




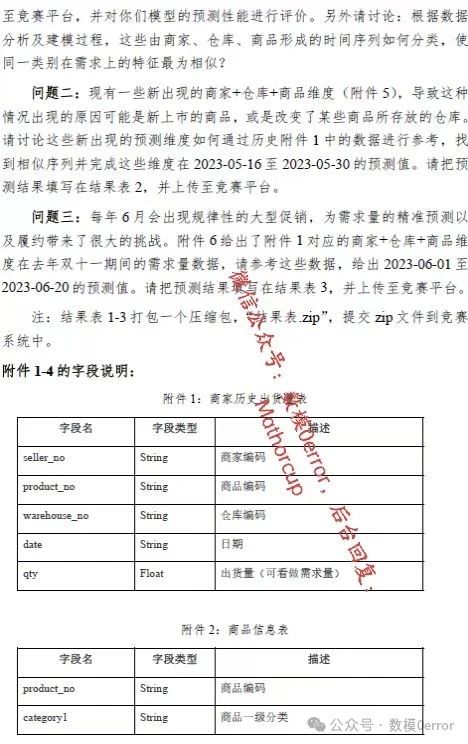
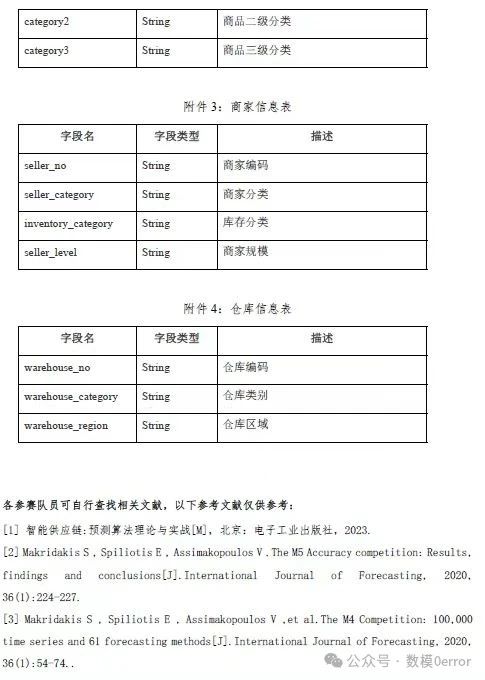


问题 1 **分析:**针对问题1,由于数据量相对较大、且需要数据维度较多,所以需要利用优化聚类方法和优化预测算法对模型进行处理。首先将商家、仓库、商品等维度基于时间序列构建基于概率密度聚类分析模型,输出其符合最为相似的特征条件下的最优的分类。其次将出货量作为因变量,聚类相关因子作为自变量,构建基于SBO-LSTM神经网络出货量优化预测模型。再者分别将85%数据作为训练集,15%数据作为测试集,对模型进行训练和测试,输出模型的精度和1-wmape维度。最后各商家在各仓库的数据导入训练好的模型当中进行预测,输出预测出各商家在各仓库的商品2023-05-16至2023-05-30的需求量,并将其存放在相应的表格附件当中。
问题 2 **分析:**针对问题2,出现了新的维度数据,那么需要对新维度的数据和旧数据进行维度匹配处理。首先将附件5数据和附件1~4联合数据集作为样本数据,由于数据集巨大,为了提升算力、提高数据优化搜索,构建基于模糊概率联合聚类模型(GDM模型)。其次导入数据将GDM最优聚类集合求解出来。再者将GDM聚类结果作为自变量,出货量作为因因变量,为了更好的迭代时间与空间维度的数据,构建基于模糊神经网络出货量预测模型(GD-FNN模型)对不同商家在不同仓库的商品出货量进行预测。最后将相关数据到训练好的模型当中,输出2023-05-16至2023-05-30的预测值存放到表1相应的位置,并对预测的准确度进行评价。
