文章目录
前言
`今天介绍三大库中的pandas部分,有关三大库的numpy和matplotlib部分可以参考之前发的两篇笔记,有关新手小白的思考和遇到的问题,大家初学的也可以一起交流一下经验。
`
一、Pandas
概述:Pandas 是一个开源的第三方 Python 库,从 Numpy 和 Matplotlib 的基础上构建而来
- Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分析)
- Pandas 已经成为 Python 数据分析的必备高级工具,它的目标是成为强大、灵活、可以支持任何编程语言的数据分析工具
- Pandas 是 Python 语言的一个扩展程序库,用于数据分析
- Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具
- Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)
- Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据
- Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
应用方向:Pandas 广泛应用在学术、金融、统计学 等各个数据分析领域
Pandas 的出现使得 Python 做数据分析 的能力得到了大幅度提升,它主要实现了数据分析的五个重要环节:加载数据、整理数据、操作数据、构建数据模型、分析数据
对于我们真正迈入人工智能的基础,那么对于算法研究和数据分析是需要娴熟掌握的,以下便开始我们对此的了解。
二、安装
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/
进入Anaconda Prompt进入安装pandas数据库
先进行激活环境

下载完成,可以进入Pycharm进行检查环境是否按照完成。

三、内置数据结构
Pandas 在 ndarray 数组(NumPy 中的数组)的基础上构建出了两种不同的数据结构
分别是 Series(一维数据结构)
区别:numpy没有标签进行访问,通过索引进行访问,固定标签按顺序0、1、2、3、4、5、6...等
DataFrame(二维数据结构):不通过坐标点找数据,通过索引编号找数据。
- Series 是带标签 的一维数组,这里的标签可以理解为索引,但这个索引并不局限于整数,它也可以是字符类型,比如 a、b、c 等
-DataFrame 是一种表格型数据结构,它既有行标签,又有列标签

4、Series
Pandas Series 类似表格中等一个列(column),类似于一维数组,可以保存任何数据类型 Series 由索引(index)和列组成,函数:
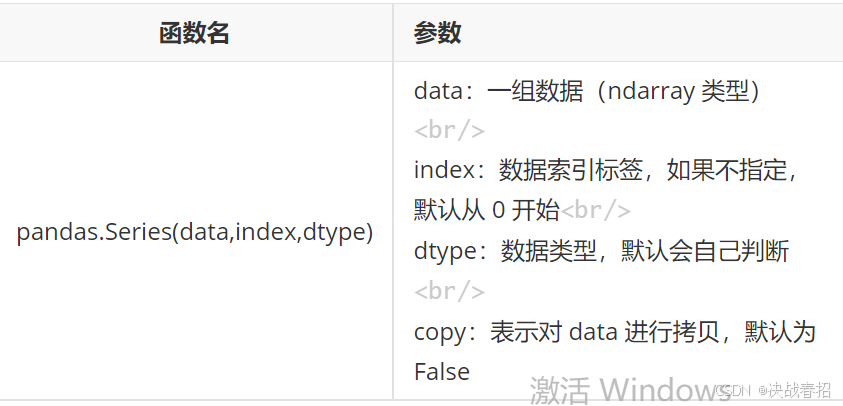
三个参数分别有相关意义,可以通过numpy、数据字典等去创建,只要是一维数组。没有指定标签默认递增按0、1、2、3、4、5...等等。主要设置的为index,修改可以按指定索引进行指定,不修改默认从0开始。
结构图:

- 0、1、2 表示行索引
- 李四、王五、张三表示数据值
- dtype 表示数据值的类型
## 4.1创建Series对象的方式
### 4.1.1创建Series空对象
举例说明: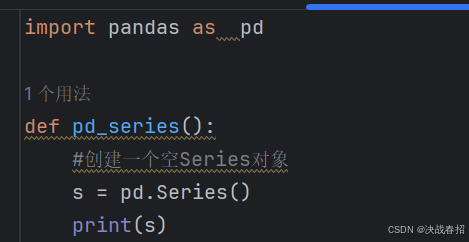

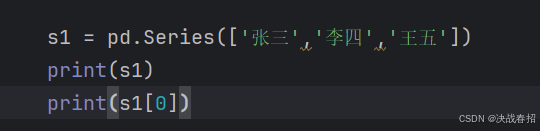
直接赋值创建Series 对象

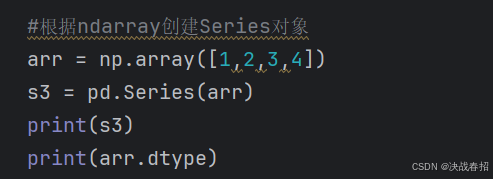
### 4.1.2 ndarray 创建 Series 对象

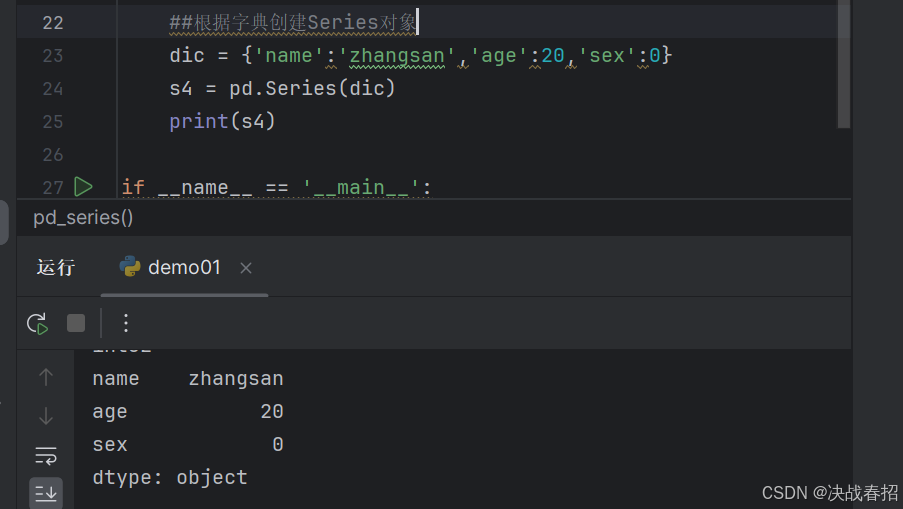
### 4.1.3 字典创建 Series 对象
### 4.2 Series 常用属性

举例相关参数输出:


## 4.4 Series 常用方法
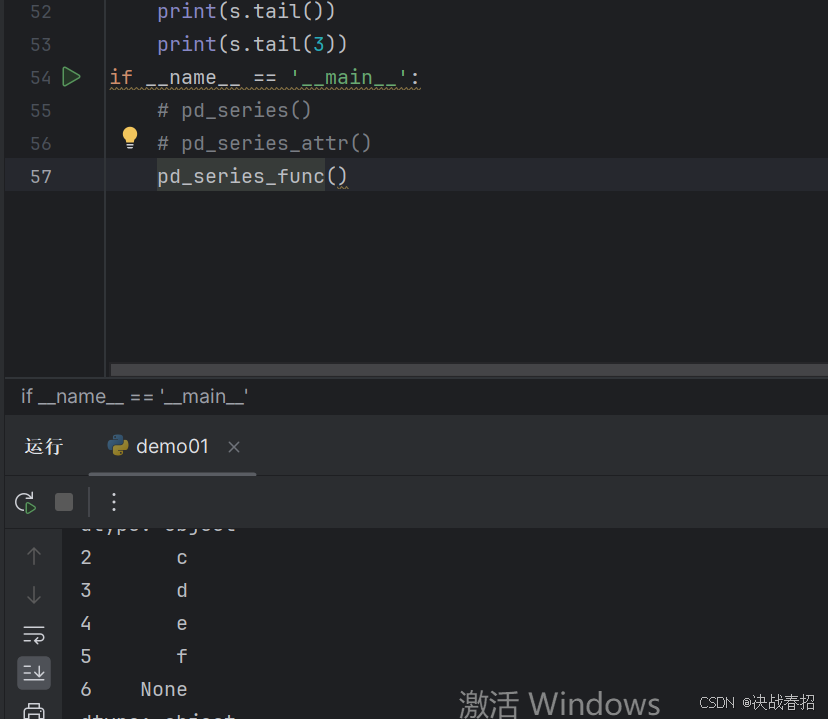
### 4.4.1 head() 和 tail()
查看 Series 的某一部分数据,使用 head() 或者 tail() 方法。其中 head() 返回前 n 行数据,默认显示前 5 行数据,tail() 返回后 n 行数据,默认为后 5 行
举例说明:
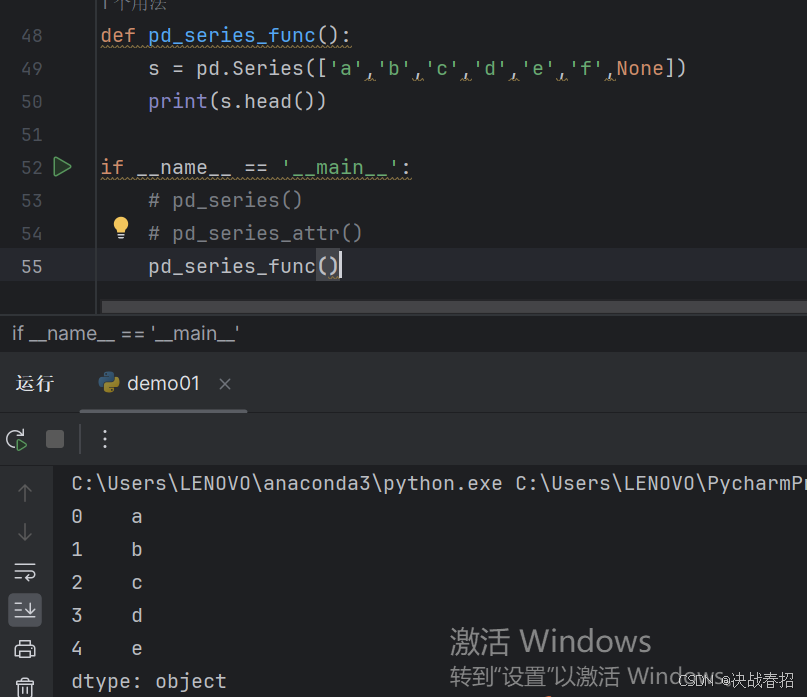
输出head=3时候,结果输出

输出tail()的时候结果打印
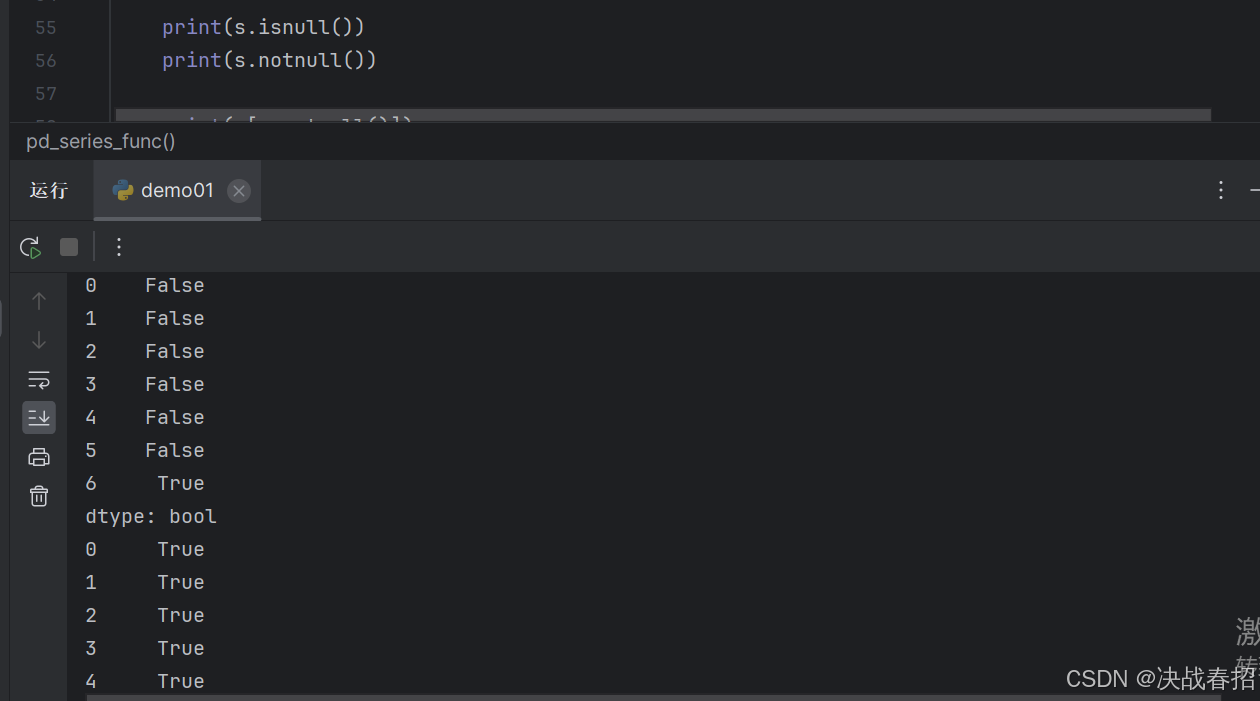
输出isnull()得到的结果和notnull得到的结果
## 5.DataFrame(重点)
概念:DataFrame 一个表格型的数据结构,既有行标签(index),又有列标签(columns),它也被称异构数据表,所谓异构,指的是表格中每列的数据类型可以不同,比如可以是字符串、整型或者浮点型等。
结构示意图:

DataFrame 的每一列数据都可以看成一个 Series 结构,只不过,DataFrame 为这些行中每个数据值增加了一个列标签。
同 Series 一样,DataFrame 自带行标签索引,默认为"隐式索引"即从 0 开始依次递增,行标签与 DataFrame 中的数据项一一对应当然你也可以用"显式索引"的方式来设置行标签。
DataFrame 构造方法如下:

## 5.1创建DataFrame对象
创建 DataFrame 对象的方式:
- 列表
- 字典
- Series
- Numpy ndarrays
- 另一个 DataFrame
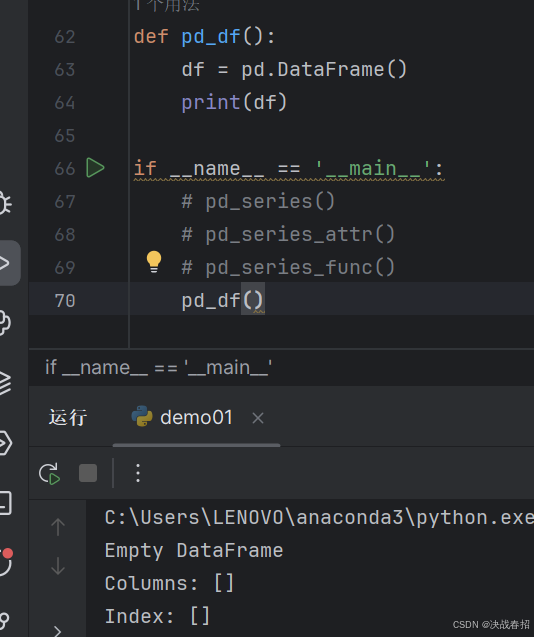
### 5.1.1创建DataFrame空对象
举例:
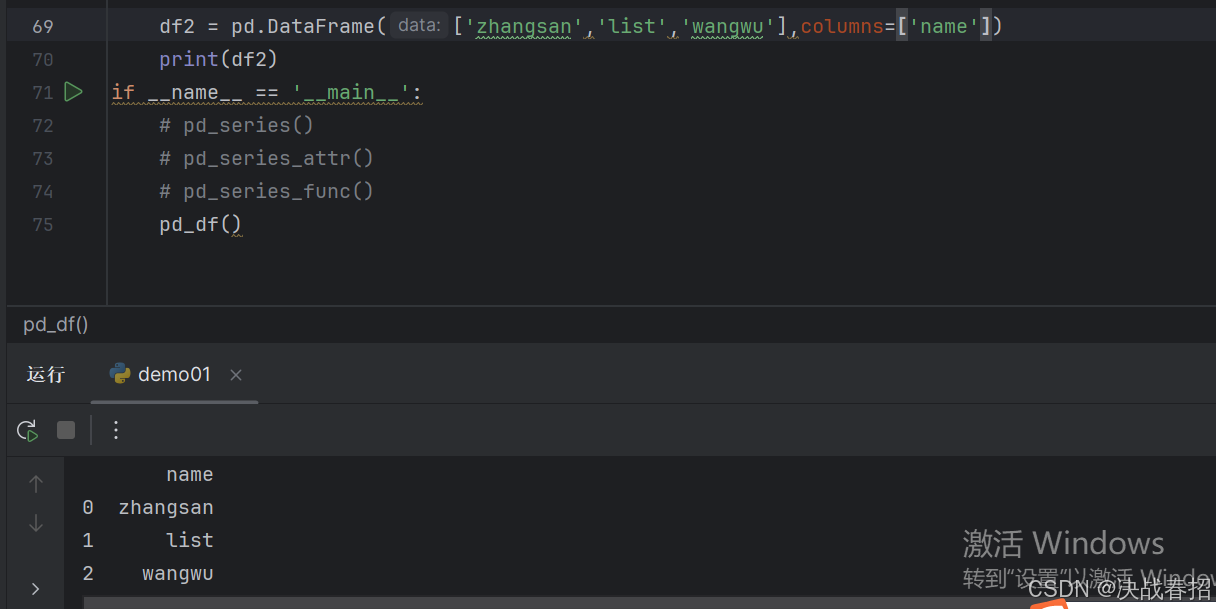
## 5.1.2 列表创建 DataFrame 对象
举例:

修改列名:
### 5.1.3 列表嵌套列表创建 DataFrame 对象
案例:
## 5.2列索引操作
DataFrame 可以使用列索(columns index)引来完成数据的选取、添加和删除操作
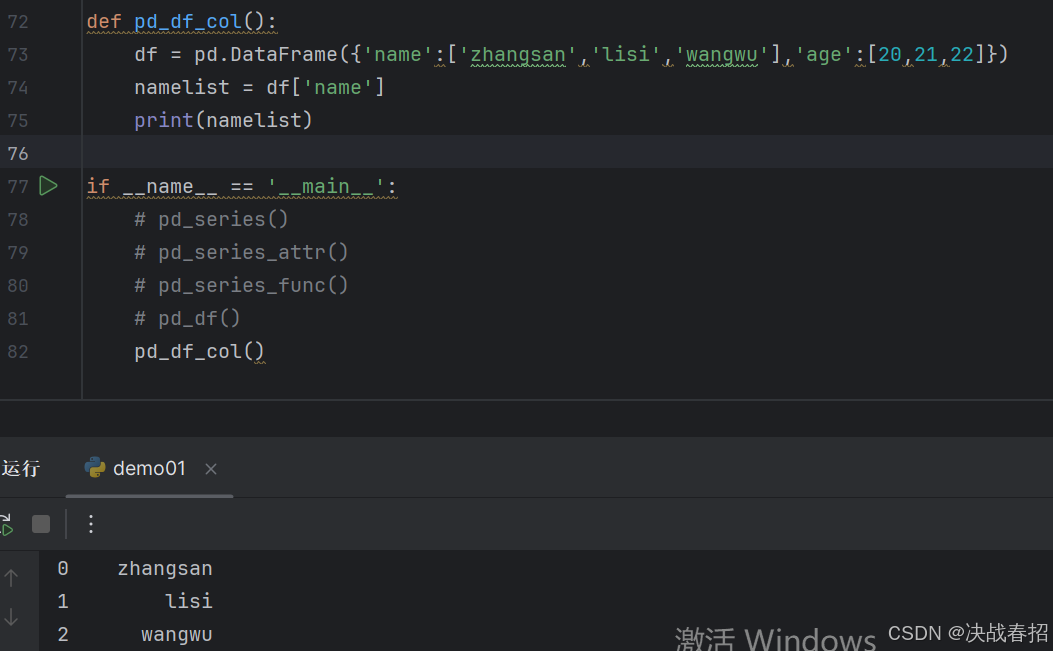
### 5.2.1选取数据
举例:
### 5.2.2 添加数据
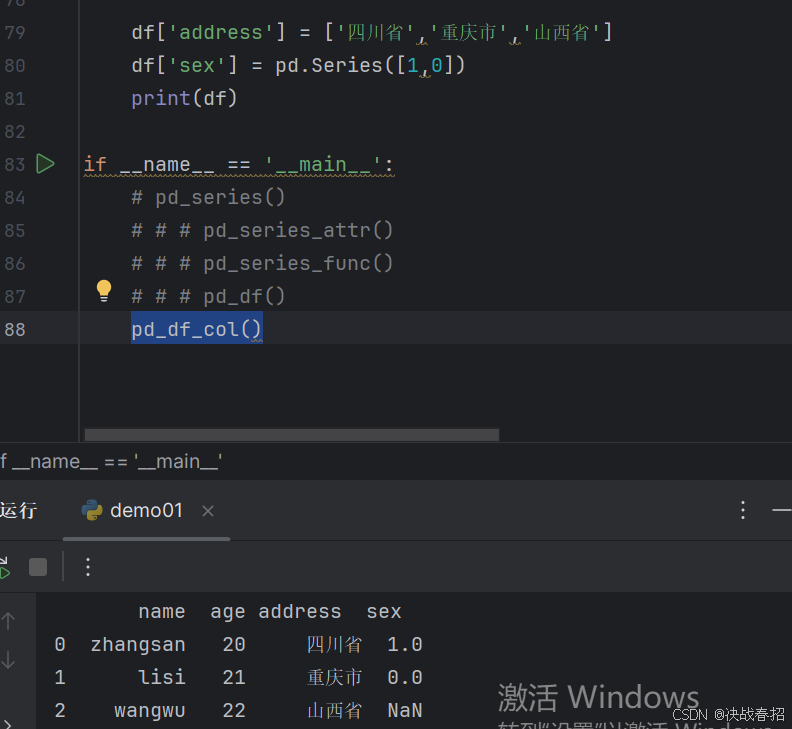
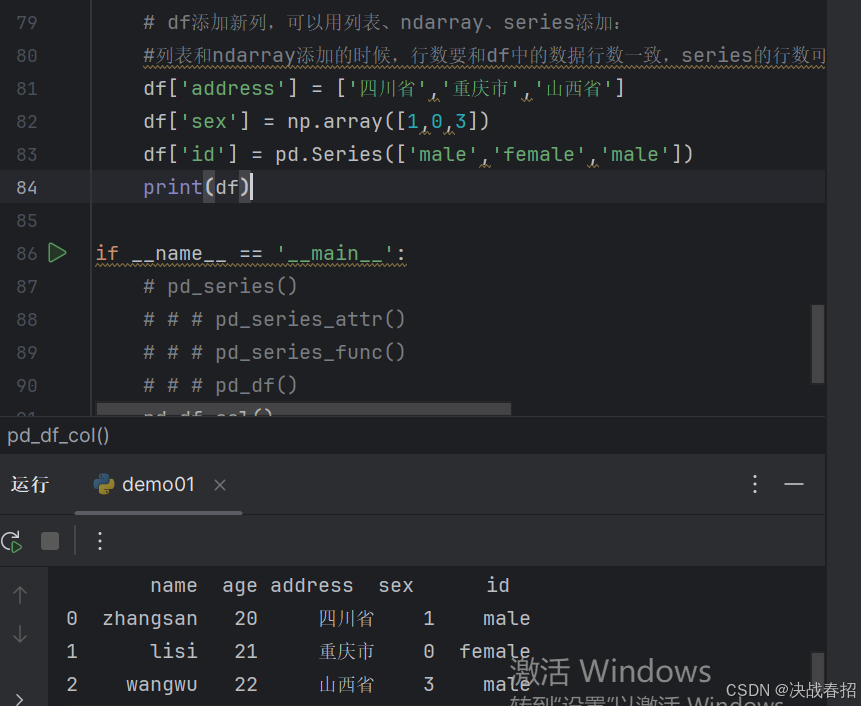
添加新列
注意事项:df添加新列,可以用列表、ndarray、series添加:
#列表和ndarray添加的时候,行数要和df中的数据行数一致,series的行数可以不一致
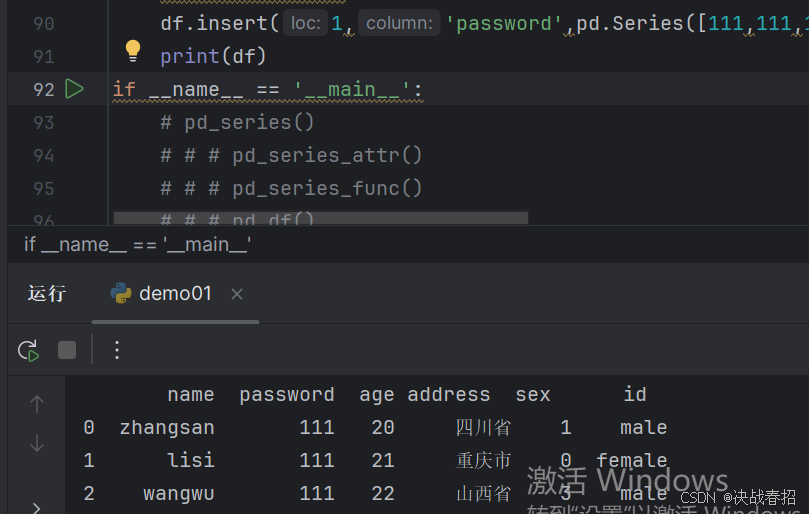
#inser在指定列插入一列数据
#loc:指定列的索引值
#column:要插入新列的列名
#value:要插入列值
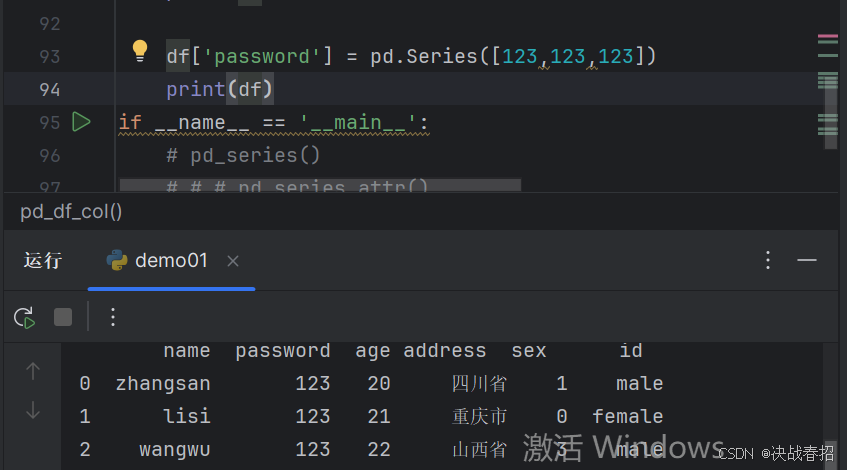
### 5.2.3 修改数据
修改某一列的值
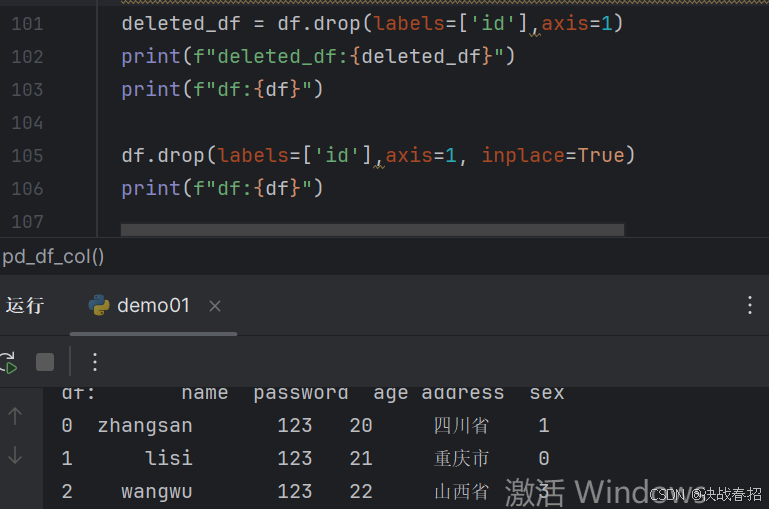
### 5.2.4删除数据


labels、axis、inplace为记忆的重点
#drop:删除列
#labels:要删除的列(行)标签
#axis:轴,axis=0:按行删除; axis=1: 按列删除
#inplace:是否在原DataFrame上删除,为True则在源Dataframe上删除
## 5.3行索引操作
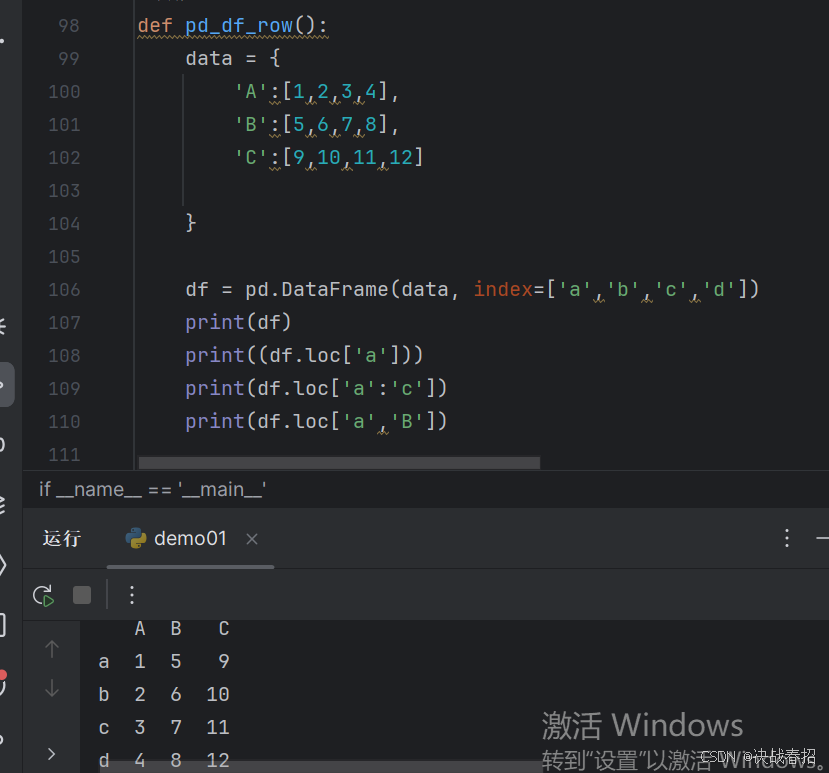
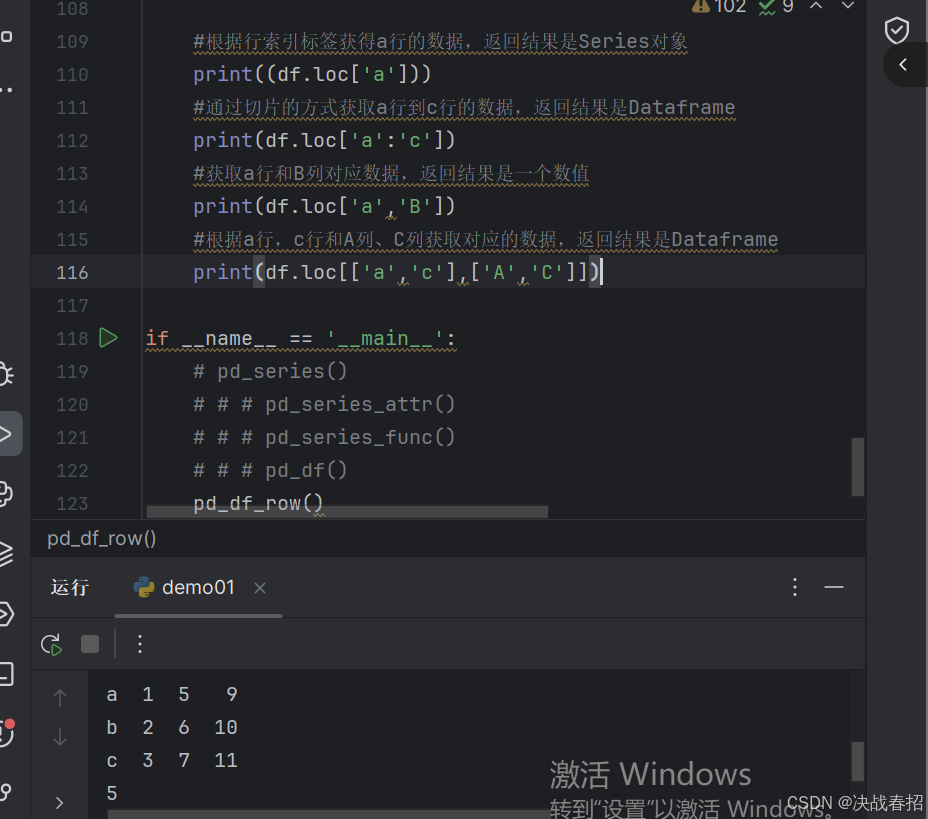
### 5.3.1loc选取数据
df.loc[] 只能使用标签索引,不能使用整数索引。当通过标签索引的切片方式来筛选数据时,它的取值前闭后闭,也就是只包括边界值标签(开始和结束)
loc方法返回的数据类型:
1.如果选择单行或单列,返回的数据类型为Series
2.选择多行或多列,返回的数据类型为DataFrame
3.选择单个元素(某行某列对应的值),返回的数据类型为该元素的原始数据类型(如整数、浮点数等)。
参数**:
- row_indexer:行标签或布尔数组。
- column_indexer:列标签或布尔数组。
举例:

### 5.3.2iloc 选取数据
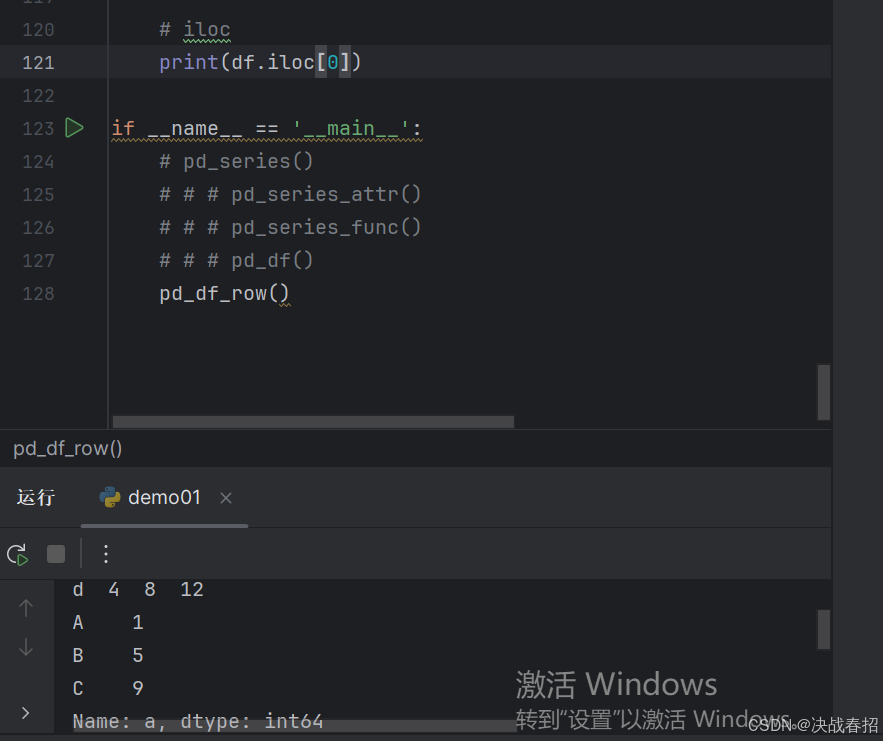
**iloc 方法用于基于位置(integer-location based)的索引**,即通过行和列的整数位置来选择数据。不能通过行或列索引标签获取数据
获取行索引位置为0的行数据
参数:
- row_indexer:行位置或布尔数组。
- column_indexer:列位置或布尔数组
- 
切片范围是左闭右闭区间
iloc区间是左闭右开区间
通过切片获取索引位置为0-2的行数据,切片的取值范围是左闭右开区间

### 5.3.3 切片多行选取
通过切片的方式进行多行数据的选取
通过行索引位置和列索引位置获取对应的数据,返回的是一个数值
得到的结果为5
### 5.3.4 添加数据行
append() 方法用于将一个 Series 或 DataFrame 追加到另一个 DataFrame 的末尾。
语法:
参数:
1. other:
- 类型:Series 或 DataFrame。
- 描述:要追加的数据。
2. ignore_index:
- 类型:布尔值,默认为 False。
- 描述:如果为 True,则忽略原 DataFrame 的索引,并生成新的整数索引,索引值默认从0开始。
3. verify_integrity:
- 类型:布尔值,默认为 False。
- 描述:如果为 True,则在创建具有重复索引的 DataFrame 时引发 ValueError。
4. sort:
- 类型:布尔值,默认为 False。
- 描述:如果为 True,则在追加之前对列进行排序。
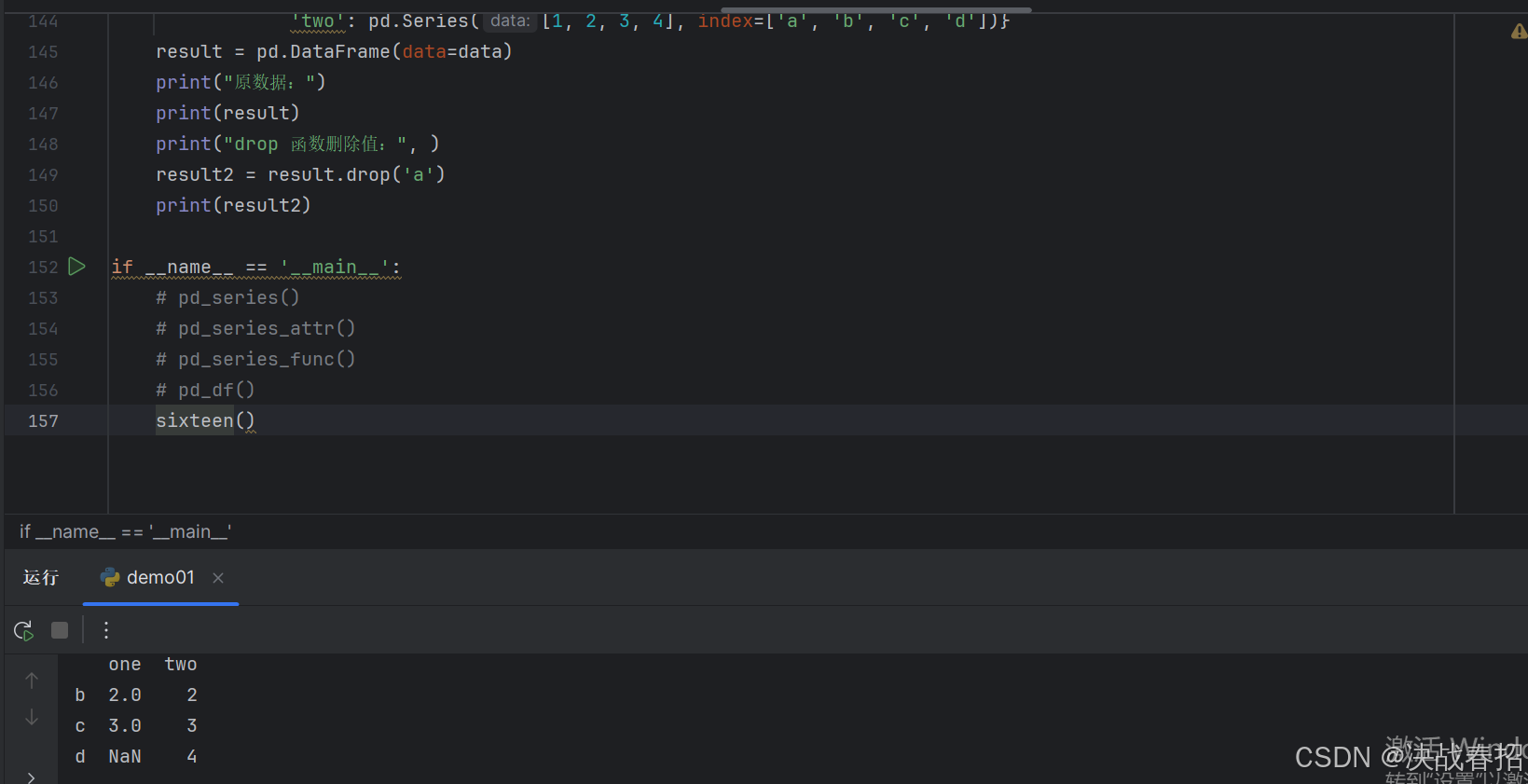
### 5.3 删除数据行
您可以使用行索引标签,从 DataFrame 中删除某一行数据。如果索引标签存在重复,那么它们将被一起删除。使用的是 drop 函数。

## 5.4 常用属性和方法
DataFrame 的属性和方法,与 Series 基本相同
| 名称 | 属性和方法描述 |
| :----: | :------------------------------------------------------: |
| T | 行和列转置。 |
| axes | 返回一个仅以行轴标签和列轴标签为成员的列表。 |
| dtypes | 返回每列数据的数据类型。 |
| empty | DataFrame中没有数据或者任意坐标轴的长度为0,则返回True。 |
| ndim | 轴的数量,也指数组的维数。 |
| shape | 返回一个元组,表示了 DataFrame 维度。 |
| size | DataFrame中的元素数量。 |
| values | 使用 numpy 数组表示 DataFrame 中的元素值。 |
| head() | 返回前 n 行数据。 |
| tail() | 返回后 n 行数据。 |