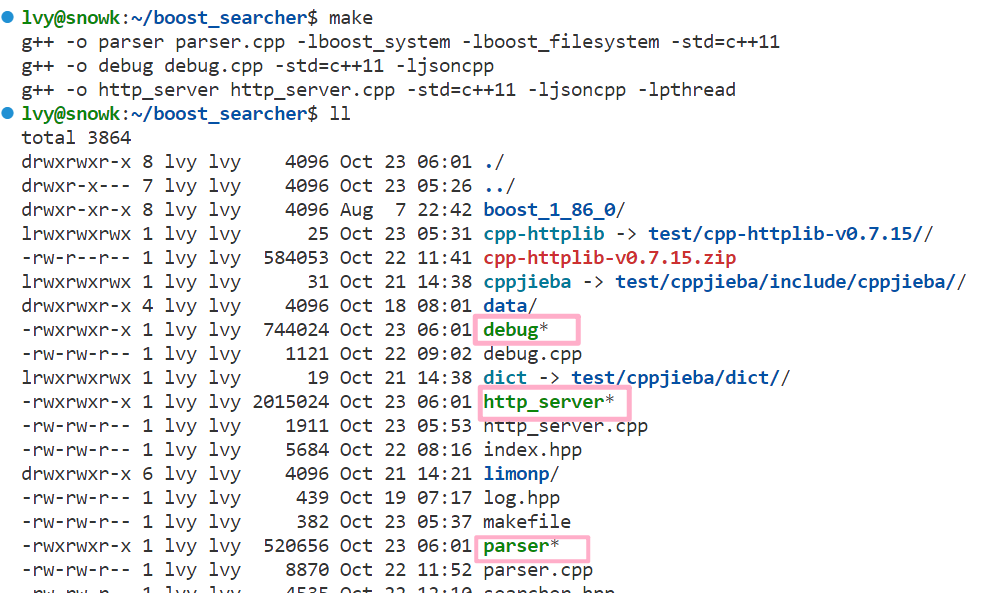
此时服务器启动成功,索引也建立完毕 ,

此时,我们在浏览器进行访问(服务器IP:3877/s)
此时,我们在浏览器进行访问(服务器IP:3877/s?word=split)

最终,在浏览器上就显示出来了,到这里我们的后端内容大致上算是完成了,最后添加一个日志就可以了,如果你对前端不感兴趣,到这里就可以了。可以把日志功能的添加看一看
九、添加日志到项目中
我们创建一个log.hpp的头文件,需要添加日志的地方:index模块,searcher模块、http_server模块。代码如下:
#pragma once
#include <iostream>
#include <string>
#include <ctime>
#define NORMAL 1 //正常的
#define WARNING 2 //错误的
#define DEBUG 3 //bug
#define FATAL 4 //致命的
#define LOG(LEVEL, MESSAGE) log(#LEVEL, MESSAGE, __FILE__, __LINE__)
void log(std::string level, std::string message, std::string file, int line)
{
// 打印日志信息
std::cout << "[" << level << "]"
<< "[" << time(nullptr) << "]"
<< "[" << message << "]"
<< "[" << file << " : " << line << "]"
<< std::endl;
}简单说明:
我们用宏来实现日志功能,其中LEVEL表明的是等级(有四种),
这里的#LEVEL的作用是:把一个宏参数变成对应的字符串(直接替换)
C语言中的预定义符号:
- FILE:进行编译的源文件
- LINE:文件的当前行号
补充几个:
- DATE:文件被编译的日期
- TIME:文件被编译的时间
- FUNCTION:进行编译的函数
假设在如下示例代码:
int main() {
LOG(NORMAL, "This is a normal log message");
LOG(WARNING, "This is a warning log message");
LOG(DEBUG, "This is a debug log message");
LOG(FATAL, "This is a fatal log message");
return 0;
}编译并运行这段代码后,输出会类似于:

所以我们可以将日志添加到有输出入口的地方,方便监视我们的代码那里出现了问题。
日志系统的作用
- 调试和错误追踪:记录程序执行过程中的各种状态和错误信息,方便定位和修复问题。
- 运行监控:监控程序的运行状态,了解程序的执行流程和重要事件。
- 审计和分析:分析日志记录,了解用户行为和系统性能,进行数据挖掘和改进。
十、编写前端模块
前端模块,我做详细的解释,代码中都有注释,直接上代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<script src="http://code.jquery.com/jquery-2.1.1.min.js"></script>
<title>boost 搜索引擎</title>
<style>
/*去掉网页中的所有内外边距,可以了解html的盒子模型*/
* {
margin: 0;
/* 设置外边距 */
padding: 0;
/* 设置内边距 */
}
/* 将我们的body内的内容100%和html的呈现吻合 */
html,
body {
height: 100%;
}
/* 以点开头的称为类选择器.container */
.container {
/* 设置div的宽度 */
width: 800px;
/* 通过设置外边距达到居中对其的目的 */
margin: 0px auto;
/* 设置外边距的上边距,保持元素和网页的上部距离 */
margin-top: 15px;
}
/* 复合选择器,选中container下的search */
.container .search {
/* 宽度与父标签保持一致 */
width: 100%;
/* 高度设置52px */
height: 50px;
}
/* 选中input标签,直接设置标签的属性,先要选中,标签选择器 */
/* input在进行高度设置的时候,没有考虑边框的问题 */
.container .search input {
/* 设置left浮动 */
float: left;
width: 600px;
height: 50px;
/* 设置边框属性,依次是边框的宽度、样式、颜色 */
border: 2px solid #CCC;
/* 去掉input输入框的右边框 */
border-right: none;
/* 设置内内边距,默认文字不要和左侧边框紧挨着 */
padding-left: 10px;
/* 设置input内部的字体的颜色和样式 */
color: #CCC;
color: #CCC;
font-size: 17px;
}
.container .search button {
/* 设置left浮动 */
float: left;
width: 150px;
height: 54px;
/* 设置button的背景颜色 #4e6ef2*/
background-color: #4e6ef2;
color: #FFF;
/* 设置字体的大小 */
font-size: 19px;
font-family: Georgia, 'Times New Roman', Times, serif 'Times New Roman', Times, serif;
}
.container .result {
width: 100%;
}
.container .result .item {
margin-top: 15px;
}
.container .result .item a {
/* 设置为块级元素,单独占一行 */
display: block;
text-decoration: none;
/* 设置a标签中的文字字体大小 */
font-size: 22px;
/* 设置字体的颜色 */
color: #4e6ef2;
}
.container .result .item a:hover {
/* 设置鼠标放在a之上的动态效果 */
text-decoration: underline;
}
.container .result .item p {
margin-top: 5px;
font-size: 16px;
font-family: 'Lucida Sans', 'Lucida Sans Regular', 'Lucida Grande', 'Lucida Sans Unicode', Geneva, Verdana, sans-serif;
}
.container .result .item i {
/* 设置为块级元素,单独占一行 */
display: block;
/* 取消斜体风格 */
font-style: normal;
color: green;
}
</style>
</head>
<body>
<div class="container">
<div class="search">
<input type="text" value="输入搜索关键字...">
<button onclick="Search()">搜索一下</button>
</div>
<div class="result">
<!-- <div class="item">
<a href="#">这是标题</a>
<p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p>
<i>https://hao.360.com/?hj=llq7a</i>
</div>
<div class="item">
<a href="#">这是标题</a>
<p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p>
<i>https://hao.360.com/?hj=llq7a</i>
</div>
<div class="item">
<a href="#">这是标题</a>
<p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p>
<i>https://hao.360.com/?hj=llq7a</i>
</div>
<div class="item">
<a href="#">这是标题</a>
<p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p>
<i>https://hao.360.com/?hj=llq7a</i>
</div>
<div class="item">
<a href="#">这是标题</a>
<p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p>
<i>https://hao.360.com/?hj=llq7a</i>
</div>
<div class="item">
<a href="#">这是标题</a>
<p>这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要这是摘要</p>
<i>https://hao.360.com/?hj=llq7a</i>
</div> -->
</div>
</div>
<script>
function Search() {
// 是浏览器的一个弹出窗
// 1.提取数据,$可以理解为就是JQuery的别称
let query = $(".container .search input").val();
console.log("query = " + query); //console是浏览器对话框,可以用来进行查看js数据
// 2.发起http请求,ajax属于一个和后端进行数据交互的函数
$.ajax({
type: "GET",
url: "/s?word=" + query,
success: function (data) {
console.log(data);
BuildHtml(data);
}
});
}
function BuildHtml(data) {
// 获取html中的result标签
let result_lable = $(".container .result");
// 清空历史搜索结果
result_lable.empty();
for (let elem of data) {
console.log(elem.title);
console.log(elem.url);
let a_lable = $("<a>", {
text: elem.title,
href: elem.url,
// 跳转到新的页面
target: "_blank"
});
let p_lable = $("<p>", {
text: elem.desc
});
let i_lable = $("<p>", {
text: elem.url
});
let div_lable = $("<div>", {
class: "item"
});
a_lable.appendTo(div_lable);
p_lable.appendTo(div_lable);
i_lable.appendTo(div_lable);
div_lable.appendTo(result_lable);
}
}
</script>
</body>
</html>最终演示:

- 将我们的项目部署到Linux上:
nohup ./http_server > log/log.txt 2>&1 & - 一些日志信息就会保存到log/log.txt中
十一. 详解传 gitee
在 Ubuntu 上向 Gitee(码云)上传代码,通常需要通过 Git 进行。下面是具体步骤:
-
安装 Git :
如果你还没有安装 Git,可以通过以下命令来安装:sudo apt-get update
sudo apt-get install git -
配置 Git :
首次使用 Git 时,需要设置你的用户名和邮箱地址。这将用于提交信息。git config --global user.name "你的用户名"
git config --global user.email "你的邮箱@example.com" -
创建 Gitee 仓库 :
登录到 Gitee 并创建一个新的仓库。记下仓库的 URL。 -
初始化本地仓库(如果你还没有一个本地 Git 仓库):
-
-
打开终端并导航到你的项目目录。
-
初始化一个新的 Git 仓库:
git init
-
-
-
添加远程仓库链接(替换
your-repo-url为你的 Gitee 仓库 URL):git remote add origin your-repo-url
-
- 添加文件到仓库:
-
将所有文件添加到暂存区:
git add .
-
-
或者你可以选择性地添加特定文件:
git add 文件名
-
- 提交更改:
-
提交文件到本地仓库,并附上提交信息:
git commit -m "初始提交或描述本次提交的内容"
- 推送到 Gitee:
-
推送你的本地分支到 Gitee 仓库的主分支(通常是
master或main):git push -u origin master
-
-
如果你的默认分支是
main而不是master,请相应地调整命令git push -u origin main
-
- 验证:
- 打开 Gitee 网站上的仓库页面,确认文件已经成功上传。
如果你在推送过程中遇到权限问题,确保你在 Gitee 上正确设置了 SSH 密钥或使用了正确的 HTTPS 凭证。
- 如果使用的是 HTTPS 方式,可能需要输入 Gitee 的用户名和密码或者使用个人访问令牌。
- 如果是 SSH 方式,则需要生成 SSH 密钥对并将公钥添加到 Gitee 账户中。
1.问题
git add .报错warning: adding embedded git repository: carreport hint: You've added another git...
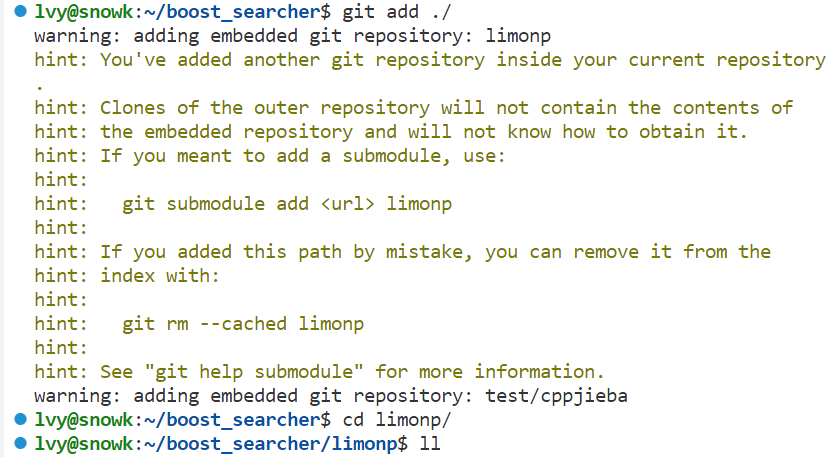
原因:
使用 git add . 时,出现上述错误。是因为在当前 git 仓库中同时包含有另一个git仓库。如当前仓库目录下的子文件夹内又是一个仓库。
解决:
删除子文件夹的.git文件, 重新add commit push
2.出错:
! [rejected] master -> master (fetch first) error: failed to push some refs to ' 。。。'
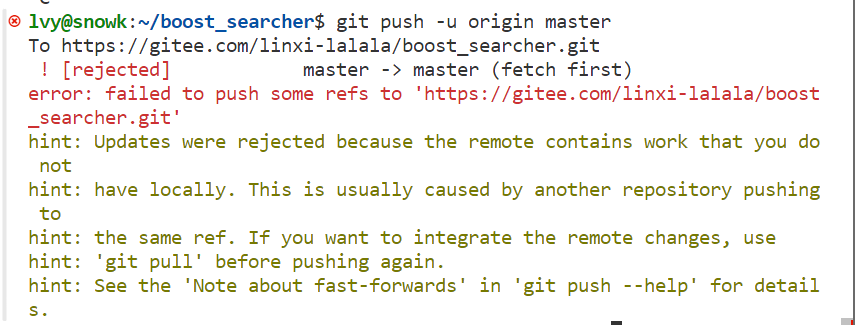
出现这个问题是因为github中的README.md文件不在本地代码目录中,可以通过如下命令进行代码合并
git pull --rebase origin master
十二、项目总结
项目的扩展
- 建立整站搜索
- 我们搜索的内容是在boost库下的doc目录下的html文档,你可以将这个库建立搜索,也可以将所有的版本,但是成本是很高的,对单个版本的整站搜索还是可以完成的,取决于你服务器的配置。
- 设计一个在线更新的方案,信号,爬虫,完成整个服务器的设计
- 我们在获取数据源的时候,是我们手动下载的,你可以学习一下爬虫,写个简单的爬虫程序。采用信号的方式去定期的爬取。
- 不使用组件,而是自己设计一下对应的各种方案
- 我们在编写http_server的时候,是使用的组件,你可以自己设计一个简单的;
- 在我们的搜索引擎中,添加竞价排名
- 我们在给用户反馈是,提供的是json串,显示到网页上,有title、content和url;就可以在构建json串时,你加上你的博客链接(将博客权重变高了,就能够显示在第一个)
-
热次统计,智能显示搜索关键词(字典树,优先级队列)
-
设置登陆注册,引入对mysql的使用
以上就是对于C++项目--基于Boost库的搜索引擎 的理解,完结撒花~
后续还会继续更新一些项目 ,有兴趣的小伙伴欢迎大家订阅【项目】专栏~