Abstract
多模态大语言模型(MLLMs)在视觉-语言任务中表现出色,涵盖了广泛的领域。然而,大规模模型和高计算成本给在消费级GPU或边缘设备上的训练和部署带来了巨大挑战,从而阻碍了其广泛应用。为了解决这个问题,我们推出了Mini-InternVL,一系列参数在1B到4B之间的多模态大语言模型,其性能可达90%,但参数量仅为5%。这种显著的效率和效果提升,使我们的模型在各种实际场景中更加易于使用和应用。为了进一步推动我们的模型普及,我们开发了一个统一的适配框架,使Mini-InternVL能够迁移并在下游任务(包括自动驾驶、医学图像和遥感)中超过专用模型。我们相信我们的研究能够为高效且有效的多模态大语言模型的发展提供宝贵的见解和资源。
项目地址:https://github.com/OpenGVLab/InternVL
欢迎加入自动驾驶实战群
Introduction
近年来,多模态大语言模型(MLLMs)取得了显著进展,利用预训练的大语言模型(LLMs)与视觉基础模型(VFMs)的强大功能相结合,通过大量图像-文本数据的多阶段训练,成功对齐了视觉表示与LLMs的潜在空间。这使得它们在通用的视觉-语言理解、推理和交互任务中表现出色。然而,模型计算负担大且在长尾领域特定任务上的表现不佳,限制了MLLMs在实际场景中的广泛应用。
轻量级MLLMs的出现为参数规模和性能之间提供了良好的平衡,缓解了对昂贵计算设备的依赖,促进了各种下游应用的发展。然而,现有模型面临诸多挑战:1)现有MLLMs使用的视觉编码器大多是基于互联网领域图像-文本数据训练的,无法涵盖广泛的视觉领域,且与LLMs的表示不一致;2)现有方法在适应特定领域时主要集中在修改模型架构、收集大量相关训练数据或为目标领域定制训练过程,但尚无一致的LLMs下游适配框架。不同领域的模型设计、数据格式和训练计划各异。
为了应对这些问题,迫切需要一个具有综合视觉知识的强大视觉编码器以及一个允许以低边际成本在各个下游任务中高效应用的通用迁移学习范式。
在本研究中,我们提出了Mini-InternVL,一系列强大的"口袋版"多模态大语言模型,能够轻松迁移到各种特定领域。首先,我们增强了轻量级视觉编码器的表示能力。我们初始化了一个300M视觉编码器,使用CLIP的权重并通过InternViT-6B作为教师模型进行知识蒸馏。随后,我们开发了Mini-InternVL系列,其参数规模为1B、2B和4B,分别与Qwen2-0.5B、InternLM2-1.8B和Phi-3-Mini等预训练LLMs集成。凭借稳健的视觉编码器,Mini-InternVL在MMBench、ChartQA和MathVista等通用多模态基准测试中表现出色。值得注意的是,与InternVL2-76B相比,Mini-InternVL-4B以5%的参数实现了90%的性能,显著减少了计算开销。
为了进一步将我们的模型适应特定领域的下游任务,我们提出了一个简单而有效的迁移学习范式,适用于包括自动驾驶、医学图像和遥感在内的各种下游任务。该方法标准化了模型架构、数据格式和训练计划。结果表明,在特定领域中,该方法有效增强了模型的视觉理解和推理能力,使其能够匹敌商业专有模型。
3.Method
在这一部分,我们介绍了 Mini-InternVL,一系列轻量级的多模态大语言模型(MLLMs)。第3.1节详细介绍了Mini-InternVL的整体架构。接下来,第3.2节描述了通过知识蒸馏开发的轻量级视觉模型 InternViT-300M,它继承了强大视觉编码器的优点。最后,第3.3节介绍了一个转移学习框架,旨在增强模型在下游任务中的适应性。
3.1 Mini-InternVL
如图1所示,Mini-InternVL包含三个主要组件:InternViT、MLP投影器和LLM。我们采用 InternViT-300M 作为我们的视觉编码器,这是一个轻量级的视觉模型,继承了强大视觉编码器的能力。基于InternViT-300M,我们开发了三个版本的Mini-InternVL:Mini-InternVL-1B、Mini-InternVL-2B 和 Mini-InternVL-4B,分别与预训练的Qwen2-0.5B、InternLM2-1.8B 和 Phi-3-mini连接。与其他开源的MLLMs类似,Mini-InternVL使用MLP投影器连接视觉编码器和LLM。
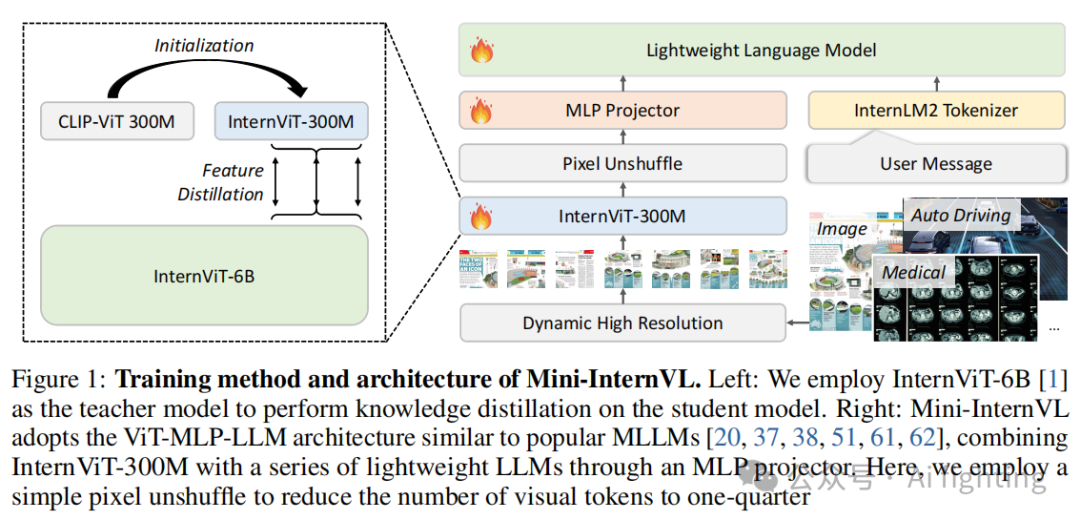
我们采用类似InternVL 1.5的动态分辨率输入策略,这提高了模型捕捉细节的能力。我们还使用像素反卷积操作,将视觉标记的数量减少到原来的四分之一。因此,在我们的模型中,448×448的图像被表示为256个视觉标记,使其能够处理多达40个图像块(即4K分辨率)。
Mini-InternVL的训练分为两个阶段:
语言-图像对齐:在这一阶段,我们仅解冻MLP组件。我们使用多样化的训练数据集进行预训练,涵盖了各种任务,包括图像标注、目标检测、OCR等。这些多样化的数据集确保了Mini-InternVL的稳健预训练,使模型能够处理跨任务的不同语言和视觉元素。
视觉指令微调:我们精心选择数据集,以增强模型在广泛多模态任务中的表现,包括图像标注、图表解释、跨领域推理等。我们通过这些数据集进行全参数微调,进一步注入世界知识,并教授模型如何遵循用户指令。
3.2 InternViT-300M
现有的大多数MLLMs采用基于大规模互联网图像-文本数据训练的视觉编码器,这些编码器的视觉世界知识有限,需要通过生成预训练和LLMs结合来迭代学习。与使用辅助路径增强视觉基础模型的方法不同,我们的方法直接利用已经通过多样化数据集进行生成训练的强大视觉模型,将知识转移到轻量级视觉模型上。具体来说,我们使用 InternViT-6B 作为教师模型,并使用 CLIP-ViT-L-336px 初始化学生模型的权重。通过计算最后K个Transformer层的隐藏状态之间的负余弦相似度损失,我们将学生模型的表示与教师模型对齐,最终得到了 InternViT-300M。
该知识转移的主要目标是继承InternViT-6B中嵌入的预训练知识。为此,我们从各种公开资源中精选了数据集,包括自然图像、OCR图像、图表和多学科图像。所有图像都被调整为448×448分辨率,并在训练时禁用了动态分辨率。最终,我们开发了一个具有多样化知识且适应多种语言模型的视觉编码器,称为 InternViT-300M。
3.3 领域适应
虽然许多研究成功地将MLLMs应用于下游任务,但尚未建立通用的适应这些应用的框架。不同领域的模型设计、数据格式和训练策略存在显著异质性,导致标准化的挑战。为了解决这个问题,我们提出了一个简单但有效的转移学习框架。
数据格式
指令微调是教会模型遵循用户指令的关键训练阶段,其中训练数据被格式化为视觉问答(VQA)和对话格式。下游任务的VQA数据集直接作为指令跟随数据使用。对于其他传统任务,我们分别将它们格式化为VQA格式。
训练策略
在领域适应阶段,我们对Mini-InternVL进行了全参数微调。对于特定领域的应用场景,我们将对应数据转换为所需的格式,并将其纳入训练数据集。在领域适应阶段添加一定比例的通用多模态数据不会影响特定领域的表现,同时保留模型的通用多模态能力。
通过这个统一的适应框架,Mini-InternVL能够高效地适应各种下游任务,同时保持其跨领域的强大能力。
4.Experiment
4.1 通用多模态基准结果
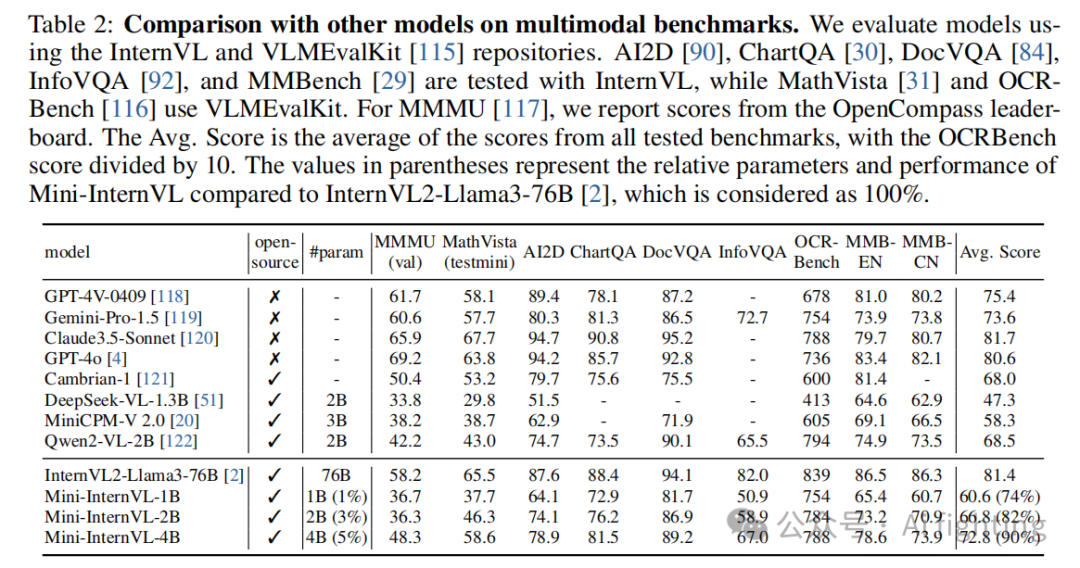
如表 2 所示,Mini-InternVL 在大多数基准上表现出色。我们最小的模型仅包含 10 亿参数,但其性能与 20 亿参数的模型(如 DeepSeek-VL-1.3B 和 MiniCPM-V 2.0)相当。与其他轻量级模型相比,Mini-InternVL-4B 在多数基准上表现出色,尤其是在 MMbench、ChartQA、DocVQA 和 MathVista 上,其性能可媲美商业模型如 Gemini-Pro-1.5。值得注意的是,与使用更大视觉模型 InternViT-6B 的 InternVL2-Llama3-76B 相比,Mini-InternVL 仅使用 5% 的参数就达到了大约 90% 的性能。这突显了我们知识蒸馏策略的有效性。
4.2 基于多视角图像的自动驾驶
设置
我们选择 DriveLM-nuScenes 1.1 版本 作为训练数据集,包含 317K 个训练样本,涵盖自动驾驶的感知、预测和规划数据。数据集中图像是从六个不同视角捕捉的,我们利用动态分辨率特性来处理这些数据。将每个视角的图像调整为 896×448 像素,并结合为一个固定的序列,最终图像分辨率为 2688×896 像素。
为了避免模型失去通用领域的感知能力,我们在训练集中加入了通用数据,保持 1:4 的通用与领域特定数据的比例。最后,我们使用 8 张 A100 GPU 对 Mini-InternVL 进行全参数微调,训练 1 个 epoch,学习率为 1e-5。
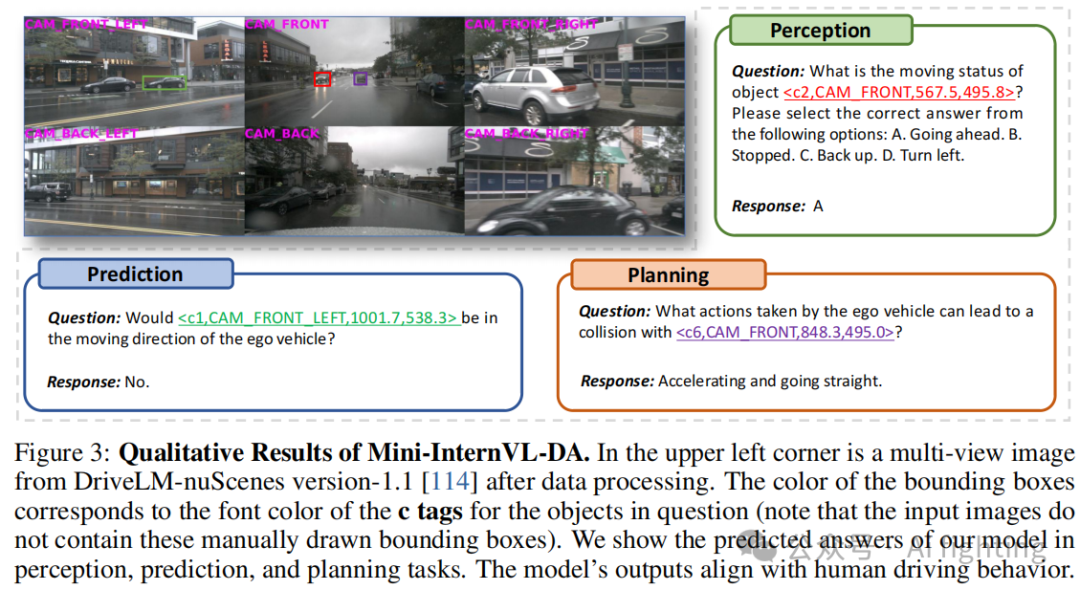
结果
我们使用 DriveLM-nuScenes 1.1 版本验证集 对模型进行测试,结果如表 4 所示。Mini-InternVL-2B 的最终得分为 0.5958,与 CVPR 2024 自动驾驶挑战排行榜上的最佳结果相当,且参数数量仅为 InternVL4Drive-v2 的十分之一。
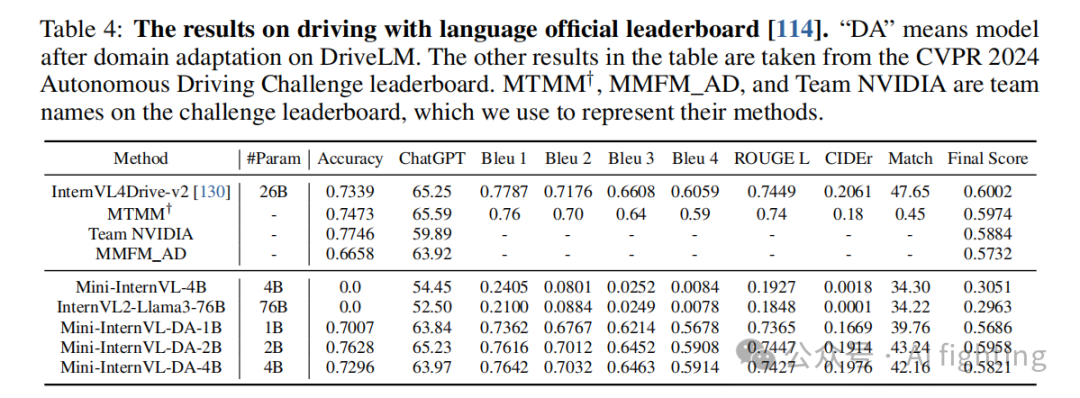
我们的模型在匹配(Match)指标上的得分略低,可能是由于Mini-InternVL在预测对象中心点方面的不足。InternVL4Drive-v2 提出了一个有效的解决方案,即使用 Segment Anything 将对象的中心点转换为边界框。在图3中,我们展示了模型在感知、预测和规划任务中的预测结果,显示出与人类驾驶行为的高度一致性。
值得注意的是,虽然我们4B参数的模型与2B参数的模型表现相似,但我们认为这可能是由于现有的训练数据和评估标准的局限性,限制了更大模型的表现提升。
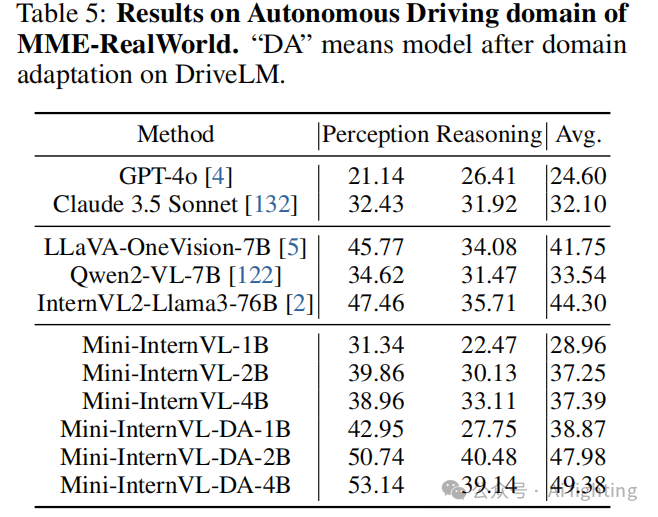
如表5所示,在 MME-Realworld 自动驾驶场景中,即使仅使用 DriveLM 作为特定领域的训练数据,我们的模型得分提高了10多个点,超过了表现最好的模型LLaVA-OneVision-7B,以及多个商业闭源模型如 GPT-4o 和 Claude 3.5 Sonnet,显示出我们模型的强大泛化能力。
4.3 带有时间信息的自动驾驶
设置
我们进一步探索了基于时间序列扩展的自动驾驶场景,使用 DriveGPT4 构建的数据集 BDD-X,其中包含 26K 段视频片段。每个训练样本包含四个方面的数据:动作描述、动作解释、速度信号预测和转向角度信号预测。
结果
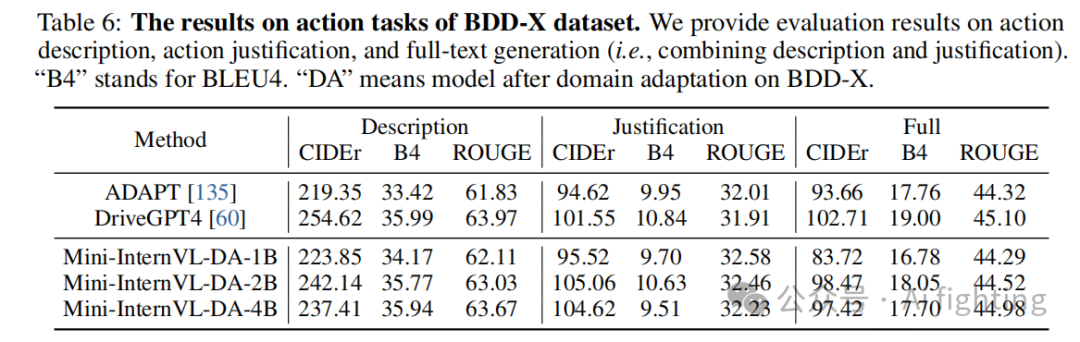
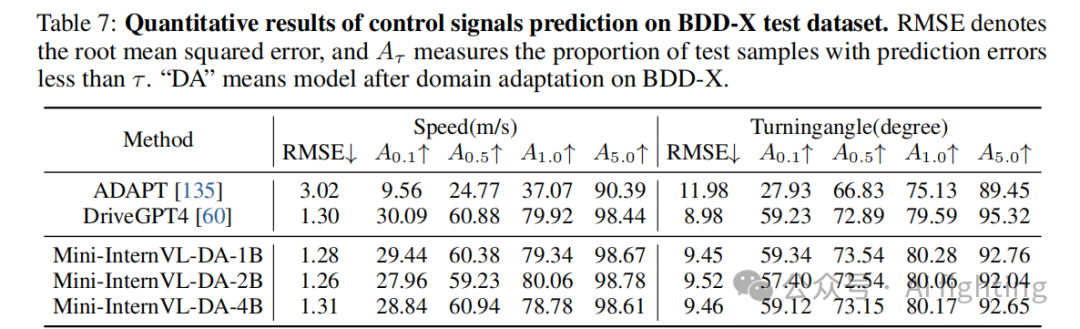
我们在 BDD-X 测试集上的得分如表 6 和表 7 所示。虽然我们的模型没有在大规模专有领域数据上进行预训练,但在四个任务上的表现与 DriveGPT4 相当,并超过了 ADAPT。
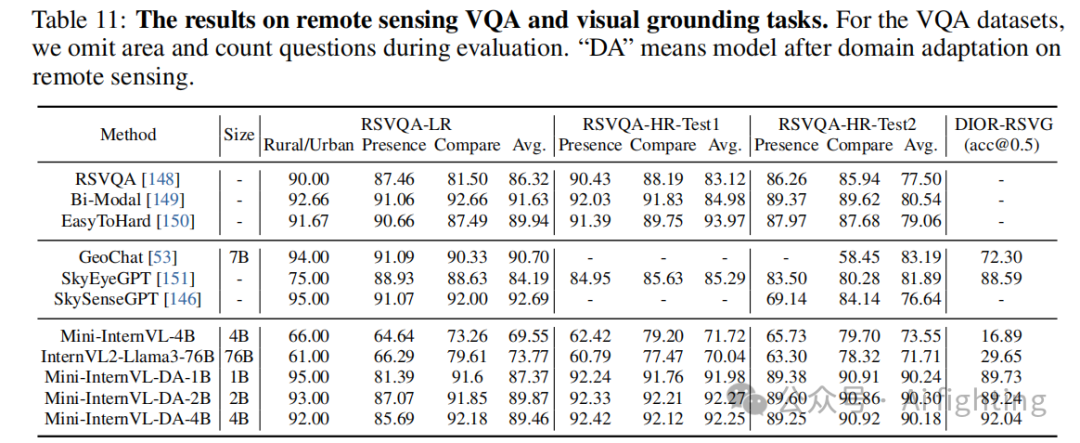
4.4 遥感
表 11 展示了我们模型在遥感 VQA 和视觉定位任务上的表现。与现有遥感 MLLMs(如 GeoChat 和 SkySenseGPT)不同,我们的模型利用动态分辨率,在高分辨率训练数据中表现优异。相比于传统模型,Mini-InternVL 在 RSVQA-HR-Test1 和 RSVQA-HR-Test2 上取得了更好的成绩,显示了它的强泛化能力。
4.5 消融研究
我们通过训练新的 20 亿参数 MLLM Mini-InternVL-CLIP-2B 来展示知识蒸馏的有效性。具体来说,我们保持 MLLM 的结构不变,但用 CLIP-ViT-L-336px 替换了视觉编码器,使用相同的训练方法。表 12 显示的结果表明,Mini-InternVL-2B 在多个基准上显著优于 Mini-InternVL-CLIP-2B。

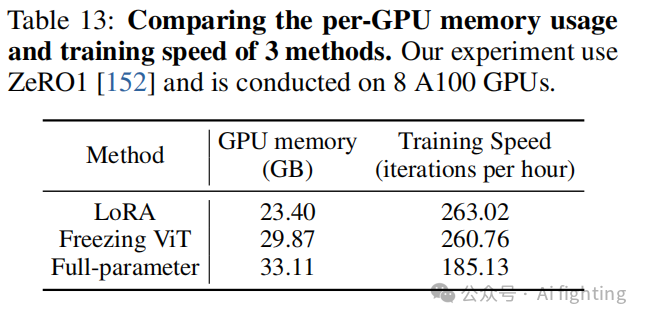
在这项研究中,我们评估了不同适应方法对模型性能的影响,包括LoRA(低秩适应)、冻结视觉编码器以及全参数微调。我们使用了 4.2.4节 中描述的数据集,对这些方法在多个基准(如通用多模态VQA、遥感VQA和视觉定位任务)上的表现进行了测试。
实验显示:
-
全参数微调:在领域特定任务上,取得了最高的分数,特别是在需要更多视觉信息处理的任务中。
-
冻结视觉编码器:在性能和计算效率之间达到了平衡。虽然分数略低于全参数微调,但在减少内存消耗和训练时间上表现出色,是计算资源有限时的一个良好选择。
-
LoRA:在视觉定位任务上的表现较弱。由于LoRA方法通过低秩矩阵近似对模型进行适应,可能在高精度定位任务中难以捕捉复杂的视觉信息。如表13所示。
结论
总结本文的贡献:
本文提出了Mini-InternVL,这是一款强大的口袋多模态模型,不仅具有不到4B参数的稳健多模态性能,还能够以较低的边际成本轻松迁移到各个领域的下游任务。
本文为Mini-InternVL开发了多个设计特性,包括适用于各种视觉领域的轻量级视觉编码器InternViT-300M。此外,我们引入了一个简单但有效的范式,标准化了模型架构、数据格式和训练计划,从而实现了下游任务的高效迁移。
本文通过广泛的实验在通用和领域特定的基准测试中对模型进行了全面评估。结果显示,Mini-InternVL在使用显著较少参数的情况下实现了90%的性能。在特定领域任务中,通过最小的计算成本进行微调,能够匹敌闭源商业模型。我们还通过一系列消融研究探讨了数据样本量对领域适应的影响,希望为MLLMs在特定领域的应用提供启示。
文章引用:Mini-InternVL: A Flexible-Transfer Pocket Multimodal Model with 5% Parameters and 90% Performance
最后别忘了,帮忙点"在看"。
您的点赞,在看,是我创作的动力。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术。
长按扫描下面二维码,加入知识星球。