我自己的原文哦~https://blog.51cto.com/whaosoft/12304421
#NeRF与自动驾驶
神经辐射场(Neural Radiance Fields)自2020年被提出以来,相关论文数量呈指数增长,不但成为了三维重建的重要分支方向,也逐渐作为自动驾驶重要工具活跃在研究前沿。
NeRF这两年异军突起,主要因为它跳过了传统CV重建pipeline的特征点提取和匹配、对极几何与三角化、PnP加Bundle Adjustment等步骤,甚至跳过mesh的重建、贴图和光追,直接从2D输入图像学习一个辐射场,然后从辐射场输出逼近真实照片的渲染图像。也就是说,让一个基于神经网络的隐式三维模型,去拟合指定视角下的2D图像,并使其兼具新视角合成和能力。NeRF的发展也和自动驾驶息息相关,具体体现在真实的场景重建和自动驾驶仿真器的应用中。NeRF擅长呈现照片级别的图像渲染,因此用NeRF建模的街景能够为自动驾驶提供高真实感的训练数据;NeRF的地图可以编辑,将建筑、车辆、行人组合成各种现实中难以捕捉的corner case,能够用于检验感知、规划、避障等算法的性能。因此,NeRF作为一个三维重建的分支方向和建模工具,掌握NeRF已经成为了研究者们做重建或者自动驾驶方向必不可少的技能。
梳理下Nerf与自动驾驶相关的内容,近11篇文章,带着大家探索Nerf与自动驾驶的前世今生;
1.Nerf开山之作
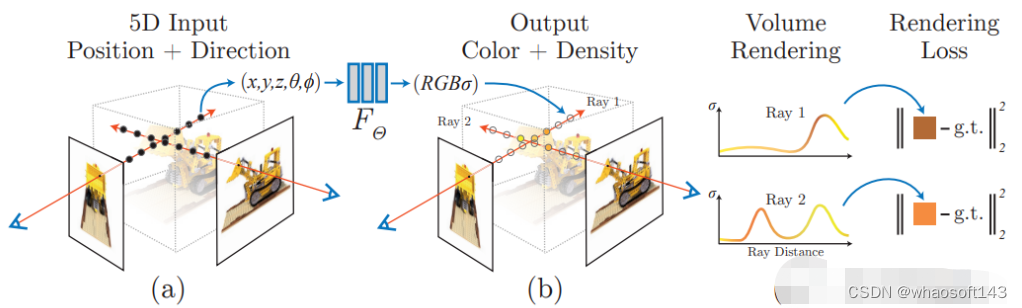
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV2020.
首篇,开山之作,提出了Nerf方法,该方法通过使用稀疏的输入视图集优化底层连续体积场景函数,实现了合成复杂场景的新视图的最新结果。算法使用全连接(非卷积)深度网络来表示场景,其输入是单个连续5D坐标(空间位置(x,y,z)和观看方向(θ,ξ)),其输出是该空间位置的体积密度和与视图相关的发射辐射。
NERF用 2D 的 posed images 作为监督,无需对图像进行卷积,而是通过不断学习位置编码,用图像颜色作为监督,来学习一组隐式参数,表示复杂的三维场景。通过隐式表示,可以完成任意视角的渲染。
2.Mip-NeRF 360
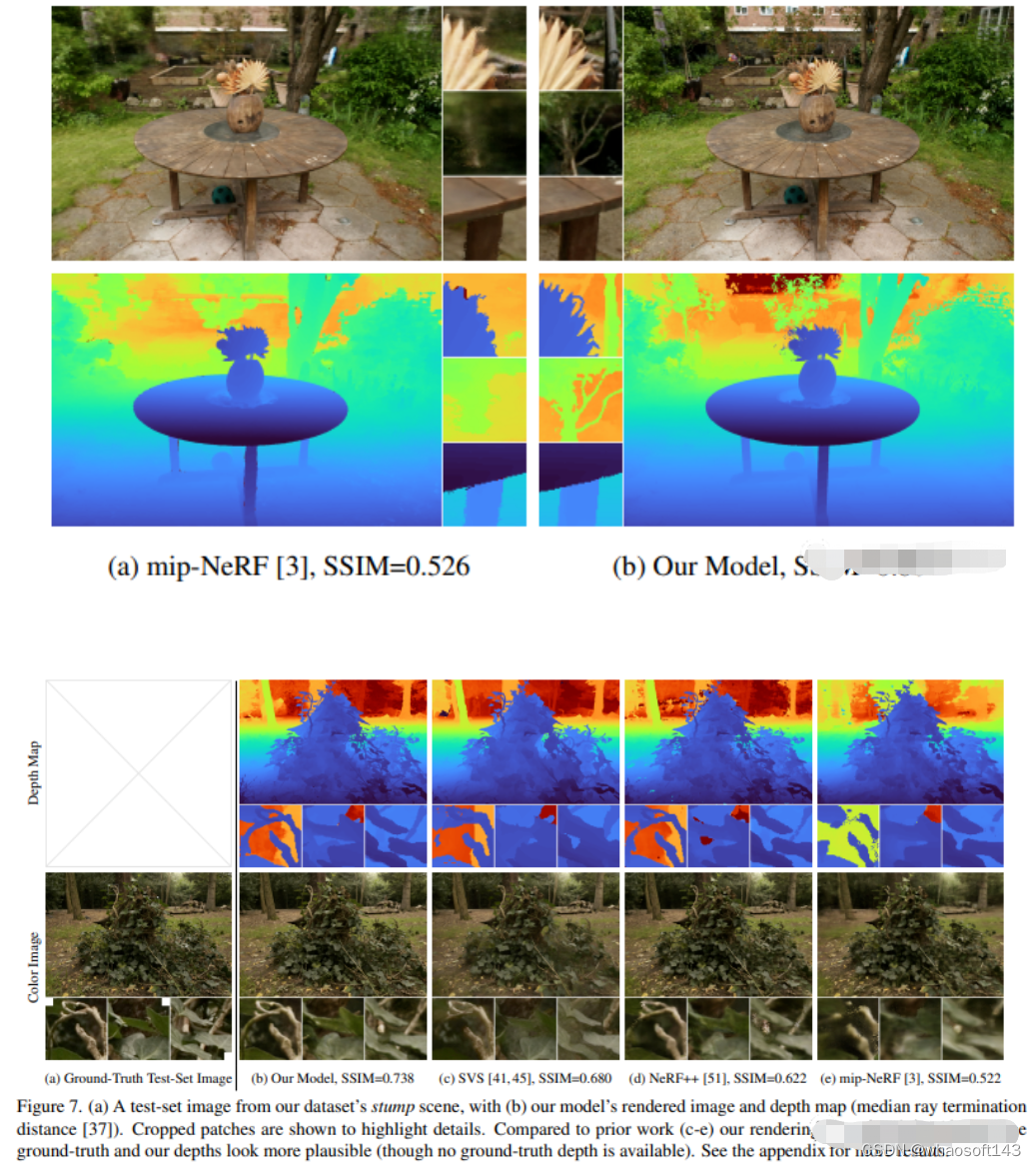
CVPR2020的工作,室外无边界场景相关。Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields
论文链接:https://arxiv.org/pdf/2111.12077.pdf
尽管神经辐射场(NeRF)已经在物体和空间的小边界区域上展示了不错的视图合成结果,但它们在"无边界"场景中很难实现,在这些场景中,相机可能指向任何方向,内容可能存在于任何距离。在这种情况下,现有的类NeRF模型通常会产生模糊或低分辨率的渲染(由于附近和远处物体的细节和比例不平衡),训练速度较慢,并且由于从一组小图像重建大场景的任务的固有模糊性,可能会出现伪影。本文提出了mip-NeRF(一种解决采样和混叠问题的NeRF变体)的扩展,它使用非线性场景参数化、在线蒸馏和一种新的基于失真的正则化子来克服无界场景带来的挑战。与mip-NeRF相比,均方误差减少了57%,并且能够为高度复杂、无边界的真实世界场景生成逼真的合成视图和详细的深度图。
3.Instant-NGP
显示体素加隐式特征的混合场景表达(SIGGRAPH 2022)
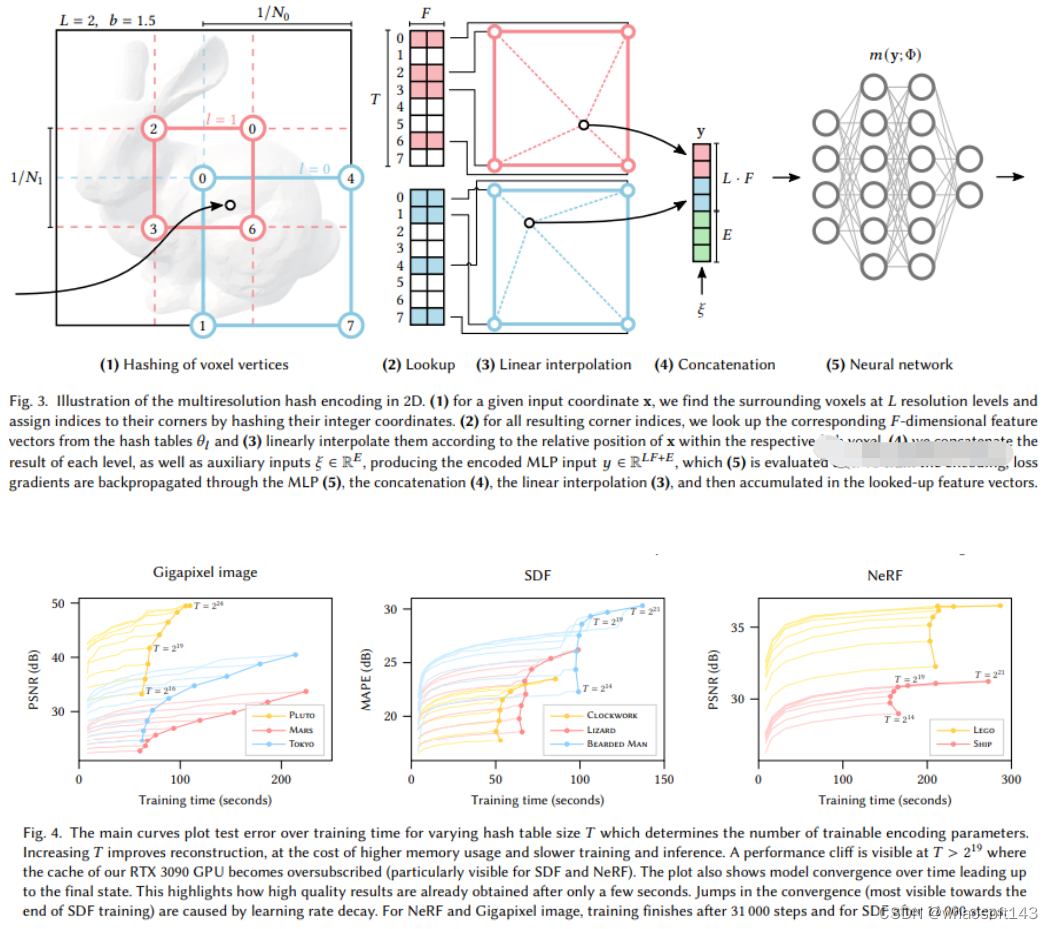
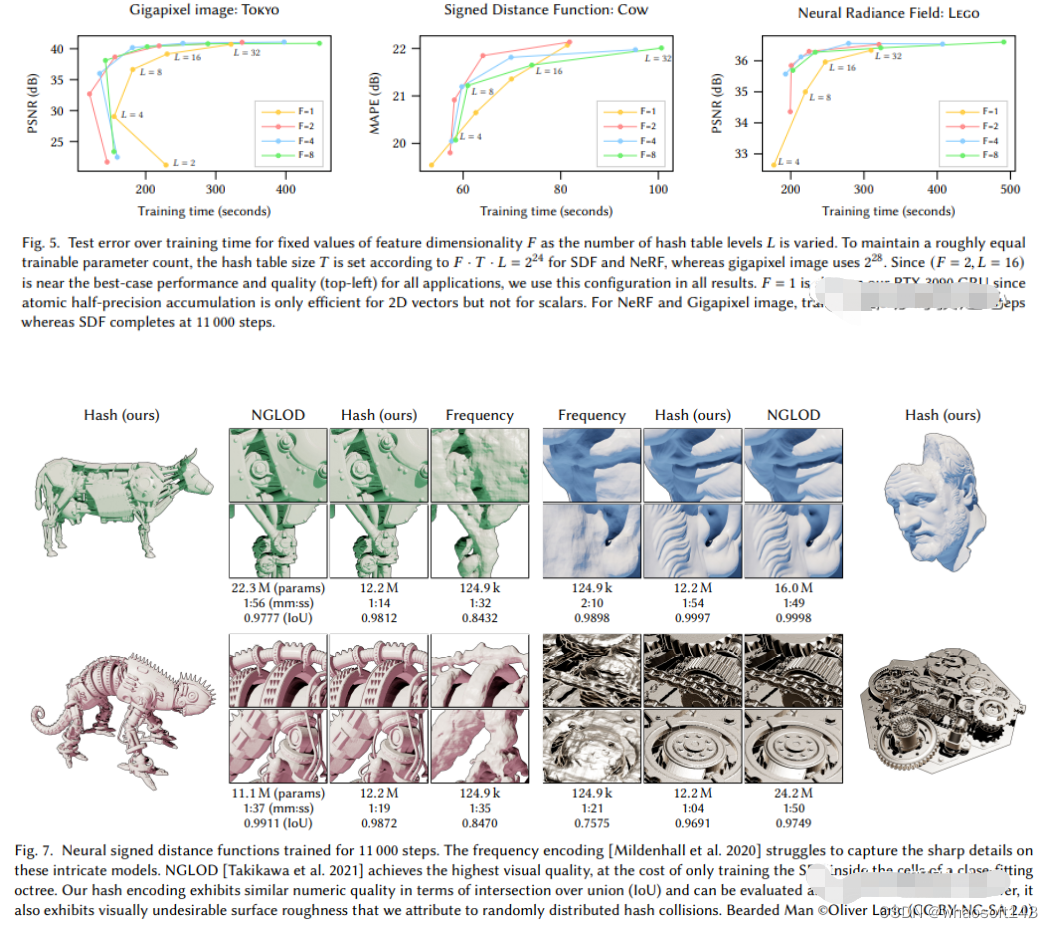
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
链接:https://nvlabs.github.io/instant-ngp
这里先直接给出Instant-NGP与NeRF的异同:
- 同样基于体渲染
- 不同于NeRF的MLP,NGP使用稀疏的参数化的voxel grid作为场景表达;
- 基于梯度,同时优化场景和MLP(其中一个MLP用作decoder)。
可以看出,大的框架还是一样的,最重要的不同,是NGP选取了参数化的voxel grid作为场景表达。通过学习,让voxel中保存的参数成为场景密度的形状。MLP最大的问题就是慢。为了能高质量重建场景,往往需要一个比较大的网络,每个采样点过一遍网络就会耗费大量时间。而在grid内插值就快的多。但是grid要表达高精度的场景,就需要高密度的voxel,会造成极高的内存占用。考虑到场景中有很多地方是空白的,所以NVIDIA就提出了一种稀疏的结构来表达场景。

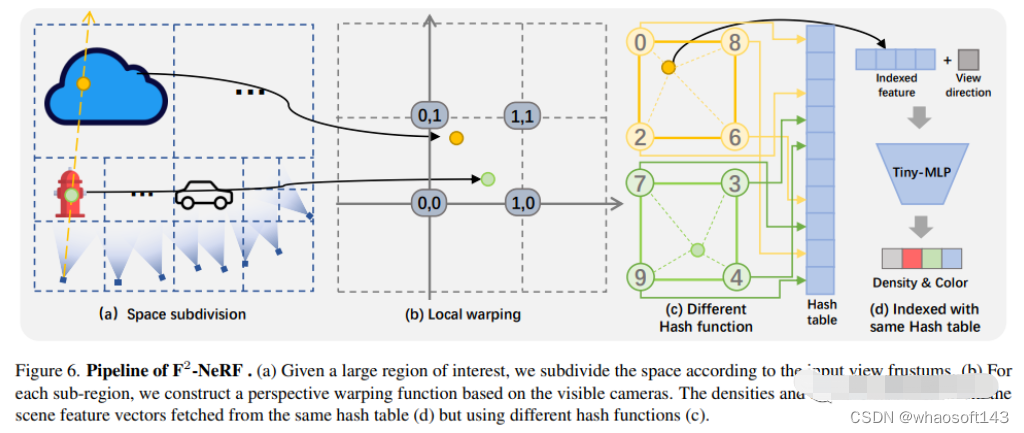
4. F2-NeRF
F2-NeRF: Fast Neural Radiance Field Training with Free Camera Trajectories
论文链接:https://totoro97.github.io/projects/f2-nerf/
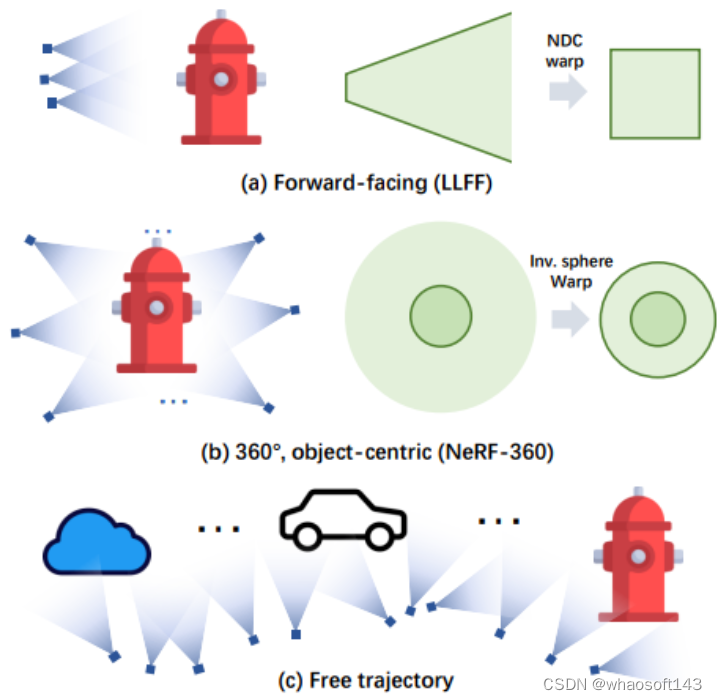
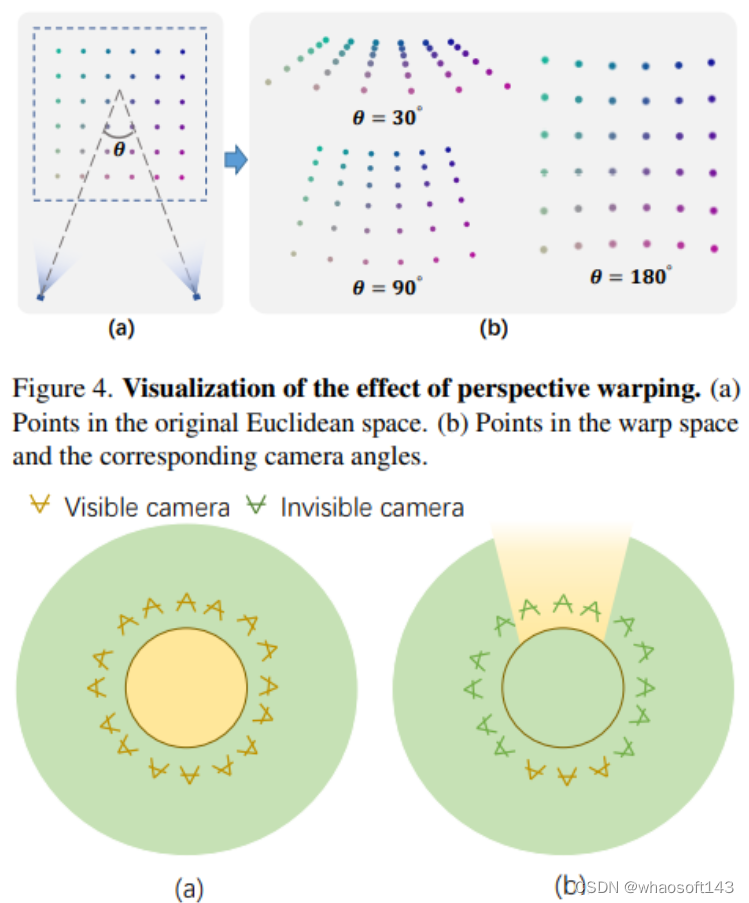
提出了一种新的基于网格的NeRF,称为F2-NeRF(Fast Free NeRF),用于新的视图合成,它可以实现任意输入的相机轨迹,并且只需要几分钟的训练时间。现有的基于快速网格的NeRF训练框架,如Instant NGP、Plenoxels、DVGO或TensoRF,主要针对有界场景设计,并依靠空间warpping来处理无界场景。现有的两种广泛使用的空间warpping方法仅针对面向前方的轨迹或360◦ 以物体为中心的轨迹,但不能处理任意的轨迹。本文深入研究了空间warpping处理无界场景的机制。进一步提出了一种新的空间warpping方法,称为透视warpping,它允许我们在基于网格的NeRF框架中处理任意轨迹。大量实验表明,F2-NeRF能够在收集的两个标准数据集和一个新的自由轨迹数据集上使用相同的视角warpping来渲染高质量图像。

5.MobileNeRF
移动端实时渲染,Nerf导出Mesh,被CVPR2023收录!
MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures.
https://arxiv.org/pdf/2208.00277.pdf
神经辐射场(NeRF)已经证明了从新颖的视图合成3D场景图像的惊人能力。然而,它们依赖于基于光线行进的专用volumetric 渲染算法,这些算法与广泛部署的图形硬件的功能不匹配。本文介绍了一种新的基于纹理多边形的NeRF表示,该表示可以通过标准渲染pipeline有效地合成新图像。NeRF表示为一组多边形,其纹理表示二元不透明性和特征向量。使用z缓冲区对多边形进行传统渲染会生成每个像素都具有特征的图像,这些特征由片段着色器中运行的小型视图相关MLP进行解释,以生成最终的像素颜色。这种方法使NeRF能够使用传统的多边形光栅化pipeline进行渲染,该pipeline提供了巨大的像素级并行性,在包括手机在内的各种计算平台上实现交互式帧率。


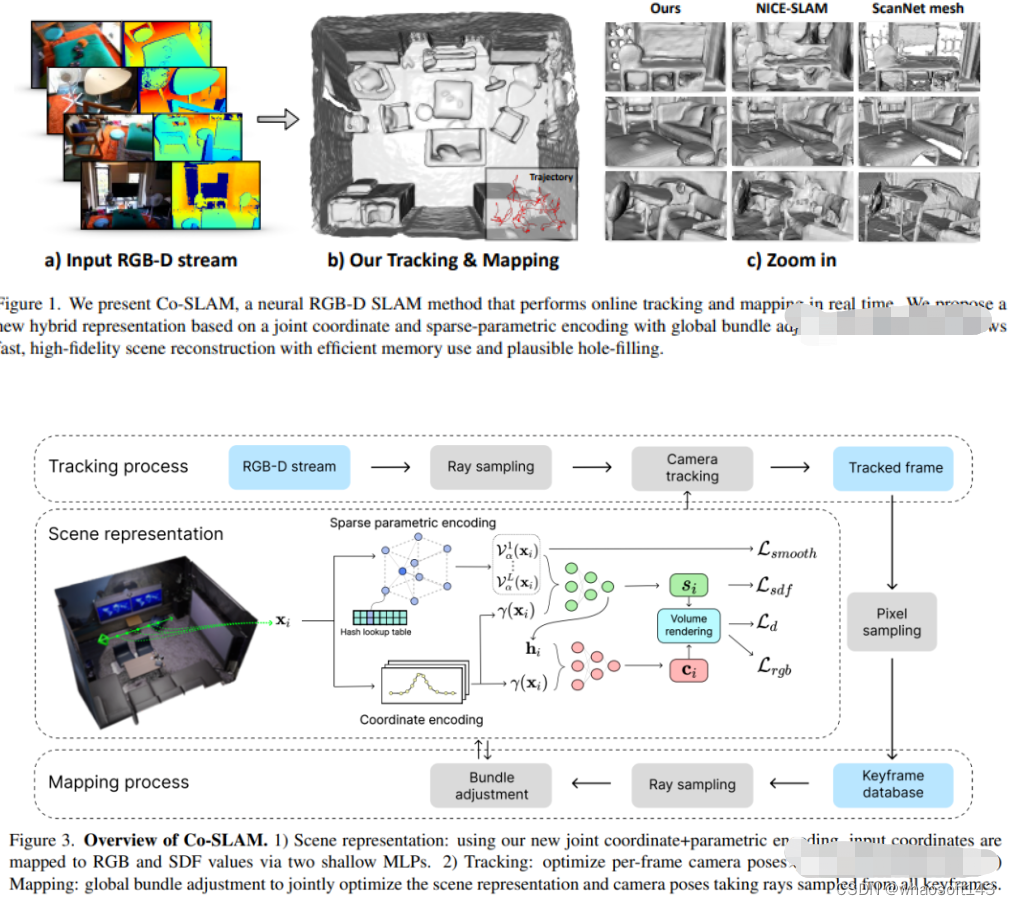
6.Co-SLAM
实时视觉定位和NeRF建图工作,被CVPR2023收录;
Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM
论文链接:https://arxiv.org/pdf/2304.14377.pdf
Co-SLAM是一个基于神经隐式表示的实时RGB-D SLAM系统,能够进行相机跟踪和高保真度的表面重建。Co-SLAM将场景表示为多分辨率哈希网格,以利用其极高的收敛速度和表示高频局部特征的能力。此外,为了融合表面一致性先验,Co-SLAM添加了一种块状编码方法,证明它使得在未观测区域能够进行强大的场景补全。我们的联合编码将两种优点结合到了Co-SLAM中:速度、高保真度重建以及表面一致性先验,射线采样策略使得Co-SLAM能够对所有关键帧进行全局捆绑调整!
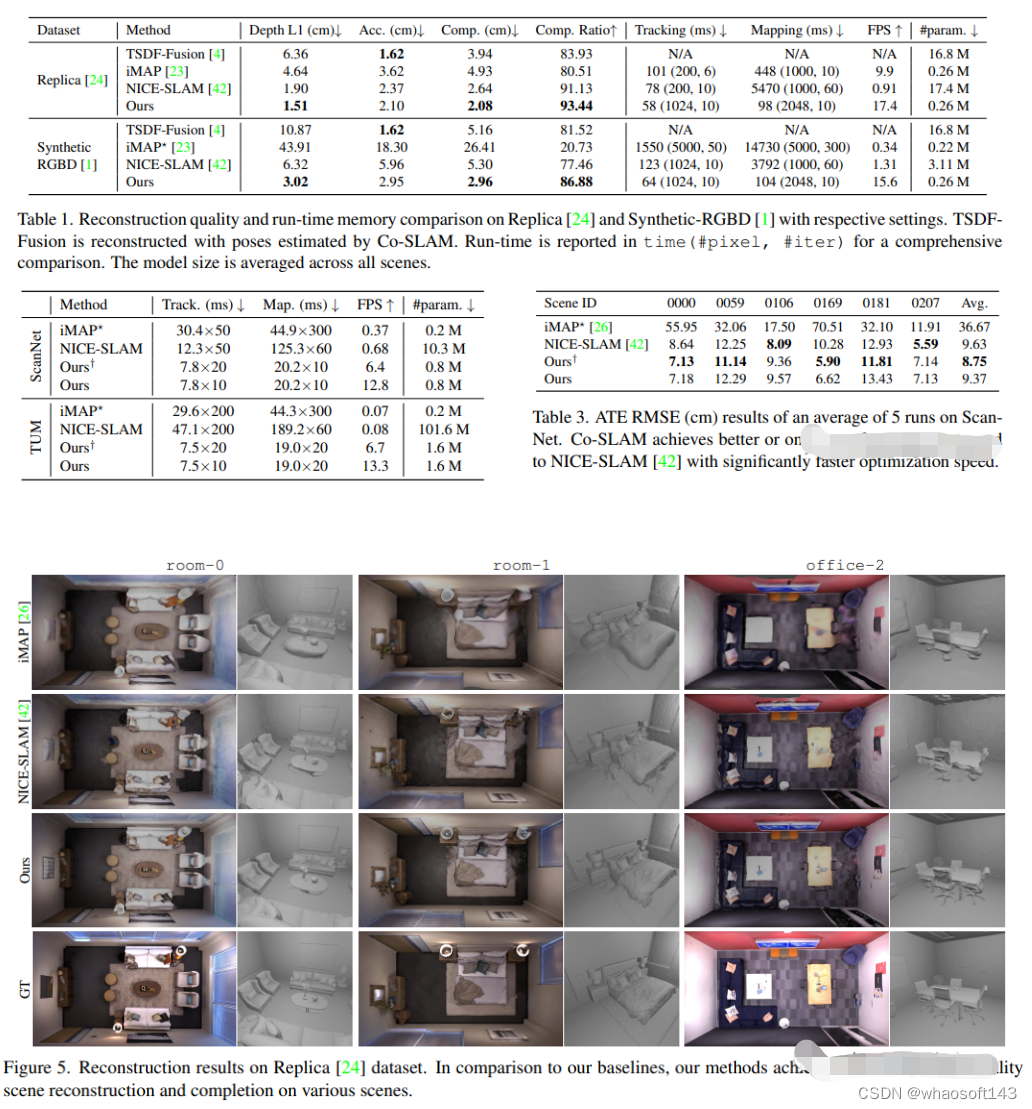
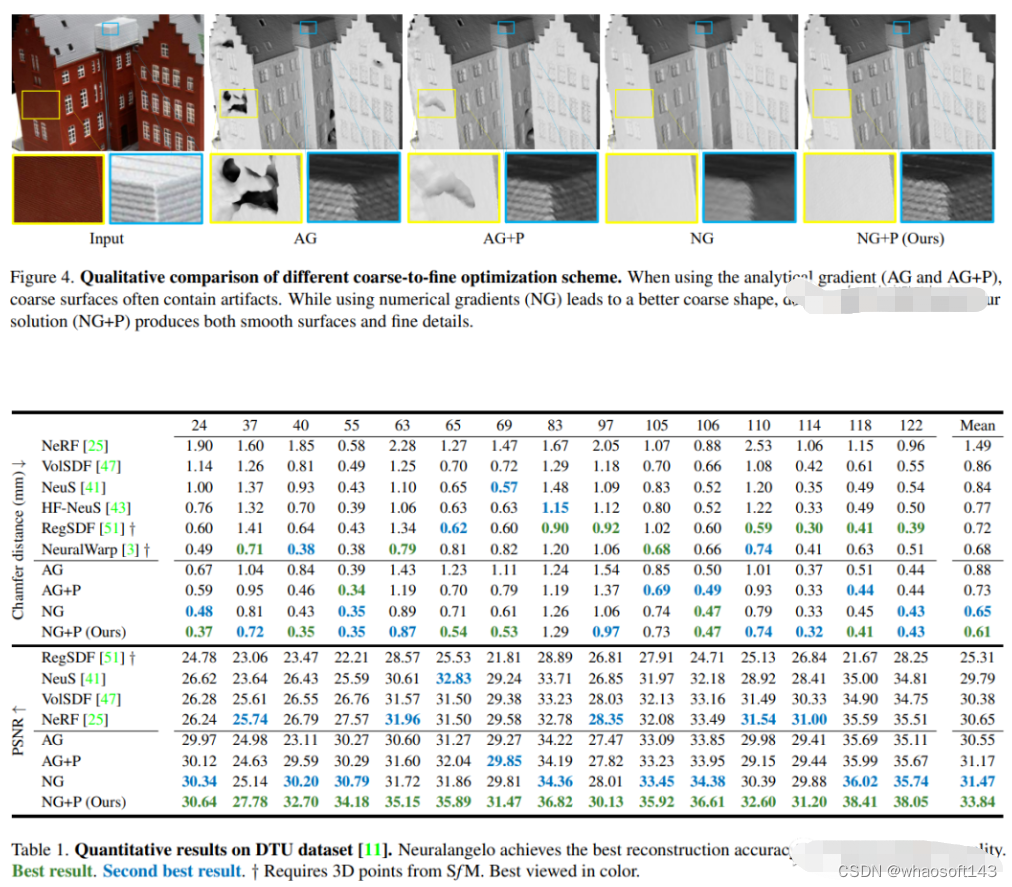
7.Neuralangelo
当前最好的NeRF表面重建方法(CVPR2023)

神经表面重建已被证明可以通过基于图像的神经渲染来恢复密集的3D表面。然而,目前的方法很难恢复真实世界场景的详细结构。为了解决这个问题,本文提出了Neuralangelo,它将多分辨率3D哈希网格的表示能力与神经表面渲染相结合。两个关键因素:
(1) 用于计算作为平滑操作的高阶导数的数值梯度,以及(2)控制不同细节级别的哈希网格上的从粗到细优化。
即使没有深度等辅助输入,Neuralangelo也可以有效地从多视图图像中恢复密集的3D表面结构,其保真度大大超过了以前的方法,从而能够从RGB视频捕获中进行详细的大规模场景重建!


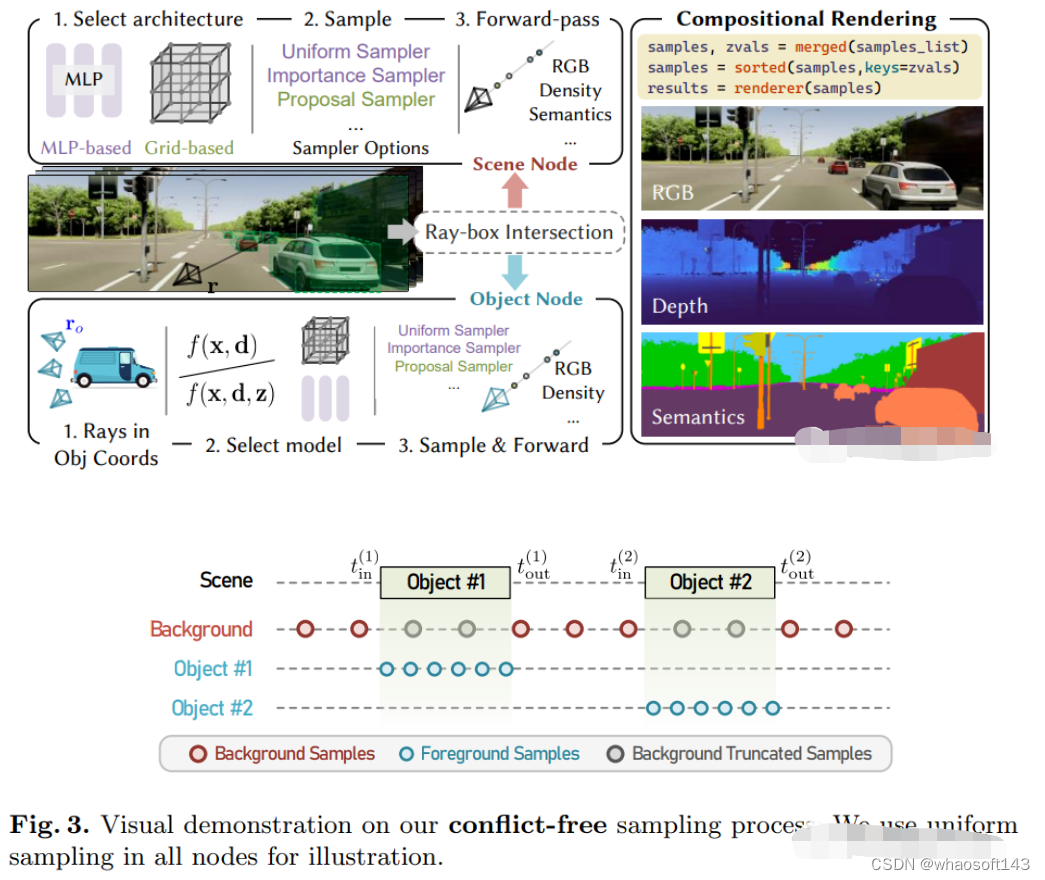
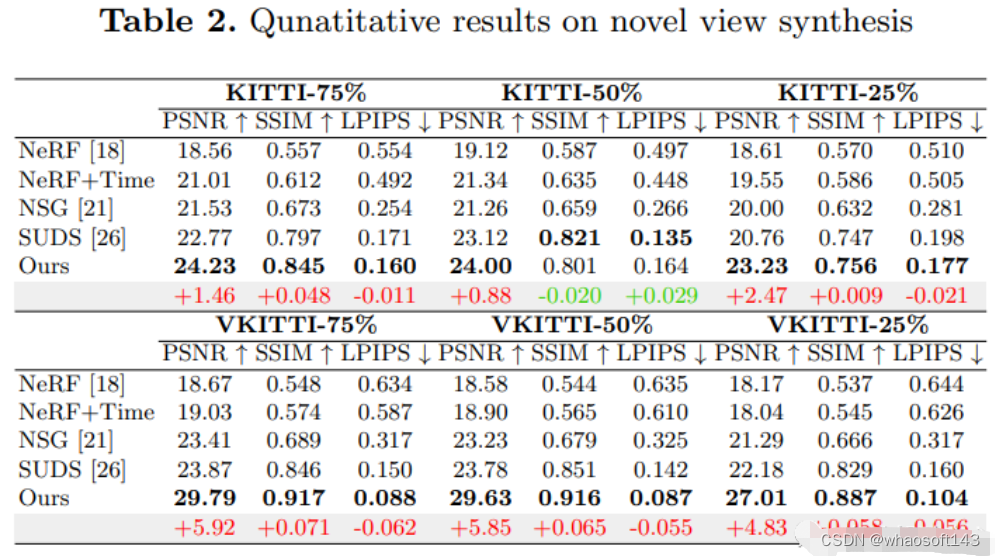
8.MARS
首个开源自动驾驶NeRF仿真工具。
https://arxiv.org/pdf/2307.15058.pdf
自动驾驶汽车在普通情况下可以平稳行驶,人们普遍认为,逼真的传感器模拟将在解决剩余拐角情况方面发挥关键作用。为此,MARS提出了一种基于神经辐射场的自动驾驶模拟器。与现有作品相比,MARS有三个显著特点:(1)实例意识。模拟器使用独立的网络分别对前景实例和背景环境进行建模,以便可以分别控制实例的静态(例如大小和外观)和动态(例如轨迹)特性。(2) 模块化。模拟器允许在不同的现代NeRF相关主干、采样策略、输入模式等之间灵活切换。希望这种模块化设计能够推动基于NeRF的自动驾驶模拟的学术进步和工业部署。(3) 真实。模拟器在最佳模块选择的情况下,设置了最先进的真实感结果。
最重要的一点是:开源!

9.UniOcc
NeRF和3D占用网络, AD2023 Challenge
UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering.
论文链接:https://arxiv.org/abs/2306.09117
UniOCC是以视觉为中心的3D占用预测,用于占用预测的现有方法主要集中于使用3D占用标签来优化3D volume 空间上的投影特征。然而,这些标签的生成过程复杂且昂贵(依赖于3D语义注释),并且受体素分辨率的限制,它们无法提供细粒度的空间语义。为了解决这一限制,本文提出了一种新的统一占用(UniOcc)预测方法,明确施加空间几何约束,并通过体射线渲染补充细粒度语义监督。方法显著提高了模型性能,并证明了在降低人工标注成本方面的潜力。考虑到标注3D占用的费力性质,进一步引入了深度感知师生(DTS)框架,以使用未标记数据提高预测精度。解决方案在单机型的官方排行榜上获得了51.27%mIoU的成绩,在本次挑战中排名第三。
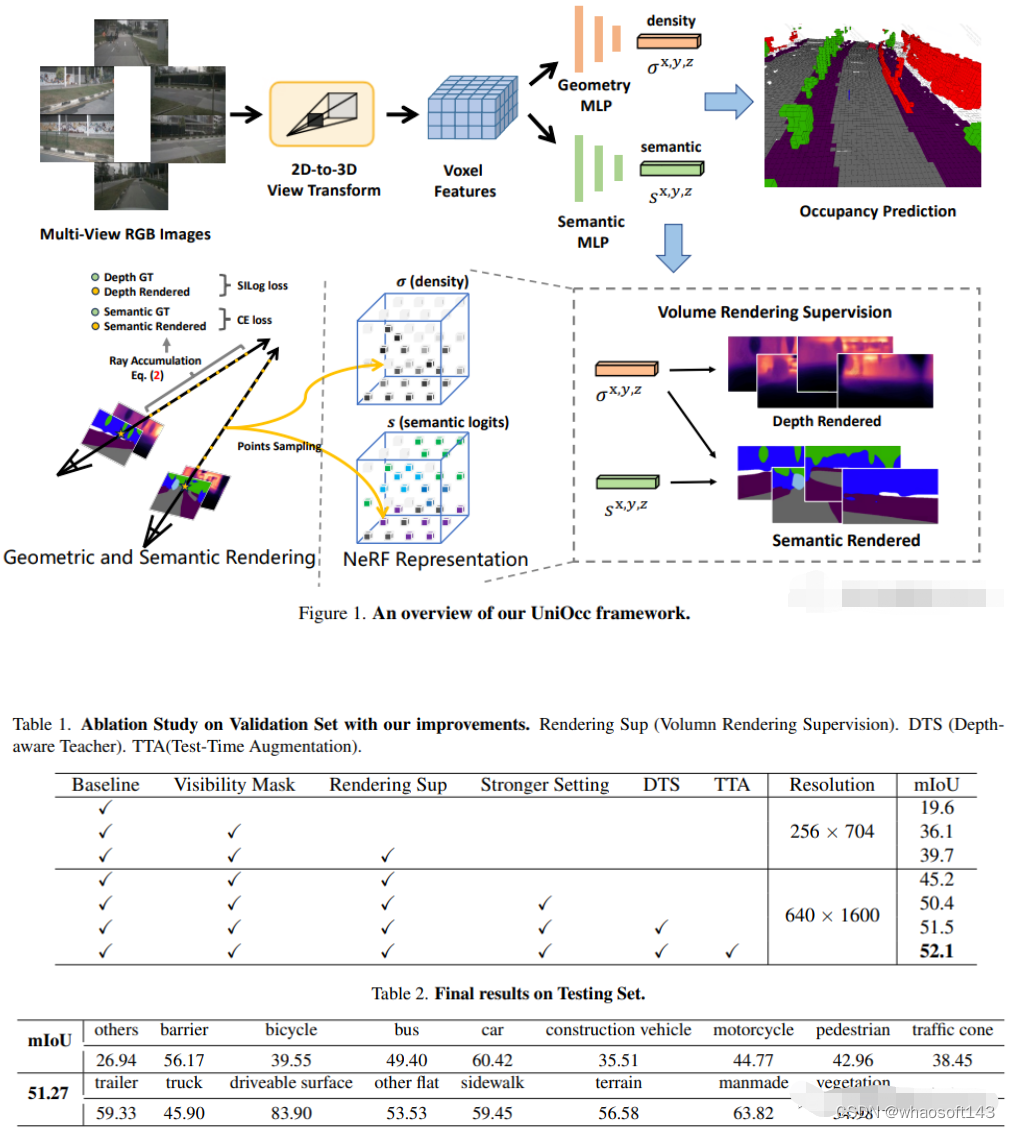
10.Unisim
waabi出品,必是精品啊!
UniSim: A Neural Closed-Loop Sensor Simulator
论文链接:https://arxiv.org/pdf/2308.01898.pdf
阻碍自动驾驶普及的一个重要原因是安全性仍然不够。真实世界过于复杂,尤其是存在长尾效应(long tail)。边界场景对安全驾驶至关重要,很多样,但又很难遇到。测试自动驾驶系统在这些场景的表现非常困难,因为这些场景很难遇到,而且在真实世界中测试非常昂贵和危险。
为了解决这个挑战,工业界和学术界都开始重视仿真系统的开发。一开始,仿真系统主要专注于模拟其他车辆/行人的运动行为,测试自动驾驶规划模块的准确性。而最近几年,研究重心逐渐转向传感器层面的仿真,即仿真生成激光雷达、相机图片等原始数据,实现端到端测试自动驾驶系统从感知、预测一直到规划。
不同于以往工作, UniSim首次同时做到了:
- 高度逼真(high realism): 可以准确地模拟真实世界(图片和LiDAR), 减小鸿沟(domain gap )
- 闭环测试(closed-loop simulation): 可以生成罕见的危险场景测试无人车, 并允许无人车和环境自由交互
- 可扩展 (scalable): 可以很容易的扩展到更多的场景, 只需要采集一次数据, 就能重建并仿真测

仿真系统的搭建
UniSim 首先从采集的数据中,在数字世界中重建 自动驾驶场景,包括汽车、行人、道路、建筑和交通标志。然后,控制重建的场景进行仿真,生成一些罕见的关键场景。
闭环仿真(closed-loop simulation)
UniSim可以进行闭环的仿真测试,首先, 通过控制汽车的行为, UniSim可以创建一个危险的罕见场景, 比如有一辆汽车在当前车道突然迎面驶来;然后, UniSim仿真生成对应的数据;接着, 运行自动驾驶系统, 输出路径规划的结果;根据路径规划的结果, 无人车移动到下一个指定位置, 并更新场景(无人车和其他车辆的位置);然后我们继续进行仿真, 运行自动驾驶系统, 更新虚拟世界状态 ......通过这种闭环测试, 自动驾驶系统和仿真环境可以进行交互, 创造出与原始数据完全不一样的场景


#自动驾驶中的MPC控制
目前的车辆控制中,最火的控制器就是MPC了。在学校,如果你不做MPC控制,不懂MPC控制,是绝对不好意思说是做车辆控制的。MPC坐稳了学界中车辆控制器中的第一把交椅,但是在业界中呢?
不咋地。
业界中最火的还是LQR+PID。。。
这就要聊聊MPC到底哪里比LQR强了,我认为,MPC最大的优势就是可以有不等式约束。
举一个栗子。
你要上一个两米高的屋顶,直接蹦肯定上不去,容易腿摔折,咋办呢?首先你要知道自己的弹跳能力,比如小于半米,超过了就蹦不上去了,所以你要弄来三个相差半米的台阶,蹦四次就能上房揭瓦了。
MPC控制器就能够直接按照一定的约束计算出台阶以及你该咋蹦。
那为什么在业界中MPC还不咋地呢?
我们先不谈MPC控制器的参数调节难度和稳定性的问题(这问题忒大了)。就看必要性。
来,看图, apollo 的L3的模块图。
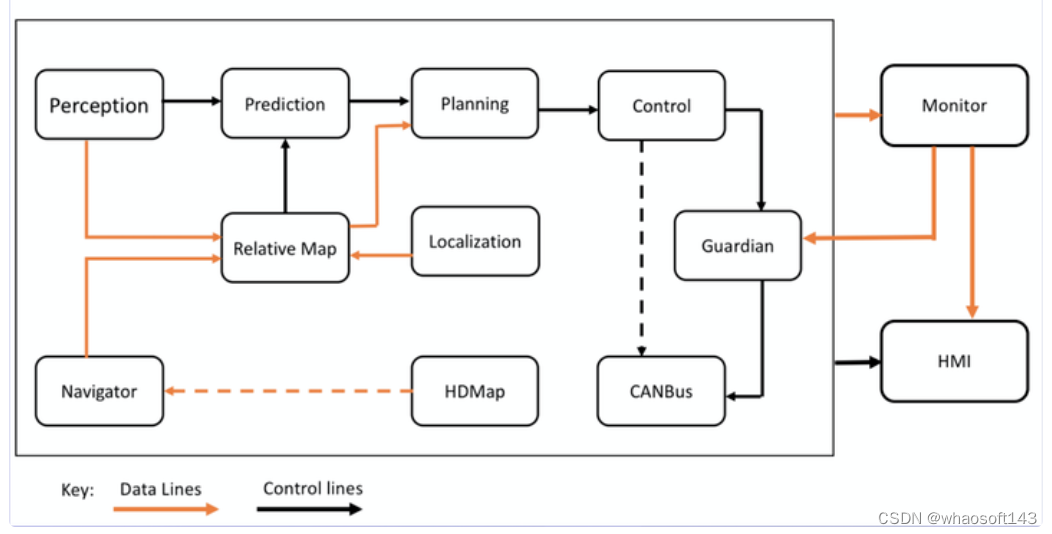
可以看到control的上游模块是planning,其中planning就包括motion planning(MP)。
MP的作用就是规划一条安全 ,舒适 ,可行驶 的轨迹。
注意四个加粗词。
安全的意思就是避免撞上马路牙子和其他车。
舒适的意思就是要尽量满足人的舒适性要求。
可行驶的意思就是给出的这条轨迹是控制能够跟随的。
轨迹就是带时间信息的,把控制的输入定死了,不许耍花样。
那还MPC啥了?MP模块把台阶给你铺好了,把梯子给你搭好了,如果你说这个台阶不合适,那就反应给MP,最终MP就会给你一个最合适的台阶,这就是MP模块的职责。
所以,这时候control模块的任务就是伺服了,就是要尽快减少误差,执行10Hz的MP指令。
一个伺服控制是不需要在控制中再做一遍规划求最优的,台阶是不需要重复的铺两遍的。因此,MPC就显得非常鸡肋了。
你可能会说,那一套是L3的,L2中很多是没有MP模块的,这时候MPC就有用了吧?
答案是依然没有用,因为L2的主控芯片要跑很多东西,并且算力都不强,跑一个MPC的求解器是非常大的负担,团队会同意你加一个这个东西吗?
你可能又会说,百度Apollo不也做MPC算法了吗?没用他们能做吗?
答案是做了也不用,Apollo的横向默认控制器是LQR,纵向默认控制器是双环PID。
既然都不用,那他们为什么还做呢?因为那时候他们没有量产车。要知道,车辆控制的工作量不是在设计控制器,而是调节最优的参数,是和底层的EPS ESP互相磨合打交道,是要处理上万辆车出现的各种异常情况,这些看起来很low很琐碎的事情是非常关键的,占据了工程师大量的时间。
他们没有量产,在MKZ上做这些是没有意义的。那总要干一点创新的吧,那就干MPC吧,好不好用做一做就知道了。做完发现不好用,默认控制器还是PID+LQR吧
因此在以量产为目的车辆控制,很少有用MPC的,反正孤陋寡闻的我是没听过。
另外一个原因是,现在的传统PID+LQR的控制器已经足够用了,PID等传统算法有各种优化的方法,可以加各种小trick,足够满足性能需求了。因此,没听说哪一家被控制卡住脖子了。
#这是自动驾驶の从入门到放弃
UniAD1获得CVPR Best Paper Award后毫无疑问给自动驾驶领域带来了又一个热点: 端到端自动驾驶。同时马老师也在极力的宣传自己的端到端FSD。不过本篇文章只把讨论限定在一个很小的学术方向,基于nuScenes的开环端到端自动驾驶,会给出一些细节的东西,不讨论其它假大空的东西。(叠个甲,本文章仅是学术讨论,不包含任何对于文章中引用的paper,相关作者的任何负面态度)
因为不能闭环所以被迫选择了开环
以能否得到反馈为标准,端到端自动驾驶的学术研究主要分为两类,一类是在模拟器比如CARLA中进行,规划的下一步指令可以被真实的执行。第二类主要是在已经采集的现实数据上进行端到端研究,主要是模仿学习,参考UniAD。开环的缺点就是无法闭环(好像是废话),不能真正看到自己的预测指令执行后的效果。由于不能得到反馈,开环自动驾驶的测评极其受限制,现在文献中常用的两种指标分别是
- L2 距离:通过计算预测轨迹和真实轨迹之间的L2距离来判断预测轨迹的质量
- Collision Rate: 通过计算预测轨迹和其他物体发生碰撞的概率,来评价预测轨迹的安全性
事实上我们发现这两个指标完全不足以评判预测的轨迹的质量,一些技术看似提高了模型在这些指标上的表现,实则带来了其他没有被发现的问题,后续会介绍到。
nuScenes不是为planning设计的
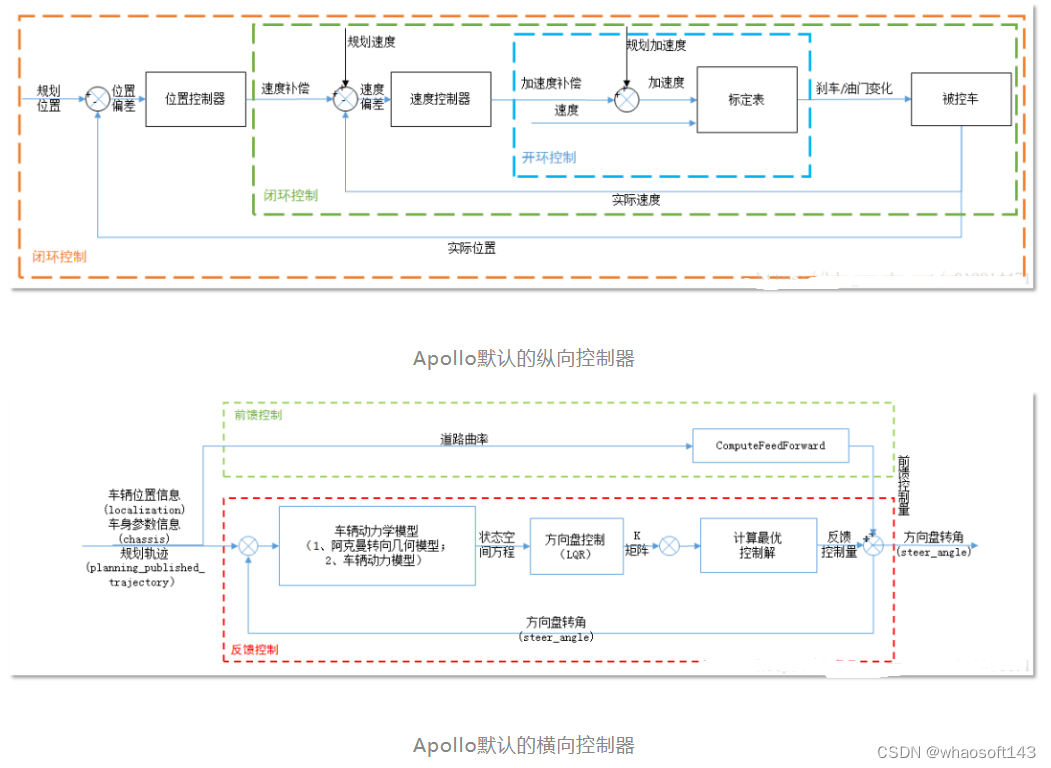
关于开环端到端自动驾驶的测评问题最早在这篇文章2 中提到。在这篇文章中他们仅使用Ego Status就能够获得和现有Sota相比较的结果。但是第一次文章放出来的时候他们的数据好像用错了3 。同时他们错误的认为VAD也用了history trajectory, 但其实VAD4并没有使用历史轨迹。在AD-MLP中历史轨迹是一个默认使用的选项,当时本人理所应当的认为AD-MLP可能是受益于历史轨迹的使用,并没有特别在意这篇文章的结论。
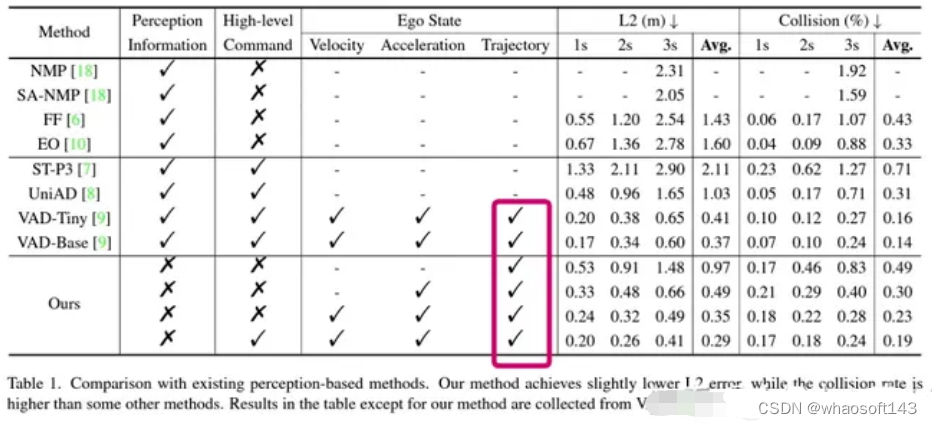
表1: AD-MLP的实验结果
不过后来实验受挫之后,心态发生了:"从相信端到端到怀疑端到端"的转变后,开始觉得AD-MLP的结论应该是对的。通过可视化很多nuScenes的整体场景,会发现相当比例的场景都是直行,而且速度变化不大,交互很少,如图1所示。考虑到我们对于AD-MLP使用历史轨迹的顾虑,我们复现了一版仅使用当前速度,加速度,转向角和转向指令的MLP网络。如图2所示,为了区分,将我们复现的这个网络记为Ego-MLP。Ego-MLP不使用任何传感器感知信息,监督loss仅为一个L2 Loss。同时我们还有一个更基础的驾驶策略Go Stright: 保持当前速度继续前进。
图1: nuScenes的场景相对简单,直行占比过大
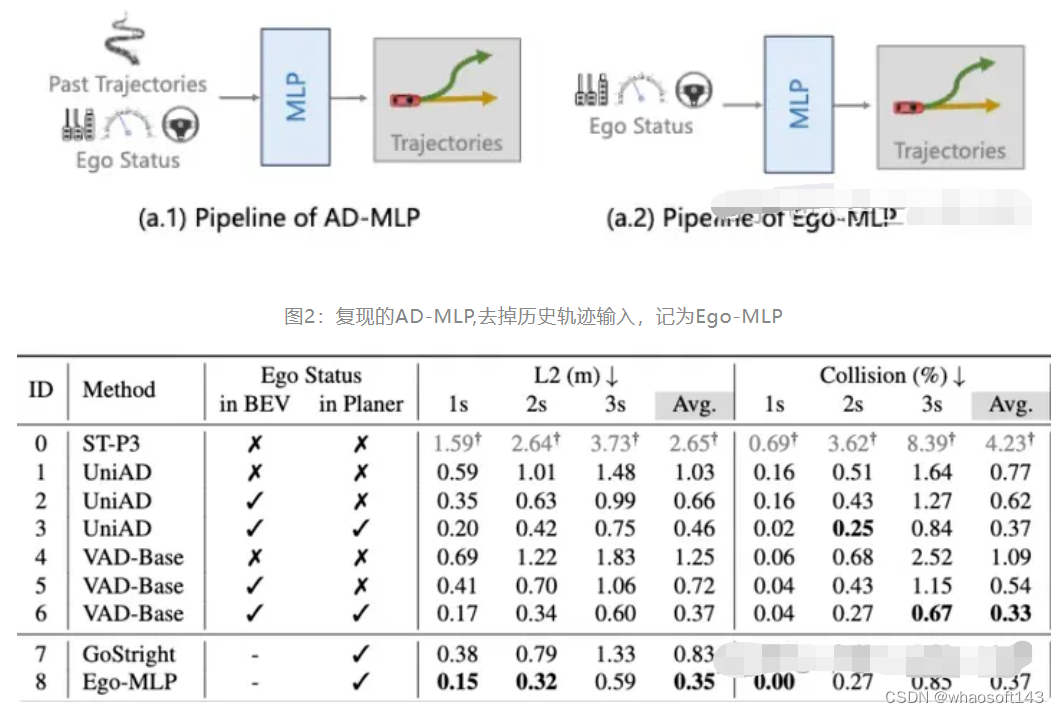
表2 实验结果由我们使用统一的Eval代码和策略获得,与之前文献中会有不一样的地方. ID-1,3,4为我们根据开源代码简单修改复现的结果, UniAD和VAD使用BEVFormer生成BEV特征,BEVFormer默认在BEV初始阶段引入can_bus (可以理解为ego status)信息
如表2所示,我们会有如下发现
- 简单的直行策略(ID-7)在2s内的指标都挺高的。
- Ego-MLP 不使用感知也能取得和现有sota差不多的结果。
第二条其实还可以换个角度这样理解,现有方法比如VAD, UniAD只有在Planner上引入Ego Status才能取得和Ego-MLP相似的效果。所以自然而然有了下面的问题:

Ego Status 引入会降低对感知的依赖
为了探究Perception 和Ego Status的效果,我们向这两个输入分别加扰动。如表3所示,在Planner中已经使用了Ego Status的情况下,就算把所有相机输入全部去掉,感知模块全部崩溃(结果变成0),模型的planning效果依然会在一个非常好的水平。我们相信这并不是一个正常的现象。与之对比的是模型会过渡依赖Ego Status的信息,假如我们改变输入模型的速度,会发现模型预测的轨迹基本会按照我们输入的假的速度去走,哪怕输入图像中事实上隐式地包含了ego的真实速度。如果输入速度全部设置成0的话,模型预测的轨迹基本处于原地不动的状态。
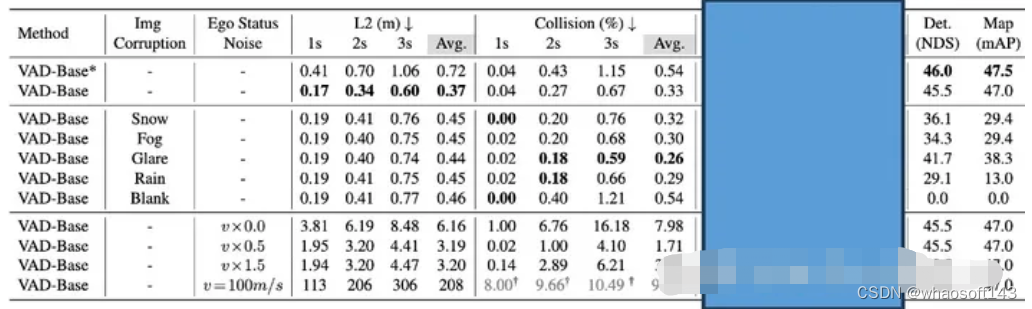
表3
结合上面我们所讨论的仅使用Ego-Status的MLP网络就能获得sota效果,说明对于nuScenes来说,Ego Status就是预测轨迹的一条shortcut, 当模型引入Ego status的时候,自然会降低对于感知信息的利用。这样的表现很难让人相信端到端模型在复杂场景下的表现。
设计一个高效的Baseline 来验证Ego Status的效果
首先,我们实在负担不起在VAD或者UniAD上来做验证实验,举例来说UniAD的第二阶段训练在我们的8* V100上就需要10天。同时,ST-P35,一个经常被拿来比较的方法使用了部分不正确的训练和测试数据,产生的结果数值上是不准确的。
因此我们认为我们需要设计一个相对简洁高效的baseline方法能够快速验证我们的想法,并且能够跟现有方法进行有效对比。不同于UniAD的模块化设计,我们使用了一个非常非常简单的设计,如下图所示,我们提出的baseline网络直接使用生成的BEV特征与一个Ego query发生交互,然后通过MLP预测最终的轨迹。与UniAD等方法不同,我们的baseline方法不使用其他任何中间监督,包括但不限于Depth, Detection, Map, Motion 等。最终模型仅使用一个L2 loss来进行轨迹的监督。Ego Status可以在BEV阶段或者最终的MLP阶段选择性加入。我们的模型训练12ep需要大概6个小。

图3
最终的结果如下表,在BEV和Planner中都使用Ego staus时,我们的方法(ID-12)和VAD-Base(ID-6)基本一致,这能说明我们的方法简单却有效吗?显然不能,这也正是Ego status主导planning性能所带来的影响,使用Ego status后,根本无需复杂设计就能取得和现有sota差不多的结果。在Ego status占据主导地位后,不同方法之间的差异根本体现不出来。事实上我们已经看到了类似的论文把使用ego status所带来的性能提升包装进自己方法里,用来展现自己方法的有效性。这是极其误导人的行为。
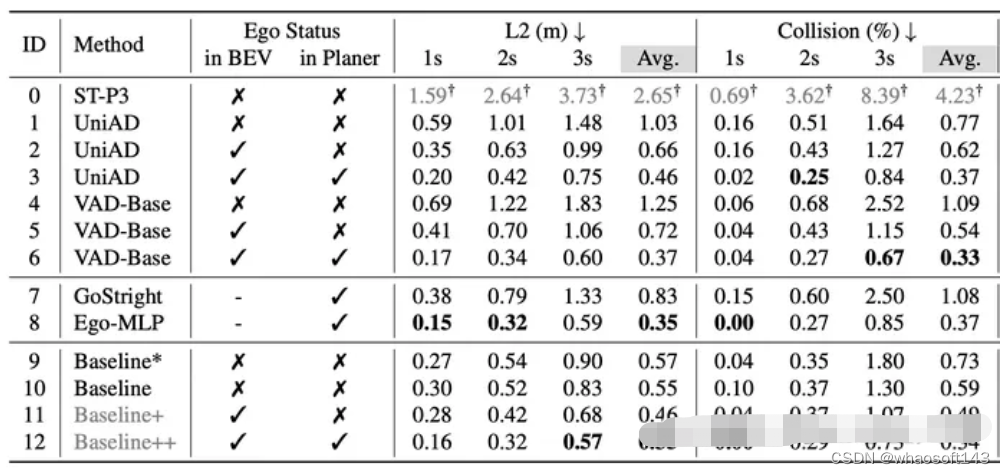
表4
看似我们的方法在使用Ego Status时取得了不错的结果,但是从下图中可以看到,在Planner中使用Ego status的方法(Baseline++)似乎只用3k个iter就能收敛了,这显然是模型学到了Ego status到planning的short cut而非从视觉信息中获得有效线索。可视化BEV特征也发现,模型几乎没有从视觉分支中学习到什么有意义的表征。
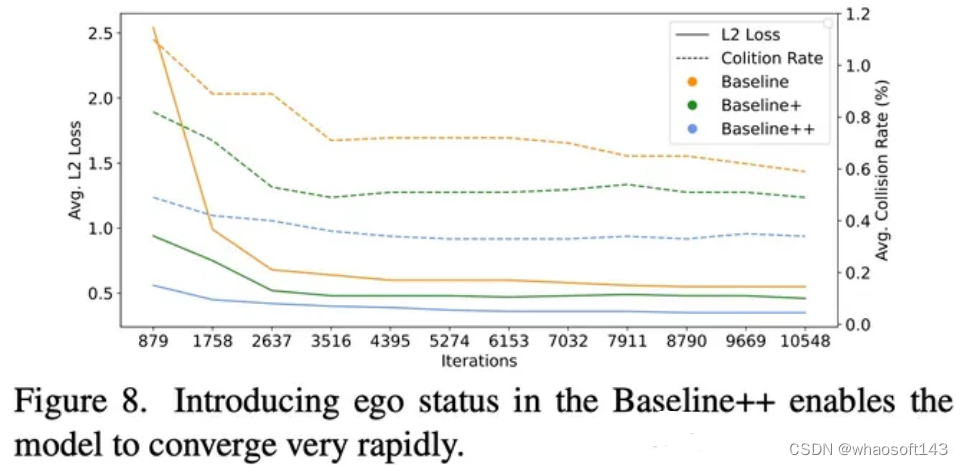
图4
我们暂时先不讨论为什么我们的方法在不使用ego status的情况下(ID-10)效果也不错的这个现象。
不用Ego Status不就完事了?
既然引入Ego Status会主导planning的学习,假如我们不想让这样的现象发生,那我们不用Ego Status不就完事了吗?第一时间这么想肯定没问题,但是
真的没有使用Ego Status吗?
为什么会有这个问题呢?因为我们发现很多方法会无意识的引入Ego Status。例如,BEVFormer默认使用了can_bus信息,这里面包含了跟自车速度,加速度,转向角相关的信息。这个东西对BEVFormer做感知其实是没啥用的,但是VAD和UniAD拿过来直接做planning话,can_bus就会发挥作用了。类似的Ego信息在感知方法中也经常被使用用来做时序对齐之类的事情。我们重新训练了去掉了can_bus的UniAD 和VAD模型,会发现明显的性能下降。考虑到ego status信息在最新的BEV方法中都被广泛使用,去掉这些信息的使用或者保证不同方法之间的公平比较都是非常困难的事情。一点点Ego status的泄漏都会对最终的planning性能产生巨大的影响。
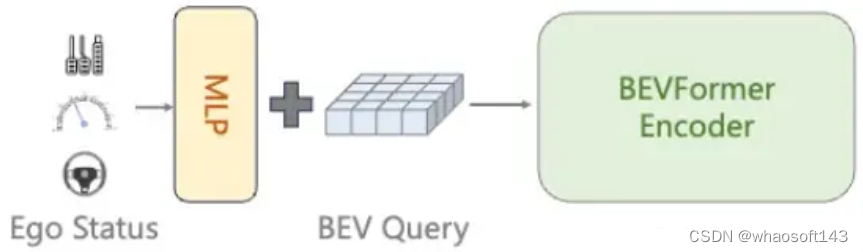
图5: BEVFormer默认使用的can_bus_info包含ego status
去掉Ego Stutus仍存在的问题
讨论到现在,可能只是简单的认为责任全在ego status,很可惜并不是这样。当我们观察上面的表4,会看到我们的方法Baseline(ID-10)在不使用任何ego status的信息的情况下,可以取得和UniAD(ID-2), VAD(ID-5)这些在BEV上用了ego status的,使用了额外感知,预测任务的模型差不多的效果。 我们再回顾一下我们的Baseline (ID-4)的设置,输入图像256x704, 仅使用GT轨迹,不使用其他中间标注,仅使用L2 loss训练12ep。 为什么这样一个朴素到极致的方法会取得这样的效果?在这里我只给出我的一个猜想,不一定正确。 既然我们能够用ego status几个数值就拟合nuScenes大多数简单场景,说明学习nuScenes 大多数简单场景的planning本身就不是一件具有挑战性的事情,学习这些简单场景下的planning根本就不需要perception map等信息。其他方法使用了更多其他模块,带来更复杂的多任务学习,事实上反而影响了planning 本身的学习,我们也做了一个简单的实验来验证我们的猜想。

表5
如上表所示,Baseline 是原来的(ID-10)的结果,我们在Baseline上添加了一个MapFormer,具体实现做法和UniAD/VAD差不多,这个Baseline+Map模型的初始化是经过Map预训练的。我们可以看到Baseline+Map的结果远远逊色于Baseline。 原因是啥呢?为了消除Map预训练的影响,我们也使用Map预训练的权重作为(ID-10)这个setting的初始化得到了Baseline(init*)这个结果,通过对比Baseline不同初始化,我们可以发现,预训练的Map权重不会导致性能下降,反而会提升性能。问题只会出现在引入Map任务本身了。
我们对比了Baseline和Baseline+Map 在直行命令下的 L2 指标:L2-ST 和左右转指令下的L2指标: L2-LR。 同样还有在直行命令下的碰撞率指标Collision-ST, 在转弯场景下的碰撞率指标Collision-LR。 我们会发现在转弯场景下引入Map只是轻微增加L2距离,并且能够大幅度降低转弯场景下的碰撞率。与之对应的是直行场景下的L2和Collision被double了。考虑到转弯场景通常是更复杂,更需要操作的,而直行场景相对简单,我们猜测是因为引入Map 带来多任务学习的干扰反而影响了这些简单场景的学习。在nuScenes验证集上,直行命令占比87%,因此主导了最终的平均指标。我们可以看到Map引入在转弯场景下实际是没什么负面效果的,但是被平均之后Map的积极效果根本彰显不出来。
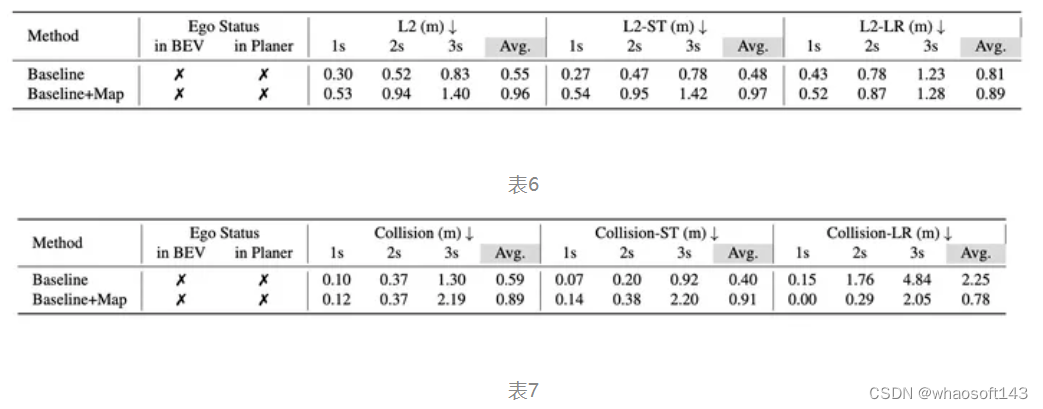
如果我们的猜想成立,这说明nuScenes做planning不单单是一个ego status的问题,而是本身全方面的不靠谱。
开环Planning指标
碰撞率指标的多个问题
我们暂时先不讨论L2 distance的问题, 因为好像更多的文章倾向于认可collision rate这个指标。实际上这个指标非常不靠谱,原因有:
- 计算碰撞的时候,其他车的未来轨迹都是回放,没有任何reaction,单从这一点上讲,这个指标就很不靠谱。
- 实际实现的问题,由于预测的轨迹只是一堆xy坐标,没有考虑ego 的yaw angle在未来的变化,计算碰撞的时候也是假设ego car的yaw angle永远保持不变,会造成很多错误的碰撞计算。我们这次也是通过轨迹估算yaw, 统一解决了这个问题。
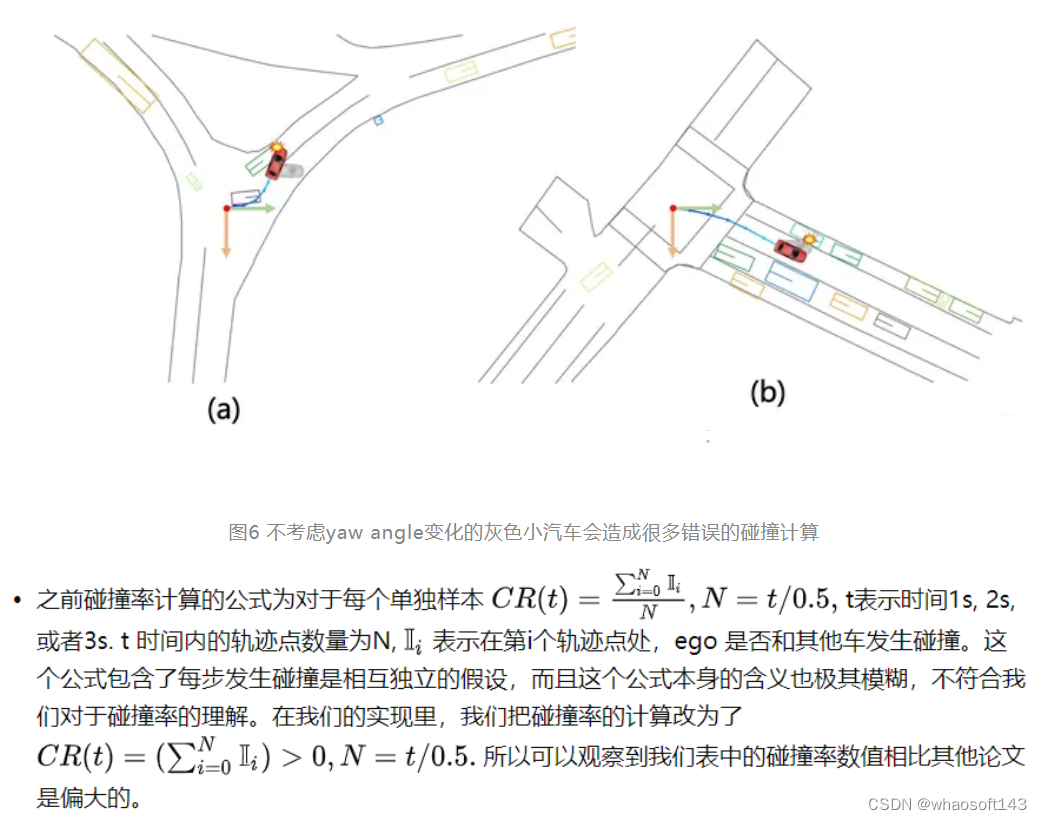
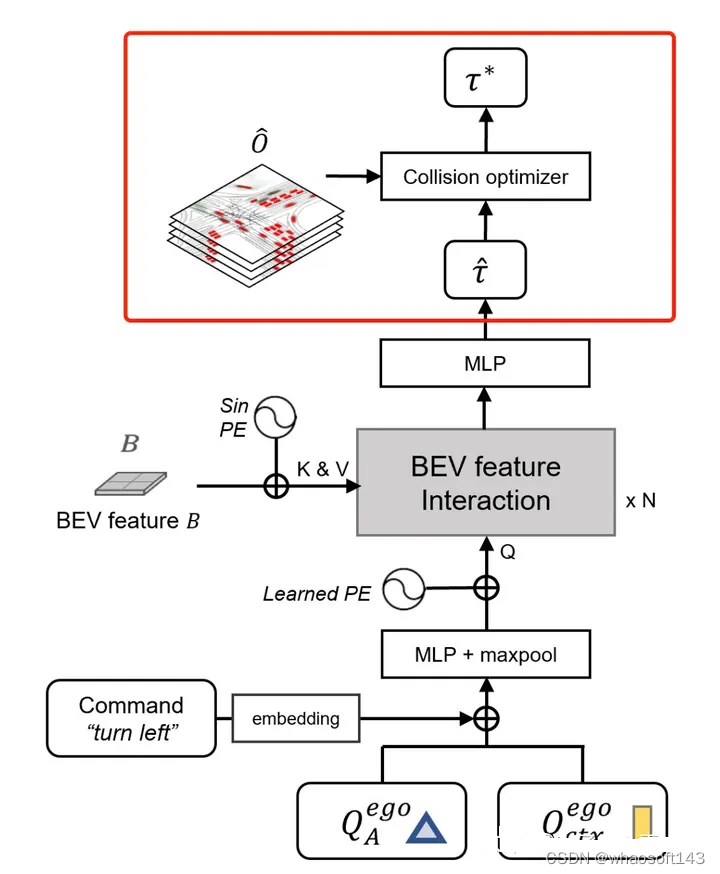
图7 UniAD引入后处理模块来优化轨迹,降低碰撞率
- Collision Rate可以被后处理进行攻击, UniAD中最有效的模块是一个后处理模块,在端到端模型给出一个初始的预测结果后,使用一个optimizer 来使得轨迹在满足一定约束条件下尽可能的远离其他物体,从而避免碰撞。从指标上讲,这个trick可以显著降低collision rate。然而看似合理的模块其实只是对于collision rate的一个hack, 原因在于约束条件不够多,例如没有考虑到地图信息。可以简单理解为:为了躲其他车,这个模块会选择打方向盘,冲到马路牙子上。但是根据现有指标,撞马路牙子是没有啥大问题的。
引入新指标
上面我们讨论了,汽车撞到马路牙子时,现在的指标是不会有什么显著惩罚的,造成一些方法可以通过用撞马路牙子的手段来降低与其他车发生碰撞的概率。所以我们使用了一个新的指标用来统计ego和road boundary(马路牙子)发生交集的概率。具体实现方法和collision rate的方法一致。经过统计,使用UniAD的后处理,降低0.1 %的碰撞概率的代价是增加5%以上与道路边界(马路牙子)发生交互的概率。这一后处理显然是不合理的,我们汇报UniAD的结果时,也都是默认不使用后处理的。
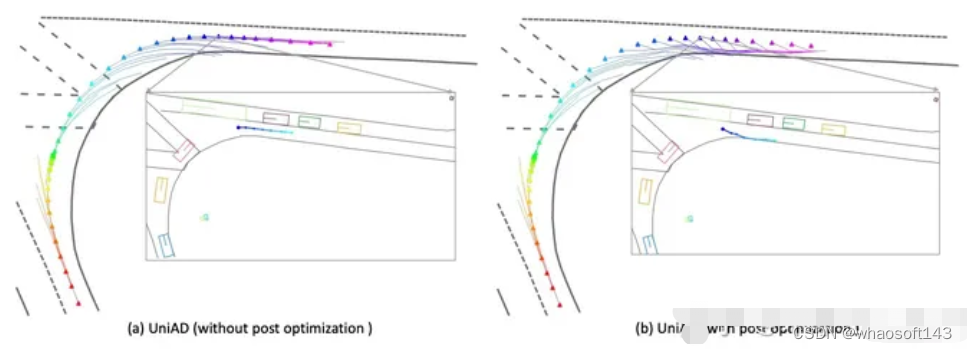
图8 UniAD的后处理显著增加了与马路边间发生交互的概率
开环的DEMO真的可靠吗
图9 左:根据当前速度直行,中:Ego-MLP 右: GT 我们可以看到左边这列使用最简单的按照当前速度直行的策略,也会减速让行,避让车辆。这其实这都是human driver 的操作。 对于开环方法,每一时刻都会刷新回human driver驾驶的安全轨迹,沿用human driver的驾驶策略。因此开环端到端方法每时每刻都是在一个安全的轨迹之上做未来的预测,不受到累计误差的影响。再难的路, 0.5s后 human driver总会给你正确答案。
你的开环端到端模型能学会转弯吗?
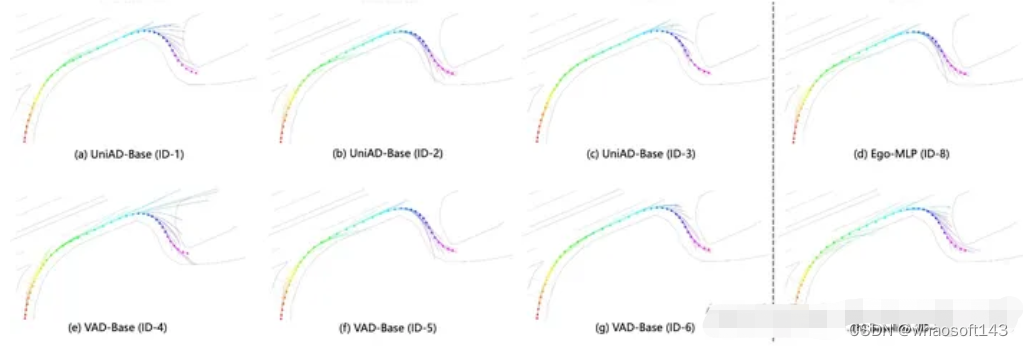
图10, 似乎所有的开环模型都不会转弯
我们发现似乎所有的开环模型都没有学会怎么转弯,转弯的时候预测的轨迹和真实轨迹差别很大,而且前后预测的轨迹不smooth,也就是前后不一致。
总结
基于nuScenes的开环端到端自动驾驶,所面临的问题太多了,心累了。
参考
- https://arxiv.org/pdf/2212.10156.pdf
- RethinkingtheOpen-LoopEvaluationofEnd-to-EndAutonomousDrivingin nuScenes https://arxiv.org/pdf/2305.10430.pdf
- AD-MLP Issue https://github.com/E2E-AD/AD-MLP/issues/4
- https://github.com/hustvl/VAD
- https://github.com/OpenDriveLab/ST-P3
# 自动驾驶轨迹/行为/运动/交通预测~论文总结
1.轨迹预测
TP-AD-Survey
题目:A Survey on Trajectory-Prediction Methods for Autonomous Driving
名称:自动驾驶轨迹预测方法综述
论文:https://ieeexplore.ieee.org/document/9756903
TP-Vision-Survey
题目:Trajectory-Prediction with Vision: A Survey
名称:视觉轨迹预测:一项调查
论文:https://arxiv.org/abs/2303.13354
TP-MultiModal-Survey
题目:Multimodal Trajectory Prediction: A Survey
名称:多模态轨迹预测:调查
论文:https://arxiv.org/abs/2302.10463
TP-DMAL-Survey
题目:A Survey on Trajectory Data Management, Analytics, and Learning
名称:轨迹数据管理、分析和学习调查
论文:https://arxiv.org/abs/2003.11547
TSM-ST-Survey
题目:Spatio-Temporal Trajectory Similarity Measures: A Comprehensive Survey and Quantitative Study
名称:时空轨迹相似性度量:综合调查和定量研究
论文:https://arxiv.org/abs/2303.05012
TP-Veh-ML-AD-Survey
题目:Machine Learning for Autonomous Vehicle's Trajectory Prediction: A comprehensive survey, Challenges, and Future Research Directions
名称:自动驾驶车辆轨迹预测的机器学习:综合调查、挑战和未来研究方向
论文:https://arxiv.org/abs/2307.07527
TP-Veh-AD-DL-Survey
题目:A Survey on Deep-Learning Approaches for Vehicle Trajectory Prediction in Autonomous Driving
名称:自动驾驶中车辆轨迹预测的深度学习方法综述
论文:https://arxiv.org/abs/2110.10436
TP-Veh-ML-Survey
题目:Machine Learning for Autonomous Vehicle's Trajectory Prediction: A comprehensive survey, Challenges, and Future Research Directions
名称:自动驾驶车辆轨迹预测的机器学习:综合调查、挑战和未来研究方向
论文:https://arxiv.org/abs/2307.07527
TP-Veh-DK-DL-AD-Survey
题目:Incorporating Driving Knowledge in Deep Learning Based Vehicle Trajectory Prediction: A Survey
名称:将驾驶知识融入基于深度学习的车辆轨迹预测:一项调查
论文:https://ieeexplore.ieee.org/document/10100881
TP-Veh-DL-AD-Survey
题目:A Survey on Deep-Learning Approaches for Vehicle Trajectory Prediction in Autonomous Driving
名称:自动驾驶中车辆轨迹预测的深度学习方法综述
论文:https://arxiv.org/abs/2110.10436
TP-Veh-DL-Survey
题目:A Survey of Vehicle Trajectory Prediction Based on Deep-Learning
名称:基于深度学习的车辆轨迹预测综述
论文:https://ieeexplore.ieee.org/document/10105706
TP-Ped-Veh-Mixed-Env-Survey
题目:Pedestrian Trajectory Prediction in Pedestrian-Vehicle Mixed Environments: A Systematic Review
名称:人车混合环境中的行人轨迹预测:系统综述
论文:https://arxiv.org/abs/2308.06419
TP-Ped-DL-AD-Survey
题目:A Review of Deep Learning-Based Methods for Pedestrian Trajectory Prediction
名称:基于深度学习的行人轨迹预测方法综述
论文:https://www.mdpi.com/1424-8220/21/22/7543
TP-Ped-DL-KB-Survey
题目:Review of Pedestrian Trajectory Prediction Methods: Comparing Deep Learning and Knowledge-based Approaches
名称:行人轨迹预测方法回顾:深度学习和基于知识的方法的比较
论文:https://arxiv.org/abs/2111.06740
2.行为预测
BP-AD-Survey
题目:Behavioral Intention Prediction in Driving Scenes: A Survey
名称:自动驾驶中车辆轨迹预测的深度学习方法综述
论文:https://arxiv.org/abs/2211.00385
BP-Ped-AD-Survey
题目:Pedestrian Behavior Prediction for Automated Driving: Requirements, Metrics, and Relevant Features
名称:自动驾驶的行人行为预测:要求、指标和相关特征
论文:https://arxiv.org/abs/2012.08418
BP-Ped-Urban-Survey
题目:A Literature Review on the Prediction of Pedestrian Behavior in Urban Scenarios
名称:城市场景行人行为预测文献综述
论文:https://dl.acm.org/doi/abs/10.1109/ITSC.2018.8569415
BP-Veh-DL-AD-Survey
题目:Deep Learning-based Vehicle Behaviour Prediction For Autonomous Driving Applications: A Review
名称:基于深度学习的自动驾驶应用车辆行为预测:综述
论文:https://arxiv.org/abs/1912.11676
BP-Driver-Human-Survey
题目:A Taxonomy and Review of Algorithms for Modeling and Predicting Human Driver Behavior
名称:人类驾驶员行为建模和预测算法的分类和综述
论文:https://arxiv.org/abs/2006.08832
3.运动预测
MP-Ped-Veh-AD-Survey
题目:A Survey on Motion Prediction of Pedestrians and Vehicles for Autonomous Driving
名称:自动驾驶行人和车辆运动预测研究综述
论文:https://ieeexplore.ieee.org/document/9559998
MP-SC-AutoVeh-Survey
题目:Scenario Understanding and Motion Prediction for Autonomous Vehicles---Review and Comparison
名称:自动驾驶汽车的场景理解和运动预测------回顾与比较
论文:https://ieeexplore.ieee.org/document/9733973
MP-3D-Human-Survey
题目:3D Human Motion Prediction: A Survey
名称:3D 人体运动预测:一项调查
论文:https://arxiv.org/abs/2203.01593
MTP-Human-Survey
题目:Human Motion Trajectory Prediction: A Survey
名称:人体运动轨迹预测:一项调查
论文:https://arxiv.org/abs/1905.06113
4.交通预测
TP-Traffic-BigData-Survey
题目:Big Data for Traffic Estimation and Prediction: A Survey of Data and Tools
名称:用于交通估计和预测的大数据:数据和工具调查
论文:https://arxiv.org/abs/2103.11824
TP-Traffic-DNN-Survey
题目:Short-term Traffic Prediction with Deep Neural Networks: A Survey
名称:使用深度神经网络进行短期交通预测:一项调查
论文:https://arxiv.org/abs/2009.00712
TP-Traffic-STG4Traffic
题目:STG4Traffic: A Survey and Benchmark of Spatial-Temporal Graph Neural Networks for Traffic Prediction
名称:STG4Traffic:用于交通预测的时空图神经网络的调查和基准
论文:https://arxiv.org/abs/2307.00495
#自动驾驶从1.0到3.0的思考
最近在思考自动驾驶( Autonomous Driving,以下简称AD)的发展趋势,发出来我的观点和大家讨论。
AD 1.0
定义
每个相机的图像输入给不同的模型来检测障碍物、车道线、交通灯等信息,融合模块使用规则来融合这些信息给规控模块,规控输出控车信号。具体架构如下图:
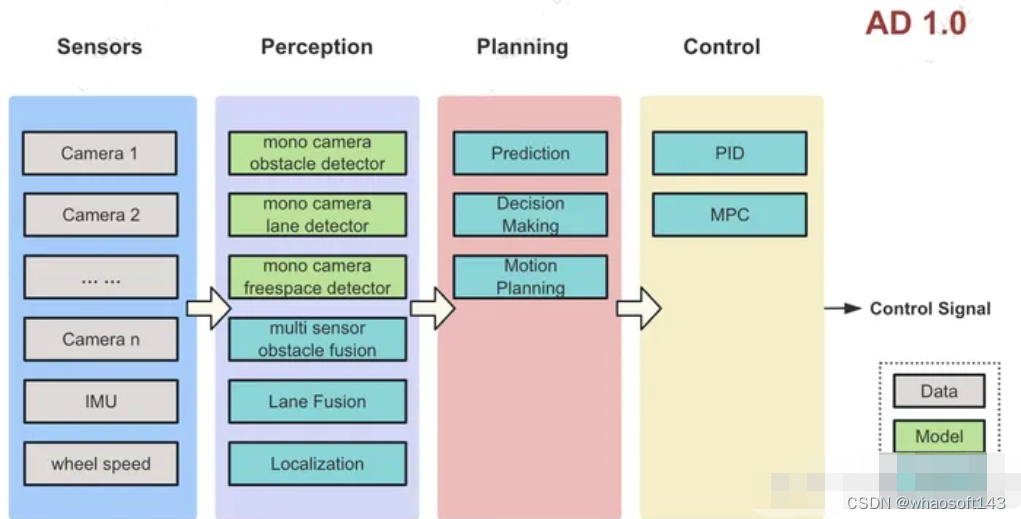
特点
- 每个相机图像单独过模型
- 有很多小模型:障碍物模型,车道线模型,交通灯模型等
- 融合、定位、规控模块都是人工编码
问题
- 障碍物是白名单制度,无法识别标注对象之外的目标,比如倒地的大卡车,路上的石块等等
- 障碍物表示为3D框,表示精度有限,比如运货大卡车凸出来的钢管等
- 规划模块不具备完备性,不考虑车辆运动之间的互相影响
- 融合、规控模块均为复杂的手工编码,迭代到最后非常容易出现顾此失彼的现象,难以维护
- 整个Debug流程本质上是用人力做反向传播,消耗的人力资源很多,无法规模化
应用案例
- TDA4等低算力平台
- 2020年之前的特斯拉
- 2022年之前的国内新势力
总结
AD1.0仅支持实现高速场景辅助驾驶,国内新势力也都已经经过了这个阶段。
AD 2.0
定义
各个相机的输入统一给模型,直接由模型完成不同相机及时序间的信息融合,感知模型同时输出障碍物、占据栅格、车道结构等等。规控模型接收感知输出的feature,输出自车预测轨迹或者控车信号。架构如下图
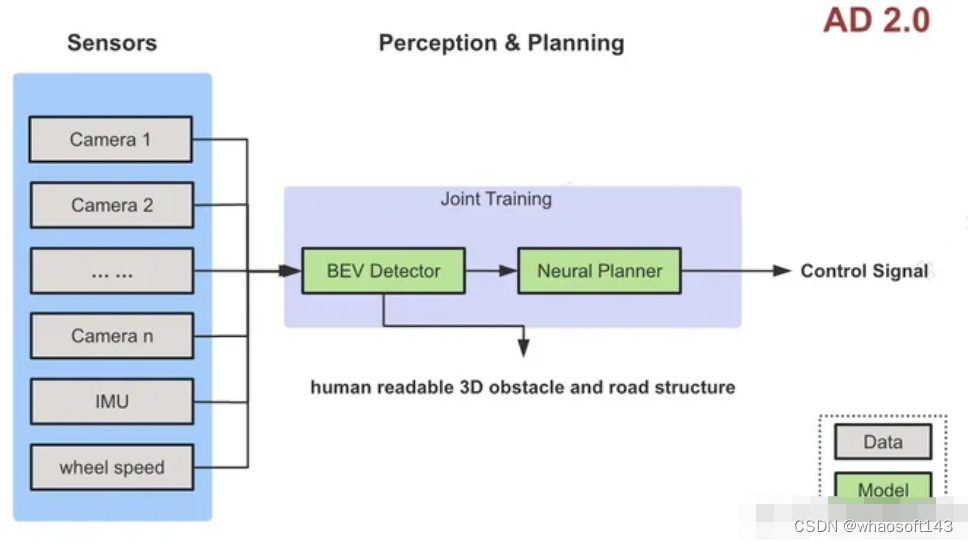
特点
- 感知只有一个BEV模型,完成多相机时序上的融合工作,输出3D障碍物、Occ、车道结构等信息。
- 规划也用模型,输出自车的预测轨迹或者控制信号
- 感知和规划模型必须要联合训练
问题
- 解决了通用障碍物的问题。但依然无法处理部分没有障碍物,但是需要特别注意的场景,比如说路面上有积水、未凝结的水泥路面、有水渍的环氧地坪地面等。
- 缺乏对现实世界的常识:比如塑料袋可以压过(物体材质),前方渣土车上的土块看起来要掉(地球有重力),前方路段是小学放学时间(社会规律),前面两个车撞到一起(突发事件)
- 和人类的交互太弱,目前的人机共驾只是人和汽车方向盘、油门的协同。人类无法告诉车辆『前面第二个路口右转,注意要提前上辅路』这类信息。
应用案例
- Tesla FSD V12 (2023年11月开始员工内部推送)
- 英国的自动驾驶公司 Wayve
总结
AD 2.0支持实现城区辅助驾驶,但由于上述问题的存在,依然无法实现无人化。国内新势力在感知端已经完成了AD 2.0的切换,但是规控端还是规则,也可以称之为AD 1.5
AD 3.0
定义
AD 1.0和AD 2.0的架构已经在业界达成共识,但还是支撑不了真正的无人化驾驶。怎么能通向真正的无人化,目前并无确定的方向。
这里介绍一种可能的方案,把多模态大模型(Multi-modal LLM)作为Agent来控车,架构如下图。
相比AD 2.0的输入只有传感器数据,这里多了人类指令交互,机器可以听从人类指令,调整驾驶行为。
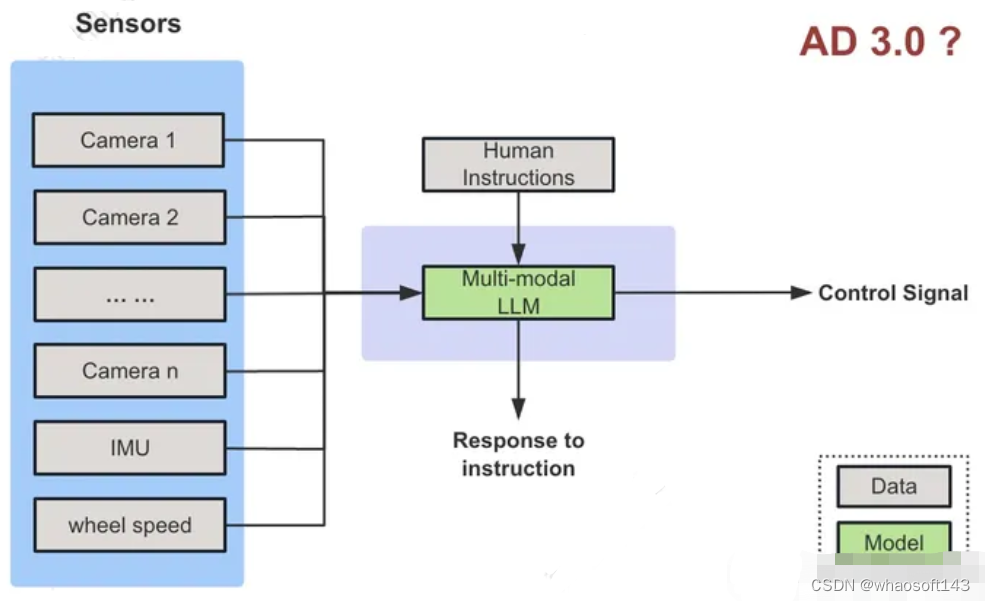
特点
- 由多模态大模型作为核心来控车
- 可以和人类(车内的乘客和车外的管理人员)进行语言交互
问题
- 怎么消除MLLM的幻觉问题?
- 怎么在车上实时的运行MLLM?
应用案例
暂无,硬要说的话可以看看OpenAI投资的自动驾驶公司Ghost Autonomy(Ghost也无法解决上车问题)
总结
这种方案上限很高,有望达到人类级别的驾驶水平。但是目前还在学术探索阶段,还需要几年时间才能落地。
在当前这个时间点,也许可以通过把MLLM部署在云端,来监管车辆自动驾驶的行为,并在必要的时候做出修正,类似于L4的远程司机,这种架构称之为AD 2.5?
#自动驾驶中基于毫米波雷达视觉融合の3D检测综述
自主驾驶在复杂场景下的目标检测任务至关重要,而毫米波雷达和视觉融合是确保障碍物精准检测的主流解决方案。本论文详细介绍了基于毫米波雷达和视觉融合的障碍物检测方法,从任务介绍、评估标准和数据集三方面展开。
并对毫米波雷达和视觉融合过程的传感器部署、传感器标定和传感器融合(融合方法分为数据级、决策级和特征级融合方法)三个部分进行了汇总讨论。
此外,还介绍了三维(3D)目标检测、自动驾驶中的激光雷达和视觉融合以及多模态信息融合,并进行了展望。
背景
较高level的自动驾驶车辆面临的挑战之一是复杂场景中的精确目标检测,当前的视觉目标检测算法已经达到了性能上限,因为检测算法在实践中面临非常复杂的情况。
对于自动驾驶场景,障碍物主要包括行人、汽车、卡车、自行车和摩托车,视觉范围内的障碍物具有不同的尺度和长宽比。此外,障碍物之间可能存在不同程度的遮挡,并且由于暴雨、大雪和大雾等极端天气,障碍物的外观可能会模糊,从而导致检测性能大大降低13。研究表明,CNN对未经训练的场景泛化能力较差14。
camera不足以独立完成自动驾驶感知任务,与视觉传感器相比,毫米波雷达的检测性能受极端天气的影响较小15、16。此外,毫米波雷达不仅测量距离,还可以利用运动物体反射信号的多普勒效应测量速度矢量17、18。然而,毫米波雷达无法提供目标的轮廓信息,并且难以区分相对静止的目标。从这个方面看,视觉传感器和毫米波雷达的探测能力可以相互补充。基于毫米波雷达和视觉融合的检测算法可以显著提高自主车辆的感知能力,帮助车辆更好地应对复杂场景中的目标检测任务。
基于毫米波雷达和视觉融合的目标检测过程如下图所示,毫米波雷达与视觉融合过程包括三个部分:传感器选择、传感器标定和传感器融合,为了实现毫米波雷达和视觉融合目标检测的预期性能,需要解决以下挑战:
- 同一时间和空间的标定校准;
- 融合不同传感器的数据以实现best性能的目标检测;
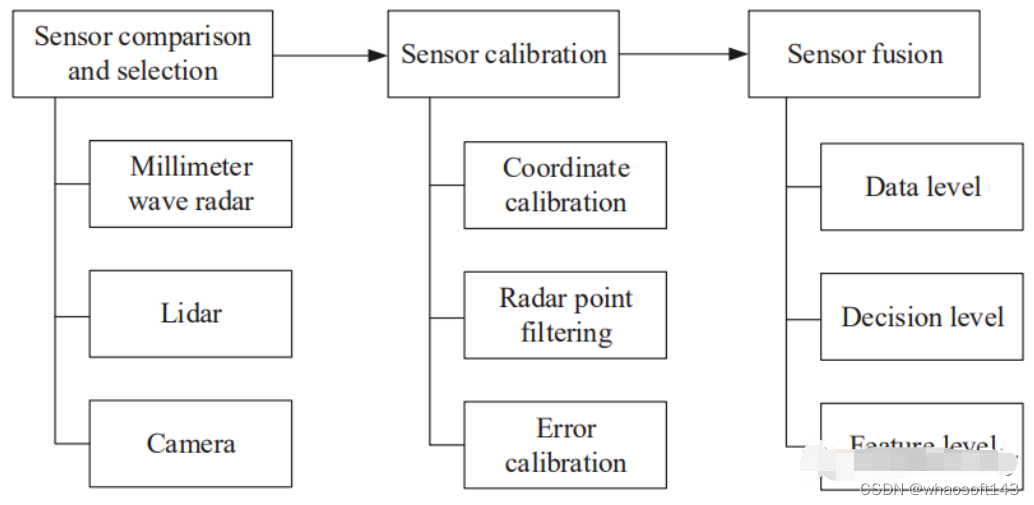
最近几年,大部分综述集中在视觉检测上,很少有radar-camera融合相关的paper,对雷达和视觉融合缺乏深入分析,本论文将重点介绍低成本毫米波雷达和视觉融合解决方案。
检测任务定义
二维(2D)目标检测使用2D box在车辆的视觉图像中选择检测到的障碍物目标,然后对目标进行分类和定位。这里的定位指的是图像中目标的定位,而不是真实世界中目标相对于车辆的定位。
在三维(3D)目标检测中,使用3D box定位目标,不仅是图像中确定目标的位置,而且还确定了现实世界中目标的姿态和位置。
评价标准
主要使用AP和AR权衡目标检测中的准确度和召回率,通过将召回值和精度值分别作为水平轴和垂直轴,可以获得精度召回(PR)曲线,平均精度(mAP)表示检测模型的合并结果,可通过计算所有类别的平均AP值获得。
以自动驾驶KITTI数据集为例,对于2D对象检测,通过比较检测边界框和gt边界框之间的IoU是否大于阈值来确定目标定位的正确性22。然而在自主驾驶的研究中,三维目标检测目前更具吸引力。KITTI正式规定,对于车辆,正确预测要求预测的3D框与真实3D框重叠70%以上,而对于行人和自行车,则要求3D框重叠50%24。
相关数据集
相关数据集主要包括:Apolloscape、KITTI、Cityscapes、Waymo Open Dataset、nuScenes等;
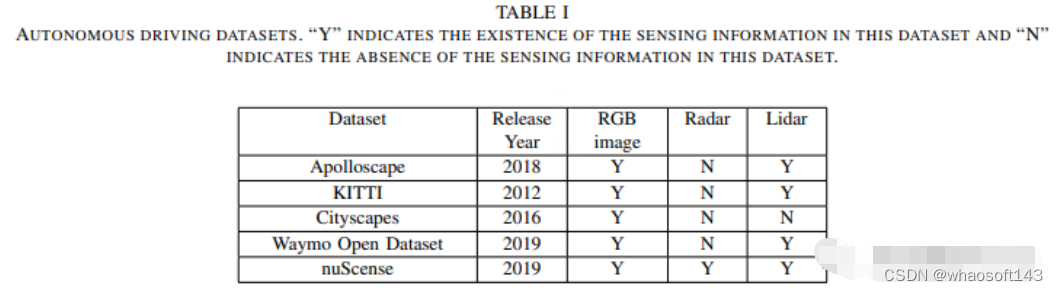
Apolloscape
百度在2017年创建的阿波罗开放平台的part,它使用Reigl激光雷达收集点云,Reigl生成的三维点云比Velodyne生成的点云更精确、密度更高。目前,ApolloScape已经打开了147000帧像素级语义标注图像,包括感知分类和道路网络数据等。
KITTI
KITTI数据集22,由德国卡尔斯鲁厄理工学院和美国丰田学院建立,是目前最常用的自动驾驶数据集。该团队使用了一辆配备camera和Velodyne激光雷达的大众汽车在德国卡尔斯鲁厄开车6小时,记录交通信息。数据集为每个序列提供原始图像和精确的三维box以及类标签。类主要包括汽车、面包车、卡车、行人、自行车和电车。
Cityscapes
由三个德国实验室联合提供:戴姆勒、马克斯·普朗克信息研究所和达姆施塔特科技大学。它是一个语义理解图像-城市街道场景数据集,主要包含来自50多个城市的5000张城市环境中驾驶场景的高质量像素级标注图像(2975张用于training,500张用于val,1525张用于test,共19个类别)。此外,它还有20000张粗略的标注图像。
Waymo Open Dataset
Waymo数据集是Alphabet股份有限公司旗下自动驾驶公司Waymo的开源项目。它由Waymo自动驾驶汽车在各种条件下收集的标定数据组成,包括覆盖25个城市的1000多万英里自动驾驶里程数据。数据集中包括激光雷达点云和视觉图像。车辆、行人、骑自行车的人和标志都经过了精心标记,该团队完成了1200多万条3D标注和120万条2D标注。
nuScenes
nuTonomy建立的Nuscene数据集29是现有最大的自动驾驶数据集,这是第一个配备全自动车辆传感器的数据集。该数据集不仅提供相机和激光雷达数据,还包含radar数据,是目前唯一一个包含雷达数据的数据集。nuScenes提供的三维边界框标注不仅包含23个类,还包含8个属性,包括行人姿势、车辆状态等。
传感器部署
绝大多数汽车制造商采用了radar和摄像头相结合的传感器配置方案,除了特斯拉,其他制造商也使用了融合传感技术,将激光雷达、毫米波雷达和camera结合起来。可以得出结论,使用radar和视觉融合的传感解决方案是当前自主驾驶车辆障碍物检测领域的主流趋势,主要因为radar和camera具有互补的特性。
领域方案传感器部署汇总:
Lidar、Radar、Camera三类传感器性能对比:
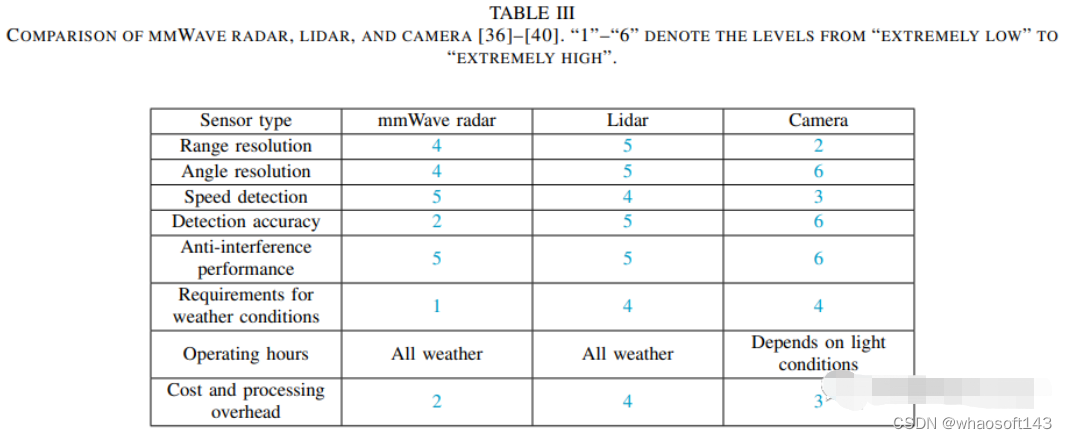
毫米波雷达作为自动驾驶车辆上常见和必要的传感器,具有远距离探测、低成本和动态目标可探测性的特点。由于这些优点,车辆的感应能力和安全性得到了提高37。与激光雷达相比,毫米波雷达的优势主要体现在应对恶劣天气和低部署成本方面36。此外,它还有以下优点:
- 毫米波雷达可以探测250米范围内的障碍物,这对自主驾驶的安全至关重要,而激光雷达的探测范围在150米范围内41。
- 毫米波雷达可以基于多普勒效应测量目标车辆的相对速度,分辨率为0.1m/s,这对于自主驾驶中的车辆决策至关重要41。
与毫米波雷达相比,激光雷达具有以下优点38、39:
- 激光雷达比毫米波雷达具有相对较高的角度分辨率和检测精度。此外,毫米波雷达数据更稀疏;
- 激光雷达的测量包含语义信息,并满足先进自主驾驶的感知要求,而毫米波雷达缺乏这一点;
- 无法从毫米波雷达测量中完全滤除杂波,导致雷达信号处理中出现错误;
radar是探测距离和径向速度的最佳传感器。它具有"全天候"功能,特别是考虑到它在夜间仍能正常工作。然而,雷达无法区分颜色,目标分类能力较差36。camera具有良好的颜色感知和分类能力,角度分辨率能力不弱于激光雷达36。然而,它们在估计速度和距离方面受到限制40。此外,图像处理依赖于车载芯片算力,而不需要毫米波雷达的信息处理。充分利用雷达感应信息可以大大节省计算资源36。通过比较radar和摄像机的特性,可以发现它们之间有许多互补的特性。因此,将radar和视觉融合感知技术应用于障碍物检测领域,可以有效提高感知精度,增强自主车辆的目标检测能力。毫米波雷达或激光雷达和视觉融合都很有用。
传感器标定
不同传感器的空间位置和采样频率不同,同一目标的不同传感器的传感信息可能不匹配。因此,校准不同传感器的传感信息非常必要,毫米波雷达返回的检测信息是雷达点,camera接收视觉图像。以nuScenes29的相机和毫米波雷达数据作为示例。该数据集提供的数据已通过帧同步处理,因此不需要时间同步,下图效果可通过空间坐标变换获得。雷达点的RGB值由横向速度、纵向速度和距离这三个物理量转换而来,雷达点的颜色表示与雷达点对应的对象的物理状态。一般而言,传感器校准包括坐标标定42--48、雷达点滤波43、45和误差校准49--51。

坐标系标定
坐标标定的目的是将雷达点与图像中的目标进行匹配。对于坐标标定,最常用的方法分为坐标变换方法45、46、传感器验证方法42、44、47和基于视觉的方法43、52。
坐标变换法通过矩阵运算将同一坐标系下的雷达信息和视觉信息统一起来。46根据毫米波雷达和视觉传感器的空间位置坐标,通过坐标变换方法完成空间校准。针对不同传感器采样率引起的时间不一致性,采用线程同步方法实现图像帧和毫米波雷达数据的同时采集。45使用了基于伪逆的点对齐方法,该方法使用最小二乘法获得坐标变换矩阵。传统的坐标变换无法生成目标的精确位置,给最终结果带来误差。53Wang等人提出了一个校准实验,在不使用专用工具和雷达反射强度的情况下,将真实坐标投影到雷达探测图中,这削弱了对校准误差的依赖性。
传感器验证方法利用同一物体上不同传感器的检测信息相互校准多个传感器。在42中,传感器验证包括两个步骤。首先通过雷达生成目标列表,然后通过视觉信息对列表进行验证。47经过radar坐标变换后,首先粗略搜索图像,然后与雷达信息进行比较。比较结果将目标分为两类:匹配目标和非匹配目标。在44中,Streubel等人设计了一种融合时隙方法,匹配雷达和视觉在同一时隙中检测到的对象。
基于视觉的方法:52使用运动立体技术实现雷达目标和图像目标的匹配。43Huang等人使用自适应背景减法来检测图像中的运动目标,生成候选区域,并通过判断目标是否存在来验证目标雷达点是否位于候选区域。
Radar点滤波
雷达点滤波的目的是滤除噪声和无用的检测结果,以避免这些雷达点造成的误判。45Guo等人提出了一种利用帧内聚类和帧间跟踪信息进行噪声滤波和有效目标提取的方法。在43中,通过毫米波雷达获得的速度和角速度信息对雷达点进行滤波。然后对无效雷达点进行滤波,从而减少树木和桥梁等固定目标对毫米波雷达的影响。
误差校准
由于传感器或数学计算中的误差,校准的雷达点可能存在误差。一些文章提出了纠正这些错误的方法。在50中,提出了一种基于交互式微调的方法,对投影在视觉图像上的雷达点进行最终校正。51中的作者提出了一种改进的扩展卡尔曼滤波(EKF)算法,用于建模不同传感器的测量误差。在49中,分析了各种坐标对检测结果的影响,并提出了一种半积分笛卡尔坐标表示方法,将所有信息转换为随宿主车辆移动的坐标系。目前使用开源数据集时,不需要进行误差校准。然而,如果数据集是自制的,则雷达滤波和纠错是必要的技术步骤。
基于传感器融合的检测任务
一般来说,毫米波雷达和视觉融合分为三个层次,包括数据层、决策层和特征层。数据级融合是毫米波雷达和摄像机检测到的数据的融合,具有最小的数据丢失和最高的可靠性。决策级融合是毫米波雷达和摄像机检测结果的融合。特征级融合需要提取雷达特征信息,然后将其与图像特征融合。
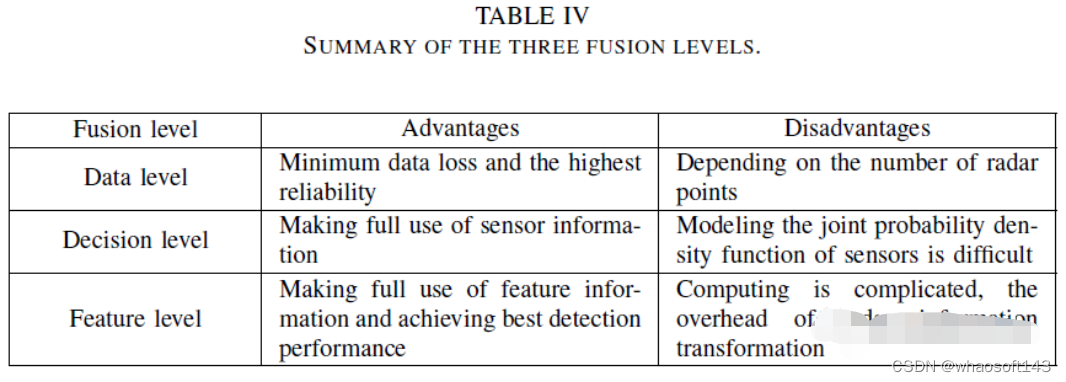
数据层融合
数据级融合是一种成熟的融合方案,目前还不是主流的研究趋势。然而,其融合不同传感器信息的想法仍有参考价值。如下表所示,数据级融合首先基于雷达点42、45、54、55生成感兴趣区域(ROI)。然后根据ROI提取视觉图像的对应区域。最后,使用特征提取器和分类器对这些图像进行目标检测45、47、53、55--61。
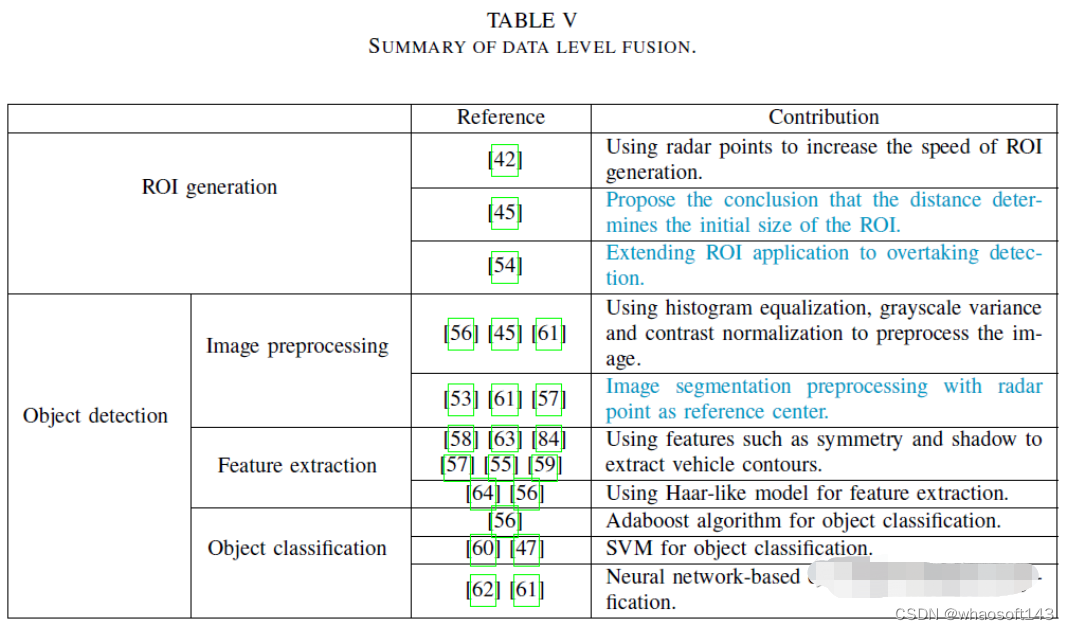
一些文献使用神经网络进行目标检测和分类61、62。对于数据级融合,有效雷达点的数量直接影响最终的检测结果。如果图像的某一部分中没有雷达点,则该部分将被忽略。该方案缩小了目标检测的搜索空间,节省了计算资源,同时留下了安全隐患。数据级融合过程如图4所示。

ROI的生成
ROI是图像中的选定区域,与纯图像处理方案相比,数据级融合方案使用雷达点生成ROI,这可以显著提高ROI生成的速度42。初始ROI的大小由障碍物和毫米波雷达之间的距离决定45。
目标检测
由于图像中目标位置和大小的不确定性,基于视觉的目标检测通常采用滑动窗口和多尺度策略,产生大量候选框,导致检测效率低。毫米波雷达与视觉融合方案避免了滑动窗口方法,降低了计算成本,提高了检测效率。
决策层融合
决策级融合是目前主流的融合方案,该过程如下表所示:
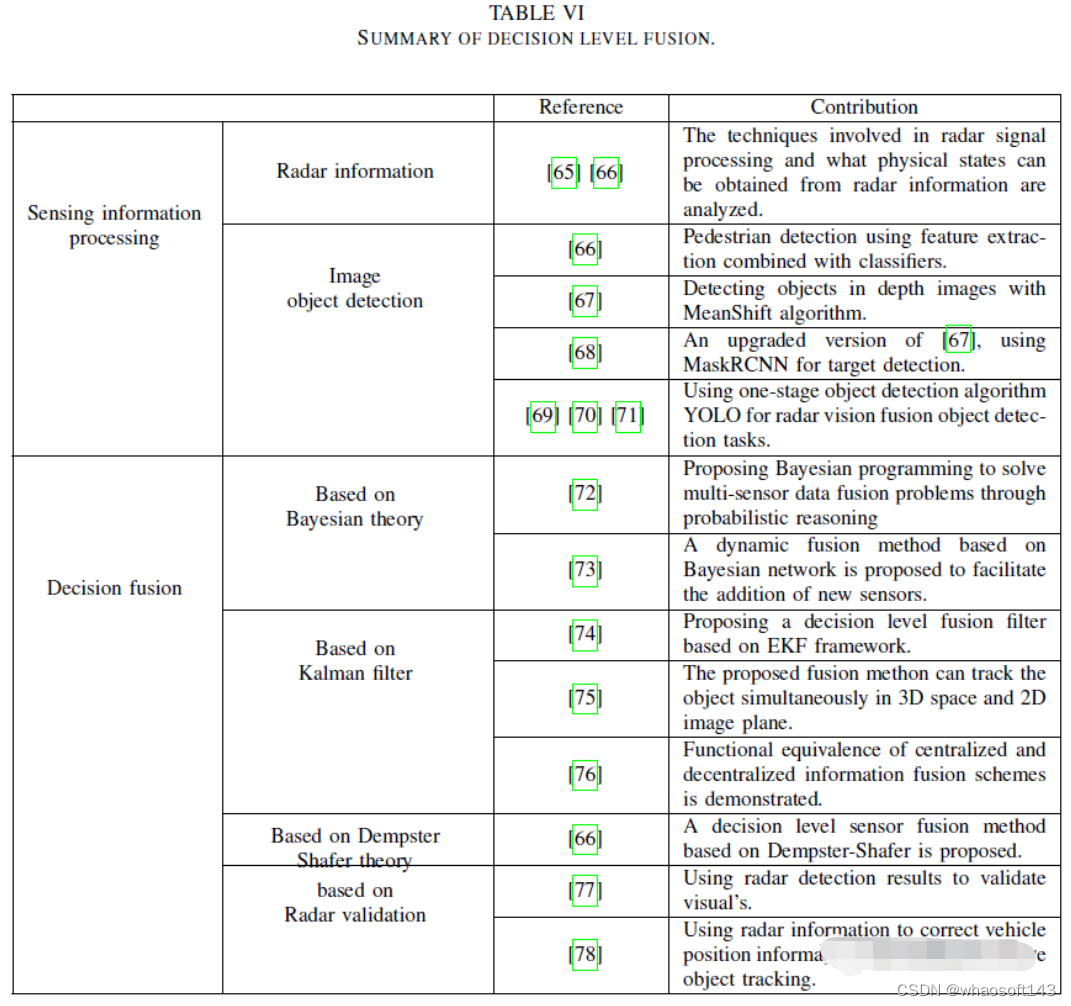
雷达的优势在于纵向距离,视觉传感器的优势在于水平视野。决策级融合可以兼顾这两方面的优点,充分利用传感信息。决策级融合滤波算法的挑战是建模两种检测信息的联合概率密度函数,决策级融合主要包括两个步骤:传感信息处理65--69、71和决策融合66、72--78、84。
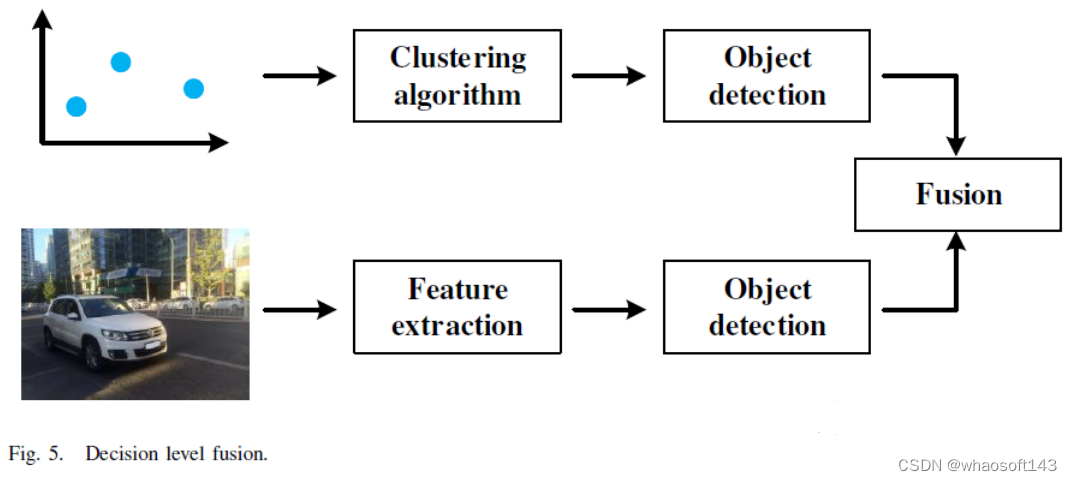
传感信息处理
传感信息的处理包括雷达信息和视觉信息。雷达探测结果生成一个物体列表,并包含物体的速度和距离等信息65、66;视觉信息处理对图像执行目标检测算法,定位2D位置。
决策融合
车辆检测的决策级融合融合不同传感器的检测结果,主流滤波算法应用贝叶斯理论72、73、卡尔曼滤波框架74--76和Dempster-Shafer理论66。在一些文献中,雷达检测目标列表用于验证视觉检测结果77、78,此外,参考文献84提出了运动立体算法来调整和细化最终检测结果。
基于贝叶斯理论的融合方法
参考文献72提出了一种基于贝叶斯理论的方法,通过使用概率推理方法来解决多传感器数据融合问题,称为贝叶斯规划。当添加新的传感器时,传统的多传感器融合算法不再适用。融合算法在73中进行了模块化和推广,并提出了一种基于贝叶斯网络的动态融合方案,以提高每个融合算法的可重用性。
基于卡尔曼滤波的融合方法
74基于李群的EKF框架,提出了一种使用特殊欧几里德群的决策级融合滤波器。参考文献75提出了一种融合框架,可以在3D空间和2D图像平面中同时跟踪检测对象。类似于卡尔曼滤波器的不确定性驱动机制用于均衡不同质量的传感结果。在76中,雷达首先检测到给定图像,以粗略搜索目标。然后使用经过训练的点检测器来获得对象的边界框。采用基于卡尔曼滤波的信息融合方法,证明了集中式和分散式信息融合方案的功能等价性。
基于Dempster-Shafer理论的融合方法
参考文献66提出了基于Dempster-Shafer理论的决策级融合,将多个传感器的检测列表作为输入,使用其中一个作为临时evidence 网格,并将其与当前evidence 网格融合,最后执行聚类处理,在evidence 网格中确定了目标。
基于雷达验证的融合方法
参考文献77将视觉检测和雷达检测生成的目标列表重叠,以生成唯一的车辆列表。雷达数据用于验证视觉检测结果,如果存在与雷达数据中的视觉检测结果匹配的目标,则蓝色框将被标记为强假设。否则,如果没有目标,它不会被丢弃:一个绿框将被标记为弱假设。参考文献78提出了一种多目标跟踪(MTT)算法,该算法可以通过评估雷达散射中心的跟踪分数来实时校正被跟踪目标列表。利用立体视觉信息拟合目标车辆的轮廓,并利用与目标车辆匹配的雷达目标校正其位置。
特征级融合
特征级融合是近年来出现的一种新方案,该过程如下表所示:
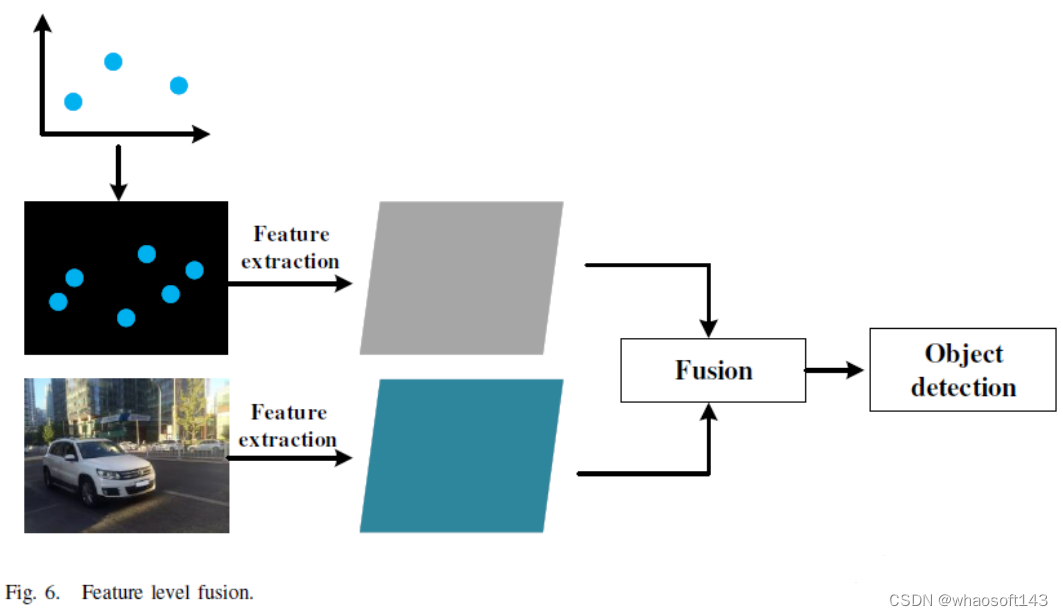
在特征级融合方法79--83中,使用额外的雷达输入分支是一种常见的方法,基于CNN的目标检测模型可以有效地学习图像特征信息。通过将雷达检测信息转化为图像形式,检测模型可以同时学习雷达和视觉特征信息,实现特征级融合,特征级融合过程如下图所示:
基于CNN的融合框架
雷达特征提取的目的是变换雷达信息,因为雷达信息不能与图像信息直接融合。雷达特征提取主要采用将雷达点转换到图像平面生成雷达图像的方法。多通道变换后的雷达图像包含雷达检测到的所有环境特征,每个通道表示一个物理量,如距离、纵向速度、横向速度等。参考文献83提出了一种新的条件多生成器生成对抗网络(CMGGAN),该网络利用雷达传感器的测量数据生成类似camera图像,包括雷达传感器检测到的所有环境特征。80提出了一种新的雷达特征描述方法,称为雷达稀疏图像,雷达稀疏图像是416×416三通道图像,其大小直接对应于视觉图像的大小,这三个通道包含雷达点速度和深度特征信息。在82中,Chang等人将雷达点处的深度、水平和垂直信息转换为不同通道的真实像素值。对于没有雷达点的区域,他们将像素值设置为0,并使用以雷达点为中心的圆圈渲染雷达图像。在81中,考虑到雷达检测结果中缺乏高度信息,Nobis等人在垂直方向上拉伸投影雷达点,以便更好地将其与图像整合。雷达信息的特征以像素值的形式存储在增强图像中。此外,还提出了一种地面真值噪声滤波器来滤除无效雷达点。
特征融合
基本特征融合方法可分为两类:级联和元素相加。前者将雷达特征矩阵和图像特征矩阵连接成多通道矩阵,而后者将两个矩阵合并成一个矩阵。
79设置了两种融合方法:级联和逐元素相加,实验结果表明这两种融合方式都提高了检测性能。按逐元素添加方法在手动标注的测试集上性能更好,而级联方法在生成的测试集中性能更好。82中提出了一种用于传感器特征融合的新块,称为空间注意融合(SAF)。使用SAF块生成注意力权重矩阵,以融合雷达和视觉特征。同时,82将SAF方法与三种逐元素加法、乘法和级联方法进行了比较,结果表明,SAF具有最佳性能。此外,82在Faster R-CNN上进行了泛化实验,SAF模型也提高了检测性能。
挑战和未来趋势
Challenges
对于目标检测任务,目前的研究成果已经取得了优异的性能,然而,这些成果大多是二维目标检测。在真实的自动驾驶场景中,复杂的交通环境通常需要3D目标检测来更准确地感知环境信息,当前3D对象检测网络的性能远低于2D检测的水平。因此,提高三维目标检测的精度不仅是自动驾驶领域的一项挑战,也是目标检测任务中的一项重大挑战。
毫米波雷达和视觉的融合仍然存在挑战,这是本文的重点。毫米波雷达的最大缺点是雷达特征稀疏,与视觉图像相比,毫米波雷达提供的信息非常少,无法带来显著的性能改进。此外,毫米波雷达和视觉的特征信息是否可以进一步整合,以及它们之间的相关互信息是否已经挖掘出来,还有待研究。因此,毫米波雷达视觉融合仍然面临两大挑战:稀疏感知信息和更有效的融合,这也是多传感器融合领域的两大挑战!
Future Trends
作者认为有三个主要趋势,其中之一是3D对象检测:提高三维目标检测的精度将是一个主要的研究趋势。其余两个趋势涉及雷达视觉融合。一方面,有必要整合新的传感信息,即增加新的传感器,如激光雷达,它在自动驾驶方面取得了优异的性能;另一方面,有必要探索传感信息融合的新方法,如多模态融合。
基于多传感器融合的三维目标检测还在基于视觉的目标检测网络的基础上增加了雷达输入分支和信息融合模块。参考文献91使用了一种类似于特征级融合的方案,首先通过2D检测将雷达点绘制成矩形区域,然后执行3D检测。此外,由于激光雷达具有丰富的特征,可以重建物体轮廓,更容易估计三维box,因此,利用激光雷达进行多传感器融合三维物体检测的研究较多。
随着激光雷达成本的降低,配备激光雷达的自动驾驶车辆已成为一种趋势。然而,激光雷达不能替代毫米波雷达,毫米波雷达有其独特的优势。激光雷达具有更高的探测精度,它们相辅相成,激光雷达和视觉的融合在自动驾驶中正变得很有价值。无论是毫米波雷达还是激光雷达,其传感信息在不同模式下都是相同的环境信息。雷达感测信息和视觉信息也是不同模态的信息。将雷达视觉融合视为多模态信息融合,可能有更好的解决方案。此外,在自动驾驶领域,数据集提供的毫米波雷达数据是后处理数据。然而,从信息保护的角度来看,后处理雷达数据中包含的信息量必须相对于原始数据丢失。如果将原始雷达检测数据和视觉图像视为两种不同的传感信息模式进行融合,则可以获得更丰富的传感信息。多模态信息融合的挑战在于如何完美地组合不同模态的信息及其携带的噪声,以及如何挖掘相关信息以帮助理解同一事物。
#大模型技术在自动驾驶的应用与影响
深入分析大模型技术在自动驾驶领域的应用和影响
- 文中首先概述了大模型技术的发展历程,自动驾驶模型的迭代路径 ,以及大模型在自动驾驶行业中的作用。
- 接着,详细介绍了大模型的基本定义、基础功能和关键技术,特别是Transformer注意力机制和预训练-微调范式。
- 文章还介绍了大模型在任务适配性、模型变革和应用前景方面的潜力。
- 在自动驾驶技术的部分,详细回顾了从CNN到RNN、GAN,再到BEV和Transformer结合的技术迭代路径 ,以及占用网络模型的应用。
- 最后,文章重点讨论了大模型 如何在自动驾驶的感知、预测和决策层面提供赋能,突出了其在该领域的重要性和影响力。
一、概述
1.1 大模型技术发展历程
大模型泛指具有数十亿 甚至上百亿 参数的深度学习模型,而大语言模型是大模型的一个典型分支(以ChatGPT为代表)
Transformer架构的提出引入了注意力机制,突破了RNN和CNN处理长序列的固有局限,使语言模型能在大规模语料上得到丰富的语言知识预训练:
- 一方面,开启了大语言模型快速发展的新时代;
- 另一方面奠定了大模型技术实现的基础,为其他领域模型通过增大参数量提升模型效果提供了参考思路。
复杂性、高维度、多样性和个性化要求 使得大型模型在自动驾驶、量化交易、医疗诊断和图像分析、自然语言处理和智能对 话任务上更易获得出色的建模能力。
1.2 自动驾驶模型迭代路径
自动驾驶算法模块可分为感知、决策和规划控制三个环节。其中感知模块为关键的组成部分,经历了多样化的模型迭代:
CNN(2011-2016)------ RNN+GAN(2016-2018)------ BEV(2018-2020)------ Transformer+BEV(2020至 今)------ 占用网络(2022至今)
可以看一下特斯拉智能驾驶迭代历程:

2020年重构自动驾驶算法,引入BEV+Transformer取 代传统的2D+CNN算法,并采用特征级融合取代后融合,自动标注取代人工标注。
- 2022年算法中引入 时序网络,并将BEV升级为占用网络(Occupancy Network)。
- 2023年8月,端到端AI自动驾驶系统FSD Beta V12首次公开亮相,完全依靠车载摄像头和神经网络来识别道路和交通情况,并做出相应的决策。
1.3 大模型对自动驾驶行业的赋能与影响
自动驾驶领域的大模型发展相对大语言模型滞后,大约始于2019年,吸取了GPT等模型成功经验。
大模型的应用加速模型端的成熟,为L3/L4级别的自动驾驶技术落地提供了更加明确的预期。
可从成本、技术、监管与安全四个层面 对于L3及以上级别自动驾驶落地的展望,其中:
- 成本仍有下降空间
- 技术的发展仍将沿着算法和硬件两条主线并进
- 法规政策还在逐步完善之中
- 安全性成为自动驾驶汽车实现商业化落地必不可少的重要因素
各主机厂自2021年开始加速对L2+自动驾驶的布局,且预计在2024年左右实现L2++(接近L3)或者更高级别的自动驾驶功能的落地,其中政策有望成为主要催化。
二、大模型技术发展历程
2.1 大模型基本定义与基础功能
大模型基本定义:由大语言模型到泛在的大模型大模型主要指具有数十亿甚至上百亿参数的深度学习模型,比较有代表性的是大型语言模型( Large Language Models,比如最近大热的ChatGPT)。
大型语言模型是一种深度学习算法 ,可以使用非常大的数据集来识别、总结、翻译、预测和生成内容。
大语言模型在很大程度上代表了一类称为Transformer网络的深度学习架构。Transformer模型是一个神经网络,通过跟踪序列数据中的关系(像这句话中的词语)来学习上下文和含义。
Transformer架构的提出,开启了大语言模型快速发展的新时代:
- 谷歌的BERT首先证明了预训练模型的强大潜力
- OpenAI的GPT系列及Anthropic的Claude等继续探索语言模型技术的边界。越来越大规模的模型不断刷新自然语言处理的技术状态。这些模型拥有数百亿或上千亿参数,可以捕捉语言的复杂语义关系,并进行人类级别的语言交互。
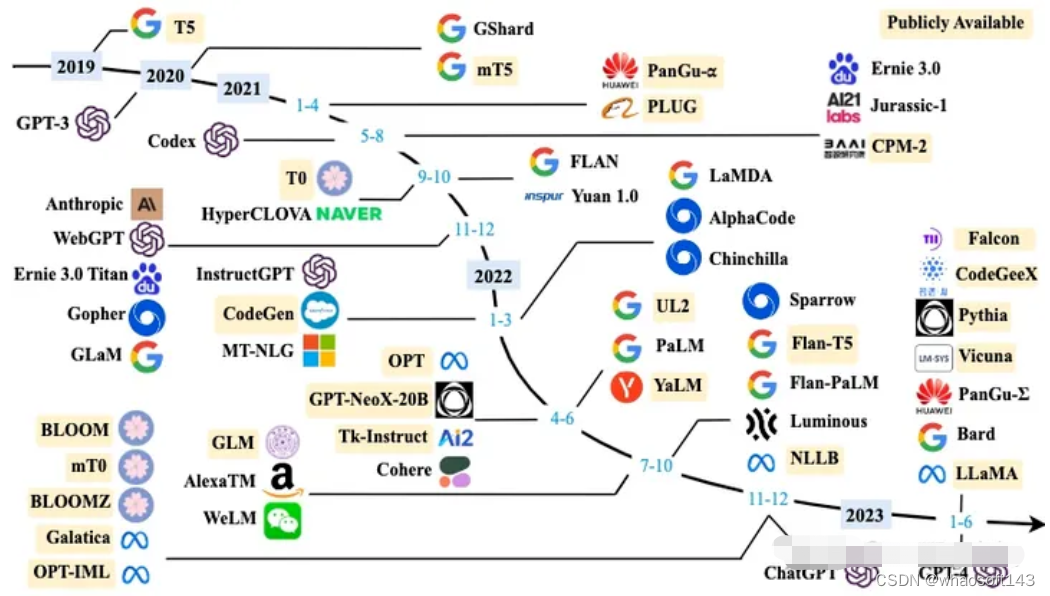
下图是大模型的发展历程:
2.2 大模型的基础------Transformer注意力机制
注意力机制:Transformer的核心创新
创新点1:Transformer模型最大的创新在于提出了注意力机制,这一机制极大地改进了模型学习远距离依赖关系的能力,突破了传统RNN和CNN在处理长序列数据时的局限。
创新点2:在Transformer出现之前,自然语言处理一般使用RNN或CNN来建模语义信息。但RNN和CNN均面临学习远距离依赖关系的困难:
- RNN的序列处理结构使较早时刻的信息到后期会衰减;
- 而CNN的局部感知也限制了捕捉全局语义信息。
- 这使RNN和CNN在处理长序列时,往往难以充分学习词语之间的远距离依赖。
创新点3:Transformer注意力机制突破了RNN和CNN处理长序列的固有局限 ,使语言模型能在大规模语料上得到丰富的语言知识预训练。该模块化、可扩展的模型结构也便于通过增加模块数量来扩大模型规模和表达能力,为实现超大参数量提供了可行路径。
Transformer解决了传统模型的长序列处理难题,并给出了可无限扩展的结构,奠定了大模型技术实现的双重基础。
下面是Transformer结构图:
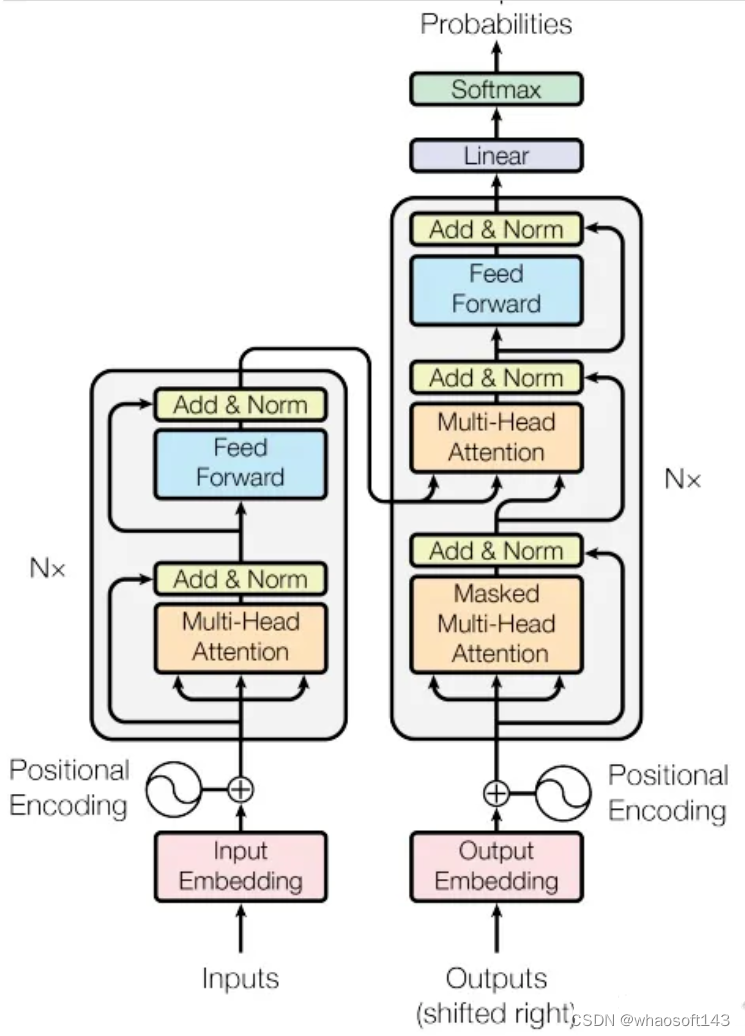
2.3 大模型的预训练-微调范式
大模型代表了一种新的预训练-微调范式,其核心是先用大规模数据集预训练一个极大的参数模型,然后微调应用到具体任务。
这与传统的单任务训练形成了对比,标志着方法论的重大变革。
参数量的倍数增长是大模型最根本的特点,从早期模型的百万量级,发展到现在的十亿甚至百亿量级,实现了与以往数量级的突破。
Transformer架构 的提出开启了NLP模型设计的新纪元,它引入了自注意力机制和并行计算思想,极大地提高了模型处理长距离依赖关系的能力,为后续大模型的发展奠定了基础。
正是由于Transformer架构的成功 ,研究者们意识到模型的架构设计在处理复杂任务和大规模数据中发挥着举足轻重的作用。这一认识激发了研究者进一步扩大模型参数量的兴趣。虽然之前也曾有过扩大参数量的尝试,但因受限于当时模型本身的记忆力等能力,提高参数数量后模型的改进并不明显。
GPT-3的成功充分验证了适度增大参数量能显著提升模型的泛化能力和适应性,由此掀起了大模型研究的热潮。
它凭借过千亿参数量和强大的语言生成能力,成为参数化模型的典范。GPT-3在许多NLP任务上表现亮眼,甚至在少样本或零样本学习中也能取得惊人的效果。
增大参数量的优点:
- 更好的表示能力:增大参数量使模型能够更好地学习数据中的复杂关系和模式,从而提高模型的表示能力,使其在不同任务上表现更出色。
- 泛化能力和迁移学习:大模型能够从一个领域学习到的知识迁移到另一个领域,实现更好的迁移学习效果,这对于数据稀缺的任务尤其有价值。
- 零样本学习:增大参数量可以使模型更好地利用已有的知识和模式,从而在零样本学习中取得更好的效果,即使只有很少的示例也能完成任务。
- 创新和探索:大模型的强大能力可以帮助人们进行更多创新性的实验和探索,挖掘出更多数据中的隐藏信息。
2.4 探索大模型:任务适配性、模型变革与应用前景
与早期的人工智能模型相比,大型模型在参数量上取得了质的飞跃,导致了在复杂任务的建模能力整体上的提升:
1)学习能力增强:以应对更复杂的任务;
2)泛化能力加强:以实现更广泛的适用性;
3)鲁棒性提高;
4)具备更高层次认知互动能力:可模拟某些人类能力等。
复杂性、高维度、多样性和个性化要求使得大型模型在某些任务上更易获得出色的建模能力:
- 多模态传感器数据的融合分析,尤其涉及到时序数据的处理,如自动驾驶
- 复杂且动态的目标,需要模型从大规模多样化的数据模式中学习,如金融领域中的量化交易策略优化
- 涉及异构数据源的高维输入空间,如医学图像和报告
- 需要为不同用户或场景进行个性化建模的定制化需求,如智能助理

三、自动驾驶技术迭代路径
3.1 自动驾驶算法核心模块概览
自动驾驶算法模块可分为感知、决策和规划控制三个环节,其中感知模块为关键的组成部分
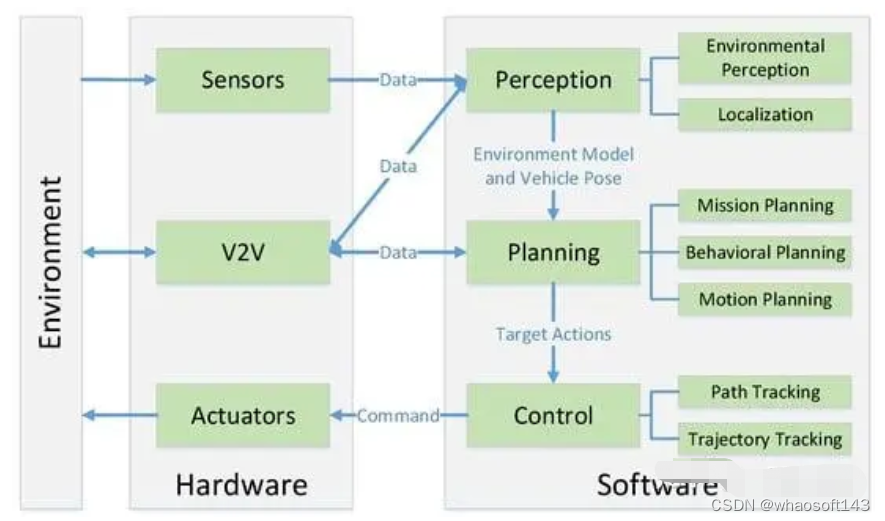
感知模块:感知模块负责解析并理解自动驾驶所处车辆周边的交通环境,是实现自动驾驶的基础和前提,感知模块的精准程度,直接影响并制约着自动驾驶系统的整体安全性和可靠性。
感知模块主要通过摄像头、激光雷达、毫米波雷达等各类传感器获取输入数据,然后通过深度学习等算法,准确解析出道路标线、其他车辆、行人、交通灯、路标等场景元素,以供后续流程使用。
决策和规划控制:与感知模块相比,决策和规划控制等模块的作用更为单一和被动。
这些模块主要依据感知模块输出的环境理解结果,通过算法决策生成驾驶策略,并实时规划车辆的运动轨迹和速度,最终转换为控制命令,以实现自动驾驶。
但是,大模型在车端赋能主要作用于感知和预测环节,逐渐向决策层渗透。
3.2 CNN
2011-2016:CNN引发自动驾驶领域的首次革新浪潮
随着深度学习和计算能力的提升,卷积神经网络(CNN)在图像识别任务上的出色表现引发了自动驾驶领域的首次革新浪潮。
- 2011年,IJCNN的论文《Traffic Sign Recognition with Multi-Scale Convolutional Networks》展示了CNN在交通标志识别方面的潜力;
- 2016年,Nvidia团队发表的《End-to-End Deep Learning for Self-Driving Cars》成为最早将CNN应用于端到端自动驾驶的工作之一。
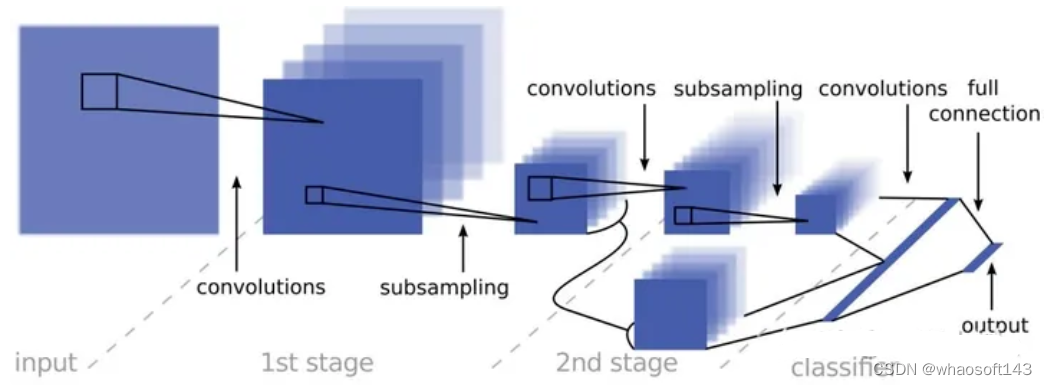
这是一个两阶段的卷积神经网络架构,输入通过两个卷积和子采样阶段进行前馈处理,最终通过线性分类器进行分类。
CNN极大提升了自动驾驶车辆的环境感知能力
- 一方面,CNN在图像识别与处理方面的卓越表现,使车辆能够准确分析道路、交通标志、行人与其他车辆;
- 另一方面,CNN有效处理多种传感器数据的优势,实现了图像、激光雷达等数据的融合,提供全面的环境认知。叠加计算效率的提高,CNN模型进一步获得了实时进行复杂的感知与决策的能力。
但CNN自动驾驶也存在一定局限性:
- 1)需要大量标注驾驶数据进行训练,而获取足够多样化数据具有难度;
- 2)泛化性能有待提高;
- 3)鲁棒性也需要经受更复杂环境的考验;
- 4)时序任务处理能力:相比较而言RNN等其他模型可能更占优势。
3.3 RNN、GAN
2016-2018:RNN和GAN被广泛应用到自动驾驶相关的研究,推动自动驾驶在对应时间区间内快速发展
RNN相较于CNN更适合处理时间序列数据:RNN的循环结构可以建模时间上的动态变化,这对处理自动驾驶中的轨迹预测、行为 分析等时序任务非常有用。例如在目标跟踪、多智能体互动建模等领域,RNN和LSTM(RNN的改进版本)带来了巨大突破,可以 预测车辆未来的运动轨迹,为决策和规划提供支持。
GAN的生成能力缓解自动驾驶系统训练数据不足的问题:GAN可以学习复杂分布,生成高质量的合成数据,为自动驾驶领域带来 了新思路,用于缓解自动驾驶系统训练数据不足的问题。例如GAN可以生成模拟的传感器数据、场景信息,测试自动驾驶算法的 鲁棒性,也可以用于交互式模拟场景生成。
RNN+GAN,可以实现端到端的行为预测和运动规划:RNN负责时序建模,GAN负责数据生成,两者相互协同,可以为自动驾驶系统提供更全面和可靠的环境感知、状态预测和决策支持。

这是融合了LSTM和GAN的模型架构示例。
RNN和GAN仍未解决的问题:
- RNN类模型:长期时序建模能力仍较弱,特别是在处理较长的时间序列数据时可能出现梯度消失或梯度爆炸的问题,限制了它在某些自动驾驶任务上的应用效果。
- GAN模型:生成的数据质量难以控制,很难达到足够逼真的程度。此外,尽管GAN可以生成合成数据,但在实际应用中,它在自动驾驶领域的具体应用仍相对有限。
- 样本效率低:RNN和GAN在样本效率方面仍较低,通常需要大量的真实场景数据来训练和优化模型。而且这些模型难以解释,缺乏对内部决策过程的清晰解释,同时模型的稳定性和可靠性也是需要进一步解决的问题之一。
RNN和GAN在自动驾驶领域应用趋冷的原因:
- 效率和实时性需求:自动驾驶系统需要在实时性要求较高的情况下做出决策和控制。传统的RNN在处理序列数据时,存在计算效率较低的问题,处理实时感知和决策任务能力有限。
- 复杂性和泛化能力:自动驾驶涉及复杂多变的交通场景和环境,需要具备强大的泛化能力。然而,传统的RNN可能在处理复杂的时序数据时遇到困难,而无法很好地适应各种交通情况。
- 新兴技术的兴起:随着深度学习领域的发展,新的模型架构和算法不断涌现,如Transformer架构、强化学习等,这些新技术在处理感知、决策和规划等任务方面可能更加高效和适用。
3.4 BEV
2018-2020:基于鸟瞰视角(BEV)的模型在自动驾驶领域获得了广泛的研究和应用
BEV模型的核心思想是将车辆周围的三维环境数据(如来自激光雷达和摄像头的点云、图像等数据)投影到俯视平面上生成二维的鸟瞰图。这种将三维信息"压平"成二维表示的方式,为自动驾驶系统的环境感知和理解带来了重要优势:
- 鸟瞰图提供了比直接的原始传感器数据更加直观和信息丰富的环境表示,可以更清晰地观察道路、车辆、行人、标志等元素的位置和关系,增强自动驾驶对复杂环境的感知能力
- 全局的俯视视角更有利于路径规划和避障系统进行决策,根据道路和交通状况规划更合理稳定的路径
- BEV模型可以将来自不同传感器的输入数据统一到一个共享表示中,为系统提供更加一致和全面的环境信息
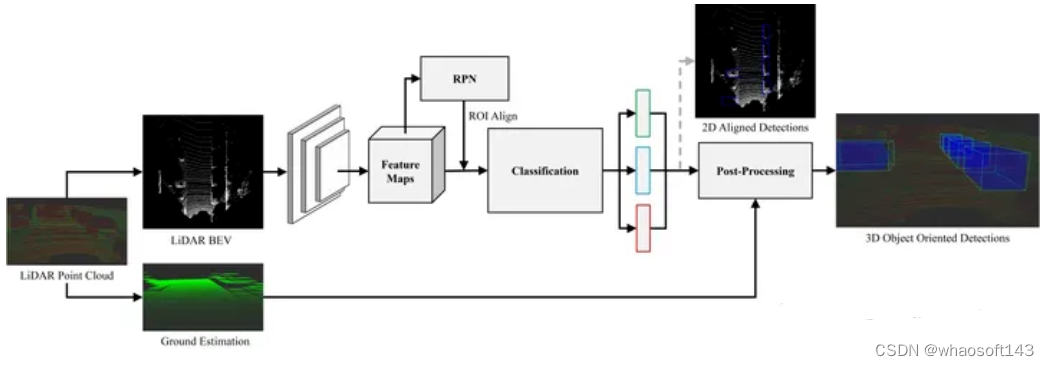
这是BirdNet 3D 对象检测框架,网络的三个输出是:类别(绿色)、2d 边界框(蓝色)和偏航角(红色)。
但是,BEV模型也存在一些问题亟待解决:
- 从原始三维数据生成BEV表示需要进行大量坐标变换和数据处理,增加了计算量和对硬件的要求
- 信息损失问题,三维信息投影到二维时难免会损失一些细节,如遮挡关系等
- 不同传感器到BEV坐标系的转换也需要进行复杂的标定和校准
- 需要研究如何有效融合各种异构数据源,以生成更加准确和完整的BEV
3.5 Transformer+BEV
2020年以来, Transformer+BEV结合正在成为自动驾驶领域的重要共识,推动自动驾驶技术进入崭新发展阶段
将Transformer模型与BEV(鸟瞰视角)表示相结合的方法,正在成为自动驾驶领域的重要共识,推动完全自主驾驶的实现
- 一方面,BEV可以高效表达自动驾驶系统周围的丰富空间信息;
- 另一方面,Transformer在处理序列数据和复杂上下文关系方面展现了独特优势,在自然语言处理等领域得到成功应用。两者结合可以充分利用BEV提供的环境空间信息,以及Transformer在多源异构数据建模方面的能力,实现更精确的环境感知、更长远的运动规划和更全局化的决策。
特斯拉率先引入BEV+Tranformer大模型,与传统2D+CNN小模型相比,大模型的优势主要在于:
- 1)提高感知能力:BEV将激光雷达、雷达和相机等多模态数据融合在同一平面上,可以提供全局视角并消除数据之间的遮挡和重叠问题,提高物体检测和跟踪的精度;
- 2)提高泛化能力:Transformer模型提取特征函数,通过注意力机制寻找事物本身的内在关系,使智能驾驶学会总结归纳而不是机械式学习。主流车企及自动驾驶企业均已布局BEV+Transformer,大模型成为自动驾驶算法的主流趋势。
下面是Transformer+BEV的示例框图:
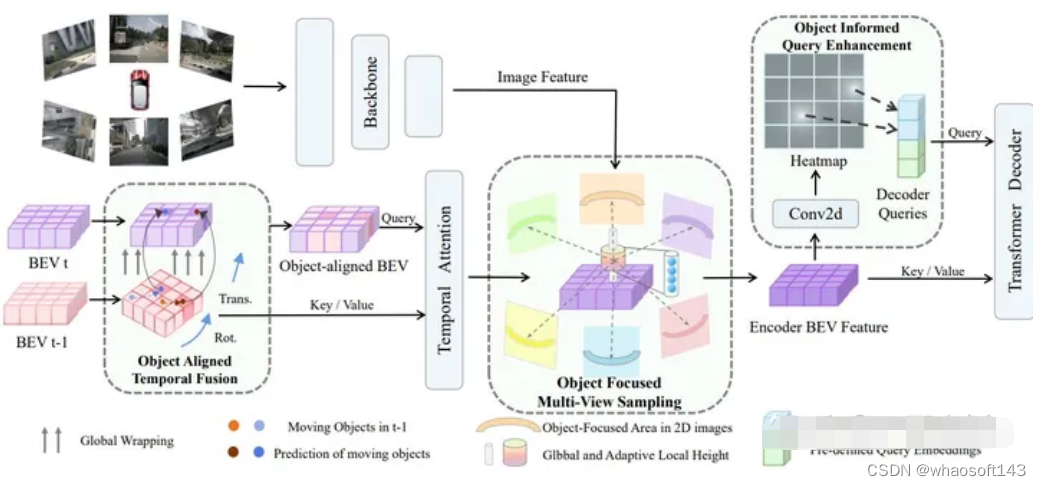
(a) 对象对齐时间融合:首先根据车辆自身的移动情况,把 当前时刻(t时刻)的鸟瞰视角地图变形调整成上一时刻(t-1 时刻)的样子。这样就可以根据对象在上一时刻的位置, 结合速度预测出它当前的位置,从而实现对象在不同时刻 地图上的融合。
(b) 对象聚焦多视图采样:首先在三维空间预设一些点,然后把这些点投影到图像上的特征上。这样不仅可以在整个高度范围采样,还可以对某些主要对象按照自适应和聚焦的方式,在它们所处的局部空间区域采样更多点。
(c) 对象通知查询增强:在编码器处理图像特征后,添加热图的监督信息。同时用检测到对象高置信度位置对应的点 来替换掉原本预设要查询的一些点。
下面是Transformer+BEV的示例框图2:
GPT的出现对Transformer+BEV模型的产生起到了重要影响
- GPT的成功表明了Transformer模型的潜力,促使更多研究者将Transformer应用到计算机视觉和自动驾驶领域,产生了 Transformer+BEV的创新做法。
- GPT的预训练思想为Transformer+BEV的预训练和迁移学习提供了借鉴,可以通过预训练捕捉语义信息,然后迁移应用。
- OpenAI公开的代码和模型也加速了Transformer类模型在各领域的研究进程。
当前Transformer+BEV模型受关注,主要基于它综合了Transformer和BEV各自的优势
- Transformer擅长处理序列数据,捕捉语义信息;而BEV提供场景整体观,有利解析空间关系。两者组合可实现互补,增强 对复杂场景的理解表达。
- 自动驾驶数据积累为训练大模型奠定基础。大数据支持学习更复杂特征,提升环境感知精度,也使端到端学习成为可能。
- 提升安全性和泛化能力仍是自动驾驶核心难题。目前阶段Transformer+BEV较好地结合语义理解和多视角建模,可处理相对 不常见、复杂或者挑战性的交通场景或环境,具有很大潜力。
3.6 占用网络模型
2022年,自动驾驶系统中使用了占用网络模型,实现了对道路场景的高效建模
占用网络模型
- 占用网络是特斯拉在2022年应用到自动驾驶感知的一种技术,相较于BEV可以更精准地还原自动驾驶汽车行驶周围3D环境,提升车辆的环境感知能力。
- 占用网络包含两部分:一个编码器学习丰富语义特征,一个解码器可以生成三维场景表达。
- 特斯拉使用车载摄像头采集的大量行车数据,训练占用网络模型。解码器部分能够复原和想象各种场景,增强异常情况下的感知棒性。
- 占用网络技术使特斯拉可以充分利用非标注数据,有效补充标注数据集的不足。这对于提升自动驾驶安全性、减少交通事故具有重要意义。特斯拉正在持续改进该技术在自动驾驶系统中的集成应用。
特斯拉在2023年AI Day公开了occupancy network(占用网络)模型,基于学习进行三维重建,意图为更精准地还原自动驾 驶汽车行驶周围3D环境,可视作BEV视图的升华迭代:
- BEV+Transformer的不足:鸟瞰图为2D图像,会缺失一些空间高度信息,无法真实反映物体在3D空间的实际占用体积, 故而在BEV中更关心静止物体(如路沿、车道线等),而空间目标的识别(如物体3D结构)难以识别
- 占用网络:现存三维表示方法(体素、网格、点云)在储存、结构和是否利于学习方面均不够完全理想,而占用网络基于学习将三维曲面表示为深度神经网络分类器的连续决策边界,可以在没有激光雷达提供点云数据的情况下对3D环境进行重建,且相较于激光雷达还可以更好地将感知到的3D几何信息与语义信息融合,得到更加准确的三维场景信息
华为ADS 2.0进一步升级GOD 网络,道路拓扑推理网络进一步增强,类似于特斯拉的占用网络。
- GOD 2.0(通用障碍物检测网络, General Obstacle Detection)障碍物识别无上限,障碍物识别率达到99.9%;
- RCR2.0能识别更多路,感知面积达到2.5个足球场,道路拓扑实时生成。
- 2023年12月,搭载ADS 2.0的问界新M7可实现全国无高精地图的高阶智能驾驶。
对比BEV效果,下面BEV鸟瞰视图

下面是占用网络3D视图:
四、大模型对自动驾驶行业的赋能
4.1 自动驾驶的大模型
以GPT为代表的大模型通常包含亿级甚至百亿级参数,采用Transformer结构进行分布式训练,以提升模型能力。
GPT的成功激发了:自动驾驶研究者利用类似架构进行端到端学习,甚至涌现出专为自动驾驶设计的预训练模型。这些努力为自动驾驶行业带来新思路,大模型通过强大的数据分析和模式识别能力,增强了自动驾驶系统的安全性、效率和用户体验,实现了更准确的环境感知、 智能决策。

大模型的应用加速模型端的成熟,为L3/L4级别的自动驾驶技术落地提供了更加明确的预期
模型的成熟使得自动驾驶系统更加稳定和可靠,为商业化应用奠定了基础。随着深度学习和神经网络技术的迅速发展,模型在 感知、决策和控制等方面取得了显著进展,向着高效地处理大量传感器数据,准确识别交通标志、行人、车辆等、实现环境感 知的方向发展。此外,模型也能够辅助实时路径规划和决策制定,使车辆能够在复杂的交通环境中安全行驶。
大模型的应用为L3/L4级别的自动驾驶技术落地提供了更加明确的预期,尤其特斯拉在前沿技术领域的探索,正在成为实现L3/L4级别自动驾驶落地的风向标。特斯拉提出的Transformer+BEV+占用网络算法让车辆能够更精准地理解复杂的交通环境, 为L3/L4级别的自动驾驶系统提供更强的环境感知能力,从而在城市道路和高速公路等特定场景中更自信地行驶。
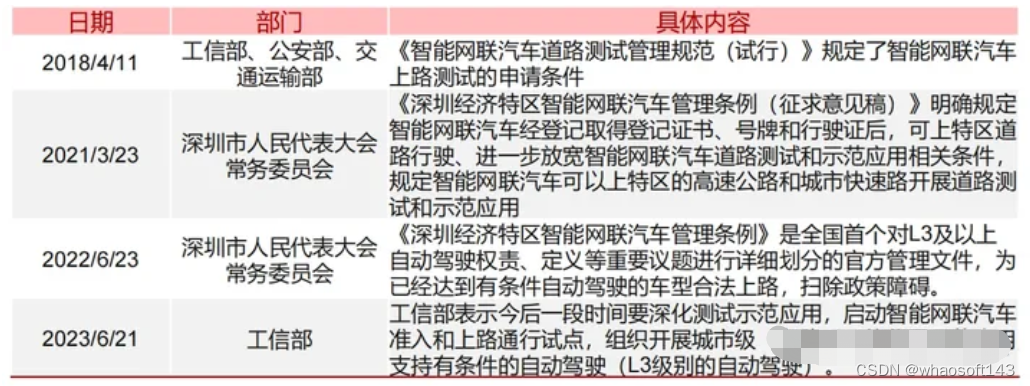
国内重要自动驾驶政策节选
安全性自动驾驶汽车实现商业化落地必不可少的重要因素
为保证自动驾驶系统的安全可靠,按照国家监管要求,自动驾驶车辆必须经过5000公里以上的封闭场地训练评估,且测试驾驶员须通过不少于50小时培训,并通过车辆安全技术检验后方可申请上路测试资格。目前我国智能网联汽车道路测试总里 程已超7000万公里,我们预计L3级及以上自动驾驶汽车开放个人使用上路试点区域仍需一定的时间才能实现。
汽车通信安全和数据安全也需达到国标或相关条例要求。我们预计未来中国会参考欧美国家实践,进一步细化安全要求,加强相关法规制度建设,如制定自动驾驶汽车安全评估标准、明确自动驾驶系统开发生命周期各阶段的安全保障要求、建立自 动驾驶汽车事故责任认定机制等。
部分自动驾驶汽车安全标准:

4.2 车端赋能主要作用于感知和预测环节,逐渐向决策层渗透
大模型在自动驾驶中的应用简单来说,就是把整车采集到的数据回传到云端,通过云端部署的大模型,对数据进行相近的训练。
大模型主要作用于自动驾驶的感知和预测环节。
- 在感知层,可以利用Transformer模型对BEV数据进行特征提取,实现对障碍物的监测和定位;
- 预测层基于感知模块的输出,利用Transformer模型捕捉学习交通参与者的运动模式和历史轨迹数据,预测他们未来行为和轨迹。
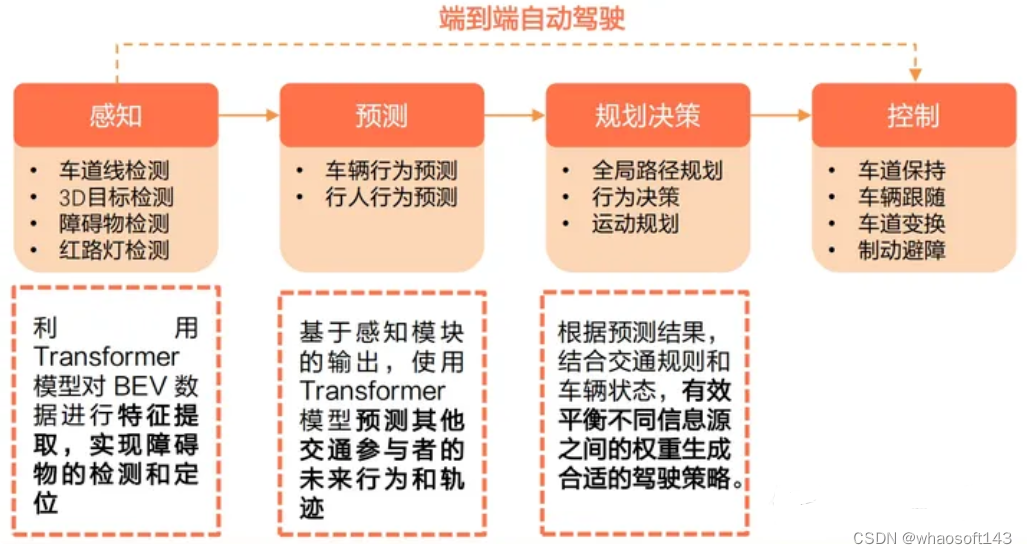
未来将驱动驾驶策略生成 逐渐从规则驱动向数据驱动转变。规划决策层的驾驶策略的生成有两种方式:
1)基于数据驱动的深度学习算法;
2)基于规则驱动(出于安全考虑,目前普遍采取基于规则生成驾驶策略,但随着自动驾驶等级的提升及应用场景的不断拓展,基于规则 的规控算法存在较多Corner Case处理局限性)。
结合车辆动力学,可利用Transformer模型生成合适的驾驶策略:
将动态环境、路况信息、 车辆状态等数据整合到模型中,Transformer多头注意力机制有效平衡不同信息源之间的权重,以便快速在复杂环境中做出合理决策。
本文内容来自以下资料:
- AI+行业系列之智能驾驶:自动驾驶的"大模型"时代
- 智能汽车行业专题研究:大模型应用下自动驾驶赛道将有哪些变化
- 2023年行业大模型标准体系及能力架构研究报告
- 人工智能行业专题报告:多模态AI研究框架
- AI大时代系列报告之一(基础篇):大模型与算力共振,奇点时刻到来
- 等等......
#2023国内自动驾驶公司
1. tire1厂商,供应链企业
这部分公司的划分原则是tire1的供应链厂商,结合我个人了解到的技术积累情况。以上,难免有失偏颇,还请见谅!
持续布局企业
这部分企业是国内比较早开始从事自动驾驶方面研究的,并且在硬件和软件方面都取得了不错的进展。入职可以快速提高自身自动驾驶开发能力,另外跳槽的下家也会基于更高的工资上浮。
华为
入职理由:华为的技术研发能力毋庸置疑,虽然最近华为自动驾驶技术才被外界所知,但其实内部已经进行了很长时间的技术预研和储备。在硬件领域,华为比国内的所有企业都有很大的优势,也是目前国内最有希望实现国内自动驾驶技术软硬一体化解决方案的企业。目前华为对外释放的消息是要给企业提供自动驾驶解决方案的tire1厂商。
- 曾用名:华为车BU
- 入局时间:2015年底
- 团队背景:2012实验室,秦通等。
- 自动驾驶等级:L2,L3,L4
- 代表产品:MDC,赛力斯,问界M5等。
- 融资情况:无
- 推荐评分:8.0
百度apollo
入职理由:魏则西事件后,很多网友喷百度没有底线,只会卖假药的营销公司。但其实百度在自动驾驶技术上的投资要早于绝大部分企业。百度的apollo技术开源也增加了国内技术开发者投身自动驾驶领域的热情。毫不夸张的说,百度堪比中国自动驾驶技术的黄埔军校。从百度走出很多大佬支撑这自动驾驶的未来。目前百度定位是tire1厂商,也和国内的整车/零部件企业有很多合作。
- 曾用名:百度,apollo
- 入局时间:2015年底
- 团队背景:陆奇,余凯等前百度大佬。
- 自动驾驶等级:L2,L3,L4
- 代表产品:apollo,apollo lite, robotaxi(自动驾驶出租车)。
- 融资情况:无
- 推荐评分:8.0
小马智行
入职理由:pony.ai创立时间于2016年。前百度北美研发主任架构师彭军(Stanford PhD)和中国编程"楼教主"楼天城联合创立,二人分别担任小马智行的CEO和CTO。主要产品是PonyPilot+ ,提供的自动驾驶移动出行服务应用(Robotaxi)。与丰田、现代、一汽、广汽、博世等均有合作的tire1厂商。
- 曾用名:小马智行,pony.ai
- 入局时间:2016年底
- 团队背景:楼教主,彭军。
- 自动驾驶等级:L2,L3,L4
- 代表产品:PonyPilot+ ,Robotaxi(自动驾驶出租车)和Robotruck(自动驾驶卡车)
- 融资情况:C
- 推荐评分:7.5
momenta
入职理由:在中国、德国、日本有全球业务,并已获得上汽集团、通用汽车、梅赛德斯-奔驰、丰田和博世的战略投资。目前定位为tire1厂商。研发能力很强,项目需求很旺。
- 曾用名:魔门塔,初速度
- 入局时间:2016年底
- 团队背景:曹旭东,任少卿(离职)。
- 自动驾驶等级:L2,L3,L4
- 代表产品:Mpilot,MSD(Momenta Self Driving)自动驾驶解决方案,自由泊车
- 融资情况:C+
- 推荐评分:7.5
图森未来
入职理由:无人卡车,可商用的L4级别(SAE标准)无人驾驶卡车解决方案、高速场景及港口集装箱卡车的无人驾驶运输解决方案。目前已经上市,在自动驾驶的技术积累和创新上为业界做出了很多贡献。在北美路测均取得了很多进展。最近顶会也常常发paper和数据集。
- 曾用名:图森未来
- 入局时间:2015年
- 团队背景:北美团队
- 自动驾驶等级:L4无人驾驶卡车
- 代表产品:无人卡车
- 融资情况:纳斯达克上市
- 推荐评分:7.5
2. 头部创业,潜力巨大
文远知行
入职理由:主要定位于实现L4级别的自动驾驶。于2017年12月将全球总部落户广州,目前在硅谷和广州都设立了研发中心,团队中70%-80%为来自于海内外知名大厂的优秀研发工程师。公司的愿景是成为中国第一、世界一流的智能出行公司。
- 曾用名:文远知行,WeRide
- 入局时间:2017年底
- 团队背景:韩旭(Tony Han),前百度自动驾驶首席科学家
- 自动驾驶等级:L4
- 代表产品:Robotaxi,自由泊车
- 融资情况:C,33亿美金
- 推荐评分:7.5
autox
入职理由:同样是在北美测试榜的前十公司,获得上汽集团、东风汽车等整车厂的看好。AutoX布局全球八大地区城市,在深圳、北京、上海、广州等地设有五大研发中心,在常州设有无人车产线,在深圳、上海、广州、北京设有十大运营中心。目前除了提供自动驾驶服务意外,据传也在提供解决方案。
- 曾用名:安途,autox
- 入局时间:2016
- 团队背景:Stanford顶级团队
- 自动驾驶等级:L4
- 代表产品:Robotaxi,AutoX Gen5
- 融资情况:Pre-B
- 推荐评分:7.5
元戎启行
入职理由:元戎启行是一家国际化的 L4级自动驾驶公司,聚焦自动驾驶出行和自动驾驶同城货运两大场景。于2021年9月获得获阿里巴巴领投 3 亿美元 B 轮融资;
核心团队有着丰富的研发和商业化经验,汇集了清华、北大、剑桥、哥伦比亚、 卡耐基梅隆等国内外名校的硕博士,以及曾供职于谷歌、微软、福特、英特尔、通用、Cruise、 百度、华为、腾讯等世界顶尖科技公司的精英。公司研发人员占比高达 80%,覆盖自动驾驶技术的各个模块;
在深圳、北京设有研发中心,和东风汽车、曹操出行、厦门远海码头等知名企业在全国多地开展自动驾驶相关合作,进行了大量的道路测试和试运营。运营车队已分别获得杭州、武汉、深圳等地的测试、试运营许可。自2019年2月成立以来,元戎启行在全国累计的安全路测里程已超过200万公里。
- 曾用名:元戎启行
- 入局时间:2019年2月
- 团队背景:Stanford顶级团队
- 自动驾驶等级:L4
- 代表产品:Robotaxi,AutoX Gen5
- 融资情况:B 轮,3 亿
- 推荐评分:7.5
驭势科技
入职理由:世界领先智能驾驶企业,无人驾驶商业化领跑者。用人工智能和大数据重构人和物的交通,用无人驾驶解决十亿级别人群的交通和物流问题。驭势科技致力于打造未来的自动驾驶系统和全新的交通方式,我们深信人工智能将赋予交通工具智慧和灵性,让人类的出行更加便捷、安全和舒适。
- 曾用名:驭势科技
- 入局时间:2016年11月
- 团队背景:吴甘沙,前英特尔中国研究院院长
- 自动驾驶等级:L4
- 代表产品:无人驾驶物流车,U-Drive智能驾驶系统
- 融资情况:B 轮
- 推荐评分:7.5
毫末智行
入职理由:长城汽车旗下自动驾驶公司+百度系。聚焦To C端乘用车高级别自动驾驶解决方案及To B端车规级无人物流小车。现有团队规模近200人,拥有保定和北京两个研发中心。其中来自清华、中科大、南开、中科院等国内985/211重点院校的占比超过25%。
- 曾用名:毫末智行, HAOMO.AI
- 入局时间:2019年11月
- 团队背景:张凯,CEO, 长城汽车技术副总工程师。顾维灏,原百度智能汽车事业部总经理
- 自动驾驶等级:L2~L4,其中,L2~L3级产品已商业化
- 代表产品:无人驾驶物流车,U-Drive智能驾驶系统
- 融资情况:A轮,10亿美元
- 推荐评分:7.5
轻舟智航
入职理由:创于硅谷的全华人团队。基于大规模智能仿真系统、可自主学习决策规划框架和多传感器融合和时序融合方案等核心技术,轻舟智航推出了专注城市复杂交通场景的无人驾驶方案"Driven-by-QCraft。推出的首款无人驾驶小巴------龙舟ONE(又称轻舟无人小巴)已在苏州、深圳、武汉等多个城市落地,是国内布局城市最多的公开道路无人公交。
- 曾用名:轻舟智航, QCraft
- 入局时间:2019年5月
- 团队背景:侯聪,曾就职于Waymo Perception Team
- 自动驾驶等级:L4
- 代表产品:龙舟ONE(又称轻舟无人小巴)
- 融资情况:A+轮,1亿美元
- 推荐评分:7.5
智行者(iDriverPlus)
入职理由:北京智行者科技有限公司,聚焦无人驾驶汽车的"大脑"研发,致力于成为多通用场景L4解决方案提供商。已获得厚安(厚朴/Arm)百度、顺为、京东等多家国内外知名机构的投资。智行者是业内同时具备开放L4技术能力及限定区域L4落地能力的无人驾驶企业。
公司已有员工400多人,核心团队均来自清华大学汽车系,技术能力业界顶尖,自研的无人驾驶车辆累计测试里程已超过两百万公里,位列国内无人驾驶初创企业前列。
- 曾用名:智行者,iDriverPlus,智行者科技
- 入局时间:2015年
- 团队背景:清华系 | CEO张德兆;CTO 王肖,清华 PhD
- 自动驾驶等级:L4级
- 代表产品:robotaxi、robobus、无人驾驶清扫车、无人驾驶吸尘车、无人驾驶洗地车、无人驾驶巡逻等
- 融资情况:C+轮 70亿
- 推荐评分:7.2
纵目科技
入职理由:入局时间早,技术积累深厚,目前有很多已经可以落地的辅助驾驶产品。纵目科技在自动驾驶(AD)和高级驾驶辅助系统(ADAS)技术上都有所积累。当前业务涵盖智能驾驶系统、智能传感器和智慧城市产品、服务以及无线充电四大部分。是国内率先获得整车厂L4级别量产项目定点合同的自动驾驶企业之一,并与一汽红旗、长安汽车等多家国内主流主机厂商建立了量产合作关系。
- 曾用名:纵目科技
- 入局时间:2013年
- 团队背景:--
- 自动驾驶等级:L2,L3为主
- 代表产品:环视ADAS,全景泊车系统、移动物体监测(MOD)还可叠加车道偏离预警(LDW)等
- 融资情况:10亿元 E轮
- 推荐评分:7.2
西井科技
入职理由:西井科技主要做码头集装箱物流。业务需求旺盛,业务已遍及海内外80余个节点。其重点产品WellOcean(人工智能智慧港口解决方案)、Qomolo(新能源无人驾驶商用解决方案),正在使全局化、多场景的AI应用组合创新变得更简单、快速和高效。
- 曾用名:西井科技,WESTWELL
- 入局时间:2015-05
- 团队背景:---
- 自动驾驶等级:L4(受限场景)
- 代表产品:Q-Truck无人电动重卡
- 融资情况:D+
- 推荐评分:7.0
云骥智行
入职理由:云骥智行由全球知名的自动驾驶技术研发专家,在自动驾驶、车路协同、大数据等领域,具有深厚的技术积累和独到的行业洞见。致力于打造覆盖车、路、云的L4-L5级别自动驾驶通用平台解决方案,为干线物流、城市货运和乘用出行三大应用场景提供跨平台的体化解决方案。
云骥智行已在中国上海、深圳和美国硅谷等地设有研发中心,公司团队70%的人员在汽车领域深耕10年以上,硕博占比为80%。
- 曾用名:云骥智行
- 入局时间:021年11
- 团队背景:前百度副总裁、Apollo平台研发总经理王京傲;小鹏/TESLA曹光植
- 自动驾驶等级:L4-L5
- 代表产品:--
- 融资情况:数亿元天使轮
- 推荐评分:7.1
禾多科技
入职理由:禾多科技成立于2017年6月,基于前沿人工智能技术和汽车工业技术,打造由本地数据驱动的自动驾驶量产解决方案。作为量产领先的自动驾驶公司,禾多科技具备从人工智能算法到嵌入式系统,从大数据闭环到系统迭代进化的完整布局,以行车和泊车两大场景为量产切入点,最终实现全场景的无人驾驶解决方案部署。
- 曾用名:禾多科技
- 入局时间:2017年6月
- 团队背景:清华大学无人车团队
- 自动驾驶等级:L4,L5
- 代表产品:--
- 融资情况:B轮数亿
- 推荐评分:7.1
奥特酷
入职理由:AutoCore是Autoware基金会的创建者之一,同时也是基金会多个项目的主要贡献者之一。奥特酷比较低调, 没有进行大规模的宣传。据了解公司造血能力很强,盈利状态。主要领导都是技术大佬出身,对行业方向的把握精准。在南京的小伙伴可以尝试。此外AutoCore还与Arm等联手打造的开源平台OpenADKit。
- 曾用名:奥特酷,autocore
- 入局时间:2018年3月
- 团队背景:Autoware开源技术贡献者
- 自动驾驶等级:L2
- 代表产品:os,Autoware
- 融资情况:A轮,高瓴等
- 推荐评分:7.1
赢彻科技
友道智图
酷哇机器人
3.技术大厂,后发优势
大疆
入职理由:大疆依靠在无人机领域积累的视觉、算法等经验,专强势进入自动驾驶领域,直指自动驾驶L3/4级别系统方案。大疆的技术研发和创新能力毋庸置疑。目前大疆在自动驾驶技术上的定位是作为一个tr1的企业。其外在自动驾驶硬件上,大疆也有很深的技术积累和布局。(大疆的公司文化和以前华为有点,踏踏实实搞技术,不太愿意搞 噱头)
- 曾用名:大疆车载,大疆创新
- 入局时间:2018
- 团队背景:内部孵化
- 自动驾驶等级:L2
- 代表产品:智能驾驶D80\D80+、智能驾驶D130\D130+、智能泊车系统
- 融资情况:--
- 推荐评分:7.6
美团
入职理由:美团的无人驾驶应用场景主要是线下的无人配送。此外,美团也是一个拥有美团打车等服务的出行公司,不排除以后入局无人出租车领域。美团的无人送货车辆已经落地应用,但是还没有完全铺开,目前存在诸多的问题。此外在乘用车的无人驾驶方面,美团也在测试L4级别的应用。
- 曾用名:美团
- 入局时间:2016年
- 团队背景:内部孵化
- 自动驾驶等级:L4
- 代表产品:无人配送车
- 融资情况:--
- 推荐评分:7.5
阿里巴巴
入职理由:阿里自身自动驾驶领域的积累较少,入局时间也比较晚。但是投资了很多自动驾驶公司。此外,近两年阿里的达摩院和菜鸟等旗下公司也慢慢开始了自己对自动技术的积累。主要的应用场景集中在物流车上。从公开的顶会论文上看,阿里在自动驾驶的研究上的布局取得了不错的进展。
- 曾用名:阿里巴巴,达摩院,菜鸟
- 入局时间:2020年
- 团队背景:内部孵化,贾扬清(caffe主要贡献者)
- 自动驾驶等级:L4
- 代表产品:物流车,货车
- 融资情况:--
- 推荐评分:7.3
腾讯
入职理由:腾讯下面有很多优秀的实验室,包括优图,AI Lab等。他们的技术积累被用于自动驾驶上不会存在太多的障碍。此外,腾讯还有低调的自动驾驶实验室,目前整个自动驾驶实验室囊括了高精地图、融合定位、仿真平台、系统与架构、数据平台、核心算法等 6 大部门。腾讯应该是以车联网和云服务为抓手,搭建自己的自动驾驶平台。
- 曾用名:腾讯,腾讯AI Lab,腾讯自动驾驶实验室
- 入局时间:2016年9月
- 团队背景:内部孵化
- 自动驾驶等级:L4
- 代表产品:--
- 融资情况:已上市
- 推荐评分:7.5
滴滴
入职理由:滴滴入局自动驾驶合情合理,入局时间也比较早。在自动驾驶方面,滴滴有很多优势,比如数据积累等。以前自动驾驶可以靠滴滴的其他业务和融资进行持续输血,现在已经拆分出独立的公司进行融资与发展。是否有影响,还是个未知数。以前滴滴的主要产品是Robotaxi,现在滴滴也进入了自动驾驶卡车(Robotruck)业务。
- 曾用名:滴滴,
- 入局时间:2016
- 团队背景:内部孵化
- 自动驾驶等级:L4
- 代表产品:Robotaxi
- 融资情况:已上市,快退市了(速度太快)
- 推荐评分:7.3
小米汽车
小米从宣布开始造车以来投入了很多资源,小米汽车未来在产品一定会吸引很多的年轻消费者,但是自动驾驶还需要足够多的时间沉淀。
小米自动驾驶吸引了很多有经验的从业人员,会少走不少的弯路。产品定位更多的是在L2,L3附近的高级辅助驾驶功能。除了自动驾驶,小米在智能座舱方面也有很大的需求。智能座舱和自动驾驶相比,安全性要求会比较低,部署和落地更快一点,无论是自动驾驶还是智能座舱,对于算法工程师来说都是个不错的选择。
- 曾用名:小米,小米汽车
- 入局时间:2018
- 团队背景:内部孵化
- 自动驾驶等级:L2,L3,L4
- 代表产品:--
- 融资情况:已上市
- 推荐评分:7.4
4. 整车企业,全栈自研
小鹏
入职理由:小鹏汽车大家都很熟知了,从开始切入新能源汽车后就大力投入到自动驾驶技术的研发,在国内主机厂中,自动驾驶研发和应用落地无出其右。在某些方面自动驾驶的用户体验比特斯拉还有优秀。无论应届生还是社会青年劳动力都会让你有很大的收获。目前在L2, L3方面的车辆已经量产,L4级别的自动驾驶技术也在积极研发
小鹏汽车于2014年中建立研发团队,2015年1月在广州正式注册成立,目前拥有员工近万人,是中国领先的智能电动汽车设计及制造商,也是融合前沿互联网和人工智能创新的科技公司。致力于通过数据驱动智能电动汽车的变革,引领未来出行方式。小鹏汽车于2020年8月27日登陆纽交所上市,2021年7月7日登陆港交所上市。截至2021年6月30日,小鹏汽车在广州、北京、上海、深圳、硅谷、圣地亚哥、肇庆、郑州等地设有研发生产中心,其中肇庆小鹏汽车智能网联科技产业园已取得生产资质并投产,销售网络覆盖全国105座城市及欧洲挪威,实现了生产、研发及销售全球化布局,2021年累计交付量达到30738台,已超去年全年交付量。
- 曾用名:小鹏 xpen
- 入局时间:2014
- 团队背景:前期特斯拉
- 自动驾驶等级:L2, L3,L4
- 代表产品:p7
- 融资情况:已上市
- 推荐评分:7.6
蔚来
入职理由:蔚来相信大家已经很熟悉了。2016年之前,蔚来被很多人质疑,但是乘着新能源汽车的东风,蔚来迅速扩张。蔚来在自动驾驶领域的技术积累并不深厚,也就是从近年开始,蔚来才逐步加大自动驾驶技术自主研发的投入。目前已经有业内的多位大佬入职。比如,任少卿,曾就职与momenta,也是faster rcnn的一作。从入职的同学处获得反馈,整体研发路线和规划已经走在了行业的前列。在接下来的量产车上,蔚来可能会用上自己开发的自动驾驶系统。
- 曾用名:蔚来,NIO
- 入局时间:2014年11月成立
- 团队背景:任少卿
- 自动驾驶等级:L2,L3
- 代表产品:ES6,ES8,ET5等(自动驾驶技术非自研)
- 融资情况:已上市
- 推荐评分:7.5
理想
入职理由:相比较小鹏和蔚来,理想汽车要显得更加低调。而且定位上和小鹏等有所区别,主打家用舒适,并不强调智能,这造成了理想初期在自动驾驶上的研发投入不够,技术水平拉跨,自动驾驶产品频繁延期等问题。现在理想和蔚来一样,在自动驾驶方面正在加大投入的力度。目前自研情况良好,和地平线等企业存在业务上的合作。整体研发氛围轻松,但是节奏很快。后面也许会和地平线一起发布自己的自动驾驶量产产品。
- 曾用名:理想,NIO
- 入局时间:2015年7月
- 团队背景:--
- 自动驾驶等级:L2,L3
- 代表产品:理想ONE(自动驾驶技术非自研)
- 融资情况:已上市
- 推荐评分:7.5
中汽创智
入职理由:很多同事跳槽了中汽创智,所以对这家公司还算熟悉。属于传统车企强强联合造就的新势力造车企业。公司的定位和技术前瞻性要强于现在的的传统车企。主要是为了智能化出行的愿景,以此挖了很多业界的大佬和高级技术人员,很多都是北美自动驾驶技术的高级人才。公司虽然成立三年不到,但是业务已经涵盖了L2,L3,L4等级的自动驾驶业务,目前车辆在进行路测,但离正真的量产还有一段距离。技术上除了自研,也和地平线存在业务往来,主要是在自动驾驶技术的研发上。
中汽创智科技有限公司由中国一汽、长安汽车、东风公司、兵器装备集团、和南京江宁经开科技共同出资160亿元设立。公司聚焦智能电动底盘、氢燃料动力、智能网联三大业务领域。开展IBC集成制动系统、氢燃料动力系统、驾驶中央计算平台,下一代感知系统、人车路云信息聚合平台、固态动力电池、下一代智能座舱域控制器及信息安全等项目,力争三年实现行业领先。
- 曾用名:中汽创智
- 入局时间:2020年6月
- 团队背景:---
- 自动驾驶等级:L2, L3,L4
- 代表产品:--
- 融资情况:国资委控股
- 推荐评分:7.4
上汽
入职理由:上汽的历史悠久,典型的主机厂做派。但是在所有传统主机厂中,我觉得上汽在自动驾驶业务上投入精力和时间都是独一份的。自动驾驶业务,上汽一直在持续的投入,无论是自研还是拉供应链一起都做了不少的工作,我的上一家公司在自动驾驶业务的开发上,上汽就出了不少力(钱)。我的很多同学在毕业后入职的第一家公司也有在上汽的,但是无奈,后来都因种种原因离职了。或许这也是上汽存在的问题,他们早就觉得要加大自动驾驶的投入,但是航母掉头需要的时间太长了,而且容易翻车。这种情况希望能慢慢的改变。
- 曾用名:上海汽车,上汽
- 入局时间:2007-07
- 团队背景:---
- 自动驾驶等级:L2, L3,L4
- 代表产品:××(无自研的自动驾驶系统落地)
- 融资情况:--
- 推荐评分:7.3
华人运通
入职理由:华人运通大家可能有点陌生,说高合汽车大家应该就明白了。华人运通开发的高合HiPhi X有幸体验过一次。也尝试开启了自动/辅助驾驶功能,当我看到屏幕上闪烁的车辆行人等障碍物时,我明白了这家公司的伟大。和蔚来,比亚迪不一样,高合应该是要走自研自动驾驶技术的路了,而且更加坚定,只不过,技术积累还有待进一步提高。如果你是有技术积累的话,华人运通是个不错的选项,你的思想或者工作会有落地的可能。另外。据华人运通的同学反馈,研发氛围不错,和传统主机厂明显不同。
- 曾用名:华人运通,高合
- 入局时间:2019-02
- 团队背景:---
- 自动驾驶等级:L2, L3
- 代表产品:高合HiPhi X
- 融资情况:--
- 推荐评分:7.2
哪吒
入职理由:合众汽车最近发布了很多性价比很高的产品,但是自动及时技术并未及时跟上。最近这两年也在加大自动驾驶的投入力度。
- 曾用名:合众汽车,哪吒汽车
- 入局时间:2014年10月
- 团队背景:---
- 自动驾驶等级:L2, L3
- 代表产品:哪吒
- 融资情况:--
- 推荐评分:7.1
三一重工
入职理由:前段时间找机会,很荣幸参加了三一重工的面试,面试情况个人感觉挺好。
和其他乘用车市场不一样,三一主要关注于工业用的特种车辆,包括无人矿车,物流车等等。了解下来,三一给我的感觉是比较踏实,技术路线清晰,且和leader交流觉得很愉快。
相比较乘用车,特征车辆工况比较简单,没有复杂的交通博弈。此外,也没有量产控制成本的压力。因此,可以上目前比较成熟的基于激光雷达的L4自动驾驶方案。
三一目前,应该已经有车辆在矿区测试。目前在招人的是深圳的一个部门,是三一孵化的内部企业--海星智驾,未来有单独上市的可能。
- 曾用名:三一重工,海星智驾
- 入局时间:1994年10月
- 团队背景:--
- 自动驾驶等级:L4
- 代表产品:无人矿卡
- 融资情况:已上市
- 推荐评分:7.7
5. 零部件企业,自研部分技术
常见的自动驾驶硬件包括计算芯片,光学摄像头,激光雷达,毫米波雷达等。这类企业在发展自身业务的同时也在积累自动驾驶技术。一方面可以提高产品的毛利率,另外也可以提高产品的核心竞争力。
对于求职者来说,零部件企业更关注某些特定领域的知识积累。比如地平线的面试中可能要考察计算加速、前向推理部署等问题。在准备面试的时候要有所针对。
地平线
入职Tips:地平线刚开始的定位是一家人工智能芯片公司,公司的创始人余凯来自百度。在那个风起云涌的人工智能创业时代,地平线的发展可谓高开低走。站在2022年这个时间点上来看,大规模量产的芯片也较少。早期地平线为了给自己的芯片增加更多的应用场景,慢慢的开始在芯片上集成人脸相关的应用,诸如DMS等系统,后来也遇到了一些困难。
在19年末的时候进行了一次大裁员,尤其是南京这边的研究院裁撤比例较大。借着自动驾驶的浪潮,投入了自动驾驶芯片和算法的研发。目前看来,有部分新势力车企已经把地平线的自动驾驶芯片安排上了(比如零度等)。但是实话实话,和英伟达的芯片和算法相比还有很大的差距。量产上路的效果目前还没有太多的反馈。
依托行业领先的软硬结合产品,地平线向行业客户提供"芯片 + 算法 + 云"的完整解决方案。在智能驾驶领域,地平线同全球四大汽车市场(美国、德国、日本和中国)的业务联系不断加深,目前已赋能合作伙伴包括奥迪、博世、长安、比亚迪、上汽 、广汽等国内外的顶级 Tier1s ,OEMs 厂商;而在 AIoT 领域,地平线携手合作伙伴已赋能多个国家级开发区、国内一线制造企业、现代购物中心及知名品牌店
- 曾用名:地平线
- 入局时间:2017
- 团队背景:百度余凯
- 自动驾驶等级:L2,L3, L4, L5
- 代表产品:征程3,征程5
- 融资情况:C 轮
- 推荐评分:8.2
禾赛
入职Tips:禾赛虽然是一家专注激光雷达研发的企业,但是在自动驾驶领域也在进行技术积累。在自动驾驶现有的算法体系中,基于激光雷达的环境感知是实现L4的必由之路。禾赛目前的激光雷达以成本和稳定性等优势逐渐进入整车企业的供应链中。完善自己的软件,形成软硬一体的产品,会进一步拓宽盈利空间,另外也会增加产品的竞争力。目前禾赛在辅助驾驶和自动驾驶上都有涉及,在辅助驾驶中更多是要突出固态激光雷达的成本优势。而在L4级别的自动驾驶上,更多的应该是发挥机械激光雷达的感知优势。
- 曾用名:禾赛,hesai
- 入局时间:2014
- 团队背景:内部孵化
- 自动驾驶等级:L2,L3,L4,L5
- 代表产品:激光雷达,固态激光雷达,机械激光雷达
- 融资情况:D+ 轮
- 推荐评分:7.6
四维图新
入职Tips:四维图新是中国导航地图产业的开拓者。高精地图对自动驾驶的重要性不言而喻,目前国内的TOP3之一就有四维图新,高精地图的产业涉及面也非常的广,无论采集,标注,使用都还没有形成通用的标准。是自动驾驶细分技术领域的朝阳产业。
目前四维图新已成为导航地图、导航软件、动态交通信息、位置大数据、以及乘用车和商用车定制化车联网解决方案领域的领导者。如今,四维图新以全面的技术发展战略迎接汽车"新四化"时代的来临,致力于以高精度地图、高精度定位、云服务平台、以及应用于ADAS和自动驾驶的车规级芯片等核心业务。
- 曾用名:四维图新
- 入局时间:2002年
- 团队背景:内部孵化
- 自动驾驶等级:L4,L5
- 代表产品:--
- 融资情况:B轮数亿
- 推荐评分:7.6
寒武纪(自动驾驶芯片)
入职Tips:寒武纪在芯片领域有十余年的积累,目前也在涉足自动驾驶领域。我想初衷和地平线类似,都想给自己的芯片找一个应用的出口,而火热的自动驾驶恰恰满足了这个要求。但是进入时间稍晚,目前芯片也还没有量产,自动驾驶软件还没有路测的相关新闻。
公司的使命是打造各类智能云服务器、智能终端以及智能机器人的核心处理器芯片,让机器更好地理解和服务人类。公司创始人、执行官陈天石博士,在处理器架构和人工智能领域深耕十余年,是国内外学术界享有盛誉的杰出青年科学家,曾获国家自然科学基金委员会"优青"、CCF-Intel青年学者奖、中国计算机学会优秀博士论文奖等荣誉。公司骨干成员均毕业于国内外名校,具有丰富的芯片设计开发经验和人工智能研究经验,从事相关领域研发的平均时间达九年以上。公司在2016年推出的"寒武纪 1A"处理器是世界终端人工智能专用处理器,已应用于数千万智能手机中,入选了第三届世界互联网大会评选的十五项"世界互联网科技成果"。公司在2018年推出的MLU100机器学习处理器芯片,运行主流智能算法时性能功耗比全面超越CPU和GPU。目前,寒武纪已与智能产业的各大上下游企业建立了良好的合作关系。
- 曾用名:寒武纪
- 入局时间:2020
- 团队背景:内部孵化
- 自动驾驶等级:L2
- 代表产品:SD5223(年中)
- 融资情况:已上市
- 推荐评分:7.6
欧菲车联
入职Tips:欧菲车联在自动驾驶领域主要的硬件产品是摄像头,此外在激光雷达等传感器硬件上也有所布局。从主营业务出发,欧菲车联也在进行感知算法等自动驾驶模块的开发和研究。
- 曾用名:欧菲车联,欧菲智联,欧菲智
- 入局时间:2015
- 团队背景:内部孵化
- 自动驾驶等级:L2
- 代表产品:SD5223(年中)
- 融资情况:已上市
- 推荐评分:7.6
速腾聚创
入职Tips:主要业务是激光雷达,包括固态激光雷达和机械机关雷达。产品已经进入了很多车场的供应体系。目前,除了自动驾驶感知的硬件,也在积极的部署自动驾驶相关的软件。
(速腾聚创)是全球领先的智能激光雷达系统(Smart LiDAR Sensor System)科技企业。RoboSense通过激光雷达硬件、AI算法与芯片三大核心技术闭环,为市场提供具有信息理解能力的智能激光雷达系统,颠覆传统激光雷达硬件纯信息收集的定义,赋予机器人和车辆超越人类眼睛的感知能力,守护智能驾驶的安全。
RoboSense总部位于深圳,在北京、上海、苏州、斯图加特(德国)和硅谷(美国)等地设有分支机构。RoboSense在全球拥有500+名员工,来自全球顶尖企业和科研机构的人才团队,为RoboSense提供源源不断的创新能力。截止2021年,RoboSense获得超过500项专利。
- 曾用名:RoboSense,速腾聚创
- 入局时间:2015
- 团队背景:内部孵化
- 自动驾驶等级:L2
- 代表产品:固态、机械激光雷达
- 融资情况:D
- 推荐评分:7.6
6. 研究机构
上海人工智能实验室
入职Tips:上海人工智能实验室是国内为数不多的研究性实验室。最近这两年,在自动驾驶领域,产出了很多优秀的论文和算法。促进了中国本土自动驾驶技术的研究。研发能力非常强大。
上海人工智能实验室是我国人工智能领域的新型科研机构,于2020年7月在世界人工智能大会正式揭牌。实验室开展战略性、原创性、前瞻性的科学研究与技术攻关,突破人工智能的重要基础理论和关键核心技术,打造"突破型、引领型、平台型"一体化的大型综合性研究基地,支撑我国人工智能产业实现跨越式发展,目标建成国际一流的人工智能实验室,成为享誉全球的人工智能原创理论和技术的策源地。实验室牵头科学家团队由汤晓鸥、姚期智、陈杰等人工智能领域全球顶尖学者组成。
- 曾用名:上海人工智能实验室
- 入局时间:2020
- 团队背景:汤晓鸥、姚期智、陈杰等巨佬
- 自动驾驶等级:L2,L3,L4,L5
- 代表产品:
- 融资情况:D
- 推荐评分:7.6
#自动驾驶标定技术
最近有朋友问到是否用overlay标定完后数据就直接在Flash中,其实不然,是需要关闭overlay然后通过XCP Program指令集或者UDS刷进Flash。
从这里看出,之前文章对于标定的描述还是不够细致,导致出现了误会,因此这里再详细分析一下标定的概念。如有错误,请大家指正。
我们知道,标定参数(即Parameter)实际上对于ECU的控制算法来说是一个常数,最简单的例子,油门踏板开度影响喷油量,假设算法为y= ax+b。要在某个固定踏板开度(x)达到我们预期喷油量(y),要反复调整的只能是常数a和b。
因此,所谓参数的标定,就是通过技术手段保证在ECU的开发阶段能够调整paremeter的值。那么我们就来看看有哪些技术手段可以实现参数的调整。
Flash中的标定参数
我们在开发的时候,对于常数其实会用修饰符进行限定的,如下:
const uint32 Parameter_A = 1;
在进行编译链接之后,编译器会把这个Parameter_A分配到Flash的区间(链接文件里的ROM段)并给定一个地址(通过Map文件可以查找),同时也从编译出来的hex的地址去找到这个值 1,如下图所示:
那么要修改这些参数,应该怎么办呢?有两个办法:
- 通过在源码中修改常数值,重新进行编译,然后刷进ECU里。这样很麻烦,遇到稍微大一点的工程,编译都得十几二十分钟,很显然这种方法是不符合现在的开发流程的。
- 通过FlashDriver对存放Paremeter_A的Flash空间进行重编程,这种方式比上述重新编译要好一点,但是还是实时性不够,并且目前的FLash特性是没有办法按照Byte进行擦除的,意味着要修改一个标定参数就必须擦掉整个Sector,重新刷写所有的标定参数,这显然是不可接受的。当然,如果ECU外挂的EEPROM,那么就不会存在这个问题了,但是访问速度和相应的开发成本也是阻碍参数的实时标定。
另外,还需要提一点的就是,如果编译器优化等级开的比较高,作为常量的Parameter_A有可能会被优化,直接作为一个数值出现嵌入到代码中,而不会出现在map文件里。因此我们在定义标定参数这种类型常量时,通常会按照如下定义:
volatile const uint32 Parameter_A = 1;
volatile可以有效防止被编译器优化 ;
此外,为了方便管理和能迅速定位到标定参数,我们通常也会在链接文件里定义一块单独的空间,在代码里使用#pragma把参数放到该空间里,如下:
#pragma section "Cal_Flash"
const uint32 Parameter_A = 1;
这里我们简单讲了标定参数只在Flash里的时候应该如何修改,实际上这种方式并不能支持我们在ECU运行过程中动态修改
所以,我们能不能想个办法把这些参数搬到一段RAM中,在RAM里实时修改,修改完成后再把标好的参数重新刷进Flash。
显然这个想法是成立的。
RAM中的标定参数
我们定义一个带初值的变量,如下图:
uint32 Parameter_A = 1;
编译器会给这个参数分配RAM空间地址,并且初值存放在Flash中。我做过一个试验,用英飞凌TC2xx系列,在不修改链接文件的情况下,编译器给标定参数分配一个RAM地址,但实际上存在Flash里,如下图:
这是怎么实现的呢?我们查看链接文件关于.data段的定义:
这行代码的含义就是加载运行在RAM(DSPR),但是初值存放在PFlash,上电时启动代码会将Flash中的值拷贝到RAM里。
控制算法去获取Parameter_A的值也是从RAM去拿值的,所以这种情况我们就可以在ECU运行过程中动态修改标定参数的值。
这个时候还不是完全体,通常我习惯是拿出一段单独的Flash空间方便标定数据的管理,借鉴上面链接文件的修改,就可以在RAM和Flash单独定义一块空间专门给标定使用,因此在链接文件里有了如下定义:
#pragma section "calDataOvc"
const uint32 Parameter_A = 1;
但是这样又有一个问题,因为标定数据的地址是RAM地址,那么使用标定上位机导出的标定数据hex文件还是RAM的空间。
这个时候我们想要把标定数据刷到Flash,还需要对hex文件做一个地址的偏移,最后通过UDS或者XCP自带编程指令集进行刷写。
这也比较麻烦,所以英飞凌、NXP均针对这个问题实现了memory overlay的功能。
AUTOSAR基于指针标定概念
在AUTOSAR RTE的SWS里,明确提出来标定和测量功能的支持,如下图:
在XCP文档里提出来基于指针标定的概念,其具体实现形式如下:
标定参数的访问地址和数据大小在启动阶段被收集到Pointer Table,最开始均是该Table中收集到的均是参数的Flash地址,并且通过软件给Flash里的参数分配RAM地址,但是此时RAM还是没有内容填充的。
注意,这个时候A2L文件里面标定量的地址为Flash地址,当它下发一个download命令后,在XCP Slave这一层首先会检查当前处于WP还是RP,如果是WP,那么此时就Pointer Table就选择使用该标定量对应的RAM地址(对用户不可见),然后进行填充,此时算法获取标定量就通过RAM,从而实现了标定动态修改参数的功能,如下:
这个方案的提出就是为了解决某些标定软件在A2L文件里只识别Flash地址的参数,但是确定很明显:多了一个Pointer Table增加了RAM消耗,同时为了防止内存泄露,本身装标定量的RAM空间也是需要空出来的。
目前,我还没有使用过这种方式。
小结
本文主要梳理了标定的概念,目前使用的比较多的还是基于RAM的标定,同时只要芯片支持overlay(Flash emulation),上位机可以直接使用标定参数的flash地址,在MCU内部硬件自动进行地址重映射,需要注意的是,即使使用Overlay功能,标定参数的修改始终针对是RAM里的值,如果想要固化到Flash里面,有两种方式:
- 上位机通过XCP 编程指令集进行刷写,ECU端需要关闭Overlay,保证访问的是Flash。CANape方便一点,INCA的话还需要自制ProF文件
- 通过上位机将标定数据导出为Hex,通过UDS直接刷写进Flash。