一、概述
最近客户给了几台GPU服务器,长期放置落灰那种,然后想利用起来,所以上去看看了配置,系统是Ubuntu20.04,相关的驱动版本稍嫌老一些,所以需要更新Nvidia驱动,同时在安装CUDA和CUDNN,查看了显卡型号之后,打算使用onnxruntime进行推理,对比了版本,最后选择了CUDA12.1 + CUDNN8.9.7。
二、下载CUDA
开始准备更新,首先下载CUDA,包含了550版本驱动的,是直接在服务器上下载的。
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda_12.1.0_530.30.02_linux.run然后又再本地下载了cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz,然后上传到服务器上去了。https://developer.nvidia.com/rdp/cudnn-archive
三、卸载旧驱动
1、卸载驱动
首先可以查看电脑上的所有驱动,其实看不看也无所谓。
sudo dpkg --list | grep nvidia-*但是建议先卸载,如果之前的驱动有卸载程序,可以直接使用,个人感觉卸载的会干净一些。
sudo /usr/bin/nvidia-uninstall直接安装的话,可能会有类似提示
The package that is already installed is named nvidia-455-455.
You can upgrade the driver by running:
`apt-get install nvidia-455-455`
You can remove nvidia-455-455, and all related packages, by running:
`apt-get remove --purge nvidia-455`
`apt-get autoremove`如果之前的旧驱动程序没有对应的卸载程序,可以使用下面的命令卸载旧驱动。
sudo apt-get --purge remove nvidia-*
sudo apt-get purge nvidia*
sudo apt-get purge libnvidia*
卸载所有自动安装且不再使用的软件包
sudo apt autoremove过程中仔细看最后输出的日志,如果有类型的autoremove等,按照提示执行。
sudo apt autoremove nvidia-*上面卸载过程完成了,使用如下命令判断,是否卸载干净,没有nvidia相关的运行程序即可。
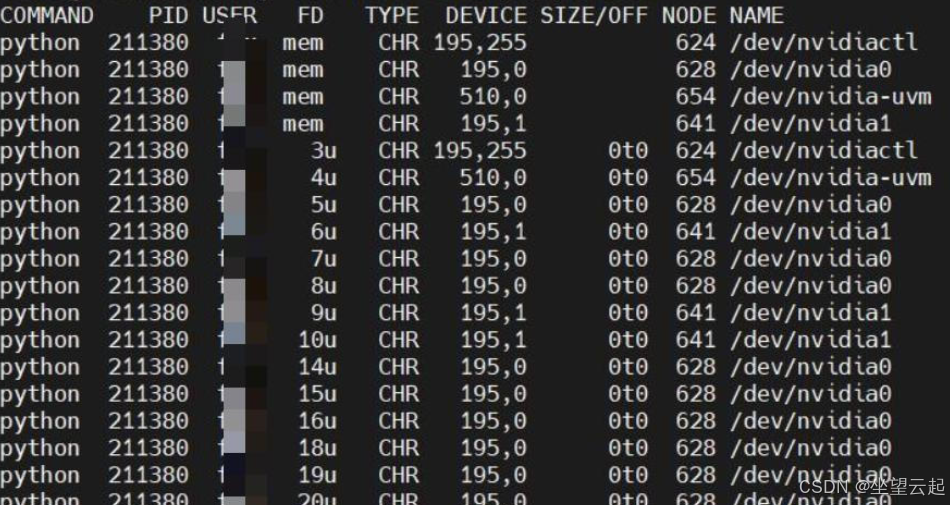
sudo dpkg --list | grep nvidia-*
sudo lsof -n -w /dev/nvidia*保证没有下图类似的东西在运行
2、安装CUDA和新驱动
建议先看下面可能遇到的问题,然后再安装。
安装驱动的命令为
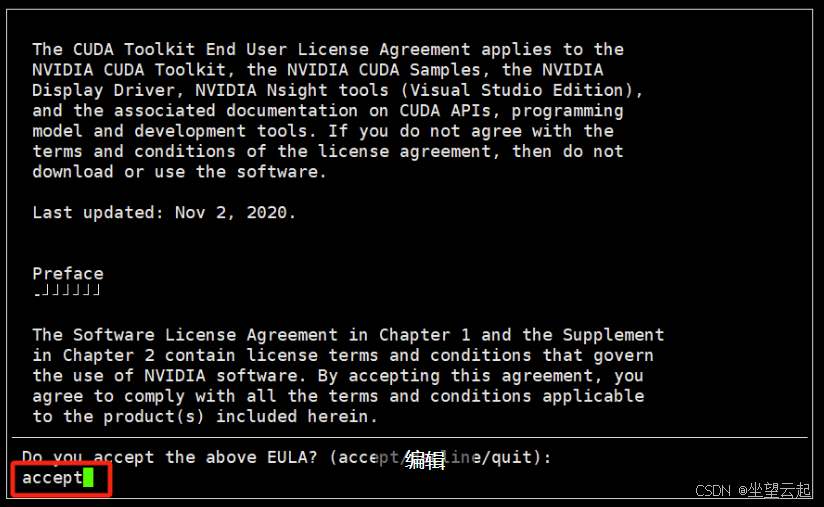
sudo sh cuda_12.1.0_530.30.02_linux.run系统首先会解压,然后出现一个界面,输入accept,然后回车
之后会让我们选择安装那些东西,我这个图片忘记截了,所有拿别人的图片顶一下,我这里要装这个驱动,选择好之后选择Install,回车,开始安装。
安装成功之后会大概显示这样的内容,如果安装失败可以查看两个日志,一个是/var/log/cuda-installer.log和/var/log/nvidia-installer.log这两个log查看安装失败的原因。

安装完成之后,运行nvidia-smi,可以看到驱动和cuda的版本。
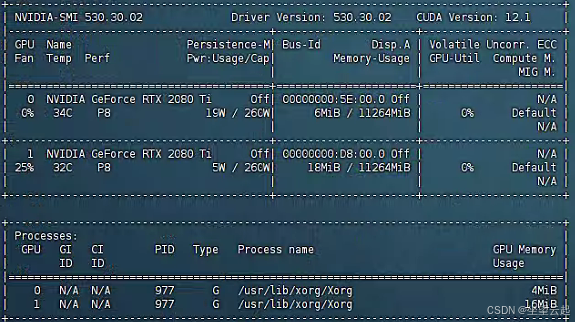
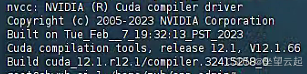
输入nvcc -V查看cuda版本
3、安装cudnn
上面我们上传到服务器了,找到它,先解压
tar -xvf cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz然后进入文件夹
cd cudnn-linux-x86_64-8.9.7.29_cuda12-archive然后copy文件到cuda的目录
sudo cp lib/* /usr/local/cuda-12.1/lib64/
sudo cp include/* /usr/local/cuda-12.1/include/之后执行一下权限,我测试好像不执行也没啥问题,记不清了。
sudo chmod a+r /usr/local/cuda-12.1/lib64/*
sudo chmod a+r /usr/local/cuda-12.1/include/*4、修改环境变量
输入如下指令查看PATH和LD_LIBRARY_PATH中环境变量
echo $PATH
echo $LD_LIBRARY_PATH查看有无添加上述两个环境变量,若无,则采用如下两种方法添加环境变量
1、直接运行export命令定义变量【只对当前shell(BASH)有效(临时的)】
export PATH=$PATH:/usr/local/cuda-12.1/bin
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64
2、在用户目录下的.bashrc文件中增加变量【(永久的)】
sudo vim ~/.bashrc
点i进入编辑模式,在最后一行输入
export PATH=$PATH:/usr/local/cuda-12.1/bin
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64
输入好了按Esc退出编辑模式,然后输入:wq 保存退出就好

保存好了之后注意,这个时候如果查看环境变量会发现还是没有添加好的,所以我们需要更新一下bashrc文件。更新指令如下:
source ~/.bashrc
查看cudnn版本
8.0以前的版本这样查看
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 28.0以后的版本这样看
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
5、安装中遇到的问题
如果安装失败,可以看/var/log/nvidia-installer.log里面的说明,会明确讲述为什么安装失败,的这几台表现都不同,我遇到了三种状况。
(1)可能会遇到nvidia-modeset服务始终无法杀死。
An NVIDIA kernel module 'nvidia-modeset' appears to already be loaded in your kernel. This may be because it is in use (for example, by an X server, a CUDA program, or the NVIDIA Persistence Daemon), but this may also happen if your kernel was configured without support for module unloading. Please be sure to exit any programs that may be using the GPU(s) before attempting to upgrade your driver. If no GPU-based programs are running, you know that your kernel supports module unloading, and you still receive this message, then an error may have occurred that has corrupted an NVIDIA kernel module's usage count, for which the simplest remedy is to reboot your computer.
ERROR: Installation has failed. Please see the file '/var/log/nvidia-installer.log' for details. You may find suggestions on fixing installation problems in the README available on the Linux driver download page at www.nvidia.com.解决的办法是看看有没有守护进程,先把守护进程杀掉,然后再找到sudo dpkg --list | grep nvidia-*这个命令下面运行的所有nvidia程序,都杀掉。
查看是否运行了守护进程
ps -ef | grep nvidia-persistenced(2)可能会遇到You appear to be running an X server; please exit X before installing.的问题。
解决的办法是关闭X Server
sudo systemctl stop gdm3
sudo systemctl stop display-manager.service(3)安装失败的时候,可能会遇到Nouveau kernel driver正在运行
(Answer: Continue installation)
ERROR: The Nouveau kernel driver is currently in use by your system. This driver is incompatible with the NVIDIA driver, and must be disabled before proceeding. Please consult the NVIDIA driver README and your Linux distribution's documentation for details on how to correctly disable the Nouveau kernel driver.
-> For some distributions, Nouveau can be disabled by adding a file in the modprobe configuration directory. Would you like nvidia-installer to attempt to create this modprobe file for you? (Answer: Yes)查看Nouveau的运行状态的命令参考下面nvidia的网址
解决办法是参考下面的链接,增加一些配置,禁用Nouveau的驱动,然后重启服务器,重启之后可能X Server又运行了,杀掉然后再次安装。
https://docs.nvidia.com/ai-enterprise/deployment/vmware/latest/nouveau.html
https://support.huawei.com/enterprise/zh/doc/EDOC1100164073/95d56075#ZH-CN_TOPIC_0283833529(4)安装过程都很顺利,但是使用onnx运行时,发现Failed to load library libonnxruntime_providers_cuda.so with error: libcublasLt.so.12:,这样的错误
Connection id "0HN7HGVUOQQI8", Request id "0HN7HGVUOQQI8:00000002": An unhandled exception was thrown by the application.
System.TypeInitializationException: The type initializer for 'AI.Inference.Api.Tools.InferenceTools' threw an exception.
---> Microsoft.ML.OnnxRuntime.OnnxRuntimeException: [ErrorCode:RuntimeException] /onnxruntime_src/onnxruntime/core/session/provider_bridge_ort.cc:1426 onnxruntime::Provider& onnxruntime::ProviderLibrary::Get() [ONNXRuntimeError] : 1 : FAIL : Failed to load library libonnxruntime_providers_cuda.so with error: libcublasLt.so.12: cannot open shared object file: No such file or directory我四台服务器,有两台出现这个问题,我都是使用sudo /usr/bin/nvidia-uninstall这个命令重新卸载又安装了一遍驱动和cuda,然后重启服务器,重启应用就好用了。
个人猜测还是之前没卸载干净导致,具体原因没有细究,毕竟不是专业的运维。暂时先记录到这里,下一篇介绍一下onnxruntime+ubuntu上的程序,不过是基于donet6.0的。