编译环境
操作系统:ubuntu 20.04/22.04
OCR版本:paddleocr 2.8.1
Opencv版本:opencv3.4.16/4.10.0
o参照官方文档:
第一步 安装opencv
方式一 源代码编译安装
【推荐】篇幅太长,请按照我另外一篇文章使用源代码安装
方式二 使用已经编译好的版本
如果源代码编译容易报错或编译速度很慢,可使用我以下的编译好的版本,下载后解压到个人目录下的opencv文件夹中备用。
以下链接中按需下载指定版本,目前包含3.4.16及4.10.0版本。3.4.16的版本是ubuntu 2020.04下g++ 9.4.0编译,4.10.0的版本是ubuntu 2024.04下g++ 13.2.0编译,请按照自己的环境下载使用。
链接: https://pan.baidu.com/s/1IW9YVIXADV_QmcS7RwrQJg 提取码: n6h4
第二步 下载paddleOcr源码
执行如下代码,会在当前目录下生成一个PaddleOCR文件夹
bash
git clone https://github.com/PaddlePaddle/PaddleOCR.git上述无法clone时使用国内gitee镜像
git clone https://gitee.com/paddlepaddle/PaddleOCR.git进入PaddleOCR路径下
bash
cd PaddleOCR进入PaddleOCR,查看发行版本,切换版本到2.8.1.
bash
git show-ref 切换tag到v2.8.1
切换tag到v2.8.1
bash
git checkout 40c56628fda416e1c8710eb19e4b260536902520切换后使用git log查看,可以看到当前版本执行2.8.1即可

第二步 下载paddle预测库
注意此时所在路径是PaddleOCR下。
我这里使用官方已经编译好的版本,执行一下代码会直接下载并加以到paddle_inference文件夹中
bash
wget https://paddle-inference-lib.bj.bcebos.com/2.3.2/cxx_c/Linux/CPU/gcc8.2_avx_mkl/paddle_inference.tgz && tar -xf paddle_inference.tgz && rm paddle_inference.tgz第三步 下载paddleOCR推理模型
注意此时所在路径是PaddleOCR下,新建一个目录infer,后续的三个模型都会下载到该infer目录中。
bash
mkdir infer && cd infer下载检测模型v4轻量版,这里使用轻量的原因是轻量版本的速度比高清版本快了10倍(我个人电脑上实测)不止
bash
wget https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_det_infer.tar && tar -xf ch_PP-OCRv4_det_infer.tar && rm ch_PP-OCRv4_det_infer.tar下载文字识别模型v4轻量版,这里使用轻量的原因是轻量版本的速度比高清版本快了10倍(我个人电脑上实测)不止
bash
wget https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_infer.tar && tar -xf ch_PP-OCRv4_rec_infer.tar && rm ch_PP-OCRv4_rec_infer.tar下载文字方向分类器
bash
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar && tar xf ch_ppocr_mobile_v2.0_cls_infer.tar && rm ch_ppocr_mobile_v2.0_cls_infer.tar以上下载完成后当前目录下文件内容如下:
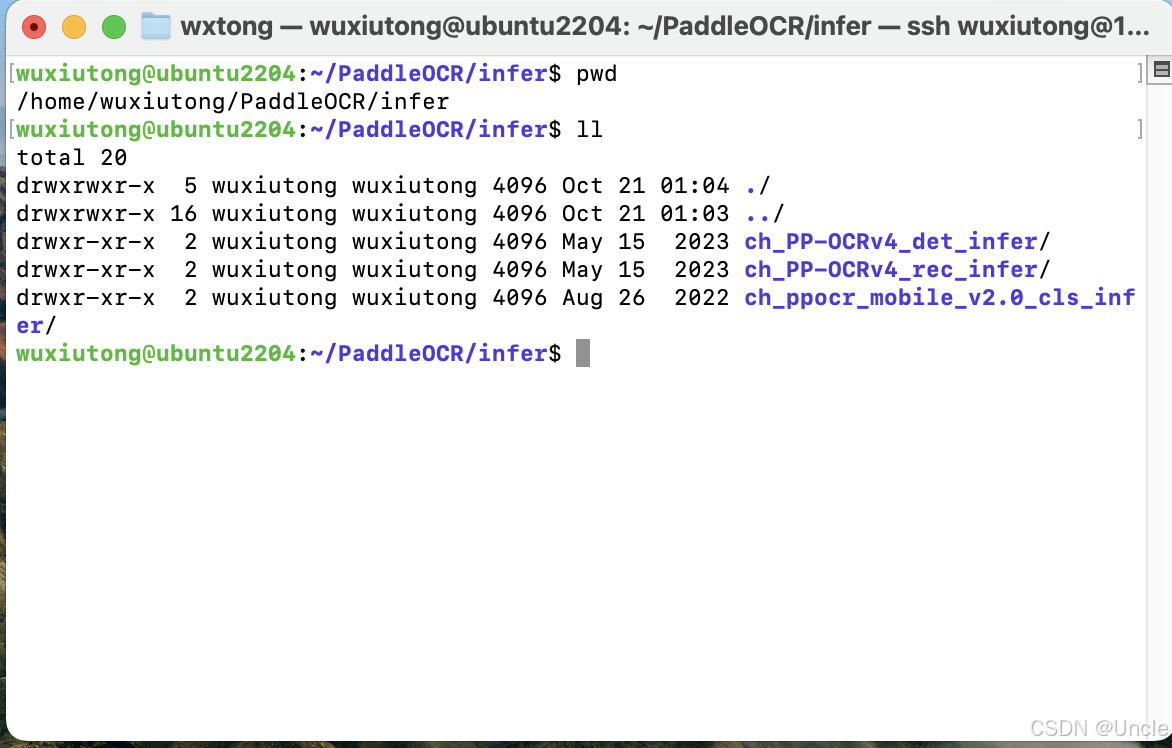
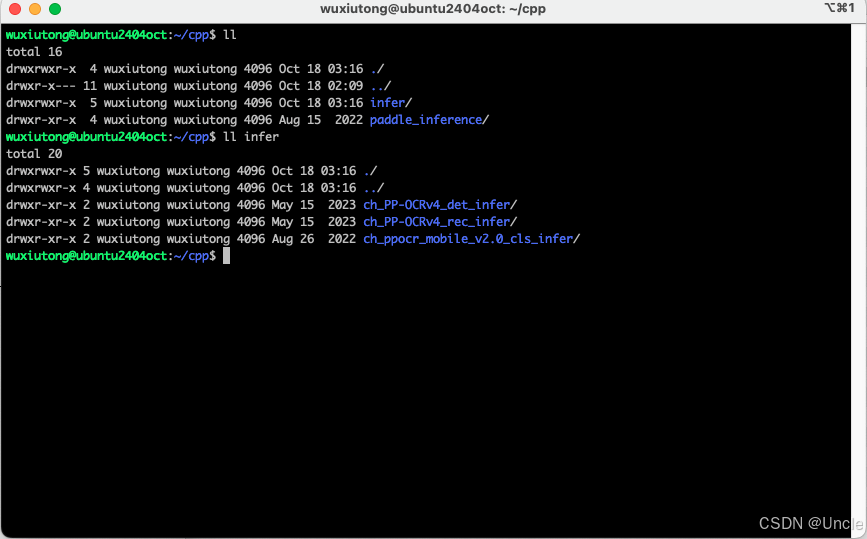
第四步 编译paddleOCR代码
进入PaddleOCR下的deploy/cpp_infer/
bash
cd deploy/cpp_infer1、修改tools/build.sh脚本
修改tools/build.sh文件中的OPENCV_DIR路径指向第一步编译后的opencv文件夹和LIB_DIR路径指向第三步下载的paddle_inference文件夹,因为不使用GPU所以将CUDA_LIB_DIR和CUDNN_LIB_DIR文件夹置空,具体如下
bash
OPENCV_DIR="/home/wuxiutong/opencv"
LIB_DIR="/home/wuxiutong/PaddleOCR/paddle_inference"
CUDA_LIB_DIR=""
CUDNN_LIB_DIR=""
BUILD_DIR=build
rm -rf ${BUILD_DIR}
mkdir ${BUILD_DIR}
cd ${BUILD_DIR}
cmake .. \
-DPADDLE_LIB=${LIB_DIR} \
-DWITH_MKL=ON \
-DWITH_GPU=OFF \
-DWITH_STATIC_LIB=OFF \
-DWITH_TENSORRT=OFF \
-DOPENCV_DIR=${OPENCV_DIR} \
-DCUDNN_LIB=${CUDNN_LIB_DIR} \
-DCUDA_LIB=${CUDA_LIB_DIR} \
-DTENSORRT_DIR=${TENSORRT_DIR} \
make -j上述脚本的中/home/wuxiutong这路径需要替换成你当前电脑。
2、执行编译
执行编译提示没有cmake的时候请安装cmake这个版本提示3.11及以上均可。
sudo apt install cmake运行脚本执行编译
bash
sudo sh ./tools/build.sh若编译报错则主要看后面的异常处理。
编译成功截图如下:
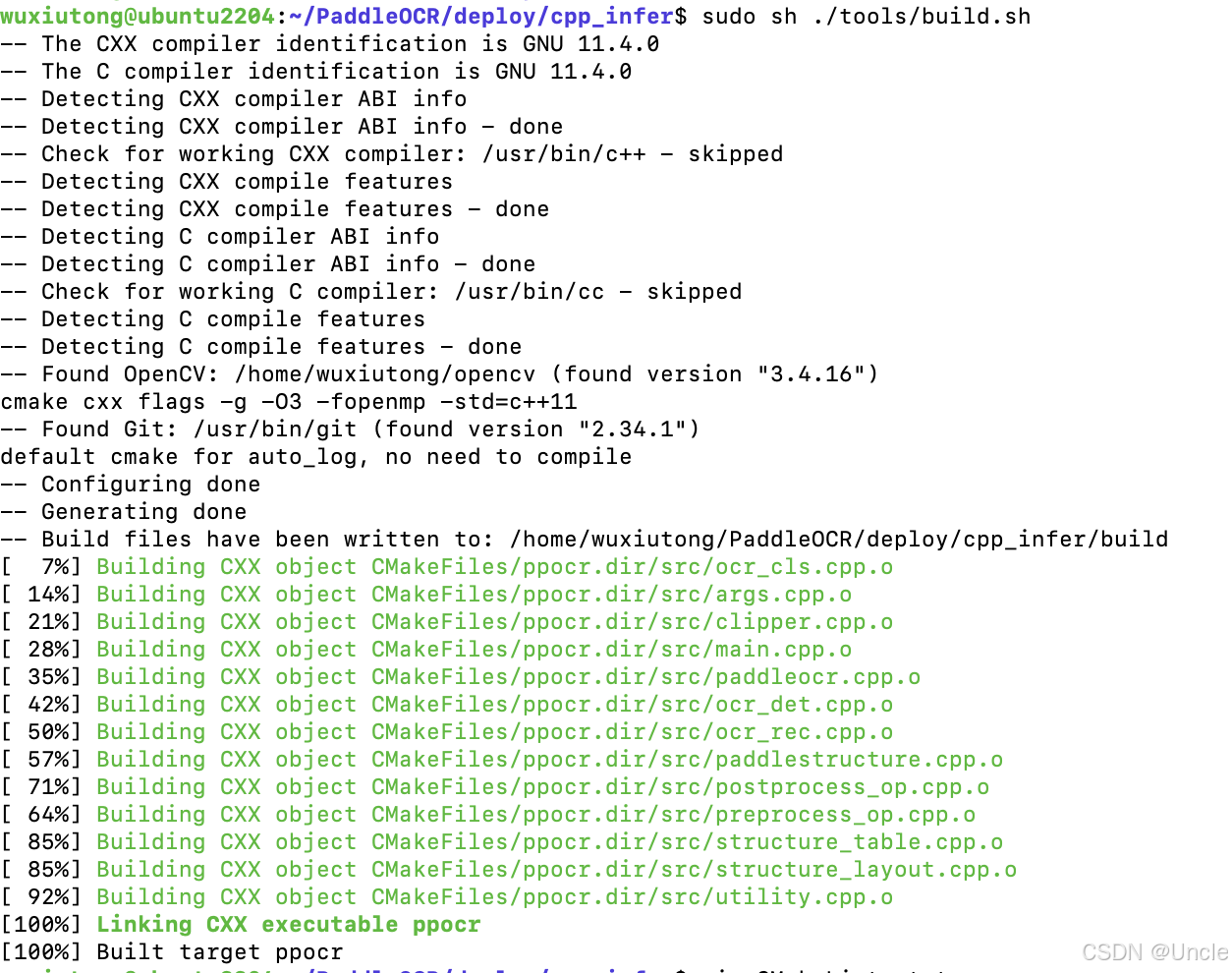
编译成功后在PaddleOCR/deploy/cpp_infer/build下会有一个ppocr可执行文件生成。
3、编译异常处理
a、提示cc1plus: error *****too many filenames given字样报错。
该错误在ubuntu 20.04的g++ 9.4.0上不会报错,但是在ubuntu 22.04的g++ 11.4.0上则会报错,如下图所示
报以上错误则需要去PaddleOCR/deploy/cpp_infer下的CMakeLists.txt文件中第74行的-o3修改成-O3(前者是小写字母,后者是大写字符),如下图所示。
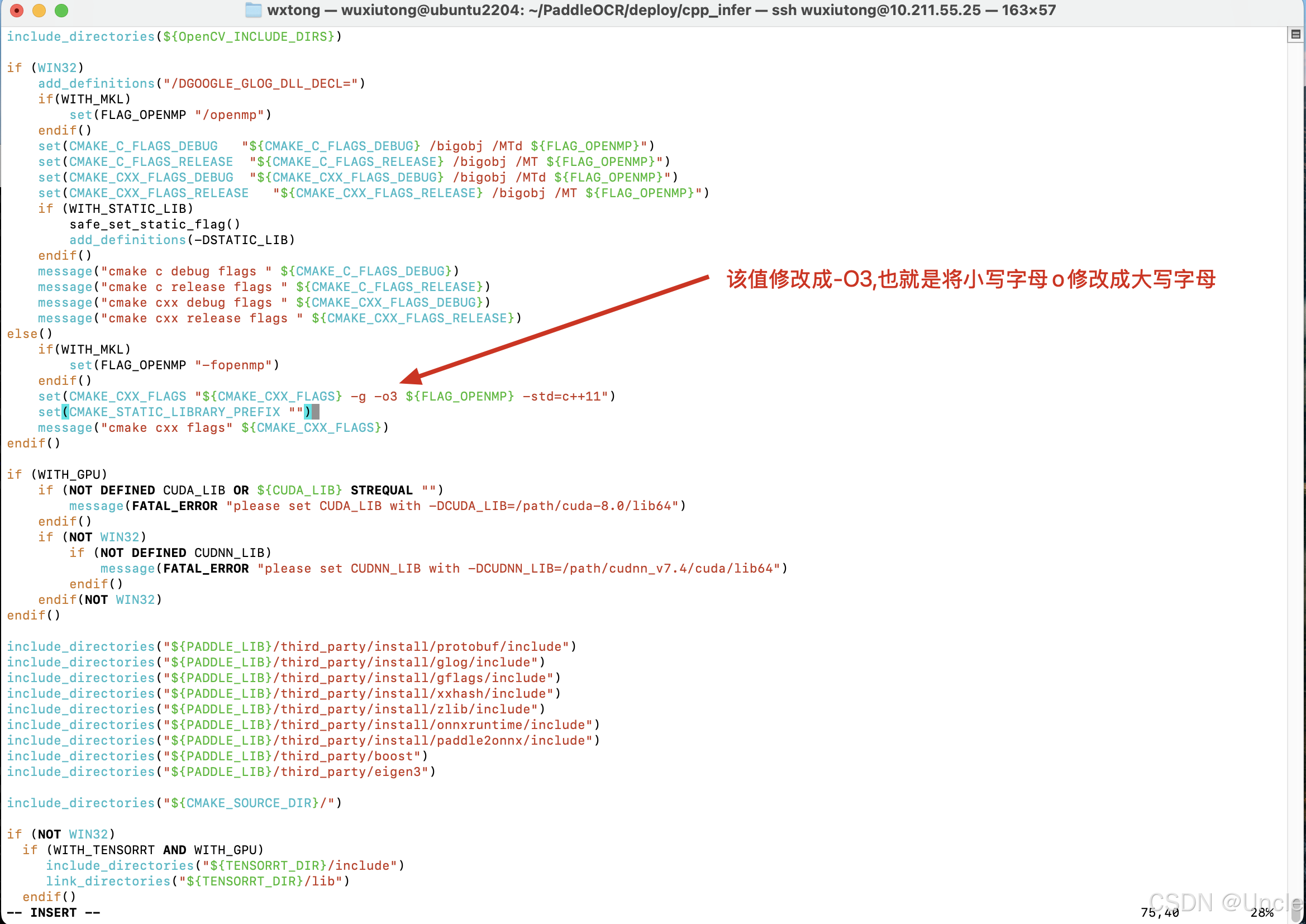
说明:两者区别是大写O是指定编译器优化级别(Optimize的首字母),总共四个级别(-O0不优化,-O1默认值,-O2,-O3最高优化级别),小写o是指定输出文件(output的首字母),应该是官方的打字错误导致)。
b、提示unable to access 'https://github.com/LDOUBLEV/AutoLog.git/字样
该
错误是因为无法方式github导致的,错误如下图所示:
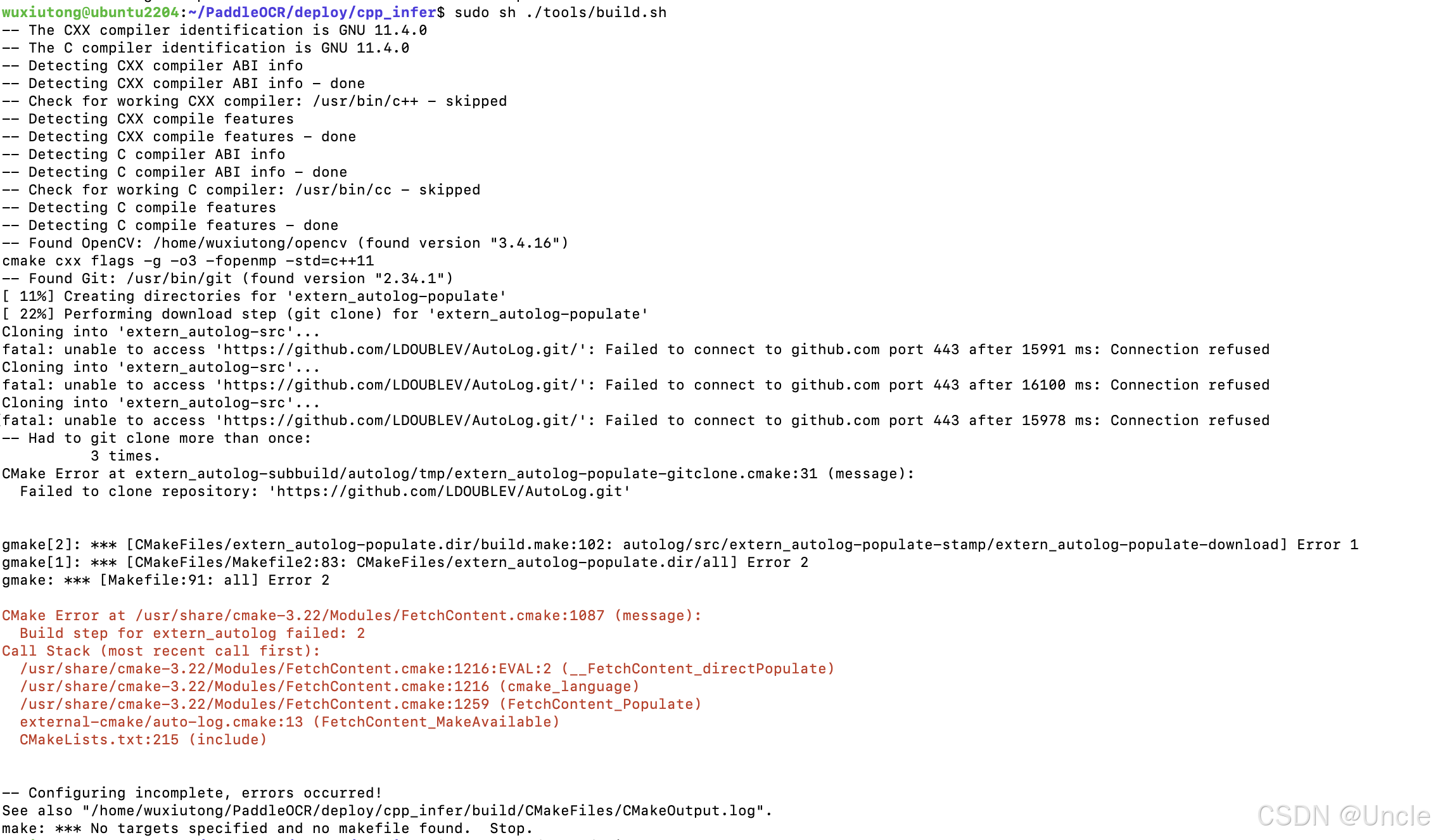
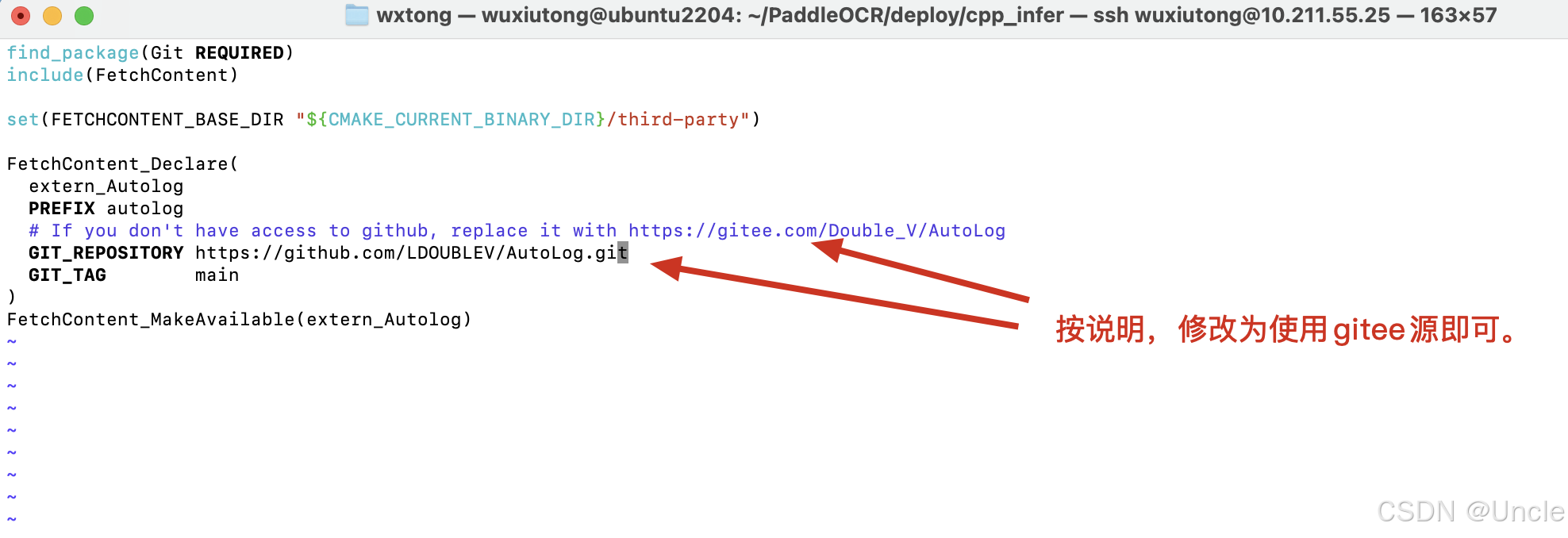
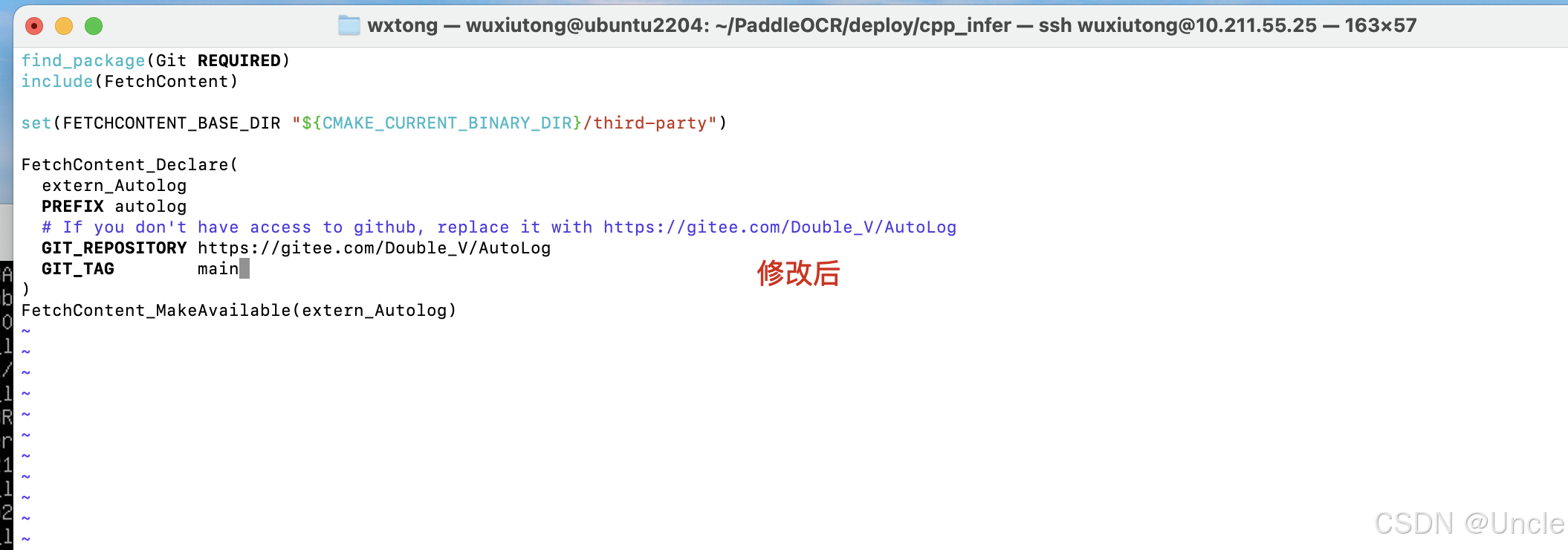
如上图报错则去修改PaddleOCR/deploy/cpp_infer/external-cmake/auto-log.cmake文件,将里面的GIT_REPOSITORY修改整gitee库即可解决。
c、提示opencv***.cmake文件找不到
报错如下图所示:
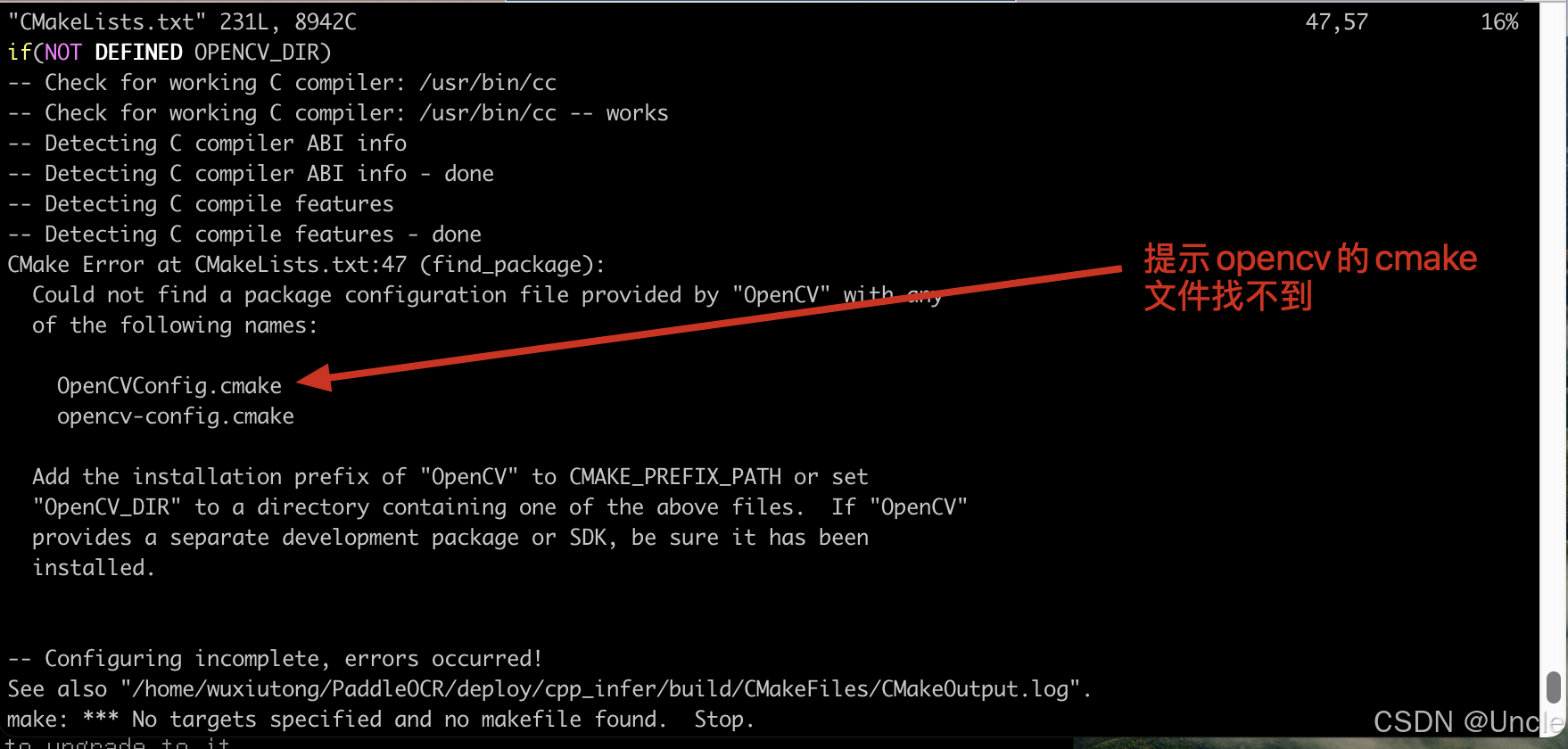
以上是编译时检测opencv的cmake文件位置,查看deploy/cpp_infer下的CMakeLists.txt文件发现默认查找的是opencv/share/OpenCV文件夹下如图所示:
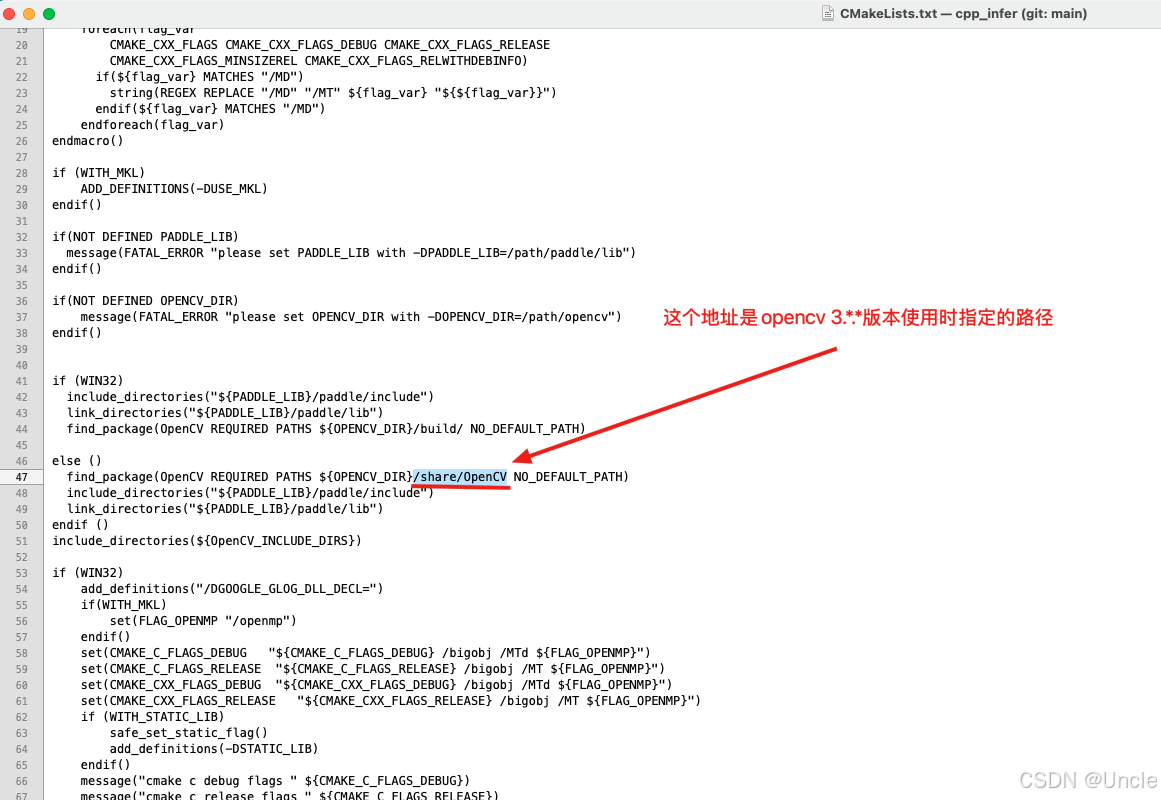
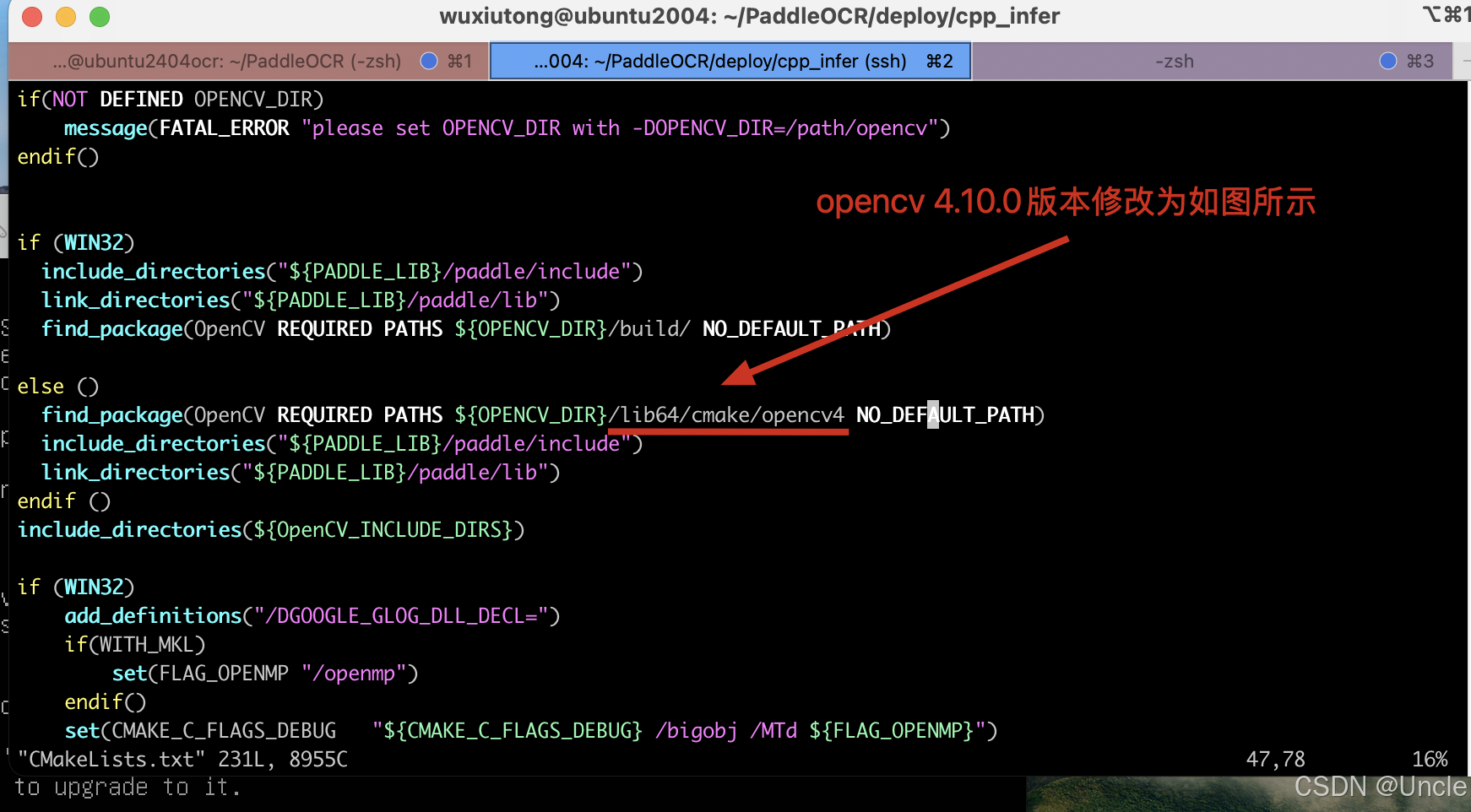
请自行去编译好的opencv路径下查找包含"OpenCVConfig-version.cmake,OpenCVConfig.cmake, OpenCVModules-release.cmake,OpenCVModules.cmake"的路径,然后将deploy/cpp_infer/CMakeLists.txt下如上图所示路径做调整执行以上路径。
如opencv-4.10.0编译时指定了"-DCMAKE_INSTALL_LIBDIR=lib64",所以需要将该地址修改为如下图所示:
第五步 运行ppocr识别图片
1、添加运行脚本ocr.sh
添加在PaddleOCR/deploy/cpp_infer/下新增运行脚本ocr.sh
bash
vim ocr.shrun.sh脚本内容如下,其中/home/wuxiutong/infer/路径部分根据你实际下载的ocr模型地址调整,--image_dir值可以指向具体图片或者一个文件夹(一个文件夹则文件夹下的所有图片格式jpg、png都会被执行ocr识别,该图片自行准备)。
bash
./build/ppocr --det_model_dir=/home/wuxiutong/PaddleOCR/infer/ch_PP-OCRv4_det_infer \
--rec_model_dir=/home/wuxiutong/PaddleOCR/infer/ch_PP-OCRv4_rec_infer \
--cls_model_dir=/home/wuxiutong/PaddleOCR/infer/ch_ppocr_mobile_v2.0_cls_infer \
--image_dir=/home/wuxiutong/pic/jzpz1.png \
--use_angle_cls=true \
--det=true \
--rec=true \
--cls=true \2、执行ocr识别
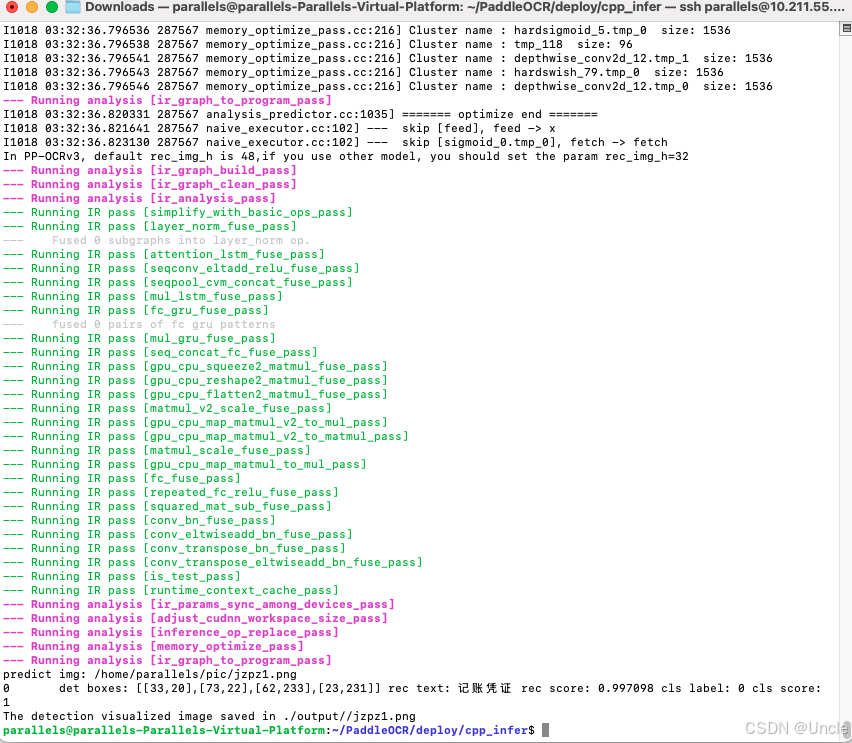
bash
sh ocr.sh识别结果如下图所示
3、运行报错排查
如果执行遇到类似于如下的报错则需要去paddle_inference/install下找提示中的如libiomp5.so文件然后做个软连接到/usr/lib/下就可以解决。
./build/ppocr: error while loading shared libraries: libiomp5.so: cannot open shared object file: No such file or directory
以下就是我整理的需要连接的库文件,其中/home/wuxiutong/PaddleOCR/paddle_inference/路径需要根据前面"第三步"下载的paddleOCR推理库路径修改。
bash
sudo ln -s /home/wuxiutong/PaddleOCR/paddle_inference/third_party/install/mklml/lib/libiomp5.so /usr/lib/libiomp5.so
sudo ln -s /home/wuxiutong/PaddleOCR/paddle_inference/third_party/install/onnxruntime/lib/libonnxruntime.so /usr/lib/libonnxruntime.so.1.11.1
sudo ln -s /home/wuxiutong/PaddleOCR/paddle_inference/third_party/install/paddle2onnx/lib/libpaddle2onnx.so /usr/lib/libpaddle2onnx.so.1.0.0rc2
sudo ln -s /home/wuxiutong/PaddleOCR/paddle_inference/third_party/install/mkldnn/lib/libdnnl.so.2 /usr/lib/libdnnl.so.2最后再次运行sh run.sh即可出现识别成功提示。
本文更新日期:2024年11月22日
下文将会讲些windows下如何执行编译。