
用CPU玩那些大型的语言模型确实挺有意思的,但看着电脑一个字一个字地慢慢显示结果,那股兴奋劲儿很快就过去了。让这些语言模型软件在GPU上跑起来可能会有点麻烦,因为这得看你的系统和硬件支不支持。我这篇文章就是想告诉你,怎么在你的NVIDIA RTX 2060上跑起来llamafile这个软件。里面的例子会用到llamafile、NVIDIA CUDA、Ubuntu 22.04操作系统还有Docker这几个工具。

先检查一下你的GPU和NVIDIA CUDA软件
首先得确认一下你的CUDA装了没有。NVIDIA有个工具,能显示你的GPU和CUDA的状态。
% nvidia-smi
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.154.05 Driver Version: 535.154.05 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 2060 Off | 00000000:01:00.0 On | N/A |
| N/A 44C P8 8W / 90W | 1322MiB / 6144MiB | 6% Default |
| | | N/A |
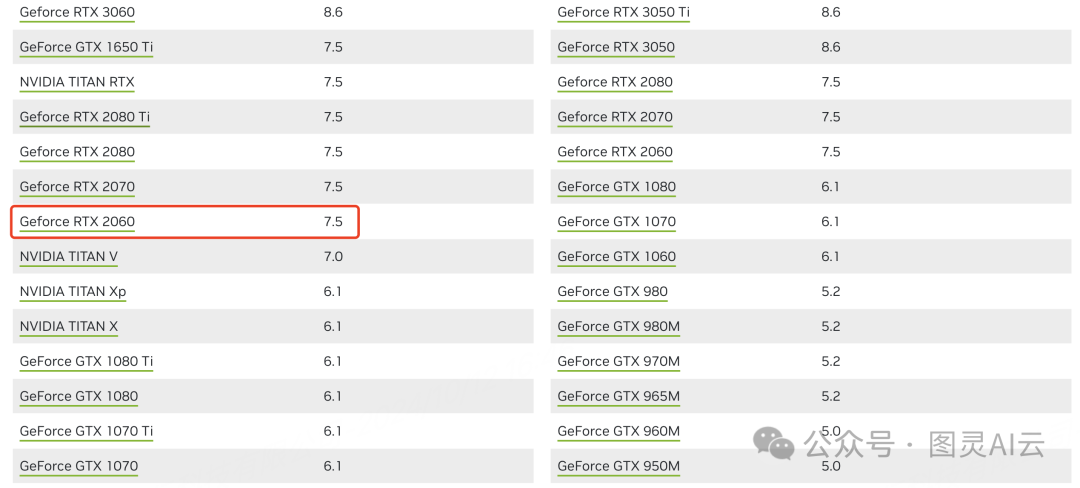
+-----------------------------------------+----------------------+----------------------+如果你看到的输出和这个差不多,那就说明你的CUDA已经装好了。别忘了看一眼CUDA的版本号。这个版本号还有你的显卡的计算能力,会决定你构建镜像时得用哪个基础镜像。NVIDIA有提供一张图表(https://developer.nvidia.com/cuda-gpus#compute),上面列出了他们家各种设备的计算能力。你可以根据你的设备型号去查对应的菜单选项。比如说,你要是用的RTX 2060这款显卡,就在图表里找到它对应的那一项。
配置Docker
NVIDIA Container Toolkit这个工具能让Docker用上GPU的能力。NVIDIA也给出了安装Container Toolkit的详细指南。但如果你等不及想看简化版的,我这就来给你说说简化后的步骤。
% distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
% sudo apt-get update
% sudo apt-get install -y nvidia-docker2在Linux系统里,你得更新这个文件/etc/docker/daemon.json来设置Docker Engine后台服务,并且把NVIDIA的容器运行时加进去。要是你的系统里没有daemon.json这个文件呢,你就新建一个,内容大概是这样的:
{
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}这样设置好之后,重启Docker以应用更改。你的Docker就能用上NVIDIA的GPU加速功能了。
% sudo systemctl restart docker测试运行时是否工作。
% $ docker run --rm --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi如果工作正常,你应该看到类似的结果。
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.154.05 Driver Version: 535.154.05 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 2060 Off | 00000000:01:00.0 On | N/A |
| N/A 44C P8 10W / 90W | 1530MiB / 6144MiB | 6% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+来聊聊怎么构建Llamafile的镜像吧
咱们得一步步来分析这个Dockerfile。我会详细解释我做每个选择的原因。Dockerfile用的是多阶段构建的方法,咱们先从编译llamafile的二进制文件开始说起。
FROM debian:trixie as builder
WORKDIR /download
RUN mkdir out && \
apt-get update && \
apt-get install -y curl git gcc make && \
git clone https://github.com/Mozilla-Ocho/llamafile.git && \
curl -L -o ./unzip https://cosmo.zip/pub/cosmos/bin/unzip && \
chmod 755 unzip && mv unzip /usr/local/bin && \
cd llamafile && make -j8 && \
make install PREFIX=/download/out这段Dockerfile是用来编译llamafile的二进制文件的。就像很多开源项目一样,llamafile非常活跃,几乎每周都有新功能更新和bug修复。所以我选择从源代码来编译llamafile,而不是直接用现成的二进制文件。另外,llamafile还能被编译成一个包含模型的单个可执行文件,但为了保持简单,我就没包括这一步。
接下来,多阶段构建的下一步是创建一个运行llamafile的镜像,这个镜像会用到主机上的GPU。NVIDIA提供了适合像llamafile这种GPU应用的CUDA基础镜像。前面我们记下了CUDA的版本和驱动程序的版本,NVIDIA也特别指出了:
"为了运行CUDA应用程序,系统应该具有支持CUDA的GPU和与用于构建应用程序本身的CUDA Toolkit兼容的NVIDIA显示驱动程序。如果应用程序依赖于库的动态链接,则系统还应该具有正确版本的这些库。"
基础的NVIDIA CUDA镜像得和你的主机上的CUDA版本对得上号。比如说,你手里有个挺新的显卡,那你就应该选一个最新的主机平台镜像。你还能挑挑不同的Linux发行版,决定是用那种带软件开发工具链的开发镜像,还是用那种拿来部署现成应用的运行时版本。
不过得注意啊,我这篇文章里头做的实验,用的GeForce RTX 2060显卡和最新的CUDA镜像不兼容。我们其实可以用老一点的镜像,但是NVIDIA的CUDA仓库里头维护了各种不同CUDA版本的Dockerfiles。所以我们可以为我们自己的CUDA版本和Linux发行版定制一个镜像。如果你想自己来构建一个CUDA镜像,那就去下载对应的Dockerfile,然后动手构建吧:
% docker build -t cuda12.2-base-ubuntu-22.04 .这部分的Dockerfile是用来安装和设置CUDA工具包的,这对于让llamafile在CUDA基础镜像里用上GPU功能是必不可少的。你得用一个跟你的CUDA版本和Linux发行版相匹配的基础镜像来替换。另外,这里还创建了一个用户,这样容器就不会以root用户的身份运行了,安全性更高。
FROM cuda-12.2-base-ubuntu-22.04 as out
RUN apt-get update && \
apt-get install -y linux-headers-$(uname -r) && \
apt-key del 7fa2af80 && \
apt-get update && \
apt-get install -y clang && \
apt-get install -y cuda-toolkit && \
addgroup --gid 1000 user && \
adduser --uid 1000 --gid 1000 --disabled-password --gecos "" user
USER user接下来的步骤是从构建器镜像中复制llamafile的二进制文件、手册页,还有LLM模型。在这个例子里,LLM模型codellama-7b-instruct.Q4_K_M.gguf是从Hugging Face上下载的。你也可以用任何和llamafile(或者llama.cpp)兼容的GGUF格式的模型。要记住,llamafile是作为服务器启动的,它包含了一个OPENAI API的接口,而且通过-ng 9999这个参数来启用GPU功能。
WORKDIR /usr/local
COPY --from=builder /download/out/bin ./bin
COPY --from=builder /download/out/share ./share/man
COPY codellama-7b-instruct.Q4_K_M.gguf /model/codellama-7b-instruct.Q4_K_M.gguf
# 不要写日志文件。
ENV LLAMA_DISABLE_LOGS=1
# 暴露8080端口。
EXPOSE 8080
# 设置入口点。
ENTRYPOINT ["/bin/sh", "/usr/local/bin/llamafile"]
# 设置默认命令。
CMD ["--server", "--nobrowser", "-ngl", "9999","--host", "0.0.0.0", "-m", "/model/codellama-7b-instruct.Q4_K_M.gguf"]构建并标记镜像。
% docker build -t llamafile-codellama-gpu .这是完整的Dockerfile。
FROM debian:trixie as builder
WORKDIR /download
RUN mkdir out && \
apt-get update && \
apt-get install -y curl git gcc make && \
git clone https://github.com/Mozilla-Ocho/llamafile.git && \
curl -L -o ./unzip https://cosmo.zip/pub/cosmos/bin/unzip && \
chmod 755 unzip && mv unzip /usr/local/bin && \
cd llamafile && make -j8 && \
make install PREFIX=/download/out
FROM cuda-12.2-base as out
RUN apt-get update && \
apt-get install -y linux-headers-$(uname -r) && \
apt-key del 7fa2af80 && \
apt-get update && \
apt-get install -y clang && \
apt-get install -y cuda-toolkit && \
addgroup --gid 1000 user && \
adduser --uid 1000 --gid 1000 --disabled-password --gecos "" user
USER user
WORKDIR /usr/local
COPY --from=builder /download/out/bin ./bin
COPY --from=builder /download/out/share ./share/man
COPY codellama-7b-instruct.Q4_K_M.gguf /model/codellama-7b-instruct.Q4_K_M.gguf
# 不要写日志文件。
ENV LLAMA_DISABLE_LOGS=1
# 暴露8080端口。
EXPOSE 8080
# 设置入口点。
ENTRYPOINT ["/bin/sh", "/usr/local/bin/llamafile"]
# 设置默认命令。
CMD ["--server", "--nobrowser", "-ngl", "9999","--host", "0.0.0.0", "-m", "/model/codellama-7b-instruct.Q4_K_M.gguf"]享受性能提升
咱们可以利用continue.dev这个开源的LLM编码VSCode插件,来试试看给llamafile开启GPU后搭配codellama-7b-instruct.Q4_K_M.gguf模型的效果。Continue.dev这个插件兼容任何支持OpenAI API的LLM。如果你想在装有GPU的笔记本上用服务器模式运行llamafile,同时在M2 Mac mini上使用VSCode,那下面这些步骤就能帮到你。
提示:
"深度优先搜索URL并打印页面作为树。"
补全:
import requests
from bs4 import BeautifulSoup
def depth_first_search(url):
"""深度优先搜索URL并打印页面作为树。"""
# 初始化一个集合来跟踪访问过的URL
visited = set()
# 创建一个队列来存储要访问的URL
queue = [url]
while queue:
# 从队列中获取下一个URL
url = queue.pop(0)
# 如果URL尚未访问,则访问它并将其子项添加到队列中
if url not in visited:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for link in soup.find_all('a'):
queue.append(link.get('href'))
print(f"{url} -> {', '.join(queue)}")
visited.add(url)首先,我先在CPU上跑了跑llamafile的可执行文件,作为性能对比的基准。
% llamafile --server --host 0.0.0.0 -m codellama-7b-instruct.Q4_K_M.gguf用CPU跑的话,提示评估的速度是每秒24个标记,整个补全过程得花上超过一分钟的时间。
print_timings: prompt eval time = 4963.79 ms / 121 tokens ( 41.02 ms per token, 24.38 tokens per second)
print_timings: eval time = 64191.60 ms / 472 runs ( 136.00 ms per token, 7.35 tokens per second)
print_timings: total time = 69155.39 ms然后呢,我开启了GPU,又运行了一遍llamafile的可执行文件。
% llamafile --server --host 0.0.0.0 -ngl 9999 -m codellama-7b-instruct.Q4_K_M.gguf用上GPU之后,提示评估的速度比用CPU快了17倍,每秒能处理426个标记。整个补全过程在11秒内就搞定了,响应时间明显提升了不少。
print_timings: prompt eval time = 283.92 ms / 121 tokens ( 2.35 ms per token, 426.18 tokens per second)
print_timings: eval time = 11134.10 ms / 470 runs ( 23.69 ms per token, 42.21 tokens per second)
print_timings: total time = 11418.02 ms后来我又试了试运行开了GPU功能的llamafile容器,想看看容器化会不会对性能有啥影响。
% docker run -it --gpus all --runtime nvidia -p 8111:8080 llamafile-codellama-gpu可以看出,容器的性能并没有下降,因为容器其本质上就是一个进程,下面的测量结果反而比单纯启用GPU的可执行文件还要稍微好那么一点儿。这个我感觉不是特别准确,应该是差不多才对。
print_timings: prompt eval time = 257.56 ms / 121 tokens ( 2.13 ms per token, 469.80 tokens per second)
print_timings: eval time = 11498.98 ms / 470 runs ( 24.47 ms per token, 40.87 tokens per second)
print_timings: total time = 11756.53 ms总结一下哈
给llamafile加上GPU支持,一下子就让它从一个实验性的玩具变成了软件工具箱里的实用工具。而且,把LLM容器化了之后,大家就不用安装和下载那些二进制文件,就能直接跑LLM了。我们可以直接从仓库拉取LLM,用很少的设置就能启动。另外,容器化还为在各种编排框架里部署LLM提供了新的可能性,你觉得呢?
