-
本篇文章用于记录从各处收集到的o1复现方案的推测以及介绍
目录
-
- [Journey Learning - 上海交通大学+NYU+MBZUAI+GAIR](#Journey Learning - 上海交通大学+NYU+MBZUAI+GAIR)
- [A Tutorial on LLM Reasoning: Relevant methods behind ChatGPT o1 - UCL汪军教授](#A Tutorial on LLM Reasoning: Relevant methods behind ChatGPT o1 - UCL汪军教授)
-
- [Core Idea](#Core Idea)
- 先导
- 自回归LLM面临的挑战
- 将LLM推理看作是马尔科夫决策过程
- 实现方法
- [Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning](#Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning)
-
- [Core Idea](#Core Idea)
-
Journey Learning - 上海交通大学+NYU+MBZUAI+GAIR
- github:https://github.com/GAIR-NLP/O1-Journey#about-the-team
- paper: https://github.com/GAIR-NLP/O1-Journey/blob/main/resource/report.pdf
Core Idea
- "Journey Learning," was proposed to teach models to learn through trial and error rather than shortcuts

Key Questions
- o1的思维链有哪些特征:
- 迭代式
- 关键思维方式:结论、路径、反思、计算
- 递归与反思:经常评估与验证中间结果
- 假设探索
- 结论与验证
- 思维链如何工作?
- 团队给出了自己的猜测
- 如何构建长思维链?(本质上是数据集构建方法 )
- 尝试1:基于 LLM 和奖励的树搜索
- 反思回溯 (要求有) 推理树 (需要) 细粒度的奖励模型
- 尝试2:提议 - 批评循环
- 为模型预定义了一些可能的行为(即继续、回溯、反思、终止),并让模型自身选择行为来构建推理树
- 如果树没有达到最终答案,可以将这个负面信号告知模型,引导它反思和纠正其方法
- 尝试3:多智能体方法
- 挑战:基于推理树构建长思维存在许多冗余的无效节点,以及存在不依赖于反思行为的推理步骤,从而引起构建的长思维逻辑不一致
- 多智能体辩论的算法:其中一个智能体充当策略模型,持续推理,而另一个智能体充当评论模型,指示策略模型是否应该继续当前推理或执行回溯等行为。两个智能体进行持续对话,在找到正确答案时自然构建长思维数据集
- 完整的人类思维过程注释:通过记录人类思维过程产生高质量的思维链数据
- 尝试1:基于 LLM 和奖励的树搜索
- 如何构建奖励模型?
- 团队将评估粒度定义在步骤层面
- 如何构建on-policy推理树?
- 如何从推理树中导出长思维链?
- 如何进行评估?
- 如何训练?
- 什么是人类和 AI 协同标注的有效策略?
Key Technologies
- Multi-Agent Debate System
- 包含两个Agents
- Agent#1: 生成推理步骤
- Agent#2: 评价Agent#1生成的推理步骤
- 包含两个Agents
- Reasoning Trees
- 用于表示整个思维过程
- Reward Models Design
- 用于对reasoning tree中的每一个步骤进行评价
Training
- Stage#1: Supervised Fine-Tuning(SFT)
- Phase#1: short-cut reasoning data
- Phase#2: journey learning data
- Stage#2: Direct Preference Optimization(DPO)
- 一次性生成多个回答,学习如何判断回答的正确性与有效性
Inference
- Stage#1: Reasoning Tree Construction
- 构建思维树
- Stage#2: Traversal and Output
- 采用深度优先的方式(DFS)进行推理
A Tutorial on LLM Reasoning: Relevant methods behind ChatGPT o1 - UCL汪军教授
Core Idea
- o1 的训练使用了强化学习技术,通过显式地嵌入一个**原生「思维链」(NCoT)**过程,可出色地完成复杂的推理任务
- 范式转变 :从快速、直接的反应转向缓慢、深思熟虑、多步骤的推理时间计算

- 疑问与思考:不同的研究者对快慢推理有着很不一样的理解,例如汪教授认为原来的direct autoregressive model就是快推理;而部分研究者从模型的角度进行划分,大模型是慢推理,小模型是快推理
先导
- 思维链方案能够提升大语言模型的执行能力并不是才出现(COT,TOT等);同时,你也可以通过简单的prompt使(o1前)时代的LLM输出思维过程,从而提升整体表现
- 这些方法都基于已有的 LLM,并没有将思维链嵌入到模型本身之中。因此,LLM 无法内化这种学习能力
- 之前人们提出的方法包括收集专门的训练数据 、构建奖励模型 和增加解码的计算复杂度,但目前还没有一种方法能大规模地在性能上取得重大突破
- 注意:由于OpenAI不再Open,汪军教授表示,我们目前尚不清楚 OpenAI 的 o1 创新是否植根于模型本身,还是依然依赖于外部提示系统。如果它确实涉及在架构中明确嵌入分步推理,那么这将是一个重大突破
- OpenAI表示:"传统上在训练期间应用的扩展原则现在也与推理阶段相关了"
- 算力(重心)逐渐向推理过度
- 如果LLM能够在推理过程中提升自己的能力,那么就是向**自我改进式智能体(self-improving agent)**迈出的重要一步
- 汪军教授表示:这个研究方向暂且称为 LLM 原生思维链(LLM-Native Chain-of-Thought/NativeCoT),其应当能够固有地反映人类系统2思维所具有的深思熟虑的分析过程。
自回归LLM面临的挑战
- 自回归LLM以预测下一个token为目标
- 汪军教授表示,仅仅专注于预测下一个词会限制智能的潜力。为了得到更深层次的智能,可能需要不同的优化目标和学习范式
- 如何使系统超越其训练数据的界限并开发出新颖的、可能更优的策略?
- 汪军教授:如果使用数据来开发更深度的理解或世界模型,就有可能实现复杂策略的演进,进而超越训练数据的限制
- 世界模型(World Model)
- 代表了智能体对环境的理解
- 基于模型的策略(如蒙特卡洛树搜索 (MCTS))是这种方法的经典例证。向系统 2 型推理的过渡(o1 可能就是一个例证)依赖于建立某种类型的世界模型并利用强化学习(奖励最大化),而不仅仅是最小化预测误差。这种方法的转变可能是 OpenAI o1 强大推理能力背后的关键过渡技术之一
- 通过将 LLM 的预测能力与强化学习和世界建模的策略深度相结合,像 o1 这样的 AI 系统可以解决更复杂的问题和实现更复杂的决策过程。这种混合方法既可以实现快速模式识别(类似于系统 1 思维),也可以实现深思熟虑的逐步推理(系统 2 思维的特征)。
- 巨大的计算复杂性
- LLM 运行时受到二次计算复杂性的约束(Transformer架构)。当 LLM 遇到多步数学难题时,这种约束会变得尤为明显
- 思维链却有望减轻这一限制
- 尽管该方法颇具潜力,但它仍然不是一个完全动态的内存系统,并且没有原生地融入解码阶段。这种必要性使得研究社区亟需超越当前 Transformer 解码器网络能力的高级计算架构。
- 需求:在推理和解码阶段实现类似于蒙特卡洛树搜索 (MCTS)的基于模型的复杂策略。
- 这种先进的推理时间计算系统将使 AI 模型能够维护和动态更新问题空间的表征,从而促进更复杂的推理过程(汪军教授这里提到了Working Memory这个概念)
将LLM推理看作是马尔科夫决策过程
- 为了建模问答或问题解答等任务中的推理过程,这里将推理的结构调整成 Q → {R} → A 序列的形式
- Q:表示启动推理过程的问题或提示词;
- R:表示为了得到解答,模型生成的中间推理步骤的序列;
- A:表示推理步骤完成后得到的最终答案或解。
- 汪军教授表示,可以将该推理过程定义为一个马尔可夫决策过程(MDP)
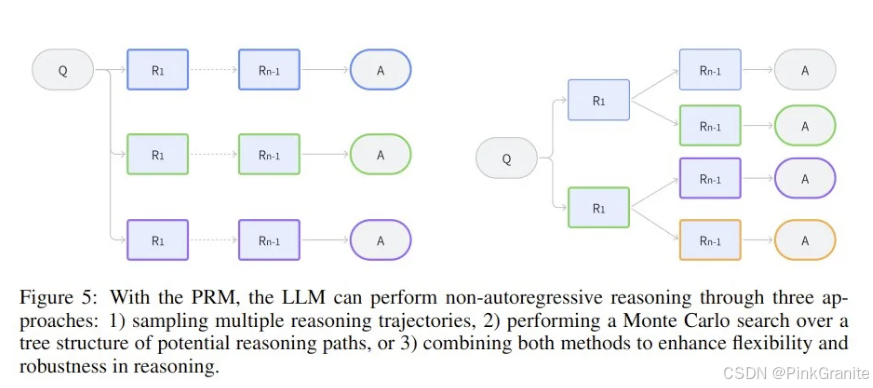
- MDP 能为建模推理提供一个灵活的框架。它允许模型自回归地生成迈向最终答案的顺序推理步骤,同时还通过在每个步骤采样多条路径来实现树结构以获得备选推理轨迹。
- 现在可以使用状态、动作、策略和奖励 来描述这个推理过程了。其中 LLM 的任务是逐步生成与推理步骤和最终答案相对应的连贯 token 序列 。

- 思考:
- 这里可以的动作空间只有两个:选择新推理步骤、结束推理(得到final answer)
- 反思在这里没有具体的体现,但带着新的信息回到原来的推理节点是否同样可以被看作是生成新的推理节点?
- 汪军教授有明确的提到树结构,如何在这里得到体现------State相同
- 是否可以认为:旅行推理对State进行了结构化的定义,而汪军教授提出的方法是一种更加宏观的方法------二者是否具有一致性?

- 过程奖励模型(Process Reward Model, PRM)是一种基于强化学习的模型,专注于对中间步骤或过程的质量进行评估和奖励,而不仅仅是对最终结果进行评分。它的目标是鼓励系统在任务的每个步骤中都做出合理和高质量的决策,从而提高整个任务执行的效率和效果。
- 优势:
- 细粒度反馈:相较于传统的结果奖励模型,针对执行过程提供持续的反馈
- 加快学习速度:更早地提供奖励信号
- 稳定性更高:能过缓解仅依赖最终奖励导致的奖励稀疏问题,减少陷入局部最优解的风险
实现方法
- 核心步骤
*- 收集中间推理数据
-
- 训练过程奖励模型PRM
-
- 利用PRM来训练LLM
-
- 在解码阶段引导推理过程
- 自动获取推理步骤数据
- Self-Taught Reasoner (STaR): 一种无需人类监督,有效的收集数据和提升 LLM 推理的方法
- "The STaR (Self-Taught Reasoner) method is a technique used to improve the reasoning capabilities of language models. It works by having the model generate intermediate reasoning steps (called rationales) for given problems, which helps it learn how to solve more complex tasks. Initially, the model is trained to solve problems and generate reasoning steps. If it fails, it reviews its own rationales, refines them, and learns from the corrected version. This iterative process helps improve the accuracy and reliability of the model's reasoning abilities over time."

- 要求:1. LLM有能力生成中间步骤;2. LLM能够通过自己的策略验证正确性
- 收集到的 {Q, {R}, A} 就可进一步用于训练策略 π_LLM,提升有效推理步骤的生成过程
- 当推理序列较长时,还会用到蒙特卡洛树搜索(MCTS)
- Self-Taught Reasoner (STaR): 一种无需人类监督,有效的收集数据和提升 LLM 推理的方法
- 自我增强式训练

- 在训练时:LLM基于policy进行生成;PRM进行评价
- Stage1: PRM价值迭代 :训练世界模型------过程奖励模型(PRM)
- 目标:构建引导搜索、推理和解码过程的通用奖励模型------通常被称为验证器vPRM
- 训练方式一 :使用有标注的推理步骤数据集 进行训练。其训练通常涉及根据推理步骤的正确性优化一个分类损失函数
- 训练方式二 :将PRM视为一个可迭代价值函数(贝尔安方程-递归关系)------预测累积奖励,通过选择最佳动作指导推理过程
- 目标:学习一个由 θ \theta θ参数化的价值函数 V θ ( s ) V_\theta(s) Vθ(s),其中 s s s是当前的状态,用于预测从状态 s s s开始的预期累积奖励

- 其中 r ( s ) r(s) r(s)是奖励函数,根据中间推理步骤或最终答案的正确性为状态s分配一个标量奖励, γ \gamma γ是折扣因子,决定了未来奖励的相对重要性
- 疑问:这里的 a a a表示动作空间,LLM的动作本身只有一个"Text generation",在这种情况下是否意味着该方法同样需要划分明确的动作空间,是否可以理解为这里是对世界模型的特殊定义------包含反思、推理、计算等"动作"?
- 为了学习 θ \theta θ,TD(时序差分)损失函数定义为:
- Stage 2: LLM的策略迭代
- 分组相对策略优化(Group Relative Policy Optimization - GPRO)
- 假设对于每个问题 Q = q,策略都会生成推理步骤 { o 1 , o 2 , . . . , o G } \{o_1, o_2, . . . , o_G\} {o1,o2,...,oG},每个输出 o i o_i oi由多个步骤 { a i , 1 , a i , 2 , . . . , a i , K i } \{a_{i,1}, a_{i,2}, . . . , a_{i,Ki} \} {ai,1,ai,2,...,ai,Ki} 组成,其中 K i K_i Ki 是输出 o i o_i oi 中的推理步骤(或 token)总数
- 优化策略:

- GRPO 没有将 K L KL KL 惩罚直接纳入奖励,其规范策略的方式是将当前策略 π θ π_θ πθ 和参考策略 π θ r e f π_{θ_{ref}} πθref 之间的 K L KL KL 散度直接添加到损失函数中。这可确保更新后的策略在训练期间不会过度偏离参考策略,从而有助于保持稳定性
- 这种 GRPO 形式是通过利用推理步骤和最终步骤中的分组相对奖励来优化 LLM 策略,专门适用于通过过程奖励模型的推理任务
- 归一化的优势函数(advantage function)是根据相对性能计算的,鼓励策略偏向在一组采样输出中表现更好的输出
- K L KL KL 正则化可确保更新后的策略与参考策略保持接近,从而提高训练稳定性和效率
- 其他策略:token-level DPO (direct preference optimization)------ Token-level direct preference optimization ------ 一种区别于RLHF的LLM训练方法
- 分组相对策略优化(Group Relative Policy Optimization - GPRO)
- Stage 3: 推理优化
- LLM 常用的方法是自回归,即根据之前的 token 逐一生成新 token。但是,对于推理任务,还必需更复杂的解码技术
- 使用 MCTS 模型
- MCTS 可模拟多条推理路径,并根据奖励系统对其进行评估,选择预期奖励最高的路径。这允许模型在推理过程中探索更大范围的可能性,从而增加其获得最优解的机会
- 使用 MDP对推理过程结构进行定义
- 原生思维链(Native Chain-of-Thought - NCoT)
- 使LLM在无需外部提示词的情况下自动执行逐步式的结构化推理
- 该能力可以表述为一个马尔可夫决策过程(MDP) ( S , A , π , R ) (S, A, π, R) (S,A,π,R)
- S S S 是状态空间,表示生成到给定位置处的 token 序列或推理步骤
- A A A 是动作空间,由潜在推理步骤 R t R_t Rt 或最终答案 A A A 组成
- π L L M ( a t ∣ s t ) π_{LLM (a_t | s_t)} πLLM(at∣st) 是控制动作选择的策略(也是LLM ------ 多LLM ),其可根据当前状态 s t s_t st 确定下一个推理步骤或最终答案
- R ( s t a t ) R (s_t a_t) R(stat) 是过程奖励模型(PRM,其作用是根据所选动作 a t a_t at 的质量和相关性分配奖励 r t r_t rt,以引导推理过程
- 该模型既可以通过展开 MDP 来遵循顺序推理路径,也可以通过在每个状态下采样不同的推理步骤来探索多个轨迹(树状推理)


Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Core Idea
- Structured Reasoning Framework: Pangu-Agent引入了内在和外在函数,将先验知识整合到感知-行动循环中,允许智能体将结构化推理纳入其学习过程。内在功能作用于内部记忆,而外在功能则与环境相互作用 。
- 内在函数 是修改代理的内部状态或记忆的操作。
- Thinking:基于过去的经验或观察,对某一情况产生高层次的思考
- Planning:组织步骤以有效地解决问题
- Reflection:评估过去的行动,为未来的决策提供信息
- Tool Use:利用诸如代码解释器之类的工具来帮助代理改进其推理
- Communication:与其他代理相互作用,进行合作决策
- 外在功能与主体与外部环境的相互作用直接相关。
- 内在函数 是修改代理的内部状态或记忆的操作。
- Modularity and Flexibility: 该框架允许人工智能代理通过监督微调和强化学习微调模块化地适应多个任务。该体系结构旨在创建能够跨各种环境进行交互的通才代理,通过结构化推理提高其性能和适应性。
- Supervised fine-tuning (SFT)
- Reinforcement learning fine-tuning (RLFT)
- Improved AI Agent Performance: 实验表明,结构化推理和微调的使用显著提高了人工智能智能体的适应性和泛化性。得益于结构化的模块化功能和内存管理,代理能够跨各种任务实现更高的成功率。